高可靠的Turbo译码器后向边界初始化方法与流程
本发明属于无线通信领域中的信道编译码领域,更具体地涉及Turbo译码器的译码方法,尤其是一种适用于分量译码器采用log-map算法或max-log-map算法的Turbo译码器的高可靠Turbo译码器后向边界初始化方法。
背景技术:
为了提高无线通信的传输可靠性,一般在通信系统中采用前向信道编码技术。1993年,C.Berrou,A.Glavieux和P.Thitimajshima首先提出Turbo码的概念,Turbo码是一种并行级联卷积码,Turbo编码器中使用了两个并行的卷积码分量编码器,其中第二个分量码的输入信息序列会经过随机交织器的处理,然后进行卷积编码,编码后的信息会进行复用并进行打孔处理,以提高码率。Turbo码的提出是信道编码领域中里程碑式的突破,以其可以逼近香农极限的优异性能引起了学者们的广泛关注和研究,基于迭代的思想迅速在无线通信领域中得到普遍应用,比如迭代接收机和基于迭代方法的信道估计等。
由于Turbo码性能可以逼近香农极限,因此被多个无线通信标准采用作为前向纠错编码方案,比如高速下行分组接入(High Speed Download Packet Access,HSDPA)协议、第三代合作伙伴(3rd Generation Partnership Project,3GPP)组织的长期演进(Long Term Evolution,LTE)协议。同时Turbo码已逐渐被应用到卫星通信等系统中。
在Turbo码的应用中,接收端的译码器为了避免存储整个码块的状态度量,减少存储器的使用,一般采用滑动窗算法。为了提高传输效率,Turbo编码方案中一般都采用打孔技术删除校验比特以提升码率,在3GPP LTE系统中码率最高可达0.95。删除的校验比特对应的对数似然比(Log Likelihood Ratios,LLR)用0来填充,由于大量有效的LLR信息被删除,会导致明显的译码性能损失。传统方法通过增加训练序列长度和译码窗口长度,来提升高码率下的性能,但会导致存储器开销和译码延迟增加。
技术实现要素:
有鉴于此,本发明为了解决现有技术方案在采用滑动窗算法的译码算法时,在高码率下存在性能下降明显的问题,特别提出了一种高可靠的Turbo译码器后向β边界初始化方法。
具体地,本发明提出了一种Turbo译码器后向边界初始化方法,其特征在于,包括以下步骤:
同时结合训练序列和迭代之间边界传递的方法,将第k-1次迭代时的第i个译码窗口起始位置的β边界值进行存储,在第k次迭代时将上一次迭代时第i个窗口起始位置的β边界值传递给第i-2个译码窗口对应的训练窗口作为其β边界初始值,通过训练窗口的后向递归计算产生第i-2个译码窗口的β边界初始值,其中i为自然数,i≥3。
其中,在第一次迭代中,除最后一个译码窗口外,译码窗口的边界初始值只通过训练序列产生,训练序列的β初始值设置为等概率值。
其中,在每次迭代时,从第三个译码窗口开始到最后一个译码窗口,需要将这些译码窗口的头部起始位置的β边界值存储到SMP存储器中。
其中,在第二次及后续的迭代中,对第一个译码窗口的训练序列而言,其β边界初始值设置为上一次迭代时SMP存储器中保存的第三个译码窗口的β边界初始值。
其中,最后两个译码窗口不需要上次迭代传递的边界值作为训练序列的边界初始值。
其中,所述Turbo译码器采用log-map译码算法或max-log-map译码算法的分量译码器。
本发明还提供了一种Turbo译码器后向边界初始化方法,其特征在于,包括以下步骤:
步骤S1,进行数据分窗,假设码块长度为N,窗口的长度为W,则共有个译码窗口,其中表示向上取整,N和W均为正整数;训练序列的长度和译码窗口长度一致均为W;
步骤S2,在第一次迭代时,先同时进行前向递归计算和训练序列的后向递归计算,由此通过前向递归计算得到前向递归状态度量α,并将其存储到后进先出存储器,通过训练序列的后向递归计算得到译码窗口的β边界初始值;
然后开始译码窗口内的后向递归计算,在后向递归计算的过程中,将得到的β边界初始值和从后进先出存储器中取出的α值送给对数似然比计算单元计算对应比特的对数似然比值;当第一个译码窗口内的所有比特的对数似然比值都计算结束后,计算下一个译码窗口,并重复上面操作;
从第三个译码窗口开始,将译码窗口的头部起始位置的β值存储到SMP存储器中,用来在下一次迭代中作为相依训练序列的β边界初始值;
步骤S3,在第二次迭代时,将上一次迭代时存储在SMP存储器中第i个窗口头部起始位置的β边界初始值传递给第i-2个译码窗口对应的训练序列作为其β边界初始值,其中i为自然数,且i≥3;
步骤S4,重复上述步骤S3直到达到固定迭代次数,译码结束。
其中,步骤2在第一次迭代中,所述训练序列的后向递归β的边界初始值都设置为等概率的值。
其中,对第个窗口而言,即倒数第二个译码窗口,其训练序列的边界初始值就是整个网格图的β边界初始值,不需要上次迭代的边界值;对第个窗口而言,即最后一个译码窗口,没有训练序列,同样不需要上次迭代的边界值;但是两个窗口的头部起始位置的β值需传递给下一次迭代。
从上述技术方案可知,和现有的边界初始化方案相比,本发明的方案同时需要训练序列和迭代间的边界传递,在第一次迭代时译码窗口的训练序列长度为L,但在第二次迭代时译码序列的训练长度可以认为是3L,当第三次迭代时训练长度为6L。随着迭代次数增加训练序列的等效长度迅速增加,所以该方案计算产生的后向β边界可靠性更高,这样在达到同样误码率的情况下可以使用更小的译码窗口,从而减少了存储器的开销;本发明可以同时适用于分量译码器采用log-map译码算法和max-log-map译码算法的Turbo译码器,可以适用于多种通信标准。
和现有技术方案相比,在同样的误码率条件下,该方案大大降低了存储器开销;可以同时适用于分量译码器采用log-map译码算法和max-log-map译码算法的Turbo译码器,可以适用于多种通信标准;在高码率下可以使用更小的滑动窗窗口实现同样的性能,而且在并行译码架构下,可以大量的减少存储状态度量信息的存储器开销。
附图说明
图1为对译码过程中窗口划分的说明图;
图2为本发明的边界初始化方法的操作示意图;
图3为使用该方法的Turbo译码器中分量译码器的原理架构图;
图4为将该方法应用于3GPP LTE系统中码块长度6144、码率为0.95时的误码率仿真图;
图5为在3GPP LTE系统的Turbo译码器中应用该方案的误码率仿真图。
具体实施方式
Turbo译码器借鉴了电子电路中反馈的概念,采用了一种迭代译码架构,通过在两个软输入/软输出(SISO)分量译码器之间交换外信息的方式进行多次迭代译码,译码结束进行硬判决输出译码结果。
出于性能和复杂度的综合考虑,译码算法一般采用max-log-MAP算法。
其中αk和βk分别是前向递归状态度量和后向递归状态度量,γk(s’,s)表示的是从状态s’跳转到状态s的分支度量。
前向递归状态度量αk和后向递归状态度量βk可以通过以下递归公式进行计算:
αk(s)≈max(αk-1(s′0)+γk(s′0,s),αk-1(s′1)+λk(s′1,s)) (2)
βk(s)≈max(βk+1(s0)+γk+1(s′,s0),βk+1(s1)+γk+1(s′1,s)) (3)
由于编码器初始状态为0,则状态度量α的边界初始值α0(0)=0,α0(s)=-∞,s≠0。编码器终止状态也为0,故β的边界初始值为βN(0)=0,βN(s)=-∞,s≠0。
在LLR计算中,根据不同的信息比特输入分成两组,分支度量计算公式如下:
其中uk、分别代表造成状态转换的信息比特、编码器输出的系统比特和校验比特,La(uk)代表信息比特的先验信息,代表系统比特的信道软信息,代表校验比特的信道软信息。
迭代译码时,两个分量译码器之间需要传递外信息作为先验信息。外信息计算公式如下:
max-log-MAP算法是在log-MAP算法的基础上做了近似,带来约0.4dB的性能损失,通过对外信息乘以修正因子s可以将性能损失减小到0.1dB左右。
同时,在接收端,译码算法中为了避免存储整个码块的状态度量,较少存储器的使用,一般采用滑动窗算法。为了提高传输效率,Turbo编码方案中一般都采用打孔技术删除校验比特以提升码率,在3GPP LTE系统中码率最高可达0.95。删除的校验比特对应的对数似然比(Log Likelihood Ratios,LLR)用0来填充,由于大量有效的LLR信息被删除,会导致明显的译码性能损失。传统方法通过增加训练序列长度和译码窗口长度,来提升高码率下的性能,但会导致存储器开销和译码延迟增加。
为了提升高码率下性能,第一种方案是将译码窗口和训练窗口长度增加到低码率下的2到3倍;第二种方案是将译码窗口和训练窗口长度均设置为128,传递方式下窗口设置为96,但仍存在不足。第三种方案是将上一次迭代过程中训练窗口提供给译码窗口的边界初始值传递给下一次迭代,作为相邻的训练窗口的边界初始值,在第k-1次迭代时,窗口2L~3L为训练窗口,给译码窗口L~2L提供边界初始值,将该边界初始值存储下来,并传递给第k次迭代作为训练窗口L~2L的边界初始值。针对在高码率下滑动窗算法由于边界不可靠造成性能下降的问题,本发明提出了一种解决方案,同样结合训练序列和边界传递的方法,但是在同样的窗口大小时,相比于上述三种方案均有很明显的误码率性能提升。
更具体地,本发明针对分量译码器采用log-map算法或max-log-map算法的Turbo译码器的设计,公开了一种应用于采用滑动窗算法的Turbo译码器的译码窗口边界β初始化设计方案,其中结合训练方式和传递方式,将上一次迭代时译码窗口起始位置的β值传递给下一次迭代,作为前一个训练窗口的β的边界初始值,从而可以保证随迭代次数增加,获得β边界的等效训练长度快速增加,从而提升了β初始边界值的可靠性;和现有技术方案相比,在同样的误码率条件下,该方案大大降低了存储器开销;可以同时适用于分量译码器采用log-map译码算法和max-log-map译码算法的Turbo译码器,可以适用于多种通信标准;在高码率下可以使用更小的滑动窗窗口实现同样的性能,而且在并行译码架构下,可以大量的减少存储状态度量信息的存储器开销。
作为本发明的一个优选实施方式,本发明公开了一种适用于高码率下高可靠的Turbo译码器后向边界初始化方法,包括以下步骤:
同时结合训练序列的方法和迭代之间边界传递的方法,将第k-1次迭代时的译码窗口i(i≥3)起始位置的β边界值存储起来,在第k次迭代时将上一次迭代时窗口i(i≥3)起始位置的β边界值传递给译码窗口i-2对应的训练窗口作为其β边界初始值。在经过训练窗口的后向递归计算产生译码窗口i-2的β边界初始值。
其中,在第一次迭代中,除最后一个译码窗口外,译码窗口的边界初始值只通过训练序列产生,训练序列的β初始值设置为等概率值。
其中,在每次迭代时,从第三个译码窗口开始到最后一个译码窗口,需要将这些译码窗口的头部起始位置的β边界值存储到SMP存储器中。
其中,在第二次及后续的迭代中,对第一个译码窗口的训练序列而言,其β初始值设置为上一次迭代时SMP存储器中保存的第三个译码窗口的β边界初始值。
其中,最后两个译码窗口不需要上次迭代传递的边界值作为训练序列的边界初始值。
作为本发明的一个优选实施方式,本发明公开了本发明的适用于高码率下的边界初始化方法,主要包括以下步骤:
首先进行数据分窗,假设码块长度为N,窗口的长度为W,则共有个译码窗口,其中表示向上取整。训练序列的长度和译码窗口长度一致均为W。
在第一次迭代或分量译码器中的半迭代运算时,首先同时进行前向α递归计算和训练序列的后向递归计算,在第一次迭代中,训练序列的后向递归β的边界值都设置为等概率的值。在前向递归计算时,译码窗口内的α值都存储在LIFO存储器(Last in first out,后进先出存储器)中。当前向递归和后向递归都计算到该译码窗口的尾部结束位置时,前向递归和训练序列的后向递归结束,后向递归计算出译码窗口的β边界初始值,然后开始译码窗口内的后向递归计算,在后向递归计算的过程中,将计算出来的β和从LIFO中取出来的α值送给LLR计算单元计算对应比特的LLR值,由于计算的LLR是逆着窗口的顺序计算,所以需要对计算出的LLR进行整序。当第一个译码窗口内的所有比特的LLR都计算结束后,可以计算下一个译码窗口,并重复上面操作。从第三个译码窗口开始,将译码窗口的头部起始位置的β值存储到SMP存储器中,用来在下一次迭代中作为相依训练序列的β边界初始值。
在第二次迭代时,在第k次迭代将上一次迭代时存储在SMP存储器中窗口i(i≥3)头部起始位置的β值传递给译码窗口i-2对应的训练序列作为其β边界初始值。这样的话对于本次迭代的译码窗口i-2而言,就有相当于三倍窗口长度W的训练序列长度。对第个窗口而言,即倒数第二个译码窗口,其训练序列就是最后一个窗口,所以其训练序列的边界初始值就是整个网格图的β边界初始值,不需要上次迭代的边界值,对第个窗口而言,即最后一个译码窗口,没有训练序列,同样不需要上次迭代的边界值。但是两个窗口的头部起始位置的β值需传递给下一次迭代。
重复以上步骤直到达到固定迭代次数,译码结束。
为使本发明的目的、具体方案和优点更加清晰,以下结合3GPP LTE系统中Turbo编译码的具体实施例,并参照附图,对本发明进一步详细说明。
图1所示为对译码过程中窗口划分的说明图,其中将整个码块划分为5个窗口,每个窗口长度为L。其中译码窗口指的是当前译码比特所在的窗口,训练序列或训练窗口是指与当前译码窗口相邻的后一个窗口。以图1中为例,0~L为当前译码窗口,则L~2L为对应的训练窗口。其中译码窗口的0处为起始位置,L处为尾部位置。其中译码窗口的尾部L处β值称为译码窗口的β边界初始值,其中训练窗口的尾部2L处的β边界值称为β边界初始值。译码时译码窗口内的前向递归和训练序列的后向递归同时进行,递归到两个窗口的交界处,即达到译码窗口的尾部后,开始译码窗口内的后向递归计算β,同时计算LLR。
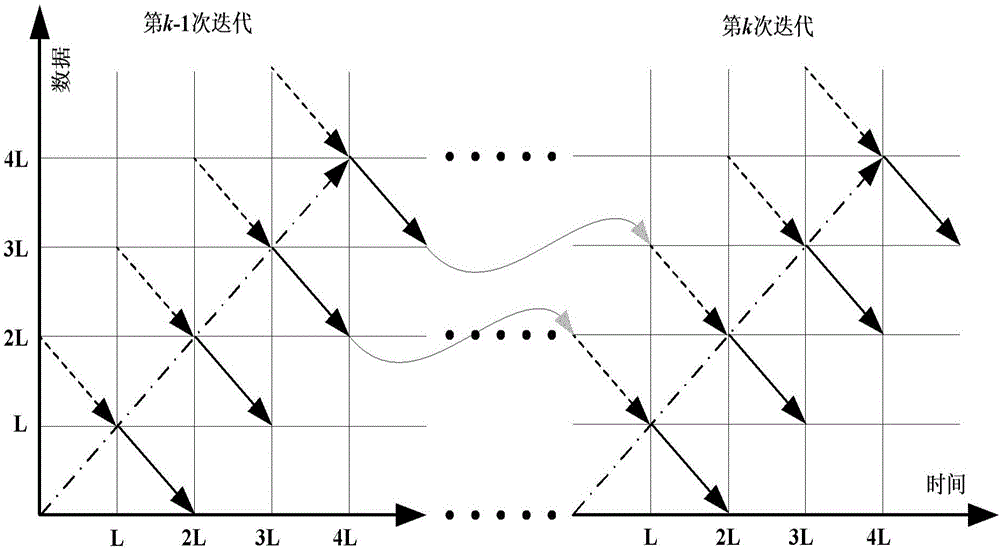
图2所示为本发明的具体的边界初始化方法的迭代示意图,主要阐述如何结合上一次迭代过程中的β值进行边界传递。要分两种情况对待,区分第一次迭代和后续的迭代计算过程。在第一次迭代时,只通过训练序列来产生译码窗口的后向β边界初始值,没有边界传递。在后续的迭代过程中,将k-1迭代计算中保存下来的第i+2个译码窗口头部起始位置的β边界值传递给第k迭代的第i个译码窗口对应的训练序列,作为训练序列的β边界初始值,然后通过训练序列的后向递归产生译码窗口的β边界初始值。以图2中为例,在第k次迭代时,假设当前的译码窗口为0~L,则其对应的训练序列为L~2L,则将上一次迭代中存储的译码窗口2L~3L的头部起始位置的β边界值传递给训练序列作为β初始值。这样对于第k次迭代的译码窗口0~L而言,产生其β边界初始值的相当于是由上次迭代中2L~4L,加上本次迭代中的L~2L共同递归计算产生的译码窗口的β边界初始值,这样的话就有等效为3L长度的训练序列来产生译码窗口的边界初始值。
图3所示为本发明的Turbo译码器分量译码器的原理架构图,首先将译码器前面的软解调模块产生的信道软输出信息存储到存储器中,当译码开始后,读取信道软输出的存储器,首先计算分值度量值γ,将计算出来的γ值一路送给其中SMP存储器用于存储每次迭代中译码窗口的边界初始值,另一路送给前向状态度量α计算单元,其计算结果保存在后入先出LIFO存储器中,用来LLR的计算。还有一路送给dummy β计算单元,用于训练序列的后向递归训练,将计算产生的β边界值传递给β计算单元作为译码窗口的边界初始值。后向状态度量β计算单元则进行译码窗口的后向递归计算,在计算过程中当有β计算出来后送给LLR计算单元计算对应比特的LLR,当后向递归到译码窗口的头部起始位置后,将该位置的β值存储在SMP存储器中传递给下一次迭代。由于从第三个译码窗口开始保存,故只需要保存个译码窗口头部起始位置的β边界值。
图4所示为在3GPP LTE系统中的Turbo译码器中应用该方案的性能仿真图,其中横坐标表示信噪比(Signal Noise Ratio,SNR),纵坐标表示比特误码率(Bit Error Rate,BER)。码块长度为6144,打孔后码率为0.95,为了方便对比,所有的方案译码算法均采用max-log-map算法,可见本发明的方案在达到同样的性能时,窗口长度仅为32,传统的单纯采用训练序列需要窗口长度为128,单纯采用边界传递的方案需要窗口长度为96。本发明需要的窗口长度分别是训练序列方案和边界传递方案的1/4和1/3。
图5所示为在3GPP LTE系统中的Turbo译码器中应用该方案的性能仿真图,其中横坐标表示信噪比(SNR),纵坐标表示比特误码率(BER)。码块长度为6144,打孔后码率为0.95,为了方便对比,所有的方案译码算法均采用max-log-map算法。和现有的混合训练序列和边界传递的方案相比,在窗口长度均为32的时候,本发明的方案在误码率为10-5时较现有的混合方案性能好0.1dB,但是采用的硬件开销是一致的。现有的方案在窗口长度为40时可以达到和本发明的方案同样的性能。
通过上述方案,和单纯使用训练序列的方式相比,本发明仅增加了存储L-2个窗口边界值的存储器,译码器就可以在高码率下以窗口长度为32达到非常优异的性能,而传统的训练序列方案则需要窗口长度为128,和传统的结合训练序列和边界传递的方案相比,该方案存储的窗口边界数目与传统方案一致,即增加的用于存储每次迭代时窗口边界的存储器大小一样,但是滑动窗口比传统的混合方案更小就可以达到同样的性能。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!