基于TCP重组的审计系统的制作方法
本实用新型涉及网络信息安全技术领域,具体说是一种基于TCP重组的审计系统。
背景技术:
随着网络技术的广泛应用,信息安全问题日益严峻,网络安全分析系统也应运而生,如网络审计系统、网络入侵检测系统和网络信息还原系统等。此类系统大多包括三个模块:数据获取模块、数据解析模块和数据存储模块。其中,怎样高效的正确的获取网络中的数据流是整个系统的基础,同时也是最关键最重要的一项技术。
现有的网络安全分析系统,大多是由网络中间链路抓取数据包,再通过分析这些数据包的特征来区分网络行为的,从网络中间链路抓取的数据包并不交由操作系统的协议栈进行处理。抓取网络中的数据包有很多开源的工具包,比如Linux系统下的Libcap,windows系统下的winpcap以及Java中间件JPCAP。但是,单单捕获数据包并不能保证数据的正确性。因为同一数据流中的数据包可能经过不同的网络路径到达目的地,造成数据包的不同时延,丢失,乱序等现象出现。因此,将从网络中间链路捕获来的数据包整合成有序的,不丢失的有序数据流的技术(即数据重组技术)成为了很多安全系统研究的关键技术。
可见,为适应当前大流量网络安全需求,高效的、可靠的数据重组方法的研究显得尤为重要。
现有的基于哈希表和TCP接收序列号的TCP数据流重组算法,其基本思想是:对于一个捕获的数据包,需要根据一个哈希函数将其映射到哈希表中,同时根据哈希表中tcp链接数据流的接收序列号来判断该数据包是否合法。利用哈希表查找的高效性保证高速大流量TCP数据流重组,利用数据包的序列号保证数据包接收的正确性。
目前,在各种网络安全软件中都会涉及到TCP数据流重组的技术,相关的技术也有很多:
(1)基于二维链表实现TCP重组
二维链表的第一列为链表头节点,链表头节点有三部分组成:第一个部分主要是源IP地址、目的IP地址、源端口号和目的端口号组成的四元组;第二部分由TCP数据包的基本信息字段和指向同一个TCP连接的下一个数据包对象的引用组成,其中基本信息字段包括源IP地址、目的IP地址、源端口号、目的端口号、标志位、序号和数据等字段;第三部分表示的是下一个头结点的对象引用,而在头结点之后是普通数据节点,普通数据节点包括源IP地址、目的IP地址、源端口号和目的端口号组成的四元组,还有数据信息、Prex引用和Next引用,这两个引用分别指向该节点的上一个节点和下一个节点,每个节点中还有时间字段,增加时间字段是为了后续操作中动态的删除过时或超时的连接及其数据包。二维链表来存放数据有很多优点:首先,它具有良好的组织架构,并且许多优秀的查找算法能保证查找的速度,提高了系统运行的效率;其次,删除结点的操作更加节省空间和时间,只需简单的修改该节点的前后结点引用就可以。
(2)基于splay树实现TCP重组
splay树是一种自调整形式的二叉查找树,每次将访问结点通过一系列旋转移动到最上层成为根结点。其理论依据是应用程序访问树结点有偏颇性,即在一段时间内部分结点访问相对频繁,不停地将最近访问的结点移到树根,可以提高整体访问效率。由于网络数据包的到达存在局部性原理,即本次数据包所属连接的下一个数据包会很快到达,因此,本次访问结点很可能再次被访问,查找只需比较一次即可。当该树经历一系列访问后,最近频繁访问的结点就会靠近根结点,减少了平均查找遍历次数,提高了整体查找效率。
但是,基于二维链表实现TCP重组的技术,在进行TCP链接查找的时候受限于链表这种数据结构效率不够高;而基于splay树实现TCP重组的技术实现起来较为复杂且效率提升也不是很明显。因此,为适应当前大流量网络安全需求,对于高效率的,可靠的网络数据流重组方法的研究显得尤为重要。
TCP重组完成后,需要对TCP链接进行解析,并对解析后的文本内容进行敏感词汇匹配,检索是否存在敏感信息,从而保证局域网的安全。目前,使用范围最为广泛的字符串匹配算法是单模式和多模式匹配算法。单模式匹配和多模式匹配的主要区别在于:如果存在多个模式需要匹配,单模式匹配算法每次只能执行一次模式匹配,而如果使用多模式匹配算法,则会把全部模式进行相关处理后能够一次匹配所有模式。单模式匹配算法中,最著名的两个是KMP算法和BM算法。这两个算法在最坏情况下均具有线性的查找时间。但是如果字符串模式不止一个而是多个字符串模式组成的集合,那么BM算法就不太适合了。WM算法是一种典型的多模式匹配算法,它是在BM算法基础上改进而来的匹配算法,它使用多个字符组成的字符块来进行匹配,不像其他算法的单个字符比较,前缀表的恰当运用,降低了匹配过程中所消耗的时间,因此能够取得良好的实际效果。但是,WM算法有时不够稳定,对于某些模式集和字符串可能会发生退化现象,导致效率不够高。
TCP协议是一种面向连接的、可靠的传输协议,而在TCP之下的IP协议是面向报文不可靠协议,不能保证将报文按顺序的、可靠的交付。因此,大量的数据包可能同时到来且杂乱无章,甚至出现丢失的情况。为了将这些乱序的数据包重新整合成有序的数据流,TCP首部的序列号和标识符成为关键。
数据包重组仅关心TCP序号、应答号及数据,还有几个特殊的TCP标志。所述特殊的标志有:SYN,ACK,RST,FIN。
SYN:表示同步序号,用来建立连接。SYN和ACK要在一起使用,如果SYN=1,ACK=0,则表示发送的是请求数据;如果SYN=1,ACK=1,则表示发送的是响应数据。
ACK:表示应答域有效,即TCP数据包中的TCP应答号,该域有两个取值:0和1,当其大小为1时,表示有效,取其大小为0时则表示无效;
RST:表示发送复位请求。当出现异常连接和数据时,需要通过此标志位来设置复位请求。
FIN:当发送方把全部信息传输完后,需要通过FIN通知接收方,然后关闭彼此间的连接。
TCP是面向连接的可靠传输服务,可靠的传输服务需要通过可靠的双向连接来实现,TCP连接建立的过程称为三次握手,其大致流程如下:
第一次握手:客户端通过向服务器发送syn包(syn=i),表示自己期望和服务器之间建立连接,准备接收服务器的应答消息;
第二次握手:当服务器接收到客户端发送过来的syn包后,如果同意建立连接,则向客户端发送两个包告诉客户端可以建立连接,这两个包一个确认包ack(ack=i+l;)和一个自己的SYN包(syn=j);
第三次握手:客户端接收到服务器发送过来的两个数据包后,知道双方可以建立连接,现在就向服务器发送确认包ACK(ack=j+l),这样经过过三次握手就建立起了可靠的通信连接。
技术实现要素:
针对现有技术中存在的缺陷,本实用新型的目的在于提供一种基于TCP重组的审计系统。该系统提供了基于哈希表和TCP链接序列号的数据重组模块,使得哈希映射的冲突降低,同时又利用了哈希表实现简单的特点,提高了TCP重组的效率。并且对数据处理中的多字符匹配进行了改进,提高了审计的效率。
为达到以上目的,本实用新型采取的技术方案是:
一种基于TCP重组的审计系统,包括:数据捕获模块、数据重组模块和数据处理模块;
数据捕获模块,与数据重组模块相连,用于抓取被审计主机的数据包,并将抓取的数据包存储到其存储单元中;
数据重组模块,与数据处理模块相连,用于从存储单元中的数据包中提取数据,并对提取的数据进行重组,形成完整的TCP链接;
数据处理模块,用于对数据重组模块形成的TCP链接进行解析,并对解析后的文本内容进行敏感词匹配。
在上述方案的基础上,所述数据捕获模块包括:JPCAP单元、数据包拆封单元、信息提取单元、哈希值计算单元和存储单元;
JPCAP单元与数据包拆封单元连接,数据包拆封单元与信息提取单元连接,信息提取单元与哈希值计算单元连接;
JPCAP单元用于抓取链路层上的数据包;
数据包拆封单元用于对每一个数据包进行拆封,获取其传输层协议信息,当传输层协议信息为TCP协议时,将拆封后的数据包输出至信息提取单元;
信息提取单元用于提取数据包中的四元组信息、序列号、确认号和标识位;所述四元组信息包括源IP地址、目的IP地址、源端口和目的端口;
哈希值计算单元用于通过四元组信息获取TCP链接的哈希值,哈希值用于定位到哈希表中该TCP链接。
在上述方案的基础上,所述存储单元中的数据包形成数据包队列,依次输出给数据重组模块。
在上述方案的基础上,所述数据重组模块包括:TCP标志位判断单元、指令获取单元和哈希表管理单元;
TCP标志位判断单元与指令获取单元连接,指令获取单元与哈希表管理单元连接;
哈希表管理单元用于通过哈希表存储TCP链接;
TCP标志位判断单元用于根据TCP标志位的情况计算出相应的决策信息;
指令获取单元用于根据决策信息输出对应的控制指令。
在上述方案的基础上,所述控制指令包括:
创建一个新的TCP链接放入哈希表指令,
根据哈希值查找哈希表指令,
更新客户端和服务器端状态指令,
更新接收流和发送流指令,
TCP链接完成接收指令,
TCP链接移除指令。
在上述方案的基础上,所述数据处理模块包括数据解析单元和数据匹配单元;
数据解析单元用于对数据重组模块形成的TCP链接进行解析;
数据匹配单元用于对解析后的文本内容进行敏感词匹配。
在上述方案的基础上,所述数据匹配单元包括Trie树构造单元和敏感词匹配单元;
Trie树构造单元,用于根据敏感词中各字符的位置信息判断字符状态,根据字符状态将敏感词加载到内存中构造Trie树;
敏感词匹配单元,用于根据敏感词字符在Trie树中的字符状态,对敏感词进行多字符匹配。
在上述方案的基础上,所述字符状态包括:中间态和结尾态。
本实用新型所述的基于TCP重组的审计系统的有益效果:
本实用新型通过基于哈希表和TCP链接序列号的数据重组模块高效率的实现了TCP重组,使得哈希映射的冲突降低,提高了查表效率,查找TCP链接的速度提高,从而使得TCP重组的效率得到提高。并且,数据处理模块对多字符匹配进行了改进,有效的提高了审计的速度和效率。
附图说明
本实用新型有如下附图:
图1基于TCP重组的审计系统的系统架构示意图;
图2改进的Trie树逻辑结构示意图。
具体实施方式
以下结合附图对本实用新型作进一步详细说明。
如图1和图2所示,本实用新型所述的一种基于TCP重组的审计系统,包括:数据捕获模块、数据重组模块和数据处理模块;
数据捕获模块设于审计服务器中,与数据重组模块相连,用于抓取被审计主机的数据包,并将抓取的数据包存储到其存储单元中;
数据重组模块,与数据处理模块相连,用于从存储单元中的数据包中提取数据,并对提取的数据进行重组,形成完整的TCP链接;
数据处理模块,用于对数据重组模块形成的TCP链接进行解析,并对解析后的文本内容进行敏感词汇匹配。
在上述方案的基础上,所述数据捕获模块包括:JPCAP单元、数据包拆封单元、信息提取单元、哈希值计算单元和存储单元;
JPCAP单元与数据包拆封单元连接,数据包拆封单元与信息提取单元连接,信息提取单元与哈希值计算单元连接;
JPCAP单元用于抓取链路层上的数据包;
数据包拆封单元用于对每一个数据包进行拆封,获取其传输层协议信息,当传输层协议信息为TCP协议时,将拆封后的数据包输出至信息提取单元;
信息提取单元用于提取数据包中的四元组信息、序列号、确认号和标识位;所述四元组信息包括源IP地址、目的IP地址、源端口和目的端口;
哈希值计算单元用于通过四元组信息获取TCP链接的哈希值,哈希值用于定位到哈希表中该TCP链接。
在上述方案的基础上,所述存储单元中的数据包形成数据包队列,依次输出给数据重组模块。
在上述方案的基础上,所述数据重组模块包括:TCP标志位判断单元、指令获取单元和哈希表管理单元;
TCP标志位判断单元与指令获取单元连接,指令获取单元与哈希表管理单元连接;
哈希表管理单元用于通过哈希表存储TCP链接;
TCP标志位判断单元用于根据TCP标志位的情况计算出相应的决策信息;
指令获取单元用于根据决策信息输出对应的控制指令。
在上述方案的基础上,所述控制指令包括:
创建一个新的TCP链接放入哈希表指令,例如:如果数据包的SYN为1,ACK为0,说明这是一个请求同步包,所以创建一个新的TCP链接放入HASH表中,同时初始化该链接中发送流的信息:状态为SYN_SENT,下一个包的序列号为当前包的SEQ+1;
根据哈希值查找哈希表指令,例如:如果数据包的SYN为1,ACK为1,根据该包的四元组的哈希值去哈希表中找,如果找到,则服务器同意建立链接,如果该数据包的ACK_NUM等于客户端的下一个包的序列号,那么初始化该链接中服务器端的信息:状态为SYN_RCVD,设置服务器端的期望接收的序列号为数据包的ACK_NUM;
更新客户端和服务器端状态指令,例如:如果数据包的ACK为1,来自客户端,且客户端的状态为SYN_SENT,服务器端状态为SYN_RCVD,且它的序列号与服务器端期待接收的序列号相等,则连接建立成功,更新客户端和服务器端状态为ESTABLISHED;
更新接收流和发送流指令,例如:如果数据包长度不为0或者标志位FIN为1,说明这是普通的数据包或者释放连接的包;如果当前包的序列号等于接受数据流中期待接收的序列号,把当前包加入到接收流中;如果这个包FIN为1,要设置发送流的状态为FIN_SENT;如果ACK同时也为1的话,通过接收流状态为FIN_SENT,则更新其状态为CONFIRMED,更新接收流的期待接收序列号为:数据包的长度+1;如果这个包FIN为0,更新接收流的期待接收序列号为:数据包的长度;更新后遍历接收流中的乱序包缓冲区,是否有包符合接收流期待的序列号,如果有重复该步骤;
TCP链接完成接收指令,例如:如果数据包的ACK为1,如果接收流状态为FIN_SENT,更新其状态为CONFIRMED;如果接收流和发送流都为CONFIRMED,则TCP链接完成接收;
TCP链接移除指令,例如:如果包RST为1,在哈希表中移除该链接。
在上述方案的基础上,所述数据处理模块包括数据解析单元和匹配单元;
数据解析单元用于对数据重组模块形成的TCP链接进行解析;
匹配单元用于对解析后的文本内容进行敏感词匹配。
在上述方案的基础上,所述匹配单元包括Trie树构造单元和敏感词匹配单元;
Trie树构造单元,用于根据敏感词中各字符的位置信息判断字符状态,根据字符状态将敏感词加载到内存中构造Trie树;
敏感词匹配单元,用于根据敏感词字符在Trie树中的字符状态,对所有敏感词进行多字符匹配。
在上述方案的基础上,所述字符状态包括:
中间态,例如:读取敏感词的首字符,判断Trie树中是否有该字符,如果有则读取下一个字符;如果没有则作为Trie树的头结点插入首字符哈希表中,并设置该字符的状态为中间态;读取下一个字符,判断Trie树中是否存在该字符,如果有则继续读取下一个字符,以此类推;如果没有则向Trie树中插入该字符,如果该字符不是该敏感词的最后一个字符,设置该字符状态为中间态;
结尾态,例如:读取敏感词的最后一个字符,判断Trie树中是否有该字符,如果没有则向Trie树中插入该字符,如果有则设置该字符状态为结尾态。
敏感词匹配单元用于根据敏感词字符在Trie树中的字符状态,对所有敏感词进行快速多字符匹配,例如:依次读取待匹配敏感词的字符,在Trie树中的首字符哈希表中查找是否有匹配的字符,如果没有,则继续读取下一个字符;如果有,判断当前字符状态,如果为中间态,读取待匹配敏感词的下一个字符;
在当前Trie树的子节点中查找是否有匹配的字符,如果没有则继续读取下一个字符,如果有则判断当前字符状态;如果为中间态,读取待匹配敏感词的下一个字符;如果当前字符为结尾态,匹配成功;重复上述步骤,直至所有待匹配敏感词匹配完成。
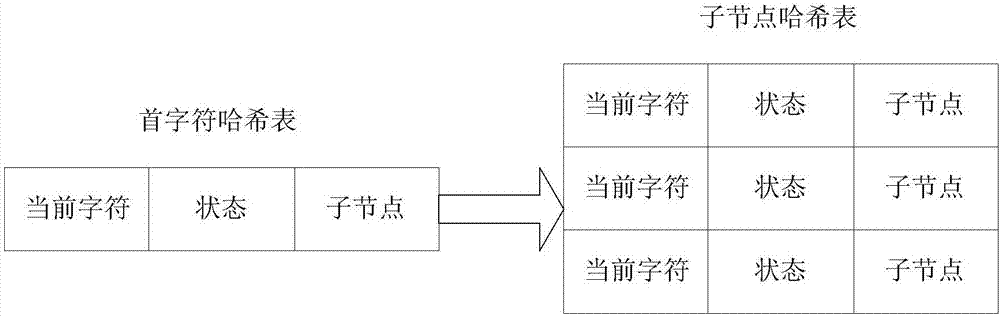
数据处理模块中的数据匹配单元式一种基于改进Trie树的有限自动机(DFA)多模式匹配单元,DFA的基本功能是可以通过event和当前的state得到下一个state,即event+state=nextstate。在敏感词匹配单元中为了能够应付较高的并发,有一个目标比较重要,就是尽量减少计算,而在DFA中基本没有什么计算,有的只是状态转移。本系统采用改进的Trie树实现DFA。改进的Trie树由首字符哈希表和子节点构成,每个敏感词都能构成一棵Trie树,构造Trie树的过程中把字符参与构词的位置信息定义成不同的状态,这样就构成一个有限的自动机。如果一个字符不是某个敏感词的尾字,称为中间态,用0表示。
子节点是所有以当前字符为前缀的的字符集合,子节点的数据结构可以采用顺序机构、链式结构和哈希结构等等。数据结构决定了查找时间的复杂度以及空间复杂度。这里我们采用哈希结构。敏感词的首字符形成的节点,存放在首字符哈希表中,子节点采用哈希结构,状态用来判断是否到达词尾,改进的Trie树逻辑结构如图2所示。
Trie树构造完成之后就可以对文本内容进行快速多字符匹配了。以文本内容中的某个首字符作为首字符查找改进的Trie树结构,以该首字符作为首字符的所有敏感词构成一个有限自动机,每个节点处于有限自动机的一个状态,读取字符串的下一个字符作为自动机的输入,根据自动机状态进行转移,当到达结尾状态时完成一个匹配。
本说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!