用于耳机虚拟化的混响生成的制作方法
相关申请的交叉引用
本申请要求以下申请的优先权:2015年2月12日提交的中国专利申请no.201510077020.3;2015年2月17日提交的美国临时申请no.62/117,206;以及2016年2月5日提交的中国申请no.2016100812817,这些申请通过引用被整体结合于此。
本公开的实施例大体上涉及音频信号处理,并且更具体地涉及用于耳机虚拟化的混响生成。
背景技术:
为了创建更令人沉浸的音频体验,当通过耳机呈现2声道立体声和多声道音频节目时,可以使用双耳音频渲染来对这些音频节目给予空间感觉。一般地,可以通过对适当设计的双耳房间脉冲响应(brir)与节目中的每个音频声道或对象进行卷积来创建空间感觉,其中brir表征特定声学环境中的从空间中的特定点到收听者的耳朵的音频信号的变换。该处理可以或者由内容创建者应用,或者由消费者回放设备应用。
虚拟器设计方法是从或者物理房间/头部测量或者房间/头部模型模拟来导出brir的全部或部分。通常,具有非常期望的声学性质的房间或房间模型被选择,目标是耳机虚拟器可以复制实际房间的引人注目的收听体验。在房间模型精确地体现所选择的收听房间的声学特性的假定下,该方法产生虚拟化brir,这些虚拟化brir固有地应用空间音频感知所必需的听觉线索。听觉线索可以例如包括耳间时差(itd)、耳间声强差(ild)、耳间互相关(iacc)、混响时间(例如,随频率而变化的t60)、直接与混响(dr)能量比、特定的谱峰和谱凹口(notches)、回声密度等。在理想的brir测量和耳机收听条件下,基于物理房间brir的多声道音频文件的双耳音频渲染可以听起来与相同房间中的扩音器呈现几乎不可区分。
但是,该方法的缺点是,物理房间brir可以以不期望的方式修改要被渲染的信号。当遵照房间声学法则设计brir时,导致外部化(externalization)感觉的感知线索中的一些(诸如谱梳理(spectralcombing)和长的t60时间)还引起副作用,诸如声染色(soundcoloration)和时间拖尾。事实上,即使是最高品质的收听房间也将对渲染的输出信号给予对于耳机再现不期望的一些副作用。此外,在实际测量房间中收听双耳内容期间可以实现的引人注目的收听体验在其他环境(房间)中收听相同内容期间很少实现。
技术实现要素:
鉴于以上,本公开提供了一种关于用于耳机虚拟化的混响生成的解决方案。
在一个方面,本公开的示例实施例提供了一种生成用于耳机虚拟化的双耳房间脉冲响应(brir)的一个或多个分量的方法。在该方法中,生成定向控制(directionallycontrolled)的反射,其中定向控制的反射对与声源定位对应的音频输入信号给予期望的感知线索,然后至少所生成的反射被组合以获得brir的该一个或多个分量。
在另一方面,本公开的另一示例实施例提供了一种生成用于耳机虚拟化的双耳房间脉冲响应(brir)的一个或多个分量的系统。该系统包括反射生成单元和组合单元。反射生成单元被配置为生成定向控制的反射,这些定向控制的反射对与声源定位对应的音频输入信号给予期望的感知线索。组合单元被配置为组合至少所生成的反射以获得brir的该一个或多个分量。
通过以下描述,将意识到,根据本公开的示例实施例,通过组合来自被选择的方向的多个合成房间反射来生成brir后期响应以增强空间中的给定定位处的虚拟声源的错觉(illusion)。反射方向上的改变对随着时间和频率而变化的模拟后期响应给予iacc。iacc主要影响声源外部化和宽敞度(spaciousness)的人类感知。本领域技术人员可以意识到,在本文中所公开的示例实施例中,某些定向反射图案可以在相对于现有技术方法保持音频保真度的同时传达自然的外部化感觉。例如,定向图案可以是振荡(摆动)形状。另外,通过在方位角(azimuth)和仰角(elevation)的预定范围内引入扩散(diffusion)方向分量,对反射给予一定程度的随意性(randomness),这可以提高自然的感觉。以这种方式,该方法旨在捕获物理房间的本质而没有其限制。
完整的虚拟器可以通过组合多个brir来实现,每个虚拟声源(固定的扩音器或音频对象)一个brir。根据以上第一示例,每个声源具有独特的后期响应,该后期响应具有加强声源定位的方向属性。该方法的关键优点是,较高的直接与混响(dr)比可以用于实现与常规的合成混响方法相同的外部化感觉。较高的dr比的使用导致渲染的双耳信号中更小的可听伪像(audibleartifact)(诸如谱染色和时间拖尾)。
附图说明
通过以下参照附图的详细描述,本公开的实施例的以上和其他目的、特征和优点将变得更可理解。在附图中,本公开的数个示例实施例将被以示例的而非限制性的方式示出,其中:
图1是根据本公开的示例实施例的用于耳机虚拟化的混响生成的系统的框图;
图2示出根据本公开的示例实施例的预定定向图案的示图;
图3a和图3b分别示出用于左声道扩音器和右声道扩音器的良好外部化和不良外部化brir对的、短期表观方向(apparentdirection)随着时间推移的改变的示图;
图4示出根据本公开的另一示例实施例的预定定向图案的示图;
图5示出根据本公开的示例实施例的用于在给定发生时间点生成反射的方法;
图6是一般的反馈延迟网络(fdn)的框图;
图7是根据本公开的另一示例实施例的用于fdn环境中的耳机虚拟化的混响生成的系统的框图;
图8是根据本公开的进一步的示例实施例的用于fdn环境中的耳机虚拟化的混响生成的系统的框图;
图9是根据本公开的更进一步的示例实施例的用于fdn环境中的耳机虚拟化的混响生成的系统的框图;
图10是根据本公开的示例实施例的用于fdn环境中的多个音频声道或对象的耳机虚拟化的混响生成的系统的框图;
图11是根据本公开的另一示例实施例的用于fdn环境中的多个音频声道或对象的耳机虚拟化的混响生成的系统的框图;
图12是根据本公开的进一步的示例实施例的用于fdn环境中的多个音频声道或对象的耳机虚拟化的混响生成的系统的框图;
图13是根据本公开的更进一步的示例实施例的用于fdn环境中的多个音频声道或对象的耳机虚拟化的混响生成的系统的框图;
图14是根据本公开的示例实施例的生成brir的一个或多个分量的方法的流程图;以及
图15是适合用于实现本公开的示例实施例的示例计算机系统的框图。
在整个附图中,相同的或对应的附图标记是指相同的或对应的部分。
具体实施方式
现在将参照附图中所示的各种示例实施例来描述本公开的原理。应意识到,这些实施例的描绘仅仅是为了使得本领域技术人员能够更好地理解并且进一步实现本公开,而非意图以任何方式限制本公开的范围。
在附图中,本公开的各种实施例是在框图、流程图和其他示图中示出的。流程图或框图中的每个方框可以表示包含用于执行特定的逻辑功能的一个或多个可执行指令的模块、程序或代码的一部分。虽然这些方框是按照用于执行该方法的步骤的特别的顺序示出的,但是它们可能不一定严格地根据示出的顺序执行。例如,依赖于相应操作的性质,它们可以按照相反的顺序或同时地执行。还应注意,框图和/或流程图中的每个方框及其组合可以由用于执行特定的功能/操作的基于专用硬件的系统来实现,或者由专用硬件和计算机指令的组合来实现。
如本文中所使用的,术语“包括”及其变型要被解读为意指“包括但不限于”的开放式的术语。术语“或”要被解读为“和/或”,除非上下文以其他方式清楚地指示。术语“基于”要被解读为“至少部分基于”。术语“一个示例实施例”和“示例实施例”要被解读为“至少一个示例实施例”。术语“另一实施例”要被解读为“至少一个其他的实施例”。
如本文中所使用的,术语“音频对象”或“对象”是指在声场中存在限定的持续时间的单个的音频元素。音频对象可以是动态的或静态的。例如,音频对象可以是充当声场中的声源的人类、动物或任何其他对象。音频对象可以具有相关联的元数据,该元数据描述音频对象的定位、速率、轨迹、高度、大小和/或任何其他方面。如本文中所使用的,术语“音频床”或“床”是指为了在预定义的固定定位中再现的一个或多个音频声道。如本文中所使用的,术语“brir”是指关于每个音频声道或对象的双耳房间脉冲响应(brir),这些brir表征特定声学环境中的从空间中的特定点到收听者的耳朵的音频信号的变换。一般而言,brir可以被分成三个区域。第一区域被称为直接响应,其表示从无回声空间中的点到耳道的入口的脉冲响应。该直接响应通常约为5ms持续时间或更短,并且更普遍地被称为头部相关传递函数(hrtf)。第二区域被称为早期反射,其包含来自最靠近声源和收听者的对象(例如,地板、房间墙壁、家具)的声音反射。第三区域被称为后期响应,其包括来自各种方向的具有不同强度的更高阶反射的混合。该第三区域由于其复杂结构而经常由随机(stochastic)参数(诸如峰密度、模型密度、能量衰减时间等)来描述。人类听觉系统已经演进到对在全部三个区域中传达的感知线索做出响应。早期反射对源的感知方向具有适度的影响,但是对源的感知音色(timbre)和距离有较强的影响,而后期响应影响声源定位在其中的感知环境。其他显式的和隐式的限定可以在下面被包括。
如上文所述,在从房间或房间模型导出的虚拟器设计中,brir具有通过声学法则确定的性质,因而从其产生的双耳渲染器包含各种感知线索。这样的brir可以以期望的和不期望的方式两者修改要通过耳机渲染的信号。鉴于此,在本公开的实施例中,通过解除由物理房间或房间模型强加的约束中的一些,提供了一种用于耳机虚拟化的混响生成的新颖的解决方案。所提出的解决方案的一个目标是以受控的方式对合成的早期和后期响应仅给予期望的感知线索。期望的感知线索是以最小可听减损(impairment)(副作用)向收听者传达定位和宽敞度的令人信服的错觉的感知线索。例如,可以通过将房间反射包括在具有从相对于声源的方位角/仰角的有限范围的到达方向的后期响应的早期部分中来增强从收听者的头部到特定定位处的虚拟声源的距离的印象。这在最小化谱染色和时间拖尾的同时给予导致自然的空间感觉的特定iacc特性。本发明旨在通过在基本上保持原始混音师(soundmixer)的艺术意图的同时添加自然的空间感觉来提供比常规的立体声引人注目的收听者体验。
下文中,将参照图1至图9来描述本公开的一些示例实施例。但是,应意识到仅仅出于示例的目的而做出这些描述并且本公开不限于此。
首先参照图1,图1示出了根据本公开的一个示例实施例的用于耳机虚拟化的单声道系统100的框图。正如所示出的,系统100包括反射生成单元110和组合单元120。生成单元110可以由例如滤波单元110实现。
滤波单元110被配置为对brir与对应于声源定位的音频输入信号进行卷积,该brir包含给予期望的感知线索的定向控制的反射。输出是左耳中间信号和右耳中间信号的集合。组合单元120从滤波单元110接收左耳中间信号和右耳中间信号并且组合它们以形成双耳输出信号。
如上所述,本公开的实施例能够模拟brir响应、尤其是早期反射和后期响应以在保持自然性的同时减小谱染色和时间拖尾。在本公开的实施例中,这可以通过以受控的方式对brir响应、尤其是早期反射和后期响应给予定向线索来实现。换言之,方向控制可以被应用于这些反射。特别地,反射可以以这样的方式生成:它们具有期望的定向图案,在期望的定向图案中,到达方向具有随着时间的期望改变。
本文中所公开的示例实施例提供:可以使用预定定向图案来生成期望的brir响应以控制反射方向。特别地,预定定向图案可以被选择以给予感知线索,该感知线索增强空间中的给定定位处的虚拟声源的错觉。作为一个示例,预定定向图案可以是摆动函数。对于给定时间点的反射,摆动函数完全地或部分地确定到达方向(方位角和/或仰角)。反射方向上的改变创建具有随着时间和频率而变化的iacc的模拟brir响应。除了itd、ild、dr能量比以及混响时间之外,iacc也是影响收听者对声源外部化和宽敞度的印象的主要感知线索中的一个。但是,iacc跨时间和频率的哪些特定演进图案对于传达3维空间的感觉同时尽可能多地保持混音师的艺术意图最有效在本领域中并不是众所周知的。本文中所描述的示例实施例提供:特定的定向反射图案(诸如摆动形状的反射)可以在相对于常规方法保持音频保真度的同时传达自然的外部化感觉。
图2示出根据本公开的示例实施例的预定定向图案。在图2中,示出了合成反射的摆动轨迹,其中每个点表示具有相关联的方位角方向的反射分量,并且首先到达信号的声音方向由时间原点处的黑色方块指示。从图2清楚的是,反射方向改变而远离首先到达信号的方向并且围绕它振荡,同时反射密度则大体上随着时间增大。
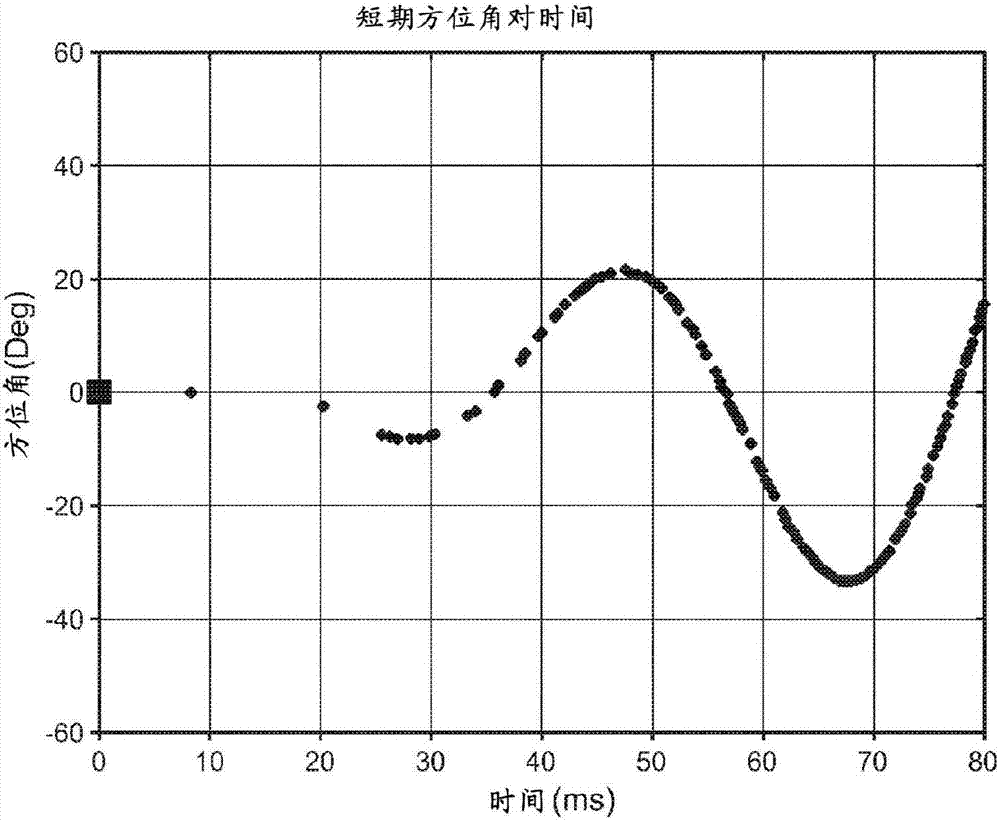
在具有良好外部化的房间中测量的brir中,强烈的且良好限定的定向摆动与良好的外部化相关联。这可以从图3a和图3b看出,图3a和图3b示出当来自具有良好和不良外部化的brir的4ms片段通过耳机收听被试听时的表观方向改变的示例。
从图3a和图3b,可以清楚地看出,良好外部化与强烈的定向摆动相关联。短期定向摆动不仅存在于方位角平面中,而且还存在于内侧面(medialplane)中。这是真的,因为常规的6表面房间中的反射是3维现象,而不仅仅是2维现象。因此,10-50ms的时间间隔中的反射也可以在仰角中产生短期定向摆动。因此,将这些摆动包括在brir对中可以用于增大外部化。
短期定向摆动对于声学环境中的全部可能的源方向的实际应用可以经由有限数量的定向摆动来实现以用于生成具有良好外部化的brir对。这可以例如通过将首先到达声音方向的全部垂直方向和水平方向的球体划分为有限数量的区域来进行。来自特别区域的声源与用于该区域的两个或更多个短期定向摆动相关联以生成具有良好外部化的brir对。也就是说,可以基于虚拟声源的方向来选择摆动。
基于房间测量的分析,可以看出,声音反射通常首先在方向上摆动,但是快速地变为各向同性,由此创建扩散声场。因此,有用的是,在创建具有自然声音的良好外部化brir对时包括扩散或随机分量。扩散性的添加是自然声音、外部化和集中(focused)源大小之间的权衡。太多的扩散性可能创建非常宽的且不良的定向限定的声源。另一方面,太少的扩散性可以导致来自声源的不自然的回声。结果,源方向上的适度增长的随意性是期望的,这意味着随意性应被控制到一定程度。在本公开的实施例中,方向范围被限制在预定方位角范围内以覆盖原始源方向周围的区域,这可以导致自然性、源宽度和源方向之间的良好权衡。
图4进一步示出根据本公开的另一示例实施例的预定定向图案。特别地,在图4中示出了对于中央声道添加的扩散分量以及示例方位角短期定向摆动的随时间变化的反射方向。反射到达方向最初来源于相对于声源的小范围的方位角和仰角,然后随着时间的推移扩展得更宽。如图4中所示,来自图2的缓慢变化的定向摆动与增大的随机(随意)方向分量组合以创建扩散性。如图4中所示的扩散分量在80ms处线性地增长到±45度,并且方位角的整个范围与六面矩形房间中的±180度相比仅为相对于声源±60度。预定定向图案还可以包括具有来自水平面以下的到达方向的反射的部分。这样的特征对于模拟地面反射是有用的,该地面反射对于人类听觉系统将前面的水平声源局部化在正确仰角处是重要的。
鉴于扩散分量的添加引入了进一步的扩散性的事实,如图4中所示的对于brir对得出的反射和相关联的方向可以实现更好的外部化。事实上,类似于摆动,扩散分量也可以基于虚拟声源的方向来选择。以这种方式,可以生成合成brir,该合成brir给予增强收听者对声源定位和外部化的感觉的感知效果。
如前面所述,这些短期定向摆动通常使每个耳朵中的声音具有频率依赖iacc的实部以便在反射在方向上变为各向同性和均匀之前的时间间隔(例如,10-50ms)中具有强烈的系统变化。随着brir以后在时间上演进,高于大约800hz的iacc实值由于声场的扩散性增大而下降。因而,从左耳响应和右耳响应导出的iacc的实部随着频率和时间而变化。频率依赖实部的使用具有以下优点:它揭示了相关性特性和反相关性特性,并且它是对虚拟化的有用度量。
事实上,在iacc的实部中存在创建强外部化的许多特性,但是时变相关性特性在时间间隔(例如,10至50ms)中的持续性可以指示良好的外部化。就本文中所公开的示例实施例而言,它可以产生具有较高值的iacc的实部,这意味着相关性的持续性(高于800hz并且延伸到90ms)比物理房间中将发生的相关性的持续性高。因而,就如本文中所公开的示例实施例而言,它可以获得更好的虚拟器。
在本公开的实施例中,可以使用随机回声发生器来生成滤波单元110的系数以获得具有上述转变特性的早期反射和后期响应。如图1中所示,滤波单元可以包括延迟器111-1,…,111-i,…,111-k(下文统称为111)以及滤波器112-0,112-1,…,112-i,…112-k(下文统称为112)。延迟器111可以由z-ni表示,其中i=1至k。用于滤波器112的系数可以例如从hrtf数据集合导出,其中每个滤波器对于左耳和右耳两者提供与来自预定方向的一个反射对应的感知线索。如图1中所示,在每个信号线中,存在延迟器和滤波器对,该延迟器和滤波器对可以在预定时间生成来自已知方向的一个中间信号(例如,反射)。组合单元120包括例如左求和器121-l和右求和器121-r。全部的左耳中间信号在左求和器121-l中被混合以产生左双耳信号。类似地,全部的右耳中间信号在右求和器121-r中被混合以产生右双耳信号。以这样的方式,可以从所生成的具有预定定向图案的反射与由滤波器112-0生成的直接响应一起来生成混响以产生左双耳输出信号和右双耳输出信号。
在本公开的实施例中,随机回声发生器的操作可以被实现如下。首先,在随机回声发生器沿着时间轴前进的每个时间点,首先做出独立的随机二元决定以决定反射是否应在给定时刻生成。肯定决定的概率随着时间而增大,优选地二次方地增大,以用于增大回声密度。也就是说,反射的发生时间点可以随机地确定,但是同时,在预定的回声密度分布约束内做出该确定以便实现期望的分布。该决定的输出是对如图1中所示的延迟器111的延迟时间做出响应的反射的发生时间点(也被称为回声位置)的序列,n1,n2,...,nk。然后,对于时间点,如果反射被确定为生成,则将根据期望方向来生成用于左耳和右耳的脉冲响应对。该方向可以基于表示随着时间而变化的到达方向的预定函数(诸如摆动函数)来确定。在没有任何进一步的控制的情况下,反射的振幅(amplitude)可以是随机值。该对脉冲响应将被认为是在该时刻的生成的brir。在2015年7月9日公布的pct申请wo2015103024中,该申请详细地描述了随机回声发生器,该申请通过引用被整体结合于此。
为了示例的目的,接下来将参照图5来描述用于在给定发生时间点生成反射的示例过程以使得本领域技术人员能够完全地理解并且进一步实现本公开中所提出的解决方案。
图5示出根据本公开的示例实施例的用于在给定发生时间点生成反射的方法(500)。如图5中所示,方法500在步骤510进入,在步骤510,基于预定定向图案(例如定向图案函数)和给定的发生时间点来确定反射的方向ddir。然后,在步骤520,确定反射的振幅damp,damp可以是随机值。接下来,在步骤530,获得具有期望方向的滤波器,诸如hrtf。例如,可以分别获得用于左耳和右耳的hrtfl和hrtfr。特别地,可以针对特别的方向从测量的hrtf数据集合检索hrtf。测量的hrtf数据集合可以通过针对特别的测量方向离线地测量hrtf响应而形成。以这样的方式,可以在生成反射期间从hrtf数据集合选择具有期望方向的hrtf。选择的hrtf对应于如图1中所示的相应信号线处的滤波器112。
在步骤540,可以确定用于左耳和右耳的hrtf的最大平均振幅。特别地,可以首先分别计算左耳和右耳的检索到的hrtf的平均振幅,并且然后进一步确定左耳和右耳的hrtf的平均振幅中的最大的一个振幅,该最大的一个振幅可以被表示为,但不限于:
ampmax=max(|hrtfl|,|hrtfr|)(公式1)
接下来,在步骤550,用于左耳和右耳的hrtf被修改。特别地,根据确定的振幅damp来对用于左耳和右耳两者的hrtf的最大平均振幅进行修改。在本公开的示例实施例中,它可以被修改为,但不限于:
结果,可以在给定时间点获得分别用于左耳和右耳的具有期望方向分量的两个反射,这两个反射从如图1中所示的相应滤波器输出。所得出的hrtflm作为用于左耳的反射被混合到左耳brir中,而hrtfrm作为用于右耳的反射被混合到右耳brir中。生成反射并且将反射混合到brir中以创建合成混响的过程继续直到达到期望的brir长度为止。最终的brir包括用于左耳和右耳的直接响应,后面跟着合成混响。
在上文所公开的本公开的实施例中,可以针对特别测量方向离线地测量hrtf响应以便形成hrtf数据集合。因而在生成反射期间,可以根据期望方向从测量的hrtf数据集合选择hrtf响应。因为hrtf数据集合中的hrtf响应表示用于单位脉冲信号的hrtf响应,所以选择的hrtf将由确定的振幅damp修改以获得适合用于确定的振幅的响应。因此,在本公开的这个实施例中,通过基于期望方向从hrtf数据集合选择适合的hrtf并且根据反射的振幅进一步修改hrtf来生成具有期望方向和确定的振幅的反射。
但是,在本公开的另一实施例中,可以基于球形头部模型来确定用于左耳和右耳的hrtf,hrtfl和hrtfr,而不是从测量的hrtf数据集合选择。也就是说,可以基于确定的振幅和预定的头部模型来确定hrtf。以这样的方式,可以显著地节省测量工作。
在本公开的进一步的实施例中,可以用具有类似的听觉线索(例如,耳间时差(itd)和耳间声强差(ild)听觉线索)的脉冲对来取代用于左耳和右耳的hrtf,hrtfl和hrtfr。也就是说,可以基于给定的发生时间点的期望方向和确定的振幅以及预定球形头部模型的宽带itd和ild来生成用于两个耳朵的脉冲响应。可以例如直接基于hrtfl和hrtfr来计算脉冲响应对之间的itd和ild。或者,可替代地,可以基于预定的球形头部模型来计算脉冲响应对之间的itd和ild。一般地,一对全通滤波器,特别是多级全通滤波器(apf),可以被应用于生成的合成混响的左声道和右声道作为回声发生器的最后操作。以这样的方式,可以将受控的扩散和解相关效果引入到反射,因而改进由虚拟器产生的双耳渲染器的自然性。
虽然描述了用于在给定时刻生成反射的特定方法,但是应意识到,本公开不限于此;相反,任何其他的适当的方法可以创建类似的转变行为。作为另一示例,也可以借助于例如图像模型来生成具有期望方向的反射。
通过沿着时间轴前进,反射发生器可以生成具有随着时间而变化的受控到达方向的用于brir的反射。
在本公开的另一实施例中,可以生成用于滤波单元110的多组系数以便产生多个候选brir,然后可以例如基于合适地限定的目标函数来做出基于感知的性能评估(诸如谱平坦性、与预定房间特性的匹配程度等)。来自具有最佳特性的brir的反射被选择以用于滤波单元110中。例如,具有表示各种brir性能属性之间的最佳权衡的早期反射和后期响应特性的反射可以被选择为最后的反射。而在本公开的另一实施例中,可以生成用于滤波单元110的多组系数直到期望的感知线索被给予为止。也就是说,预先设置期望的感知度量,并且如果满足该感知度量,则随机回声发生器将停止其操作并且输出所得出的反射。
因此,在本公开的实施例中,提供了一种用于耳机虚拟化的混响的新颖的解决方案,特别是用于设计耳机虚拟器中的双耳房间脉冲响应(brir)的早期反射和混响部分的新颖的解决方案。对于每个声源,将使用独特的、方向依赖的后期响应,并且通过组合多个合成房间反射与随着时间而变化的定向控制的到达方向来生成早期反射和后期响应。通过对反射应用方向控制而不是使用基于物理房间或球形头部模型测量的反射,可以模拟在最小化副作用的同时给予期望的感知线索的brir响应。在本公开的一些实施例中,预定定向图案被选择使得空间中的给定定位处的虚拟声源的错觉得到增强。特别地,预定定向图案可以例如是具有在预定方位角范围内的附加扩散分量的摆动形状。反射方向上的改变给予时变的iacc,该时变的iacc提供进一步的主要感知线索并且因而在保持音频保真度的同时传达自然的外部化感觉。以这种方式,该解决方案可以捕获物理房间的本质而没有其限制。
另外,本文中所提出的解决方案支持使用直接卷积或计算效率更高的方法的、基于声道的和基于对象的音频节目素材两者的双耳虚拟化。用于固定声源的brir可以通过组合相关联的直接响应与方向依赖的后期响应来简单地离线地设计。用于音频对象的brir可以在耳机渲染期间通过组合时变的直接响应与通过对来自空间中的邻近的时不变定位的多个后期响应进行插值而导出的早期反射和后期响应来即时地(on-the-fly)构造。
此外,为了以计算效率高的方式实现所提出的解决方案,所提出的解决方案也可以在反馈延迟网络(fdn)中实现,这将在下文中参照图6至图8来描述。
如所提及的,在常规的耳机虚拟器中,brir的混响普遍被划分为两个部分:早期反射和后期响应。brir的这样的分离允许专用模型模拟brir的每个部分的特性。已知早期反射是稀疏的且定向的,而后期响应是密集的且扩散的。在这样的情况下,早期反射可以使用一组延迟线而被应用于音频信号,每个后面跟着与和相关联的反射对应的hrtf对的卷积,而后期响应可以用一个或多个反馈延迟网络(fdn)来实现。fdn可以使用由具有反馈矩阵的反馈回路互连的多个延迟线来实现。该结构可以用于模拟后期响应的随机特性,特别是回声密度随着时间的推移的增大。与诸如图像模型的确定性方法相比,它的计算效率更高,因而它普遍被用于导出后期响应。为了示例的目的,图6示出现有技术中的一般的反馈延迟网络的框图。
如图6中所示,虚拟器600包括具有一般地用611指示的三个延迟线的fdn,这三个延迟线由反馈矩阵612互连。每个延迟线611可以输出输入信号的时间延迟版本。延迟线611的输出将被发送到混合矩阵621以形成输出信号,并且同时还被馈送到反馈矩阵612中,并且从反馈矩阵输出的反馈信号进而在求和器613-1至613-3处与输入信号的下一帧混合。要注意,只有早期响应和后期响应被发送到fdn并且通过三个延迟线,而直接响应被直接发送到混合矩阵而不被发送到fdn,因而它不是fdn的一部分。
但是,早期-后期响应的缺点中的一个在于从早期响应到后期响应的突然转变。即,brir在早期响应中将是定向的,但是突然改变为密集的且扩散的后期响应。这与真实的brir当然不同并且将影响双耳虚拟化的感知质量。因而,如果如本公开中所提出的构思可以在fdn中体现,则这是期望的,fdn是用于模拟耳机虚拟器中的后期响应的普遍结构。因此,下文中提供了另一解决方案,该解决方案是通过在反馈延迟网络(fdn)的前面添加一组并行hrtf滤波器来实现的。每个hrtf滤波器生成与一个房间反射对应的左耳和右耳响应。将参照图7来做出详细描述。
图7示出根据本公开的示例实施例的基于fdn的耳机虚拟器。与图6不同,在虚拟器700中,进一步布置了滤波器(诸如hrtf滤波器714-0,714-1,…714-i...714-k)和延迟线(诸如延迟线715-0,715-1,715-i,…715-k)。因而,输入信号将通过延迟线715-0,715-1,715-i,…715-k而被延迟以输出输入信号的不同的时间延迟版本,然后输入信号的这些时间延迟版本在进入混合矩阵720或fdn之前、特别是在通过至少一个反馈矩阵馈送回来的信号被添加之前被滤波器(诸如hrtf滤波器714-0,714-1,…714-i...714-k)预处理。在本公开的一些实施例中,用于延迟线715-0的延迟值d0(n)可以是零,以便节省存储器存储。在本公开的其他实施例中,延迟值d0(n)可以被设置为非零值,以便控制对象和收听者之间的时间延迟。
在图7中,可以基于如本文中所描述的方法来确定每个延迟线的延迟时间和对应的hrtf滤波器。而且,将需要较小数量的滤波器(例如,4个、5个、6个、7个或8个),并且后期响应的一部分是通过fdn结构生成的。以这样的方式,可以以计算效率更高的方式来生成反射。同时,可以确保:
●后期响应的早期部分包含定向线索。
●到fdn结构的全部输入是定向的,这允许fdn的输出是定向扩散的。因为fdn的输出现在是通过定向反射的求和而创建的,所以这更类似于真实世界的brir生成,这意味着从定向反射的平滑转变,因而漫反射被确保。
●后期响应的早期部分的方向可以被控制成具有预定的到达方向。与通过图像模型生成的早期反射不同,后期响应的早期部分的方向可以由不同的预定定向函数确定,这些定向函数表示后期响应的早期部分的特性。作为示例,前述摆动函数可以在这里被采用以引导hrtf对(hi(n),0≤i≤k)的选择过程。
因而,在如图7中所示的解决方案中,通过控制后期响应的早期部分的方向以使得它们具有预定到达方向来对音频输入信号给予定向线索。从而,代替一般的fdn中的反射的硬性的定向到扩散的转变,实现软性转变,该软性转变是从完全定向反射(将由前面讨论的模型处理的早期反射)到半定向反射(将具有定向和扩散之间的二重性的后期响应的早期部分),并且最后演进到完全扩散反射(后期响应的其余部分(reminder))。
应理解,为了实现效率,延迟线715-0,715-1,715-i,…,715-k也可以被构建在fdn中。可替代地,它们也可以是抽头延迟线(多个延迟单元的级联,在每个延迟单元的输出处具有hrtf滤波器),以便以较少的存储器存储来实现与图7中所示的功能相同的功能。
另外,图8进一步示出根据本公开的另一示例实施例的基于fdn的耳机虚拟器800。与如图7中所示的耳机虚拟器的不同之处在于,两个反馈矩阵812l和812r分别用于左耳和右耳,而不是一个反馈矩阵712。以这样的方式,计算效率可以更高。关于延迟线组811以及求和器813-1l至813-kl、813-1r至813-kr、814-0至814-k,这些部件在功能上类似于延迟线组711以及求和器713-1l至713-kl、713-1r至713-kr、714-0至714-k。即,分别如图7和图8中所示,这些部件以使得它们与输入信号的下一帧混合的方式(matter)运作,因此,为了简化的目的,将省略它们的详细描述。另外,延迟线815-0,815-1,815-i,…815-k也以与延迟线715-0,715-1,715-i,…715-k类似的方式运作,因而在此被省略。
图9进一步示出根据本公开的进一步的示例实施例的基于fdn的耳机虚拟器900。与如图7中所示的耳机虚拟器不同,在图9中,延迟线915-0,915-1,915-i,…915-k和hrtf滤波器914-0,914-1,…914-i...914-k不与fdn串联连接,而是与fdn并联连接。也就是说,输入信号将通过延迟线915-0,915-1,915-i,…915-k而被延迟,并且被hrtf滤波器914-0,914-1,…914-i...914-k预处理,然后被发送到混合矩阵,在混合矩阵中,预处理的信号将被与通过fdn的信号混合。因而,被hrtf滤波器预处理的输入信号不被发送到fdn网络,而是被直接发送到混合矩阵。
应注意,图7至图9中所示的结构与各类音频输入格式(包括但不限于基于声道的音频以及基于对象的音频)是完全兼容的。事实上,输入信号可以是以下中的任何一个:多声道音频信号的单个声道、多声道信号的混合、基于对象的音频信号的信号音频对象、基于对象的音频信号的混合、或它们的任何可能组合。
在多个音频声道或对象的情况下,每个声道或每个对象可以被布置有用于对输入信号进行处理的专用虚拟器。图10示出根据本公开的示例实施例的用于多个音频声道或对象的耳机虚拟化系统1000。如图10中所示,来自每个音频声道或对象的输入信号将被分离的虚拟器(诸如虚拟器700、800或900)处理。来自每个虚拟器的左输出信号可以被求和以便形成最后的左输出信号,并且来自每个虚拟器的右输出信号可以被求和以便形成最后的右输出信号。
尤其是当存在足够的计算资源时,可以使用耳机虚拟化系统1000;但是,对于具有有限计算资源的应用,它需要另一解决方案,因为系统1000所需要的计算资源对于这些应用将是不可接受的。在这样的情况下,可以在fdn之前或者与fdn并行地获得多个音频声道或对象与它们的对应的反射的混合。换言之,音频声道或对象与它们的对应的反射可以被处理并且被转换为单个音频声道或对象信号。
图11示出根据本公开的另一示例实施例的用于多个音频声道或对象的耳机虚拟化系统1100。与图7中所示的系统不同,在系统1100中,为m个音频声道或对象提供了m个反射延迟和滤波器网络1115-1至1115-m。每个反射延迟和滤波器网络1115-1,…或1115-m包括k+1个延迟线和k+1个hrtf滤波器,其中一个延迟线和一个hrtf滤波器用于直接响应,而其他延迟线和其他hrtf滤波器用于早期响应和后期响应。正如所示出的,对于音频声道或对象1,输入信号通过第一反射延迟和滤波器网络1115-1,也就是说,输入信号首先通过延迟线1115-1,0,1115-1,1,1115-1,i,…,1115-1,k而被延迟,然后被hrtf滤波器1114-1,0,1114-1,1,…1114-1,i...1114-1,k滤波;对于音频声道或对象m,输入信号通过第m反射延迟和滤波器网络1115-m,也就是说,输入信号首先通过延迟线1115-m,0,1115-m,1,1115-m,i,…,1115-m,k而被延迟,然后被hrtf滤波器1114-m,0,1114-m,1,…1114-m,i...1114-m,k滤波。来自反射延迟和滤波器网络1115-1中的hrtf滤波器1114-1,1,…,1114-1,i,…,1114-1,k和1114-1,0中的每个的左输出信号被与来自其他反射延迟和滤波器网络1115-2至1115-m中的对应hrtf滤波器的左输出信号组合,获得的用于早期响应和后期响应的左输出信号被发送到fdn中的求和器,并且用于直接响应的左输出信号被直接发送到混合矩阵。类似地,来自反射延迟和滤波器网络1115-1中的hrtf滤波器1114-1,1,…,1114-1,i,…,1114-1,k和1114-1,0中的每个的右输出信号被与来自其他反射延迟和滤波器网络1115-2至1115-m中的对应hrtf滤波器的右输出信号组合,并且获得的用于早期响应和后期响应的右输出信号被发送到fdn中的求和器,并且作为直接响应的右输出信号被直接发送到混合矩阵。
图12示出根据本公开的进一步的示例实施例的用于多声道或多对象的耳机虚拟化系统1200。与图11不同,系统1200是基于如图9中所示的系统900的结构而构建的。在系统1200中,也为m个音频声道或对象提供了m个反射延迟和滤波器网络1215-1至1215-m。反射延迟和滤波器网络1215-1至1215-m与图11中所示的那些是类似的,不同之处在于,来自反射延迟和滤波器网络1215-1至1215-m的k+1个求和的左输出信号和k+1个求和的右输出信号被直接发送到混合矩阵1221,并且它们中没有一个被发送到fdn;同时,来自m个音频声道或对象的输入信号被求和以获得下混音频信号,该下混音频信号被提供给fdn并且进一步被发送到混合矩阵1221。因而,在系统1200中,为每个音频声道或对象提供了分离的反射延迟和滤波器网络,并且延迟和滤波器网络的输出被求和,然后被与来自fdn的输出混合。在这样的情况下,每个早期反射将在最后的brir中出现一次并且对左/右输出信号没有进一步的影响,并且fdn将提供纯粹扩散的输出。
另外,在图12中,反射延迟和滤波器网络1215-1至1215-m与混合矩阵之间的求和器也可以被移除。也就是说,延迟和滤波器网络的输出可以在不求和的情况下被直接提供给混合矩阵1221并与来自fdn的输出混合。
在本公开的更进一步的实施例中,音频声道或对象可以被下混以形成具有主导(domain)源方向的混合信号,并且在这样的情况下,混合信号可以作为单个信号直接输入到系统700、800或900。接下来,将参照图13来描述实施例,其中图13示出根据本公开的更进一步的示例实施例的用于多个音频声道或对象的耳机虚拟化系统1300。
如图13中所示,音频声道或对象1至m首先被发送到下混和主导(dominant)源方向分析模块1316。在下混和主导源方向分析模块1316中,将通过例如求和来将音频声道或对象1至m进一步下混为音频混合信号,并且可以对音频声道或对象1至m进一步分析主导源方向以获得音频声道或对象1至m的主导源方向。以这样的方式,可以获得具有例如方位角和仰角上的源方向的单声道音频混合信号。所得出的单声道音频混合信号可以作为单个音频声道或对象输入到系统700、800或900中。
可以借助于任何合适的方式(诸如在现有的源方向分析方法中已经使用的那些)在时间域中或在时间-频率域中对主导源方向进行分析。在下文中,为了示例的目的,将在时间-频率域中描述示例分析方法。
作为示例,在时间-频率域中,第ai音频声道或对象的声源可以用声源矢量ai(n,k)表示,声源矢量ai(n,k)是其方位角μi、仰角ηi和增益变量gi的函数,并且可以由以下公式给出:
其中k和n分别是频率索引和时间帧索引;gi(n,k)表示用于该声道或对象的增益;
可以通过应用从具有最高振幅的声道选择的相位信息
下混信号的由其方位角θ(n,k)和仰角φ(n,k)呈现的方向于是可以由以下公式给出:
以这样的方式,可以确定音频混合信号的主导源方向。但是,可以理解,本公开不限于上述示例分析方法,并且任何其他合适的方法也是可能的,例如在时间频率中的那些。
应理解,混合矩阵中用于早期反射的混合系数可以是单位矩阵。混合矩阵是要控制左输出和右输出之间的相关性。应理解,全部这些实施例可以在时间域和频率域两者中实现。对于频率域中的实现,输入可以是用于每个带的参数,并且输出可以是用于该带的处理后的参数。
此外,注意,本文中所提出的解决方案还可以在不必进行任何结构修改的情况下促进现有的双耳虚拟器的性能改进。这可以通过基于由本文中所提出的解决方案生成的brir获得用于耳机虚拟器的最佳的参数集合来实现。该参数可以通过最佳过程(optimalprocess)来获得。例如,通过本文中(例如关于图1至图5)所提出的解决方案创建的brir可以设置目标brir,然后感兴趣的耳机虚拟器用于生成brir。目标brir和所生成的brir之间的差异被计算。然后,重复brir的生成和差异的计算,直到参数的全部可能组合被覆盖为止。最后,将选择用于感兴趣的耳机虚拟器的最佳的参数集合,该最佳参数集合可以最小化目标brir和所生成的brir之间的差异。两个brir之间的相似性或差异的测量可以通过从brir提取感知线索来实现。例如,左声道和右声道之间的振幅比可以被采用作为摆动效果的测量。以这样的方式,通过最佳的参数集合,即使是现有的双耳虚拟器也可以在没有任何结构修改的情况下实现更好的虚拟化性能。
图14进一步示出根据本公开的示例实施例的生成brir的一个或多个分量的方法。
如图14中所示,方法1400在步骤1410进入,在步骤1410,生成定向控制的反射,并且其中定向控制的反射可以对与声源定位对应的音频输入信号给予期望的感知线索。然后在步骤1420,至少所生成的反射被组合以获得brir的一个或多个分量。在本公开的实施例中,为了避免特别的物理房间或房间模型的限制,可以将方向控制应用于反射。预定到达方向可以被选择以便增强空间中的给定定位处的虚拟声源的错觉。特别地,预定到达方向可以是摆动形状,在该形状中,反射方向缓慢地远离虚拟声源演进并且来回振荡。反射方向上的改变对随着时间和频率而变化的模拟响应给予时变的iacc,这在保持音频保真度的同时提供自然的空间感觉。尤其是,预定到达方向可以进一步包括预定方位角范围内的随机扩散分量。结果,它进一步引入了扩散性,这提供了更好的外部化。而且,摆动形状和/或随机扩散分量可以基于虚拟声源的方向被选择,使得外部化可以被进一步改进。
在本公开的实施例中,在生成反射期间,在预定的回声密度分布约束内教条地(scholastically)确定反射的相应的发生时间点。然后,基于相应的发生时间点和预定的定向图案来确定反射的期望方向,并且教条地确定相应的发生时间点的反射的振幅。然后,基于确定的值,在相应的发生时间点生成具有期望方向和确定的振幅的反射。应理解,本公开不限于如上所述的操作次序。例如,确定反射的期望方向和确定反射的振幅的操作可以按照相反的顺序执行或同时执行。
在本公开的另一实施例中,可以通过以下操作来创建相应的发生时间点的反射:基于相应的发生时间点的期望方向从针对特别的方向测量的头部相关传递函数(hrtf)数据集合选择hrtf,并且然后基于相应的发生时间点的反射的振幅来对这些hrtf进行修改。
在本公开的替代实施例中,创建反射也可以通过以下操作来实现:基于相应的发生时间点的期望方向和预定的球形头部模型来确定hrtf,随后基于相应的发生时间点的反射的振幅来对这些hrtf进行修改以便获得在相应的发生时间点的反射。
在本公开的另一替代实施例中,创建反射可以包括基于相应的发生时间点的期望方向和确定的振幅以及预定的球形头部模型的宽带耳间时差和耳间声强差来生成用于两个耳朵的脉冲响应。另外,可以通过全通滤波器来对创建的用于两个耳朵的脉冲响应进行进一步的滤波以获得进一步的扩散和解相关。
在本公开的进一步的实施例中,该方法是在反馈延迟网络中操作的。在这样的情况下,通过hrtf对输入信号进行滤波,以便至少控制后期响应的早期部分的方向以满足预定定向图案。以这样的方式,可以以计算效率更高的方式来实现解决方案。
另外,执行最佳过程。例如,可以重复生成反射以获得多小组(group)反射,然后可以选择该多小组反射中的具有最佳反射特性的一小组反射作为用于输入信号的反射。或者可替代地,可以重复生成反射直到获得预定反射特性为止。以这样的方式,可以进一步确保获得具有期望反射特性的反射。
可以理解,为了简化的目的,简要地描述了如图14中所示的方法;关于相应操作的详细描述,可以在参照图1至图13的对应描述中找到。
可以意识到,尽管本文中描述了本公开的特定实施例,但是这些实施例仅仅是为了示例的目的而给出的,并且本公开不限于此。例如,预定定向图案可以是除了摆动形状之外的任何适当的图案,或者可以是多个定向图案的组合。滤波器也可以是代替hrtf的任何其他类型的滤波器。在生成反射期间,可以以除了公式2a和公式2b中所示的方式之外的任何方式根据确定的振幅来对获得的hrtf进行修改。如图1中所示的求和器121-l和121-r可以在单个一般的求和器而不是两个求和器中实现。而且,延迟器和滤波器对的布置可以改变为反过来,这意味着它可能需要分别用于左耳和右耳的延迟器。此外,如图7和图8中所示的混合矩阵也可以由分别用于左耳和右耳的两个分离的混合矩阵实现。
另外,还将理解,系统100、700、800、900、1000、1100、1200和1300中的任何一个的部件可以是硬件模块或软件模块。例如,在一些示例实施例中,该系统可以部分地或完整地实现为软件和/或固件,例如,实现为在计算机可读介质中体现的计算机程序产品。可替代地或附加地,该系统可以部分地或完整地基于硬件来实现,例如,实现为集成电路(ic)、专用集成电路(asic)、片上系统(soc)、现场可编程门阵列(fpga)等。
图15示出了适合用于实现本公开的示例实施例的示例计算机系统1500的框图。如所示出的,计算机系统1500包括中央处理单元(cpu)1501,其能够根据存储在只读存储器(rom)1502中的程序或从存储单元1508加载到随机存取存储器(ram)1503的程序来执行各种过程。在ram1503中,当cpu1501执行各种过程等时所需要的数据也根据需要存储。cpu1501、rom1502和ram1503经由总线1504彼此连接。输入/输出(i/o)接口1505也连接到总线1504。
以下部件连接到i/o接口1505:输入单元1506,其包括键盘、鼠标等;输出单元1507,其包括显示器(诸如阴极射线管(crt)、液晶显示器(lcd)等)以及扩音器等;存储单元1508,其包括硬盘等;以及通信单元1509,其包括网络接口卡(诸如lan卡、调制解调器等)。通信单元1509经由网络(诸如互联网)来执行通信过程。驱动器1510也根据需要连接到i/o接口1505。可移除介质1511(诸如磁盘、光盘、磁光盘、半导体存储器等)根据需要被安装在驱动器1510上,使得从其读取的计算机程序根据需要被安装到存储单元1508中。
特别地,根据本公开的示例实施例,上述过程可以被实现为计算机软件程序。例如,本公开的实施例包括计算机程序产品,其包括有形地体现在机器可读介质上的计算机程序,该计算机程序包括用于执行方法的程序代码。在这样的实施例中,该计算机程序可以经由通信单元1509从网络下载和安装,和/或从可移除介质1511安装。
一般地,本公开的各种示例实施例可以用硬件或专用电路、软件、逻辑或它们的任何组合来实现。一些方面可以用硬件来实现,而其他方面可以用可以被控制器、微处理器或其他计算设备执行的固件或软件来实现。虽然本公开的示例实施例的各种方面被作为框图、流程图或使用一些其他的图形表示示出和描述,但是将意识到,本文中所描述的方框、装置、系统、技术或方法可以用作为非限制性示例的硬件、软件、固件、专用电路或逻辑、通用硬件或控制器或其他计算设备或它们的一些组合来实现。
另外,流程图中所示的各种方框可以被视为方法步骤,和/或被视为由计算机程序代码的操作导致的操作,和/或被视为被构造为实施相关联的(一个或多个)功能的多个耦合的逻辑电路元件。例如,本公开的实施例包括计算机程序产品,其包括有形地体现在机器可读介质上的计算机程序,该计算机程序包含被配置为实施如上所述的方法的程序代码。
在本公开的上下文下,机器可读介质可以是可以包含或存储供指令执行系统、装置或设备使用的或与指令执行系统、设备或装置有关的程序的任何有形介质。机器可读介质可以是机器可读信号介质或机器可读存储介质。机器可读介质可以包括但不限于电子、磁、光学、电磁、红外线或半导体系统、装置或设备、或前述的任何合适组合。机器可读存储介质的更具体的示例将包括具有一个或多个导线的电连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光学存储设备、磁存储设备、或前述的任何合适的组合。
用于实施本公开的方法的计算机程序代码可以用一种或多种编程语言的组合编写。这些计算机程序代码可以被提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,使得这些程序代码当被计算机或其他可编程数据处理装置的处理器执行时使流程图和/或框图中指定的功能/操作被执行。程序代码可以完全在计算机上执行、部分在计算机上执行、作为独立的软件包执行、部分在计算机上部分在远程计算机上执行,或者完全在远程计算机或服务器上执行,或者分布在一个或多个远程计算机和/或服务器上而执行。
此外,虽然操作是按照特别的次序描绘的,但是这不应被理解为需要这样的操作按所示的特别的次序或顺序的次序而被执行或者全部示出的操作都被执行以实现期望的结果。在某些情形下,多任务处理和并行处理可以是有利的。同样地,虽然数个特定实现细节被包含在以上讨论中,但是这些不应被解释为是对任何发明或要求保护的内容的范围的限制,而是应被理解为可以特定于特别的发明的特别的实施例的特征的描述。在本说明书中在分离的实施例的背景下描述的某些特征也可以组合地实现在单个实施例中。相反,在单个实施例的背景下描述的各种特征也可以分离地在多个实施例中实现,或者以任何合适的子组合实现。
当结合附图阅读本发明的前述示例实施例时,鉴于前面的描述,对本发明的前述示例实施例的各种修改和改动对于相关领域的技术人员可以变得清楚。任何和全部的修改仍将落在本发明的非限制性的示例实施例的范围内。此外,与本发明的这些实施例有关的领域的、受益于前面的描述和附图中呈现的教导的技术人员将想到本文中所阐释的发明的其他实施例。
本公开可以以本文中所描述的形式中的任何一种形式体现。例如,以下枚举的示例实施例(eee)描述了本公开的一些方面的一些结构、特征和功能。
eee1.一种用于生成用于耳机虚拟化的双耳房间脉冲响应(brir)的一个或多个分量的方法,包括:生成定向控制的反射,该定向控制的反射对与声源定位对应的音频输入信号给予期望的感知线索;并且组合至少所生成的反射来获得brir的一个或多个分量。
eee2.根据eee1所述的方法,其中,期望的感知线索以最小的副作用导致自然的空间感觉。
eee3.根据eee1所述的方法,其中,定向控制的反射具有预定到达方向,在该预定到达方向上,空间中的给定定位处的虚拟声源的错觉得到增强。
eee4.根据eee3所述的方法,其中,预定定向图案具有摆动形状,在该摆动形状中,反射方向改变远离虚拟声源,并且围绕虚拟声源来回振荡。
eee5.根据eee3所述的方法,其中,预定定向图案进一步包括预定方位角范围内的随机扩散分量,并且其中摆动形状或随机扩散分量中的至少一个是基于虚拟声源的方向选择的。
eee6.根据eee1所述的方法,其中,生成定向控制的反射包括:在预定的回声密度分布约束下教条地确定反射的相应的发生时间点;基于相应的发生时间点和预定的定向图案来确定反射的期望方向;教条地确定相应的发生时间点的反射的振幅;并且在相应的发生时间点创建具有期望方向和确定的振幅的反射。
eee7.根据eee6所述的方法,其中,创建反射包括:
基于相应的发生时间点的期望方向从针对特别的方向测量的头部相关传递函数(hrtf)数据集合选择hrtf;并且基于相应的发生时间点的反射的振幅来对hrtf进行修改以在相应的发生时间点获得所述反射。
eee8.根据eee6所述的方法,其中,创建反射包括:
基于相应的发生时间点的期望方向和预定的球形头部模型来确定hrtf;并且基于相应的发生时间点的反射的振幅来对hrtf进行修改以便在相应的发生时间点获得反射。
eee9.根据eee5所述的方法,其中,创建反射包括:基于相应的发生时间点的期望方向和确定的振幅并且基于预定的球形头部模型的宽带耳间时差和耳间声强差来生成用于两个耳朵的脉冲响应。
eee10.根据eee9所述的方法,其中,创建反射进一步包括:
通过全通滤波器来对创建的用于两个耳朵的脉冲响应进行滤波以获得扩散和解相关。
eee11.根据eee1所述的方法,其中,该方法是在反馈延迟网络中操作的,并且其中生成反射包括通过hrtf对音频输入信号进行滤波,以便控制至少后期响应的早期部分的方向以对输入信号给予期望的感知线索。
eee12.根据eee11所述的方法,其中,在用hrtf对音频输入信号进行滤波之前,通过延迟线使音频输入信号延迟。
eee13.根据eee11所述的方法,其中,在添加通过至少一个反馈矩阵馈送回来的信号之前,对所述音频输入信号进行滤波。
eee14.根据eee11所述的方法,其中,与音频输入信号被输入到反馈延迟网络中并行地用hrtf对音频输入信号进行滤波,并且其中,混合来自反馈延迟网络和来自hrtf的输出信号以获得用于耳机虚拟化的混响。
eee15.根据eee11所述的方法,其中,对于多个音频声道或对象,用hrtf对用于所述多个音频声道或对象中的每个的输入音频信号进行分离地滤波。
eee16.根据eee11所述的方法,其中,对于多个音频声道或对象,对用于多个音频声道或对象的输入音频信号进行下混和分析以获得具有主导源方向的音频混合信号,该音频混合信号被看作是输入信号。
eee17.根据eee1所述的方法,进一步包括通过以下操作来执行最佳过程:
重复生成反射以获得多小组反射,并且选择多小组反射中的具有最佳反射特性的一小组反射作为用于输入信号的反射;或者重复生成反射直到获得预定反射特性为止。
eee18.根据eee17所述的方法,其中,生成反射部分地由基于随机模式而生成的随意变量中的至少一些来驱动。
将意识到,本发明的实施例不限于如以上所讨论的特定实施例,并且修改和其他实施例意图被包括在所附权利要求的范围内。虽然本文中使用了特定术语,但是它们是以通用的描述性的意义使用的,而不是为了限制的目的。
- 还没有人留言评论。精彩留言会获得点赞!