视频译码中的系数等级译码的制作方法
本申请要求2015年9月1日申请的第62/212,996号美国临时专利申请案的权益,所述临时专利申请案的全部内容以引用的方式并入本文中。
本发明涉及视频编码和解码。
背景技术:
数字视频能力可以并入到多种多样的装置中,包含数字电视、数字直播系统、无线广播系统、个人数字助理(pda)、膝上型或桌上型计算机、平板计算机、电子图书阅读器、数码相机、数字记录装置、数字媒体播放器、视频游戏装置、视频游戏控制台、蜂窝式或卫星无线电电话、所谓的“智能电话”、视频电话会议装置、视频流式传输装置及其类似者。数字视频装置实施视频压缩技术,例如由mpeg-2、mpeg-4、itu-th.263、itu-th.264/mpeg-4第10部分、高级视频译码(avc)定义的标准、高效率视频译码(hevc)标准及此些标准的扩展中所描述的技术。视频装置通过实施此类视频压缩技术可以更有效地发射、接收、编码、解码和/或存储数字视频信息。
视频压缩技术执行空间(图片内)预测和/或时间(图片间)预测来减少或移除视频序列中固有的冗余。对于基于块的视频译码,可将视频切片(即,视频帧或视频帧的一部分)分割成若干视频块。使用关于同一图片中的相邻块中的参考样本的空间预测对图片的经帧内译码(i)切片中的视频块进行编码。图片的经帧间译码(p或b)切片中的视频块可使用相对于同一图片中的相邻块中的参考样本的空间预测或相对于其它参考图片中的参考样本的时间预测。图片可被称为帧。
空间或时间预测产生待译码块的预测性块。残余数据表示待译码原始块与预测块之间的像素差。经帧间译码块是根据指向形成预测性块的参考样本块的运动向量及指示经译码块与预测性块之间的差的残余数据编码的。经帧内译码块是根据帧内译码模式及残余数据来编码的。为了实现进一步压缩,可以将残余数据从像素域变换到变换域,从而产生残余系数,接着可以对残余系数进行量化。
技术实现要素:
本发明描述与基于块的混合视频译码中的熵编码和解码相关的技术。举例来说,本发明描述将用于熵编码和解码过程中的系数等级的语法元素二进制化的技术。作为将用于系数等级的语法元素二进制化的部分,视频译码器(即,视频编码器或视频解码器)可确定用于所述语法元素的莱斯参数k。k阶莱斯码可表示所述语法元素。在一些实例中,本发明的所提出技术也可以应用于其中利用阶k的其它二进制化方法。如本文中所描述,在一些实例中,视频译码器可使用基于模板的莱斯参数导出方法和基于统计的莱斯参数导出方法用于同一变换单元的系数等级。
在一个实例中,本发明描述一种对视频数据进行解码的方法,所述方法包括:使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对所述视频数据的当前图片的当前译码单元(cu)的单个变换单元(tu)的系数等级进行解码,其中:所述第一莱斯参数导出方法是基于统计的导出方法,且所述第二莱斯参数导出方法是基于模板的导出方法;以及通过将所述当前cu的一或多个预测单元的样本添加到所述tu的变换块的对应样本而重构所述当前cu的译码块。
在另一实例中,本发明描述一种对视频数据进行编码的方法,所述方法包括:产生所述视频数据的当前图片的译码单元(cu)的残余块,所述残余块中的每一样本指示所述cu的预测单元(pu)的预测性块中的样本与所述cu的译码块中的对应样本之间的差;将所述cu的所述残余块分解为一或多个变换块,其中所述cu的变换单元(tu)包括所述一或多个变换块中的变换块;以及使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对所述tu的系数等级进行编码,其中:所述第一莱斯参数导出方法是基于统计的导出方法,且所述第二莱斯参数导出方法是基于模板的导出方法。
在另一实例中,本发明描述一种用于对视频数据进行译码的装置,所述装置包括:计算机可读存储媒体,其经配置以存储所述视频数据;以及一或多个处理器,其经配置以:使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对所述视频数据的当前图片的当前译码单元(cu)的单个变换单元(tu)的系数等级进行译码,其中:所述第一莱斯参数导出方法是基于统计的导出方法,且所述第二莱斯参数导出方法是基于模板的导出方法。
在另一实例中,本发明描述一种用于对视频数据进行译码的装置,所述装置包括:用于存储所述视频数据的装置;以及用于使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对所述视频数据的图片的当前译码单元(cu)的单个变换单元(tu)的系数等级进行译码,其中:所述第一莱斯参数导出方法是基于统计的导出方法,且所述第二莱斯参数导出方法是基于模板的导出方法。
在附图和以下描述中阐明本发明的一或多个实例的细节。其它特征、目标和优点将从所述描述、图式以及权利要求书而显而易见。
附图说明
图1是说明可使用本发明中描述的技术的实例视频译码系统的框图。
图2是说明例如高效视频译码(hevc)中使用的基于残余四叉树的变换方案的概念图。
图3是说明例如在hevc中使用的基于译码群组的系数扫描的概念图。
图4是说明实例局部模板的概念图。
图5是说明可实施本发明中描述的技术的实例视频编码器的框图。
图6是说明可实施本发明中所描述的技术的实例视频解码器的框图。
图7是说明根据本发明的技术用于对视频数据进行编码的实例操作的流程图。
图8是说明根据本发明的技术用于对视频数据进行解码的实例操作的流程图。
图9是说明根据本发明的技术用于对视频数据进行解码的实例操作的流程图。
图10是说明根据本发明的技术用于对视频数据进行译码的实例操作的流程图。
图11是说明根据本发明的技术其中视频译码器使用基于统计的导出方法的实例操作的流程图。
图12是说明根据本发明的技术其中视频译码器使用基于模板的导出方法的实例操作的流程图。
图13是说明根据本发明的技术基于通用函数而确定莱斯参数的实例操作的流程图。
图14是说明根据本发明的技术用于将一系列语法元素二进制化或去二进制化的实例操作的流程图。
具体实施方式
本发明描述可涉及在基于块的混合视频译码中的熵译码模块的技术,尤其用于系数等级译码。所述技术可应用于现有视频编解码器,例如高效视频译码(hevc)编解码器,或者可为未来视频译码标准中的高效译码工具。
在各种视频编码技术中,特定语法元素经熵编码以减少表示所述语法元素所需的位数目。作为对语法元素进行熵编码的部分,视频编码器可将所述语法元素二进制化。将语法元素二进制化指代确定表示所述语法元素的可变长度二进制码的过程。因此,经二进制化的语法元素是所确定的表示语法元素的可变长度二进制码。经二进制化的语法元素可被称为码字。视频编码器可使用算术译码技术对经二进制化的语法元素进行编码。举例来说,视频编码器可使用上下文自适应二进制算术译码(cabac)对经二进制化的语法元素进行编码。相反,视频解码器可使用算术译码技术对经二进制化的语法元素进行解码。视频解码器可随后将经二进制化的语法元素去二进制化以恢复语法元素的原始值。视频解码器可随后使用恢复的语法元素作为重构视频数据的一或多个图片的过程的部分。
视频编码器可以各种方式将语法元素二进制化。举例来说,视频编码器可使用莱斯译码(ricecoding)或指数(exp)-哥伦布译码将语法元素二进制化。莱斯译码取决于莱斯参数。较大的莱斯参数更适合于将具有较大值的语法元素二进制化,而较小的莱斯参数更适合于将具有较小值的语法元素二进制化。
在hevc和特定其它基于块的视频译码系统中,使用译码单元(cu)的集合对图片进行编码。图片的每一cu可对应于所述图片内的一或多个位于同一地点的译码块。为了对cu进行编码,视频编码器可确定用于cu的一或多个预测单元(pu)的预测性块,且可基于cu的pu的预测性块中的样本以及cu的译码块中的对应样本而确定cu的残余数据。举例来说,cu的残余数据的每一样本可等于cu的pu的预测性块中的样本与cu的译码块的对应样本之间的差。cu的残余数据可分割成一或多个变换块,所述变换块中的每一者对应于cu的变换单元(tu)。视频编码器可随后将例如离散余弦变换等变换应用于tu的变换块以确定系数块。系数块中的系数的值可被称为“系数等级”。举例来说,在hevc中,变换系数是将在频域中考虑的标量,且与解码过程的逆变换部分中的特定一维或二维频率指数相关联;变换系数等级可为表示在用于变换系数值的计算的按比例缩放之前与解码过程中的特定二维频率指数相关联的值的整数量。在一些实例中,视频编码器可量化系数块中的系数等级。
此外,视频编码器可将每一系数块细分为一或多个系数群组(cg)。在hevc中,每一cg是系数块的4x4子块。对于系数块的每一相应cg,视频编码器可产生指示所述相应cg是否包含一或多个非零系数等级的语法元素。对于包含一或多个非零系数等级的每一相应cg,视频编码器可使用用于相应系数等级的一或多个语法元素的相应集合来表示相应cg的每一相应系数等级。用于系数等级的语法元素集合可包含:指示系数等级是否为非零的语法元素(即,有效性旗标语法元素)、指示系数等级是否大于1的语法元素(即,greater1旗标)、指示系数等级是否大于2的语法元素(即,greater2旗标)、指示系数等级的正或负号的语法元素(即,正负号旗标),以及指示系数等级的余数值的语法元素(即,余数语法元素)。如果有效性旗标指示系数等级是0,那么greater1旗标、greater2旗标、正负号旗标和余数语法元素可不存在。如果有效性旗标指示系数等级为非零且greater1旗标指示系数等级不大于1,那么greater2旗标不存在且余数语法元素指示系数等级。如果有效性旗标指示系数等级为非零且greater1旗标指示系数等级大于1,那么greater2旗标存在。如果greater2旗标存在但指示系数等级不大于2,那么余数语法元素指示系数等级减去1。如果greater2旗标存在且指示系数等级大于2,那么余数语法元素指示系数等级减去2。
在hevc中,视频编码器可使用莱斯码将具有小值的余数语法元素二进制化,且可使用指数-哥伦布码将具有较大值的余数语法元素二进制化。如上文提到,确定用于值的莱斯码的过程取决于莱斯参数。在hevc中,视频编码器使用所谓的“基于回顾的导出方法”来设定用于将余数语法元素二进制化的莱斯参数。在hevc范围扩展中,视频编码器使用所谓的“基于统计的导出方法”来设定用于将余数语法元素二进制化的莱斯参数。称为“基于模板的导出方法”的另一技术基于由局部模板覆盖的相邻系数等级的绝对值而确定用于将余数语法元素二进制化的莱斯参数。模板可包含与变换块中的当前系数的位置相比的若干相对位置。在一些实例中,模板是按剖析或解码次序在当前系数等级之前发生的邻接样本集合。
如下文进一步详细描述,在hevc、hevc范围扩展和各种其它先前建议中用于导出莱斯参数的技术可以改进。本发明中描述的技术可表示对这些技术的改进。举例来说,根据本发明的实例,视频译码器(例如,视频编码器或视频解码器)可使用第一莱斯参数导出方法和第二莱斯参数导出方法用于对图片的当前cu的单个tu的系数等级进行解码。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。因此,在此实例中,视频译码器可使用基于统计的导出方法用于tu中的一些余数语法元素,且可使用基于模板的导出方法用于同一tu中的其它余数语法元素。此技术可允许视频译码器选择可带来较好压缩的莱斯参数。
图1是说明可利用本发明的技术的实例视频译码系统10的框图。如本文所使用,术语“视频译码器”一般是指视频编码器及视频解码器两者。在本发明中,术语“视频译码”或“译码”可一般地指代视频编码或视频解码。
如图1中所示出,视频译码系统10包含源装置12和目的地装置14。源装置12产生经编码视频数据。因此,源装置12可被称为视频编码装置或视频编码设备。目的地装置14可以对由源装置12所产生的经编码视频数据进行解码。因此,目的地装置14可以被称作视频解码装置或视频解码设备。源装置12和目的地装置14可为视频译码装置或视频译码设备的实例。
源装置12和目的地装置14可包括广泛范围的装置,包含桌上型计算机、移动计算装置、笔记型(例如,膝上型)计算机、平板计算机、机顶盒、例如所谓的“智能”电话的电话手持机、电视、摄像机、显示装置、数字媒体播放器、视频游戏控制台、车载计算机(in-carcomputer)或其类似者。
目的地装置14可经由信道16从源装置12接收经编码的视频数据。信道16可包括能够将经编码的视频数据从源装置12移动到目的地装置14的一或多个媒体或装置。在一个实例中,信道16可包括使得源装置12能够实时地将经编码的视频数据直接发射到目的地装置14的一或多个通信媒体。在此实例中,源装置12可根据例如无线通信协议的通信标准调制经编码视频数据,并且可将经调制的视频数据发射到目的地装置14。一或多个通信媒体可包含无线通信媒体和/或有线通信媒体,例如,射频(rf)频谱或一或多个物理发射线。所述一或多个通信媒体可形成基于包的网络的部分,例如局域网、广域网或全球网络(例如,因特网)。所述一或多个通信媒体可包含路由器、交换器、基站或促进从源装置12到目的地装置14的通信的其它设备。
在另一实例中,信道16可包含存储由源装置12产生的经编码视频数据的存储媒体。在此实例中,目的地装置14可例如经由磁盘存取或卡存取来存取存储媒体。存储媒体可包含多种本地存取的数据存储媒体,例如蓝光光盘、dvd、cd-rom、快闪存储器或用于存储经编码视频数据的其它适合的数字存储媒体。
在另一实例中,信道16可以包含存储由源装置12产生的经编码的视频数据的文件服务器或另一中间存储装置。在此实例中,目的地装置14可以经由流式传输或下载来存取存储于文件服务器或其它中间存储装置处的经编码的视频数据。文件服务器可为能够存储经编码的视频数据并且将经编码的视频数据发射到目的地装置14的服务器类型。实例文件服务器包含网络服务器(例如,用于网站)、文件传输协议(ftp)服务器、网络附接存储(nas)装置及本地磁盘驱动器。
目的地装置14可通过标准数据连接(例如因特网连接)来存取经编码视频数据。实例类型的数据连接可包含无线信道(例如wi-fi连接)、有线连接(例如dsl、电缆调制解调器等),或适合于存取存储在文件服务器上的经编码视频数据的两者的组合。经编码视频数据从文件服务器的发射可为流式发射、下载发射或两者的组合。
本发明的技术不限于无线应用或设置。所述技术可应用于视频译码以支持多种多媒体应用,例如空中电视广播、有线电视发射、卫星电视发射、流式传输视频发射(例如,经由因特网)、编码视频数据以存储于数据存储媒体上、解码存储于数据存储媒体上的视频数据,或其它应用。在一些实例中,视频译码系统10可经配置以支持单向或双向视频传输以支持例如视频流式传输、视频回放、视频广播和/或视频电话等应用。
图1中说明的视频译码系统10仅是实例,且本发明的技术可应用于不一定包含编码与解码装置之间的任何数据通信的视频译码设定(例如,视频编码或视频解码)。在其它实例中,数据是从本地存储器检索、在网络上流式传输等。视频编码装置可以对数据进行编码并且将数据存储到存储器,和/或视频解码装置可以从存储器检索数据并且对数据进行解码。在许多实例中,通过并不彼此通信而是简单地将数据编码到存储器及/或从存储器检索数据且解码数据的装置执行编码及解码。
在图1的实例中,源装置12包含视频源18、视频编码器20及输出接口22。在一些实例中,输出接口22可包含调制器/解调器(调制解调器)和/或发射器。视频源18可以包含视频捕获装置(例如,摄像机)、含有先前捕获的视频数据的视频存档、用以从视频内容提供者接收视频数据的视频馈入接口、和/或用于产生视频数据的计算机图形系统,或视频数据的此些源的组合。
视频编码器20可对来自视频源18的视频数据进行编码。在一些实例中,源装置12经由输出接口22将经编码的视频数据直接发射到目的地装置14。在其它实例中,经编码的视频数据也可存储到存储媒体或文件服务器上以供稍后由目的地装置14存取以用于解码和/或回放。
在图1的实例中,目的地装置14包含输入接口28、视频解码器30和显示装置32。在一些实例中,输入接口28包含接收器和/或调制解调器。输入接口28可以在信道16上接收经编码的视频数据。显示装置32可以与目的地装置14集成在一起或可以在目的地装置14的外部。一般来说,显示装置32显示经解码的视频数据。显示装置32可包括多种显示装置,例如液晶显示器(lcd)、等离子显示器、有机发光二极管(oled)显示器或另一类型的显示装置。
视频编码器20和视频解码器30各自可实施为多种合适的电路中的任一者,例如一或多个微处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)、离散逻辑、硬件或其任何组合。如果部分地以软件实施技术,则装置可将软件的指令存储于合适的非暂时性计算机可读存储媒体中且可使用一或多个处理器以硬件执行指令从而执行本发明的技术。前述内容(包含硬件、软件、硬件与软件的组合等)中的任一者可被视为一或多个处理器。视频编码器20和视频解码器30中的每一者可以包含在一或多个编码器或解码器中,所述编码器或解码器中的任一者可以集成为相应装置中的组合编码器/解码器(编解码器)的部分。
本发明可大体上涉及将某些信息“用信号表示”或“发射”到另一装置(例如,到视频解码器30)。术语“用信号表示”或“发射”可大体上指代用以对经压缩视频数据进行解码的语法元素和/或其它数据的通信。此通信可实时或几乎实时发生。替代地,此类通信可经过一段时间后发生,例如可在编码时以经编码位流将语法元素存储到计算机可读存储媒体时发生,解码装置接着可在所述语法元素存储到此媒体之后的任何时间检索所述语法元素。
在一些实例中,视频编码器20和视频解码器30根据视频压缩标准操作,即视频译码标准。实例视频译码标准包含itu-th.261、iso/iecmpeg-1visual、itu-th.262或iso/iecmpeg-2visual、itu-th.263、iso/iecmpeg-4visual及itu-th.264(也被称为iso/iecmpeg-4avc),包含其可缩放视频译码(svc)及多视图视频译码(mvc)扩展。另外,新的视频译码标准,即高效视频译码(hevc)或itu-th.265,包含其范围扩展、多视图扩展(mv-hevc)和可缩放(shvc)扩展,最近已由itu-t视频译码专家组(vceg)和iso/iec动画专家组(mpeg)的视频译码联合合作小组(jct-vc)以及3d视频译码扩展开发联合合作小组(jct-3v)开发。hevc的草案规范且下文称为hevcwd或“hevc规范”从http://phenix.int-evry.fr/jct/doc_end_user/documents/14_vienna/wg11/jctvc-n1003-v1.zip可用。hevc的另一草案规范是布洛斯等人的“高效视频译码(hevc)文字规范草案10(用于fdis和最后呼叫)”,itu-tsg16wp3和iso/iecjtc1/sc29/wg11的视频译码联合合作小组(jct-vc)第12次会议:瑞士日内瓦,2013年1月14-23日,文档jctvc-l1003_v34(下文为“jctvc-l1003”),其可在http://phenix.it-sudparis.eu/jct/doc_end_user/documents/12_geneva/wg11/jctvc-l1003-v34.zip可用。举例来说,下文介绍hevc的设计方面,聚焦于变换系数译码,以及上下文自适应二进制算术译码(cabac)。
在hevc及其它视频译码标准中,视频序列通常包含一系列图片。图片也可被称为“帧”。图片可包含一或多个样本阵列。举例来说,图片可包含一个明度样本阵列和两个色度样本阵列,分别表示为sl、scb和scr。sl是明度样本的二维阵列(即,块)。scb是cb色度样本的二维阵列。scr是cr色度样本的二维阵列。在其它情况下,图片可为单色的且可仅包含明度样本阵列。
在hevc中,切片中的最大译码单元称为译码树单元(ctu)。ctu含有四叉树,其节点是译码单元。ctu的大小可介于hevc主简档中的16×16到64×64的范围(尽管技术上可支持8×8ctu大小)。为了产生图片的经编码表示(即,对图片进行编码),视频编码器20可产生译码树单元(ctu)的集合。每个相应ctu可以是明度样本的译码树块、色度样本的两个对应的译码树块,以及用以对译码树块的样本进行译码的语法结构。在单色图片或具有三个单独颜色平面的图片中,ctu可包括单个译码树块及用于对所述译码树块的样本进行译码的语法结构。译码树块可为样本的nxn块。ctu也可以被称为“树块”或“最大译码单元(lcu)”。切片可包含以例如光栅扫描次序的扫描次序连续排序的整数数目个ctu。
在hevc中为了产生经编码ctu(即,对ctu进行编码),视频编码器20可对ctu的译码树块递归地执行四叉树分割以将译码树块划分为译码块,因此名为“译码树单元”。译码块是样本的n×n块。cu可为具有明度样本阵列、cb样本阵列和cr样本阵列的图片的明度样本的译码块和色度样本的两个对应译码块,以及用于对译码块的样本进行译码的语法结构。在单色图片或具有三个单独颜色平面的图片中,cu可包括单个译码块和用以对译码块的样本进行译码的语法结构。cu可与ctu为相同大小,但cu可小达8x8。
视频编码器20可产生cu的经编码表示(即,对cu进行编码)。作为对cu进行编码的部分,视频编码器20可将cu的译码块分割为一或多个预测块。预测块可为其上应用相同预测的样本的矩形(即,正方形或非正方形)块。cu的预测单元(pu)可以是图片的明度样本的预测块,图片的色度样本的两个对应的预测块,以及用以对预测块样本进行预测的语法结构。视频编码器20可以产生用于cu的每个pu的明度预测块、cb预测块以及cr预测块的预测性明度块、cb块以及cr块。在单色图片或具有三个单独颜色平面的图片中,pu可包括单个预测块和用于预测预测块的语法结构。
视频编码器20可使用帧内预测或帧间预测以产生pu的预测块。每一cu是以帧内预测模式或帧间预测模式中的一者译码的。如果视频编码器20使用帧内预测以产生pu的预测块,那么视频编码器20可基于与pu相关联的图片的经解码样本产生pu的预测块。如果视频编码器20使用帧间预测以产生pu的预测性块,那么视频编码器20可基于除与pu相关联的图片外的一或多个图片的经解码样本而产生pu的预测性块。当cu经帧间译码时(即,当使用帧间预测来产生cu的pu的预测性块时),cu可分割成2或4个pu,或者当进一步分割不适用时cu可变为仅一个pu。当两个pu存在于一个cu中时,所述两个pu可为cu的大小的二分之一大小矩形或者1/4或3/4大小的两个矩形。此外,当cu经帧间译码时,针对每一pu存在一个运动信息集合。另外,当cu经帧间译码时,cu的每一pu是以单独帧间预测模式译码以导出所述运动信息集合。
在视频编码器20产生cu的一或多个pu的预测性块(例如,预测性明度、cb和cr块)之后,视频编码器20可产生cu的一或多个残余块。cu的残余块中的每个样本指示关于cu的pu的预测块中的样本与cu的译码块中的对应样本之间的差异。举例来说,视频编码器20可产生cu的明度残余块。cu的明度残余块中的每一样本指示cu的pu的预测性明度块中的明度样本与cu的明度译码块中的对应样本之间的差异。另外,视频编码器20可产生cu的cb残余块。cu的cb残余块中的每个样本可指示cu的pu的预测cb块中的cb样本与cu的cb译码块中的对应样本之间的差异。视频编码器20还可以产生cu的cr残余块。cu的cr残余块中的每一样本可指示cu的pu的预测性cr块中的cr样本与cu的cr译码块中的对应样本之间的差异。
此外,视频编码器20可将cu的每一残余块分解为一或多个变换块(例如,使用四叉树分割)。变换块可以是将对其应用同一变换的矩形(正方形或非正方形)样本块。cu的变换单元(tu)可以是明度样本的变换块、色度样本的两个对应的变换块,以及用以对变换块样本进行变换的语法结构。因此,cu的每一tu可与明度变换块、cb变换块及cr变换块相关。与tu相关联的明度变换块可为cu的明度残余块的子块。cb变换块可为cu的cb残余块的子块。cr变换块可为cu的cr残余块的子块。在单色图片或具有三个单独颜色平面的图片中,tu可包括单个变换块和用于对变换块的样本进行变换的语法结构。在一些实例中,用于明度和色度分量的同一cu中的残余块可以不同方式分割。在一些实例中,存在cu大小应当等于pu大小和tu大小的限制;即,一个cu仅含有一个pu和一个tu。
视频编码器20可将一或多个变换应用到tu的变换块从而产生tu的系数块。tu的系数块可包括tu的系数等级。举例来说,视频编码器20可将一或多个变换应用到tu的明度变换块以产生tu的明度系数块。视频编码器20可将一或多个变换应用至tu的cb变换块以产生tu的cb系数块。视频编码器20可将一或多个变换应用至tu的cr变换块以产生tu的cr系数块。系数块可为变换系数的二维阵列。变换系数可为标量。如先前指示,变换系数的值可被称为系数等级。在一些实例中,视频编码器20跳过变换的应用。当针对块跳过变换的应用时,所述块(例如,tu)是“变换跳过块”。因此,在此类实例中,视频编码器20和视频解码器30可以与变换系数相同的方式处理变换块中的残余样本。
在产生系数块之后,视频编码器20可量化系数块。量化总体上是指对变换系数进行量化以可能减少用以表示变换系数的数据的量从而提供进一步压缩的过程。在一些实例中,视频编码器20跳过量化系数块的步骤。在视频编码器20量化系数块之后,视频编码器20可对指示经量化变换系数的语法元素进行熵编码。举例来说,视频编码器20可对指示经量化变换系数的语法元素执行上下文自适应二进制算术译码(cabac)。视频编码器20可以在位流中输出经熵编码的语法元素。
视频编码器20可输出可包含经熵编码语法元素和未经熵编码语法元素的位流。位流可包含形成经译码图片和相关联数据的表示的位序列。因此,位流可形成视频数据的经编码表示。位流可包括网络抽象层(nal)单元的序列。所述nal单元中的每一者包含nal单元标头且囊封原始字节序列有效负载(rbsp)。nal单元标头可包含指示nal单元类型码的语法元素。由nal单元的nal单元标头指定的nal单元类型码指示nal单元的类型。rbsp可为含有囊封在nal单元内的整数数目个字节的语法结构。在一些情况下,rbsp包含零个位。
不同类型的nal单元可囊封不同类型的rbsp。举例来说,第一类型的nal单元可囊封用于图片参数集(pps)的rbsp,第二类型的nal单元可囊封用于经译码切片的rbsp,第三类型的nal单元可囊封用于补充增强信息(sei)的rbsp,等等。囊封视频译码数据的rbsp(与参数集及sei消息的rbsp相对)的nal单元可被称为视频译码层(vcl)nal单元。
在图1的实例中,视频解码器30接收视频编码器20所产生的位流。另外,视频解码器30可剖析位流以从位流获得语法元素。作为从位流获得语法元素的部分,视频解码器30可执行熵解码(例如,cabac解码)以从位流获得特定语法元素。视频解码器30可至少部分地基于从位流获得的语法元素而重构(即,解码)视频数据的图片。用以重构视频数据的过程一般可与由视频编码器20执行以对视频数据进行编码的过程互逆。举例来说,视频解码器30可以使用帧内预测或帧间预测来确定当前cu的pu的预测块。另外,视频解码器30可逆量化当前cu的tu的系数块。视频解码器30可对系数块执行逆变换以重构当前cu的tu的变换块。通过将用于当前cu的pu的预测块的样本添加到当前cu的tu的变换块的对应的样本上,视频解码器30可重构当前cu的译码块。通过重构用于图片的每一cu的译码块,视频解码器30可重构所述图片。
如上文所指出,视频编码器20和视频解码器30可执行cabac译码。cabac是在h.264/avc中首先介绍且现在hevc中使用的熵译码的方法。cabac涉及三个主要功能:二进制化、上下文模型化,以及算术译码。二进制化将语法元素映射到称为二进位串的二进制符号(二进位)。换句话说,为了将cabac编码应用于语法元素,视频编码器可将所述语法元素二进制化以形成一系列一或多个位,所述位称为“二进位”。上下文模型化估计二进位的概率。最后,二进制算术译码器基于估计概率而将二进位压缩为位。
作为上下文模型化的部分,视频编码器可识别译码上下文。译码上下文可以识别译码二进位具有特定值的概率。举例来说,译码上下文可以指示对0值二进位进行译码的0.7概率,以及对1值二进位进行译码的0.3概率。在识别出译码上下文之后,视频编码器20可将区间划分成下部子区间和上部子区间。所述子区间中的一者可与值0相关联,且另一子区间可与值1相关联。所述子区间的宽度可与由经识别的译码上下文关于相关联值所指示的概率成比例。如果语法元素的二进位具有与下部子区间相关联的值,那么经编码值可等于下部子区间的下边界。如果语法元素的同一二进位具有与上部子区间相关联的值,那么经编码值可等于上部子区间的下边界。为了编码语法元素的下一个二进位,视频编码器20可重复这些步骤,其中区间为与经编码位的值相关联的子区间。当视频编码器针对下一个二进位重复这些步骤时,视频编码器可使用基于由经识别的译码上下文指示的概率及经编码的二进位的实际值的经修改概率。
当视频解码器对语法元素执行cabac解码时,视频解码器30可识别译码上下文。视频解码器可接着将区间划分成下部子区间和上部子区间。所述子区间中的一者可与值0相关联,且另一子区间可与值1相关联。所述子区间的宽度可与由经识别的译码上下文关于相关联值所指示的概率成比例。如果经编码值在下部子区间内,那么视频解码器30可解码具有与下部子区间相关联的值的二进位。如果经编码值在上部子区间内,那么视频解码器30可解码具有与上部子区间相关联的值的二进位。为了解码语法元素的下一个二进位,视频解码器30可重复这些步骤,其中区间为含有经编码值的子区间。当视频解码器30针对下一个二进位重复这些步骤时,视频解码器30可使用基于由经识别的译码上下文指示的概率及经解码的二进位的经修改概率。视频解码器30可接着对二进位去二进制化以恢复语法元素。
视频编码器20可使用旁路cabac译码对一些二进位进行编码,而不是对所有语法元素执行常规cabac编码。与对二进位执行常规cabac译码相比,对二进位执行旁路cabac译码在计算上可较便宜。此外,执行旁路cabac译码可允许较高的并行度和处理量。使用旁路cabac译码来编码的二进位可被称为“旁路二进位”。旁路cabac译码引擎可较简单,因为旁路cabac译码引擎并不选择上下文,且可对两个符号(0和1)假定概率1/2。因此,在旁路cabac译码中,区间直接以二分之一分裂。将旁路二进位分组在一起可增加视频编码器20和视频解码器30的处理量。旁路cabac译码引擎可能够在单个循环中对若干二进位进行译码,而常规cabac译码引擎在一循环中可仅能够对单个二进位进行译码。
因此,算术译码可基于递归区间划分。在常规算术译码器中,具有0到1的初始值的范围基于二进位的概率而划分成两个子区间。经编码位提供偏移,所述偏移当转换成二进制分数时选择两个子区间中的一个,其指示经解码二进位的值。在每个经解码二进位之后,范围经更新为等于选定的子区间,且区间划分过程自身重复。范围和偏移具有有限的位精度,因此每当范围低于某一值时可需要重新归一化以防止下溢。重新归一化可在每一二进位经解码之后发生。
算术译码可使用估计概率(上下文经译码)(称为常规译码模式)来完成,或假定0.5的相等概率(旁路译码,称为旁路模式)来完成。对于经旁路译码二进位,范围划分为子区间可通过移位完成,而对于经上下文译码二进位可能需要查找表。hevc使用与h.264/avc相同的算术译码。jctvc-l1003的章节9.3.4.3.2.2中描述解码过程的实例。
在hevc中使用若干不同二进制化过程,包含一元(u)、截断一元(tu)、k阶指数-哥伦布(egk)以及固定长度(fl)。hevc中使用的二进制化过程的细节可以参见jctvc-l1003。如上文所提及,k阶指数-哥伦布译码是hevc中使用的二进制化过程中的一者。当阶k等于0时,可使用以下过程以使用用于给定非负整数x的指数-哥伦布译码产生二进位串(例如,二进位的串):
1.以二进制记录x+1。
2.对写入的位计数,减去一,且记录在先前位串前的开始零位的数目(即,以x+1的二进制表示记录位数目,减去1,前置到x+1的二进制表示)。
举例来说,假设x等于4。因此,在步骤1中,记录二进制值101。在步骤2中,位数目是3;3减去1是2。因此,前缀由两个0组成。因此,4的k阶指数-哥伦布码是00101。
为了以k阶指数-哥伦布码对非负整数x进行编码:
1.使用上述0阶指数-哥伦布码对
2.以k位的固定长度二进制值对xmod2k进行编码。
表达此情况的等效方式为:
1.使用0阶指数-哥伦布码对x+2k-1进行编码(即使用eliasγ码对x+2k进行编码),随后
2.从编码结果删除k个前导零位。
举例来说,假设k等于2且x等于4。在此实例中,在步骤1中,
下表中给出实例:
表1.使用k阶指数-哥伦布码的m的码字
以另一表示方式:
表2.使用k阶指数-哥伦布码的m的码字
在表2中,x的值可以是0或1。应注意对于一些情况,上文所列的‘1’和‘0’可以交换。即,二进位串可以由连续的‘1’前导而不是‘0’。
对于k阶莱斯译码器,可通过以下步骤产生码字:
1.将参数m固定为整数值(m=(1<<k)。
2.对于待编码的数字n,找到
1.商=q=int[n/m]
2.余数=r=nmodulom
3.产生码字
1.码格式:<商码><余数码>,其中
2.商码(以一元译码)
1.写入1位的q长度串
2.写入0位
3.余数码(以截断二进制编码):需要k位
举例来说,假设k等于2且n等于5。因此,m等于二进制的100(十进制的4)。在此实例中,5/4的整数除法商等于1;余数等于1(二进制的1)。因此,商码为10(即,1位的1长度串,接着是0位)。余数码为01(即,表示余数值1的k位的固定长度码)。因此,用于5的2阶莱斯码是1001。
以下在表3中示出对于高达15的数字的莱斯码,其中除数m等于4:
表3.使用k阶莱斯码(k等于2)的m的码字
如上文简要描述,hevc和潜在其它视频译码规范中使用的cabac过程使用上下文模型化。上下文模型化提供实现高译码效率所必要的准确概率估计。因此,上下文模型化是高度自适应的。不同上下文模型可用于不同二进位,其中上下文模型的概率是基于经先前译码二进位的值而更新。具有相似分布的二进位常常共享同一上下文模型。用于每一二进位的上下文模型可基于语法元素的类型、语法元素(binidx)中的二进位位置、明度/色度、相邻信息等而选择。
在一些实例中,上下文切换发生在每一二进位译码之后。此外,在一些实例中,概率模型存储为上下文存储器中的7位条目(6位用于概率状态且1位用于最可能符号(mps))且使用由上下文选择逻辑计算的上下文索引来寻址。
如上文简要描述,在hevc中,cu可根据残余四叉树分割成tu。因此,为了适应残余块的各种特性,在hevc中应用使用残余四叉树(rqt)的变换译码结构,其在夫朗和斐hhi(fraunhoferhhi)的文章“使用残余四叉树(rqt)的变换译码”中简单描述,所述文章先前在http://www.hhi.fraunhofer.de/fields-of-competence/image-processing/researchgroups/image-video-coding/hevc-high-efficiency-video-coding/transform-coding-using-the-residual-quadtree-rqt.html可用,但从2016年6月28日起在http://www.hhi.fraunhofer.de/departments/video-coding-analytics/research-groups/image-video-coding/research-topics/hevc-high-efficiency-video-coding/transform-coding-using-the-residual-quadtree-rqt.html可用。
如上文所描述,在hevc中,每一图片划分成译码树单元(ctu),其是针对特定瓦片或切片以光栅扫描次序经译码。ctu是正方形块且表示四叉树的根,即译码树。ctu大小可从8×8到64×64明度样本变动,但通常使用64×64。每一ctu可进一步分裂成较小正方形块,称为译码单元(cu)。在ctu递归地分裂为cu之后,每一cu进一步划分成pu和tu。cu分割为tu是基于四叉树方法递归地实行,因此每一cu的残余信号是通过树结构译码,即rqt。rqt允许从4×4直到32×32明度样本的tu大小。
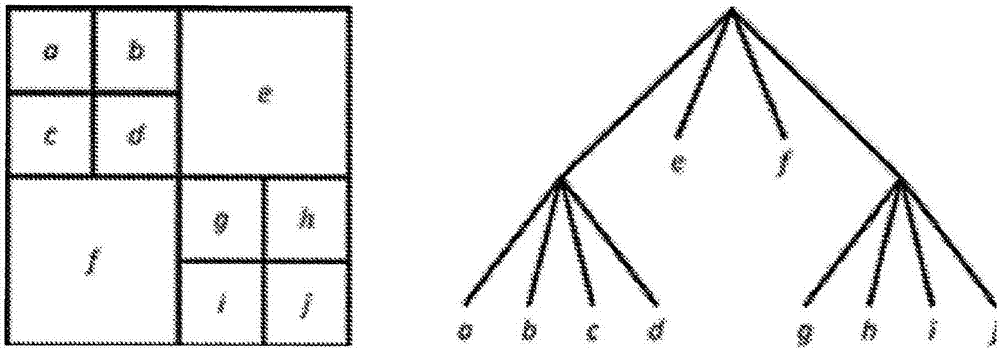
图2是说明例如高效视频译码(hevc)中使用的基于残余四叉树的变换方案的概念图。图2示出了其中cu包含标记有字母a到j的十个tu以及对应块分割的实例。rqt的每一节点实际是tu。以深度优先树遍历次序处理个别tu,其在图中说明为字母次序,其跟随具有深度优先遍历的递归z扫描。四叉树方法实现变换对残余信号的变化空间频率特性的适配。通常,具有较大空间支持的较大变换块大小提供较好频率分辨率。然而,具有较小空间支持的较小变换块大小提供较好空间分辨率。空间和频率分辨率两者之间的折衷可以例如基于速率失真优化技术通过编码器模式决策而选择。速率失真优化技术计算用于每一译码模式(例如,特定rqt分裂结构)的译码位和重构失真的加权和,即速率失真成本,且选择具有最小速率失真成本的译码模式作为最佳模式。
在一些实例中,rqt中定义三个参数:(1)树的最大深度,(2)最小允许的变换大小,以及(3)最大允许的变换大小。在hevc中,最小和最大变换大小可在从4×4到32×32样本的范围内变化,其对应于上文所提及的支持块变换。rqt的最大允许深度限制tu的数目。等于1的最大深度意味着如果每一所包含tu达到最大允许的变换大小,例如32×32,则cu无法进行任何进一步分裂。
所有这些参数可与rqt结构相互作用且影响rqt结构。举例来说,考虑其中根cu大小是64×64的情况,最大深度等于零且最大变换大小等于32×32。在此情况下,cu必须经分割至少一次,因为否则将导致64×64tu,这是不允许的。rqt参数,即最大rqt深度、最小和最大变换大小,可在位流中在序列参数集层级传输。关于rqt深度,对于经帧内和帧间译码cu可指定且用信号表示不同的值。举例来说,对于以帧内模式编码的cu可指定第一最大深度值,且对于以帧间模式编码的cu可指定第二不同最大深度值。
四叉树变换适用于帧内和帧间残余块。通常,当前残余四叉树分割的相同大小的dct-ii变换(即,类型2离散余弦变换)适用于残余块。然而,如果当前残余四叉树块是4×4且由帧内预测产生,那么应用4×4dst-vii变换(即,类型7离散正弦变换)。在hevc中,不采用例如64×64变换的较大大小变换,主要是由于其对于相对较小分辨率视频的有限的益处和相对高复杂性。
在hevc中,不管tu大小如何,tu的残余是以非重叠系数群组(cg)译码的。cg中的每一者含有tu的4×4块的系数。举例来说,32×32tu具有总共64个cg,且16×16tu具有总共16个cg。tu内的cg是根据某一预定义扫描次序而译码。当对每一相应cg进行译码时,相应cg内的系数是根据用于4×4块的某一预定义扫描次序而扫描且译码。图3说明在hevc中使用的用于含有4个cg的8×8tu的系数扫描。
在hevc中用于用信号表示tu的残余数据的语法元素表如下定义:
7.3.8.11残余译码语法
对于每一相应颜色分量(例如,明度、cb、cr),可首先用信号表示相应旗标以指示当前tu是否具有至少一个非零系数。如果存在至少一个非零系数,那么tu中按系数扫描次序的最后有效系数的位置随后以相对于tu的左上角的坐标进行显式译码。所述坐标的垂直或水平分量是由其前缀和后缀表示。前缀是以0阶截断莱斯(tr)二进制化,且后缀是以固定长度二进制化。以上莱斯译码的论述是截断莱斯(tr)译码的实例。
在上表中,last_sig_coeff_x_prefix指定变换块内按扫描次序的最后有效系数的列位置的前缀。last_sig_coeff_x_prefix的值将处于0到(log2trafosize<<1)-1(包含性)的范围内。
在上表中,last_sig_coeff_y_prefix指定变换块内按扫描次序的最后有效系数的行位置的前缀。last_sig_coeff_y_prefix的值将处于0到(log2trafosize<<1)-1(包含性)的范围内。
在上表中,last_sig_coeff_x_suffix指定变换块内按扫描次序的最后有效系数的列位置的后缀。last_sig_coeff_x_suffix的值将处于0到(1<<((last_sig_coeff_x_prefix>>1)-1))-1(包含性)的范围内。
变换块内按扫描次序的最后有效系数的列位置lastsignificantcoeffx如下导出:
-如果last_sig_coeff_x_suffix不存在,那么以下适用:
lastsignificantcoeffx=last_sig_coeff_x_prefix
-否则(last_sig_coeff_x_suffix存在),那么以下适用:
lastsignificantcoeffx=(1<<((last_sig_coeff_x_prefix>>1)-1))*(2+(last_sig_coeff_x_prefix&1))+last_sig_coeff_x_suffix
在上表中,last_sig_coeff_y_suffix指定变换块内按扫描次序的最后有效系数的行位置的后缀。last_sig_coeff_y_suffix的值将处于0到(1<<((last_sig_coeff_y_prefix>>1)-1))-1(包含性)的范围内。
变换块内按扫描次序的最后有效系数的行位置lastsignificantcoeffy如下导出:
-如果last_sig_coeff_y_suffix不存在,那么以下适用:
lastsignificantcoeffy=last_sig_coeff_y_prefix
-否则(last_sig_coeff_y_suffix存在),那么以下适用:
lastsignificantcoeffy=(1<<((last_sig_coeff_y_prefix>>1)-1))*(2+(last_sig_coeff_y_prefix&1))+last_sig_coeff_y_suffix
当scanidx等于2时,交换坐标如下:
(lastsignificantcoeffx,lastsignificantcoeffy)=swap(lastsignificantcoeffx,lastsignificantcoeffy)。
通过此经译码位置以及还有cg的系数扫描次序,对于除最后cg(按扫描次序)之外的cg进一步用信号表示一个旗标,其指示最后cg是否含有非零系数。
当对一个cg是否具有非零系数、即cg旗标(hevc规范中的coded_sub_block_flag)进行译码时,视频译码器可使用相邻cg的信息来建置上下文。举例来说,在hevc中,用于对cg旗标进行译码的上下文选择被定义为:
(右边cg可用&&右边cg的旗标等于1)||(下方cg可用&&下方cg的旗标等于1)
在以上公式中,右边cg和下方cg是靠近当前cg的两个相邻cg。举例来说,在图3中,当对左上方4×4块进行译码时,右边cg被定义为右上方4×4块且下方cg被定义为左下方4×4块。色度和明度使用上下文模型的不同集合,但视频译码器可使用同一规则为色度和明度中的每一者选择上下文模型中的一者。上下文索引增量(ctxinc)的导出的细节可参见hevc规范的子条款9.3.4.2.4。
对于含有非零系数的那些cg,视频译码器可进一步根据预定义4x4系数扫描次序针对每一系数对有效旗标(significant_flag或sig_coeff_flag)、系数的绝对值(包含coeff_abs_level_greater1_flag、coeff_abs_level_greater2_flag和coeff_abs_level_remaining)以及正负号信息(coeff_sign_flag)进行译码。变换系数等级的译码分成多个扫描遍次。
在第一二进位译码的第一遍次中,在一个cg内的每一位置处的变换系数的所有第一二进位(或二进位索引0bin0,其可对应于significant_flag语法元素)经译码,可导出特定变换系数等于0的情况除外。举例来说,对于在最后位置处含有系数的最后cg,按解码次序在最后位置之前经扫描的所有系数导出为0且没有二进位经译码。
如hevc规范的子条款9.3.4.2.5中所描述,变量sigctx用以导出在选择用于有效旗标的译码上下文时使用的上下文索引增量变量(ctxinc)的值。变量sigctx取决于相对于当前tu的左上方位置的当前位置、颜色分量索引cidx、变换块大小,以及语法元素coded_sub_block_flag的先前经解码二进位。取决于tu大小而应用不同规则。hevc规范的子条款9.3.4.2.5提供用于有效旗标的上下文索引增量的选择的细节。
在第二二进位译码的第二遍次中,视频译码器对coeff_abs_level_greater1_flags进行译码。用于coeff_abs_level_greater1_flags的上下文模型化取决于颜色分量索引、当前子块扫描索引,以及当前子块内的当前系数扫描索引。hevc规范的子条款9.3.4.2.6提供用于coeff_abs_level_greater1_flags的上下文索引增量变量的选择的细节。
在第三二进位译码的第三遍次中,视频译码器对coeff_abs_level_greater2_flags进行译码。用于coeff_abs_level_greater2_flags的上下文模型化类似于由coeff_abs_level_greater1_flags使用的上下文模型化。hevc规范的子条款9.3.4.2.7提供上下文索引增量的选择的细节。
为了改善处理量,第二和第三遍次可不处理cg中的所有系数。而是,cg中的前八个coeff_abs_level_greater1_flags以常规模式译码。在那之后,剩下的值在第五遍次中通过语法coeff_abs_level_remaining以旁路模式译码。类似地,cg中仅具有大于1的量值的第一系数的coeff_abs_level_greater2_flag经译码。cg的具有大于1的量值的其余系数使用coeff_abs_level_remaining对值进行译码。此技术可将用于系数等级的常规二进位的数目限制为每cg最大9个:8个用于coeff_abs_level_greater1_flags且1个用于coeff_abs_level_greater2_flags。
第四遍次用于正负号信息。在hevc中,每一非零系数的正负号是在第四扫描遍次中以旁路模式译码。对于每一cg,且取决于准则,当使用正负号数据隐藏(sdh)时简单地省略对最后非零系数(按反向扫描次序)的正负号的编码。实际上,使用预定义惯例将正负号值嵌入于cg的等级的总和的奇偶校验中:偶数对应于“+”且奇数对应于“-”。使用sdh的准则是cg的第一与最后非零系数之间的在扫描次序上的距离。具体来说在hevc中,如果此距离等于或大于4,那么使用sdh。否则,不使用sdh。hevc中选择4的值,因为4的值提供hevc测试序列上的最大增益。
在最后遍次中,剩余二进位是在又一扫描遍次中经译码。假设系数的baselevel定义为:
baselevel=significant_flag+coeff_abs_level_greater1_flag+
coeff_abs_level_greater2_flag(1)
其中旗标(即,significant_flag、coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag)具有0或1的值,且如果不存在则推断为0。随后,系数的绝对值简单地定义为:
abscoefflevel=baselevel+coeff_abs_level_remaining。(2)
在hevc中,coeff_abs_level_remaining经旁路译码,且因此不需要上下文模型化。
hevc中的语法元素coeff_abs_level_remaining指示用于系数等级的绝对值的剩余值(如果所述值大于用于系数译码的先前扫描遍次中经译码的值)。语法元素coeff_abs_level_remaining是以旁路模式译码以便增加处理量。如钱(chien)等人的“关于系数等级剩余译码(oncoefficientlevelremainingcoding)”(jctvc-i0487,视频译码联合合作小组(jct-vc)第9次会议,瑞士日内瓦,2012年4月-5月)所描述,hevc采用莱斯码用于coeff_abs_level_remaining的小值且切换到指数-哥伦布码用于coeff_abs_level_remaining的较大值。
hevc从使用莱斯码用于coeff_abs_level_remaining语法元素切换到使用指数-哥伦布码用于coeff_abs_level_remaining语法元素的点可被称为切换点。切换点可定义为以下两个方法中的一者:
1)切换点等于(3<<k):当coeff_abs_level_remaining小于(3<<k)时,使用k阶莱斯码。否则,使用k阶指数-哥伦布码的前缀(具有三个‘1’)和后缀用于旁路译码
2)切换点等于(4<<k):当coeff_abs_level_remaining小于(4<<k)时,使用k阶莱斯码。否则,使用(k+1)阶指数-哥伦布码的前缀(具有四个‘1’)和后缀用于旁路译码。
为简单起见,在以下描述中,使用第一方法,即切换点被定义为(3<<k)。表4中给出实例:
表4.等于m的coeff_abs_level_remaining的码字
如j.索尔(j.sole)等人的“hevc中的变换系数译码(transformcoefficientcodinginhevc)”(ieee视频传输电路和系统会刊(hevc增刊),2012年12月)所描述,在hevc中,莱斯参数k在每一cg(系数群组,其为4x4子块)的开始处设定成0,且k取决于参数的先前值和当前绝对等级而有条件地更新,如下:
如果abscoefflevel>3*2k,那么k=min(k+1,4)(3)
否则,k=k
其中k是莱斯参数且函数min()返回两个输入当中的较小值。因此,如果用于当前系数等级的abscoefflevel值大于3*2k,那么视频译码器将k更新为等于k+1和4中的较小者,无论是哪一个。如果当前系数等级的abscoefflevel值不大于3*2k,那么视频译码器不更新k。参数更新过程允许二进制化以当在分布中观察到大值时适配于系数统计。在以下描述中,导出莱斯参数的此方法被命名为‘基于回顾的导出方法’。
卡塞维茨(karczewicz)等人提议的另一技术“rce2:莱斯参数初始化的测试1的结果(rce2:resultsoftest1onriceparameterinitialization)”(jctvc-p0199,itu-tsg16wp3和iso/iecjtc1/sc29/wg11的视频译码联合合作小组(jct-vc)第16次会议:美国圣何塞,2014年1月9-17日(下文为“jctvc-p0199”))在hevc范围扩展中用于莱斯参数导出,以更高效地对可存在于无损或高位深度译码中的大得多的系数等级进行译码。
首先,在hevc范围扩展中使用的技术中,4×4子块(即,cg)划分成不同类别(“sbtype”)。对于每一子块,基于同一类别中经先前译码的子块而导出初始莱斯参数。分类是基于子块(即,cg)是否为变换跳过块(“istsflag”)以及块是否用于明度分量:
sbtype=isluma*2+istsflag(4)
取决于子块中的第一系数的coeff_abs_level_remaining,视频译码器维持用于每一子块类型(sbtype)的统计statcoeff:
if(abscoefflevel>=3*(1<<(statcoeff/4)))statcoeff++;(5)
elseif((2*abscoefflevel)<(1<<(statcoeff/4)))statcoeff--;
视频译码器更新statcoeff变量是使用子块的第一经译码coeff_abs_level_remaining的值每4×4子块经更新至多一次。视频译码器在切片的开始处复位statcoeff的条目为0。此外,视频译码器使用statcoeff的值以将每一4×4子块的开始处的莱斯参数k初始化为:
criceparam=min(maxricepara,statcoeff/4)。(6)
在以下描述中,导出莱斯参数(例如,criceparam)的此方法被命名为“基于统计的导出方法”或“基于统计的莱斯参数导出方法”。因此,在基于统计的导出方法中,视频译码器可将当前图片的多个子块划分为多个类别以使得对于所述多个子块中的相应子块,相应子块是基于所述相应子块是否为变换跳过块以及所述相应子块是否用于明度分量而分类。此外,对于所述多个类别中的每一相应类别,视频译码器可维持用于相应类别的相应统计值。对于所述多个子块中的每一相应子块,视频译码器可使用相应统计值用于相应子块所属于的类别,以初始化用于相应子块的相应莱斯参数。所述多个子块中的特定子块中的coeff_abs_level_remaining语法元素是使用k阶莱斯码而二进制化,k是用于所述特定子块的莱斯参数。
对于所述多个类别中的每一相应类别,作为维持用于相应类别的相应统计值的部分,视频译码器可针对属于相应类别的图片的每一相应子块,针对所述相应子块使用针对所述相应子块首先经译码的等级剩余语法元素更新用于相应类别的相应统计值至多一次。此外,作为更新用于相应类别的相应统计值的部分,视频译码器可在(abscoefflevel>=3*(1<<(statcoeff/4)))的情况下递增用于相应类别的相应统计值;且在((2*abscoefflevel)<(1<<(statcoeff/4)))的情况下递减用于相应类别的相应统计值。如前所述,abscoefflevel是相应子块的绝对系数等级,且statcoeff是用于相应类别的相应统计值。对于所述多个子块中的每一相应子块,作为使用相应子块所属于的类别的相应统计值以初始化用于相应子块的相应莱斯参数的部分,视频译码器可将用于相应子块的相应莱斯参数确定为最大莱斯参数以及相应子块所属于的类别的相应统计值除以4中的最小值。
阮等人的“non-ce11:用于变换系数译码的所提议清理(non-ce11:proposedcleanupfortransformcoefficientcoding)”(jctvc-h0228,第8次会议:美国加利福尼亚州圣何塞,2012年2月1-10日(下文为“jctvc-h0228”)提议单个扫描遍次译码,即关于变换系数等级的所有信息是在单个步骤中译码,而不是如hevc中的多遍次译码。对于每一扫描位置,评估由局部模板覆盖的相邻者(即,相邻样本),如hevc的当前设计中针对bin0(二进位串的第一二进位,也被称作significant_coeff_flag或coeff_abs_greater0_flag)所完成。根据此评估,导出上下文模型和莱斯参数,其控制剩余绝对值的自适应二进制化。更特定的,全部基于位于局部模板中的变换系数量值而选择用于bin0、bin1、bin2和莱斯参数的上下文模型(bin1和bin2也被称作coeff_abs_greater1_flag和coeff_abs_greater2_flag)。
图4是说明实例局部模板的概念图。具体来说,在图4中针对具有对角线扫描的8×8变换块给出局部模板的实例,x表示当前扫描位置,且i∈[0,4]的xi表示由局部模板覆盖的相邻者。
在以下等式中,指示相邻者的绝对总和的sum_absolute_level以及指示每一等级的绝对总和减去1的sum_absolute_levelminus1用以导出用于bin0、bin1、bin2(即,用于significant_flag、coeff_abs_greater1_flag和coeff_abs_greater2_flag)的上下文索引,且确定莱斯参数r。
sum_absolute_level=∑|xi|
sum_absolute_levelminus1=∑δj(xi)(7)
其中
在jctvc-h0228中描述的技术中,莱斯参数r如下导出。对于每一扫描位置,参数设定成0。随后,将sum_absolute_levelminus1对照阈值集合tr={3,9,21}进行比较。换句话说,如果sum_absolute_levelminus1属于第一区间则莱斯参数是0,如果sum_absolute_levelminus1属于第二区间则莱斯参数是1,等等。莱斯参数r的导出如下概括。
其中x等于sum_absolute_levelminus1。莱斯参数的范围在[0,3]内。
在以下描述中,导出莱斯参数的此方法被命名为“基于模板的导出方法”或“基于模板的莱斯参数导出方法”。因此,在基于模板的导出方法中,当前图片包括多个4x4子块,局部模板覆盖tu的当前样本的相邻者,且当前样本处于当前扫描位置。此外,视频编码器20可用信号表示且视频解码器30可获得指示用于当前样本的相应系数等级的绝对值的相应剩余值的语法元素(例如,coeff_abs_level_remaining语法元素)。在基于模板的导出方法中,对于由局部模板覆盖的每一相应相邻者,视频译码器(例如,视频编码器20或视频解码器30)可确定用于相应相邻者的相应值。在此实例中,用于相应相邻的相应值在相邻者的绝对值大于0的情况下等于相邻者的绝对值减去1,且在相邻者等于0的情况下等于0。另外,在基于模板的导出方法中,视频译码器可确定等于相邻者的值的总和的总和值(例如,sum_absolute_levelminus1)。此外,在基于模板的导出方法中,视频译码器可确定莱斯参数在总和值属于第一区间(例如,x是0与3之间(包含性)的整数)的情况下等于0,在总和值属于第二区间(例如,x是4与9之间(包含性)的整数)的情况下等于1,在总和值属于第三区间(例如,x是10与21之间(包含性)的整数)的情况下等于2,且在总和值属于第四区间(例如,x>21)的情况下等于3。所述语法元素是使用k阶莱斯码二进制化,其中k等于所确定的莱斯参数。还可使用除以上实例中提供的那些区间外的区间。所述区间可不重叠。
当前莱斯参数导出方法具有至少以下缺陷。第一,在hevc中的设计中,仅考虑一个先前经译码系数等级,这可为次最佳的。另外,在一个cg内,莱斯参数保持不变或增加,其中在局部区域中,可观察到较小系数等级,其偏向于用于较少经译码二进位的较小莱斯参数。举例来说,由于在每一cg的开始处k设定成0,且前提是k小于4,因此当系数的abscoefflevel大于3*2k时k递增,或否则保持在同一值。然而在此实例中,hevc的设计不准许k递减,即使这样做将产生较好压缩。
第二,虽然hevc范围扩展(参见jctvc-p0199)中采用的初始化方法极有益于无损或高位深度译码,但其仍具有一些缺陷。举例来说,在一个cg内,莱斯参数保持不变,可观察到较小系数等级,其偏向于用于较少经译码二进位的较小莱斯参数。举例来说,在hevc范围扩展中的技术中,莱斯参数是基于statcoeff值而确定,所述值每4×4子块经更新至多一次。在无损译码中,可跳过量化。在有损译码中,可执行量化,并且因此原始视频数据的信息丢失。
第三,jctvc-h0228中的设计通过考虑多个相邻者而对于有损译码更高效。然而,未像hevc范围扩展那样利用不同tu之间的相关。此外,如以上等式(8)中提到,jctvc-h0228中产生的最大莱斯参数等于3。预测误差(即,残余样本的值)对于无损译码或高位深度译码可为相当大的。在此情况下,如jctvc-h0228中设定的等于3的最大莱斯参数可能并不充分高效。另外,如何基于sum_absolute_levelminus1而设定莱斯参数是未知的。
为了解决上文所提及的问题中的一些或全部,提议用于莱斯参数导出和潜在地更高效变换系数上下文模型化的以下技术。可以个别地应用以下详细列举的方法。替代地,可应用其任何组合。本发明中描述的技术还可与以下各者中提议的技术联合使用:2015年5月29日提交的第62/168,571号美国临时专利申请、2016年5月26日提交的第15/166,153号美国专利申请,以及2016年5月27日提交的pct申请pct/us2016/034828。
根据本发明的实例技术,基于统计和基于模板的参数导出方法可单独地用于对一个tu中的系数等级进行编码/解码。举例来说,根据此技术,视频译码器可使用第一莱斯参数导出方法和第二莱斯参数导出方法用于对图片的当前cu的单个tu的系数等级进行解码。在此实例中,第一莱斯参数导出方法是基于统计的导出方法。此外,在此实例中,第二莱斯参数导出方法是基于模板的导出方法。
更具体地说,在一个实例中,基于统计的方法在解码器侧在每一tu中按解码/剖析次序应用于第一coeff_abs_level_remaining语法元素,而对于其它coeff_abs_level_remaining语法元素,应用基于模板的导出方法。举例来说,视频译码器可基于子块的第一经译码coeff_abs_level_remaining语法元素的值针对4×4子块更新如上文所描述的statcoeff的值。此外,在此实例中,视频译码器可基于statcoeff的值而初始化莱斯参数。视频译码器可随后在对tu的第一coeff_abs_level_remaining语法元素进行译码时使用此莱斯参数。另外,在此实例中,视频译码器可针对除tu的第一coeff_abs_level_remaining语法元素外的tu的每一coeff_abs_level_remaining语法元素执行如上文所描述的基于模板的导出方法。
替代地,在一些实例中,基于统计的方法在每一tu中按编码/解码次序应用于第一少数coeff_abs_level_remaining语法元素,而对于其它coeff_abs_level_remaining语法元素,应用基于模板的导出方法。因此,在一些实例中,视频编码器20可用信号表示且视频解码器30可获得一系列语法元素(例如,coeff_abs_level_remaining语法元素),所述系列语法元素的每一相应语法元素指示tu的相应系数等级的绝对值的相应剩余值。在此类实例中,作为视频译码器(例如,视频编码器20或视频解码器30)使用第一莱斯参数导出方法(例如,基于统计的导出方法)和第二莱斯参数导出方法(例如,基于模板的导出方法)用于对tu的系数等级进行解码的部分,视频译码器可按解码或剖析次序将第一莱斯参数导出方法应用于tu中首先出现的语法元素,其中所述语法元素在所述系列语法元素中。另外,在此实例中,视频译码器可将第二莱斯参数导出方法应用于所述系列语法元素的每一其它语法元素。
替代地,在一些实例中,基于统计的导出方法在每一tu中应用于位于特定相对位置的系数的一或多个coeff_abs_level_remaining语法元素,而对于其它coeff_abs_level_remaining语法元素,应用基于模板的导出方法。举例来说,视频译码器可使用基于统计的导出方法以确定用于对tu的第一、第16、...和第32系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数,且使用基于模板的导出方法以导出用于对tu的每一其它coeff_abs_level_remaining语法元素进行译码的莱斯参数。
替代地,在一些实例中,基于统计的方法在解码器侧在每一系数群组(cg)中按解码/剖析次序应用于第一coeff_abs_level_remaining语法元素,而对于cg中的其它coeff_abs_level_remaining语法元素,应用基于模板的导出方法。举例来说,视频译码器(例如,视频编码器20或视频解码器30)对于tu的每一4×4子块可使用基于统计的导出方法以确定用于对在解码相应子块时使用的按剖析/解码次序首先出现的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数。在此实例中,视频译码器使用基于模板的导出方法以导出用于对tu的每一其它系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数。
替代地,在一些实例中,基于统计的方法在解码器侧在每一cg中按解码/剖析次序应用于第一少数coeff_abs_level_remaining语法元素,而对于cg中的其它coeff_abs_level_remaining,应用基于模板的导出方法。举例来说,视频译码器(例如,视频编码器20或视频解码器30)对于tu的每一4×4子块可使用基于统计的导出方法以确定用于对在解码相应子块时使用的按剖析/解码次序例如在前两个或三个位置中出现的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数。在此实例中,视频译码器使用基于模板的导出方法以导出用于对tu的每一其它系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数。
根据本发明的实例技术,联合地使用基于统计和基于模板的莱斯参数导出方法以用于确定用于对一个系数等级进行编码/解码的莱斯参数。以此方式,视频译码器可联合地使用第一莱斯参数导出方法和第二莱斯参数导出方法以对变换单元的单个系数等级进行译码,其中第一莱斯参数导出方法是基于统计的导出方法,且第二莱斯参数导出方法是基于模板的导出方法。
因此,在此实例中,视频译码器可使用函数来确定用于对tu的当前系数的系数等级进行解码的莱斯参数值。在此实例中,所述函数的输入包含所记录值和当前导出的莱斯参数值。所记录值可基于用以对在当前系数之前的系数进行解码的莱斯参数值。在此实例中,视频译码器可使用基于模板的导出方法导出当前导出的莱斯参数值。此外,在此实例中,所述函数可以是最大值函数。
举例来说,在一个实例中,用以对当前coeff_abs_level_remaining语法元素进行编码/解码的莱斯参数是使用函数来确定,其中基于用以对先前系数进行编码/解码的莱斯参数值的所记录值以及使用基于模板的方法的当前导出莱斯参数值作为输入。下文描述确定所记录值的实例。
在其中用以对当前coeff_abs_level_remaining语法元素进行译码(即,编码或解码)的莱斯参数是使用函数确定的一个实例中,所述函数是最大值函数,例如用以对当前coeff_abs_level_remaining语法元素进行编码/解码的莱斯参数是所记录莱斯参数值与使用基于模板的方法的当前导出值之间的最大值。在一个实例中,实际用于对一个coeff_abs_level_remaining语法元素进行编码/解码的莱斯参数设定成用于对下一coeff_abs_level_remaining语法元素进行编码/解码的所记录值。替代地,在一些实例中,在对一个coeff_abs_level_remaining语法元素进行编码/解码之后,用于对下一coeff_abs_level_remaining语法元素进行编码/解码的所记录莱斯参数值设定成等于实际使用的莱斯参数减去变量diff。在一个此类实例中,变量diff设定成等于1。举例来说,视频译码器可将所记录值设定为等于用于对当前系数的系数等级进行解码的所确定莱斯参数值减去1。替代地,变量diff取决于输入/经译码的内部位深度和/或译码模式。在一些实例中,视频译码器可确定所记录值是否小于0。基于所记录值小于0,视频译码器可将所记录值复位为0。
如上文所描述,所记录值可用作用于对coeff_abs_level_remaining语法元素进行译码的莱斯参数。在不同实例中,视频译码器可以不同方式确定所记录值。举例来说,在一个实例中,在对一个变换单元或cg进行解码的开始,所记录莱斯参数值设定成等于0。替代地,在一些实例中,所记录莱斯参数值设定成等于根据基于统计的方法导出的值。换句话说,视频译码器可使用基于统计的方法设定所记录莱斯参数值。替代地,在一些实例中,当对tu或cg中的第一coeff_abs_level_remaining语法元素进行解码时,直接使用根据基于统计的方法导出的莱斯参数而无需考虑莱斯参数的先前值。换句话说,当对tu中首先出现(或另外在一些实例中,在tu的每一cg中首先出现)的coeff_abs_level_remaining语法元素进行解码时,视频译码器直接使用根据基于统计的方法导出的莱斯参数而无需考虑莱斯参数的任何先前值。替代地,在一些实例中,‘基于模板的方法’可被以上实例中的‘基于回顾的方法’代替。
根据本发明的特定实例技术,在基于模板的方法中,提出通用函数以从sum_absolute_levelminus1导出莱斯参数k。如上文所指出,在基于模板的方法中,值sum_absolute_levelminus1可指示值的总和,每一相应值是由用于当前系数的局部模板覆盖的相应系数的非零等级的绝对值减去1。因此,根据本发明的一些此类实例,视频译码器可确定等于多个等级中的每一等级的绝对总和减去1的值(例如,sum_absolute_levelminus1),其中所述多个等级中的每一相应系数等级在由模板界定的区中。在此实例中,视频译码器可基于值而确定莱斯参数,且基于莱斯参数而产生用于tu的当前系数的经解码值。
举例来说,在其中视频译码器使用通用函数以从sum_absolute_levelminus1导出莱斯参数的一个实例中,k被定义为满足(1<<(k+3))>(sum_absolute_levelminus1+m)的最小整数,其中m是整数,例如4。替代地,在一些实例中,‘>’被‘>=’代替。举例来说,假设m等于4且假设sum_absolute_levelminus1等于5,因此(sum_absolute_levelminus1+m)等于9。在此实例中,如果k等于0,那么(1<<(k+3))等于8,且如果k等于1,那么(1<<(k+3))等于16。因此,在此实例中,由于k=1是产生(1<<(k+3))>(sum_absolute_levelminus1+m)的最小整数值,因此视频译码器将k设定为等于1。
在一个实例中,k被定义为满足(1<<(k+3))>(sum_absolute_levelminus1+m+(1<<k))的最小整数,其中m是整数,例如4。替代地,在一些实例中,‘>’被‘>=’代替。举例来说,假设m等于4且假设sum_absolute_levelminus1等于5。在此实例中,如果k等于0,那么(1<<(k+3))等于8且(sum_absolute_levelminus1+m+(1<<k))等于10。此外,在此实例中,如果k等于1,那么(1<<(k+3))等于16且(sum_absolute_levelminus1+m+(1<<k))等于11。因此,在此实例中,由于k=1是产生(1<<(k+3))>(sum_absolute_levelminus1+m+(1<<k))的最小整数值,因此视频译码器将k设定为等于1。
替代地,在其中视频译码器使用通用函数以从sum_absolute_levelminus1导出莱斯参数的一些实例中,所导出k可最高达到阈值。举例来说,所述阈值可为9、10或另一值。在一个实例中,所述阈值可以针对一个序列(例如,经译码视频序列)和/或针对一个图片和/或针对一个切片而预定义或用信号表示。举例来说,在各种实例中,所述阈值可在序列参数集、图片参数集和/或切片标头中定义。在另一实例中,所述阈值取决于译码模式(无损译码或有损译码)和/或输入/经译码的内部位深度。举例来说,所述阈值在无损译码中可比有损译码中更大。类似地,当对具有较大内部位深度的系数进行译码时所述阈值可更大。
根据本发明的实例技术,在基于模板的参数导出方法中,定义且利用多个模板(即,用于计算sum_absolute_levelminus1的相邻者的相对位置)。在其中定义且利用多个模板的一个实例中,模板的选择是基于扫描模式。因此,根据此实例,视频译码器可从多个模板当中选择模板以用于导出莱斯参数,所述多个模板中的每一相应模板指示相对于当前系数的相邻系数的不同位置。此外,视频译码器可使用莱斯参数以对用于指示当前系数的剩余值的绝对等级的值的码字进行解码。
在其中定义且利用多个模板的一些实例中,扫描模式可为用于扫描tu的系数的模式,例如图3的实例中示出的模式。举例来说,视频译码器可在使用第一扫描模式(例如,图3的扫描模式)的情况下选择第一模板(例如,图4的模板),但在使用第二不同扫描模式的情况下可选择第二不同模板。举例来说,如果第二扫描模式是图3的扫描模式的反转,那么第二模板可以类似于图4的模板,但垂直地且水平地翻转。
在其中定义且利用多个模板的一些实例中,模板的选择是基于帧内预测模式。举例来说,视频译码器可在用于帧内预测cu的pu的帧内预测模式是水平或近似水平的情况下选择第一模板以用于确定用于对cu的tu的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数,且可在所述帧内预测模式是垂直或近似垂直的情况下选择第二不同模板。
在其中定义且利用多个模板的一些实例中,模板的选择是基于译码模式(例如,帧内或帧间译码模式)和/或变换矩阵。举例来说,视频译码器可在cu是使用帧内预测译码的情况下选择第一模板以用于确定用于对cu的tu的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数,且在cu是使用帧间预测译码的情况下选择第二不同模板。
在其中定义且利用多个模板的一些实例中,模板的选择是基于当前tu的量化参数(qp)。qp可以是由解码过程使用以用于变换系数等级的按比例缩放的变量。举例来说,视频译码器可在qp小于阈值的情况下选择第一模板以用于确定用于对cu的tu的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数,且可在qp大于阈值的情况下选择第二不同模板。
在另一实例中,模板的选择可基于cg的位置或相对于tu和/或变换单元大小的系数等级的位置。举例来说,视频译码器可选择第一模板以用于确定用于对cu的tu的cg的底部行的系数的coeff_abs_level_remaining语法元素进行译码的莱斯参数,且可选择第二不同模板用于tu的每一其它cg。
如上文所指出,在hevc中使用的基于回顾的导出方法中,如果用于当前系数等级的abscoefflevel值大于3*2k,那么视频译码器将k更新为等于k+1和4中的较小者,无论是那一者。如果当前系数等级的abscoefflevel值不大于3*2k,那么视频译码器不更新k。根据本发明的实例技术,在基于回顾的导出方法中,并非使用绝对值(abscoefflevel)来计算莱斯参数,使用待译码的coeff_abs_level_remaining语法元素的值(等于如等式(1)中定义的(abscoefflevel-baselevel))。因此,在此实例中,如果用于当前系数等级的coeff_abs_level_remaining语法元素的值大于3*2k,那么视频译码器将k更新为等于k+1和4中的较小者,无论是那一者。如果当前系数等级的abscoefflevel值不大于3*2k,那么视频译码器不更新k。在此实例中,视频译码器可随后使用k的所得值作为用于对当前系数等级的coeff_abs_level_remaining语法元素进行译码的莱斯参数。
举例来说,视频译码器可确定用于先前系数的等级剩余值(例如,coeff_abs_level_remaining),所述等级剩余值等于第一值与第二值之间的差,所述第一值在先前系数的绝对值之间,所述第二值等于第一旗标(例如,significant_flag)、第二旗标(例如,coeff_abs_level_greater1_flag)和第三旗标(例如,coeff_abs_level_greater2_flag)的总和。第一旗标指示先前系数是否为非零,第二旗标指示先前系数是否大于1,且第三旗标指示先前系数是否大于2。在此实例中,视频译码器可基于用于先前系数的等级剩余值而确定是否修改莱斯参数。此外,在此实例中,视频译码器可使用莱斯参数以对用于当前系数的剩余值的绝对等级的码字进行解码。
如上文所指出,在hevc范围扩展中使用的基于统计的导出方法中,statcoeff值在当前系数等级的abscoefflevel大于或等于(3*(1<<(statcoeff/4)))的情况下递增,且在((2*abscoefflevel)<(1<<(statcoeff/4)))的情况下递减。根据本发明的实例技术,在基于统计的导出方法中,并非使用绝对值(abscoefflevel)来更新统计statcoeff,使用待译码的coeff_abs_level_remaining语法元素(其等于如等式(1)中定义的(abscoefflevel-baselevel))。因此,在此实例中,如果当前系数等级的coeff_abs_level_remaining语法元素大于或等于(3*(1<<(statcoeff/4))),且在((2*coeff_abs_level_remaining)<(1<<(statcoeff/4)))的情况下递减。在此实例中,视频译码器可将k设定为等于最大莱斯参数和(statcoeff/4)中的较小者,无论是哪一者。在此实例中,视频译码器可随后使用k作为用于对当前系数等级的coeff_abs_level_remaining语法元素进行译码的莱斯参数。
举例来说,根据此实例,视频译码器可确定用于先前系数的等级剩余值(例如,coeff_abs_leve_remaining),所述等级剩余值等于第一值与第二值之间的差,所述第一值在先前系数的绝对值(例如,abscoefflevel)之间,所述第二值(例如,baselevel)等于第一旗标(例如,significant_flag)、第二旗标(例如,coeff_abs_level_greater1_flag)和第三旗标(例如,coeff_abs_level_greater2_flag)的总和。第一旗标指示先前系数是否为非零,所述第二值指示先前系数是否大于1,且第三旗标指示先前系数是否大于2。在此实例中,视频译码器可基于等级剩余值而更新统计。另外,在此实例中,视频译码器可基于所述统计而确定莱斯参数。此外,在此实例中,视频译码器可使用莱斯参数以对用于当前系数的剩余值的绝对等级的码字进行解码。
根据本发明的实例技术,在上文所提及的三个方法(即,基于模板、基于回顾和基于统计的方法)中的任一者中,用于莱斯码以及莱斯码加指数-哥伦布码的切换点可以设定成等于(m<<k),其中m也取决于k,但对于不同k值可为不同的。在一个实例中,对于等于0、1、2的k,m分别设定成6、5、6。在此实例中,对于其它k值,m设定成3。在另一实例中,当k小于3时,m设定成6,且对于其它k值,m设定成3。
举例来说,在此实例中,视频译码器可确定切换点为m<<k,其中m等于1<<k且k是码字的余数部分中的位的数目。在此实例中,视频译码器可基于切换点而选择莱斯译码方法或指数-哥伦布译码方法。另外,在此实例中,视频译码器可使用选定译码方法以对用于当前系数的剩余值的绝对等级的码字进行解码。
根据本发明的实例技术,用于莱斯参数的导出方法可进一步取决于输入视频的位深度或内部编解码器位深度。在一个实例中,当位深度等于8时,应用基于模板的方法,且当位深度大于8,例如为10或12时,应用基于统计的方法。
因此,根据此实例,视频译码器可基于输入视频的位深度或基于内部编解码器位深度而确定莱斯参数。在此实例中,视频译码器可使用莱斯参数以对用于当前系数的剩余值的绝对等级的码字进行解码。
根据本发明的实例技术,有损或无损译码可使用不同方法以导出莱斯参数。举例来说,视频译码器可在块是使用有损译码经编码的情况下使用基于模板的导出方法,且可在所述块是使用无损译码经编码的情况下使用基于统计的导出方法。在另一实例中,视频译码器可在块是使用有损译码经编码的情况下使用基于统计的导出方法,且可在所述块是使用无损译码经编码的情况下使用基于模板的导出方法。
因此,根据此实例,视频译码器可取决于是使用有损还是无损译码而使用不同方法导出莱斯参数。此外,在此实例中,视频译码器可使用莱斯参数以对用于当前系数的剩余值的绝对等级的码字进行解码。
替代地,在一些实例中,根据当前tu的量化参数(qp)值可以应用不同方法以导出莱斯参数。举例来说,视频译码器可在当前tu的qp值大于阈值的情况下使用基于模板的导出方法,且可在当前tu的qp值小于阈值的情况下使用基于统计的导出方法。在另一实例中,视频译码器可在当前cu的qp值大于阈值的情况下使用基于统计的导出方法,且可在当前cu的qp值小于阈值的情况下使用基于模板的导出方法。
如上文所指出,在一些实例中,视频译码器使用莱斯码用于具有较小值的coeff_abs_level_remaining语法元素且使用指数-哥伦布码用于具有较大值的coeff_abs_level_remaining语法元素。莱斯码和指数-哥伦布码都是使用参数k而确定。根据本发明的实例技术,以上方法可用以确定莱斯码和指数-哥伦布码两者的阶。举例来说,视频译码器可使用以上提供的实例中的任一者用于确定用于对特定系数等级的coeff_abs_level_remaining语法元素进行译码的值k,且使用所确定的k值用于确定用于特定系数等级的coeff_abs_level_remaining语法元素的k阶莱斯码或k阶指数-哥伦布码。替代地,在一些实例中,本发明中描述的方法仅用以确定莱斯码或指数-哥伦布码的阶。换句话说,在此类实例中,视频译码器可使用本发明中提供的实例用于确定参数k的值以仅用于确定k阶莱斯码;或者视频译码器可使用本发明中提供的实例用于确定参数k的值以仅用于确定k阶指数-哥伦布码。
根据本发明的实例技术,替代地,在一些实例中,以上方法可应用于其它种类的二进制化方法以用于对需要阶的确定的系数等级进行译码,例如k阶eg码。
根据本发明的实例技术,替代地,以上方法也可以应用于在改变或不改变模板的情况下应用k阶二进制化方法的其它语法元素。在一个实例中,运动向量差的译码可使用以上方法。经帧间译码块是根据指向形成预测性块的参考样本块的运动向量及指示经译码块与预测性块之间的差的残余数据编码的。并非直接用信号表示运动向量,视频编码器可识别运动向量候选者的集合,其可指定块的空间或时间相邻者的运动参数。视频编码器可用信号表示运动向量候选者集合中的选定运动向量候选者的索引,且用信号表示选定运动向量候选者的运动向量与块的运动向量之间的差。用信号表示的差可被称为“运动向量差”(mvd)。类似于hevc中用于用信号表示系数等级的方法,hevc中针对水平尺寸x和垂直尺寸y中的每一者可使用abs_mvd_greater0_flag语法元素、abs_mvd_greater1_flag语法元素、abs_mvd_minus2语法元素和mvd_sign_flag语法元素来用信号表示mvd。如hevc规范的子条款7.4.9.9中指示,abs_mvd_minus2[compidx]加2指定运动向量分量差的绝对值。hevc规范的表9-38指示abs_mvd_minus2是使用1阶指数-哥伦布码而二进制化。然而,根据本发明的实例,用以将abs_mvd_minus2语法元素(或用于用信号表示mvd的其它语法元素)二进制化的指数-哥伦布码的莱斯的阶k可以使用本发明中在别处提供的实例中的任一者来确定。
根据本发明的使用基于模板的莱斯参数导出方法的实例,定义函数sum_template(k)以返回模板中其量值大于k的系数的数目,为:
sum_template(k)=∑δj(xi,k)
其中
此外,在此实例中,定义函数f(x,y,n,t)以处置位置信息,且δk(u,v)经定义以处置分量信息,如下:
图4中描绘模板。当前变换系数标记为‘x’且其五个空间相邻者被标记为‘xi’(其中i为0到4)。如果满足以下两个条件中的一者,那么将xi标记为不可用且不用于上下文索引导出过程:
-xi和当前变换系数x的位置不位于同一变换单元中;
-xi的位置位于图片水平或垂直边界之外
-变换系数xi尚未经译码/解码。
根据本发明的一些技术,视频译码器可针对系数等级的significant_flag语法元素(bin0)执行上下文选择。为了执行上下文选择,视频译码器可确定或另外计算识别选定上下文的上下文索引。根据一个此类实例,用于bin0的上下文索引计算定义如下:
-对于bin0,上下文索引导出为:
c0=min(sum_template(0),5)+f(x,y,6,2)+δk(f(x,y,6,5),cidx)
c0=c0+offset(cidx,width)
其中
在以上等式中,在添加偏移之前,c0是用于bin0的上下文索引,且c0可从0到17变动。在添加偏移之后,c0可从0到53变动。此外,在以上等式中,值sum_template如上文所描述确定,即,sum_template(k)=∑δj(xi,k)其中
在一些实例中,基于c0的范围,明度上下文的一个集合包含numberlumactxoneset,即18个上下文模型。用于对明度bin0进行译码的不同变换大小(其中变换宽度由‘w’表示)可选择其自身的集合。举例来说,视频译码器可使用用于对bin0进行译码的第一上下文集合用于第一大小的变换块中的明度样本,且可使用用于对bin0进行译码的第二不同上下文集合用于第二不同大小的变换块中的明度样本。
另外,可分离色度和明度上下文以进一步改善译码性能。举例来说,对于ycbcr输入,可表示三个颜色分量(即,y、cb及cr),其中分量索引v分别等于0、1和2。因此,在此实例中,视频译码器可选择译码上下文以用于像素的明度样本的bin0的算术译码,且选择不同译码上下文用于同一像素的色度样本的bin0的算术译码。
此外,在一些实例中,视频译码器可选择系数等级的bin1(例如,coeff_abs_level_greater1_flag)和bin2(例如,coeff_abs_level_greater2_flag)的算术译码的上下文。举例来说,对于bin1,上下文索引(c1)导出为:
c1=min(sum_template(1),4)+n
c1=c1+δk(f(x,y,5,3),cidx)+δk(f(x,y,5,10),cidx)
对于bin2,上下文索引(c2)导出为:
c2=min(sum_template(2),4)+n
c2=c2+δk(f(x,y,5,3),cidx)+δk(f(x,y,5,10),cidx)
在以上等式中,n等于1且f(x,y,n,t)如上文定义(即,
如上文所指出,视频译码器可以莱斯码或当存在时以指数-哥伦布码将用于系数等级的剩余二进位(例如,coeff_abs_level_remaining语法元素)二进制化。根据此实例,视频译码器可使用基于统计的莱斯参数导出方法和基于模板的莱斯参数导出方法两者对信号tu的系数等级进行译码。更具体地说,在此实例中,视频译码器使用基于统计的莱斯参数导出方法和基于模板的莱斯参数导出方法两者对信号tu的系数等级的剩余二进位进行译码。在此实例中,以下规则应用于决定莱斯码或指数-哥伦布码的莱斯参数阶k。
■在对一个变换单元进行解码之前,将变量prevk设定为0
■如果其为待解码的第一值,那么将变量ktemp设定成criceparastatistics。换句话说,如果正译码的coeff_abs_level_remaining语法元素是待译码的变换单元的第一coeff_abs_level_remaining语法元素,那么将变量ktemp设定成criceparastatistics
■否则(其不是待解码的第一值),将变量ktemp设定成criceparatemplate
■将k设定为等于max(prevk,ktemp)
■更新prevk:prevk=k-m
因此,在此实例中,视频译码器可将基于统计的莱斯参数导出方法应用于tu的第一coeff_abs_level_remaining语法元素,且可将基于模板的莱斯参数导出方法应用于tu的每一后续coeff_abs_level_remaining语法元素。在一个实例中,m设定成1。在另一实例中,m设定成0。此外,在先前段落中描述的实例的一些情况下,criceparastatistics的导出过程与用于确定criceparam的过程相同,如本发明中在别处所描述。在先前段落中描述的实例的一些情况下,criceparatemplate的导出过程按次序遵循以下步骤:
-遵循等式(7)中使用的方式计算sum_absolute_levelminus1(即,sum_absolute_levelminus1=∑δj(xi)其中
-将uival设定为等于sum_absolute_levelminus1
-使用以下伪代码选择k:
因此,在此实例中,视频译码器将k设定为最大所允许阶或iorder的最小非负值中的较小者,无论是哪一者,其中(1<<(iorder+3))>(uival+4)。在一个实例中,max_gr_order_residual设定成10。在另一实例中,max_gr_order_residual设定成12。
替代地或此外,等式(7)可以如下修改:
sum_absolute_level=∑|xi|
sum_absolute_levelminus1=∑δj(xi)(7)
其中
在一个实例中,在以上等式(7)中,m设定成等于输入/内部位深度减去8。替代地,在以上等式(7)中,m设定成0。替代地,m的值取决于有损/无损译码模式,和/或输入/内部位深度和/或帧内/帧间译码模式,和/或来自经先前译码信息的用信号表示的值或导出值。在一个实例中,offset设定成(1<<(m-1))。替代地,在一些实例中,offset设定成0。替代地,函数δj(x)定义为:
在一些实例中,sp(k)是返回用于确定切换点的值(即如下的值,高于所述值时将使用指数-哥伦布码而不是莱斯码)的函数。在一个实例中,sp(0)=sp(2)=6,sp(1)=5,且对于k的其它值,sp(k)等于3。替代地此外,在基于统计的导出方法中考虑sp(k)用于等式(5)和(6)。在一些实例中,coeff_abs_level_remaining语法元素的二进制化被定义为:
-如果coeff_abs_level_remaining语法元素小于(sp(k)<<k),那么应用k阶莱斯码;
-否则(coeff_abs_level_remaining等于或大于(sp(k)<<k)),那么前缀和后缀用作码字,且前缀是sp(k)数目个‘1’,且后缀是k阶指数-哥伦布码。
表1.等于m的coeffabslevelremaining的码字
在以上表中,*表示sp(k)个‘1’值。举例来说,如果sp(k)是6,那么*表示六个连续的1。
图5是说明可实施本发明的技术的实例视频编码器20的框图。图5是出于解释的目的而提供,且不应被视为将技术限制为本发明中所大致例示及描述者。出于解释的目的,本发明在hevc译码的上下文中描述视频编码器20。然而,本发明的技术可以适用于其它译码标准或方法。
在图5的实例中,视频编码器20包含预测处理单元100、视频数据存储器101、残余产生单元102、变换处理单元104、量化单元106、逆量化单元108、逆变换处理单元110、重构单元112、滤波器单元114、经解码图片缓冲器116和熵编码单元118。预测处理单元100包含帧间预测处理单元120及帧内预测处理单元126。帧间预测处理单元120包含运动估计单元及运动补偿单元(未图示)。在其它实例中,视频编码器20可包含更多、更少或不同功能组件。
视频数据存储器101可存储待由视频编码器20的组件编码的视频数据。可(例如)从视频源18获得存储在视频数据存储器101中的视频数据。经解码图片缓冲器116可为存储供用于由视频编码器20以例如帧内或帧间译码模式编码视频数据的参考视频数据的参考图片存储器。视频数据存储器101及经解码图片缓冲器116可由多种存储器装置中的任一者形成,例如动态随机存取存储器(dram),包含同步dram(sdram)、磁阻式ram(mram)、电阻性ram(rram)或其它类型的存储器装置。视频数据存储器101及经解码图片缓冲器116可由相同存储器装置或单独存储器装置提供。在各种实例中,视频数据存储器101可与视频编码器20的其它组件一起在芯片上,或相对于那些组件在芯片外。
视频编码器20接收视频数据。视频编码器20可对视频数据的图片的切片中的每个ctu进行编码。ctu中的每一者可以与图片的大小相等的明度译码树块(ctb)以及对应的ctb相关联。作为对ctu进行编码的一部分,预测处理单元100可执行四分树分割以将ctu的ctb划分为逐渐更小的块。这些更小的块可以是cu的译码块。例如,预测处理单元100可将与ctu相关联的ctb分割成四个大小相等的子块,将子块中的一或多者分割成四个大小相等的子子块等。
视频编码器20可对ctu的cu进行编码以产生cu的经编码表示(即,经译码的cu)。作为对cu进行编码的部分,预测处理单元100可在cu的一或多个pu当中分割与cu相关联的译码块。因此,每一pu可与明度预测块和对应的色度预测块相关联。视频编码器20和视频解码器30可支持具有各种大小的pu。cu的大小可指cu的明度译码块的大小并且pu的大小可指pu的明度预测块的大小。假定特定cu的大小为2nx2n,视频编码器20及视频解码器30可支持用于帧内预测的2nx2n或nxn的pu大小,及用于帧间预测的2nx2n、2nxn、nx2n、nxn或类似大小的对称pu大小。视频编码器20和视频解码器30还可支持用于帧间预测的2nxnu、2nxnd、nlx2n和nrx2n的pu大小的不对称分割。
帧间预测处理单元120可通过对cu的每个pu执行帧间预测来产生用于pu的预测性数据。pu的预测性数据可包含pu的预测性块和pu的运动信息。帧间预测处理单元120可根据pu是否在i切片、p切片或b切片中而对cu的pu执行不同操作。在i切片中,所有pu都是经帧内预测。因此,如果pu是在i切片中,那么帧间预测处理单元120不对pu执行帧间预测。因此,对于在i模式中编码的块,使用来自同一帧内的经先前编码的相邻块的空间预测而形成经预测块。如果pu在p切片中,那么帧间预测处理单元120可使用单向帧间预测以产生pu的预测性块。
帧内预测处理单元126可通过对pu执行帧内预测而产生pu的预测性数据。pu的预测性数据可包含pu的预测性块及各种语法元素。帧内预测处理单元126可对i切片、p切片和b切片中的pu执行帧内预测。
为了对pu执行帧内预测,帧内预测处理单元126可使用多个帧内预测模式产生pu的预测性数据的多个集合。帧内预测处理单元126可使用来自相邻pu的样本块的样本来产生用于pu的预测性块。假定对于pu、cu及ctu采用从左到右、从上到下的编码次序,相邻pu可以在所述pu的上方、右上方、左上方或左方。帧内预测处理单元126可使用各种数目的帧内预测模式,例如,33个定向帧内预测模式。在一些实例中,帧内预测模式的数目可以取决于与pu相关联的区域的大小。
预测处理单元100可从pu的由帧间预测处理单元120产生的预测性数据或pu的由帧内预测处理单元126产生的预测性数据当中选择cu的pu的预测性数据。在一些实例中,预测处理单元100基于预测性数据集合的速率/失真量度选择cu的pu的预测性数据。所选预测性数据的预测性块在本文中可被称作所选预测性块。
残余产生单元102可基于用于cu的译码块(例如,明度、cb和cr译码块)和用于cu的pu的选定预测性块(例如,预测性明度、cb和cr块)而产生用于cu的残余块(例如,明度、cb和cr残余块)。举例来说,残余产生单元102可产生cu的残余块以使得残余块中的每一样本具有等于cu的译码块中的样本与cu的pu的对应选定预测性块中的对应样本之间的差的值。
变换处理单元104可执行四叉树分割以将与cu相关联的残余块分割为与cu的tu相关联的变换块。因此,tu可与明度变换块及两个色度变换块相关联。cu的tu的明度变换块以及色度变换块的大小和位置可以或可不基于cu的pu的预测块的大小和位置。被称为“残余四叉树”(rqt)的四叉树结构可包含与区域中的每一者相关联的节点。cu的tu可以对应于rqt的叶节点。
变换处理单元104可以通过将一或多个变换应用到tu的变换块而产生用于cu的每一tu的变换系数块。变换处理单元104可以将各种变换应用到与tu相关联的变换块。例如,变换处理单元104可以将离散余弦变换(dct)、定向变换或概念上类似的变换应用于变换块。在一些实例中,变换处理单元104并不将变换应用于变换块。在此类实例中,变换块可被视作变换系数块。
量化单元106可量化系数块中的变换系数。量化过程可减少与变换系数中的一些或全部相关联的位深度。举例来说,n位变换系数可在量化期间舍入到m位变换系数,其中n大于m。量化单元106可基于与cu相关联的量化参数(qp)值量化与cu的tu相关联的系数块。视频编码器20可通过调整与cu相关联的qp值来调整应用于与cu相关联的系数块的量化程度。量化可导致信息的损耗,因此经量化变换系数可具有比原始变换系数更低的精度。
逆量化单元108和逆变换处理单元110可分别将逆量化和逆变换应用于系数块,以由所述系数块重构残余块。重构单元112可将经重构的残余块添加到来自由预测处理单元100产生的一或多个预测性块的对应样本,以产生与tu相关联的经重构变换块。通过以此方式重构用于cu的每一tu的变换块,视频编码器20可重构cu的译码块。
滤波器单元114可执行一或多个去块操作来减少与cu相关联的译码块中的成块效应。在滤波器单元114对经重构译码块执行一或多个去块操作之后,经解码图片缓冲器116可存储经重构译码块。帧间预测处理单元120可使用含有经重构译码块的参考图片来对其它图片的pu执行帧间预测。另外,帧内预测处理单元126可以使用经解码图片缓冲器116中的经重构的译码块以对处于与cu相同的图片中的其它pu执行帧内预测。
熵编码单元118可以从视频编码器20的其它功能组件接收数据。例如,熵编码单元118可以从量化单元106接收系数块,并且可以从预测处理单元100接收语法元素。熵编码单元118可以对数据执行一或多个熵编码操作以产生经熵编码的数据。例如,熵编码单元118可以对数据执行上下文自适应可变长度译码(cavlc)操作、cabac操作、可变到可变(v2v)长度译码操作、基于语法的上下文自适应二进制算术译码(sbac)操作、概率区间分割熵(pipe)译码操作、指数-哥伦布编码操作或另一类型的熵编码操作。视频编码器20可输出包含由熵编码单元118产生的经熵编码的数据的位流。举例来说,位流可包含表示用于cu的rqt的数据。
熵编码单元118可经配置以执行本发明中所提议的技术。举例来说,熵编码单元118可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对图片的当前cu的单个tu的系数等级进行编码。在此实例中,第一莱斯参数导出方法可为基于统计的导出方法且第二莱斯参数导出方法可为基于模板的导出方法。在此实例中,作为使用第一或第二莱斯参数导出方法对系数等级进行编码的部分,熵编码单元118可将与系数等级相关联的语法元素(例如,coeff_abs_level_remaining语法元素)二进制化为k阶莱斯或指数-哥伦布码字,其中k是使用第一或第二莱斯参数导出方法而确定。此外,在此实例中,熵编码单元118可对码字执行算术编码。
图6是说明经配置以实施本发明的技术的实例视频解码器30的框图。图6是出于解释的目的而提供,且并不将技术限制为本发明中所大致例示和描述者。出于解释的目的,本公开在hevc译码的上下文中描述视频解码器30。然而,本发明的技术可以适用于其它译码标准或方法。
在图6的实例中,视频解码器30包含熵解码单元150、视频数据存储器151、预测处理单元152、逆量化单元154、逆变换处理单元156、重构单元158、滤波器单元160和经解码图片缓冲器162。预测处理单元152包含运动补偿单元164和帧内预测处理单元166。在其它实例中,视频解码器30可包含更多、更少或不同的功能组件。
视频数据存储器151可存储待由视频解码器30的组件解码的视频数据,例如经编码视频位流。存储于视频数据存储器151中的视频数据可例如从信道16获得,例如从例如相机等本地视频源、经由视频数据的有线或无线网络通信或通过存取物理数据存储媒体。视频数据存储器151可形成存储来自经编码视频位流的经编码视频数据的经译码图片缓冲器(cpb)。经解码图片缓冲器162可为存储供用于由视频解码器30以例如帧内或帧间译码模式解码视频数据的参考视频数据的参考图片存储器。视频数据存储器151及经解码图片缓冲器162可由多种存储器装置中的任一者形成,例如动态随机存取存储器(dram),包含同步dram(sdram)、磁阻式ram(mram)、电阻性ram(rram)或其它类型的存储器装置。视频数据存储器151和经解码图片缓冲器162可由相同存储器装置或单独的存储器装置提供。在各种实例中,视频数据存储器151可与视频解码器30的其它组件一起在芯片上,或相对于那些组件在芯片外。
视频数据存储器151接收且存储位流的经编码视频数据(例如,nal单元)。熵解码单元150可从cpb接收经编码视频数据(例如,nal单元)且剖析nal单元以获得语法元素。熵解码单元150可对nal单元中的经熵编码语法元素进行熵解码。预测处理单元152、逆量化单元154、逆变换处理单元156、重构单元158以及滤波器单元160可以基于从位流提取的语法元素来产生经解码的视频数据。熵解码单元150可执行与熵编码单元118的过程大体上互逆的过程。
作为对位流进行解码的部分,熵解码单元150可从经译码切片nal单元提取语法元素且对所述语法元素进行熵解码。经译码切片中的每一者可包含切片标头及切片数据。切片标头可以含有关于切片的语法元素。熵编码单元118可经配置以执行本发明中所提议的技术。
熵解码单元150可执行本发明的各种实例的至少部分。举例来说,熵解码单元150可将例如coeff_abs_level_remaining语法元素等经二进制化语法元素去二进制化。作为将经二进制化语法元素去二进制化的部分,熵解码单元150可以本发明中在别处提供的实例中描述的方式确定莱斯参数。举例来说,根据本发明的一个实例,熵解码单元150可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对图片的当前cu的单个tu的系数等级进行解码,其中第一莱斯参数导出方法是基于统计的导出方法,且第二莱斯参数导出方法是基于模板的导出方法。
在此实例中,作为使用第一或第二莱斯参数导出方法对系数等级进行解码的部分,熵解码单元150可执行算术解码以恢复用于与系数等级相关联的语法元素(例如,coeff_abs_level_remaining语法元素)的码字。在此实例中,熵解码单元150可将码字解译为k阶莱斯或指数-哥伦布码字,其中k是使用第一或第二莱斯参数导出方法而确定。此外,在此实例中,熵解码单元150可通过将莱斯或指数-哥伦布码字转换回到未经编码数字而将所述码字去二进制化。
除了获得来自位流的语法元素之外,视频解码器30可对未分割的cu执行重构操作。为了对cu执行重构操作,视频解码器30可对cu的每一tu执行重构操作。通过对cu的每一tu执行重构操作,视频解码器30可重构cu的残余块。
作为对cu的tu执行重构操作的部分,逆量化单元154可逆量化(即,解量化)与tu相关联的系数块。逆量化单元154可使用与tu的cu相关联的qp值来确定量化的程度,且同样地确定逆量化单元154将应用的逆量化的程度。即,可通过调整当量化变换系数时使用的qp的值而控制压缩比,即,用以表示原始序列和经压缩序列的位数目的比率。压缩比还可取决于所使用的熵译码的方法。
在逆量化单元154逆量化系数块之后,逆变换处理单元156可将一或多个逆变换应用于系数块以便产生与tu相关联的残余块。例如,逆变换处理单元156可以将逆dct、逆整数变换、逆卡忽南-拉维(karhunen-loeve)变换(klt)、逆旋转变换、逆定向变换或另一逆变换应用于系数块。
如果使用帧内预测对pu进行编码,那么帧内预测处理单元166可执行帧内预测以产生pu的预测性块。帧内预测处理单元166可使用帧内预测模式以基于样本空间相邻块产生pu的预测性块。帧内预测处理单元166可基于从位流获得的一或多个语法元素确定用于pu的帧内预测模式。
如果pu是使用帧间预测经编码,那么熵解码单元150可确定所述pu的运动信息。运动补偿单元164可基于pu的运动信息来确定一或多个参考块。运动补偿单元164可基于所述一或多个参考块产生pu的预测性块(例如,预测性明度、cb和cr块)。
预测处理单元152可以基于从位流提取的语法元素构造第一参考图片列表(refpiclist0)以及第二参考图片列表(refpiclist1)。此外,如果使用帧间预测对pu进行编码,则熵解码单元150可以提取用于pu的运动信息。运动补偿单元164可基于pu的运动信息来确定用于pu的一个或一个以上参考区。运动补偿单元164可以基于在pu的一或多个参考块处的样本块产生pu的预测性明度块、cb块以及cr块。
重构单元158可使用cu的tu的变换块(例如,明度、cb和cr变换块)以及cu的pu的预测性块(例如,明度、cb和cr块)(即,在适用时,帧内预测数据或帧间预测数据)来重构cu的译码块(例如,明度、cb和cr译码块)。举例来说,重构单元158可将变换块(例如,明度、cb及cr变换块)的样本添加到预测性块(例如,明度、cb及cr预测性块)的对应样本以重构cu的译码块(例如,明度、cb及cr译码块)。
滤波器单元160可执行解块操作以减少与cu的译码块相关联的成块假象。视频解码器30可将cu的译码块存储在经解码图片缓冲器162中。经解码图片缓冲器162可提供参考图片以用于后续运动补偿、帧内预测及在显示装置(例如图1的显示装置32)上的呈现。举例来说,视频解码器30可基于经解码图片缓冲器162中的块对其它cu的pu执行帧内预测或帧间预测操作。
图7是说明根据本发明的技术用于对视频数据进行编码的实例操作的流程图。图7类似于本发明的其它流程图是作为实例而提供。其它实例可包含更多、更少或不同动作,或者动作可以不同次序执行。
在图7的实例中,视频编码器20产生视频数据的图片的cu的残余块(200)。残余块中的每一样本可指示cu的pu的预测性块中的样本与cu的译码块中的对应样本之间的差。此外,视频编码器20可将cu的残余块分解为一或多个变换块(202)。cu的tu包括所述一或多个变换块中的变换块。在一些实例中,视频编码器20可使用四叉树分割将cu的残余块分解为一或多个变换块。此外,在一些实例中,视频编码器20将一或多个变换应用于tu的变换块以产生包括tu的系数等级的用于tu的系数块(204)。举例来说,视频编码器20可将离散余弦变换(dct)应用于变换块。在其它实例中,视频编码器20跳过变换的应用。因此,tu的系数等级可为残余值。
另外,视频编码器20可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对tu的系数等级进行编码(206)。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。
图8是说明根据本发明的技术用于对视频数据进行解码的实例操作的流程图。在图8的实例中,视频解码器30使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对图片的当前cu的单个tu的系数等级进行解码(250)。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。此外,在此实例中,视频解码器30可通过将当前cu的一或多个预测单元的样本添加到tu的变换块的对应样本而重构当前cu的译码块(252)。举例来说,视频解码器30可使用帧内预测或帧间预测以确定当前cu的一或多个pu的预测性块。另外,视频解码器30可将逆变换应用于当前cu的tu的系数等级以确定当前cu的tu的变换块的样本。在一些实例中,视频解码器30可在应用逆变换之前逆量化变换块的样本。
图9是说明根据本发明的技术用于对视频数据进行解码的实例操作的流程图。在图9的实例中,视频解码器30可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对图片的当前cu的单个tu的系数等级进行解码(300)。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。此外,视频解码器30可逆量化tu的系数等级(302)。另外,视频解码器30可将逆变换应用于tu的系数等级以重构tu的变换块(304)。视频解码器30可通过将当前cu的一或多个预测单元的样本添加到tu的变换块的对应样本而重构当前cu的译码块(306)。举例来说,视频解码器30可使用帧内预测或帧间预测以确定当前cu的一或多个pu的预测性块。另外,视频解码器30可将逆变换应用于当前cu的tu的系数等级以确定当前cu的tu的变换块的样本。在一些实例中,视频解码器30可在应用逆变换之前逆量化变换块的样本。
图10是说明根据本发明的技术用于对视频数据进行译码的实例操作的流程图。图10的操作可用作图7到9的实例操作的部分。
在图10的实例中,视频译码器获得(例如,如果视频译码器是视频解码器,例如视频解码器30)或产生(例如,如果视频译码器是视频编码器,例如视频编码器20)一系列语法元素(350)。所述系列语法元素中的每一相应语法元素指示tu的相应系数等级的绝对值的相应剩余值。一般来说,产生语法元素可包括确定语法元素的值且将语法元素的值存储于计算机可读存储媒体中。此外,在图10的实例中,作为使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对单个tu的系数等级进行解码(例如,在图7的动作204、图8的动作250和图9的动作300中)的部分,视频译码器可将第一莱斯参数导出方法应用于按解码或剖析次序在tu中首先出现的语法元素,其中所述语法元素在所述系列语法元素中(352)。一般来说,剖析次序是其中过程从经译码二进制位流设定语法值的次序。
另外,作为使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对单个tu的系数等级进行解码(例如,在图7的动作204、图8的动作250和图9的动作300中)的部分,视频译码器可将第二莱斯参数导出方法应用于所述系列语法元素中的每一其它语法元素(354)。在一些实例中,作为将第二莱斯参数导出方法应用于所述系列语法元素中的每一其它语法元素的部分,视频译码器可使用函数以确定用于对tu的当前系数的系数等级进行译码的莱斯参数值(356)。所述函数的输入可包含所记录值和当前导出的莱斯参数值。所记录值可基于用以对在当前系数之前的系数进行解码的莱斯参数值。此外,当前导出的莱斯参数值可使用基于模板的导出方法而导出。所述函数可为最大值函数。
图11是说明根据本发明的技术其中使用基于统计的导出方法的实例操作的流程图。例如视频编码器20或视频解码器30等视频译码器可执行图11的操作作为执行图7到9中的任一者的操作的部分。在图11的实例中,当前图片包括多个4x4子块,且视频译码器经配置以获得(例如,如果视频译码器是视频解码器,例如视频解码器30)或产生(例如,如果视频译码器是视频编码器,例如视频编码器20)指示当前图片的tu的系数等级的绝对值的相应剩余值的语法元素(400)。另外,如在本发明中在别处所论述,视频译码器可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对tu的系数等级进行解码。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。
作为使用第一莱斯参数导出方法(402)的部分,视频译码器可将当前图片的所述多个子块划分为多个类别以使得对于所述多个子块中的相应子块,基于所述相应子块是否为变换跳过块以及所述相应子块是否用于明度分量而将所述相应子块分类(404)。
另外,对于所述多个类别中的每一相应类别,视频译码器可维持相应类别的相应统计值(例如,statcoeff)(406)。在一些实例中,作为维持相应类别的相应统计值的部分,视频译码器可针对所述多个类别中的每一相应类别且针对属于相应类别的图片的每一相应子块,针对所述相应子块使用针对所述相应子块首先经译码的等级剩余语法元素更新用于相应类别的相应统计值至多一次。作为更新用于相应类别的相应统计值的部分,视频译码器可在(abscoefflevel>=3*(1<<(statcoeff/4)))的情况下递增用于相应类别的相应统计值,且在((2*abscoefflevel)<(1<<(statcoeff/4)))的情况下递减用于相应类别的相应统计值,其中abscoefflevel是相应子块的绝对系数等级且statcoeff是用于相应类别的相应统计值。
对于所述多个子块中的每一相应子块,视频译码器可使用所述相应子块属于的类别的相应统计值来初始化相应莱斯参数(408)。视频译码器可使用k阶莱斯码将语法元素二进制化,k是所确定的莱斯参数。在一些实例中,作为使用相应子块所属于的类别的相应统计值以初始化用于相应子块的相应莱斯参数的部分,针对所述多个子块中的每一相应子块,视频译码器可将用于相应子块的相应莱斯参数确定为最大莱斯参数以及相应子块所属于的类别的相应统计值除以4中的最小值。
图12是说明根据本发明的技术其中使用基于模板的导出方法的实例操作的流程图。例如视频编码器20或视频解码器30等视频译码器可执行图12的操作作为执行图7到9中的任一者的操作的部分。
在图12的实例中,当前图片包括多个4x4子块,局部模板覆盖当前图片的cu的tu的当前样本的相邻者,且当前样本处于当前扫描位置。在图12的实例中,例如视频编码器20或视频解码器30等视频译码器可获得(例如,如果视频译码器是视频解码器,例如视频解码器30)或产生(例如,如果视频译码器是视频编码器,例如视频编码器20)指示当前样本的相应系数等级的绝对值的相应剩余值的语法元素(例如,coeff_abs_level_remaining)(450)。
如在本发明中在别处所论述,视频译码器可使用第一莱斯参数导出方法和第二莱斯参数导出方法以用于对tu的系数等级进行解码。在此实例中,第一莱斯参数导出方法是基于统计的导出方法且第二莱斯参数导出方法是基于模板的导出方法。作为使用第二莱斯参数导出方法(452)的部分,视频译码器可针对由局部模板覆盖的每一相应相邻者确定用于相应相邻者的相应值(例如,δj(x))(454)。在此实例中,用于相应相邻的相应值在相邻者的绝对值大于0的情况下等于相邻者的绝对值减去1,且在相邻者等于0的情况下等于0。另外,视频译码器可确定等于相邻者的值的总和的总和值(例如,sum_absolute_levelminus1)(456)。此外,在图12的实例中,视频译码器可确定莱斯参数在所述总和值属于第一区间的情况下等于0,在所述总和值属于第二区间的情况下等于1,在所述总和值属于第三区间的情况下等于2,且在所述总和值属于第四区间的情况下等于3(458)。所述语法元素是使用k阶莱斯码二进制化,k等于所确定的莱斯参数。
图13是说明根据本发明的技术基于通用函数而确定莱斯参数的实例操作的流程图。图13的操作可以单独地使用或与本发明的其它实例结合使用。图13的操作可为执行本发明的其它流程图中描述的基于模板的莱斯参数导出过程的一种方式。
在图13的实例中,当前图片包括多个4x4子块,局部模板覆盖当前图片的cu的tu的当前样本的相邻者,且当前样本处于当前扫描位置。作为使用基于模板的莱斯参数导出方法的部分,视频译码器可针对由局部模板覆盖的每一相应相邻者确定用于相应相邻者的相应值(500)。用于相应相邻的相应值在相邻者的绝对值大于0的情况下等于相邻者的绝对值减去1,且在相邻者等于0的情况下等于0。此外,视频译码器可确定等于相邻者的值的总和的总和值(502)。另外,视频译码器可确定值k(504)。使用k阶莱斯码将tu的系数等级二进制化。举例来说,视频编码器20可将系数等级二进制化且视频解码器30可将系数等级去二进制化。
在此实例中,k的定义可选自由以下各项组成的群组:
·k被定义为满足(1<<(k+3))>(sum_absolute_levelminus1+m)的最小整数,其中m是整数且sum_absolute_levelminus1是总和值,
·k被定义为满足(1<<(k+3))>(sum_absolute_levelminus1+m)的最小整数,其中m是整数且sum_absolute_levelminus1是总和值,以及
·k被定义为满足(1<<(k+3))≥(sum_absolute_levelminus1+m)的最小整数,其中m是整数且sum_absolute_levelminus1是总和值。
图14是说明根据本发明的技术用于将一系列语法元素二进制化或去二进制化的实例操作的流程图。图14的操作可以单独地使用或与本发明的其它实例结合使用。在图14的实例中,视频译码器(例如,视频编码器20或视频解码器30)产生或获得一系列语法元素(例如,abs_coeff_level_remaining语法元素)(550)。在图14的实例中,所述系列语法元素中的每一相应语法元素可指示tu的相应系数等级的绝对值的相应剩余值。
此外,在图14的实例中,视频译码器可针对所述系列语法元素中的每一相应语法元素执行动作552到560(551)。在图14的实例中,视频译码器可使用第一莱斯参数导出方法(例如,基于统计的莱斯参数导出方法)或第二莱斯参数导出方法(例如,基于模板的莱斯参数导出方法)导出用于相应语法元素的莱斯参数k(552)。此外,视频译码器可将用于相应语法元素的切换点设定为等于(m<<k)(554)。m取决于k。举例来说,视频译码器可分别针对等于0、1和2的k值将m设定为等于6、5和6,且可针对k的所有其它值将m设定为3。
此外,在图14的实例中,视频译码器可确定相应语法元素是否小于切换点(556)。响应于确定相应语法元素小于切换点(556的“是”分支),视频译码器可使用k阶莱斯码将相应语法元素二进制化或去二进制化(558)。否则,如果相应语法元素不小于切换点(556的“否”分支),那么视频译码器可使用k阶指数-哥伦布码将相应语法元素二进制化或去二进制化(560)。
应理解,本文中描述的所有技术可个别地或组合地使用。应认识到,取决于实例,本文中所描述的技术中的任一者的某些动作或事件可用不同顺序来执行,可添加、合并或全部省略所述动作或事件(例如,实践所述技术未必需要所有所描述动作或事件)。此外,在某些实例中,可(例如)通过多线程处理、中断处理或多个处理器同时而非循序地执行动作或事件。另外,虽然为了清晰起见,本发明的某些方面被描述为由单一模块或单元执行,但是应理解,本发明的技术可由与视频译码器相关联的单元或模块的组合执行。
出于说明的目的已经相对于hevc标准而描述本发明的某些方面。然而,本发明中描述的技术可适用于其它视频译码过程,包含尚未开发的其它标准或专有视频译码过程。
上文所描述的技术可由视频编码器20(图1及5)和/或视频解码器30(图1及6)执行,其两者可大体上被称作视频译码器。同样地,在适用时,视频译码可指视频编码或视频解码。此外,虽然本发明已参考coeff_abs_level_remaining语法元素,但本发明的技术可以适用于与coeff_abs_level_remaining语法元素具有相同语义的不同命名的语法元素,或变换单元的其它语法元素。
虽然在上文描述所述技术的各种方面的特定组合,但提供这些组合只是为了说明本发明中描述的技术的实例。因此,本发明的技术不应限于这些实例组合且可涵盖本发明中描述的技术的各种方面的任何可设想的组合。
在一或多个实例中,所描述功能可以硬件、软件、固件或其任何组合来实施。如果用软件实施,则所述功能可以作为一或多个指令或代码在计算机可读媒体上存储或传输,并且由基于硬件的处理单元执行。计算机可读媒体可以包含计算机可读存储媒体,其对应于例如数据存储媒体或通信媒体等有形媒体,通信媒体(例如)根据通信协议包含促进将计算机程序从一处传送到另一处的任何媒体。以此方式,计算机可读媒体通常可对应于(1)非暂时性的有形计算机可读存储媒体,或(2)通信媒体,例如,信号或载波。数据存储媒体可以是可由一或多个计算机或者一或多个处理器存取以检索用于实施本发明中描述的技术的指令、代码和/或数据结构的任何可用媒体。计算机程序产品可包含计算机可读媒体。
借助于实例而非限制,此类计算机可读存储媒体可包括ram、rom、eeprom、cd-rom或其它光盘存储装置、磁盘存储装置或其它磁性存储装置、快闪存储器,或可用以存储呈指令或数据结构形式的所要程序代码且可由计算机存取的任何其它媒体。并且,适当地将任何连接称作计算机可读媒体。举例来说,如果使用同轴电缆、光纤缆线、双绞线、数字订户线(dsl)或例如红外线、无线电及微波等无线技术从网站、服务器或其它远程源传输指令,则同轴电缆、光纤缆线、双绞线、dsl或例如红外线、无线电及微波等无线技术包含在媒体的定义中。然而,应理解,计算机可读存储媒体和数据存储媒体并不包含连接、载波、信号或其它暂时性媒体,而实际上是针对非暂时性有形存储媒体。如本文中所使用,磁盘和光盘包含压缩光盘(cd)、激光光盘、光学光盘、数字多功能光盘(dvd)、软性磁盘及蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。以上各项的组合也应包含在计算机可读媒体的范围内。
指令可以由一或多个处理器执行,所述一或多个处理器例如是一或多个数字信号处理器(dsp)、通用微处理器、专用集成电路(asic)、现场可编程逻辑阵列(fpga)或其它等效的集成或离散逻辑电路。因此,如本文中所使用的术语“处理器”可指代上述结构或适用于实施本文中所描述的技术的任何其它结构中的任一者。另外,在一些方面中,本文中所描述的功能性可在经配置以用于编码和解码的专用硬件和/或软件模块内提供,或并入在组合编解码器中。并且,所述技术可完全实施于一或多个电路或逻辑元件中。
本发明的技术可在广泛多种装置或设备中实施,包含无线手持机、集成电路(ic)或一组ic(例如,芯片组)。本发明中描述各种组件、模块或单元是为了强调经配置以执行所揭示的技术的装置的功能方面,但未必需要通过不同硬件单元实现。确切地,如上文所描述,各种单元可结合合适的软件和/或固件组合在编解码器硬件单元中,或由互操作硬件单元的集合来提供,所述硬件单元包含如上文所描述的一或多个处理器。
描述了各种实例。这些和其它实例在所附权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!