提取和传播地理位置信息的制作方法
地理位置数据库基于在线用户的互联网协议(ip)地址和/或在线用户的用户简档来确定在线用户的位置。作为示例,当用户在计算机上的搜索引擎中搜索“天气”时,搜索引擎基于其ip地址或基于其用户简档中的信息来确定用户的地理位置。搜索引擎接着显示如基于ip地址或用户简档确定的地理位置的天气预报。搜索引擎可基于ip地址使用ip地理位置数据库来确定用户的位置。然而,ip地理位置数据库的准确度基于位置而变化。此外,地理位置数据库的使用也是非常昂贵的。
技术实现要素:
本文中公开了一种用于将地理位置分配给网站的新用户的地理位置提取和传播系统。地理位置提取和传播系统的实现基于网站的各种网页的内容以及被分配给与网站相关联的各种用户的地理位置来向网站分配地理位置。地理位置提取和传播系统通过响应于新用户点击网站的网页而将网站的地理位置分配给新用户来进一步将网站的地理位置传播给新用户。
提供本概述以便以简化的形式介绍以下在详细描述中进一步描述的概念的选集。本概述并不旨在标识所要求保护的主题的关键特征或必要特征,亦非旨在用于限制所要求保护的主题的范围。
本文中还描述和列举了其他实现。
附图说明
图1解说了用于提取和传播地理位置信息的系统的示例实现。
图2解说了用于通过网站点击传播用户位置的示例操作。
图3解说了用于通过用户点击传播网站位置的示例操作。
图4解说了用于从网页提取地理位置的示例操作。
图5解说了用于基于来自具有已知位置的用户的点击来确定网页的地理位置的示例操作。
图6解说了用于基于搜索引擎中的查询来确定地理位置的示例操作。
图7解说了用于基于web托管ip地址确定地理位置的示例操作。
图8解说了用于基于链接的网页的地理位置将地理位置分配给网页的示例操作。
图9解说了用于基于子页面的地理位置将地理位置分配给网页的示例操作。
图10解说了用于在具有区域和全球范围的网站之间消除歧义的示例操作。
图11解说了用于消除多个候选地理位置之间的歧义的示例操作。
图12解说了被用于消除多个候选地理位置之间的歧义的示例位置树。
图13解说了用于基于用户动作传播位置的示例操作。
图14解说了可有助于实现所描述的技术的示例系统。
具体实施方式
搜索引擎通常使用用户的位置来自定义页面上显示的结果。例如,对于查询“天气”,搜索引擎基于用户的位置上下文使用用户的位置来显示天气预报。确定用户位置的一种精确方式是使用诸如地理定位系统(gps)之类的定位系统。遗憾的是,该信息不适用于大多数用户,因为用户需要使用带有gps的设备,并且还需要授予搜索引擎对该信息的访问权。确定用户位置的另一种方法是要求用户将其自行报告。尽管这在短期内可能是准确的,但从长远来看,用户可能移动到另一位置而不更新经自行报告的位置。(贯穿本文档,术语地理位置指代要么互联网协议(ip)地址要么用户地理位置的地理位置。本文中所公开的技术涵盖ip地理位置和用户地理位置的两种情形,并且因此,ip级地理位置和用户级地理位置被互换地使用。类似地,贯穿本文档,术语“地理位置”和“位置”也被互换地使用。)
为了克服上述限制,用户的位置通过咨询ip地理位置数据库来确定。ip地理位置数据库可包含ip地址及其对应的位置的范围。当用户访问搜索引擎时,地理位置数据库被用来确定它们最有可能的地理位置。地理位置数据库的粒度各不相同,但它们可能降低到街坊或街道级别的粒度。然而,此类地理位置数据库的准确度基于地理区域而显著地变化。此外,对此类地理位置数据库的访问可能是昂贵的。
本文中所公开的技术提供了将地理位置分配给用户点击的若干方法。本文中所公开的一种方法描述了将具有已知位置的用户的地理信息传播给具有未知位置的用户或ip地址。该方法基于如下前提:如果具有已知位置的许多用户点击某个网站,则点击同一网站的位置未知的用户也可能与这些其他用户位于同一位置。此处所描述的另一种方法涉及提取网站次或子页面的文本中所提到的地理地址,以及将多个位置分配给网站的主页。随后,当具有未知位置的用户点击该网站的主页时,这样的用户被归到该网站的地理位置。
在本申请的上下文中,关于网站或网页的术语“用户点击”、“用户的点击”、“用户进行点击”、“用户所作的点击”等意味着将用户所作的多个各种动作包括在内。例如,此类动作包括用户选择网站的通用资源定位(url)(在浏览器中、在应用中、从移动应用等)、用户在搜索引擎中提交网站的查询、用户被重定向到网站、用户实际点击网页上的内容或链接等。因此,例如,如果用户已在浏览器上将www.seattle.com的书签保存为“西雅图(seattle)”,并且响应于用户选择该书签,www.seattle.com的主页被加载到用户的浏览器上,用户被视为已点击了www.seattle.com的主页。
类似地,如果用户提交查询并且查询结果之一是到www.seattle.com的链接,则用户选择该查询结果在本文中所公开的技术的上下文中被视为用户点击www.seattle.com。需要注意,对于被认为已点击了网页的用户,该用户不需要执行任何附加动作。因此,用户不需要已查看网页达任何特定时间量,用户不需要已向网页提供任何信息——无论是直接还是间接地经由任何cookie,用户不需要已从网页中选择任何内容、激活该网页上的任何链接等。
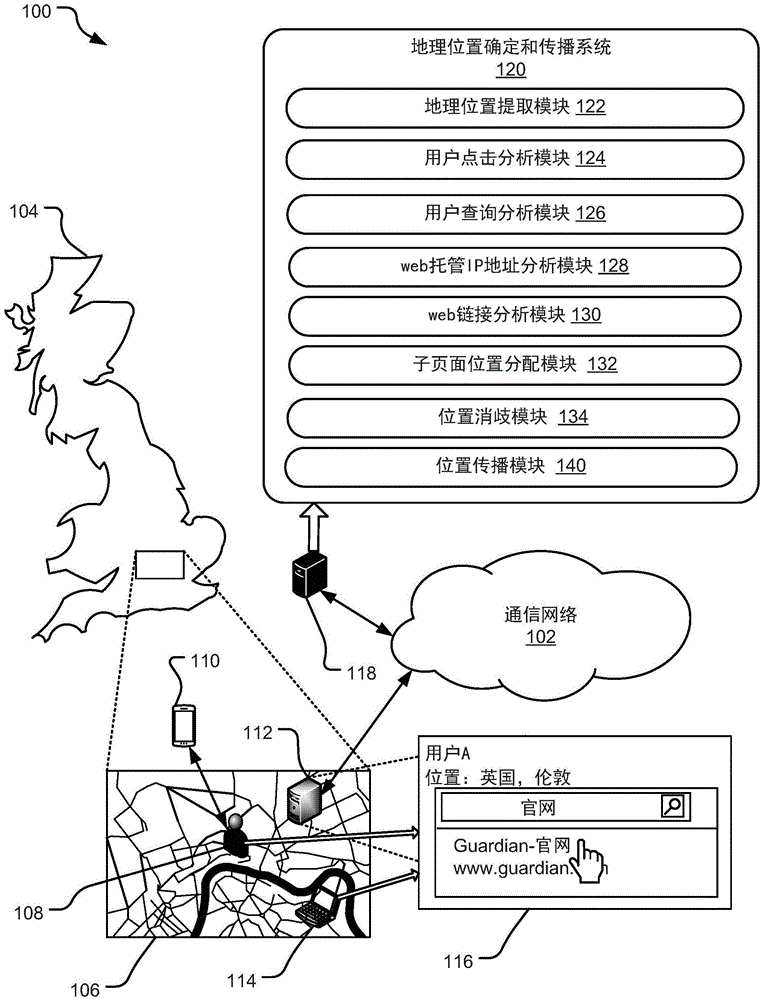
图1解说了用于提取和传播地理位置信息的系统100的实现。具体而言,图1解说了可被实现在服务器118上的地理位置确定和传播系统120。服务器118可被通信地连接到诸如互连网之类的通信网络102。地理位置确定和传播系统120允许将地理位置分配给各种网站,诸如网站116http://www.guardian.com/。在所解说的实现中,网站116由位于伦敦地铁区域106(其位于英国104)中的web托管服务器112主控。网站116可以由第一用户108访问,其中第一用户108的位置可以基于用户108所使用的移动设备110的gps位置来确定。第二用户(未示出)也可使用计算机114来访问网站116。
地理位置确定和传播系统120包括可以通过各种计算机指令在服务器118上实现的各种模块。下面参考图3-13进一步描述这些模块的各种算法和操作。例如,地理位置确定和传播系统120包括地理位置提取模块122,该地理位置提取模块122分析网站116的一个或多个网页的内容以确定网站116的地理位置。例如,地理位置提取模块122可寻找可被用来标识网站116的地理位置是伦敦地铁区域106的文本字符串,诸如不列颠、温布利、上议院等。地理位置确定和传播系统120的用户点击分析模块124可以分析对网站116的点击,诸如由其在伦敦地铁区域106中的位置基于用户108所使用的移动设备110的gps参数而已知的用户108所作的点击。因此,用户点击分析模块124可以将用户108的地理位置分配给网站116的地理位置。需要注意,该示例仅将一个用户108的地理位置分配给网站116的地理位置,在替代实现中,网站116的地理位置可以基于对点击网站116的大量用户的分析进行分配。
用户查询分析模块126分析用户查询并点击这些查询的结果以确定网站116的地理位置。web托管ip地址分析模块128确定:因为web托管服务器112的位置在伦敦地铁区域106中,所以其将伦敦地铁区域106同样分配作为网站116的地理位置。
web链接分析模块130分析从网站116的各种页面到其他网页(未示出)的一个或多个链接以确定网站116的地理位置。例如,如果web链接分析模块130确定到网站116的网页的大量传入或传出链接也在伦敦地铁区域106中发起和终止,则其将伦敦地铁区域106分配作为网站116的地理位置。
子页面位置分配模块132确定网站116的各种子网页(未示出)的地理位置,以确定网站116的地理位置。例如,如果网站116的大量子网页包括指示其地理位置是伦敦地铁区域106的文本字符串,则子页面位置分配模块132还将伦敦地铁区域106分配作为网站116的地理位置。
位置消歧模块134消除网站116的各种候选地理位置之间的歧义。例如,世界上大约有29个地方被命名为伦敦(london),包括美国中的15个。位置消歧模块134生成各种信号,诸如来自网站116的高准确度位置(诸如英国伦敦)、潜在位置候选、世界上名为伦敦的每个位置的人口、伦敦与其他潜在位置候选之间的距离等,以确定网站116的实际位置是<伦敦,英国,欧洲,世界>。
位置传播模块140将网站116的地理位置传播到使用计算机114访问网站116的用户的地理位置。具体而言,位置传播模块140鉴于具有已知位置的其他用户(诸如用户108)所作的点击来分析从计算机114到网站116的各种点击,以确定网站116的地理位置可被分配给计算机114及其用户的地理位置。
图2解说了用于通过网站点击传播用户位置的操作200。具体而言,操作204聚集网站202www.seattletimes.com上的大量用户的位置和所做的点击。操作206分析这些用户位置和点击以确定点击www.seattletimes.com的用户通常位于西雅图。操作208将网站202的地理位置传播给新用户,诸如点击网站202的用户b210。
图3解说了用于通过用户点击传播网站位置的操作300。具体而言,操作304聚集可能在网站302的各个页面中被提到的位置。操作306基于对经聚集的位置的分析来确定网站302主要是关于西雅图和华盛顿州的。操作308还通过用户点击来传播网站302的地理位置。换言之,操作308分析各种用户对网站302的各种点击,并且确定这些用户可能来自西雅图。因此,当用户a310点击网站www.seattletimes.com312中,用户a310的地理位置被确定为是西雅图。
图4解说了用于从网页提取地理位置的操作400。具体而言,一些网页(诸如新闻文章)通常包含指示地理位置的词语。因此,如果网页提到位置,则对网页的点击可间接指示与所提取的位置的亲和性。操作400提供处理来自此类网站的信息以提取此类地理位置。操作402从互联网检索网页的内容。例如,由本文中所公开的地理位置提取和传播系统使用的爬虫可以检索这样的网页内容并将其储存在数据库中以供进一步处理。在一个实现中,操作404从检索到的网页内容中移除广告和其他样板(boilerplate)部分,诸如版权声明等。操作406将网页内容转换为纯文本、或其中其可被分析以找到经命名的实体的此类其他形式。
操作408分析网页内容的纯文本以从网页内容中找到一个或多个经命名的实体。例如,此类经命名的实体可以是地点、人、组织、地标等的名称。例如,对于诸如www.seattle.com之类的新闻网站,操作408可以分析内容以找到经命名的实体,诸如“bellevue(贝尔维尤)”、“redmond(雷德蒙德)”、“microsoft(微软)”、“starbucks(星巴克)”、“satyanadella(萨蒂亚·纳德拉)”、“seahawks(海鹰队)”等。这些实体字符串中的每一个都可以指示给定网站与华盛顿州西雅图相关。操作410确定经命名的实体是地理位置还是不同于地理位置的某事物,诸如人、组织、地标等的名称。
对于表示地理位置的每个经命名的实体,操作412可以对所提取的位置执行地址验证和标准化。例如,如果输入是包含地址的字符串,则输出可以是经验证和经标准化的地址。作为示例,对于输入:“450108thavbellevue”,验证和标准化操作410的输出可以是“450108thavene,bellevuewa98004-5506”。在一个实现中,操作410可以将输入字符串输入到数据库以找到经验证和经标准化的输出。
操作414将地理位置的粒度增加到期望的水平。例如,如果需要城市级粒度,则操作414丢弃街道地址并且仅保留来自经验证和经标准化的字符串的城市、州和国家。操作416将期望的粒度位置添加到字典,其中键是经标准化的地址并且值是生成经标准化的地址的字符串在网站中被找到的次数。因此,如果有十(10)个字符串导致“bellevue”,则对于键“bellevue”,值为十(10)。
对于来自表示不同于位置的实体的网站的每个经命名的实体(诸如组织、人、地标等的名称),操作418在具有固定本体(ontology)的知识库中搜索该实体,该知识库可将各种信息组织成各种类别。本体是知识领域的正式表示。换言之,它是一种解释对象类型与其属性之间的关系的模式。城市的模式可以指定每个城市应该具有名称、市长、乡村(country)等。本体不包含数据本身,它仅描述数据应如何被结构化。这种本体数据库的示例可具有实体、产品、位置、关于世界的事实等的分类。例如,这样的知识库中的条目可以指定“微软公司的总部位于华盛顿州雷德蒙德市”。
如果实体已在这种知识数据库中被找到,则操作420将地理位置分配给该实体。例如,某些人(诸如城市市长或州长)可能与地理区域相联系。例如,如果一篇文章提到jayinslee(杰伊·英斯利)(他在本文撰写时是华盛顿州州长),则操作420可以推断该文章间接引用了华盛顿州的地理区域。类似地,诸如当地餐馆之类的组织可以与特定地理地址相联系。例如,如果网页包含餐馆评论,则操作420可以结合知识库来使用餐馆的名称以确定文章间接引用特定地址(餐馆的位置)。操作420还可以在文本提到连锁店的特定位置的情况下将这种方法用于诸如星巴克之类的连锁餐馆。类似地,如果诸如“太空针塔(spaceneedle)”之类的地标(兴趣点)在文本中被提到,则操作420可以通过确定“太空针塔”地标的地址来推断文章的位置。
图5解说了用于基于来自具有已知位置的用户的点击来确定网页的地理位置的操作500。操作500能够根据具有已知位置的用户的点击来确定网页的地理位置,因为来自给定位置的用户更可能点击与该位置相关的网页。例如,鉴于来自西雅图的人更有可能点击www.seattletimes.com,如果具有未知位置的新用户也点击了www.seattletimes.com,那么也许这样的新用户也在西雅图。操作500可以使用具有已知位置的用户的数据库,以及这些用户访问过的网页的点击日志。具有已知位置的用户的数据库可以例如从搜索引擎获得,其中具有带gps硬件的设备的用户的子集授予搜索引擎在用户发出查询时收集实时gps位置数据的许可。相同的在线服务还可以收集相同用户点击过的所有网站的点击日志。
对于给定网站的每个网页,操作502确定点击过该网页至少一次的各种用户。随后,对于点击过至少一个网页的这些各种用户中的每一者,操作504通过从日志群聚该用户的所有位置读数来确定它们的主导位置。在一个实现中,操作504可丢弃异常值并选取最大群集的中心。操作506反转用户的主导位置的地理编码。具体而言,操作506获取地理位置读数的坐标(纬度、经度)并将其转换成诸如123mainst(主街道),city(城市),state(州),country(国家)之类的地址。操作508将每个用户的地理位置添加到用于网页的字典,其中键是经标准化的地址,并且值是导致经标准化的地址的字符串或实体在网页上被找到的次数。对于点击日志中的每个网页,操作510选取对应于该网页的字典中的共同位置。
替代地,除了从带gps硬件的设备提取的地理位置之外,地理位置还可以通过使用来自用户的简档的信息来被分配给用户。例如,如果在线服务要求用户在他们注册时提供地址,则该地址可以取代从用户的gps轨迹推断出的位置来被直接使用。
图6解说了用于基于搜索引擎中的查询来确定地理位置的操作600。操作600能够基于搜索引擎中的查询来确定地理位置,因为来自给定地理位置的用户可以搜索包含该地理位置的名称的查询。例如,如果来自西雅图的许多人搜索包含西雅图的查询(诸如“西雅图新闻”),并接着点击komonews.com,则komonews.com可能在某种程度上与西雅图相关。作为结果,如果具有未知位置的新用户点击komonews.com,则这样的新用户也可能位于西雅图。操作600使用包含由一群用户发出的查询和搜索结果点击的搜索引擎查询日志。
对于如搜索引擎查询日志所提供的对搜索结果的每次点击,操作602确定用户在点击搜索结果之前所发出的查询。操作604从查询中提取显式地理位置。例如,对于查询“kirkland(柯克兰)的天气”,显式位置是“kirkland”。如果提取操作604成功,则操作606对该位置进行标准化。例如,操作606可以将“kirkland”标准化为“kirkland,wausa”。操作608将经标准化的位置添加到每个点击搜索结果的字典,其中键是查询中所提到的导致用户点击该结果的地址,并且值是用户在查询中已使用导致点击该搜索结果的该位置的次数。对于每个查询搜索结果,操作610从对应的字典中选取共同位置。
图7解说了用于基于web托管ip地址确定地理位置的操作700。操作700能够基于网络托管ip地址确定地理位置,因为网站中的所有页面可以被分配由主控网站的服务器的ip地址给出的位置。操作700使用现有的ip地理位置数据库和点击日志。ip地理位置数据库将ip范围映射到地理位置。因此,在给定特定ip地址的情况下,数据库可被用来确定该ip地址的可能的地理位置。
操作702通过每个通用资源定位符(url)的域对点击日志中的项进行分组。例如,对于如http://www.seattletimes.com/seattle-news/之类的url,操作702将其分组到seattletimes.com域中。对于每个分组,操作704从每个域分组中选择一个代表性url。在一个实现中,分组中的代表性url可以是该分组中的公共url,并且任何并列(tie)可以被随机地处理。例如,对于seattletimes.com分组,代表性url可以是http://www.seattletimes.com/。操作706从代表性url中提取主机名。在此处给出的示例http://www.seattletimes.com中,主机名可以是www.seattletimes.com。
操作708发出域名服务(dns)请求以确定主机名的ip地址。如果需要的话,操作708可以遵循规范名称(cname)记录重定向直到它找到a记录,其中a记录将主机名映射到一个或多个ip地址。操作710通过咨询地理位置数据库来确定ip地址的地理位置。如果地理位置被找到,则操作712将该地理位置分配给域分组中的各个url。
图8解说了用于基于链接的网页的地理位置将地理位置分配给网页的操作800。给定网页通过超链接或链接互连(在同一网站内和/或到其他网站的网页),则链接结构可被用来推断具有未知位置的网页的位置。操作800使用在线网页的代表性子集以及它们之间的链接来执行这些操作中的一个或多个。操作802确定具有已知位置的网页的子集(子集a)。例如,操作802可以使用本文中所公开的多种其他方法中的任何方法来确定网页的位置。操作804确定具有未知位置的网页的子集(子集b)。
对于子集b中的每个网页,操作806确定具有未知位置的网页(子集b)是否具有到子集a中的网页的任何链接,无论是传入的还是传出的。如果没有找到这样的链接,则操作在814处结束。然而,如果这样的链接被找到,则对于到子集a的网页的每个这样的传入或传出链接,操作808确定子集a中的这种经链接的网页的位置。操作810将经链接的网页的这种位置从子集a添加到字典,其中键是来自子集a的经链接的网页的位置,并且值是该位置对于子集b中的网页的出现次数。操作812从字典中选取共同位置并将其分配给子集b中的网页。
图9解说了用于基于子页面的地理位置将地理位置分配给网页的操作900。操作900假设:针对特定网站确定了若干子页面(次页)的地理位置,但是该网站的根或主页的地理位置是未知的。这可以在例如其中子页面可被链接到具有已知位置的另一网页、子页面可包括可被用来标识子页面的地理位置的实体等的情形中。需要注意,对于操作900,不要求子页面链接到主页的根,或反之亦然。
操作902确定网页的子网页或次网页的列表。对于每个子网页或次网页,操作904提取其地理位置信息。操作906从子web页面的此类地理位置中选取共同地理位置并将其分配给主网页或根网页。
图10解说了用于在具有区域和全球范围的网站之间消除歧义的操作1000。存在包含对世界各地的各种位置的引用的许多网站。例如,cnn.com包含指向各种位置的数千篇文章。如果本文中所公开的地理位置提取和传播系统要把所有cnn.com的页面中最常提到的位置分配给cnn.com,则这可能是不正确的。为了解决该问题,本文中所公开的实现提供了用于在区域范围和全球范围之间进行区分的方法。具体而言,如果网站没有提到任何位置,或者它提到了世界各地或全国各地的各种位置,则其被标识为具有全球范围。如果网站主要提到特定的较小地理位置,则其被标识为具有区域范围。
操作1002爬取网站的所有可访问页面。对于网站的每个页面,操作1004确定网页是否提到地理位置,或者是否可以使用本文中所公开的一个或多个方法来被分配地理位置。操作1006对每一个网页的地理位置进行标准化,并且操作1008聚集可被分配给网页的各种地理位置。在一个实现中,操作1008以不同粒度级别聚集地理位置,诸如聚集各个国家的计数、聚集国家和州的各个组合的计数、聚集国家、州和城市的各个组合的计数等。操作1010在每个粒度级别处聚集地理位置并且针对各种粒度级别对跨网站的所有页面的独特实例进行计数。对于给定页面,如果受欢迎的位置的计数占比具有该粒度的所有位置的计数的比例高于预定阈值,则操作1012确定该页面具有区域范围。否则,假设它具有全球范围。
例如,对于kirklandreporter.com,假设位置“kirkland”跨kirklandreporter.com的所有页面被提到了800次,位置“seattle”跨kirklandreporter.com的所有页面被提到了300次,并且位置“bellevue”跨kirklandreporter.com的所有页面被提到了200次。在该情形中,“kirkland”显然是受欢迎的位置。操作1012将“kirkland”的计数(800)除以所有位置的计数(800+300+200)。结果是0.615(或约62%)。给定60%的预定阈值,则除法的结果高于预定阈值。因此,操作1012确定kirklandreporter.com具有区域范围,并且该范围是“kirkland,wa”。操作1012还可以针对相同页面以其他粒度级别(例如“kingcounty(国王郡)”或“washingtonstate(华盛顿州)”)来被执行,以获得甚至更高的阈值。
图11解说了用于消除多个候选地理位置之间的歧义的操作1100。具体而言,操作1100解决了具有类似名称的多个地理位置的问题。例如,在美国存在至少十(10)个名为“easton(伊斯顿)”的城市。这种模糊的地理位置名称使得难以从网页的文本内容中正确地提取地理位置。例如,如果新闻文章提到名为“easton”的地理位置,则本文中所公开的地理位置提取和传播系统消除名为“easton”的十个候选城市之间的歧义,以便对包含该新闻文章的网页进行正确的地理定位。具体而言,操作1100收集可被用作消歧信号的信息的各种片段。
操作1102从消歧操作1100被应用到的网站的网页中提取最高准确度地理位置。高准确度地理位置可以是被以高细节度指定的地理位置,诸如“easton,pennsylvania(宾夕法尼亚州伊斯顿)”。在一个实现中,来自网站的高准确度地理位置候选可以使用以下来被提取:可以使用经命名的实体数据库的经命名的实体提取算法。地理位置算法将所提取的经命名的实体位置作为输入并且输出元组,其中第一元素是被精确地地理定位的位置(诸如“northamerica,unitedstatesofamerica,pennsylvania,northampton,easton(北美,美国,宾夕法尼亚,北安普顿,伊斯顿)”),而第二元素是表示地理位置算法对结果有多少把握的置信度百分比分数。
地理位置算法可以忽略其中输出的置信度值低于阈值(诸如80%)、或者结果是模糊的(多于一个的位置候选)的所有结果。随后,操作1102以不同粒度级别聚集独特位置,诸如:对独特国家进行计数;对<国家,州>的独特组合进行计数;对<国家,州,郡>的独特组合进行计数;以及对<国家,州,郡,市>的独特组合进行计数。这四个粒度级别中的每一者处的最高位置被选取。
操作1104编译尽可能多的位置的树。操作1104可以使用包含地理实体及它们之间的关系的数据库。作为示例,一个良好的起点是可通过geonames.org公开可用的数据库。随后,操作1104通过从地球开始、接着寻找所有洲、接着寻找每个洲中的所有国家、接着寻找每个国家中的每个州或地区等来创建位置的树。操作1104可通过从所有城市开始并且往上到各郡、各地区、各国家等来自下而上地编译该树。在两种情形中,结果是一棵树,其中第一级是名为地球(earth)的单个项,然后第二级包含所有的洲,然后第三级包含所有国家等。
操作1106从目标页面提取地理位置候选。在一个实现中,操作1106可以使用经命名的实体提取算法从目标网页提取潜在的地理位置候选。随后,操作1106使用地理位置算法,该地理位置算法将所提取的经命名的实体位置作为输入并且输出元组,其中第一元素是被精确地地理定位的位置(诸如“northamerica,unitedstatesofamerica,pennsylvania,northampton,easton(北美,美国,宾夕法尼亚,北安普顿,伊斯顿)”),而第二元素是表示地理位置算法对结果有多少把握的置信度百分比分数。需要注意,操作1106提取地理位置的潜在候选的列表,而操作1102在存在具有高准确度的单个地理位置候选的情况下生成输出。例如,对于输入“easton”,操作1106的输出可以是十一个元组的列表,每个城市的一个元组在“usa”中被命名为“easton”。这个元组列表是名为“easton”的实体的位置候选的列表。
操作1108确定世界中各种位置的人口。具体而言,操作1108使用与操作1104所使用的相同的数据源,并且编译世界上所有位置以及它们的经估计的人口的列表。
操作1110创建在操作1104处生成的树的副本。对于经命名的实体的每个候选位置,操作1112在操作1104处所生成的树上跟踪其路径。当操作1104在树上跟踪其路径时,它对被附连到树触及到的树的每个节点的计数器进行递增。例如,对于候选位置“北美,美国,宾夕法尼亚州,北安普顿,伊斯顿”,北美节点计数器将从0递增到1,“美国”节点计数器将从0递增到1等。需要注意,如果后续候选位置也在“pa,usa”中,则“usa”计数器和“pa”计数器两者都将变为两(2)。
操作1114跟踪树以寻找在操作1102处提取的各种经命名的实体的每个地理位置。操作1114还将在操作1102处提取的位置的计数器递增2(二)。与在操作1106期间提取的位置(模糊位置)相比,对计数器进行这种递增有效地给予在操作1102期间提取的位置(高准确度位置)更高的权重。操作1116从在操作1106生成的各个候选位置中挑选候选位置。具体而言,操作1116包括为经命名的实体的每个候选位置生成线性组合分数,其中该线性组合分数将候选的及其父的节点计数器以及当前候选地理位置与具有在上述步骤中的树上跟踪到的不同名称的所有其他地理位置之间的以英里为单位的距离纳入考虑。如果存在并列,则其可以通过提升具有如在操作1108处所确定的最高人口的候选的分数来解决。
图12解说了被用于在如图11中所示的操作1100所使用的多个候选地理位置之间消除歧义的位置的树1200。可以鉴于利用包含以下文本的新闻文章对网站的地理位置进行消歧来解说树1200:
“abethlehemwomantwicebitherboyfriendduringanargumenttuesdaynightinaneastonapartment,citypolicesayincourtpapers.(市警方在法庭文件中说:周二晚上在伊斯顿公寓中伯利恒的一名女士在一次争吵期间两次咬伤她的男友。)”
本文中所公开的地理位置提取和传播系统识别到该文章中的“bethlehem(伯利恒)”和“easton(伊斯顿)”两个名称是模糊的,因为在美国有十(10)座城市被命名为“easton”且有五(5)座城市被命名为“bethlehem”。如图11所示的操作1112追踪树1200以寻找每个经命名的实体bethlehem和easton,以确定在潜在的“bethlehem”和“easton”的所有组合中,它们中只有两个位于同一个郡(宾夕法尼亚州北安普顿)。这意味着当操作1112跟踪树1200上的候选位置时,因为这些位置中的两个位于同一个郡,所以它们的父northampton节点的计数器被递增到二。类似地,如图11所示的操作1116确定在所有潜在的<bethlehem,easton>候选对中,它们中只有两(2)个位于彼此靠近(约12英里)的位置。因此,如图11所示的操作1100确定网站的正确地理位置自<bethlehem,easton>向northampton(北安普顿)、pennsylvania(宾夕法尼亚)、usa(美国)northamerica(北美)、world(世界)来跟踪树。
图13解说了用于基于用户动作传播位置的操作1300。具体而言,操作1300公开了对被分配给不同类型的用户动作的候选位置进行排名并将候选位置传播给执行用户动作的用户。
如操作1302至1314所解说的训练阶段使用具有用户的已知位置的所有可能用户的小子集来建立训练模型,其中对于用户和候选位置的列表,输出是元组的列表。操作1300的训练阶段使用用户动作的日志、与每个用户相关的位置列表(被用于训练的基础事实(groundtruth)),以及用于使用本文档中以上所描述的方法来训练模型的这些动作的经预先计算的候选位置。另外,对于训练模型,键是候选位置并且值是0和1之间的分数,其预测该候选位置与该用户或ip地址相关的可能性。
操作1302选择训练集中的用户。对于所选择的用户,操作1304确定被给定为链接到动作日志中的动作链接的各种候选位置。操作1306选择各种候选位置中的一个。对于所选择的候选位置,操作1308创建位置向量,其中该位置向量的每个维度对应于被用来确定该位置的方法以及表示该方法和该位置的原始分数的对应值。在一个示例中,对于用户a,多个信号被找到,其中这些信号指示西雅图为候选位置。具体而言,使用诸如以下之类的多种方法将西雅图提取为该用户的位置:用户发送了十(10)封关于西雅图的电子邮件、点击了二十(20)个西雅图相关的网站,以及有三十(30)个住在西雅图的朋友。在该情形中,对于<用户a,位置西雅图>组合,操作1308生成具有如下三(3)个维度的向量,每种方法一个维度,其中西雅图被提取为该用户的位置:
·电子邮件维度,值:10
·网站点击维度,值:20
·朋友维度,值:30
操作1310评估是否提取了更多这样的位置,并且针对每个这样的附加位置重复操作1306和1308,从而导致一个或多个候选位置向量。操作1312为每个<用户,候选位置>确定二元标签,其中二元标签的1的值意味着候选位置是相关的,而二元标签的0的值意味着候选位置值是不相关的。在一个实现中,这样的二元值通过构建逻辑回归模型来生成,该逻辑回归模型调整被用于向量的每个维度的权重。操作1314评估是否要为更多用户重复提取候选位置、生成位置向量和确定相关性的操作。
随后,经训练的模型被应用于新数据,如操作1320所解说。操作1320使用用户的用户动作日志,其中与用户相关的位置是未知的并且针对这些动作预先计算候选位置以找到新用户的位置。可以对各种用户的每个用户执行操作1320。具体而言,对于给定的新用户,操作1322提取与该给定的新用户相关的有区别的候选位置。操作1324以上面在操作1308中所讨论的方式生成向量。随后,对于一对用户和候选位置,操作1326应用由操作1302-1324生成的经训练的模型以确定候选位置是否与给定的新用户相关。因此,实际上,经训练的模型允许位置通过用户动作(诸如点击)从诸如网页之类的实体传播到没有位置的用户。
图14解说了可有助于实现所描述的用于地理位置提取和传播的技术的示例系统1400。图14的用于实现所描述的技术的示例硬件和操作环境包括诸如计算机20形式的通用计算设备之类的计算设备、移动电话、个人数据助理(pda)、平板、智能手表、游戏控制器或其他类型的计算设备。例如,在图14的实现中,计算机20包括处理单元21、系统存储器22,以及将包括系统存储器22的各种系统组件在操作上耦合到处理单元21的系统总线23。可存在仅一个或可存在一个以上的处理单元21,使得计算机20的处理器包括单个中央处理单元(cpu),或通常被称为并行处理环境的多个处理单元21。计算机20可以是常规计算机、分布式计算机、或者任何其他类型的计算机;各实现不限于此。计算机20的实现可被用来实现如本文中所公开的用于提取和传播地理位置信息的系统。
系统总线23可以是若干类型的总线结构中的任何一种,包括使用各种总线体系结构中的任何一种的存储器总线或存储器控制器、外围总线、交换结构、点到点连接,以及局部总线。系统存储器22也可以简称为存储器,并且包括只读存储器(rom)24和随机存取存储器(ram)25。基本输入/输出系统(bios)26通常存储在rom24中,包含了诸如在启动过程中帮助在计算机20内的元件之间传输信息的基本例程。计算机20还包括用于对硬盘(未示出)进行读写的硬盘驱动器27、用于对可移动磁盘29进行读写的磁盘驱动器28、以及用于对可移动光盘31(诸如cd-rom、dvd或其他光介质)进行读写的光盘驱动器30。
硬盘驱动器27、磁盘驱动器28和光盘驱动器30分别通过硬盘驱动器接口32、磁盘驱动器接口33和光盘驱动器接口34连接到系统总线23。驱动器及其相关联的有形计算机可读介质为计算机20提供了对计算机可读指令、数据结构、程序模块以及其他数据的非易失性存储。本领域技术人员应该领会,可以在示例操作环境中使用任何类型的有形计算机可读介质。
可以有若干个程序模块存储在硬盘驱动器27、磁盘29、光盘31、rom24或ram25上,包括操作系统35、一个或多个应用程序36、其他程序模块37,以及程序数据38。例如,本文中所公开的地理位置提取和传播系统的一个或多个模块可以用硬盘驱动器27、磁盘29、光盘31、rom24或ram25上的指令来实现。用户可以通过诸如键盘40和定点设备42之类的输入设备在个人计算机20上生成提醒。其他输入设备(未示出)可以包括话筒(例如,用于语音输入)、相机(例如,用于自然用户界面(nui))、操纵杆、游戏垫、圆盘式卫星天线、扫描仪等等。这些及其他输入设备常常通过耦合到系统总线23的串行端口接口46连接到处理单元21,但是也可以通过诸如并行端口、游戏端口或通用串行总线(usb)之类的其他接口来进行连接。监视器47或其他类型的显示设备也可经由诸如视频适配器48之类的接口被连接到系统总线23。除了监视器47之外,计算机通常还包括其他外围输出设备(未示出),诸如扬声器和打印机。
计算机20可以使用到一个或多个远程计算机(诸如远程计算机49)的逻辑连接来在联网环境中操作。这些逻辑连接由耦合至或者作为计算机20的一部分的通信设备来实现;各实现不限于特定类型的通信设备。远程计算机49可以是另一计算机、服务器、路由器、网络pc、客户端、对等设备或其他常见的网络节点,并且通常包括以上关于计算机20所描述的许多或全部元件。图14中所描绘的逻辑连接包括局域网(lan)51和广域网(wan)52。这样的联网环境在办公室网络、企业范围的计算机网络、内联网和互连网(这些是各种类型的网络)中是普遍的。
当用于lan联网环境中时,计算机20通过网络接口或适配器53(这是一种类型的通信设备)连接到局域网51。当用于wan联网环境中时,计算机20通常包括调制解调器54、网络适配器、某类型的通信设备,或用于通过广域网52建立通信的任何其他类型的通信设备。可以是内置或者外置的调制解调器54经由串行端口接口46连接到系统总线23。在联网环境中,参考个人计算机20所描述的程序引擎或其某些部分可被储存在远程存储器存储设备中。可以领会,所示出的网络连接只是示例,并且用于在计算机之间建立通信链路的其他装置和通信设备也可以被使用。
在示例实现中,用于提取和传播地理位置的软件或固件指令可被储存在存储器22和/或存储设备29或31中并由处理单元21处理。用于提取和传播地理位置的规则可被储存在作为持久数据存储的存储器22和/或存储设备29或31中。例如,地理位置提取模块可以用被储存在存储器22和/或存储设备29或31中且由处理单元21处理的指令来实现。类似地,地理位置确定和传播系统的一个或多个模块也可以用被储存在存储器22和/或存储设备29或31中且由处理单元21处理的指令来实现。存储器22可被用来储存一个或多个地理位置提取和传播模块。
与有形计算机可读存储介质对比,无形计算机可读通信信号可具体化驻留在诸如载波或其他信号传输机制等已调数据信号中的计算机可读指令、数据结构、程序模块或其他数据。术语“已调数据信号”意指使其一个或多个特性以这样的方式被设置或者改变以便在信号中对信息进行编码的信号。作为示例而非限制,无形通信信号包括有线介质(诸如有线网络或直接线路连接),以及无线介质(诸如声学、rf、红外线和其他无线介质)。
一些实施例可包括制品。制品可包括用于储存逻辑的有形存储介质。存储介质的示例可包括能够储存电子数据的一种或多种类型的计算机可读存储介质,包括易失性存储器或非易失性存储器、可移动或不可移动存储器、可擦除或不可擦除存储器、可写入或可重写存储器,等等。逻辑的示例可包括各种软件元素,诸如软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、函数、方法、规程、软件接口、应用程序接口(api)、指令集、计算代码、计算机代码、代码段、计算机代码段、文字、值、符号、或其任意组合。例如,在一个实施例中,制品可储存可执行计算机程序指令,该指令在由计算机执行时致使该计算机执行根据所描述的各实施例的方法和/或操作。可执行计算机程序指令可包括任何合适类型的代码,诸如源代码、已编译代码、已解释代码、可执行代码、静态代码、动态代码等。可执行计算机程序指令可根据预定义计算机语言、方式或句法来实现,以用于指令计算机执行特定功能。这些指令可以使用任何合适的高级、低级、面向对象、可视、已编译、和/或已解释编程语言来实现。
用于地理位置提取和传播的系统可包括各种有形计算机可读存储介质和无形计算机可读通信信号。有形计算机可读存储可以由可被地理位置确定和提取系统120(图1)访问的任何可用介质来体现,并且包括易失性和非易失性存储介质、可移动和不可移动存储介质两者。有形计算机可读存储介质不包括无形和瞬态通信信号,而是包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任一方法或技术实现的易失性和非易失性、可移动和不可移动存储介质。有形计算机可读介质包括但不限于,ram、rom、eeprom、闪存存储器或其他存储器技术、cdrom、数字多功能盘(dvd)或其他光学磁盘存储、磁带盒、磁带、磁盘存储或其他磁存储设备、或可被用来储存所需信息且可以由地理位置确定和提取系统120(图1)访问的任何其他有形介质。与有形计算机可读存储介质对比,无形计算机可读通信信号可具体化驻留在诸如载波或其他信号传输机制等已调数据信号中的计算机可读指令、数据结构、程序模块或其他数据。术语“已调数据信号”意指使其一个或多个特性以这样的方式被设置或者改变以便在信号中对信息进行编码的信号。作为示例而非限制,无形通信信号包括有线介质(诸如有线网络或直接线路连接),以及无线介质(诸如声学、rf、红外线和其他无线介质)。
一种用于确定用户的地理位置的系统,其包括存储器,一个或多个处理器单元,以及被储存在存储器中且由一个或多个处理器单元执行的地理位置提取模块,该地理位置提取模块被配置成基于被分配给多个用户的网页的内容和地理位置来将地理位置分配给该网页,其中该多个用户中的每一个与该网页相关联,以及当新用户点击该网页时将该网页的地理位置分配给新用户。在该系统的一个实现中,多个用户中的每一个通过以下中的至少一者来与该网页相关联:已查看了该网页、已搜索了该网页,以及已点击了该网页的内容。在该系统的替代实现中,地理位置提取模块被进一步配置成通过将网页的内容转换为纯文本并从纯文本中提取表示地理位置的一个或多个字符串来基于网页的内容将地理位置分配给网页。
在该系统的另一实现中,子页面地理位置分配模块被配置成分析与网页相关的子页面的内容以确定表示地理位置的一个或多个字符串,基于表示地理位置的一个或多个字符串来确定子页面地理位置,以及将子页面地理位置分配给网页。在该系统的又一实现中,web链接分析模块被配置成分析来自网页的传入和传出链接以确定网页的地理位置。在该系统的另一实现中,用户点击分析模块被储存在存储器中且能由一个或多个处理器单元执行,该用户点击分析模块被配置成基于点击网页的一个或多个用户的位置来确定网页的位置。
在该系统的替代实现中,用户查询分析模块被储存在存储器中且能由一个或多个处理器单元执行,该用户查询分析模块被配置成基于提交导致点击网页的查询的用户的位置来确定网页的位置。
一种将地理位置分配给新用户的方法,其包括基于被分配给多个用户的网页的内容和地理位置来将地理位置分配给该网页,其中多个用户中的每一个与该网页相关联,以及当新用户点击该网页时将该网页的地理位置分配给新用户。在该方法的一个实现中,多个用户中的每一个通过以下中的至少一者来与该网页相关联:已查看了该网页、已搜索了该网页,以及已点击了该网页的内容。在该方法的又一实现中,基于网页的内容将地理位置分配给网页进一步包括将网页的内容转换为纯文本,以及从纯文本中提取表示地理位置的一个或多个字符串。该方法的替代实现进一步包括验证和标准化表示地理位置的一个或多个字符串;以及如果验证是成功的,则将地理位置的粒度增加到期望的水平。
在一个实现中,该方法还包括将经标准化的粒度地理位置添加到字典,其中该字典将经标准化的粒度地理位置包括为键以及将网页上的经标准化的粒度地理位置的出现次数包括为值。在另一实现中,基于网页的内容将地理位置分配给网页进一步包括分析与网页相关的子页面的内容以确定表示地理位置的一个或多个字符串,基于表示地理位置的一个或多个字符串确定子页面地理位置,以及将子页面地理位置分配给网页。
在一个实现中,基于网页的内容将地理位置分配给网页进一步包括分析被链接到网页的链接的页面的内容以确定表示地理位置的一个或多个字符串,基于表示地理位置的一个或多个字符串确定链接的页面地理位置,以及将链接的页面地理位置分配给网页。在一个实现中,基于被分配给多个用户的地理位置将地理位置分配给网页进一步包括基于根据以下中的至少一者来推断多个用户之一的位置来将地理位置分配给用户:多个用户之一的在线简档和用户的地理定位系统(gps)轨迹。在另一实现中,如果确定网页内容的一个或多个字符串与多于一个的地理位置相关,则通过使用与该多于一个的地理位置相关的位置的树来消除在该多于一个的地理位置之间的歧义。
一种包括一个或多个有形计算机可读存储介质的物理制品,该一个或多个有形计算机可读存储介质编码用于在计算机系统上执行计算机过程的计算机可执行指令,该计算机过程包括基于被分配给多个用户的网页的内容和地理位置来将地理位置分配给该网页,其中多个用户中的每一个与该网页相关联,以及当新用户点击该网页时将该网页的地理位置分配给新用户。在替代实现中,该计算机过程进一步包括将网页的内容转换为纯文本,以及从纯文本中提取表示地理位置的一个或多个字符串。在又一实现中,该计算机过程进一步包括验证和标准化表示地理位置的一个或多个字符串;以及如果验证是成功的,则将地理位置的粒度增加到期望的水平。在一个实现中,该计算机过程进一步包括将经标准化的粒度地理位置添加到字典,其中该字典将经标准化的粒度地理位置包括为键以及将网页上的经标准化的粒度地理位置的出现次数包括为值。
上面的说明、示例和数据提供了对本发明的示例性实施例的结构和使用的完整的描述。因为可以在不背离本发明的精神和范围的情况下做出本发明的许多实现方式,所以本发明落在所附权利要求的范围内。此外,不同实施例的结构特征可以与另一实现方式相组合而不偏离所记载的权利要求书。
- 还没有人留言评论。精彩留言会获得点赞!