一种基于FPGA的CABAC熵编码方法与装置与流程
本发明涉及异构计算领域,具体涉及一种基于fpga的cabac熵编码方法与装置,其能够高效且同时基于上下文进行自适应二进制算术熵编码(cabac)。本发明的显著特征是通过采用双路径存储上下文和多级流水线设计,消除了数据依赖,用很小的代价获得了较高的性能和吞吐率。
背景技术:
fpga(field-programmablegatearray),即现场可编程门阵列,它是在pal、gal、cpld等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(asic)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
熵编码压缩是一种无损压缩,其实现原理是使用新的编码来表示输入的数据,从而达到压缩的效果。常用的熵编码有游程编码,哈夫曼编码和cavlc编码等。cabac(contextadaptivebinaryarithmaticcoding)是h.264/mpeg-4avc中使用的熵编码算法。cabac在不同的上下文环境中使用不同的概率模型来编码。其编码过程大致是这样:首先,将欲编码的符号用二进制bit表示;然后对于每个bit,编码器选择一个合适的概率模型,并通过相邻元素的信息来优化这个概率模型;最后,使用算术编码压缩数据。cabac是h.264和vp8压缩标准中采用的熵编码机制,在经典的广播应用中它可以节约9%~14%的比特率,要比哈夫曼编码和基于上下文的自适应可变长编码cavlc更有效率,其压缩效率比cavlc高20%。cavlc(contextadaptivevariablelengthcoding)是在h.264/mpeg-4avc中使用的熵编码方式。在h.264中,cavlc以zig-zag顺序用于对变换后的残差块进行编码。cavlc是cabac的替代品,虽然其压缩效率不如cabac,但cavlc实现简单,并且在所有的h.264profile中都支持。
随着超高清视频技术的发展,对熵编码的压缩效率提出了越来越苛刻的要求。但cabac算法复杂度高,其内生的数据串联特性使得硬件实现难度大,一个比特的编码结果会对接下来的一系列比特的编码都有直接的影响,因此很难用并行技术对其进行加速,这也成为了它的一个速度瓶颈。同时由于其中的上下文管理和算术编码需要进行很多存储器访问和alu操作,计算复杂度较高,在传统的可编程器件中实现效率较低。
针对上述问题,本发明提出了一种基于fpga实现的算术编码设计方法和硬件加速装置,其能够高效且同时基于上下文进行自适应二进制算术熵编码(cabac)。本发明的显著特征是通过采用双路径存储上下文和多级流水线设计,消除了数据依赖,用很小的代价获得了较高的性能和吞吐率。
技术实现要素:
本申请发明一种基于fpga的cabac熵编码器装置,该装置具体包括两个功能模块:上下文更新模块,该模块使用两个上下文寄存器、两个索引比较器和三个数据选择器避免了空闲状态的产生;算术编码数据产生模块,用于更新编码引擎的内部状态range、low和bitoutstanding寄存器,并且输出比特流。
如上所述的基于fpga的cabac熵编码器装置,其特征还在于,上下文更新模块中包括下一级流水,下一级流水具体包括两部分,一部分用于判断所编码的符号,另部分用于读取存储器。
如上所述的基于fpga的cabac熵编码器装置,其特征还在于,算术编码数据产生模块还包括多个两输入的补码加法器和两个高速的超前进位加法器,超前进位加法器用于进行rmps和lownew的计算。
一种基于fpga的cabac熵编码方法,该方法具体包括如下步骤:二值化步骤,将句法元素转化为二进制字符串的形式,实现兼容h.264规定的四种二值化方法:一元码(u);一元截断码(tu);k阶哥伦布编码(egk);固定长度二进制化(fl);上下文模型选择步骤,根据句法元素和相邻模块的信息,为每一个二进制符号分配一个上下文模型每一个上下文模型对应一组{mps,pstateidx},mps代表将要编码的大概率符号,pstateidx表示当前概率状态索引;算术编码步骤,用一个码子表示一段数据流,每个码子都是对一段数据流不断分割后获得的。cabac算术编码的输入只有两种符号:最大可能符号(mps)和最小可能符号(lps),每个编码的符号都有其对应的上下文模型,每个符号编码完成后都需要对上下文进行更新,每个上下文都独立地使用对应的概率表维护概率状态。
如上所述的基于fpga的cabac熵编码方法,其特征还在于,将计算不相关的变量分开,置于不同的流水线中,将同一操作分步进行,用以消除数据依赖。
附图说明
图1、本申请所述的cabac算术编码器结构图
图2、数据依赖产生图
图3、上下文更新微体系结构图
图4、计算range和low示意图
具体实施方式
算术编码可以看作是基于符号概率而对一段区间进行的迭代式分割。cabac是一种简化的算术编码机制。在cabac中,编码进程采用最大可能符号(mps)和最小可能符号(lps)替代0和1,而且大多数符号都在一个上下文环境中进行编码,那些具有相同统计特性的符号具有相同的上下文。每个上下文维护一种概率模型,包含两个值:6位概率状态state和1位mps值,他们共同描述了当前上下文中二进制符号的概率分布。
每次编码一个符号后,根据该符号是mps或者lps更新概率状态和mps值。假设给出了lps的概率估计为plps,而且给定的区间由其较小端的边界值low和宽度range表示,那么给定区间进一步划分为两个子区间,分别对应于lps和mps。如果待编码符号为lps,新的当前区间更新为:
rangenew=rlps(1)lownew=low+range-rlps(2)
如果待编码符号为mps,新的当前区间更新为:
rangenew=range-rlps(3)lownew=low(4)
为了更清楚地说明本发明或现有技术中的技术方案,下面对结合附图对本申请所述的方法作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,都属于本发明保护的范围。
cabac算术编码器整体结构如图1所示。
本申请所述的基于fpga的cabac熵编码器设计方法与装置将实现电路划分为两个功能模块:上下文更新模块、算术编码数据产生模块。
1、上下文更新模块(二进制算术编码器微体系结构)
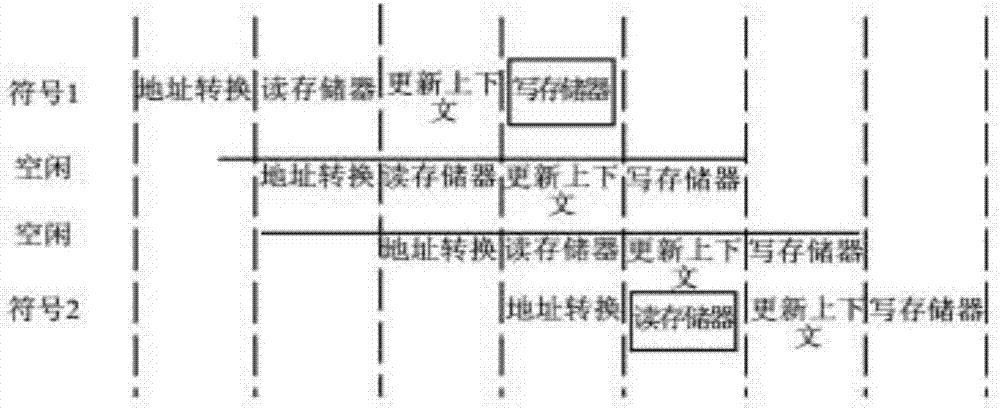
首先通过上下文索引读取更新上下文存储器,存储器选择sram,因为相对于寄存器集来讲,sram拥有更精简的结构,能够节省大约35%的面积。上下文的读取和更新需要四个过程,即地址生成、读存储器、更新上下文和写存储器。若相邻符号的上下文索引相同,就必须等到前一个符号的上下文更新完毕后,再对下一个符号的上下文进行读取,数据依赖产生如图2所示。
为了消除空闲周期,本发明增加一路寄存器用来存储更新过的上下文模型,有两个路径可以产生上下文,如果当前符号的索引与它之前的两个符号的索引不相同,那么直接选择路径1,否则就会产生数据依赖,此时选择路径2,无需再去访问存储器。使用两个上下文寄存器、两个索引比较器和三个数据选择器避免了空闲状态的产生,提高了系统的吞吐率,微体系结构如图3所示。
下一级流水包括两部分内容,左边部分为判断所编码的符号是mps还是lps,右边部分为读取rlps存储器。rlps存储器中共有256个值,但其地址是由pstateidx和range共同决定的,为解决range的数据依赖问题,把读取rlps的过程分为两部分。先用来自pstateidx的6bit读取rlps存储器,得到4个不同的rlps值。在下一级流水中根据range值选出正确的rlps值,接下来是对range和low的计算。
2、算术编码数据产生模块
模块的任务是更新编码引擎的内部状态(range,low和bitoutstanding寄存器)和输出比特流。它包含几个两输入的补码加法器,来完成加法和减法运算,计算的目的是为了等比例缩减range和改变low的状态。本申请所述的发明中使用两个高速的超前进位加法器来进行rmps和lownew的计算。更新range是通过检测range前导o的个数,对相应的range寄存器进行移位操作可以保证range寄存器的最高位为1。计算新的low时,寄存器需要左移相同的位数,但low寄存器的最高位要根据移出的数据流做相应的改变,如果移出的数据流全是1,那么low寄存器的最高位要置1,否则为零,算术编码数据产生模块结构如图4所示。
bitoutstanding寄存器根据low的位模式进行更新,如果前两位为“10”,那么bitoutstanding加1。它的值还与数据产生模块有关,如果数据产生模块输出的数据是正确的,bitoutstanding寄存器清零,同时输出相应的0,1字符串。本申请采用查找表的方式以保证每个时钟都有比特输出,查找表的结果包括更新bitoutstanding寄存器和输出溢出比特流。
本申请所述的基于fpga的cabac熵编码方法包括的具体实施方式如下:
1、二值化步骤,将句法元素转化为二进制字符串的形式,实现兼容h.264规定的四种二值化方法:一元码(u);一元截断码(tu);k阶哥伦布编码(egk);固定长度二进制化(fl)。
2、上下文模型选择步骤,根据句法元素和相邻模块的信息,为每一个二进制符号分配一个上下文模型每一个上下文模型对应一组{mps,pstateidx},mps代表将要编码的大概率符号,pstateidx表示当前概率状态索引。
3、算术编码步骤,算术编码就是用一个码子表示一段数据流,这个码子是对一段数据流不断分割后获得的。cabac算术编码的输入只有两种符号:最大可能符号(mps)和最小可能符号(lps),每个编码的符号都有其对应的上下文模型。每个符号编码完成后都需要对上下文进行更新,每个上下文都独立地使用对应的概率表维护概率状态。
4、在实现方面,将计算不相关的变量分开,置于不同的流水线中,例如range和low;将同一操作分步进行,消除数据依赖,优化流水线设计,如读取rlps;通过引入额外寄存器来缓存数据防止气泡的产生,如在更新上下文的时候采用双路径存储,消除了空闲状态。
本申请所述的发明与其他现有的数据压缩方式相比优势在于拥有更高的性能和吞吐率,能够合理利用fpga的双端口ram、流水线结构等,可以灵活地集成到h.264和vp8图像压缩系统中。采用fpga芯片作为计算加速器正在成为数据中心及服务器发展的一种新趋势,本申请所述的发明有助于公司在异构计算前沿技术方面的积累,很多国际大公司例如ibm、百度和腾讯等公司对熵编码加速也有广泛应用需求,因此市场前景广阔。
- 还没有人留言评论。精彩留言会获得点赞!