一种虚拟机集群的故障监控方法及装置与流程
本发明涉及虚拟机领域,特别是涉及一种虚拟机集群的故障监控方法及装置。
背景技术:
对于虚拟机集群,当一个控制器节点故障时,该节点上的相关资源服务会切换到另一个节点,然后在对需要对故障节点进行恢复,故集群故障监控显得尤为重要。
在建立集群的每个控制器中都可以存在一个虚拟机,这些虚拟机要建立集群,并监控集群。在两个控制节点的情况下,如果虚拟机集群的心跳中断,两个节点孤立存在,法定节点数(quorum)就不起作用了,会造成这两个节点争抢资源,无法实现故障监控。
针对两个控制节点的虚拟机集群,目前主要使用ipquorum来实现监控,即通过外置ip连接集群的两个节点,当集群心跳中断时,哪个节点先与外置ip通信,拿到quorum,则将该节点作为dc节点继续工作,另一个节点释放资源。但是,这样需要提供外置ip的服务器,来提供ipquorum,增加成本,同时增加一条外部通信链路就多一分风险,使得监控不可控。
技术实现要素:
本发明的目的是提供一种虚拟机集群的故障监控方法及装置,目的在于解决现有技术中虚拟机集群监控方法的成本较高且不可控风险较高。
为解决上述技术问题,本发明提供一种虚拟机集群的故障监控方法,该方法包括:
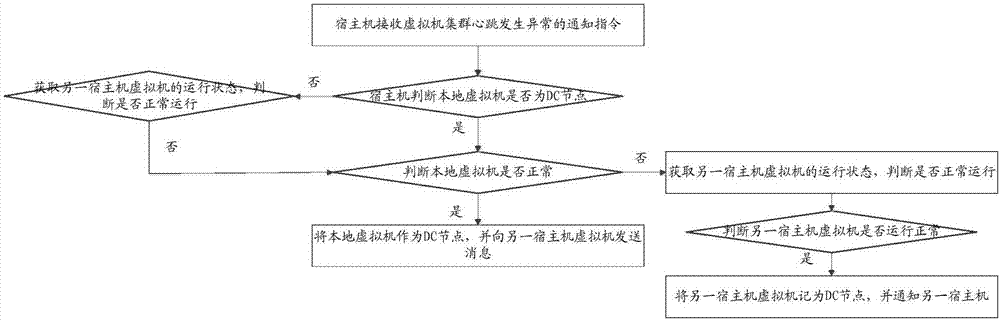
宿主机接收虚拟机集群心跳发生异常的通知指令;
所述宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点;
当所述虚拟机为所述dc节点时,判断所述虚拟机运行是否正常;
当所述虚拟机运行正常时,所述宿主机将所述虚拟机作为所述dc节点,并向另一宿主机发送消息;
当所述虚拟机运行异常时,所述宿主机获取另一宿主机虚拟机的运行状态,判断所述另一宿主机虚拟机运行是否正常;
当所述另一宿主机虚拟机运行正常时,将所述另一宿主机虚拟机作为所述dc节点。
可选地,在所述宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点之后还包括:
当所述虚拟机为非dc节点时,所述宿主机获取所述另一宿主机虚拟机的所述运行状态,判断所述另一宿主机虚拟机运行是否正常;
若正常,将所述另一宿主机虚拟机作为所述dc节点;
若异常,结束进程。
可选地,在所述宿主机接收虚拟机集群心跳发生异常的通知指令之前还包括:
在所述虚拟机转为所述dc节点后,记录所述虚拟机的信息,得出所述节点信息。
此外,本发明还提供了一种虚拟机集群的故障监控装置,该装置包括:
接收模块,用于宿主机接收虚拟机集群心跳发生异常的通知指令;
第一判断模块,用于所述宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点;
第二判断模块,用于当所述虚拟机为所述dc节点时,判断所述虚拟机运行是否正常;
第一作为模块,用于当所述虚拟机运行正常时,所述宿主机将所述虚拟机作为所述dc节点,并向另一宿主机发送消息;
第三判断模块,用于当所述虚拟机运行异常时,所述宿主机获取另一宿主机虚拟机的运行状态,判断所述另一宿主机虚拟机运行是否正常;
第二作为模块,用于当所述另一宿主机虚拟机运行正常时,将所述另一宿主机虚拟机作为所述dc节点。
可选地,还包括:
第四判断模块,用于当所述虚拟机为非dc节点时,所述宿主机获取所述另一宿主机虚拟机的所述运行状态,判断所述另一宿主机虚拟机运行是否正常;
第三作为模块,用于若正常,将所述另一宿主机虚拟机作为所述dc节点;
结束模块,用于若异常,结束进程。
可选地,还包括:
节点信息记录模块,用于在所述虚拟机转为所述dc节点后,记录所述虚拟机的信息,得出所述节点信息。
本发明所提供的一种虚拟机集群的故障监控方法及装置,通过宿主机接收虚拟机集群心跳发生异常的通知指令;宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点;当虚拟机为dc节点时,判断虚拟机运行是否正常;当虚拟机运行正常时,宿主机将虚拟机作为dc节点,并向另一宿主机发送消息;当虚拟机运行异常时,宿主机获取另一宿主机虚拟机的运行状态,判断另一宿主机虚拟机运行是否正常;当另一宿主机虚拟机运行正常时,将另一宿主机虚拟机作为dc节点。本申请通过宿主机监控虚拟机集群状态,即利用宿主机自身资源对集群进行故障监控,不用借助外置工具,降低了成本,且不借助外部因素,使得监控自主可控。
附图说明
为了更清楚的说明本发明实施例或现有技术的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例所提供的虚拟机集群故障监控方法的一种具体实施方式的流程示意图;
图2为本发明实施例所提供的虚拟机集群故障监控方式的逻辑关系流程图;
图3为本发明实施例提供的虚拟机集群故障监控装置的结构框图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参见图1,图1为本发明实施例所提供的虚拟机集群故障监控方法的一种具体实施方式的流程示意图,该方法包括以下步骤:
步骤101:宿主机接收虚拟机集群心跳发生异常的通知指令。
具体地,当虚拟机集群发送心跳中断时,即当前虚拟机集群的通信异常,虚拟机向各自的宿主机发送通知指令,以告知宿主机此刻虚拟机集群的心跳异常。而各个宿主机可以接收到相应通知指令。
需要说明的是,上述虚拟机集群可以是指包括两个虚拟机的集群,每个虚拟机各自设置在各自的宿主机上,即一个虚拟机对应一个宿主机。此时,两个宿主机都可以接收到心跳异常通知指令。
步骤102:所述宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点。
需要说明的是,上述宿主机可以是指集群中的任意一个宿主机。该宿主机在接收到通知指令之后,首先判断本地节点是否为dc节点。
上述dc节点可以是指当集群发生故障时继续处理相应资源的节点。
而上述节点信息可以是指表明宿主机节点是否为dc节点的信息,该信息可以是在虚拟机节点转换为dc节点之后,虚拟机主动通知宿主机记录的。
作为一种具体实施方式,在上述宿主机接收虚拟机集群心跳发生异常的通知指令之前还可以包括:在所述虚拟机转为所述dc节点后,记录所述虚拟机的信息,得出所述节点信息。
具体地,每个宿主机上的虚拟机转换为dc节点之后,都会通知自身宿主机,记录对应当前虚拟机为dc节点。而当宿主机上的虚拟机转换为普通节点时,也会向自身宿主机发送通知,自身宿主机可以将之前所记录的dc节点信息清除。
此时,宿主机可以根据是否存储有相应的节点信息,来判断自身虚拟机是否为dc节点。
步骤103:当所述虚拟机为所述dc节点时,判断所述虚拟机运行是否正常。
具体地,当宿主机存储有节点信息,则可以判断自身虚拟机为dc节点,然后再根据自身虚拟机的状态,来判断虚拟机是否正常运行。
而当宿主机上没有存储相应节点信息时,则其自身虚拟机不是dc节点,此时,需要判断是否可以将另一个宿主机作为dc节点。
作为一种具体实施方式,在上述宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点之后还可以包括:当所述虚拟机为非dc节点时,所述宿主机获取所述另一宿主机虚拟机的所述运行状态,判断所述另一宿主机虚拟机运行是否正常;若正常,将所述另一宿主机虚拟机作为所述dc节点;若异常,结束进程。
可以理解的是,可以判断另一宿主机是否正常运行,来确定是否可以将其作为dc节点。故可以去获取另一宿主机上的虚拟机的运行状态,根据该运行状态来判断其是否运行正常。
当然,若另一宿主机运行异常,也可以继续判断自身虚拟机是否运行正常,继而确定是否可以将自身虚拟机转换为dc节点,以保证虚拟机集群的稳定运行。
步骤104:当所述虚拟机运行正常时,所述宿主机将所述虚拟机作为所述dc节点,并向另一宿主机发送消息。
具体地,宿主机上存储有自身虚拟机的节点信息,且自身虚拟机正常运行时,则可以利用自身虚拟机来接管集群的资源,以保证虚拟机集群的稳定运行。并且向另一宿主机发送消息,告知其dc节点为自身虚拟机。
步骤105:当所述虚拟机运行异常时,所述宿主机获取另一宿主机虚拟机的运行状态,判断所述另一宿主机虚拟机运行是否正常;
需要说明的是,当本地虚拟机运行异常时,此时,不能将本地虚拟机作为dc节点。可以通过判断另一宿主机上的虚拟机运行正常与否,来确定是否可以将另一宿主机虚拟机作为dc节点,以保证虚拟机集群的稳定运行。
步骤106:当所述另一宿主机虚拟机运行正常时,将所述另一宿主机虚拟机作为所述dc节点。
为了更好地说明各个步骤之间的逻辑关系,可以参见图2,图2为本发明实施例所提供的虚拟机集群故障监控方式的逻辑关系流程图。
本发明实施例所提供的虚拟机集群故障监控方法,通过宿主机接收虚拟机集群心跳发生异常的通知指令;宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点;当虚拟机为dc节点时,判断虚拟机运行是否正常;当虚拟机运行正常时,宿主机将虚拟机作为dc节点,并向另一宿主机发送消息;当虚拟机运行异常时,宿主机获取另一宿主机虚拟机的运行状态,判断另一宿主机虚拟机运行是否正常;当另一宿主机虚拟机运行正常时,将另一宿主机虚拟机作为dc节点。该方法通过宿主机监控虚拟机集群状态,即利用宿主机自身资源对集群进行故障监控,不用借助外置工具,降低了成本,且不借助外部因素,使得监控自主可控。
下面对本发明实施例提供的虚拟机集群故障监控装置进行介绍,下文描述的虚拟机集群故障监控装置与上文描述的虚拟机集群故障监控方法可相互对应参照。
图3为本发明实施例提供的虚拟机集群故障监控装置的结构框图,参照图3虚拟机集群故障监控所装置可以包括:
接收模块31,用于宿主机接收虚拟机集群心跳发生异常的通知指令;
第一判断模块32,用于宿主机根据预记录的节点信息,判断本地节点的虚拟机是否为dc节点;
第二判断模块33,用于当虚拟机为所述dc节点时,判断虚拟机运行是否正常;
第一作为模块34,用于当虚拟机运行正常时,宿主机将虚拟机作为dc节点,并向另一宿主机发送消息;
第三判断模块35,用于当虚拟机运行异常时,宿主机获取另一宿主机虚拟机的运行状态,判断另一宿主机虚拟机运行是否正常;
第二作为模块36,用于当另一宿主机虚拟机运行正常时,将另一宿主机虚拟机作为dc节点。
可选地,还包括:
第四判断模块,用于当虚拟机为非dc节点时,宿主机获取另一宿主机虚拟机的运行状态,判断另一宿主机虚拟机运行是否正常;
第三作为模块,用于若正常,将另一宿主机虚拟机作为dc节点;
结束模块,用于若异常,结束进程。
可选地,还包括:
节点信息记录模块,用于在虚拟机转为dc节点后,记录虚拟机的信息,得出节点信息。
本发明实施例所提供的虚拟机集群故障监控装置,该装置通过宿主机监控虚拟机集群状态,即利用宿主机自身资源对集群进行故障监控,不用借助外置工具,降低了成本,且不借助外部因素,使得监控自主可控。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上对本发明所提供的虚拟机集群的故障监控方法及装置进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!