一种基于任意内核的极化码编码方法与流程
本发明涉及属于数字通信的信道编码技术领域,尤其涉及一种基于任意内核的极化码编码方法。
背景技术:
极化码(polarcodes)是2009年由e.arikan提出的一种被严格证明能够达到信道容量的构造性的信道编码方法,可以产生任意大小的内核,内核是用来生成极化码的关键,有了内核可以轻松的生成极化码的生成矩阵。这种方法可以用于生成任意大小矩阵,适用于任意长度的编码。同时,此方法生成的内核,可以产生比现在经常用的2*2大小的内核效果好。用此方法,可以减小生成矩阵的复杂度,实现起来比较简单。
于2016年11月18日,在美国内华达州里诺结束的3gpp的ran1#87会议上,3gpp确定了由华为华为等中国公司主推的的polar码方案作为5gembb(增强移动宽带)场景的控制信道编码方案。至此,5gembb(增强移动宽带)场景的信道编码技术方案完全确定,其中polar码作为控制信道的编码方案。极化码的研究越来多,对于极化码的生成也是很重要。
2008年,erdalarikan在国际信息论isit会议上首次提出了信道极化(channelpolarization)的概念;2009年在“ieeetransactiononinformationtheory”期刊上发表了一篇长达23页的论文更加详细地阐述了信道极化,并基于信道极化给出了一种新的编码方式,名称为极化码(polarcode)。极化码具有确定性的构造方法,并且是已知的唯一一种能够被严格证明“达到”信道容量的信道编码方法。
polarcode是通过引入信道极化概念而构建的。信道极化分为两个阶段,分别是信道联合和信道分裂。通过信道的联合与分裂,各个子信道的对称容量将呈现两级分化的趋势:随着码长(也就是联合信道数)n的增加,一部分子信道的容量趋于1,而其余子信道的容量趋于0。polarcode正是利用这一信道极化的现象,在容量趋于1的k个子信道上传输消息比特,在其余子信道上传输冻结比特(即收发双方已知的固定比特,通常设置为全零)。由此构成的编码即为polarcode,码率为k/n。
现有技术中极化码具有一般的二元线性分组码的基本编码要素,因而可以通过显示地写出其生成矩阵来完成编码:
其中,
生成矩阵表示为:
其中
有递归式
通过此方法可以生成编码矩阵g。
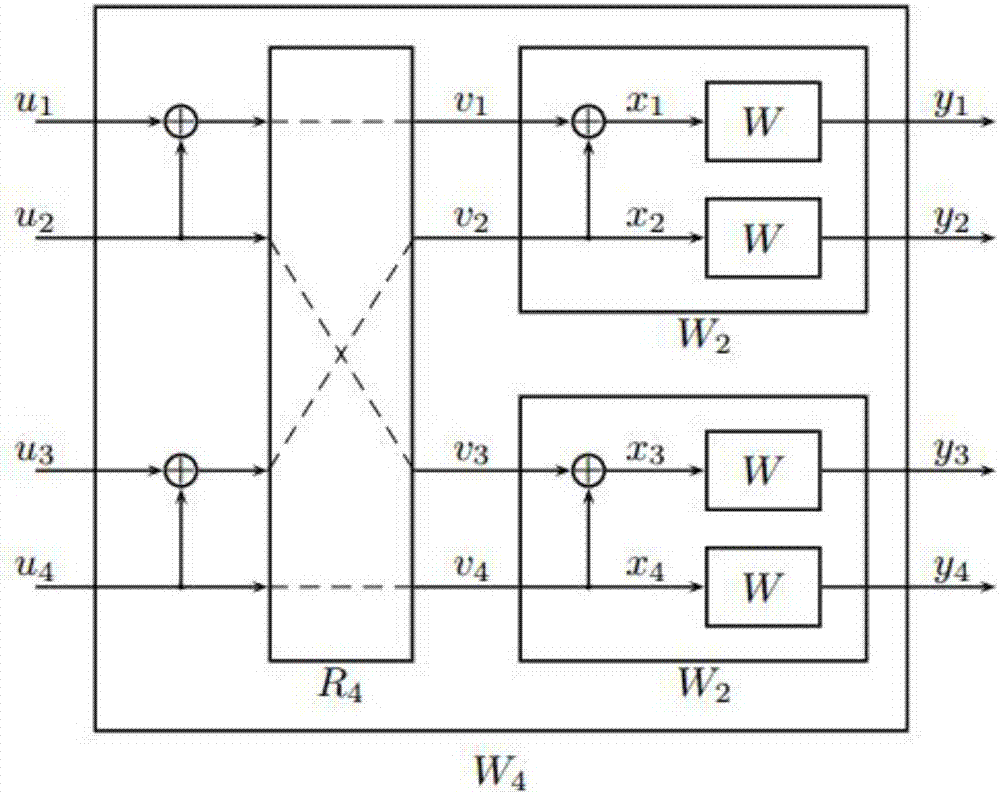
如图1所示,是一个二比特的码字编码的示意图,用的是内核
同理,如果是四比特的码字,那么就是
其生成矩阵如下:
对应的编码示意图(经过比特翻转后)如图2所示:
下面是一个8比特(经过比特翻转之后)的例子:
以此方法,可以构造出码长为n=2n的生成矩阵。而实际数字通信系统中,对码长的要求非常灵活,不一定能够满足为2的幂次的要求,那么,对于码长不是n=2n的怎么办,现有的方法是:若在构造极化码时,码长不为2的幂次,则用一组容量为零的虚拟信道将信道数补齐到2的幂次,然后按照容量等分原则对各个信道进行交织映射,再对所得到的信道进行极化变换,并在变换后的信道中,根据设计的码率选择信道容量较大的信道用于传输信息比特序列,剩余的信道则用于传输一个收发端都已知的固定比特序列。
由于现在研究普遍都是用此内核
技术实现要素:
本发明所要解决的技术问题是提供一种基于任意内核的极化码编码方法,使得极化码编码允许码长为任意大小内核,计算量小,实现简单。
本发明解决上述技术问题的技术方案如下:
一种基于任意内核的极化码编码方法,包括以下步骤:
(1)对输入的n比特数据进行因子分解,得到对应的k个内核因子qi,且满足如下关系:
其中,qi>1,取整数,i的取值范围是1到k;
(2)根据所述内核因子qi计算内核矩阵
j的取值范围是1到m;
(3)将所述k个内核矩阵
其中,
(4)将所述极化码生成矩阵gn和比特翻转矩阵进行克罗内克乘积,得到新的生成矩阵gbn:
其中,
(5)将所述新的生成矩阵gbn与原始比特序列进行计算,得到极化码。
本发明的有益效果是:本发明可以简单生成任意大小的内核因子,借此因子可以组合生成任意大小的生成矩阵,实现简便和多变极化码编码矩阵,对每一个内核因子做比特翻转可以减少信息的关联度,让信息比特之间干扰变小,可以提高整个编码的容错性能,让极化程度更加深,实现更好的纠错性能,本方法计算简单,计算量比较小。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述步骤(2)的内核矩阵
g1=[11111…1],
gm=[00000…1],
其中,
采用上述进一步方案的有益效果是,通过使用对每一个内核因子做比特翻转可以减少信息的关联度,让信息比特之间干扰变小,可以提高整个编码的容错性能,让极化程度更加深,实现更好的纠错性能。
进一步,所述比特翻转矩阵为:
其中,
所述比特翻转矩阵
当m是偶数时:
bm/2是(m/2)*(m/2)维的矩阵,bm/2由,
则bm=(b1b2...bm);
当m为奇数时,令m1=m-1,则m1为偶数;
则
bm1/2是(m1/2)*(m1/2)维的矩阵,bm1/2由,
令bs是1*m维矩阵(000…1…0)t,
其中,1在矩阵bs的下标位置为(m-1)/2,将bs插入bm1的中间位置,
则bm=(b1b2…bs…bm1-1bm1)。
采用上述进一步方案的有益效果是,对每一个内核因子做比特翻转可以减少信息的关联度,让信息比特之间干扰变小,可以提高整个编码的容错性能,让极化程度更加深,实现更好的纠错性能。
附图说明
图1为二比特码字编码示意图;
图2为四比特码字编码示意图;
图3为本发明方法流程图;
图4为本发明内核为3*3的仿真效果图;
图5为本发明不同内核的仿真效果图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图3所示,本发明提供了一种基于任意内核的极化码编码方法,其特征在于,包括以下步骤:
(1)对输入的n比特数据进行因子分解,得到对应的k个内核因子qi,且满足如下关系:
其中,qi>1,取整数,i的取值范围是1到k;
(2)根据所述内核因子qi计算内核矩阵
j的取值范围是1到m;
(3)将所述k个内核矩阵
其中,
(4)将所述极化码生成矩阵gn和比特翻转矩阵进行克罗内克乘积,得到新的生成矩阵gbn:
其中,
所述比特翻转矩阵为:
其中,
所述比特翻转矩阵
当m是偶数时:
bm/2是(m/2)*(m/2)维的矩阵,bm/2由,
则bm=(b1b2...bm);
当m为奇数时,令m1=m-1,则m1为偶数;
则
bm1/2是(m1/2)*(m1/2)维的矩阵,bm1/2由,
令bs是1*m维矩阵(000…1…0)t,
其中,1在矩阵bs的下标位置为(m-1)/2,将bs插入bm1的中间位置,
则bm=(b1b2…bs…bm1-1bm1)。
(5)将所述新的生成矩阵gbn与原始比特序列进行计算,得到极化码。
所述步骤(2)中的内核qi对应的内核矩阵
一般情况有以下规定:
g1=[11111…1],
gm=[00000…1],
其中,
一般而言,有以下几种情况是较好的可以参考,n为质素,那么直接取内核因子q=n,若n可以取对数,那么就取小对数因子m,让内核因子q=m;在生成内核矩阵时候,我们一般让第一列全为1,g1=[11111…1],其他列向量的数值从三个中取较大的一个,且一般不让产生全为0的列向量。
下面是产生任意大小的内核的具体方法:
(1)对于n比特的输入数据,进行取对数和因式分解,得到最基本的内核因子。对于素数m,不能进行因子分解,直接取其数值m为因子。例如51,内核因子就是51.其他情况,例如n=1024,直接取对数(一般取最小对数因子,其他值也可以),1024=210,直接用最基本的内核。
例如n=36,对其取对数36=62,构造大小为6*6的内核,而6=2*3,那么就构造大小为2和3的内核。
(2)得到内核因子后,用下面的方法构造出内核。
(a):假设内核因子是k,那么内核就是k*k维的矩阵。矩阵的元素取值只有两中:1和0;
(b):一般情况下:第一列的数值是2k-1,把2k-1用二进制表示出来,就是第一列的元素,也就是k个1,g1=[11…1];
对于最后一列:gk=[00...01],gk是1*k为的矩阵。
接下来的第二列一直到倒数第二列,其数值为gj=2j,gj=2j±1三个中任意选一个,把它表示为二进制,这就是gj列的元素。
通用方法是每一列都可以用此法,但是一般不要有重复的列,列的顺序可以交换。
(c):在(b)中生成的矩阵有很多种,其个数为m>3k-1个。如果码长n取对数是单一因子,用(b)中方法即可。如果是多因子的,例如6=2*3,对应的生成矩阵
此方法和用(b)产生任意一个的都不一样。
因为在本发明中所做的极化处理中的生成内核矩阵种类很多,加上比特翻转后,对于的编码方案很多,每一个编码方案性能差异很多,可以用较小的内核矩阵来先处理,计算验证每一种小内核矩阵的性能,得到最优的,然后再以内核矩阵做克罗内克乘积,就是用最优的内核矩阵来克罗内克乘积,那么性能就是最优。
如图4所示,内核为3*3的产生和效果:
用此方法产生g3(7,5,1),72=(111),52=(101),12=(001)
则
同理
以上并没全部列举出。
相应的仿真结果如下:用n=35=243,信道是高斯白噪声信道,信噪比snr=0db,
解码采用的是串行抵消列表(successivecancellationlist,scl)译码算法,并称参数l为搜索宽度。其中l=8.
如图5所示为多组不同内核的仿真图,
分别有
可以看出,不同内核对误码率是有影响的,所以提出不同内核的搭建,对极化码的研究很有必要,本方法计算简单,计算量比较小。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!