基于多视点视频特征的3D‑HEVC深度视频信息隐藏方法与流程
本发明涉及一种视频信息隐藏技术,尤其是涉及一种基于多视点视频特征的3d-hevc深度视频信息隐藏方法。
背景技术:
数字通信技术的快速发展已使得三维(3d)视频逐步走入人们日常生活,相比于传统的二维视频,其能够提供场景的深度信息,满足人们对真实性和立体感的视觉渴望。此外,三维视频技术在视频会议、远程医疗、军事以及航天等领域具有广阔的发展前景。但是,科技的进步给三维数字产品的复制、传输、视频信号处理等操作带来便利的同时,致使信息安全问题变得日益突出。信息隐藏技术作为隐秘通信和版权保护的有效手段,已成为当前研究的热点方向。
三维视频在编码过程中增加了深度信息和视点间的参考,因此二维视频的信息隐藏方法并不适用,而目前三维视频的信息隐藏技术还处在初步发展阶段。如:asikuzzaman等人提出了一种基于dibr的数字水印的算法,其采用双树复小波变换(dtcwt)将水印嵌入在中间视点yuv的色度分量上,水印既可以由中间视点提取,也可以由经过绘制的左、右视点提取,不需要原始视频参与。又如:yang等人提出了一种基于量化索引调制的3d视频盲水印算法,其将水印嵌入在深度视频的dct系数上,其具有较强的鲁棒性,能够抵抗一般的几何攻击和滤波操作。但是,上述两种方法都是针对原始域的信息隐藏,嵌入的秘密信息经编码压缩后极有可能丢失。目前,也有针对压缩域的信息隐藏,如:song等人采用一种可逆的立体视频信息隐藏算法,将秘密信息嵌入在3dmvc的b4帧中,可以避免误差漂移。又如:li等人探索三维视频的时间和视点间相关性,采用矩阵编码的方式将秘密信息嵌入到宏块中的dct系数中。但是,上述两种方法主要针对于h.264编码标准的三维视频,并不能很好地适用于3d-hevc编码标准的三维视频。3d-hevc编码标准是立体视频通信领域的一项最新的关键技术,当前三维场景主要采用多视点彩色视频加深度视频(multi-viewvideoplusdepth,mvd),而深度视频通常不用于观看,在绘制过程中转化为视差辅助信息,能够生成更多的虚拟视点,且不同于彩色视频,深度视频包含大量的平滑区域和尖锐的边缘,并且深度视频的部分失真不会影响绘制的质量,因此为了更安全地传输秘密信息和保护三维视频,研究一种3d-hevc深度视频信息隐藏方法非常必要。
技术实现要素:
本发明所要解决的技术问题是提供一种基于多视点视频特征的3d-hevc深度视频信息隐藏方法,其在压缩过程中实现信息隐藏,实现过程简单、快速,计算复杂度低,具有不可感知性和实时性,能实现解码端的盲提取,且能够保证虚拟绘制视点的质量。
本发明解决上述技术问题所采用的技术方案为:一种基于多视点视频特征的3d-hevc深度视频信息隐藏方法,其特征在于包括信息嵌入和信息提取两部分;
所述的信息嵌入部分的具体步骤为:
①_1、将原始的三维视频的左视点彩色视频和右视点彩色视频对应记为
①_2、以帧为单位依次对
①_3、判断当前帧属于
①_4、读取k中当前待嵌入的比特,设为k中的第n个比特kn;并以3d-hevc编码树的最大编码单元为单位对当前帧进行处理,将当前帧中当前待处理的最大编码单元定义为当前单元;
①_5、若当前帧对应的彩色图像中与当前单元相对应的64×64区域内存在一个像素点属于纹理区域,那么再判断当前单元中属于边缘区域的像素点的个数是否大于设定数目,如果大于设定数目,则将当前单元确定为深度图像内属于边缘区域且对应的彩色图像内相对应的64×64区域属于纹理区域的单元,记为tder,如果小于或等于设定数目,则将当前单元确定为深度图像内属于平滑区域且对应的彩色图像内相对应的64×64区域属于纹理区域的单元,记为tdsr;
若当前帧对应的彩色图像中与当前单元相对应的64×64区域内不存在像素点属于纹理区域,那么再判断当前单元中属于边缘区域的像素点的个数是否大于设定数目,如果大于设定数目,则将当前单元确定为深度图像内属于边缘区域且对应的彩色图像内相对应的64×64区域属于平坦区域的单元,记为fder,如果小于或等于设定数目,则将当前单元确定为深度图像内属于平滑区域且对应的彩色图像内相对应的64×64区域属于平坦区域的单元,记为fdsr;
①_6、根据当前单元的类型,采用不同的调制方式对当前单元的原始编码量化参数进行调制,以实现kn的嵌入,得到当前单元的调制编码量化参数,记为qp',
①_7、采用qp'对当前单元进行编码压缩,同时判断当前单元的预测模式是否为帧间skip模式或单深度帧内模式,如果是,则保留kn作为下一个最大编码单元应嵌入的比特,然后执行步骤①_8,否则,令n=n+1,读取k中下一个待嵌入的比特,然后执行步骤①_8;其中,n=n+1中的“=”为赋值符号;
①_8、将当前帧中下一个待处理的最大编码单元作为当前单元,然后返回步骤①_5继续执行,直至当前帧中的所有最大编码单元处理完毕,再执行步骤①_9;
①_9、将下一帧待编码压缩的图像作为当前帧,然后返回步骤①_3继续执行,直至
所述的信息提取部分的具体步骤为:
②_1、将嵌有加密信息的视频流记为stream.bit;
②_2、以帧为单位解析stream.bit,将stream.bit中当前待解析的图像定义为当前帧;
②_3、判断当前帧属于
②_4、以3d-hevc编码树的最大编码单元为单位解析当前帧,将当前帧中当前待解析的最大编码单元定义为当前单元;
②_5、判断当前单元的预测模式是否为帧间skip模式或单深度帧内模式,如果是,则执行步骤②_6;否则,根据当前单元的编码量化参数提取出当前单元中嵌入的比特,将提取出的当前单元中嵌入的比特记为k*,
②_6、将当前帧中下一个待处理的最大编码单元作为当前单元,然后返回步骤②_5继续执行,直至当前帧中的所有最大编码单元处理完毕,再执行步骤②_7;
②_7、将stream.bit中下一帧待解析的图像作为当前帧,然后返回步骤②_3继续执行,直至stream.bit中的所有图像处理完毕,共提取得到n个比特,按序组成提取出的加密信息,记为k*,
②_8、采用密钥key对k*进行解密,得到解密的秘密信息。
所述的步骤①_3中,利用canny检测算法确定当前帧的纹理区域和平坦区域。
所述的步骤①_3中,当前帧的边缘区域和平滑区域的确定过程为:
①_3a、利用sobel算子计算当前帧中的每个像素点的梯度值;
①_3b、对当前帧中的每个像素点的梯度值进行归一化处理,获得当前帧中的每个像素点的归一化梯度值;
①_3c、根据当前帧中的所有像素点的归一化梯度值,自适应地获取判别阈值,记为td;
①_3d、比较td与当前帧中的每个像素点的归一化梯度值来确定当前帧的边缘区域和平滑区域,具体为:对于当前帧中的任意一个像素点,若该像素点的归一化梯度值大于td,则将该像素点归属到边缘区域;若该像素点的归一化梯度值小于或等于td,则将该像素点归属到平滑区域。
所述的步骤①_3c中,
所述的步骤①_5中设定数目为32个。
所述的步骤①_6中,
与现有技术相比,本发明的优点在于:
1)本发明方法在3d-hevc编码过程中进行信息隐藏,利用深度视频不用于观看、绘制过程中转化为视差辅助信息、能够生成更多的虚拟视点的特性,通过轻微调制深度视频中的最大编码单元的编码量化参数来嵌入秘密信息,相比于传统的在彩色视频中嵌入秘密信息导致视频质量下降,本发明方法对彩色单视点无失真,而且能够保证虚拟绘制视点的质量。
2)本发明方法充分考虑到深度视频中的边缘区域对绘制视点质量会产生较大影响,而深度视频在其对应位置为彩色视频中的纹理区域会发生失真对绘制虚拟视点质量的影响更大,因此采用彩色视频中的纹理区域映射到对应的深度视频中,再根据深度视频中的边缘区域对深度视频以最大编码单元为单位进行区域划分,针对不同区域类型对编码效率的影响,采用不同的调制方式修改其最大编码单元的编码量化参数嵌入秘密信息,以达到在容易引起绘制视点失真的区域分配较多的码率,在对绘制视点失真影响较小的区域分配较少的码率,进一步提高本发明方法的性能,抑制因嵌入的秘密信息导致的码率过快增长。
3)本发明方法选择秘密信息嵌入的载体为深度视频中的编码量化参数值,相比于压缩域的dct系数、其他语法元素等嵌入载体会产生误差漂移的缺点,本发明方法在量化过程前根据秘密信息修改最大编码单元的编码量化参数,然后采用修改后的编码量化参数压缩编码,无误差漂移现象产生,进一步减少了绘制视点质量的下降。
4)本发明方法在信息嵌入部分中利用密钥加密待嵌入的秘密信息,有效地提高了本发明方法的安全性。
5)本发明方法嵌入秘密信息和提取秘密信息的实现过程简单、快速,计算复杂度低,具有不可感知性和实时性,且提取过程无需原始三维视频参与,从而能实现解码端的盲提取。
附图说明
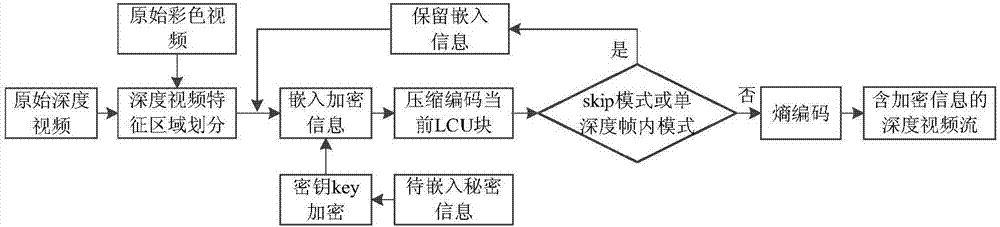
图1a为本发明方法的信息嵌入部分的总体实现框图;
图1b为本发明方法的信息提取部分的总体实现框图;
图2a为原始的newspaper三维视频序列编码重建得到的三维视频序列绘制的5视点的第60帧图像;
图2b为原始的undodancer三维视频序列编码重建得到的三维视频序列绘制的3视点的第60帧图像;
图2c为newspaper三维视频序列经本发明方法处理后编码重建得到的三维视频序列绘制的5视点的第60帧图像;
图2d为undodancer三维视频序列经本发明方法处理后编码重建得到的三维视频序列绘制的3视点的第60帧图像。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于多视点视频特征的3d-hevc深度视频信息隐藏方法,其包括信息嵌入和信息提取两部分。
所述的信息嵌入部分的总体实现框图如图1a所示,其具体步骤为:
①_1、将原始的三维视频的左视点彩色视频和右视点彩色视频对应记为
在此,原始秘密信息可以为图像、语音、文字等;密钥key可自行设定。
①_2、以帧为单位依次对
①_3、判断当前帧属于
在此具体实施例中,步骤①_3中,利用canny检测算法确定当前帧的纹理区域和平坦区域。
在此具体实施例中,步骤①_3中,当前帧的边缘区域和平滑区域的确定过程为:
①_3a、利用sobel算子计算当前帧中的每个像素点的梯度值。
①_3b、对当前帧中的每个像素点的梯度值进行归一化处理,获得当前帧中的每个像素点的归一化梯度值。
①_3c、根据当前帧中的所有像素点的归一化梯度值,自适应地获取判别阈值,记为td,
①_3d、比较td与当前帧中的每个像素点的归一化梯度值来确定当前帧的边缘区域和平滑区域,具体为:对于当前帧中的任意一个像素点,若该像素点的归一化梯度值大于td,则将该像素点归属到边缘区域;若该像素点的归一化梯度值小于或等于td,则将该像素点归属到平滑区域。
①_4、读取k中当前待嵌入的比特,设为k中的第n个比特kn;并以3d-hevc编码树的最大编码单元(lcu,尺寸大小为64×64)为单位对当前帧进行处理,将当前帧中当前待处理的最大编码单元定义为当前单元。
①_5、若当前帧对应的彩色图像(当前帧属于
若当前帧对应的彩色图像中与当前单元相对应的64×64区域内不存在像素点属于纹理区域(即全部像素点属于平坦区域),那么再判断当前单元中属于边缘区域的像素点的个数是否大于设定数目,如果大于设定数目,则将当前单元确定为深度图像内属于边缘区域且对应的彩色图像内相对应的64×64区域属于平坦区域的单元,记为fder,如果小于或等于设定数目,则将当前单元确定为深度图像内属于平滑区域且对应的彩色图像内相对应的64×64区域属于平坦区域的单元,记为fdsr。
在此具体实施例中,步骤①_5中设定数目为32个。
①_6、根据当前单元的类型,采用不同的调制方式对当前单元的原始编码量化参数进行调制,以实现kn的嵌入,得到当前单元的调制编码量化参数,记为qp',
在此具体实施例中,步骤①_6中,
①_7、采用qp'对当前单元进行编码压缩,同时判断当前单元的预测模式是否为帧间skip模式或单深度帧内模式(单深度帧内模式是3d-hevc编码标准新增的专门针对深度视频平坦区域的编码模式,该编码模式不需要变换量化过程),如果是,则保留kn作为下一个最大编码单元应嵌入的比特,然后执行步骤①_8,否则,令n=n+1,读取k中下一个待嵌入的比特,然后执行步骤①_8;其中,n=n+1中的“=”为赋值符号。
①_8、将当前帧中下一个待处理的最大编码单元作为当前单元,然后返回步骤①_5继续执行,直至当前帧中的所有最大编码单元处理完毕,再执行步骤①_9。
①_9、将下一帧待编码压缩的图像作为当前帧,然后返回步骤①_3继续执行,直至
所述的信息提取部分的总体实现框图如图1b所示,其具体步骤为:
②_1、将嵌有加密信息的视频流记为stream.bit。
②_2、以帧为单位解析stream.bit,将stream.bit中当前待解析的图像定义为当前帧。
②_3、判断当前帧属于
②_4、以3d-hevc编码树的最大编码单元(lcu)为单位解析当前帧,将当前帧中当前待解析的最大编码单元定义为当前单元。
②_5、判断当前单元的预测模式是否为帧间skip模式或单深度帧内模式,如果是,则执行步骤②_6;否则,根据当前单元的编码量化参数提取出当前单元中嵌入的比特,将提取出的当前单元中嵌入的比特记为k*,
②_6、将当前帧中下一个待处理的最大编码单元作为当前单元,然后返回步骤②_5继续执行,直至当前帧中的所有最大编码单元处理完毕,再执行步骤②_7。
②_7、将stream.bit中下一帧待解析的图像作为当前帧,然后返回步骤②_3继续执行,直至stream.bit中的所有图像处理完毕,共提取得到n个比特,按序组成提取出的加密信息,记为k*,
②_8、采用密钥key对k*进行解密,得到解密的秘密信息。
为验证本发明方法的有效性和可行性,对本发明方法进行试验。
采用3d-hevc平台的参考软件htm13.0进行仿真测试,测试环境为标准测试环境。测试序列选择3d-hevc的标准测试序列,balloons三维视频序列的1视点和5视点、newspaper三维视频序列的4视点和6视点、shark三维视频序列的1视点和9视点、undodancer三维视频序列的1视点和5视点,前两个三维视频序列的分辨率为1024×768,后两个三维视频序列的分辨率为1920×1088。编码参数为:编码帧数为120帧,帧率为30f/s,i帧间隔24帧,图像组的大小为8,开启码率控制,其余均为默认配置。下面分别从主客观视频质量、嵌入容量和比特率变化等方面来评价本发明方法的性能。
1)三维视频序列的主客观质量
由于深度视频主要用于虚拟视点的绘制,不用于用户的观看,因此通过评价绘制的虚拟视点的质量体现深度视频质量的变化。选取newspaper三维视频序列和undodancer三维视频序列来进行说明本发明方法的主观效果。图2a给出了原始的newspaper三维视频序列编码重建得到的三维视频序列绘制的5视点的第60帧图像;图2b给出了原始的undodancer三维视频序列编码重建得到的三维视频序列绘制的3视点的第60帧图像;图2c给出了newspaper三维视频序列经本发明方法处理后编码重建得到的三维视频序列绘制的5视点的第60帧图像;图2d给出了undodancer三维视频序列经本发明方法处理后编码重建得到的三维视频序列绘制的3视点的第60帧图像。从主观感知上,利用本发明方法嵌入秘密信息并没有引起视频绘制图像的视觉感知失真,具有较好的视觉不可见性。
本发明方法采用代表性指标即峰值信噪比(peaksignal-noise-ratio,psnr)进一步证明本发明方法的视觉不可感知性。表1给出了三维视频序列经本发明方法处理后编码重建的绘制视点的质量与三维视频序列未经本发明方法处理的编码重建得到绘制视点的质量,表1中嵌入秘密信息前后峰值信噪比的变化量表示为δpsnr,δpsnr=psnrpro-psnrorg,其中,psnrpro表示经本发明方法处理后深度视频所绘制的虚拟视点与原始视点之间的峰值信噪比,psnrorg表示原始深度视频所绘制的虚拟视点与原始视点之间的峰值信噪比。
表1三维视频序列经本发明方法处理后编码重建的绘制视点的质量与三维视频序列未经本发明方法处理的编码重建得到绘制视点的质量
从表1中可以看出,在不同目标码率下编码三维视频序列,重建后绘制视点的质量不同,由于给定的目标码率增加,分配给视点的码率也在增加,视频编码的质量不断提高。嵌入秘密信息后绘制视点的峰值信噪比比原始绘制该视点的峰值信噪比平均下降0.0015db,而且嵌入秘密信息前后绘制视点视频序列的峰值信噪比的差异范围在-0.0062~0.0122db,表明秘密信息的嵌入没有导致三维视频序列的客观质量的明显变化,同时部分三维视频序列,例如newspaper三维视频序列在较高目标码率下,绘制质量得到轻微提升,主要因为本发明方法结合多视点视频的特征指导秘密信息的嵌入,且对编码量化参数进行微调,能较好地保障绘制视点的客观质量。
2)嵌入容量和码率变化
采用码率的变化率来衡量本发明方法对目标码率产生的影响,将码率的变化率表示为bri,
表2三维视频序列采用本发明方法的嵌入容量和码率的变化率的测试结果
从表2可知,不同的三维视频序列的嵌入容量有较大的差异,总体上在不同的目标码率下都保持了较大的嵌入容量。每个三维视频序列的平均嵌入容量为6656比特,码率的变化率平均增长0.0572%,同时undodancer和balloons三维视频序列在较高目标码率下,码率的变化率有所降低,说明本发明方法能提供较高的嵌入容量,且对编码码流影响较小,主要由于利用多视点视频特征,选择性地对编码量化参数进行修改,同时开启码率控制模块,有效地控制了码率的改变。
- 还没有人留言评论。精彩留言会获得点赞!