一种移动用户异常行为检测方法与流程
本发明涉及信息安全可信技术领域,具体涉及一种基于选择性聚类融合的移动用户异常行为检测方法。
背景技术:
随着internet的广泛应用,整个人类社会的生活与工作正在逐渐被计算机技术、网络技术及通信技术所影响和改变着。随着智能终端的快速普及和移动互联网的迅猛发展,许多用户将互联网入口从pc端转移到了智能手机等移动智能终端,云计算技术在移动通信行业的应用必然会开创移动互联网的新时代。目前移动云服务所涉及的安全性等可信要求大多相对较低,移动云服务所涉及的各个要素和环节的可信性已成为阻碍移动云服务发展和广泛应用的重要障碍。本文旨在从用户可信方面研究用户协作层的异常行为分析技术,立足移动终端的固有缺陷,向用户提供低耗、高效、可靠的满意服务。只有当用户行为是正常合法的,用户的请求才会被智慧映射层接收,进行进一步的处理。
聚类融合技术是将多个对一组对象进行聚类划分的不同结果进行合并的技术,合并后的结果比原先单一聚类的结果更加优越,稳定性和精确性都得到了明显提升。选择性聚类融合是利用设计的选择策略对聚类成员进行筛选,选出优质的聚类成员再进行融合,提高了聚类结果的质量。
现有的选择性聚类融合算法一般采用差异度计算公式来对聚类成员的差异度进行衡量,从而选择优质的成员。而仅仅依据差异度来选择聚类成员容易造成检测结果误报率高,所以必须联合多方面因素考量,才能取得较好的结果。
技术实现要素:
为了克服现有技术中来选择聚类成员容易造成检测结果误报率高的问题,本发明提供了一种移动用户异常行为检测方法,其采用滑动窗口动态的获取数据,以提高用户行为获取的准确性,在传统fc算法的初始聚类和增量阶段之后引入duun_index概念,对增量后产生的聚类成员进行选择,再将选择后的优质成员用投票算法进行融合得到最终结果,再与用户的正常行为进行相似度对比时引入关联矩阵,利用平均差异度的变化来判断用户行为是否正常,从而达到异常检测高效、准确的目的。
本发明为解决上述问题所采用的技术方案是:一种移动用户异常行为检测方法,其技术方案是:包含以下步骤:
s1.对数据集进行训练,建立正常行为数据库;
s2.利用滑动窗口模型获取移动用户窗口范围内的数据集x,采用基于分形的聚类融合算法得到数据集x的聚类融合结果γ;
s3.异常检测过程:
s301.对s2步骤得到的聚类融合结果γ与s1步骤中的正常行为数据库中的n个正常行为数据p={p1,p2,...,pn}进行关联矩阵转换,得到相应的关联矩阵m={m1,m2,...,mn};
s302.对s1步骤中的正常行为数据库中的n个正常行为数据p={p1,p2,...,pn}进行平均差异度计算;
s303.把s2步骤得到的聚类融合结果γ加入到正常行为数据集p中,再次进行平均差异度计算;
s304.对s302步骤和s303步骤得到的差异度进行比较,如果s303步骤得到的差异度小于s302步骤得到的差异度,则s2步骤中的数据集x为正常行为,将s1步骤中的正常行为数据库更新为n+1个聚类结果的聚类成员集合;如果s303步骤得到的差异度大于s302步骤得到的差异度,则s2步骤中的数据集x确定为异常行为。
进一步的,所述的s2步骤中的基于分形的聚类融合算法的过程是:
s201.初始聚类过程:
s2011.利用滑动窗口模型获取移动用户窗口范围内的数据集x;
s2012.将s2011步骤获得的数据集x随机划分为h组数据子集
{xi}(i=1,2,...,h),并对xi进行k-means聚类,每组数据子集产生k个簇并记录每一个簇的聚类中心,共得到h组聚类中心;
s2013.利用s2012步骤得到的h组聚类中心对数据集x重新k-means聚类,得到数据集x的初始聚类集合λ={λ1,λ2,...,λh},其中
s202.增量过程:
s2021.对在s2011步骤中尚未分配的点b,与s2013步骤中得到的聚类集合ci求并集得到用户全部数据ci′=ci∪b(i=1,2,...,h);分别计算ci与ci'的分形维数fi、fi'及其分形影响度fidi=|fi-fi'|,相互比较后得到fidi的值最小的一个
s2022.遴选s2013步骤中的数据集x的初始聚类集合,保存满足公式
min|fi-fi'|<fidε的聚类类别;
s203:筛选融合过程:
s2031.设定阈值diε,利用duun_index算法对满足s2022步骤的聚类成员进行处理,得到类间离间距离高于设定阈值diε的聚类成员λ′={λ′1,λ′2,...,λ′h},其中,h≤h,低于设定阈值的不再考虑;
s2032.利用投票法对s2031步骤得到的高于设定阈值diε的聚类成员进行融合得到最终的聚类结果γ。
进一步的,所述的步骤s2031中类间离间距离的得到过程如下:
diam(ci)函数用来测量一个类的点的直径
优选的,所述的s2031步骤中的阈值diε=3.5。
进一步的,所述的s2032步骤中的投票法是指:设定一个矩阵matrix[n][z],n为数据集中s2步骤中的数据x中的数据个数,z为类的个数,用来存放每个数据xi针对某个类zi的出现的次数;最后扫描矩阵matrix[n][z],记录每个数据xi属于某个类zi的最大次数;把该数据xi归入次数最大的列所标识的类,得到最终的聚类结果γ。
进一步的,所述的s301步骤中的关联矩阵转换过程是:将s1骤中的n个正常行为的聚类成员集合p={p1,p2,...,pn},与意正常行为聚类成员pi,其关联矩阵为:
进一步的,所述的s303步骤中的平均差异度定义过程如下:
其中mi和mj是正常行为数据集p={p1,p2,...,pn}相应的关联矩阵m={m1,m2,...,mn}中的任意两个成员,||mi,mj||是指两个矩阵的相似性计算;1≤i≤n,1≤j≤n。
本发明的有益效果是:本发明采用滑动窗口动态的获取数据,以提高用户行为获取的准确性,在传统fc算法的初始聚类和增量阶段之后引入duun_index概念,对增量后产生的聚类成员进行选择,再将选择后的优质成员用投票算法进行融合得到最终结果,再与用户的正常行为进行相似度对比时引入关联矩阵,利用平均差异度的变化来判断用户行为是否正常,从而达到异常检测高效、准确的目的。
附图说明
图1为本发明流程图。
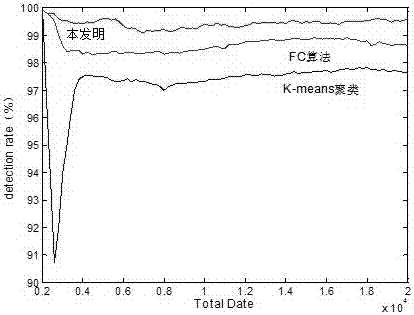
图2为本发明、fc算法和k-means聚类算法检测率对比图。
图3为本发明、fc算法和k-means聚类算法准确率对比图。
图4为本发明、fc算法和k-means聚类算法误报率对比图。
具体实施方式
下面结合附图对本发明进行进一步的说明。
如图1,一种移动用户异常行为检测方法,其技术方案是:包含以下步骤:
s1.对数据集进行训练,建立正常行为数据库;
s2.利用滑动窗口模型获取移动用户窗口范围内的数据集x,采用基于分形的聚类融合算法得到数据集x的聚类融合结果γ;
s3.异常检测过程:
s301.对s2步骤得到的聚类融合结果γ与s1步骤中的正常行为数据库中的n个正常行为数据p={p1,p2,...,pn}进行关联矩阵转换,得到相应的关联矩阵m={m1,m2,...,mn};
s302.对s1步骤中的正常行为数据库中的n个正常行为数据
p={p1,p2,...,pn}进行平均差异度计算;
s303.把s2步骤得到的聚类融合结果γ加入到正常行为数据集p中,再次进行平均差异度计算;
s304.对s302步骤和s303步骤得到的差异度进行比较,如果s303步骤得到的差异度小于s302步骤得到的差异度,则s2步骤中的数据集x为正常行为,将s1步骤中的正常行为数据库更新为n+1个聚类结果的聚类成员集合;如果s303步骤得到的差异度大于s302步骤得到的差异度,则s2步骤中的数据集x确定为异常行为。
需要明确的是:现有技术中的异常行为检测方法k-means聚类算法和fc聚类算法相比,本发明增加了s3步骤,可以明确的检测出移动用户异常行为,提高了检测的准确率。
进一步的,所述的s2步骤中的基于分形的聚类融合算法的过程是:
s201.初始聚类过程:
s2011.利用滑动窗口模型获取移动用户窗口范围内的数据集x,滑动窗口模型以外的数据b备用;
s2012.将s2011步骤获得的数据集x随机划分为h组数据子集
{xi}(i=1,2,...,h),并对xi进行k-means聚类,每组数据子集产生k个簇并记录每一个簇的聚类中心,共得到h组聚类中心;
s2013.利用s2012步骤得到的h组聚类中心对数据集x重新k-means聚类,得到数据集x的初始聚类集合λ={λ1,λ2,...,λh},其中
s202.增量过程:
s2021.对在s2011步骤中尚未分配的点b,与s2013步骤中得到的聚类集合ci求并集得到用户全部数据ci′=ci∪b(i=1,2,...,h);分别计算ci与ci'的分形维数fi、fi'及其分形影响度fidi=|fi-fi'|,相互比较后得到fidi的值最小的一个
s2022.遴选s2013步骤中的数据集x的初始聚类集合,保存满足公式
min|fi-fi'|<fidε的聚类类别;
s203:筛选融合过程:
s2031.设定阈值diε,利用duun_index算法对满足s2022步骤的聚类成员进行处理,得到类间离间距离高于设定阈值diε的聚类成员λ′={λ′1,λ′2,...,λ′h},其中,h≤h,低于设定阈值的不再考虑;
s2032.利用投票法对s2031步骤得到的高于设定阈值diε的聚类成员进行融合得到最终的聚类结果γ。
需要明确的是:聚类融合算法是现有技术中常用的计算方法。而在现有的聚类融合算法之中,增加了s2031步骤,增加了阈值diε,解决了聚类融合的质量的问题(增量阶段之后产生多个聚类成员,成员的聚类质量参差不齐,如果把所有成员都进行融合,势必会影响聚类的效果,可能还不如原先单一聚类的质量高)。
需要明确的是:duun_index算法是一种公开的算法,由anastasiosdrosouanddimitriostzovaras公布于ieeeicc2015《amulti-objectiveclusteringapproachforthedetectionofabnormalbehaviorsinmobilenetworks》。
进一步的,所述的步骤s2031中类间离间距离的得到过程如下:
其中,其中dist(ci,cj)函数表示聚类的类间离间距离
diam(ci)函数用来测量一个类的点的直径
需要明确的是:显然,di越大,类间离间的可视化就越清晰,聚类效果也就越好。在此,我们要设定一个阈值diε,高于阈值diε的视为优质聚类结果,低于阈值diε的则不进入最后的融合阶段。
优选的,所述的s2031步骤中的阈值diε=3.5。
进一步的,所述的s2032步骤中的投票法是指:设定一个矩阵matrix[n][z],n为数据集中s2步骤中的数据x中的数据个数,z为类的个数,用来存放每个数据xi针对某个类zi的出现的次数;最后扫描矩阵matrix[n][z],记录每个数据xi属于某个类zi的最大次数;把该数据xi归入次数最大的列所标识的类,得到最终的聚类结果γ。
进一步的,所述的s301步骤中的关联矩阵转换过程是:将s1骤中的n个正常行为的聚类成员集合p={p1,p2,...,pn},与意正常行为聚类成员pi,其关联矩阵为:
进一步的,所述的s303步骤中的平均差异度定义过程如下:
其中mi和mj是正常行为数据集p={p1,p2,...,pn}相应的关联矩阵m={m1,m2,...,mn}中的任意两个成员,||mi,mj||是指两个矩阵的相似性计算;1≤i≤n,1≤j≤n。
实验过程:本发明实验硬件环境为intelcorei5-2400cpu,主频3.10ghz,内存4gb,操作系统为win7,64位,编程工具使用matlab(r2010a)。本发明在上述实验环境下对本发明进行测试。
本发明s1步骤采用的正常行为数据库为kddcup99数据集,此数据集是1998年美国国防部高级规划署(darpa)在mit林肯实验室进行了一项入侵检测评估项目而建立的测试数据集。
为了达到本发明检测用户异常行为的目的,考虑检测率(detectionrate,dr)、准确率(accuracyrate,ar)和误报率(errorrate,er)这三个指标。
dr=检测到的攻击样本数/攻击样本总数×100%
ar=所有被检测到的异常样本数/异常样本数×100%
er=所有正常样本被误报为异常的样本数/正常样本数×100%
本文采用的kdd99数据集共有数据点4898431个,如果直接对数据集进行建模,会消耗大量资源。因此,从数据集中随机选取20000条数据作为实验数据,其中取出1000条数据进行初始化,然后模拟数据流环境,将剩下的数据用滑动窗口不停的获取。滑动窗口得到的数据集x划分成h=20个基本数据子集,把判定是否为离群点的阈值fidε设置为0.01,diε设置为3.50。
检测率:一个检测率较高的方法能够更加准确的分析异常行为,中断攻击行为的顺利进行,有效保护用户个人行为数据。检测率为检测到的攻击样本数与攻击样本总数之比。由图2可知,在测试样本数量极少的时候本发明的检测率都能达到100%,当样本数量在2000-4000的时候发生了异常攻击,但是k-means聚类的用户异常行为不能很好的检测出该攻击行为,误将该行为认为是正常行为,所以造成检测率急速降低。此时,fc聚类算法和本文算法的用户异常行为分析方法可以很好的识别出该攻击行为,所以检测率保持稳定。随着测试样本数量的增加,本发明所述的用户异常行为分析方法表现出了明显的优势,相比于传统的fc聚类算法,本文算法增加了选择步骤,减少了劣质聚类成员对融合结果的干扰,提高了聚类质量,使得检测率相对比较高,并且比较稳定。
准确率:为所有异常样本被检测到的样本数与异常样本数之比,由图3可以看出,3种用户异常分析算法在检测样本数量极少的情况下,准确率可以达到100%,由于样本数量在2000-4000的时候发生了异常攻击,造成了k-means聚类的用户异常行为准确率的急速降低,而另外两种检测方法可以检测出异常攻击使得准确率相对来说比较稳定。随着样本数量的增加,本发明的检测率较高且趋于平稳。
误报率:是指正常样本被误认为是异常样本的个数与总异常样本量个数之比,由图4可以看出,对于三种检测方法,误报率随着样本数的增多逐渐增大,但是相比于其他两种算法,本发明所用到的用户异常行为分析方法的误报率相对较低,表明该算法对用户的异常行为有较好的识别能力。
本发明基于分形模型,提出了一种选择性分形聚类融合算法用于用户的异常行为检测方法,在传统的fc挖掘算法只能满足一般高维数据的实时动态挖掘却没有很高准确性的基础上,本发明既实现了对任意形状数据的挖掘,也提高了分形聚类结果的准确性和有效性,在用户异常行为检测中也能够准确有效地完成聚类任务,且适用于高维、海量的数据,可应用于空间数据聚类、商业数据聚类等领域。实验表明,本发明的检测率和准确率都有明显提升,具有良好的鲁棒性,可以较好的在用户和云环境之间建立一个相互的信任关系,成为云服务环境可信的有效前提。
- 还没有人留言评论。精彩留言会获得点赞!