一种微引擎及其处理报文的方法与流程
本发明涉及网络处理器技术领域,尤其涉及一种微引擎及其处理报文的方法。
背景技术:
为了满足未来网络对金融实时交易、4k/8k超高清(ultrahighdefinition,uhd)视频、虚拟现实、远程实时控制、第五代(5g)移动通信等时序敏感类业务的支持,处于因特网(internet)骨干位置的核心路由器必须支持实现报文的低延时、低抖动传输。
在高端路由器市场,网络处理器以其杰出的报文处理性能及可编程性已经成为构成路由转发引擎不可替代的部分。在网络处理器系统中,微引擎(me,microengine)是网络处理器的核心部件。传统的网络处理器me采用多线程单流水线的细粒度多线程结构方式,虽然这种方法可以通过切换线程来降低调度上的延时时间及流水线的空闲时间比率,但是,当网络处理器性能需求增加一倍时,处理器内核的数量至少要增加一倍,导致在设计网络处理器架构时出现瓶颈。并且,传统的网络处理器内核大多不支持对低延时报文优先处理能力,因此无法预估低延时报文在网络处理器内核中的处理时间。
技术实现要素:
为了解决上述技术问题,本发明提供了一种微引擎及其处理报文的方法,能够在不增加内核数量的基础上提高网络处理器的性能。
为了达到本发明目的,本发明实施例的技术方案是这样实现的:
本发明实施例提供了一种微引擎处理报文的方法,包括:
微引擎对接收到的报文进行线程分配,并将线程分成若干个线程组;
微引擎从每个线程组中选择一个线程,获取各个线程对应的指令并发射到若干条流水线中;
各条流水线执行完所述指令中的发包指令后,微引擎将报文调度出内核并释放线程。
进一步地,所述从每个线程组中选择一个线程,具体包括:
从所述每个线程组中选择所述线程时,低延时报文对应的线程的优先级高于非低延时报文对应的线程的优先级。
进一步地,所述方法还包括:所述微引擎通过报文头中的标记位来确定报文为低延时报文或非低延时报文。
进一步地,在所述获取各个线程对应的指令时,当前取回的指令执行完后的重新取指指令、跳转指令执行完后的取指指令、新包的取指指令,三者对应的线程的优先级由高到低排列。
进一步地,所述线程组为两个,所述流水线为两条。
本发明实施例还提供了一种微引擎,包括线程管理模块、指令拾取模块、暂停指令调度器模块和指令缓存模块,其中:
线程管理模块,用于对接收到的报文进行线程分配,通知指令拾取模块;
指令拾取模块,用于接收到线程管理模块的通知,将线程分成若干个线程组,从每个线程组中选择一个线程,从指令缓存模块获取各个线程对应的指令并发射到若干条流水线中,各条流水线执行完所述指令中的发包指令后通知暂停指令调度器模块;
暂停指令调度器模块,用于接收到指令拾取模块的通知,将报文调度出内核并释放线程;
指令缓存模块,用于存储各个线程对应的指令。
进一步地,所述指令拾取模块从每个线程组中选择一个线程,具体包括:
从所述每个线程组中选择所述线程时,低延时报文对应的线程的优先级高于非低延时报文对应的线程的优先级。
进一步地,所述指令拾取模块通过报文头中的标记位来确定报文为低延时报文或非低延时报文。
进一步地,在所述获取各个线程对应的指令的步骤中,当前取回的指令执行完后的重新取指指令、跳转指令执行完后的取指指令、新包的取指指令,三者对应的线程的优先级由高到低排列。
进一步地,所述线程组为两个,所述流水线为两条。
本发明的技术方案,具有如下有益效果:
本发明提供的微引擎及其处理报文的方法,通过设置若干个线程组和若干条流水线,实现了在不增加内核数量的基础上成倍地提高网络处理器的性能;
进一步地,通过设置低延时报文高优先级调度方式,有效地控制了网络处理器内核处理低延时报文的时间。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例的一种微引擎处理报文的方法的流程示意图;
图2为本发明实施例的一种微引擎的结构示意图;
图3为本发明第一优选实施例的微引擎的结构示意图;
图4为本发明第二优选实施例的微引擎的结构示意图;
图5为本发明优选实施例的线程状态转化示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
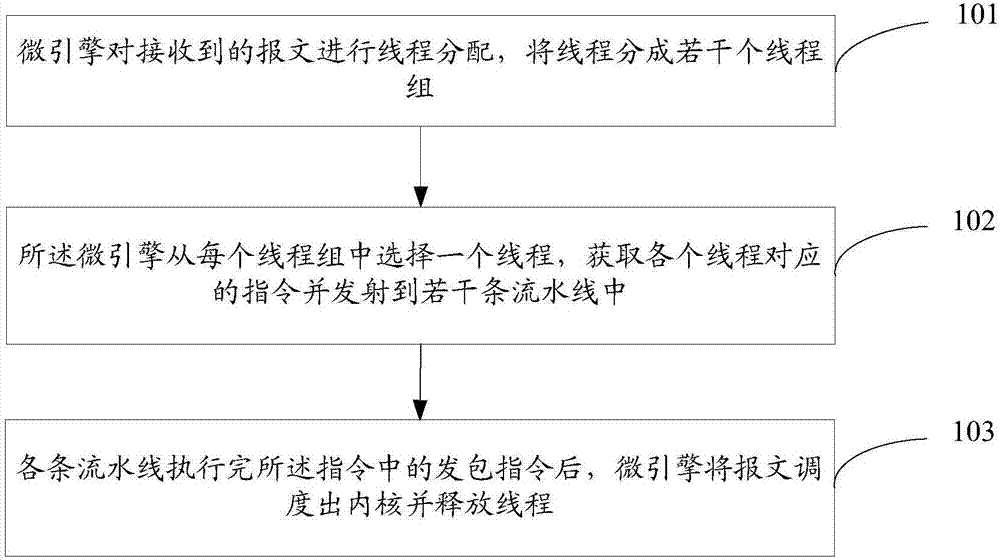
如图1所示,根据本发明的一种微引擎处理报文的方法,包括如下步骤:
步骤101:微引擎对接收到的报文进行线程分配,并将线程分成若干个线程组;
值得说明的是,在进行线程分配时,所述微引擎不区分低延时报文或非低延时报文。
步骤102:微引擎从每个线程组中选择一个线程,获取各个线程对应的指令并发射到若干条流水线中;
进一步地,所述从每个线程组中选择一个线程,具体包括:
根据每个线程的取指指令预解析以及线程在流水线中的执行情况,从每个线程组中选择一个线程。
在本发明一实施例中,所述从每个线程组中选择一个线程,具体包括:
从所述每个线程组中选择所述线程时,低延时报文对应的线程的优先级高于非低延时报文对应的线程的优先级。
需要说明的是,传统的最近最少使用(leastrecentlyused,lru)调度算法可以保证最频繁使用的线程能够拥有最高优先级,当内核中线程变多时,一个低延时报文进入内核调度必须要等到先进入内核的普通报文的线程处理完后才能处理,如果普通报文在内核中执行的指令数目很多或者因查表等指令次数和等待的时间很长,则不能保证满足低延时报文的低延时需求。本发明针对低延时报文优化了lru调度算法,将准备(ready)状态的线程分成多组,各组线程分别采用lru调度算法以及低延时报文优先策略选择一个线程,获取该线程对应的指令发射到对应流水线,由流水线去处理指令。
进一步地,所述方法还包括:所述微引擎通过报文头中的标记位来确定报文为低延时报文或非低延时报文。
例如,所述低延时报文可以根据ieee802.3br规范实现,微引擎通过报文头中的标记位来确定报文是否为低延时报文,标记位由网络处理器中的报文解析模块完成。
在本发明另一实施例中,在所述获取各个线程对应的指令时,当前取回的指令执行完后的重新取指指令、跳转指令执行完后的取指指令、新包的取指指令,三者对应的线程的优先级由高到低排列。
具体地,所述线程组可以为两个,对应的流水线条数可以为两条。
在本发明一实施例中,每个线程组中的线程的个数可以为20个或其它任意个数。
在本发明一实施例中,所述流水线可以分为七级流水或其它级数的流水。
步骤103:各条流水线执行完所述指令中的发包指令后,微引擎将报文调度出内核并释放线程。
值得说明的是,所述线程释放后,可以重新分配给下一个新包使用。
如图2所示,根据本发明的一种微引擎,包括线程管理模块、指令拾取模块、暂停指令调度器模块和指令缓存模块,其中:
线程管理模块,用于对接收到的报文进行线程分配,通知指令拾取模块;
指令拾取模块,用于接收到线程管理模块的通知,将线程分成若干个线程组,从每个线程组中选择一个线程,从指令缓存模块获取各个线程对应的指令并发射到若干条流水线中,各条流水线执行完所述指令中的发包指令后通知暂停指令调度器模块;
暂停指令调度器模块,用于接收到指令拾取模块的通知,将报文调度出内核并释放线程;
指令缓存模块,用于存储各个线程对应的指令。
进一步地,所述指令拾取模块从每个线程组中选择一个线程,具体包括:
根据每个线程的取指指令预解析以及线程在流水线中的执行情况,从每个线程组中选择一个线程。
在本发明一实施例中,所述指令拾取模块从每个线程组中选择一个线程,具体包括:
从所述每个线程组中选择所述线程时,低延时报文对应的线程的优先级高于非低延时报文对应的线程的优先级。
需要说明的是,传统的最近最少使用(leastrecentlyused,lru)调度算法可以保证最频繁使用的线程能够拥有最高优先级,当内核中线程变多时,一个低延时报文进入内核调度必须要等到先进入内核的普通报文的线程处理完后才能处理,如果普通报文在内核中执行的指令数目很多或者因查表等指令次数和等待的时间很长,则不能保证满足低延时报文的低延时需求。本发明针对低延时报文优化了lru调度算法,将准备(ready)状态的线程分成多组,各组线程分别采用lru调度算法以及低延时报文优先策略选择一个线程,获取该线程对应的指令发射到对应流水线,由流水线去处理指令。
进一步地,所述指令拾取模块可以通过报文头中的标记位来确定报文为低延时报文或非低延时报文。
例如,所述低延时报文可以根据ieee802.3br规范实现,微引擎通过报文头中的标记位来确定报文是否为低延时报文,标记位由网络处理器中的报文解析模块完成。
在本发明另一实施例中,在所述获取各个线程对应的指令的步骤中,当前取回的指令执行完后的重新取指指令、跳转指令执行完后的取指指令、新包的取指指令,三者对应的线程的优先级由高到低排列。
具体地,所述线程组可以为两个,对应的流水线条数可以为两条。
在本发明一实施例中,每个线程组中的线程的个数可以为20个或其它任意个数。
在本发明一实施例中,所述流水线可以分为七级流水或其它级数的流水。
本发明实施例还提供了几个优选的实施例对本发明进行进一步解释,但是值得注意的是,该优选实施例只是为了更好的描述本发明,并不构成对本发明不当的限定。下面的各个实施例可以独立存在,且不同实施例中的技术特点可以组合在一个实施例中联合使用。
结合图3所示的微引擎(me)结构,本发明的微引擎处理报文的方法包括如下步骤:
步骤301:me接收到新的报文时,首先为报文分配一个线程号,分配线程号时不区分低延时报文或非低延时报文;
步骤302:在线程管理(threadschedule)模块中,对低延时报文和非低延时报文向指令缓存(instructioncache)模块中发起指令申请,低延时报文的申请指令的优先级高于非低延时报文的申请指令的优先级,所示指令缓存模块为存储部分线程对应的指令的二级缓存空间,图中所示的指令存储器(instructionmemory)为存储所有线程对应的指令的一级存储空间;
步骤303:指令拾取模块(pickinstructionunit,piu)将线程分成两个线程组(threadgroup):thread_group0(包含第0至19个线程)和thread_group1(包含第20至39个线程),每个线程组根据每个线程的取指指令预解析、线程在流水线中的执行情况来选择一个线程的指令并发射到对应的流水线中;
步骤304:流水线分为七级流水(或其它级数的流水,如五级等),不同的指令会对不同的键值存储/包存储空间(keymemory/packetmemory)进行操作,当流水线执行完一条发包指令后,暂停指令调度器模块会将报文调度出内核并释放这个线程,所释放的线程可以重新分配给下一个新包使用。
如图4所示,指令拾取模块将已经处于ready状态的线程分成两组,每组线程分别采用lru调度算法以及低延时报文优先策略选择一个线程,获取该线程对应的指令发射到对应流水线去处理指令。其中,pkt_pc为新包进入内核后调度到指令缓存模块(instructioncache)中对应的取指指令,reg_pc为线程从指令缓存模块取回的指令已经执行完需要重新取指对应的取指指令,branch_pc为在流水线中解析出来是跳转指令时暂时挂起此线程、流水线执行完后计算的新取指地址对应的取指指令。当一个低延时报文进入传统的网络处理器内核中处理时,向指令缓存模块发送的取指指令pkt_pc对应的线程优先级最低,因此在低延时报文进入内核后此线程不能立即进入ready状态;而在本申请中,改进了取指指令队列的优先级调度方式,本申请中不同的取指指令对应的线程优先级为:低延时报文的reg_pc>低延时报文的branch_pc>低延时报文的pkt_pc>非低延时报文的reg_pc>非低延时报文的branch_pc>非低延时报文的pkt_pc。
图4中的线程管理模块负责管理整个内核中40个线程的状态,每个线程的状态转换如图5所示,新包进入内核后会向instructioncache中发送取指指令,从instructioncache中取回的指令存储在指令ram(instructionram)中,指令ram分成两部分,分别用于存储线程组0(threadgroup0)和线程组1(threadgroup1)的指令数据;当指令从instructioncache返回后,对应线程从开始的空闲(idle)状态转入准备(ready)状态,lru模块根据对应threadgroup是否在ready状态以及lru调度算法选出一个线程并发送给流水线,并从instructionram中读取对应指令发射至流水线处理,两个独立的lru模块可以实现同时发射两个指令到两个流水线中处理。当流水线解析指令时发现是跳转指令或者instructionram中指令已经执行完成时,线程进入等待(wait)状态,等待流水线解析出新的取指令地址,流水线返回新的取指令地址后重新进入ready状态,直到流水线执行完发包指令后,报文调度出内核并释放线程号,线程进入idle状态等待新包进入。
本发明提供的微引擎及其处理报文的方法,通过设置若干个线程组和若干条流水线,实现了在不增加内核数量的基础上成倍地提高网络处理器的性能;
进一步地,通过设置低延时报文高优先级调度方式,有效地控制了网络处理器内核处理低延时报文的时间。
本发明是根据本发明实施例一和实例二中任一实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!