一种基于深度Q学习的路由规划方法与流程
本发明涉及网络通信技术和强化学习领域,具体涉及一种基于深度q学习的路由规划方法。
背景技术:
近年来,社交网络、移动互联网和物联网等领域正在快速发展,大数据正逐步成为当前关注的焦点。海量数据也对网络服务质量提出了更高的要求。大数据依赖于事先定义好的计算模式,在集中化的管理架构下操作,通常存在着非常大量的数据传输以及聚合和划分的操作。大数据每次聚合划分操作都将会导致服务器之间有海量数据进行交换,从而需要极高网络服务质量支持。传统的网络难以满足云计算和大数据等相关业务所需要的资源需求。正是在上述背景下,sdn概念被大家逐渐广泛接受和认可。
sdn的概念由美国斯坦福大学cleanslate课题组第一次提出。sdn旨在实现网络设备的数据层和控制层的彻底分离。数据层面只关注数据的传输,控制层面则关注网络的管理。随着控制层面需要管理的功能的逐步增多,学术界提出了将控制层管理系统化,抽象化。大致总结一下,sdn的精髓主要是把控制层面管理的复杂度以三种方式抽象出来:
第一种是分布状态抽象。一个网络当中的多个状态主要是分散在各个路由器上面,路由器物理层面上的分散导致了处理上的困难。于是,分布状态抽象所做的工作就是将分散在各处的路由器上大量复杂状态抽象出来,然后向外部提供一个集中管理这些复杂状态的方式。这样其他部分就不需要一个一个路由器地去处理路由器查询问题,它们处理的是一个集中化的任务,这便是分布状态抽象。
第二种是网络虚拟化。软件定义网络的目标就是希望网络管理员可以通过开放的编程接口来表达自己管理网络的实际需求。他们只要关心自己的网络需求,而不需要去关注这些需求具体是如何被实现的。网络控制程序不需要看到整个网络的复杂拓扑,它看到的网络只要复杂到能够实现它的需求就可以。即你看到的网络是一个虚拟的网络,这便是网络虚拟化。
第三种是转发的抽象。sdn不仅仅要管理路由器上的状态,同时也需要向路由器发送相应的处理指令。各路由器由于硬件上的差异,路由器设置的细节也不尽相同。转发抽象要完成的工作就是忽略硬件上的差异,给外界抽象出一个统一的对所有路由器进行操作的界面。
要实现上述功能,通信协议非常关键,现在sdn中比较流行的是openflow,openflow在得到了ovs(openvirtualswitch)的支持后获得了广泛的应用。openflow通过多级流表实现对sdn中数据流的控制。
目前主流的sdn控制器如pox、floodlight等均提供了完成数据包转发的模块,采用的也基本都是dijkstra最短路径算法。所有数据包的转发如果都仅仅依赖于最短路径算法将会带来一个严重的问题,所有数据流很容易因为选择同一条转发路径而聚集到一起,这极大降低了网络率用率,同时也很容易导致网络拥塞。因此,需要一个更好的路由策略来管理sdn网络的路由。控制器集中式的管理模式,网络数据流量的逐步增加,急需一种新的sdn网络路由策略来保障网络的服务质量。新的网络路由策略不仅仅要考虑到面对海量数据的时候可以采用最短路径算法找到一条最短转发路径。同时还需要考虑到网络的可用带宽、时延和延迟抖动等其他链路因素,综合考虑网络各种因素的影响,给数据包选择出一条综合最优的路由策略。
强化学习是多门学科多个领域交叉结合的产物,最早可以追溯到巴普洛夫的条件反射实验,但直到上世纪九十年代才逐渐被人们应用于自动控制、机器学习等领域。这主要得益于数学基础得到的突破性的进展,强化学习逐渐成为人工智能领域的核心技术之一,对强化学习的研究和应用也逐渐成为人们研究的热点。强化学习的本质是一个“decisionmaking”问题,即智能体自行做出一个最优抉择。强化学习的基本原理是:如果一个智能体的某个行为策略导致环境给出一个正的奖赏(强化信号),那么智能体之后再次产生这个行为策略的趋势便会增强。智能体的目标是在每个离散状态发现最优策略以获得最大期望奖励。现在常用的强化学习算法有td(temporaldifference)算法、q学习算法、sarsa算法等。
深度q学习(deepqlearning,dqn),是第一个成功地将深度学习和强化学习结合起来的模型,它由google的deepmind首先提出。dqn算法的主要做法是通过经验回放(experiencereplay),将智能体探索环境得到的数据存储起来,之后随机采样,得到样本训练神经网络,更新神经网络中的参数。
experiencereplay的动机是:1)深度神经网络作为有监督学习模型,要求数据满足独立同分布;2)q学习算法得到的样本前后是有关系的。为了打破数据之间的关联性,experiencereplay通过存储-再采样的方法将数据前后的关联性打破了,使得用于训练的样本更加具有科学性。
针对日益扩大的网络流量,为了解决现有路由规划方法速度慢、易拥塞等问题,研究设计一种更加合理的sdn路由策略是保证sdn网络架构下业务部署和最优化利用网络链路的前提。
技术实现要素:
本发明为了克服dijkstra算法的不足,提出了一种基于深度q学习的路由规划方法。该方法利用了神经网络抽象化高层数据、自动学习的特点,相比于传统的dijkstra算法,在大规模应用部署时能更快速地规划出最佳路径。
本发明解决技术问题所采用的技术方案如下:一种基于深度q学习的路由规划方法,该方法为:根据网络拓扑生成奖励值矩阵,使用一个训练好的深度神经网络模型代替普通q学习的q值表进行路由规划。
进一步的,该方法具体为:
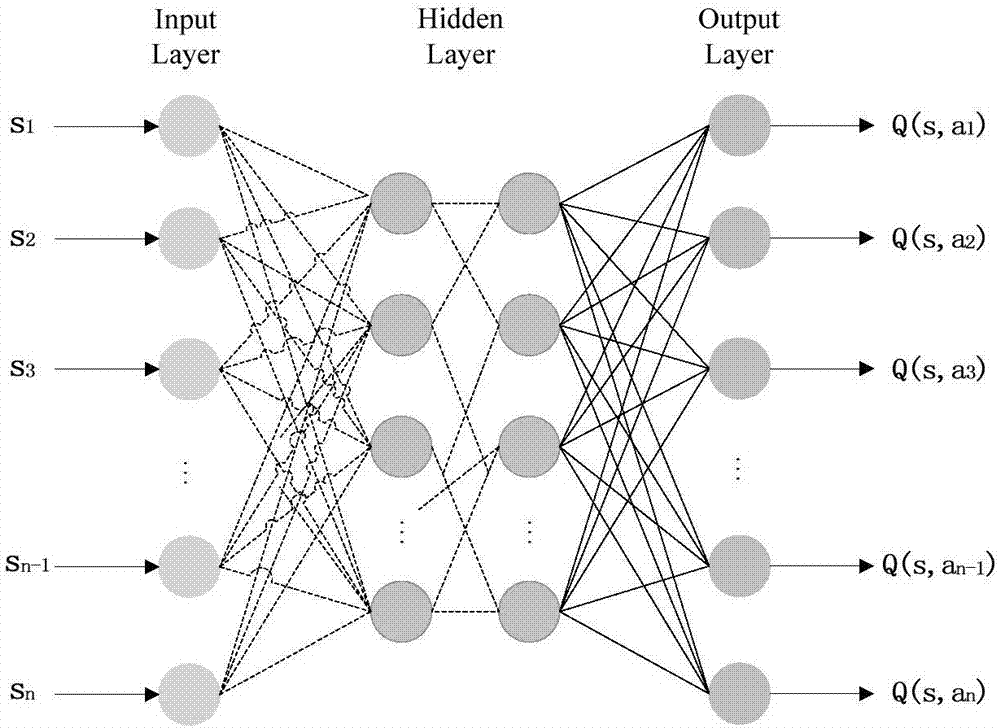
对一个已训练完成的三层bp神经网络模型,输入当前状态s,输出当前状态可以执行的动作的q值表q(s,allactions),根据q值表得到下一步状态s',然后,再将状态s'输入bp神经网络,重复上述操作,最终到达终点d。
进一步的,所述已训练完成的三层bp神经网络模型通过以下方法训练得到:
(1)训练样本m,单个样本是一个六元组{s,a,r,s',d,done},其中s代表当前状态,a代表执行动作,r代表奖励值,s'代表下一步状态,d代表终点状态,done代表是否结束,将每个样本中的s'作为一个三层bp神经网络(激活函数relu,输入节点的数目等于网络节点的个数,输出节点数目等于动作的数目)的输入值,进行批量处理,得到s'状态下选择每个行为的q值组成的表q(s',allactions);
(2)根据公式计算出q值对应的target_q值,公式为target_q=r+γ×max[q(s',allactions)],g为经验折损率;
(3)使用q与target_q计算损失函数loss=(target_q-q)2,优化神经网络参数,训练该三层bp神经网络模型。
进一步的,所述训练样本m由深度q学习的经验回放得到,具体如下:
(1)随机初始化一个起点so和终点d,初始化经验池m,并且设置观察值(样本训练之前观察的次数);
(2)自定义评价函数r,可以对状态和动作进行评价,给出奖励值r;
(3)当前状态s,初始值等于so,根据随机策略选择一个行为a;
(4)执行该行为a,得到对应的奖励值r,进入状态s',判断是否结束done,即s'是否为终点d;
(5)将前三步所涉及的相关参数s、a、r、s'、d、done作为一条记录保存到经验池m中;
(6)判断经验池中的数据是否足够,即经验池里的数据数量是否超过设置的观察值,如果不够,判断这次查找过程是否结束,如果过程未结束,则当前状态s更新为状态s',反之,过程结束,将当前状态s随机置为某一状态;回到步骤(3);如果数据足够的话,转到第(7)步;
(7)在经验池m里随机抽取出一部分数据作为训练样本m。
与现有技术相比,本发明的有益效果如下:在sdn中还没有一种固定的路由算法,基于sdn已知整体网络拓扑的情况下,控制器根据训练好的bp神经网络模型,更快速地找到两节点间的最短路径,且更适用于交换机数目众多的大型网络环境,该方法不必每次遍历网络拓扑结构,能够大大减少找路时间。
附图说明
图1为总体结构图;
图2为三层bp神经网络模型图;
图3为样本获取流程图。
具体实施方式
下面结合附图详细说明本发明。
针对现有的sdn控制均采用dijkstra算法作为最短路由查找算法,本发明尝试将强化学习应用到sdn的选路当中。利用控制器拥有的全局网络视图,直接将网络拓扑节点的连接关系用于q矩阵的训练。当状态数量过多的时候,普通的q矩阵将难以满足训练的要求,神经网络恰好可以用来解决这个问题。利用神经网络来替代普通q学习算法中的q矩阵,训练的结果将是一个逼近函数。
本发明提供的一种基于深度q学习的路由规划方法利用了神经网络抽象化高层数据、自动学习的特点,相比于传统的dijkstra算法,在大规模应用部署时能更快速地规划出最佳路径。该方法为:根据网络拓扑生成奖励值矩阵,使用一个训练好的深度神经网络模型代替普通q学习的q值表进行路由规划。
1.结构如图1所示,对一个已训练完成的三层bp神经网络模型,输入当前状态s,输出当前状态可以执行的动作的q值表q(s,allactions),根据q值表得到下一步状态s',然后,再将状态s'输入神经网络。重复上述操作,最终到达终点状态d。
2.神经网络模型如图2所示,该训练过程包含如下步骤:
(1)训练样本m,单个样本是一个六元组{s,a,r,s',d,done},其中s代表当前状态,a代表执行动作,r代表奖励值,s'代表下一步状态,d代表终点状态,done代表是否结束,将每个样本中的s'作为一个三层bp神经网络(激活函数relu,输入节点的数目等于网络节点的个数,输出节点数目等于动作的数目)的输入值,进行批量处理,得到s'状态下选择每个行为的q值组成的表q(s',allactions);
(2)根据公式计算出q值对应的target_q值,公式为target_q=r+γ×max[q(s',allactions)],g为经验折损率;
(3)使用q与target_q计算损失函数loss=(target_q-q)2,优化神经网络参数,训练该三层bp神经网络模型。
3.训练样本获取流程如图3所示,该方法包含如下步骤:
(1)随机初始化一个起点so和终点d,初始化经验池m,并且设置观察值(样本训练之前观察的次数);
(2)自定义评价函数r,可以对状态和动作进行评价,给出奖励值r;
(3)当前状态s,初始值等于so,根据随机策略选择一个行为a;
(4)执行该行为a,得到对应的奖励值r,进入状态s',判断是否结束done,即s'是否为终点d;
(5)将前三步所涉及的相关参数s、a、r、s'、d、done作为一条记录保存到经验池m中;
(6)判断经验池中的数据是否足够,即经验池里的数据数量是否超过设置的观察值,如果不够,判断这次查找过程是否结束,如果过程未结束,则当前状态s更新为状态s',反之,过程结束,将当前状态s随机置为某一状态;回到步骤(3);如果数据足够的话,转到第(7)步;
(7)在经验池m里随机抽取出一部分数据作为训练样本m。
实施例:
下面结合实施例对本发明作进一步说明。
本发明中涉及到的最短路径规划方法具体可以描述如下:
在一个有六个节点的网络中,其中一个节点希望发送服务到达另一节点,发送方为起点,接收方为终点,已知起点、终点和网络拓扑结构的控制器在此情况下进行路由规划,实现从起点到终点的最短路由。
随机选择一个节点作为起点so,一个节点作为终点d。自定义评价函数r,可以根据状态和动作计算奖励值r。然后根据上述具体实施方案训练bp神经网络模型。
模型训练完成后,每当一个服务请求到达控制器,控制器将起点so输入三层bp神经网络模型,然后神经网络输出当前状态s(s初始等于so)可以执行的动作的q值表q(s,allactions),我们就可以得到下一步状态s'。然后,将状态s'输入神经网络,又可以得到下一步状态,重复上述操作,最终到达终点d。因此,控制器可以得到一条从起点so到终点d的路径,且该路径是最短路径。
- 还没有人留言评论。精彩留言会获得点赞!