基于流式计算生成服务拓扑与服务监控的方法及系统与流程
本发明涉及到电信服务监控领域,特别是涉及到一种基于流式计算生成服务拓扑与服务监控的方法及系统。
背景技术:
由于电信系统的业务量大、应用服务多且应用服务大多采用集群部署方案,以往多使用各服务独立监控的方式,难以从业务和技术视角全局准实时监控整个系统运行状态。
技术实现要素:
为了解决上述现有技术的缺陷,本发明的目的是提供一种基于流式计算生成服务拓扑与服务监控的方法及系统。
为达到上述目的,本发明的技术方案是:
一种基于流式计算生成服务拓扑与服务监控的方法,包括以下步骤:
接收源数据流,根据源数据流生成所有的服务层级的关联关系;
接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据;
接收所有服务层级的逻辑和物理服务数据,计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
进一步地,所述接收源数据流,根据源数据流生成所有服务层级的关联关系步骤,包括,
从源数据流中提取出span数据项;
识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称;
若含有,则生成所有服务层级的关联关系;
若不含有,则配置有缺失服务层级的逻辑服务名称以及物理服务名称,并生成所有服务层级的关联关系。
进一步地,所述接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据步骤,包括,
设定逻辑和物理服务数据的更新时间,并判断更新时间是否达到;
若更新时间到达,则将服务层级的逻辑和物理名称以及关联关系存储到rdbms中。
进一步地,所述接收所有服务层级的逻辑和物理服务数据,计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值步骤,包括,
根据接收到的逻辑和物理服务数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值;
将计算后的时间索引值分别与三个时间槽的时间索引值比较,并判断是否相同;
若计算后的时间索引值等于对应任一时间槽的时间索引值,则以分钟索引值取模;
若计算后的时间索引值大于最大的时间槽的索引值,则将对应序号的分钟槽的监控指标值存入数据库,并重新初始化该序号的分钟槽。
进一步地,所述以分钟索引值取模步骤,包括,
识别取模结果值,并对监控指标值进行累加和计算。
一种基于流式计算生成服务拓扑与服务监控的系统,包括:
服务分析生成器,用于接收源数据流,根据源数据流生成所有的服务层级的关联关系;
服务数据存储器,用于接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据;
监控指标值计算器与存储器,用于接收所有服务层级的逻辑和物理服务数据,计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
进一步地,所述服务分析生成器包括提取模块,识别模块和生成模块,
所述提取模块,用于从源数据流中提取出span数据项;
所述识别模块,用于识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称;
所述生成模块,若识别模块判断含有,则生成所有服务层级的关联关系,若判断不含有,则配置有缺失服务层级的逻辑服务名称以及物理服务名称,并生成所有服务层级的关联关系。
进一步地,所述服务数据存储器包括定时更新模块,用于设定逻辑和物理服务数据的更新时间,并判断更新时间是否达到;若更新时间到达,则将服务层级的逻辑和物理名称以及关联关系存储到rdbms中。
进一步地,所述监控指标值计算器与存储器包括计算模块、对比模块、取模模块和初始化模块,
所述计算模块,用于根据接收到的逻辑和物理服务数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值;
所述对比模块,用于将计算后的时间索引值分别与三个时间槽的时间索引值比较,并判断是否相同;
所述取模模块,用于在计算后的时间索引值等于对应任一时间槽的时间索引值之后,以分钟索引值取模;
所述初始化模块,用于在计算后的时间索引值大于最大的时间槽的索引值之后,将对应序号的分钟槽内的监控指标值存入数据库,并重新初始化该序号分钟槽。
进一步地,所述取模模块,用于识别取模结果值,并对监控指标值进行累加和计算。
本发明的有益效果是:方案通过流式计算准实时算出时间槽内的监控指标值、通过定义逻辑/物理服务与服务实例的对应关系建立面向业务和技术视角的服务拓扑关系,使得运维人员能从业务和技术视角全局监控复杂电信系统的运行状态;采用时间槽的方式计算监控指标值,使得监控指标值的准确度更高、使得监控指标值限定在较少的存储空间内。
附图说明
图1为本发明一实施例一种基于流式计算生成服务拓扑与服务监控的方法流程图;
图2为本发明一实施例一种生成所有的服务层级的关联关系的方法流程图;
图3为本发明一实施例一种定时更新逻辑和物理服务数据的方法流程图;
图4为本发明一实施例一种监控指标值计算方法的方法流程图;
图5为本发明另一实施例一种监控指标值计算方法的方法流程图;
图6为本发明一实施例一种时间槽中的监控指标值示例图;
图7为本发明一实施例一种基于流式计算生成服务拓扑与服务监控的系统的架构图;
图8为本发明一实施例一种基于流式计算生成服务拓扑与服务监控的系统的逻辑流程图;
图9为本发明一实施例一种服务分析器的结构框图;
图10为本发明一实施例一种服务数据存储器的结构框图;
图11为本发明一实施例一种监控指标值计算器与存储器的结构框图。
具体实施方式
为阐述本发明的思想及目的,下面将结合附图和具体实施例对本发明做进一步的说明。
rdbms,英文全称:relationaldatabasemanagementsystem,中文名称:关系型数据库管理系统。rdbms通过数据、关系和对数据的约束三者组成的数据模型来存放和管理数据。
实时计算,强调的是实时。比如小明要查看他去年一年的消费总额度,那么当小明点下统计按钮的时候,服务器集群就在噼里啪啦的赶紧计算了,必须在小明能够忍耐的时间范围内得出结果。这种计算的背后实现,一般都是冗余+各种高性能部件在做支撑,算法也对实时性做了优化,但实时计算并没有强调用那种算法,只要能保证高实时性的就行。实时计算与离线计算的最大区别,就是离线计算是人无法忍耐的时间进行计算,因此人不需要等待,把任务丢给计算机。
流式计算,比实时计算要稍微迟钝些,但比离线计算又实时的多,而且主要强调的是计算方法。比如,服务器端,有一个值,是记录小明订单数量。当小明每买一件东西后,服务端立即发出一个交易成功的事件,该值接收到这个事件后就立即加1。如果用离线计算的方式来做,估计是在查询时,才慢腾腾的从低速存储中,把小明的所有订单取出来,统计数量。流式计算有点像数据库领域的触发器,又有些像事件总线、中间件之类的计算模式。
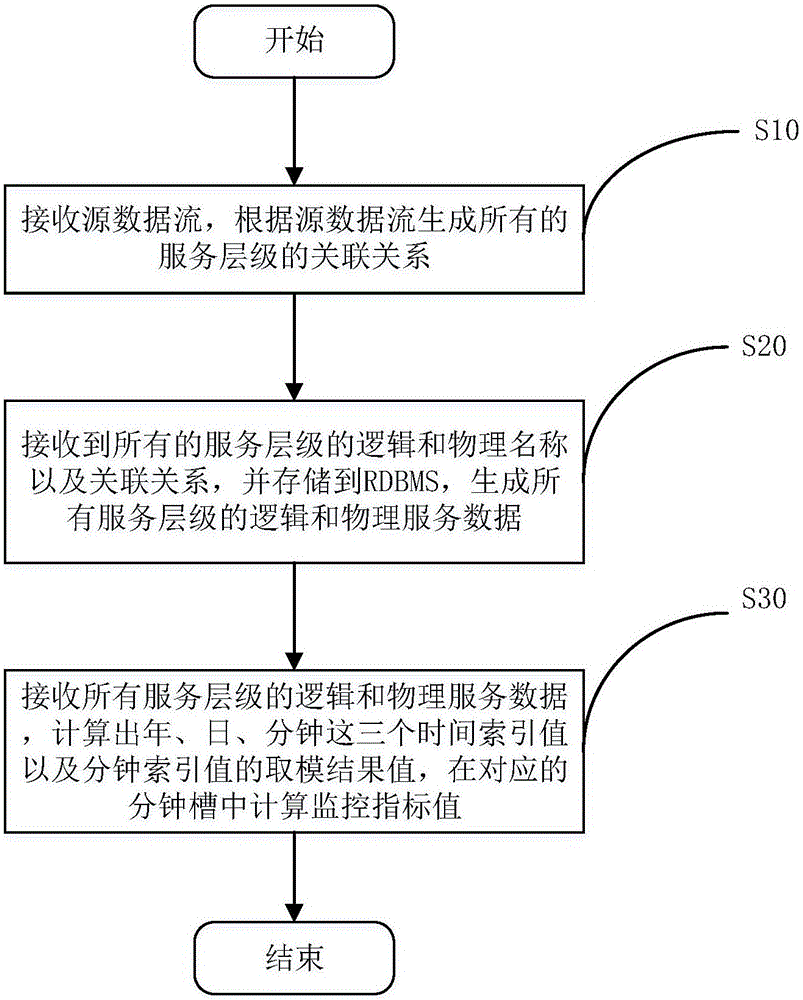
参照图1至图6,提出本发明一具体实施例,一种基于流式计算生成服务拓扑与服务监控的方法,包括以下步骤:
s10、接收源数据流,根据源数据流生成所有的服务层级的关联关系。
s20、接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据。
s30、接收所有服务层级的逻辑和物理服务数据,计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
对于步骤s10,在接收到源数据流后,从源数据流中得到各级物理和逻辑服务名称,其中部分物理和逻辑服务名称可以直接从源数据流中获得,部分物理和逻辑服务名称不直接存在于源数据流中,需要通过一定的配置才能获得。
参考图2,步骤s10包括以下步骤:
s11、从源数据流中提取出span数据项。
s12、识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称。
s13、若含有,则生成所有服务层级的关联关系。
s14、若不含有,则配置有缺失服务层级的逻辑服务名称以及物理服务名称,并生成所有服务层级的关联关系。
对于步骤s11,在接收到源数据流后,从源数据流中提取出span数据项,该数据项至少含有traceid、spanid、parentid、hostip、instancename、creattime、calltime、isentry、errcode等字段,其中instancename是服务实例名称,它既是2级逻辑服务名称,也是2级物理服务名称,把instantcename更新到数据库中。
对于步骤s12-s14,识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称,存在符合的逻辑服务名称以及物理服务名称,直接调用,不然通过配置得到缺失的服务层级的逻辑服务名称以及物理服务名称。
例如,如果能从span数据项中提取到1级逻辑服务名称componentname,则生成componentname与instancename的关联关系数据;否则,通过配置得到1级逻辑服务名称componentname,并生成componentname与instancename的关联关系数据。另外,源数据流中含有hostip,它作为1级物理服务名称,已具有与instancename的关联关系。
同时,如果能从源数据流中提取到0级逻辑服务名称appname,则生成appname与componentname的关联关系数据。否则,通过配置得到0级逻辑服务名称appname,并且生成appname与componentname的关联关系数据,存储到数据库中。其中,appname可同时作为0级物理服务名称。
最后得到2级、1级、0级逻辑/物理服务名称和关联关系,作为所有的服务层级的关联关系数据,以备后续使用。
具体的,使用instancename作为物理拓扑、逻辑拓扑共有的基础级别(本发明中作为默认层级2级),使得物理拓扑、逻辑拓扑从最底层服务建立起了关联关系;通过定义逻辑服务与一个或多个物理服务的对应关系,建立起面向业务的服务拓扑关系;同时,使用instancename(本发明中作为默认层级2级)、hostip(本发明中作为默认层级1级)作为两级物理服务级别,建立起面向技术的服务拓扑关系,使得运维人员能从业务和技术视角全局监控复杂电信系统的运行状态。
对于步骤s20,接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据。例如接收到上述的2级、1级、0级逻辑/物理服务名称和关联关系,进一步将2级、1级、0级逻辑/物理服务名称和关联关系存储到rdbms中,形成三级的逻辑和物理服务数据,具体的,逻辑和物理服务数据为逻辑/物理服务拓扑图数据。
逻辑服务不仅限于2、1、0这三级,还可根据实际业务扩展更多级逻辑拓扑结构,只需从源数据流中获取或配置得到即可。物理服务除了0级是定义外,1级和2级都是实实在在存在的,只要有实际存在的物理服务层级,就可根据实际扩展更多及物理拓扑结构,目前只有1级和2级是物理实实在在存在的,0级是定义的,如果在0级的基础上继续定义,则可以是继续定义-1级、-2级等级别。具体的,为了不出现负数层级,则把最顶级的服务定义为0级,其它级别以此递增为1级、2级、3级等级别。
参照图3,步骤s20包括以下步骤:
s21、设定逻辑和物理服务数据的更新时间,并判断更新时间是否达到。
s22、若更新时间到达,则更新逻辑和物理服务数据。
对于步骤s21,设定一具体的更新时间,例如10分钟、5分钟或3分钟,作为更新逻辑和物理服务数据的时间间隔,在更新时间到达时,自动更新逻辑和物理服务数据。所以可以通过判断更新时间是否达到,来判定是否更新逻辑和物理服务数据。
更新时间是否到达,可以是通过判断时间点是否为对应的更新时间点来实现。例如,更新时间间隔为10分钟,上一次的更新时间为15分钟,就通过判断当前时间是否为25分钟、35分钟、45分钟、55分钟或5分钟来判断是否更新数据,若为上述任一时间点,则判定更新时间已经达到,自动更新逻辑和物理服务数据。
对于步骤s22,在s21步骤判定更新时间到达,则更新逻辑和物理服务数据,生成新的服务逻辑和物理服务数据。
对于步骤s30,在每接收到一次逻辑和物理服务数据后,逻辑和物理服务数据包括有时间戳信息,根据数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
时间槽用于存储年索引值、日索引值、分钟索引值、监控指标值。时间槽中的年索引值、日索引值、分钟索引值,三者联合组成了槽标识。
参照图4,步骤s30包括以下步骤:
s31、根据接收到的逻辑和物理服务数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值。
s32、将计算后的时间索引值分别与三个时间槽的时间索引值比较,并判断是否相同。
s33、若计算后的时间索引值等于对应任一时间槽的时间索引值,则以分钟索引值取模。
s34、若计算后的时间索引值大于最大的时间槽的索引值,则将对应序号的分钟槽的监控指标值存入数据库,并重新初始化该序号的分钟槽。
对于步骤s31,时间槽用于存储年索引值、日索引值、分钟索引值、监控指标值。时间槽中的年索引值、日索引值、分钟索引值,三者联合组成了槽标识。采用时间槽的方式计算监控指标值,使得监控指标值的准确度更高、使得监控指标值限定在较少的存储空间内。
年索引值是指年值,日索引值是指该天是在一年中的第几天,分钟索引值是指该分钟数在一天中是第几分钟。比如2017年6月23日凌晨1点18分,其年索引值是2017,日索引值是174,分钟索引值是78,分钟槽索引值78模3的结果值是0,表示该分钟的数据是保存在第0个分钟槽中。通过流式计算得到时间戳时间信息对应的年索引值、日索引值和分钟索引值用于后续使用。
对于步骤s32,通过将计算后的时间索引值分别与三个时间槽的时间索引值比较,才能判定计算后的时间索引值与时间槽的时间索引值是否一致。只有新进来逻辑和物理服务数据的年、日、分钟这三个索引值与时间槽对应的年、日、分钟这三个索引值相等时,才会把新进来逻辑和物理服务数据的监控值叠加到分钟槽现有的监控指标值中。
对于步骤s33,当步骤s32判定计算后的时间索引值等于对应任一时间槽的时间索引值,则以分钟索引值取模。当判定计算后的时间索引值不等于对应任一时间槽的时间索引值时,则不会把新进来逻辑和物理服务数据的监控值叠加到分钟槽现有的监控值中。
步骤s33,包括步骤:s330、识别取模结果值,并对监控指标值进行累加和计算。
对于步骤s330,根据识别到的取模结果值的大小对对应分钟槽内的监控指标值进行累加和计算。时间槽的个数是模数,也是监控指标值的发送周期,在准实时场景中,可取n分钟为一个发送周期,即对应有n个时间槽。分钟索引值%n的运算结果作为时间槽的序号,每个数据都需按分钟索引值在对应的时间槽中计算监控值。其中,n为自然数,可根据需要以其它数取模,如1、2、3、4等。
对于步骤s34、当计算后的时间索引值大于最大的时间槽的索引值时,则将对应序号(序号是分钟索引值的取模结果值)的分钟槽的监控指标值存入数据库,并重新初始化该序号分钟槽。将原来的存在于分钟槽内的监控指标值去掉。
参考图6,为时间槽中的监控指标值示例,具体的,监控指标值包含有tps、错误数、平均响应时间。
tps,中文为吞吐量,每收到一个服务数据就自增1。
错误数,英文为err,每收到一个异常服务数据就自增1。
平均响应时间,英文为calltimeavg,每收到一个服务数据的响应时间后,就减去分钟槽中的平均响应时间,得到的差值再除以tps,tps为包含当前该条服务数据的tps,即收到该服务数据后已自增1,得到的商值再加上分钟槽中的原平均响应时间,结果值就是平均响应时间。计算公式如下:
calltimeavgnew=(calltime-calltimeavg)/tps+calltimeavg
如:时间槽中现吞吐量tps是2,平均响应时间calltimeavg是2.5毫秒,现接收到1条新数据,其响应时间calltime是7毫秒,则tps自增1后为3,新的平均响应时间为calltimeavgnew=(7毫秒-2.5毫秒)/3+2.5毫秒,结果等于4毫秒,即新的平均响应时间值是4毫秒。
图6中,最左侧时间槽的tps为10,错误数为3,平均响应时间为95;中间时间槽的tps为8,错误数为1,平均响应时间为90;最右侧时间槽的tps为6,错误数为2,平均响应时间为100。
参考图5,在本发明一具体实施例中,取3分钟为一个发送周期,即有三个时间槽。分钟索引值%3的运算结果作为时间槽的序号,每个数据都需按分钟索引值在对应的时间槽中计算监控指标值。具体步骤如下:
s31、根据接收到的逻辑和物理服务数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值。
s32、将计算后的时间索引值分别与三个时间槽的时间索引值比较,并判断是否相同。
s33、若计算后的时间索引值等于对应任一时间槽的时间索引值,则以分钟索引值取模。
s331、若结果等于0,则分钟槽0的监控指标值进行累加和计算。
s332、若结果等于1,则分钟槽1的监控指标值进行累加和计算。
s333、若结果等于2,则分钟槽2的监控指标值进行累加和计算。
s341、若计算后的时间索引值大于最大的时间槽的索引值,则将对应序号的分钟槽(槽序号0或1或2)的监控指标值入库并重新初始化该序号分钟槽(槽序号0或1或2)。
当第二个周期的数据到达时,分钟索引值取模结果值可以是任意一个时间槽序号,对应时间槽序号发送时间槽的监控指标值、清空时间槽数据并保存新数据的监控指标值。其中,序号是分钟索引值的取模结果值。
若超过两个周期仍然没有新数据到达时,为了避免监控指标值更新不及时,则把超过两个周期的时间槽监控数据发送出去、并清空时间槽数据。
本方案通过流式计算准实时算出时间槽内的监控指标值、通过定义逻辑/物理服务与服务实例的对应关系建立面向业务和技术视角的服务拓扑关系,使得运维人员能从业务和技术视角全局监控复杂电信系统的运行状态;采用时间槽的方式计算监控指标值,使得监控指标值的准确度更高、使得监控指标值限定在较少的存储空间内。
参考图7-图11,本发明还提出了一种基于流式计算生成服务拓扑与服务监控的系统,包括:
服务分析生成器10,用于接收源数据流,根据源数据流生成所有的服务层级的关联关系。
服务数据存储器20,用于接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据。
监控指标值计算器与存储器30,用于接收所有服务层级的逻辑和物理服务数据,计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
参照图7,源数据流属于源数据流层,服务分析生成器10、服务数据存储器20、监控值计算器与存储器30位于流式计算层,rdbms和时序数据库位于数据存储层。参照图8,源数据流发送至服务分析生成器10后按服务分组发送至服务数据存储器20和监控值计算器与存储器30,最后将服务拓扑存入rdbms中,将监控指标值存入时序数据库中。
对于服务分析生成器10,在接收到源数据流后,从源数据流中提取出span数据项,该数据项至少含有traceid、spanid、parentid、hostip、instancename、creattime、calltime、isentry、errcode等字段,其中instancename是服务实例名称,它既是2级逻辑服务名称,也是2级物理服务名称,把instantcename更新到数据库中。
参考图9,服务分析生成器10包括提取模块11,识别模块12和生成模块13。
提取模块11,用于从源数据流中提取出span数据项。
识别模块12,用于识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称。
生成模块13,若识别模块12判断含有,则生成所有服务层级的关联关系,若判断不含有,则配置有缺失服务层级的逻辑服务名称以及物理服务名称,并生成所有服务层级的关联关系。
通过提取模块11、识别模块12和生成模块13配合实现识别span数据项中是否含有所有服务层级的逻辑服务名称以及物理服务名称,存在符合的逻辑服务名称以及物理服务名称,直接调用,不然通过配置得到缺失的服务层级的逻辑服务名称以及物理服务名称。
例如,如果能从span数据项中提取到1级逻辑服务名称componentname,则生成componentname与instancename的关联关系数据;否则,通过配置得到1级逻辑服务名称componentname,并生成componentname与instancename的关联关系数据。另外,源数据流中含有hostip,它作为1级物理服务名称,已具有与instancename的关联关系。
同时,如果能从源数据流中提取到0级逻辑服务名称appname,则生成appname与componentname的关联关系数据。否则,通过配置得到0级逻辑服务名称appname,并且生成appname与componentname的关联关系数据,存储到数据库中。其中,appname可同时作为0级物理服务名称。
最后得到2级、1级、0级逻辑/物理服务名称和关联关系,作为所有的服务层级的关联关系数据,以备后续使用。
对于服务数据存储器20,接收到所有的服务层级的逻辑和物理名称以及关联关系,并存储到rdbms,生成所有服务层级的逻辑和物理服务数据。例如接收到上述的2级、1级、0级逻辑/物理服务名称和关联关系,进一步将2级、1级、0级逻辑/物理服务名称和关联关系存储到rdbms中,形成三级的逻辑和物理服务数据,具体的,逻辑和物理服务数据为逻辑/物理服务拓扑图数据。
逻辑服务不仅限于2、1、0这三级,还可根据实际业务扩展更多级逻辑拓扑结构,只需从源数据流中获取或配置得到即可。物理服务除了0级是定义外,1级和2级都是实实在在存在的,只要有实际存在的物理服务层级,就可根据实际扩展更多及物理拓扑结构,目前只有1级和2级是物理实实在在存在的,0级是定义的,如果在0级的基础上继续定义,则可以是继续定义-1级、-2级等级别。具体的,为了不出现负数层级,则把最顶级的服务定义为0级,其它级别以此递增为1级、2级、3级等级别。
参考图10,服务数据存储器20包括定时更新模块21,用于设定逻辑和物理服务数据的更新时间,并判断更新时间是否达到;若更新时间到达,则将服务层级的逻辑和物理名称以及关联关系存储到rdbms中。
对于定时更新模块21,设定一具体的更新时间,例如10分钟、5分钟或3分钟,作为更新逻辑和物理服务数据的时间间隔,在更新时间到达时,自动更新逻辑和物理服务数据。所以可以通过判断更新时间是否达到,来判定是否更新逻辑和物理服务数据。
更新时间是否到达,可以是通过判断时间点是否为对应的更新时间点来实现。例如,更新时间间隔为10分钟,上一次的更新时间为15分钟,就通过判断当前时间是否为25分钟、35分钟、45分钟、55分钟或5分钟来判断是否更新数据,若为上述任一时间点,则判定更新时间已经达到,自动更新逻辑和物理服务数据。
判定更新时间到达,则更新逻辑和物理服务数据,生成新的服务逻辑和物理服务数据。
对于监控指标值计算器与存储器30,在每接收到一次逻辑和物理服务数据后,逻辑和物理服务数据包括有时间戳信息,根据数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值,在对应的分钟槽中计算监控指标值。
时间槽用于存储年索引值、日索引值、分钟索引值、监控指标值。时间槽中的年索引值、日索引值、分钟索引值,三者联合组成了槽标识。
参考图11,监控指标值计算器与存储器30包括计算模块31、对比模块32、取模模块33和初始化模块34,
计算模块31,用于根据接收到的逻辑和物理服务数据的时间戳计算出年、日、分钟这三个时间索引值以及分钟索引值的取模结果值;
对比模块32,用于将计算后的时间索引值分别与三个时间槽的时间索引值比较,并判断是否相同;
取模模块33,用于在计算后的时间索引值等于对应任一时间槽的时间索引值之后,以分钟索引值取模;
初始化模块34,用于在计算后的时间索引值大于最大的时间槽的索引值之后,将对应序号(序号是分钟索引值的取模结果值)的分钟槽内的监控指标值存入数据库,并重新初始化该序号分钟槽。
对于计算模块31,时间槽用于存储年索引值、日索引值、分钟索引值、监控指标值。时间槽中的年索引值、日索引值、分钟索引值,三者联合组成了槽标识。
年索引值是指年值,日索引值是指该天是在一年中的第几天,分钟索引值是指该分钟数在一天中是第几分钟。比如2017年6月23日凌晨1点18分,其年索引值是2017,日索引值是174,分钟索引值是78,分钟槽索引值78模3的结果值是0,表示该分钟的数据是保存在第0个分钟槽中。通过流式计算得到时间戳时间信息对应的年索引值、日索引值和分钟索引值用于后续使用。
对于对比模块32,通过将计算后的时间索引值分别与三个时间槽的时间索引值比较,才能判定计算后的时间索引值与时间槽的时间索引值是否一致。只有新进来逻辑和物理服务数据的年、日、分钟这三个索引值与时间槽对应的年、日、分钟这三个索引值相等时,才会把新进来逻辑和物理服务数据的监控值叠加到分钟槽现有的监控指标值中。
对于取模模块33,当对比模块32判定计算后的时间索引值等于对应任一时间槽的时间索引值,则以分钟索引值取模。当判定计算后的时间索引值不等于对应任一时间槽的时间索引值时,则不会把新进来逻辑和物理服务数据的监控值叠加到分钟槽现有的监控值中。
具体的,取模模块33,用于识别取模结果值,并对监控指标值进行累加和计算。
根据识别到的取模结果值的大小对对应分钟槽内的监控指标值进行累加和计算。时间槽的个数是模数,也是监控指标值的发送周期,在准实时场景中,可取n分钟为一个发送周期,即对应有n个时间槽。分钟索引值%n的运算结果作为时间槽的序号,每个数据都需按分钟索引值在对应的时间槽中计算监控值。其中,n为自然数,可根据需要以其它数取模,如1、2、3、4等。
对于初始化模块34,当计算后的时间索引值大于最大的时间槽的索引值时,则将对应序号(序号是分钟索引值的取模结果值)的分钟槽的监控指标值存入数据库,并重新初始化该序号分钟槽。将原来的存在于分钟槽内的监控指标值去掉。
本方案通过流式计算准实时算出时间槽内的监控指标值、通过定义逻辑/物理服务与服务实例的对应关系建立面向业务和技术视角的服务拓扑关系,使得运维人员能从业务和技术视角全局监控复杂电信系统的运行状态;采用时间槽的方式计算监控指标值,使得监控指标值的准确度更高、使得监控指标值限定在较少的存储空间内。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!