一种基于Proxy日志数据的网络安全威胁分析方法及系统与流程
本发明涉及数据安全领域,具体涉及一种基于Proxy日志的网络安全威胁分析方法及系统。
背景技术:
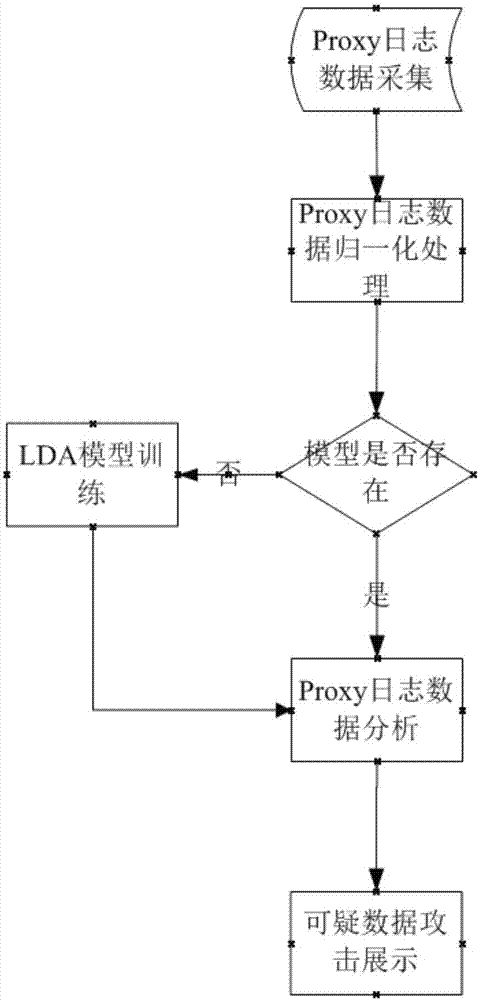
:Proxy是一种特殊的网络服务,允许一个网络终端通过这个服务与另一个网络终端进行非直接的连接。Proxy日志对客户端的访问信息进行了详细记录,通过对该日志进行分析,以辨识异常访问。机器学习LDA模型,利用监督和无监督机器学习技术,进行异常事件侦测,以辨识网路弱点。随着信息技术的快速发展,互联网技术得到了长足发展,对人们的生产生活带来了深远影响。网络技术给人们的工作学习生活带来方便的同时,也面临着巨大的挑战,网络环境交叉渗透,各种形式的异常流量,恶意攻击充斥网络,降低了网络性能,影响网络服务的正常提供。根据目前的网络安全态势,建立一个能快速、高效识别网络异常流量分析的检测模型迫在眉睫,从而保护网络环境,为人们放心安全使用网络应用打好基石。现有技术中存在一种基于异常的网络入侵检测系统(A-NIDS)。如图1,A-NIDS框架主要包括三个阶段:1.参数化阶段:系统将收集到信息按照预定的方式格式化或预处理。2.训练阶段:根据正常的行为特征表现进行分类,然后建立相应的模型。3.检测阶段:系统模型训练完成并可用,与得到的流量数据进行对比,如果发现偏差超过给定的阀值时,系统将发出警告,生成检测报告。上述方案主要存在以下缺点:分析效率低,发出警告速度慢,用户不便于快速定位问题所在。技术实现要素:本发明需要解决的问题包括:Proxy日志数据的采集和归一化处理;基于spark的机器学习lda分析模型的建立和应用;异常流量分析结果的攻击地图显示。为解决上述技术问题,本发明提供了一种基于Proxy日志的网络安全威胁分析方法,其特征在于,该方法包括以下步骤:1)对镜像网络流量数据进行采集,并对采集的Proxy请求数据进行归一化处理,以输入的Proxy数据作为输入文档,通过大量该输入文档对LDA分析模型进行训练,得到收敛的结果,并保存训练好的LDA分析模型,同时设定一个告警阈值;2)通过所述LDA分析模型对新采集到的Proxy请求数据进行分析得到一个分值;3)当判断分值低于告警阀值时,确定新采集的DNA数据为可疑Proxy请求数据,在前端页面进行展示,向用户告警,否则直接跳转到步骤4);4)结束。根据本发明的方法,优选的,在所述步骤3)中当判断分值低于告警阀值时,确定新采集的DNA数据为可疑Proxy请求数据,在前端页面进行展示,向用户告警之后,还包括下列步骤:针对确定的发现的可疑Proxy请求数据进行分析,找到该可疑Proxy请求数据对应的源IP地址和目的IP地址,并与对应的位置信息关联,展示在地图上。根据本发明的方法,优选的,所述LDA分析模型中,将对Proxy请求数据处理后的词语形成的文档作为文档集合D,将Proxy请求数据处理后形成的词语作为文档词语集合W,将Proxy请求数据中的网络行为主题作为文档主题集合T。根据本发明的方法,优选的,所述Proxy请求数据中每个词语在文档集合中出现的概率标识为:根据该概率确定新采集到的Proxy请求数据的分值。根据本发明的方法,优选的,所述Proxy请求数据处理后的词语由以下参数组成:Proxy请求数据中的域名标识、请求时间、请求方式、访问uri的熵、返回值类型和返回代码。为解决上述技术问题,本发明提供了一种基于Proxy日志的网络安全威胁分析系统,其特征在于,该系统包括:LDA分析模型训练模块,对镜像网络流量数据进行采集,并对采集的Proxy请求数据进行归一化处理,以输入的Proxy数据作为输入文档,通过大量该输入文档对LDA分析模型进行训练,得到收敛的结果,并保存训练好的LDA分析模型,同时设定一个告警阀值;Proxy数据分析模块,通过所述LDA分析模型对新采集到的Proxy请求数据进行分析得到一个分值;告警模块,当判断分值低于告警阀值时,确定新采集的DNA数据为可疑Proxy请求数据,在前端页面进行展示,向用户告警。根据本发明的系统,优选的,所述告警模块包括:展示子模块,用于针对确定的发现的可疑Proxy请求数据进行分析,找到该可疑Proxy请求数据对应的源IP地址和目的IP地址,并与对应的位置信息关联,展示在地图上。根据本发明的系统,优选的,所述LDA分析模型中,将对Proxy请求数据处理后的词语形成的文档作为文档集合D,将Proxy请求数据处理后形成的词语作为文档词语集合W,将Proxy请求数据中的网络行为主题作为文档主题集合T。根据本发明的系统,优选的,所述Proxy请求数据中每个词语在文档集合中出现的概率标识为:根据该概率确定新采集到的Proxy请求数据的分值。为解决上述技术问题,本发明提供了一种计算机可读存储介质,该介质存储有计算机程序指令,其特征在于,当执行所述计算机程序指令时,实现如上述之一的方法。采用本发明的技术方案,取得了以下技术效果:1.功能扩展:基于Proxy日志数据的机器学习威胁检测方法可以快速发现网络中的异常Proxy请求,及时向用户报警,提高处理威胁发现处理效率。2.实时性:基于LDA分析模型使得数据的分析以近乎实时的速度完成,强化了系统审计功能和警报功能的时效性。3.人机界面友好性:以直观的方式将整个攻击按IP地址的位置信息展示在地图上,以便使用者快速定位到问题的所在。附图说明图1为现有技术数据分析流程图。图2为本发明的数据分析流程图。图3为本发明的LDA分析模型概率计算矩阵图。具体实施方式LDA(LatentDirichletAllocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。[1]LDA是一种非监督机器学习技术,可以用来识别大规模文档集(documentcollection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bagofwords)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。LDA生成过程对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):1.对每一篇文档,从主题分布中抽取一个主题;2.从上述被抽到的主题所对应的单词分布中抽取一个单词;3.重复上述过程直至遍历文档中的每一个单词。语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布(multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。[1]LDA整体流程先定义一些字母的含义:文档集合D,主题(topic)集合TD中每个文档d看作一个单词序列<w1,w2,...,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)D中涉及的所有不同单词组成一个大集合VOCABULARY(简称VOC),LDA以文档集合D作为输入,希望训练出的两个结果向量(设聚成k个topic,VOC中共包含m个词):对每个D中的文档d,对应到不同Topic的概率θd<pt1,...,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。对每个T中的topict,生成不同单词的概率φt<pw1,...,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。LDA的核心公式如下:p(w|d)=p(w|t)*p(t|d)直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。[2]LDA学习过程LDA算法开始时,先随机地给θd和φt赋值(对所有的d和t)。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。再详细说一下这个迭代的学习过程:1.针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:pj(wi|ds)=p(wi|tj)*p(tj|ds)2.现在我们可以枚举T中的topic,得到所有的pj(wi|ds),其中j取值1~k。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量),即argmax[j]pj(wi|ds)3.然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w|d)的计算。对D中所有的d中的所有w进行一次p(w|d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。下面结合附图以及具体实施例对本发明作进一步的说明,但本发明的保护范围并不限于此。<Proxy数据分析方法>结合图2,在对Proxy数据进行分析之前,需要采集Proxy数据,并进行归一化处理,并定义相应的数据结构,然后利用大量文档数据训练LDA分析模型,并对异常Proxy数据告警,主要包括以下步骤:(1)通过Proxy数据采集模块对导入的镜像网络流量数据进行采集。并对采集的数据进行归一化处理。处理后的消息字段包括如下数据结构:接收到数据的时间年月天小时分钟秒时间段源IP地址目的IP地址源端口号目的端口号协议类型输入包数输入包字节数输出包数输出包字节数(2)LDA(文档主题模型)分析模型建立,以输入的Proxy数据作为输入文档,通过大量文档数据对模型进行训练,得到收敛的结果。将训练好的模型保存下来,对新采集到的Proxy数据进行分析打分,设定一个阀值,当分值低于阀值时,认为该ClientIP请求数据为可疑Proxy请求数据,在前端页面进行展示,给用户做出报警。所述分值是根据Proxy请求数据计算得到的概率来确定的,而所述阈值是用户根据需求和经验确定,不是一个固定值。(3)异常流量分析结果的攻击地图展示,对第二步中发现的可疑数据进行分析,找到该可疑的ClientIP地址,将该ClientIP地址、ServerIP地址与对应的位置信息关联上,并将该攻击展示在地图上。Proxy日志分析模型功能实现:LDA(LATENTDIRICHLETALLOCATION)文档主题模型简介LDA是一种非监督机器学习技术,可以用来识别大规模文档集(documentcollection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bagofwords)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。如果我们要生成一篇文档,它里面的每个词语出现的概率为:这个概率公式可以用矩阵表示如图3所示。本发明中与LDA模型对应的文档主题定义如下:ModelProxy日志documentProxy记录处理后的单词形成的文档wordProxy记录处理后形成的单词topic网络行为方面的主题LDA模型训练的本质是获得获得一个单词在文档中的概率分布函数,然后根据这个概率分布函数每次生成一个单词。因此,为了使基于Proxy数据的LDA模型训练得到有意义的结果,必须对收集到的Proxy数据进行分词处理,因为归一化处理以后的数据的Proxy数据是由networkaddresses和timestamps来标识的,这些数据基本上没有重复性,直接通过这些数据无法训练出有意义的模型。Proxy数据的分词处理将每条Proxy日志记录简化处理为一个与发起Proxy查询请求的ClientIp(客户端IP地址)对应的的word(单词)。Word(单词)的具体创建规则如下:DNS查询域名解析:例如:www.baidu.com,该url的域名解析之后为顶级域名com,子域名为baidu。分析中将顶级域名舍弃,根据子域名满足的条件对该标识位进行赋值。如果域名属于Alexa域名列表前100万中的数据,则将该标识位置为1。如果域名属于用户自定义域名值,则将该标识位置为2。如果不属于上述两种情况则将该标识位置为0。Timeofday(时间)该标识位的值为DNS日志中p_time字段对应时间的小时数。RequestMethod(请求方式)使用数据中reqmethod字段的值标识。EntropyofURI(访问uri的熵)计算出数据中fulluri字段的熵值,根据熵值落在如下数据大小区间所对应的编号做为该标识的值。如计算出来的熵为1.2,则与区间(0.9,1.2]对应的编号4相对应。(0.0,0.3,0.6,0.9,1.2,1.5,1.8,2.1,2.4,2.7,3.0,3.3,3.6,3.9,4.2,4.5,4.8,5.1,5.4,20)Responsecontenttype(返回值类型)使用resconttype字段的值做为该标识。Responsecode(返回代码)使用respcode字段的值做为该标识。单词生成示例A.一条Proxy数据为p_time:”Jul8201606:02:04.651847000UTC”,reqmethod:”POST”,fulluri:”hsn.mpl.miisolutions.net/send/1294067758/3”,resconttype:”image”,respcode:”OK”,ClientIP:”172.16.0.183”,ServerIP:”10.0.3.243”。生成的单词为:“1_2_POST_5_image_OK”。<Proxy数据分析系统>本发明公开了一种基于Proxy日志的网络安全威胁分析系统,其特征在于,该系统包括:LDA分析模型训练模块,对镜像网络流量数据进行采集,并对采集的Proxy请求数据进行归一化处理,以输入的Proxy数据作为输入文档,通过大量该输入文档对LDA分析模型进行训练,得到收敛的结果,并保存训练好的LDA分析模型,同时设定一个告警阀值;Proxy数据分析模块,通过所述LDA分析模型对新采集到的Proxy请求数据进行分析得到一个分值;告警模块,当判断分值低于告警阀值时,确定新采集的DNA数据为可疑Proxy请求数据,在前端页面进行展示,向用户告警。所述告警模块包括:展示子模块,用于针对确定的发现的可疑Proxy请求数据进行分析,找到该可以Proxy地址对应的源IP地址和目的IP地址,并与对应的位置信息关联,展示在地图上。所述LDA分析模型中,将对Proxy请求数据处理后的词语形成的文档作为文档集合D,将Proxy请求数据处理后形成的词语作为文档词语集合W,将Proxy请求数据中的网络行为主题作为文档主题集合T。所述Proxy请求数据中每个词语在文档集合中出现的概率标识为:根据该概率确定新采集到的Proxy请求数据的分值。所述Proxy请求数据处理后的词语由以下参数组成:Proxy请求数据中的域名标识、请求时间、请求方式、访问uri的熵、返回值类型和返回代码。以上实施例仅作为本发明保护方案的示例,不对本发明的具体实施方式进行限定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1