一种基于全景视频的图文跟随合成方法与流程
本发明涉及计算机视频图形处理领域,特别设计视频编辑和图文图形处理领域,具体涉及一种基于全景视频的图文跟随合成方法。
背景技术:
全景视频是一种新型的技术,最近几年才开始真正成熟起来。全景视频拍摄就是将一定范围内的某个时间段,记录周围所发生的一切,并且展现出来。主要用于旅游景点拍摄、医疗上的观察、或者娱乐性用途现。
全景视频预览过程中,用户的预览变得十分单一,除了图像信息,基本看不到图文描述。在对某一个物件信息进行了解时全景视频的拍摄是不能完全实现的,需要在后期进行图文并描述。
当前技术上的缺陷是图文和全景视频的分离,不能与场景中的人物,景物及其他设施有机地结合。目前,对于视频和图文的合成只是简单地将图文与视频相叠加,如第201511029298.x号中国专利申请。该申请中,只是简单地在每个视频段中输入字母和音频,并没有将图文与视频中的景物、设施以及人物实现无缝的叠加,实施有机融合,因此,合成后的视频看起来呆板、不生动,无法展现逼真的三维效果,造成用户体验非常不好。这其中的原因是无法将叠加图文与全景视频进行关联,从而实现无缝融合。造成这种问题的根本原因是不能取得全景视频的参数或者没有利用全景视频的参数来调节叠加图文的参数。没有办法实现图文信息跟随物体移动和三维展现的视觉效果。
另一方面,如果标记的文本信息太多,图文信息又会遮挡其它场景物体,大量的图文信息又会给带来不好的用户体验。
技术实现要素:
针对上面提到的现有技术中存在的技术问题,本发明提出了一种基于全景视频的图文跟随合成方法。本方法通过对全景视频进行三维场景的还原、推算摄像机参数、在三维空间内的物体进行图文叠加,解决了当前现有技术中的图文和全景视频的分离,不能与场景中的人物,景物及其他设施有机地结合,从而无法展示逼真的三维效果,造成用户体验很差的技术问题。
本发明的一种基于全景视频的图文跟随合成方法包括:
一种基于全景视频的图文跟随合成方法,其包括:
实际参数获取,测量和记录全景视频录制场景中的灯光、布景以及摄像机运动等实际参数;
视频分析及参数获取,对全景视频进行分析并获取分析参数;
三维场景还原,根据所述实际参数和所述分析参数,将全景视频还原到三维场景;
添加图文和三维素材,在还原的所述三维场景中叠加图文和三维素材;
渲染并生成新的全景视频。
其中,在视频分析及参数获取步骤中,还可以进一步包括如下处理步骤:a)将全景视频拆并分析全景视频每一帧的数据;b)根据每一帧的数据获取摄像机参数信息和位置参数;c)根据数据寻找标记物,将所述标记物做为参照生成特征点,即特征图像;d)对全景视频内的所述特征点进行识别;e)通过所述特征点的距离大小和现实的距离大小生成比例;f)通过根据所述特征点的距离大小以及和现实的距离大小生成的比例,反算出摄像机的位置、焦距信息。
此外,可选择地,在所述添加图文和素材步骤中,还包括根据实际参数计算出与场景匹配的虚拟三维物件的应有大小,并在三维场景下根据摄像机参数、特征点和要提示的物件的比较,对三维图元的动静态参数进行调整和适配。
根据本发明的可选择的具体实施方式,所述实际参数和所述分析参数通过下述方式获取:
a’)记录原始参数做为实际参数;
b’)对布置在视频中的参照物进行比例运算获取分析参数;
c’)对视频中的可以作为参照物的物体进行测量推算场景参数做为分析参数;
d’)通过运动分析和跟踪算法反算出所录制视频的摄像机参数信息和布景的位置参数做为分析参数。
此外,可选地,在所述添加图文和三维素材的步骤中,在转换完成的三维场景中还可以进一步进行如下处理:
a”)图文结合和遮罩:使用与场景中人物景物及设施相同的参数或对所述实际参数做偏移处理进行图文叠加;
b”)图文跟踪:按所述实际参数动态修改叠加三维图文的参数,修改三维场景中三维图文的位置和旋转,在不同的角度实现图文信息预览和变化;
c”)相对运动:以所述实际参数作为输入值通过特效算法计算和叠加图文的参数;
d”)场景修饰:根据原场景的人物和景物设施的参数及轮廓,制作三维场景物件,动态修改其参数,从而达到修饰效果。
对于特征点进行识别的处理可选择地,能够使用模板匹配法对全景视频内的所述特征点进行识别。其中,通过滑动模板图像和原图像进行对比,来确定最匹配的区域,从而对所述特征点进行识别。
在可替换的另外的实施例中,所述特征点的距离可通过如下步骤进行计算:
a”’)将图像转换成灰度图像;
b”’)将图像骨架化,把图像核心的骨架留下,其他的赘余点删除,得到一条单像素厚度的直线段;
c”’)使用霍夫变换的phtt方法,返回的是直线的方向以及范围,即返回的检测到的直线的两端点。
d”’)根据检测图像直线的两端点,计算特征点的距离。
本发明通过上述技术方案,很好解决了现有技术中图文和全景视频的分离、无法与场景中的人物、景物及其他设施有机地结合的缺陷,从而使叠加的图文与全景视频进行关联,在全景漫游过程中实现图文跟随效果,以不同角度展现不同的显示方式,以免对其它场景的遮挡。还可以在全景视频的场景中进行三维素材的叠加,最终合成为叠加三维图文的全景视频,从而能够逼真地展示带有图文的全景视频的三维效果,实现全景视频的高可读性,给用户带来逼真的三维视觉效果的体验。
附图说明
图1为根据本发明实施例的一种基于全景视频的图文跟随合成方法的流程图;
图2为本发明实施例中的视频分析及参数获取的流程图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,下面所描述的实施例仅是本发明的实施例,其仅用于更加清楚地对本发明进行解释和说明,并不能以此来限定本发明的保护范围。
本发明的方法本方法通过对全景视频进行三维场景的还原,推算摄像机参数,在三维空间内的物体进行图文叠加,从而实现在全景漫游过程中的图文跟随效果,不同角度展现不同的显示方式,以免对其它场景的遮挡。还可以在全景视频的场景中进行三维素材的叠加。最终合成为叠加三维图文的全景视频。
在三维场景下,根据摄像机参数、特征点和要提示的物件进行比较,在对三维图元的动静态参数进行调整适配实现图文或者三维素材的叠加;通过对全景视频中的特征点分析;通过特征点的距离大小等信息反算出计算机摄像的位置、焦距信息,把全景视频还原到三维场景。
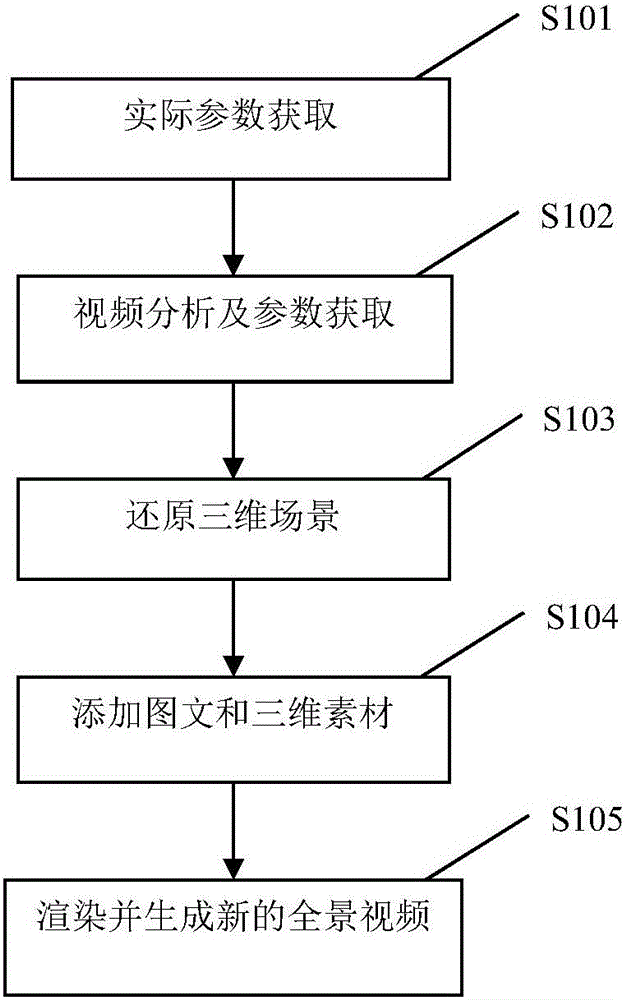
具体参考图1,本发明的一种基于图像识别的广角摄像机畸变渲染方法包括:
s101,实际参数获取,测量和记录全景视频录制场景中的灯光、布景以及摄像机运动等实际参数;
s102,视频分析及参数获取,对全景视频进行分析并获取分析参数;
s103,三维场景还原,根据所述实际参数和所述分析参数,将全景视频还原到三维场景;
s104,添加图文和三维素材,在还原的所述三维场景中叠加图文和三维素材;
s105,渲染并生成新的全景视频。
在可选择的另一实施例中,在视频分析及参数获取步骤中,还可以进一步包括如下处理步骤:
s1021,分析全景视频。将全景视频拆并分析全景视频每一帧的数据;
s1022,摄像机参数获取。根据每一帧的数据获取摄像机参数信息和位置参数;
s1023,寻找标记物,生成特征点。根据数据寻找标记物,将所述标记物做为参照生成特征点,即特征图像;
s1024,特征点识别。对全景视频内的所述特征点进行识别;
s1025,比例计算。通过所述特征点的距离大小和现实的距离大小生成比例;
s1026,反算计算机摄像的位置、焦距信息。通过根据所述特征点的距离大小以及和现实的距离大小生成的比例,反算出摄像机的位置、焦距信息。
通过上述处理步骤,能够获得全景视频还原成三维场景以及在三维场景中叠加三维图文素材的参数。
此外,可选择地,在s104添加图文和素材步骤中,还包括根据实际参数计算出与场景匹配的虚拟三维物件的应有大小,并在三维场景下根据摄像机参数、特征点和要提示的物件的比较,对三维图元的动静态参数进行调整和适配。
通过这样的处理,能够根据场景的大小,精确地控制虚拟三维物件的尺寸,从而能够将三维素材准确并合适地叠加在三维场景中,不会导致因比例不一致而造成不协调的视觉效果。
可选的实施方式中,所述实际参数和所述分析参数可以通过下述具体方式获取:
a’)记录原始参数做为实际参数;
b’)对布置在视频中的参照物进行比例运算获取分析参数;
c’)对视频中的可以作为参照物的物体进行测量推算场景参数做为分析参数;
d’)通过运动分析和跟踪算法反算出所录制视频的摄像机参数信息和布景的位置参数做为分析参数。
此外,在所述添加图文和三维素材的步骤中,为了使三维图文跟三维场景无缝地融合,在转换完成的三维场景中还可以进一步进行如下处理:
a”)图文结合和遮罩:使用与场景中人物景物及设施相同的参数或对所述实际参数做偏移处理进行图文叠加;
b”)图文跟踪:按所述实际参数动态修改叠加三维图文的参数,修改三维场景中三维图文的位置和旋转,在不同的角度实现图文信息预览和变化;
c”)相对运动:以所述实际参数作为输入值通过特效算法计算和叠加图文的参数;
d”)场景修饰:根据原场景的人物和景物设施的参数及轮廓,制作三维场景物件,动态修改其参数,从而达到修饰效果。
对于特征点进行识别的处理,可使用模板匹配法对全景视频内的所述特征点进行识别。在模板匹配法中,首先需要在全景视频中寻找与另一幅特征点图像最匹配(相似)部分,具体来说,在全景视频里,需要找到一块跟模板匹配的区域,即特征图像,因此需要检测最匹配的区域:为了确定匹配区域,通过滑动模板图像和原图像进行对比,来确定最匹配的区域,从而对所述特征点进行识别。
具体匹配过程为:通过移动特征图像块一次移动一个像素(从左往右,从上往下)。在每一个位置,都进行一次度量计算来表明它是“好”或“坏”地与那个位置匹配(或者说特征图像和原图像的特定区域有多么相似)。
此外,所述特征点的距离可使用霍夫变换中的phtt方法,其返回的是直线的方向以及范围,具体来说,实际上返回的就是检测到的直线的两端点,具体步骤如下:
a”’)将图像转换成灰度图像;
b”’)将图像骨架化,把图像核心的骨架留下,其他的赘余点删除,得到一条单像素厚度的直线段;
c”’)使用霍夫变换的phtt方法,返回的是直线的方向以及范围,即返回的检测到的直线的两端点。
d”’)根据检测图像直线的两端点,计算特征点的距离。
在实际操作中,可使用zhang并行快速算法对图像细化。
通过上述技术方案,本发明很好解决了现有技术中图文和全景视频的分离、无法与场景中的人物、景物及其他设施有机地结合的缺陷,从而使叠加的图文与全景视频进行关联,在全景漫游过程中实现图文跟随效果,以不同角度展现不同的显示方式,以免对其它场景的遮挡。还可以在全景视频的场景中进行三维素材的叠加,最终合成为叠加三维图文的全景视频,从而能够逼真地展示带有图文的全景视频的三维效果,实现全景视频的高可读性,给用户带来逼真的三维视觉效果的体验,具有非常好的应用前景。
以上对本发明的具体实施方式进行了详细的描述,但本领域内的技术人员根据本发明的创造性概念,可以对本发明进行各种变形和修改,但所做的各种变形和修改不脱离本发明的精神和范围,皆属于本发明权利要求的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!