一种异构网络中用户关联的GA-BPNN方法与流程
本发明属于通信的技术领域,特别涉及异构网络中用户关联的方法。
背景技术:
在传统的同构网络中,用户通常根据参考信号接收强度(Reference Signal Receiving Power,RSRP)或者信干噪比(Signal to Interference and Noise Ratio,SINR)选择关联基站(Base Station,BS)。然而,这类用户关联算法在异构网络中不再适用。异构网络中,宏基站(Macro BS,MBS)的发射功率通常比微小站(Small BS,SBS)大得多。比如,宏基站的发射功率可达40Watt,而微小站的传输功率为1Watt或者更低。相比于SBS,来自MBS的RSRP或者SINR要高得多,因此大多数用户将与MBS关联,从而导致MBS负载过重而SBS可能空载,此时用户体验和网络吞吐量没有得到提升,而SBS空载产生了大量的电力资源浪费。小区覆盖扩展(Cell Range Expansion,CRE)技术通过增加偏移量,可是更多的用户与SBS关联。但是,位于扩展的覆盖区域内的用户会受到来自己MBS信号的严重干扰,导致用户体验下降。由此可见,异构网络中需要更优越的用户关联算法。
近期,相关文献将异构网络的用户关联问题建模成优化问题,并针对优化问题提出大量的算法。有一种做法是将用户关联建模成相应的因子图(factor graph),并提出了一种分布式的置信传播(belief propagation)算法。但是,这种做法中没有考虑现实场景中的QoS需求对算法的限制。
贪婪算法也是一种常用的解决用户关联问题的算法。针对合适的目标函数,通常能够利用贪婪算法获得最优解。但是,贪婪算法需要对所有可能解进行遍历,因而需要相当大的计算量,所以很难应用于现实系统中。
技术实现要素:
基于此,因此本发明的首要目地是提供一种异构网络中用户关联的GA-BPNN(Greedy Algorithm-based BPNN,GA-BPNN)方法,该方法以优化问题已平衡网络吞吐量和基站负载为目标,同时考虑了用户的数据速率要求,能以合理的计算复杂度逼近最优解,并能够同时给出合适的CoMP簇选择结果。
本发明的另一个目地在于提供一种异构网络中用户关联的GA-BPNN方法,该方法能够显著地降低计算复杂度和计算时长,同时获得接近最优的关联结果,提高了关联效率。
为实现上述目的,本发明的技术方案为:
一种异构网络中用户关联的GA-BPNN方法,其特征在于该方法首先对其进行数学建模,将用户关联问题的目标函数建模为:
其中,0<λ<1表示网络吞吐量在目标函数中的权重,表示用户k在过去一段时间内获得的平均数据率,
然后利用贪婪算法获得足够样本,然后对建立的BP神经网络进行训练,最终得到能够得到近似贪婪算法性能的神经网络,基本步骤包括:建立网络、样本预处理、训练和输出结果。
进一步,为了减少计算量,根据实际情况合理地缩小可能解的搜索范围,将用户的服务基站限制在与其相邻的3个MBS和5个SBS之中。
所述GA-BPNN的工作流程为:
101、建立网络;
建立一个4层的BP神经网络,包括一个输入层,两个隐层和一个输出层。其中,每个隐层都包含10个神经元。GA-BPNN方法的目标是针对任意用户k,输入其对应的O2中基站的相关信息后即可得到最优的用户关联结果。根据O2的定义以及公式给出的目标函数,将BP神经网络的输入定义如下的16维向量:
对于每个用户,GA-BPNN输出一个表明最优关联基站ID的值。综上所述,GA-BPNN每层的神经元数量为分别为16∶10∶10∶1。
输入层和隐层的传递函数选用tansig函数,输出层则选用purelin函数。每次训练中采用Levenberg-Marquardt(L-M)方法对神经元连接的权重进行调整。
102、样本预处理;
对BPNN进行训练和测试的数据样本来自于对前文所述的贪婪算法进行大量实验得到的数据。每个样本包括输入向量和一个输出的最优解,数据样本的结构如下:
其中,yk是贪婪算法判定的用户k的关联基站ID,即
因此,为了保障神经网络性能,需要对样本进行入以下预处理:
1021、数据分类:将全部数据样本分成两个相互独立的集合:训练集和测试集;训练集的样本只用于对神经网络进行训练;测试集中的样本则只用来测试BP神经网络的性能。使用相同的数据样本对神经网络进行训练和测试,容易加速训练的收敛,是神经网络陷入局部最优。因此,为了保障BP神经网络的性能,必须避免训练集和测试集中出现相同的样本。
1022、数据随机化:顺序上相连的样本容易出现较强的相似性。如果直接用来进行训练,也容易令BP神经网络陷入局部最优。为了避免这种情况,应对样本进行随机化处理。
1023、数据归一化数据样本的归一化有两个重要的目标:一是降低数据处理的复杂度、加快收敛;二是消除数据的物理意义,避免出现冲突。为此,将样本中的数据映射到[0,1]范围内。
103、训练。
利用预处理后的样本对设置好的BP神经网络进行训练。初始时,BP神经网络中权重是随机选取的。每次训练会根据输出的误差对权重进行调整,直到误差下降到给定的目标。然后利用测试样本检验BP神经网络的性能。如果能够满足要求,则保存当前网络。
105、输出结果。
对于用户k,将如公式(12)所示的输入向量输入到训练好的神经网络中,即可得到最有的关联基站ID。这个过程既可以在计算单元中并行处理,也可以有由每个用户独立完成,因而在实际系统中能够进一步缩短计算时间。
本发明提出了解决异构网络中用户关联问题的GA-BPNN方法。该方法能够显著地降低计算复杂度和计算时长,同时获得接近最优的关联结果。在考虑使用CoMP技术提升用户体验的场景中,GA-BPNN方法还能够提供适当的CoMP簇选择。仿真结果验证了GA-BPNN方法模拟贪婪算法的精确度可达到88%,而计算时长仅为贪婪算法的1/8。
附图说明
图1是本发明所实施宏小区构成的异构网络的拓扑图。
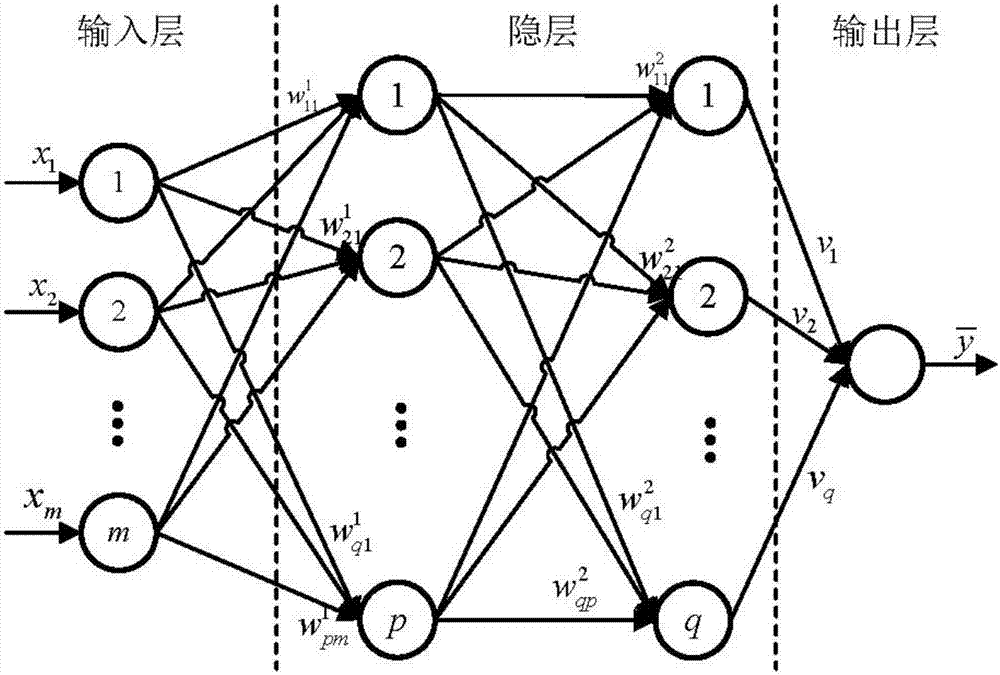
图2是本发明所实施BP神经网络结构图。
图3是本发明所实施的GA-BPNN的工作流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
考虑一个由N个宏小区构成的异构网络。每个宏小区由一个位于中心的宏基站(MBS),以及围绕在宏基站周围的M个微小站(SBSs)构建而成。共有K个用户随机分布在网络中。令Ψ表示网络中全部基站组成的集合,其中的前N个元素表示MBS的id。具体来说,Ψ的结构如下:
上述异构网络的拓扑如图1所示。
上述异构网络中,假设全部基站工作在相同的频段上。在LTE系统中资源分配的基本单位为资源块(Resource Block,RB)。因此,假设系统的总带宽为B Hz,被分为NRB个RB,每个RB的带宽则为b=B/NRBHz。
同时,假设所有的基站在实施传输之前可以知道瞬时信道新信息,因而能够根据这些信息计算最优的用户关联结果。
一个用户在进入网络的初期,必须要根据给定的规则与其中一个基站进行关联。与用户关联的基站将保留用户的注册信息,并向用户传输控制信息及数据信息。这个基站为用户的服务基站。在同构网络中,用户通常根据接收到的最大的RSRP(Reference Signal Receiving Power,RSRP)或SINR(Signal to Interference and Noise Ratio,SINR)选择服务基站。然而这种方法在异构网络中不再适用。由于MBS的发射功率通常比SBS大得多,因此根据RSRP或SINR进行用户关联,用户会更倾向于与MBS关联,而不是距离用户更近的SBS,从而导致MBS负载过重而SBS有可能空载。采用CRE(Cell Range Expansion)方法可以一定程度上解决上述的问题。CRE方法设定了一个偏移量,令用户可以与比MBS的RSRP(或SINR)小一些的SBS关联。但是CRE中位于扩展范围内的用户会受到MBS的强烈干扰,导致用户体验下降。定义一个比特变量表示用户k与基站i关联,则表示用户k不与基站i关联。值得注意的是,一个用户最多只能与一个基站关联,即
在异构网络中,由于基站间距大大缩短,因此位于基站覆盖边缘的用户遭受严峻的小区间干扰。因此,采用Joint Transmit Coordinated Multi-Point(JT CoMP,简称为CoMP)技术来对抗干扰。首先,我们将用户分为两类:小区中心用户(Cell Centre User,CCU)和小区边缘用户(Cell Edge User,CEU)。对于CEU来说,需要选择出一簇适用于CoMP传输的基站,成为用户的CoMP簇。CoMP簇内的基站以合作的方式向该用户传输数据,以增强数据信号强度并且降低对数据信号的干扰。另一方面,对于CCU采用CoMP技术并不会显著提升CCU的体验,因此通常指针对CEU采用CoMP技术。
考虑根据SINR门限进行分类。用户首先计算出接收到的全部参考信号的SINR,并找出其中的最大值,记为γmax。根据SINR的最大值,用户被按照以下规则进行分类:
其中,ε表示一个给定的阈值。
在对一个CCU传输时,该用户的服务基站向其发送数据信息,而其他同时发生的、在相同RB频率上的传输都将对该用户产生干扰。假设CCUk的服务基站为i(即),则CCUk在RBn上得到的SINR可表示为:
其中,表示用户k在RBn上得到的SINR;泰示基站i在RBn上的传输功率;表示在RBn上基站i与用户k之间的信道矩阵;表示相对应的预编码向量;σ2表示高斯白噪声的强度。
CEU的情况有所不同。由于对CEU采用了CoMP技术,因而一个CEU将会接收到承载相同数据信息的多个独立数据信号。对于一个CEUk,在RBn上得到的SINR可表示为:
其中,Ψk表示CEUk的CoMP簇;Ψ\Ψk表示网络中除CEUk的CoMP簇之外的全部基站组成的集合;表示k的服务基站的信号强度,表示k的CoMP簇中其他基站的信号强度的叠加。根据上式可以看出,CoMP技术通过增强数据信号强度和减少干扰实现CEU信干噪比的提高。
为了解决异构网络中的用户关联问题,我们首先对其进行数学建模,针对数学模型提出有效的解决方法。
在异构网络中,我们希望接近SBS的用户能够与SBS相关联,从而达到减轻MBS负载的、提升用户体验的目的。
假设基站可预先获得信道状态信息,因而能够对可能的传输进行预测。令表示在用户k与基站i关联的情况下在RBn上的传输可获得的信干噪比,可以下式进行估计:
在与基站i关联的情况下,用户k在全部RB上可获得的平均数据速率可表示为:
在实际系统中,用户的QoS需求涉及多种不同类型的参数。在这里我们只关注数据速率方面的用户需求。为了表述方便,我们假设所有用户的数据速率需求均为Rreq。根据公式(6)中的用户平均速率估计满足QoS需求所需的RB数量为:
另一方面,基站i能够分配给与其关联的用户的平均RB数量为:
其中,表示与基站i关联的用户总数。如果则预示着基站i不能为用户k提供满足需求的服务。令Ui表示与基站i相关联的用户中QoS得不到满足的用户数量。据此,定义一个反应基站负载情况的系数ωi如下:
如果ωi=1,表示:与基站i关联的全部用户能够获得满足QoS需求的服务,并且基站i的资源得到了充分的利用。
基于上式定义的负载系数,我们将用户关联问题的目标函数建模为:
其中,0<λ<1表示网络吞吐量在目标函数中的权重。λ越大,用户关联结果得到的吞吐量越大;反之,λ越小,负载均衡的权重就越大,用户关联结果得到的MBS与SBS的负载趋于一致。上式中的表示用户k在过去一段时间内获得的平均数据率。用对进行加权有助于提升网络中用户间的公平性。
贪婪算法可以用于求解上式中的优化问题。贪婪算法的核心是遍历所有可能解,选取其中满足目标函数的一组最优解作为输出。但是,上式(9)λ是一个连续的变量。为对求解上式,可先将λ离散化。需要注意的是,离散化的粒度越小,得到的最优λ精度越高,但同时计算量也越大。
为了进一步减少计算量,根据实际情况合理地缩小可能解的搜索范围。在现实系统中,一个用户不会选择与其距离较远的基站进行管理。出于这种考虑,将用户的服务基站限制在与其相邻的3个MBS和5个SBS之中。令Ωk表示可能与用户k关联的基站的结合,具体地,
其中,i1,i2,...,i8表示基站的ID。用户k可根据接收到的SINR选择出Ωk中的元素。
为了降低用户关联的计算量和时间消耗,本发明在上述贪婪算法的基础上提出了一种BP神经网络算法,简称GA-BPNN(greedy algorithm-based Back propagation neural Network)。
如图2所示,典型的BP神经网络包括一个输入层、若干个隐层和一个输出层。{x1,...,xm}表示BP神经网络的输入,表示神经元之间连接的权重,表示BP神经网络的输出。假设y*是输入{x1,...,xm}的真实输出,通过对与y*之间的误差进行分析,自动调整神经网络中的权重,这个过程层为训练。通过反复的训练,最终输出的误差逐渐收敛,此时得到的BPNN可以对原始函数进行精确的模拟。
GA-BPNN用户关联算法就是基于上述原理,利用贪婪算法获得足够样本,然后对建立的BP神经网络进行训练,最终得到能够得到近似贪婪算法性能的神经网络。GA-BPNN的基本步骤包括:建立网络、样本预处理、训练和输出结果。
GA-BPNN的工作流程如图3所示。
101、建立网络。
建立一个4层的BP神经网络,包括一个输入层,两个隐层和一个输出层。其中,每个隐层都包含10个神经元。GA-BPNN方法的目标是针对任意用户k,输入其对应的O2中基站的相关信息后即可得到最优的用户关联结果。根据O2的定义以及公式(10)给出的目标函数,可将BP神经网络的输入定义如下的16维向量:
对于每个用户,GA-BPNN输出一个表明最优关联基站ID的值。综上所述,GA-BPNN每层的神经元数量为分别为16∶10∶10∶1。
输入层和隐层的传递函数选用tansig函数,输出层则选用purelin函数。每次训练中采用Levenberg-Marquardt(L-M)方法对神经元连接的权重进行调整。BP神经网络的主要配置参数如表1所示。
102、样本预处理。
在GP-BPNN方法中,对BPNN进行训练和测试的数据样本来自于对前文所述的贪婪算法进行大量实验得到的数据。每个样本包括输入向量和一个输出的最优解,数据样本的结构如下:
其中,yk是贪婪算法判定的用户k的关联基站ID,即
因此,为了保障神经网络性能,需要对样本进行入下预处理:
1.数据分类:将全部数据样本分成两个相互独立的集合:训练集和测试集。训练集的样本只用于对神经网络进行训练;测试集中的样本则只用来测试BP神经网络的性能。使用相同的数据样本对神经网络进行训练和测试,容易加速训练的收敛,是神经网络陷入局部最优。因此,为了保障BP神经网络的性能,必须避免训练集和测试集中出现相同的样本。
2.数据随机化:顺序上相连的样本容易出现较强的相似性。如果直接用来进行训练,也容易令BP神经网络陷入局部最优。为了避免这种情况,应对样本进行随机化处理。
数据归一化数据样本的归一化有两个重要的目标:一是降低数据处理的复杂度、加快收敛;二是消除数据的物理意义,避免出现冲突。为此,将样本中的数据映射到[0,1]范围内。
103、训练。
利用预处理后的样本对设置好的BP神经网络进行训练。初始时,BP神经网络中权重是随机选取的。每次训练会根据输出的误差对权重进行调整,直到误差下降到给定的目标。然后利用测试样本检验BP神经网络的性能。如果能够满足要求,则保存当前网络。
106、输出结果。
对于用户k,将如公式(12)所示的输入向量输入到训练好的神经网络中,即可得到最有的关联基站ID。这个过程既可以在计算单元中并行处理,也可以有由每个用户独立完成,因而在实际系统中能够进一步缩短计算时间。
如果用户k是一个如公式(2)定义的CEU,那么它的CoMP簇是Ωk的一个子集,即为了选出合适的CoMP簇,GA-BPNN会保存若干个次优解。假定CEU的CoMP簇中可以包含三个基站,其中之一为其关联基站,即GA-BPNN输出的最优解;另外两个基站则可以选择性能最接近最优解的两个次优解。
GA-BPNN既可获得接近于贪婪算法的性能,有大大缩短了计算所需的时间。GA-BPNN算法在输出最优用户关联结果的同时,还能给出合适的CoMP簇选择结果。实验证明,当根据GA-BPNN给出的CoMP簇选择结果实施CoMP传输后,CEU的平均速率出现了显著的提升。
因此,本发明提出了解决异构网络中用户关联问题的GA-BPNN方法。该方法能够显著地降低计算复杂度和计算时长,同时获得接近最优的关联结果。在考虑使用CoMP技术提升用户体验的场景中,GA-BPNN方法还能够提供适当的CoMP簇选择。仿真结果验证了GA-BPNN方法模拟贪婪算法的精确度可达到88%,而计算时长仅为贪婪算法的1/8。值得注意的时,在实际系统中,如果采用分布式计算方式,可进一步显著缩短GA-BPNN的运行时间。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!