视频编码的样式基础的运动向量推导之方法及装置与流程
本申请要求于2016年3月16日提交的美国临时申请案63/309,001的优先权,本申请以引用方式包含该临时案的全部。
本发明有关于使用译码端推导的运动信息(decodersidederivedmotioninformation)的视频编码的运动补偿。更具体地,本发明是有关于对以样式为基础的运动向量推导(pattern-basedmotionvectorderivation)的性能改善或减少复杂度。
背景技术
在采用运动补偿帧间预测(motion-compensatedinterprediction)的普通视频编码系统中,运动信息通常由编码器端发送到解码器端,如此解码器能正确执行运动补偿帧间预测。在这样系统中,运动信息会占用一些编码位。为了改进编码效率,在vceg-az07中揭露了一种解码器端的运动向量推导方法(jianlechen等人,furtherimprovementstohmkta-1.0,itu-telecommunicationsstandardizationsector,studygroup16question6,videocodingexpertsgroup(vceg),第52次会议:2015年6月19-26,华沙,波兰)。根据vceg-az07,解码器端运动向量推导方法使用两个帧率升高转换(framerateup-conversion,fruc)模式。fruc模式中的一个被称做b-片双向匹配(bilateralmatching)而fruc模式中的另一个被称做p-片或b-片的模板匹配(templatematching)。
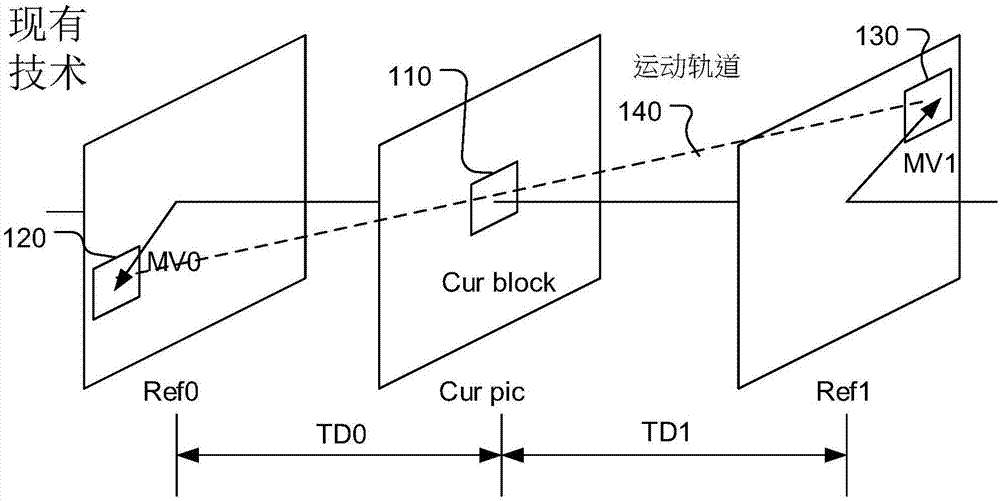
图1显示fruc双向匹配模式的一个例子,其中当前区块110的运动信息是基于两个参考图像推导。当前区块的运动信息是通过延着当前区块(curblock)的运动轨道(motiontrajectory)140上找到在两个不同参考图像(即ref0与ref1)中的两个区块(120与130)之间的最佳匹配来推导。在连续运动轨道的假定下,指向两个参考区块的与ref0相关的运动向量mv0以及与ref1相关的运动向量mv1应该与时域距离(temporaldistances)成比例,即td0与td1,在当前图像(即curpic)与两个参考图像之间。
图2显示fruc模板匹配模式的一个例子。当前图像(即curpic)中的当前区块210的邻接区域(neighbouringareas)(220a与220b)用做一个模板,来与参考图像(即ref0)中的对应模板(230a与230b)匹配。模板220a/220b与模板230a/230b之间的最佳匹配会决定一解码器推导的运动向量(decoderderivedmotionvector)240。虽然ref0如图2所示,ref1也可做为参考图像。
根据vceg-az07,在merge_flag或skip_flag为真时发信(signalled)fruc_mrg_flag。如果fruc_mrg_flag为1,那么fruc_merge_mode被发信来指示双向匹配合并模式(bilateralmatchingmergemode)或模板匹配合并模式被选择。如果fruc_mrg_flag为0,这暗示使用一般合并模式(regularmergemode)且在此情况下发信一个合并索引(mergeindex)。在视频编码中,为了改善编码效率,一个区块的运动向量可用运动向量预测(motionvectorprediction,mvp)来预测,其中会产生一个候选表。在合并模式中可使用合并候选表(mergecandidatelist)来编码一个区块。当使用合并模式来编码一个区块时,区块的运动信息(e.g.motionvector)可用合并mv表中的候选mv中的一个表示。因此,取代直接传输区块的运动信息,传输一个合并索引(mergeindex)给解码器端。解码器维持一个同样的合并表且使用合并索引来取回(retrieve)由合并索引发信的合并候选。一般来说,合并候选表(mergecandidatelist)包含少数候选并且传输合并索引比传输运动信息更有效。当区块在合并模式下编码时,其运动信息通过发信一个合并索引与临近区块的运动信息“合并”,而非实际上传输运动信息。可是,预测残值(predictionresiduals)仍要传输。在预测残值为零或非常小的情况下,预测残值被“跳过(skipped)”(即跳过模式)并且区块用合并索引来确认合并表中的合并mv来于跳过模式下编码。
虽然术语fruc是指帧率上升转换(framerateup-conversion)的运动向量,但其技术是用于解码器推导一或多个合并mv候选而无需实际传输运动信息。如此,本申请中fruc也被称做解码器推导的运动信息。因为模板匹配方法是基于样式的推导技术(pattern-basedmvderivationtechnique),fruc的模板匹配方法在本申请中也被称做基于样式的推导(pattern-basedmvderivation,pmvd)。
在解码器端mv推导方法,叫做时域推导的mvp的新的时域mvp是通过扫描所有参考帧内的所有mv来推导。为了推导list_0时域推导的mvp,对于list_0参考帧中的每个list_0mv,mv被缩放(scaled)以指向当前帧。被缩放之mv所指向的当前帧内的4x4区块是目标当前区块(targetcurrentblock)。该mv进一步缩放以指向到在list_0中的refidx等于0的参考图像给该目标当前区块。该进一步缩放的mv因目标当前区块被储存于list_0mv字段内。图3a与图3b分别显示list_0与list_1的推导时域推导的mvp的例子。在图3a与图3b中,每个小正方形区块对应于4x4区块。时域推导的mvp的流程扫描所有参考图像中缩有4x4区块内的所有mv,以产生当前帧的时域推导的list_0与list_1的mvp。例如,图3a中,区块310,区块312及区块314分别对应当前图像的4x4区块,索引等于0(即refidx=0)的list_0参考图像以及索引等于1(即refidx=1)的list_0参考图像。索引等于1的list_0参考图像的两个区块内的运动向量320与330是已知的。然后,时域推导的mvp322与332能通过分别缩放运动向量320与330推导。缩放的mvp接着被指派给一个对应区块。类似的,在图3b中,区块340,区块342与区块344分别对应当前图像的4x4区块,索引等于0(即refidx=0)的list_1参考图像以及索引等于1(即refidx=1)的list_1参考图像。索引等于1的list_0参考图像的两个区块内的运动向量350与360是已知的。然后,时域推导的mvp352与362能通过分别缩放运动向量350与360推导。
对于双向匹配合并模式及模板匹配合并模式,采用两阶段匹配(two-stagematching)。第一阶段是pu-级(pu-level)匹配,且第二阶段为子-pu-级匹配。于pu-级匹配中,分别选择list_0与list_1中多个初始mv。这些mv包含来自合并候选的mv(即传统的合并候选,例如hevc标准中指定的那些)以及来自时域推导的mvp的mv。为两个表产生两个不同的主要(staring)mv组。对于一个表中的每个mv,通过合成该mv与镜像(mirrored)mv来产生mv对(pair),该镜像mv是通过缩放该mv到另一表来推导。对于每个mv对,两个参考区块通过使用该mv对来补偿。计算这两个区块的绝对差之和(sumofabsolutelydifferences,sad)。选择具有最小sad的mv对为最佳mv对。
在推导pu的最佳mv之后,执行钻石搜寻(diamondsearch)来改善mv对。改善精度为1/8-pel。改善的搜寻范围限制在±1像素内。最终mv对是pu-级推导之mv对。钻石搜寻是一种视频编码界熟知的快速区块匹配运动估计算法。因此,钻石搜寻算法之细节不再赘述。
对于第二阶段子-pu-级搜寻,当前pu被划分为子-pu。子-pu的深度(例如3)在序列参数组(sequenceparameterset,sps)中发信。最小子-pu尺寸为4x4区块。对于每个子-pu,在list_0与list_1中选择多个开始mv,其包含pu-级推导之mv,零mv,当前子-pu与右下(bottom-right)区块的hevc同位(collocated)tmvp,当前子-pu的时域推导的mvp,以及左面及上面pu/子-pu的mv。通过使用例如pu-级搜寻的类似机制,决定子-pu的最佳m对。执行钻石搜寻来改善mv对。执行该子-pu的运动补偿来产生该子-pu的预测子(predictor)。
对于模板匹配合并模式,上面4列与左面4行的重建(reconstructed)像素用来形成一模板。执行模板匹配来寻找最佳匹配的模板及其对应mv。模板匹配也采用两阶段匹配。在pu-级匹配中,分别选择list_0与list_1中的多个开始mv。这些mv包含来自合并候选的mv(即传统合并候选,例如在hevc标准中指定的那些)以及来自时域推导的mvp的mv。产生两个表的两个不同开始mv。对于一个表中的每个mv,计算具有该mv的模板的sad成本。具有最小成本的mv为最佳mv。接着执行钻石搜寻来改善mv。改善精度为1/8-pel。改善搜寻范围限制在±1像素内。最终mv是pu-级推导的mv。list_0与list_1中的mv是独立产生的。
对于第二阶段子-pu-级搜寻,当前pu被划分为子-pu。子-pu的深度(例如3)在序列参数组sps中发信。最小子-pu尺寸为4x4区块。对于每个在左面或顶部pu边界的子-pu,在list_0与list_1中选择多个开始mv,其包含pu-级推导的mv的mv,零mv,当前子-pu与右下(bottom-right)区块的hevc同位(collocated)tmvp,当前子-pu的时域推导的mvp,以及左面及上面pu/子-pu的mv。通过使用例如pu-级搜寻的类似机制,决定子-pu的最佳m对。执行钻石搜寻来改善mv对。执行该子-pu的运动补偿来产生该子-pu的预测子。因为这些pu不是在左面或顶部pu边界,不采用第二阶段子-pu-级搜寻,且对应mv设为等于第一阶段中的mv。
在此解码器mv推导方法中,也用模板匹配来产生帧间模式编码的mvp。当选择一参考图像时,执行模板匹配来于选择的参考图像上寻找一最佳模板。其对应mv为推导的mvp。该mvp被插入进amvp中第一位置。amvp表示进阶mv预测,其中当前mv是使用候选表来预测编码(codedpredictively)。当前mv与候选表中选择的mv候选之间的差被编码。
双向光流(bi-directionalopticalflow,bio)于jctvc-c204中揭露(作者为elenaalshina与alexanderalshin,“bi-directionalopticalflow”,jointcollaborativeteamonvideocoding(jct-vc)ofitu-tsg16wp3andiso/iecjtc1/sc29/wg11第三次会议:广州,中国,7-15,2010年10月)以及vecg-az05中揭露(作者为e.alshina等人,knowntoolsperformanceinvestigationfornextgenerationvideocoding,itu-tsg16question6,videocodingexpertsgroup(vceg),第52次会议:june2015年6月19-26,华沙,波兰,document:vceg-az05)。bio使用光流与稳定运动(steadymotion)的假定来达成采样级运动改善(sample-levelmotionrefinement)。这仅为真双向预测区块采用,其从两个参考帧预测而来,其中一个是先前帧而另一个是后续帧。于vceg-az05中,bio使用5x5窗口来推导每个采样的运动改善。因此,对于nxn区块,一(n+4)x(n+4)区块的运动补偿结果与对应梯度信息(gradientinformation)用于推导nxn区块的采样-基础的运动改善。根据vceg-az05,使用一个6-抽头梯度滤波器(6-tapgradientfilter)与6-抽头插值滤波器来产生bio的梯度信息。因此,bio的计算复杂度比传统的双向预测更高。为了更进一步提升bio的性能,提出下面方法。
在marpe等人所写的技术论文中(d.marpe,h.schwarz,andt.wiegand,“context-basedadaptivebinaryarithmeticcodingintheh.264/avcvideocompressionstandard”,ieeetransactionsoncircuitsandsystemsforvideotechnology,vol.13,no.7,pp.620-636,2003年7月),提出hevccabac的多参数机率(multi-parameterprobability)更新(上下文适应性二进制编码)。参数n=1/(1–α)是之前编码的单元(bins)数量的量度,其对当前更新(up-date)有很重要影响(“窗口尺寸”)。该值在一定意义上决定系统所需的平均存储。决定模型的灵敏度参数的选择是一个困难且重要问题。灵敏的系统能迅速应对真实变化。另一方面,不灵敏的模型不会对噪声及随机误差反应。两个参数都有用,但是互相制约。通过使用不同控制讯号,能于编码中改变α。可是,这种方式非常费力与复杂。如此,不同αi可同时计算不同值:
pi_new=(1-αi)y+αipi_old.(1)
加权平均(weightedaverage)用于下个单元机率预测:
pnew=σβipi_new.(2)
上面等式中,βi是权重因子(weightingfactor)。于avccabac中,查找表(即m_aucnextstatemps与m_aucnextstatelps)及索引网格(exponentialmesh)用于机率更新。可是,机率更新可使用平均网格(uniformmesh)与无乘法的具体计算(explicitcalculationwithmultiplicationfreeformula)。
假定机率pi由从0到2k的整数表示,机率由下面决定:
pi=pi/2k.
若’αi是二次方数的反数(即αi=1/2mi),那么我们就得到机率更新的无乘法方程式:
pi=(y>>mi)+p–(pi>>mi).(3)
上面等式中,“>>mi”表示右移mi位移操作。该等式预测机率为下个单元会是“1”,其中y=2k如果最后编码单元是“1”而y=0如果最后编码单元是“0”。
为了在复杂度增加与性能改善之间保持平衡,使用仅包含两个参数的机率估计的线性组合:
p0=(y>>4)+p0–(p0>>4)(4)
p1=(y>>7)+p1–(p0>>7)(5)
p=(p0+p1+1)>>1(6)
对于avccabac中的机率计算,浮点值总是小于或等于1/2。如果机率超过该限值,lps(最不可能符号,leastprobablesymbol)变成mps(最有可能符号,mostprobablesymbol)以此来保持上述间隔(interval)内的机率。这个概念具有一些明显优点,例如减小查找表尺寸。
可是,多参数更新模型的上述方法的直接产生(directgeneralization)可能会碰到一些困难。在实作中,一个机率估计能超过限值而另一个仍然小于1/2。因此,或者每个pi需要mps/lps切换或者一些平均值需要mps/lps切换。在两种情况下,其引入了额外复杂度但也并未取得显著性能提升。因此,本申请提出提高机率的允许水平(以浮点值计)到最高1且禁止mps/lps切换。因此,推导到储存rangeone或rangezero的查找表(lut)。
技术实现要素:
揭露一种使用运动补偿的视频编码的方法及装置。根据本发明的一方法,使用双向匹配,模板匹配或两者基于一或多个第一阶段运动向量候选来推导一第一阶段运动向量或一第一阶段运动向量对。通过使用双向匹配、模板匹配或两者推导每个子区块的一或多个第二阶段运动向量来推导该多个子区块的第二阶段运动向量,其中该第一阶段运动向量或该第一阶段运动向量对作为第二阶段双向匹配,模板匹配或两者的唯一初始运动向量或运动向量对使用或搜寻窗口的中心运动向量使用。自包含该第二阶段运动向量的一组运动向量候选或运动向量预测子候选决定最终运动向量或最终运动向量预测子。分别在编码器端或解码器端使用该最终运动向量或最终运动向量预测子来编码或译码该当前区块或当前区块的当前运动向量。多个子区块的第二阶段运动向量可用初始运动向量或运动向量对作为第二阶段双向匹配,模板匹配或两者的搜寻窗口的中心运动向量来搜寻。
于另一方法中,使用双向匹配或模板匹配基于一或多个运动向量候选来推导第一阶段运动向量或第一阶段运动向量对。可是,第二阶段运动向量推导仅对双向匹配赋能。如果使用该模板匹配推导的该第一阶段运动向量对与真双向预测区块相关,对该当前区块采用双向光流流程来推导该当前区块改善之运动向量。
于又一方法中,推导该使用双向匹配,模板匹配或两者的当前区块的解码器端合并候选。产生包含该解码器端合并候选的合并候选组。使用至少两个不同码字组其中之一或使用上下文基础编码的至少两个上下文其中之一,在该编码器端发信该当前区块的选择的当前合并索引,或在该解码器端解碼该当前区块的选择的该当前合并索引,其中该至少两个不同码字组或至少两个上下文基础编码的上下文用于编码与该合并候选组的合并候选相关的合并索引。根据包含该当前区块的图片的图片类型选择一码字组。该至少两个不同码字组属于一码组,该码组包含固定长度码,一元码及截断一元码。于一实施例中,对应一双向匹配或模板匹配合并模式的第一合并索引的第一上下文与对应一普通合并模式的第二合并索引的第二上下文不同。于另一实施例中,固定长度码用于属于低延迟b/p图片或属于所有参考帧具有小于当前图像的图像序列号的p/b图片的该当前区块。
于又一方法中,在与一解码器端运动向量推导流程相关的运动向量搜索中,使用基于降低位深度的区块差值计算,根据该解码器端运动向量推导流程推导一解码器端运动向量或解码器端运动向量对。自包含该解码器端运动向量或该解码器端运动向量对的一组运动向量候选或运动向量预测子候选,决定最终运动向量或最终运动向量预测子。分别在编码器端或解码器端使用该最终运动向量或该最终运动向量预测子,编码或译码该当前区块或该当前区块的当前运动向量。该降低位深度对应像素值的k个最高位,其中k是正整数。该区块差值计算对应平方差值之和或绝对差值之和。
于又一方法中,使用模板匹配推导当前模板的第一参考表(例如表0/表1)内最佳模板。基于该当前模板,第一参考表内该最佳模板或两者,决定新当前模板。使用新当前模板推导第二参考表(例如表0/表1)内最佳模板。该流程在该第一参考表及该第二参考表重复直到重复达到一数量。该新当前模板的推导可取决于包含该当前区块的图片的图片类型。
附图说明
图1显示使用双向匹配技术的运动补偿的例子,其中当前区块由沿着运动轨道的两个参考区块所预测。
图2显示使用模板匹配技术的运动补偿的例子,其中当前区块的模板与参考图像内的参考模板匹配。
图3a显示list_0参考图像的时域运动向量预测(temporalmotionvectorprediction,mvp)推导流程的例子。
图3b显示list_1参考图像的时域运动向量预测(temporalmotionvectorprediction,mvp)推导流程的例子。
图4显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中合并索引用不同码字发信。
图5显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中第一阶段mv或第一阶段mv对被作为第二阶段搜寻的唯一初始mv或mv对或搜寻窗口的中心mv。
图6显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中在找到第一参考表的参考模板之后,当前模板被修改以用于另一参考表内的模板搜寻。
图7显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中子pu搜寻在模板搜寻被禁用。
图8显示在当前区块与参考区块之间计算差值的当前区块与参考区块内像素的例子。
图9显示根据本发明一实施例的在当前区块与参考区块之间计算差值的当前区块与参考区块内像素的例子,其中具有虚拟像素值的子区块用于减少计算差值的操作。
图10显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中解码器端mv或解码器端mv对根据解码器端mv推导流程推导,其中解码器端mv推导流程在与解码器端mv推导流程相关的mv推导中使用基于降低的位深度的区块差值计算。
具体实施方式
后文的描述是实施本发明的最佳实施方法,所做的描述是为了说明书本发明的基本原理以及不应该对此作限制性理解。本发明的范围由参考所附权利要求最佳决定。
在本发明中,揭露了多个方法来为了解码器端运动向量推导降低带宽或复杂度或提升编码效率。
用不同码字发信合并索引(signallingmergeindexwithdifferentcodewords)
于双向匹配合并模式与模板匹配合并模式中,合并候选中的list_0与list_1mv用来作为开始mv。最佳mv是通过搜寻所有这些mv来毫无疑问地推导。这些合并模式会导致高存储器带宽。因此,本发明揭露一种方法来发信双向匹配合并模式或模板匹配合并模式的合并索引(mergeindex)。如果合并索引发信了,list_0与list_1中的最佳开始mv就知道了。双向匹配或模板匹配仅需要在发信的合并候选周围执行改善搜寻。对于双向匹配,如果合并匹配是单向(uni-directional)mv,其另一表中的对应mv可通过使用镜像(缩放)mv产生。
于另一实施例,通过使用预定mv产生方法,list_0,list_1中的开始mv以及/或mv对是已知的。list_0及/或list_1中的最佳开始mv,或最佳mv对被明确发信以降低带宽要求。
虽然双向匹配与模板匹配已经以两阶段方式常用,根据本发明的用不同码字发信合并索引的方法并不限定于两阶段方式。
于另一实施例中,当一个合并索引被发信,选择的mv还可用于在第一阶段排除或选择一些候选,即pu-级匹配时。例如,候选表中远离选择的mv的一些mv可被排除。另外,候选表中最接近选择的mv但是在不同参考帧内的n个mv可被选择。
在上述方法中,合并索引的码字可为固定长度(fixed-length,fl)码,一元码(unarycode),或截断一元(truncatedunary,tu)码。双向匹配与模板匹配合并模式的合并索引之上下文(context)可与普通合并模式不同。可使用一个不同的上下文模型组。码字可为依赖图片型(slice-typedependent)或于图片头(sliceheader)中发信。例如,tu码可在随机存取(random-access,ra)图片中使用或者当参考帧的图像序列号(pictureordercount,poc)并不都小于当前图像时用于b-图片。fl码可用于低延迟b/p图片或可用于p-图片或b-图片,其中参考帧的poc并不都小于当前图像。
图4显示根据该实施例的使用解码器端推导的信息的时讯编码系统的流程图,其中合并索引被用不同码字发信。下面流程图或任何后续流程图中所示的步骤,以及本揭露书中其他流程图,可实施为编码器端以及/或解码器端的一个或多个处理器(例如一或多个cpu)上可执行的程序代码。流程图中所示的步骤也可基于硬件实施,例如用于执行流程图的步骤的一或多个电子设备或处理器。根据本方法,在步骤410,在编码器端接收与当前图像中当前区块相关的输入数据,或者在解码器端接收包含当前图像中当前区块相关的编码数据的视频串流。在步骤420,推导使用双向匹配,模板匹配或两者的当前区块的解码器端合并候选。在步骤430,产生包含解码器端的合并候选的合并候选组。产生合并候选组的方法为业界所知。一般地,其包含空间(spatial)及/或时域邻进区块的运动信息作为合并候选。根据本实施例推导的解码器端的合并候选包含在合并候选组中。在步骤440,使用至少两个不同码字组中之一或使用上下文基础编码的至少两个上下文之一,在编码器端发信选择的当前区块的当前合并索引,或在解码器端解碼选择的当前区块的当前合并索引。所述至少两个不同码字组或上下文基础编码的所述至少两个上下文用于编码与合并候选组的合并候选相关的合并索引。
无mv成本,自合并候选的子区块改善(nomvcost,sub-blockrefinedfrommergecandidate)
于双向匹配合并模式与模板匹配合并模式,初始mv首先从邻近区块及模板同位区块推导。于样式基础(pattern-based)mv搜寻中,mv成本(即mv差值乘lambda,λ)与预测失真(predictiondistortion)相加。本发明该方法限定搜寻的mv在初始mv周围。mv成本通常用在编码器端来降低mvd(mv差值)的位消耗(bitoverhead),因为发信mvd会消耗编码位。可是,解码器端推导的运动向量是解码器端程序,其不需要额外端信息。因此,在一实施例中,可消除mv成本。
于双向匹配合并模式及模板匹配合并模式中,采用两阶段mv搜寻。第一搜寻阶段(cu/pu-级阶段)中最佳mv作为第二搜寻阶段之初始mv之一。第二阶段的搜寻窗口以第二搜寻阶段的初始mv为中心。可是,其需要存储器带宽。为了进一步降低带宽要求,本发明揭露一种方法使用第一第一搜寻阶段的初始mv作为第二阶段子区块搜寻的搜寻窗口的中心mv。如此,第一阶段的搜寻窗口可在第二阶段再用。就不需要额外带宽。
在vceg-az07中,对于模板及双向匹配中的子-pumv搜寻,当前pu的左面及上面mv用来作为初始搜寻候选。在一实施例中,为了降低存储器带宽,第二阶段子-pu搜寻,仅使用第一阶段的最佳mv作为第二阶段的初始mv。
在另一实施例中,与上述的发信合并索引的方法组合,在第一阶段与第二阶段搜寻中使用明确发信合并索引mv的搜寻窗口。
图5显示根据本发明一实施例的使用解码器端推导的运动信息的视频编码系统的流程图,其中使用该第一阶段mv或第一阶段mv对作为第二阶段搜寻的唯一初始mv或mv对或作为搜寻窗口的中心mv。根据本方法,在步骤510,接收与当前图像中当前区块相关的输入数据,其中每个当前区块被划分为多个子区块。在编码器端,输入数据可对应要被编码的像素数据且输入数据可对应要在解码器端被译码的编码数据。在步骤520,使用双向匹配,模板匹配或两者基于一或多个第一阶段mv候选推导第一阶段mv或第一阶段mv对。在步骤530,通过使用双向匹配,模板匹配或两者推导每个子区块的一或多个第二阶段mv来推导多个子区块的第二阶段mv,其中第一阶段mv或第一阶段mv对作为第二阶段双向匹配,模板匹配或两者的唯一初始mv或mv对或作为搜寻窗口的中心mv。在步骤540,自包含第二阶段mv的一组mv候选或mvp候选推导最终mv或最终mvp。在步骤550,分别在编码器端或解码器端使用最终mv或最终mvp编码或译码当前区块或当前区块的当前mv。
禁用pmvd的加权预测(disableweightedpredictionforpmvd)
于模板匹配合并模式及双向匹配合并模式中,根据本方法禁用加权预测。如果list_0与list_1两者都包含匹配的参考区块,权重为1:1。
匹配标准(matchingcriterion)
当找到最佳或几个最佳list_0/list_1模板,list_0/list_1中的模板可用于搜寻list_1/list_0中的模板(即list_0中的模板用于搜寻list_1中的模板,反之亦然)。例如,list_0的当前模板可被修改为“2*(当前模板)–list_0模板”,其中list_0模板对应最佳list_0模板。新的当前模板用于在list_1中搜寻最佳模板。标记“2*(当前模板)–list_0模板”意思是当前模板与参考表0(即list_0模板)中找到的最佳模板之间的像素级操作(pixel-wiseoperation)。虽然传统模板匹配想要各自达成当前模板与参考表0中参考模板之间的最佳匹配以及当前模板与参考表1中参考模板之间的最佳匹配。另一参考表的修改后当前模板可帮助一起达成最佳匹配。可使用重复搜寻。例如,在找到最佳list_1模板之后,当前模板可被修改为“2*(当前模板)–list_1模板”。修改的新当前模板用于再次在list_0中搜寻最佳模板。重复次数与第一目标参考表应在标准中定义。
提出的list_1的匹配标准可以是依赖图片型(slice-typedependent)。例如,当参考帧的图像序列号不都小于当前图像时,“2*(当前模板)–list_0模板”可用于随机(random-access,ra)图片或可用于b-图片,“当前模板”可用于其他类型图片;反之亦然。
图6显示根据本发明的使用解码器端推导的运动信息的视频编码系统的流程图,其中在找到第一参考表中的参考模板后,修改当前模板在其他参考表的模板搜寻中用。根据本方法,在步骤610,接收与当前图像中的当前区块或子区块相关的输入数据。在编码器端,输入数据可对应要被编码的像素数据,且输入数据可对应在解码器端要被译码的编码数据。在步骤620,使用模板匹配推导当前区块或子区块的当前模板的一或多个第一最佳模板,其由第一参考表中一或多个第一最佳mv所指向,其中该一或多个第一最佳mv根据模板匹配推导。在步骤630,在推导所述一或多个第一最佳模板后,基于当前模板,所述一或多个第一最佳模板或两者决定新当前模板。在步骤640,使用模板匹配推导当前区块或子区块的新当前模板的一或多个第二最佳模板,其由第二参考表中一或多个第二最佳mv所指向,其中该一或多个第二最佳mv根据模板匹配推导,且该第一参考表与该第二参考表属于包含表0与表1的一组,该第一参考表与该第二参考表不同。在步骤650,自一组mv候选或mvp候选决定一或多个最终mv或最终mvp,所述mv候选或mvp候选包含与一或多个第一最佳mv及一或多个第二最佳mv相关的一或多个最佳mv。在步骤660,分别在编码器端或解码器端使用最终mv或最终mvp编码或译码当前区块或子区块或当前区块或子区块之当前mv。
禁用模板匹配的子-pu-级搜寻(disablesub-pu-levelsearchfortemplatematching)
根据本发明的方法,禁用模板匹配合并模式的子-pu搜寻。子-pu搜寻仅用于双向匹配合并。对于模板匹配合并模式,因为整个pu/cu可具有同样mv,bio可用于模板匹配合并模式的编码区块。如前所述,bio用于真双向预测区块(trulybi-directionalpredictedblock)来改善运动向量。
图7显示根据本方法的使用解码器端推导的运动信息的视频编码系统的流程图,其中禁用模板搜寻的子-pu搜寻。根据本方法,在步骤710,接收与当前图像中的当前区块或子区块相关的输入数据。在编码器端,输入数据可对应要被编码的像素数据,且输入数据可对应在解码器端要被译码的编码数据。在步骤720,使用双向匹配或模板匹配基于一或多个mv候选推导第一阶段mv或第一阶段mv对。在步骤730,检查是否使用双向匹配或模板匹配。如果使用双向匹配,则执行步骤740与750。如果使用模板匹配,则执行步骤760。于步骤740,通过使用双向匹配基于第一阶段mv或第一阶段mv对推导每个子区块的一或多个第二阶段mv来产生多个子区块的第二阶段mv,其中当前区块被划分为该多个子区块。在步骤750,自一组包含第二阶段mv的mv候选或mvp候选决定最终mv或最终mvp。在步骤760,自一组包含第一阶段mv的mv候选或mvp候选决定最终mv或最终mvp。在步骤770,在决定最终mv或最终mvp之后,分别在编码器端或解码器端使用最终mv或最终mvp编码或译码当前区块或当前区块的当前mv。
减少区块匹配操作(reducetheoperationsofblockmatching)
对于解码器端mv推导,计算具有多个mv的模板的sad成本来寻找解码器端的最佳mv。为了减少sad计算的操作,揭露一种趋近(approximate)当前区块810与参考区块820之间sad的方法。于传统区块匹配的sad计算中,如图8所示,计算当前区块(8x8区块)与参考区块(8x8区块)对应像素对之间的平方差(squareddifferences)且进行加总如等式(1)以取得平方差值的最终和,其中ci,j与ri,j分别表示当前区块810与参考区块820内的像素,其中宽度等于n且高度等于m。
为了加速,当前区块与参考区块被划分为尺寸为kxl的子区块,其中k与l可以是任何整数。如图9所示,当前区块910与参考区块920都是8x8区块且被划分为2x2子区块。每个子区块然后被作为虚拟像素(virtualpixel)对待并使用虚拟像素值来表示每个子区块。虚拟像素值可以是子区块内的像素和,子区块内的像素平均,子区块内的主导像素值(dominatepixelvalues),子区块内一个像素,一个预设像素值,或使用子区块内像素计算一个值的其他任何方式。sad可以当前区块与参考区块的虚拟像素之间的绝对差值和来计算。另外,平方差值和(sumofthesquareddifference,ssd)可以当前区块与参考区块的虚拟像素之间的平方差值和来计算。因此,每像素(per-pixel)的sad或ssd由虚拟像素的sad或ssd来趋近,这需要更少操作(例如更少乘法)。
而且,为了保持类似搜寻结果,本方法也揭露了使用虚拟像素的sad或ssd找到m最佳匹配之后的改善搜寻阶段(refinementsearchstage),其中m可以是任何正整数。为了m最佳候选的每个,可计算每像素sad或ssd来寻找最终最佳匹配区块。
为了降低sad与ssd计算的复杂度,本发明的方法计算第一k-位msb(或截断l-位lsb)数据。例如,对于10-位视频输入,其可使用msb的8-位来计算当前区块与参考区块的失真。
图10显示根据本方法的使用解码器端推导的运动信息的视频编码系统的流程图。根据本方法,在步骤1010,接收与当前图像中的当前区块或子区块相关的输入数据。在编码器端,输入数据可对应要被编码的像素数据,且输入数据可对应在解码器端要被译码的编码数据。在步骤1020,在与解码器端mv推导流程相关的mv搜寻中根据解码器端mv推导流程使用基于降低的位深度的区块差值计算推导解码器端mv或解码器端mv对。在步骤1030,自一组包含解码器端mv或解码器端mv对的mv候选或mvp候选决定最终mv或最终mvp。在步骤1040,分别在编码器端或解码器端使用最终mv或最终mvp编码或译码当前区块或当前区块的当前mv。
多参数cabac的范围推导(rangederivationformulti-parametercabac)
在多参数cabac中,本发明的方法使用lps表来推导每个机率状态(probabilitystates)的rangeone或rangezero。平均rangeone或rangezero可通过对rangeones或rangezeros平均推导。编码的rangeone(rangeoneforcoding,rofc)及编码的rangezero(rangezeroforcoding,rzfc)可用等式(8)推导:
rangezero_0=(mps_0==1)?rlps_0:(range–rlps_0);
rangezero_1=(mps_1==1)?rlps_1:(range–rlps_1);
rofc=(2*range–rangezero_0–rangezero_1)>>1;或
rofc=(2*range–rangezero_0–rangezero_1)>>1;(8)
在cabac中,本发明的方法在一些语法(syntax)上使用“独立(stand-alone)”上下文模型。独立上下文的机率或机率状态可与其他上下文不同。例如,“独立”上下文模型的机率或机率转换可使用不同数学模型。在一实施例中,具有固定机率的上下文模型可用于独立上下文。在另一实施例中,具有固定机率范围的上下文模型可用于独立上下文。
上述的流程图是要展示根据本发明的视频编码的例子。本领域的技术人员可修改每个步骤,重新安排这些步骤,切分一步骤,或合并步骤来实现本发明而不偏离本发明之精神。在揭露书中,特定语法及语义(semantics)用于展现例子来实施本发明之实施例。技术人员可通过用等同语法及语义替换语法及语义来实做本发明而不偏离本发明之精神。
上面展示的说明用于赋能本领域的一般技术人员来如提供的具体应用及其要求的上下文实现本发明。所述的实施例的各种变化对本领域技术人员是明显的,其中定义的总体原理可运用至其他实施例。因此,本发明并不是要被限定于所示及描述的特定实施例,而是要与这里揭露的原理及新特征的最广范围保持一致。于上面具体说明中,描写的各种具体细节是用于提供本发明的透彻理解。不仅如此,本领域的技术人员应理解本发明是可实做的。
本发明描述之实施例可用各种硬件,软件码,或两者组合实施。例如,本发明一实施例可为集成于视频压缩芯片之一或多个电路或是集成于执行上述流程之视频压缩软件中的软件码。本发明之一实施例也可为要于数字信号处理器(dsp)上运行来执行上述流程的软件代码。本发明也可涉及由计算器处理器,数字信号处理器,微处理器,现场可编程门阵列(fieldprogrammablegatearray,fpga)等执行的多个功能。这些处理器可用于根据本发明执行特定任务,通过运行定义本发明所实现的特定方法的机器可读软件码或固件码。软件码或固件码可用不同编程语言及不同格式或风格开发。软件码也可针对不同目标平台汇编。可是,不同码格式,风格及软件码语言以及其他配置码来根据本发明执行任务的方式并不偏离本发明之精神及范围。
本发明可在不偏离其精神或必要特性下以其他形式实施。上面描述的实施例需要全面考虑且仅为展示本发明而非限制本发明。在权利要求等同的意思及范围内的所有变化都在权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!