听力假体中的电声适配的制作方法
本发明总体上涉及听力假体。
背景技术:
听力损失可以归因于许多不同的原因,听力损失通常有两种类型:传导性和/或感觉神经性。当外耳和/或中耳的正常机械通路被阻碍(例如由于对听骨链或耳道的损伤)时,发生传导性听力损失。当存在对内耳的损伤、或者对从内耳到脑的神经通路的损伤时,发生感觉神经性听力损失。
患有传导性听力损失的人通常具有一些形式的残余听力,因为耳蜗中的毛细胞未被损伤。因此,患有传导性听力损失的人通常接受产生耳蜗流体运动的听觉假体。例如,这种听觉假体包括声学助听器、骨传导设备和直接声刺激器。
然而,在许多极度耳聋的人中,他们的耳聋原因是感觉神经性听力损失。患有一些形式的感觉神经性听力损失的那些人不能从产生耳蜗流体机械运动的听觉假体获得合适的益处。这类人可以受益于可植入的听觉假体,该听觉假体以其他方式(例如,电学的、光学的等)刺激接受者的听觉系统的神经细胞。当感觉神经性听力损失是由于将声学信号转换成神经冲动的耳蜗毛细胞的缺失或破坏时,通常提议人工耳蜗。听觉脑干刺激器是另一种类型的刺激性听觉假体,当接受者由于听力神经损伤而经历感觉神经性听力损失时,也可以提议听觉脑干刺激器。
某些人仅患有部分感觉神经性听力损失,并且因此保留了至少一些残余听力。这些人可以是电声听力假体的候选者。
技术实现要素:
在一方面,提供了一种方法。该方法包括:确定在由接受者佩戴的听力假体处接收的声音信号的一个或多个属性;基于所接收的声音信号,生成声刺激信号和电刺激信号;以及基于声音信号的一个或多个属性,设定声刺激信号和电刺激信号的比。
在另一方面,提供了一种听力假体。该听力假体包括:一个或多个声音输入元件,被配置为接收声音信号;电声音处理路径,被配置为将声音信号的至少第一部分转换成一个或多个输出信号,以用于将电刺激传递给接受者;声学声音处理路径,被配置为将声音信号的至少第二部分转换成一个或多个输出信号,以用于将声刺激传递给接受者;以及电声适配模块,被配置为基于声音信号的一个或多个属性来改变电刺激和声刺激中的至少一个的相对感知响度。
在另一方面,提供了一种听力假体。听力假体包括:一个或多个声音输入元件,被配置为接收声音信号;以及一个或多个处理器,被配置为生成表示声刺激信号和电刺激信号的输出信号,以用于传递给听力假体的接受者,其中声刺激信号对电刺激信号的相对电平和相对响度中的至少一个基于声音信号的一个或多个特性而被设定。
附图说明
本文结合附图描述本发明的实施例,其中:
图1a是图示根据本文提供的实施例的电声听力假体的示意图;
图1b是图1a的电声听力假体的框图;
图2是图示根据本文提供的实施例的声音处理单元的框图;
图3是由图2的声音处理单元执行的示例方法的流程图;
图4是根据本文提供的实施例的声音处理单元的框图;以及
图5是根据本文提供的实施例的方法的流程图。
具体实施方式
听觉/听力假体接受者患有不同类型的听力损失(例如,传导性和/或感觉神经性)和/或不同程度/严重性的听力损失。然而,现在常见的是,许多听力假体接受者在接受听力假体后保留一些残余的自然听力能力(残余听力)。例如,在耳蜗内电极阵列(刺激组件)、手术植入技术、工具等设计中的逐步改进已经实现了无创伤手术,无创伤手术至少保留了接收者的一些精细内耳结构(例如,耳蜗毛细胞)和自然耳蜗功能,特别是在耳蜗的较高频率区域的自然耳蜗功能。
至少部分地归因于保留残余听力的能力,接受者的数目持续扩大,这些接受者是不同类型的可植入听力假体(特别是电声听力假体)的候选者。电声听力假体是可以同时将声刺激(即,声刺激信号)和电刺激(即,电刺激信号)两者传递给接受者的同一耳朵的医学设备。通常地,受限于植入耳中的残余听力,声刺激被用来呈现对应于输入声音信号的较低频率的声音信号分量(从植入耳的残余听力能力确定),而电刺激被用来呈现对应于较高频率的声音信号分量。声音或刺激输出从声刺激转变为电刺激的耳蜗的音质区域被称为交叉频率区域。
除电刺激之外,电声听力假体的接受者通常还受益于具有声刺激,这是因为,比起仅在该耳朵中的电刺激信号,声刺激为其听力感知添加了更“自然的”声音。在一些情况下,声刺激的添加还可以提供改善的音高和音乐感知和/或欣赏,这是因为,比起电刺激可能的表示,声学信号可以包含更显著的较低频率(例如,基础音高,f0)表示。电声听力假体的其他益处可以包括例如改善的声音定位、未遮蔽而露出双耳、在嘈杂环境中区分声学信号的能力等
在电声听力假体中,声刺激信号和电刺激信号各自在预先确定的/预设的电平(例如,幅度)处和/或预先确定的/预设的所估计的感知响度(响度)处被生成并且被传递至接受者。在本文中,声刺激信号对电刺激信号(反之亦然)的相对电平和/或相对响度被统一地并且一般地被称为声刺激信号和电刺激信号的“比”。本文所呈现的是自动设定声刺激信号对电刺激信号的相对电平或相对响度中的一个或多个的技术(即,动态设定声刺激信号和电刺激信号的比)。如下文进一步描述的,基于声音信号的一个或多个特性或属性,实时地设定声刺激信号对电刺激信号的相对电平或相对强度,该声音信号由电声听力假体接收并且处理,以生成声刺激信号和电刺激信号。
为了方便说明,本文描述的实施例主要参考听力假体的一种特定类型,即包括人工耳蜗部分和助听部分的电声听力假体。然而,应该理解,本文呈现的技术可以和其他类型的听力假体一起被使用,诸如双模听力假体、包括其他类型的输出设备的电声听力假体(例如,听觉脑干刺激器、直接声刺激器、骨传导设备等)。
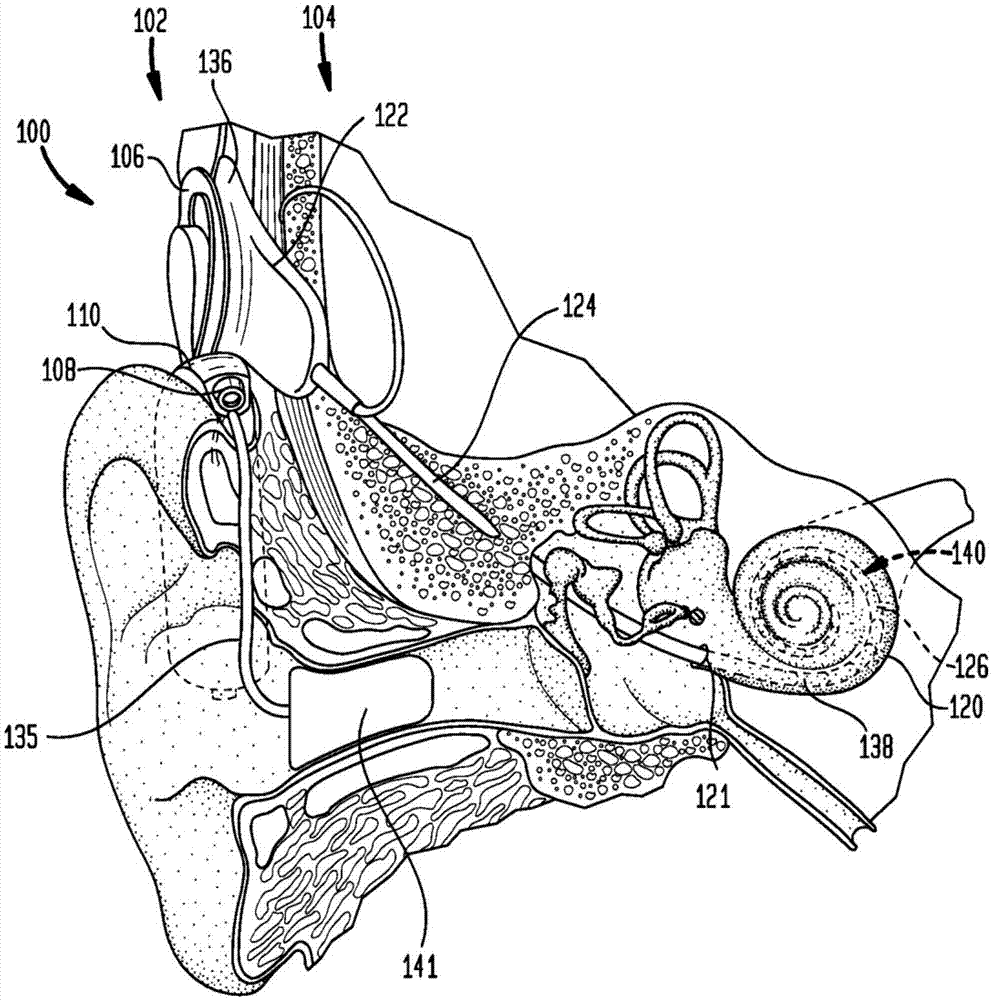
图1a是被配置为实现本发明的实施例的示例性电声听力假体100的示意图,而图1b是电声听力假体的框图。电声听力假体100包括外部部件102和内部/可植入部件104。
外部部件102直接地或间接地被附接到接受者的身体,并且包括声音处理单元110、外部线圈106以及一般地包括相对于外部线圈106被固定的磁体(未在图1a中示出)。外部线圈106经由线缆134被连接到声音处理单元110。声音处理单元110包括一个或多个声音输入元件108(例如,麦克风、音频输入端口、线缆端口、电线圈、无线收发器等)、声音处理器112、外部收发器单元(收发器)114、功率源116、电声适配模块118和声音分析模块148。例如,声音处理单元110可以是耳后(bte)声音处理单元、体佩式声音处理单元、按钮声音处理单元等。
被连接到声音处理单元110的是助听部件141,其经由线缆135被连接到声音处理单元110。助听部件141包括接收器142(图1b),其可以例如被定位在接受者的外耳中或附近。接收器142是声学换能器,其被配置为经由接受者的耳道和中耳将声学信号(声刺激信号)传递给接受者。
图1a和图1b图示使用接收器142将声刺激传递给接受者。然而,应该理解,其他类型的设备可以被用在其他实施例中,以传递声刺激。例如,其他实施例可以包括被配置为向接受者传递声刺激的外部振动器或植入振动器。
如图1b所示,可植入部件104包括植入体(主模块)122、引导区域124和伸长的内耳蜗刺激组件126。植入体122通常包括气密外壳128,内部收发器单元(收发器)130和刺激器单元132被放置该外壳中。植入体122还包括内部/可植入线圈136,其通常在外壳128的外部,但是经由气密馈通(未在图1b中示出)被连接到收发器130。可植入线圈136通常是由多匝电绝缘单股铂或多股铂或金线组成的线天线线圈。可植入线圈136的电绝缘通过柔韧模制(例如,硅胶模制)提供,其未在图1b中示出。通常地,磁体相对于可植入线圈136被固定。
伸长的刺激组件126被配置为至少部分地被植入于接受者的耳蜗120(图1b)中,并且包括多个纵向间隔的耳蜗内电刺激触体(电极)138,它们共同形成触体阵列140,以用于将电刺激(电流)传递到接受者的耳蜗。在某些布置中,除了电极138之外,触体阵列140还可以包括其他类型的刺激触体,诸如光刺激触体。
刺激组件126延伸穿过耳蜗中的开口121(例如,耳蜗造口、圆窗等),并且具有经由引导区域124和气密馈通(未在图1b中示出)被连接到刺激器单元132的近侧端。引导区域124包括将电极138电耦合到刺激器单元132的多个导体(线)。
回到外部部件102,(多个)声音输入元件108被配置为检测/接收输入声音信号并且由此生成电输出信号。声音处理器112被配置为执行声音处理和编码,以将从声音输入元件接收的输出信号转换成编码数据信号,编码数据信号表示用于传递给接受者的声刺激和/或电刺激。即,如所述,电声听力假体100用于唤起声音信号的接受者的感知,该声音信号通过将电刺激信号和声刺激信号中的一个或两个传递给接受者、由声音输入元件108接收。因此,取决于各种因素,声音处理器112被配置为将从声音输入元件接收的输出信号转换成表示电刺激的输出信号的第一集合和/或表示声刺激的输出信号的第二集合。表示电刺激的输出信号在图1b中由箭头115表示,而表示声刺激的输出信号在图1b中由箭头117表示。
输出信号115被提供给收发器114。收发器114被配置为使用输出信号115经由外部线圈106经皮地传送编码信号给可植入部件104。更具体地,相对于外部线圈106而被固定的磁体和可植入线圈136有助于外部线圈106和可植入线圈136的操作性对齐。线圈的该操作性对齐使外部线圈106能将编码数据信号以及从功率源116接收的功率信号发射到可植入线圈136。在某些示例中,外部线圈106经由无线电频率(rf)链路将信号发射到可植入线圈136。然而,各种其他类型的能量传送,诸如红外的(ir)、电磁的、电容的和感应的传送可以被用来将来自外部部件的能量和/或数据传送到电声听力假体,并且因此,图1b仅图示一个示例布置。
一般来说,编码数据和功率信号在收发器130处被接收并且被提供给刺激器单元132。刺激器单元132被配置为利用编码数据信号来生成电刺激信号(例如,电流信号),以用于经由一个或多个刺激触体138传递给接受者的耳蜗。以这种方式,电声听力假体100以使接受者感知所接收的声音信号中的一个或多个分量的方式,电刺激接受者的听觉神经细胞,绕过通常将声振动转换成神经活动的缺失或有缺陷的毛细胞。
如上所述,常见的是,听力假体接受者保留了至少一部分的这种正常听力功能(即,保留至少一些残余听力)。因此,在将声音信号传递给接受者的外耳时,听力假体接受者的耳蜗可以被声刺激。在图1a和图1b的示例中,接收器142被用以辅助接受者的残余听力。更具体地,输出信号117(即表示声刺激的信号)被提供至接收器142。接收器142被配置为利用输出信号117来生成被提供给接受者的声刺激信号。换言之,接收器142被用来增强和/或放大声音信号,该声音信号经由中耳骨和卵圆窗被传递到耳蜗,从而在耳蜗内创建外淋巴的流体运动波。
在常规的电声听力假体中,声刺激信号和电刺激信号各自以预先确定的电平和/或响度被生成并且被传递给接受者。根据本发明的实施例,图1a和图1b的电声听力假体100包括电声适配模块118,其被配置为基于输入声音信号(即,由声音输入108接收并且被用来生成声刺激信号和电刺激信号的声音)的一个或多个属性,动态地设定声刺激信号对电刺激信号的比。换言之,电声适配模块118被配置为实时地自动调整控制声刺激信号和/或电刺激信号的电平(例如,幅度)的一个或多个操作,或实时地自动调整控制声刺激信号和/或电刺激信号的感知响度的一个或多个处理操作。因此,在本文中,电声适配模块118被认为是被配置为调整或适配声刺激信号对电刺激信号相对电平和/或相对响度。声音信号的一个或多个属性由声音分析模块148来确定,该声音信号是用于设定声刺激信号对电刺激信号的比的基础。下文提供了声音分析模块148和电声适配模块118的其他细节。
图1a和图1b图示其中人工耳蜗100包括外部部件102的一种布置。然而,应该理解,本发明的实施例可以在具有备选布置的人工耳蜗中被实现。
图2是图示用于根据本文呈现的实施例的声音处理单元110的示例布置的示意性框图。为了方便说明,图2仅示出与本文呈现的电声适配技术有关的声音处理单元110的元件,即声音输入元件108、声音处理器112、电声适配模块118和声音分析模块148。
如所述,电声听力假体100包括一个或多个声音输入元件108。在本示例中,声音输入元件108包括两个麦克风109和至少一个辅助输入111(例如,音频输入端口、线缆端口、电线圈、无线收发器等)。如果所接收的声信号还未处于电形式,则声音输入元件108将所接收的声信号转换成电信号143,在本文中,电信号143被称为表示所接收的声音信号的电输出信号。如图2所示,电输出信号143被提供给预滤波器组处理模块144。
在需要时,预滤波器组处理模块144被配置为组合从声音输入元件108接收的电输出信号143,并且准备这些信号以用于后续的处理。然后,预滤波器组处理模块144生成经预滤波的输出信号145,如下文进一步描述的,该经预滤波的输出信号145是进一步处理操作的基础。经预滤波的输出信号145表示在给定的时间点处在声音输入元件108处所接收的共同的声音信号。
如所述,电声听力假体100被配置为将声刺激(即,声刺激信号)和电刺激(即,电刺激信号)两者都传递给接受者。在本文中,与电刺激组合的声刺激有时被称为电声刺激。因此,声音处理器112通常被配置为执行声音处理和编码,以将经预滤波的输出信号145转换成表示声刺激或电刺激的输出信号,以用于传递给接受者。这在图2中被示出,其中声音处理器112包括两个并行的声音处理路径146(a)和146(b)。第一声音处理路径146(a)是电声音处理路径,在本文中有时被称为人工耳蜗声音处理路径,其被配置为从经预滤波的输出信号145的至少第一部分/段生成输出信号,以用于电刺激接受者。第二声音处理路径146(b)是声学声音处理路径,在本文中,有时被称为助听声音处理路径,其被配置为从经预滤波的输出信号145的至少第二部分生成输出信号,以用于声刺激接受者。
声音处理路径146(a)(即,电声音处理路径)包括增益模块150、滤波器组152、后滤波器组处理模块154、信道选择模块156和信道映射模块158。声音处理路径146(b)(即,声学声音处理路径)包括增益模块160、滤波器组162、后滤波器组处理模块164和再合成模块168。
首先参考声音处理路径146(a),由预滤波器组处理模块144生成的经预滤波的输出信号145被提供给增益模块150,增益模块150对其应用增益调整(例如,宽带增益调整)。增益模块150将经增益调整的信号151提供给滤波器组152。
滤波器组152使用经增益调整的信号151来生成带宽有限的信道或频率区间(frequencybin)的适当集合,每个带宽有限的信道或频率区间包括所接收的声音信号中的将被用于路径146(a)中的后续声音处理的频谱分量。也就是说,滤波器组152是将经增益调整的信号151分离成多个分量的多个带通滤波器,每一个分量载有原始信号的单个频率子带(即,被包括在经预滤波的输出信号145和经增益调整的信号151中的所接收的声音信号的频率分量)。
在本文中,由滤波器组152创建的信道有时被称为声音处理信道,并且在每个声音处理信道内的声音信号分量在本文中有时被称为经带通滤波的信号或信道化的信号。如下文进一步描述的,当由滤波器组152创建的经带通滤波的信号或信道化的信号穿过电声音处理路径146(a)时,其可以被调整/修改。因此,经带通滤波的信号或信道化的信号在电声音处理路径146(a)的不同阶段处被不同地指代。然而,应该理解,在本文中,对经带通滤波的信号或信道化的信号的指代可以指在电声音处理路径146(a)内任何点处(例如,经预处理的、经处理的、经选择的等)所接收的声音信号的频谱分量。
在滤波器组152的输出处,在本文中,信道化的信号最初被称为经预处理的信号153。由滤波器组152生成的信道和经预处理的信号153的数目“m”可以取决于多个不同因素,包括但不限于植入设计、有源电极的数目、编码策略和/或接受者的(多个)喜好。在某些布置中,二十二(22)个信道化的信号被创建并且电声音处理路径146(a)被称为包括22个信道。
经预处理的信号153被提供给后滤波器组处理模块154。后滤波器组处理模块156被配置为在经预处理的信号154上执行多个声音处理操作。例如,这些声音处理操作包括在一个或多个信道中进行信道化的增益调整以用于听力损失补偿(例如,对声音信号的一个或多个离散频率范围的增益调整)、降噪操作、语音增强操作。在执行声音处理操作之后,后滤波器组处理模块154输出多个经处理的信道化的信号155。
如所述,在图2的特定布置中,电声音处理路径146(a)包括信道选择模块156。信道选择模块156被配置为执行信道选择过程,以根据一个或多个选择规则来选择“m”个信道中的哪一个信道应该被用在听力补偿中。在信道选择模块156处所选择的信号在图2中由箭头157来表示,并且所选择的信号在本文中被称为所选择的信道化的信号,或更简单地被称为所选择的信号。
在图2的实施例中,信道选择模块156选择“m”个经处理的信道化的信号155中的子集“n”,用于生成电刺激,以传递给接受者(即,声音处理信道从“m”个信道被减少到“n”个信道)。在一个特定的示例中,从“m”个可用的组合的信道信号/掩蔽信号做出“n”个最大幅度的信道(最大值),其中“m”和“n”在假体的最初试戴和/或操作期间是可编程的。应该理解的是,可以使用不同的信道选择方法,并且不限于最大值选择。
还应该理解的是,在某些实施例中,可以省略信道选择模块156。例如,某些布置可以使用连续交错采样(cis)、基于cis的或其他非信道选择的声音编码策略。
电声音处理路径146(a)还包括信道映射模块158。信道映射模块158被配置为将所选择的信号157(或在不包括信道选择的实施例中的经处理的信道化信号155)的幅度映射到表示电刺激信号的属性的输出信号的集合(例如,刺激命令)中,电刺激信号将被传递给接受者以便唤起感知所接收的声音信号的至少一部分。该信道映射可以包括例如阈值和舒适电平映射、动态范围调整(例如,压缩)、音量调整等,并且可以包括顺序和/或同时的刺激范式。
在图2的实施例中,表示电刺激信号的刺激命令的集合被编码,以用于经皮传送(例如,经由rf链路)到可植入部件104(图1a和图1b)。在图2的特定示例中,该编码在信道映射模块158处被执行。因此,在本文中,信道映射模块158有时被称为信道映射和编码模块,并且作为输出块起作用,该输出块被配置为将多个信道化的信号转换成多个输出信号159。
接下来参考声学声音处理路径146(b),由预滤波器组处理模块144生成的经预滤波的输出信号145也被提供给增益模块160,增益模块160对其应用增益调整(例如,宽带增益调整)。增益模块160将经增益调整的信号161提供给滤波器组162。与滤波器组152相似,滤波器组162使用经增益调整的信号161来生成带宽有限的(信道化的)信号的适当集合,在本文中,带宽有限的(信道化的)信号有时被称为经带通滤波的信号,其表示所接收的声音信号中的将被用于后续的助听声音处理的频谱分量。也就是说,滤波器组162是将经预滤波的输出信号145分离成多个分量的多个带通滤波器,每一个分量载有原始信号的频率子带。信道化的信号在本文中是被认为被分离成或形成不同的声音处理信道。由滤波器组162生成的信道和信道化的信号的数目“y”可以取决于多个不同因素,包括但不限于处理策略、增益模型、剩余听力(或损失)、接受者的(多个)偏好等。在某些示例中,由滤波器组162生成的信道与由滤波器组152创建的信道大体上相似,而在其他示例中,由滤波器组162创建的信道的数目、信道的频率范围等与由滤波器组152创建的信道不同。
在滤波器组162的输出处,信道化的信号被称为经预处理的信号163。经预处理的信号163被提供给后滤波器组处理模块164。后滤波器组处理模块164被配置为在经预处理的信号163上执行多个声音处理操作。例如,这些声音处理操作包括在一个或多个信道中进行增益调整,以用于听力损失补偿、降噪操作、语音增强操作等。在执行声音处理操作之后,后滤波器组处理模块164输出多个经处理的信道化的信号165。
如所述,声学声音处理路径146(b)在再合成模块166处终止。再合成模块166从经处理的信道化的信号165生成一个或多个输出信号169。输出信号169被用来驱动诸如接收器142的电声换能器,使得换能器生成声信号以用于传递给接受者。换言之,声学声音处理路径146(b)生成电声换能器驱动信号形式的一个或多个输出信号169。虽然未在图2中示出,但是在再合成模块166的再合成操作之后并且在信号被发送到接收器142之前,可以执行一个或多个操作。例如,限制器或压缩器、最大功率输出(mpo)级等可以被添加在再合成模块166和接收器142之间。
如所述,由电声听力假体生成的声刺激信号和电刺激信号各自具有所选择的电平和/或所选择的响度。同样如上所述,电声适配模块118被配置为基于由声音分析模块148所确定的一个或多个声音信号属性来自动设定声刺激信号对电刺激信号的一个或多个相对电平或相对响度(即,设定声刺激信号和电刺激信号的比)。
更具体地,由声音输入元件所接收的输入声音信号被提供给声音分析模块148。例如,如图2的实施例所示,预滤波器组处理模块144被配置为将经预滤波的输出信号145提供给声音分析模块148。虽然图2图示声音分析模块148接收作为经预滤波的输出信号145的一部分的声音信号,但是在其他实施例中,声音分析模块148可以直接从声音输入元件(即,声音分析模块148可以接收电输出信号143)接收声音信号。
声音分析模块148被配置为评估/分析所接收的声音信号,以确定声音信号的一个或多个特性/属性。例如,声音分析模块148可以被配置为确定声音信号的输入电平。备选地,声音分析模块148可以被配置为执行声音活动检测(vad),也称为语音活动检测或语音检测,以检测声音信号中的人类语音的存在(或不存在)。在其他的实施例中,声音分析模块148被配置为执行环境分类操作。也就是说,声音分析模块148被配置为使用声音信号将周围的声音环境和/或声音信号“分类”成一个或多个声音类别(例如,确定输入信号类型)。换言之,声音分析模块148可以被配置为确定所接收的声音信号的“类型”。类别可以包括但不限于“语音”、“噪声”、“语音+噪声”或“音乐”。
声音分析模块148被配置为将关于从所接收的声音信号确定的声音信号属性的信息提供给电声适配模块118。电声适配模块118被配置为使用声音信号属性来实时地动态设定从所接收的声音信号生成并且表示所接收的声音信号的声刺激信号对电刺激信号(反之亦然)的比(例如,相对电平和/或相对响度)。
更具体地,如上所述,由电声音处理路径146(a)生成的输出信号159是可用的,以生成用于传递给接受者的电刺激信号。相似地,由声学声音处理路径146(b)生成的输出信号159是可用的,以生成用于传递给接受者的声刺激信号。因此,电声适配模块118通过适配电声音处理路径146(a)或声学声音处理路径146(b)中的一者或两者的操作来动态设定(即,调整)声刺激信号对电刺激信号的比。换言之,通过基于声音信号属性来适配电声音处理路径146(a)或声学声音处理路径146(b)中的一者或两者的操作,电声适配模块118相对于彼此地调整输出信号159和输出信号169,并且相应地相对于彼此地调整所得到的电刺激和声刺激。
根据本文呈现的实施例,电声适配模块118可以被配置为以多种不同的方式来适配电声音处理路径146(a)或声学声音处理路径146(b)中的一者或两者的操作。例如,在一个布置中,电声适配模块118被配置为基于声音信号属性来动态适配或修改被应用在增益模块150或增益模块160中的一者或两者处的增益调整。增加两个增益之间的差异将改变被呈现给接受者的电刺激电平对声刺激电平的比例。
虽然图2图示了在分别先于滤波器组152和滤波器组162的增益模块150和增益模块160处的增益调整适配,应该理解,可以备选地在滤波器组152和滤波器组162之内或之后应用增益调整和实时比例调整。例如,电声适配模块118可以同样地或备选地适配在后滤波器组处理模块154和/或后滤波器组处理模块164处被应用的增益调整(例如,修改在后滤波器组处理模块处被应用的信道增益)。信道增益的修改可以使声刺激信号或电刺激信号的某些频率分量的电平或响度提高。
电声音处理路径146(a)和/或声学声音处理路径146(b)中的增益调整的修改是可以被电声适配模块118采用以适配声刺激信号和电刺激信号的比的一种机制。调整声刺激和电刺激之间的比的其他方法可以包括例如调整滤波器组操作、调整在每个路径中被应用的降噪的量或类型(例如,在后滤波器组处理模块154和/或后滤波器组处理模块164处)、修改在后滤波器组处理模块154和/或后滤波器组处理模块164处被应用的其他操作、修改在信道选择模块156处被利用的信道规则、修改在映射和编码模块158处被应用的信道映射和/或修改在再合成模块166处的再合成操作。
如所述,电声适配模块118可以通过在电声音处理路径146(a)和/或声学声音处理路径146(b)中以不同的方式并且在不同的位置处调整处理操作,以设定声刺激信号对电刺激信号的比(例如,相对电平和/或响度)。因此,电声适配模块118被示为通过箭头170与电声音处理路径146(a)和声学声音处理路径146(b)中的每一个的各种元件相连。还应该注意,电声适配模块118可以执行调整:(1)增加或减小仅声刺激信号的电平或响度,(2)增加或减小仅电刺激信号的电平或响度,或(3)增加或减小声刺激信号和电刺激信号两者的电平或响度。换言之,相对于电刺激信号的电平设定声刺激信号的电平或响度中的至少一个包括:调整声刺激信号的电平或响度、调整电刺激信号的电平或响度、或调整声刺激信号和电刺激信号的电平或响度。
在某些示例中,当设定声刺激信号对电刺激信号的比时,电声适配模块118被配置为调整声刺激信号和电刺激信号之间的“平衡”。如本文中所使用的,调整声刺激信号和电刺激信号之间的平衡是指对声刺激信号和电刺激信号两者作对应的调整(即,增加一种类型的刺激信号的响度和/或电平,而相应减小另一种类型的刺激信号的响度和/或电平)。
如所述,电声适配模块118通过修改电声音处理路径146(a)或声学声音处理路径146(b)中的一者或两者的操作而起作用,以用于处理输入声音信号,其中输入声音信号是经修改的操作的触发事件。应该注意,经修改的操作可以被用来处理触发修改的声音信号和共享相同的一个或多个触发声音信号属性的后续声音信号。然而,当一个或多个触发声音信号属性不再被检测或改变时,处理可以例如回到预先确定的或预设的操作,和/或利用不同的操作性调整。
图2图示了包括一个信号分析模块148的具体布置。应该理解,备选实施例可以利用多个信号分析模块。例如,不同的声音信号分析模块可以与不同的声音输入、不同的处理路径等相关联。在这种实施例中,电声适配模块118被配置为利用来自多个信号分析模块中的每一个信号分析模块的信息,以设定声刺激信号和电刺激信号的比。
图3是图示可以由图1a、图1b和图2的声音处理单元110执行的一个特定方法175的流程图。方法175在176处开始,在176中,由声音输入元件108接收的输入声音信号被提供给声音分析模块148。在178处,声音分析模块148确定输入声音信号是音乐信号(例如,自动检测具有强音调和谐波的信号,以便将输入信号类型分类为“音乐”)。
在180处,声音分析模块148将输入声音信号是音乐信号的指示提供给电声适配模块118。由于存在强音高和谐波结构,音乐信号通过经由接受者的残余听力所呈现的声刺激而被更好地表示。因此,在182处,电声适配模块118增加或提高被应用在声学声音处理路径146(b)中的增益,以增强接受者对存在于输入声音信号中的音调和谐波的感知。也就是说,因为声刺激传送了更自然的声音和更好的音高指示,音乐欣赏可以通过相对于电刺激来提高声刺激而被改善。
在操作中,只要声音分析模块148持续将所接收的声音信号分类为音乐信号,被应用在声学声音处理路径146(b)增益中的增益增加就可以持续。然而,在声音分析模块148停止将输入声音信号分类为音乐信号时(即,当输入信号类型不再是音乐时),增益增加被去除。
虽然图3图示了在音乐存在的情况下所应用的增益的提高,应该理解,当音乐被标识在声音信号中时,在声学声音处理路径146(b)和/或电声音处理路径146(a)中的一者或两者内的其他参数和/或操作可以备选地或附加地被适配。还应该理解,其他的声学场景可以引起根据本文呈现的实施例的声刺激信号对电刺激信号的比的变化。例如,在具有移动噪声源的场景中,更高比例的电刺激信号(其通常包含更多的高频信息)可以帮助接受者进行声音定位。因此,在这种实施例中,可以对声学声音处理路径146(b)和/或电声音处理路径146(a)中的一者或两者作出调整,以相对于声刺激信号增加电刺激信号的电平或响度中的一个或多个。
如所述,在其他实施例中,基于所接收的声音信号的输入电平、所接收的信号中的语音检测等,声学声音处理路径146(b)和/或电声音处理路径146(a)中的一者或两者可以备选地或附加地被适配。例如,电刺激信号主要负责语音清晰度,而声刺激信号主要提供存在。因此,在其中声音信号中检测出语音的实施例中,相对于声刺激的电平或响度,电刺激信号的电平或响度可以被增加。
图4是图示根据本发明的实施例的诸如声音处理单元110的声音处理单元的布置的示意性框图。如所示,声音处理单元110包括一个或多个处理器184和存储器185。存储器185包括声音处理器逻辑186、声音分析逻辑188和电声适配逻辑190。
存储器185可以是只读存储器(rom)、随机存取存储器(ram)或其他类型的物理/有形存储器存储设备。因此,一般来说,存储器185可以包括用软件编码的一个或多个有形(非暂时性)计算机可读存储介质(例如,存储器设备),软件包括计算机可执行指令,并且当软件被执行时(由一个或多个处理器184),其是可操作的,以执行本文参考声音处理器112、声音分析模块148和电声适配模块118描述的操作。
图4图示用于声音处理器112、声音分析模块148和电声适配模块118的软件实现。然而,应该理解,与声音处理器112、声音分析模块148和电声适配模块118相关联的一个或多个操作可以通过一个或多个专用集成电路(asics)中的数字逻辑门而被部分地或完全地实现。
仅为了方便说明,电声适配模块118和声音分析模块148作为与声音处理器112分开的元件而被示出和描述。应该理解,电声适配模块118和声音分析模块148的功能可以被合并到声音处理器112中。
图5是根据本文呈现的实施例的方法192的流程图。方法192在194处开始,其中听力假体确定在听力假体处接收的声音信号的一个或多个属性。在196处,基于所接收的声音信号,听力假体生成声刺激信号和电刺激信号。在198处,基于声音信号的一个或多个属性,听力假体设定声刺激信号对电刺激信号的比。
如所述,已经在本文中参考一个特定类型的听力假体(即包括人工耳蜗部分和助听部分电声听力假体)描述了本发明的实施例。然而,应该理解,本文呈现的技术可以与其他类型的听力假体一起被使用,诸如双模听力假体、包括其他类型的输出设备的电声听力假体(例如,听觉脑干刺激器、直接声刺激器、骨传导设备等)。
应该理解,本文呈现的实施例不是互相排斥的。
本文中描述和要求保护的发明不限于由本文中的特定优选实施例公开的范围,因为这些实施例旨在说明而不是限制本发明的若干方面。任何等同的实施例都旨在本发明的范围内。事实上,从上文的描述中,除了本文中所示和所述的那些,本发明的各种修改对于本领域的技术人员来说将变得清楚。这种修改也旨在落入所附权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!