用于最后系数编码的高级CABAC上下文自适应的方法和装置与流程
本原理通常涉及视频压缩和解压缩系统,更具体地涉及基于块的变换。
背景技术:
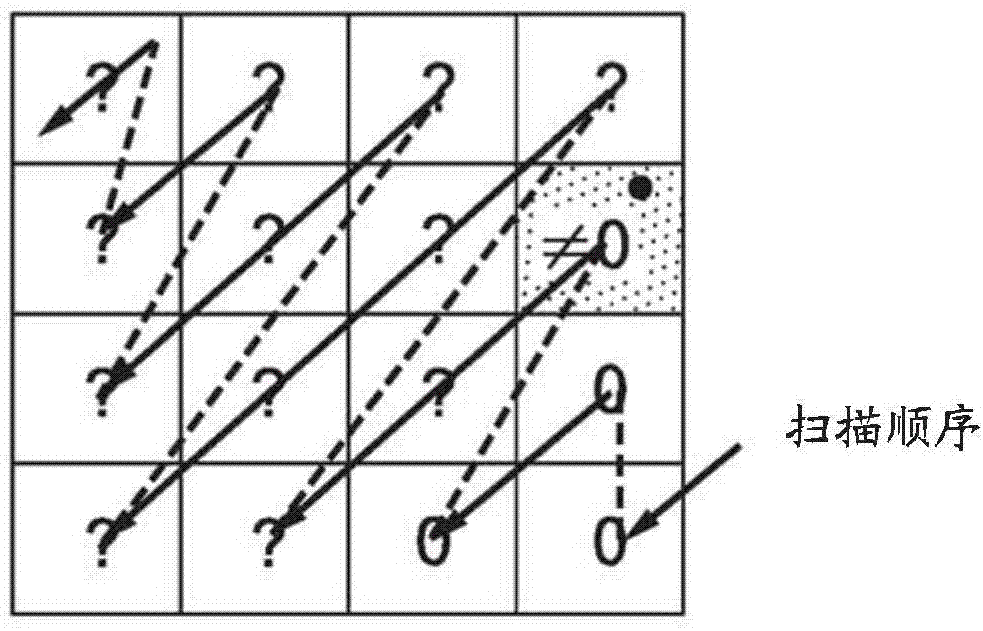
:变换t将n个像素的块变换为n个变换系数。通过对变换系数应用逆变换t-1以复原像素值,该过程是可逆的。在一些视频编码标准中,典型地从高频到低频,将变换系数放入与扫描顺序相关联的二维(2d)块中。如图1所示,在系数的量化之后,相对于高频到低频扫描顺序,第一个非零量化系数被称为最后编码系数。在与系数相关联的2d块拓扑中,对于大小为n=n×n的块,最后编码系数具有两个坐标(x,y),如图2所示。根据定义,0≤x,y≤n-1。这两个坐标被编码到比特流作为用以在解码器侧确定非零编码系数的信息。至少,这些坐标指示坐标(x,y)的系数不为零,并且相对于低到高扫描顺序,在该系数之后的系数都是零。可以添加指示变换系数的重要性的附加信息,以用信号通知剩余系数(图1中的问号标记)是否为零。传统上,在过去几十年中开发的许多视频和图像编解码器中,固定变换,例如,诸如离散余弦变换或离散正弦变换,被应用于每个块的像素以获得变换系数。然后,例如,这些系数被量化器q量化,以获得由诸如vlc、算术编码器或上下文自适应二进制算术编码(cabac)的熵编码器编码的量化系数。期望尽可能高效地编码最后编码系数位置。hevc/h.265标准通过使用两个坐标(x,y)引入了对最后编码系数位置的编码。使用截断的一元码对每个坐标进行二进制化,然后使用具有基于上下文的通道自适应的cabac对每个比特或hevc术语中的“bin(二进制位)”进行编码。在hevc中,两个坐标x和y被分别编码和解码。技术实现要素:本原理解决了现有技术的这些和其它不足和缺点,本原理针对用于最后系数编码的高级cabac上下文自适应的方法和装置。根据本原理的一个方面,提供了一种用于对一组变换系数进行编码的方法,包括:对图像值的块进行变换以获得变换系数的步骤;以及对最后编码系数的位置进行熵编码的步骤,其中,最后编码系数的位置由两个坐标提供,使得y坐标的熵编码取决于x坐标的值。根据本原理的另一方面,提供了一种用于对一组变换系数进行编码的装置,包括:变换电路,其对图像值的块进行操作以获得变换系数;以及熵编码器,其中,变换系数的最后编码系数的位置由两个坐标提供,使得y坐标的熵编码取决于x坐标的值。根据本原理的另一方面,提供了一种用于对一组变换系数进行解码的方法。该方法包括对变换系数进行熵解码以生成最后编码系数的位置,其中最后编码系数的位置由两个坐标(x,y)提供,其特征在于,y坐标的熵解码取决于x坐标的值;以及对变换系数进行逆变换以获得图像值的块的步骤。根据本原理的另一方面,提供了一种用于对一组变换系数进行解码的装置。该装置包括熵解码器,其对表示来自变换系数的最后编码系数的位置的代码进行操作,其中最后编码系数的位置由两个坐标(x,y)提供,其特征在于,y坐标的熵编码取决于x坐标的值。该装置还包括对变换系数进行操作以获得图像值的块的逆变换电路。根据本原理的另一方面,提供了一种非暂时性计算机可读存储介质,其上存储有用于对一组变换系数进行解码的指令,使得最后编码系数的位置由两个坐标(x,y)提供,其特征在于,y坐标的熵编码取决于x坐标的值。根据本原理的另一方面,提供了一种非暂时性计算机可读存储介质,其上存储有用于对一组变换系数进行解码的比特流,使得最后编码系数的位置由两个坐标(x,y)提供,其特征在于,y坐标的熵编码取决于x坐标的值。从以下结合附图阅读的示例性实施例的详细描述,本原理的这些和其他方面、特征和优点将变得明显。附图说明图1示出了变换单元的扫描顺序。图2示出了最后编码系数的坐标的示例。图3示出了具有12个系数的4×4变换单元中的编码的示例。图4示出了坐标值的后缀和前缀确定。图5示出了即时学习方案。图6示出了bd速率增益与各种场景的变换矢量的数量。图7示出了具有部分变换的8×8块的编码。图8示出了上下文值的结构。图9示出了上下文值的演变。图10示出了取决于相邻通道的上下文选择的示例。图11示出了使用本原理对一组变换系数进行编码的方法的一个实施例。图12示出了使用本原理对一组变换系数进行编码的装置的一个实施例。图13示出了使用本原理对一组变换系数进行解码的方法的一个实施例。图14示出了使用本原理对一组变换系数进行解码的装置的一个实施例。具体实施方式通过以下实施例解决的技术问题是降低在已经应用了2d变换的像素的变换块中对最后编码系数的位置进行编码的成本。这些实施例是视频编码标准中常用的熵编码方案的改进。一种这样的视频编码标准是hevc/h.265标准,但是实施例不限于该标准。本原理的主要思想是选择用于编码取决于值x的坐标y的上下文。这显然是可解码的,因为首先解码x,然后是y。这导致更好的编码性能,因为现有方法没有考虑x和y之间的依赖性。例如,相对于在x=0且y>0的情况下具有更多系数的块,所描述的构思特别有助于编码仅具有一个dc系数(x=y=0)的块。简而言之,y通道统计被更好地建模。特别地,如果使用部分变换,则隐含地考虑了并非所有坐标对(x,y)都是可接受的事实,使得(x,y)的编码更高效。在具有部分变换的该特定实施例中,已经使用部分变换对修改的hevc标准进行了测试,并且已经表明(x,y)的改进编码导致约-0.5%的压缩增益。这里呈现的构思提出推断用于编码取决于值x的y的bins的上下文。例如,如图3所示,考虑4x4的tu,其最后编码系数位置为c11。在这种情况下,x=2且y=2。一旦x按照hevc被编码,y的上下文将取决于x。在上面的示例中,使用一元码将值y=2二进制化为001,并且使用专用上下文c0,c1和c2对三个bins中的每一个进行编码。在hevc中,上下文不取决于x,使得c0表示y为零的概率p(y=0)。在本原理下,该上下文被替换为取决于x的c0,x=2,使得它表示概率p(y=0|x=2)。这需要增加由编解码器使用的上下文数量。在一个变体中,这些增加可以通过推断y的上下文,不是通过x的精确值而是通过x的值的范围来限制。例如,取决于x是否为零来选择ci,x=0。而且,这种推断对于有限数量的二进制位可以是高效的,例如仅仅是前几个索引i。在hevc中,如图4所示,坐标x或y被分解为前缀和后缀。例如,如果坐标值是14,则前缀是7,并且后缀用2比特进行编码。后缀是从坐标值中减去第一个值后的余数,14-12=2。如果坐标值为3,则前缀为3,但没有后缀。使用截断的一元码对前缀进行二进制化。基于提供用于前缀值的上限的块大小的知识来执行截断。使用cabac和专用上下文对二进制化的前缀的每个比特进行编码。例如,在4×4块中,可能的前缀是0,1,2或3,它们分别被二进制化为1,01,001和000(截断的)。在另一示例中,在8×8块中,可能的前缀是0到5,并被二进制化为1,01,001,0001,00001和00000(截断的)。使用固定长度编码对后缀进行二进制化,并且在没有上下文的情况下,在旁路模式下使用cabac来对固定长度的后缀进行编码。例如,如果坐标值在16×16的块中为14,则前缀为7(二进制化为0000000),后缀为2(二进制化为10并编码为2比特)。如同在hevc中,保留前缀和后缀的二进制化过程,仅对前缀使用上下文。本原理的主要特征在于,y的上下文取决于x的值。当然,这仅适用于y的前缀,因为后缀是在没有使用任何上下文的情况下进行编码的(而是使用旁路的cabac)。没有对后缀进行任何改变。通常,变换t将n个像素的块变换为m=n个变换系数。通过对变换系数应用逆变换t-1以复原像素值,该过程是可逆的。在部分变换p的情况下,n个像素被变换为较少的(m<n)个变换系数。等效地,可以假设缺少的m-n个系数被设置为零。对变换系数应用“逆”变换p'(当然不是数学逆,因为部分变换是不可逆的)以获得初始像素值的近似。典型地,部分变换系数表示像素块的低频信息。如果使用部分变换,则已知某些m-n个变换系数必然为零,因此对最后编码系数的位置和坐标(x,y)施加一些约束。在这种情况下,通过隐式地使用这些约束,示出了在使用部分变换将tu像素变换为变换系数的情况下,该实施例自动处理两个坐标(x,y)的高效编码。替代诸如dct或dst的系统变换,而是可以使用一组自适应的正交变换,使用不同的分类和变换优化方案在大训练集上离线学习该正交变换。将这组变换馈送到编解码器,并且在率失真优化(rdo)循环中选择组中的最佳变换。更加适应性的手段是对序列的特定帧内帧学习一组正交变换。这在本说明书的其余部分中被称为基于即时块的变换学习方案。该方案如图5所示。图5的框图示出了典型的即时方案,其中算法被分解为两部分,即视频/图像编解码器内的残差块的分类和新的变换组的生成。第一步将残差块分类为k个不同的类(s1...sk)。在第二步中,使用针对特定类的重构误差的最小化来获得针对每个类的新变换。通常,奇异值分解(svd)和(karhunen-loève变换)klt被用于生成一组正交变换。迭代这两个步骤直到达到解的收敛或停止准则。如框图所见,系统的输入是帧内帧或图像以及一些初始的不可分离的正交变换组(t1...τk)。系统输出一组学习变换(t'1…τ'k)以及需要被编码到发送到解码器的比特流中的语法信息。通常,与编码帧所需的比特相比,编码这些变换基矢量所需的开销比特相当大。由于svd的能量压缩特性,观察到通过推导学习变换的不完整表示可以显著降低开销成本,其中只有前‘m’个矢量被传输到解码器而剩余的(n-m)个变换矢量不是使用类似于gram-schmidt方法的完整算法生成就是被强制为零,从而导致部分变换。为了说明丢弃变换的最后几个矢量对bjontegaard失真率(bd率)(bjontegaarddistortionrate)的影响,在4k序列‘peopleonstreet’和‘traffic’上学习了四个大小为64×64的不可分离的优化的变换。对这些序列执行编码测试,测试中保留前‘m’个矢量,然后使用完整算法完成其余的基矢量。图6示出了性能增益相对于编码基矢量的数量的变化。垂直轴是相对于锚(hevc测试软件hm15.0)的在不考虑变换成本的情况下的增益百分比。在图2中观察到,通过仅保留变换矢量的前一半,即m=32,就bd率而言,性能下降可忽略不计。对于m=16的情况,即当仅编码前16个基矢量时,与通过编码所有‘n’个基矢量获得的总比特率相比,性能下降1%,但是变换矢量的开销成本降低至总开销的四分之一。对于m=8,就bd率性能而言,有显著的性能损失,但也进一步降低了开销。总之,这表明在性能损失和开销成本之间存在折衷。由于当仅编码前‘m’个变换矢量时,就bd率而言的性能下降取决于视频内容,因此有必要用内容自适应方法来估计‘m’的最优值。直观地,在低比特率下,大多数系数被量化为零,在高比特率下,系数的能量即使在高频率下也是显著的。因此,‘m’的值取决于内容,也取决于量化参数qp。平均的残差信号能量更多地集中在前几个系数中,其中dc系数平均具有最大能量,并且随着我们增高频率系数而降低。因此,大多数高频系数被量化为零。可以应用简单的基于阈值的方法来计算‘m’的最佳值,该最佳值需要作为开销与帧一起被编码。设e是dct系数的能量之和。阈值t被定义为参数p与e的乘积,获得,t=p·e‘m’的值可以简单地从平均能量大于该阈值的系数的数量中计算。‘p’的值可以通过实验找到。就被编码的矢量的总数的百分比而言,表1示出了对于所选择的‘p’的值,超过该阈值的矢量的数量‘m’的变化。从表1中观察到,与低qp所需的相比,在高qp下所需的矢量的平均数量要少得多。此外,矢量的数量‘m’也随内容而变化。表1:针对不同序列的编码的矢量的数量和阈值当使用部分变换应用本原理时,y前缀的范围取决于x并且y的上下文自动适应。再次考虑图3的示例,使用m=12的部分变换,使得最后的16-12=4总是为零。现在,让我们假设对于特定的tu,最后编码系数是c9。那么,如果在hevc中编码,则坐标(x,y)=(3,0)变为(000,0)。坐标x如hevc中那样被编码。关于坐标y,使用cabac上下文对二进制化的唯一比特0进行编码。在hevc中,此上下文不取决于x的值。相反,遵循这里描述的原理,用于对y前缀的二进制位进行编码的上下文却取决于x的值。所以,在本示例中,当x=3时,因为在x=3的情况下强制使其他系数在最后一列为0的部分变换,针对y前缀唯一可能的值是0,且针对y的编码的第一个比特始终为0。因此,依赖于x=3的上下文看到只有零的通道,并且它适应通道的统计,使得在tu的一些编码之后,编码0的成本就比特率而言变得可忽略不计。这就是上下文如何隐式自适应以高效地编码y的第一比特,理想情况下,根本不应该对所述y的第一比特进行编码,因为可从隐式变换得知x=3推断出y=0。具有部分变换的实施例容易扩展到使用后缀的坐标y,如图7中对8×8tu中的示例,使用m=57的部分变换。前57个变换系数可以是非零的,但最后64-57=7个系数必须为零。让我们假设最后编码系数位置是55。这给出了坐标(x,y)=(5,6)。y的前缀为5,并且后缀为0。在hevc中,后缀应该被编码为1比特,但在我们的情况下,我们知道后缀不能是1,因为在系数55正下方的系数58在这种情况下已知必然是零,所以没有对后缀进行编码并有一比特的编码的增益。在hevc/h.265标准中,在算术编码器中已经提出了用于编码二进制数据的新工具,即上下文自适应二进制算术编码(或cabac)。取值为0或1的二进制符号s以遵循概率p被编码为1以及概率1-p被编码为0。此概率是从上下文推导出来的,并且在每个符号编码之后进行适应。上下文值是8比特值,参见图8。起始比特表示最可能的符号(mostprobablesymbol)(或mps),并且接下来的7个比特表示可由其推导出概率p的概率p'(或状态)。取决于编码符号是否等于mps,遵循图9中描述的过程对上下文值进行更新。通过两个表进行演进:如果编码符号是mps,为transidxmps,如果编码符号不是mps,则为transidxlps,即,它是最小可能符号(leastprobablesymbol)(lps)。表2提供了针对条目p′的这些表,其名称为pstateidx。表2:上下文状态演进表表9-41状态转换表pstateidx0123456789101112131415transidxlps0012244567899111112transidxmps12345678910111213141516pstateidx16171819202122232425262728293031transidxlps13131515161618181919212122222324transidxmps17181920212223242526272829303132pstateidx32333435363738394041424344454647transidxlps24252626272728292930303031323233transidxmps33343536373839404142434445464748pstateidx48495051525354555657585960616263transidxlps33333434353535363636373737383863transidxmps49505152535455565758596061626263符号s为mps的概率pmps在8比特上线性量化,从0到127。它从上下文值中推导出来pmps=(p′+64)/127=(pstateidx+64)/127并且取决于mps的值,符号s为1的概率p显而易见地从pmps推导出。p=pmps如果mps=1,p=1-pmps如果mps=0。上下文自适应编码是一种允许编码动态地遵循符号所属通道的统计的强大的工具。而且,为了避免混淆统计以及失去该过程的好处,每个通道都应该有它自己的上下文。这已经导致在hevc/h.265中许多上下文的广泛使用,其使用数百个上下文,以便为许多通道建模。例如,在使用上下文的所有通道中,有·运动矢量残差,·tu编码标志,·最后显著系数位置,·编码组编码标志,·变换系数显著标志,·变换系数幅度(大于1和大于2)标志,·sao数据,·其他数据。所有这些上下文/通道也很大程度上取决于颜色通道(即,通道是亮度还是色度)、变换单元大小、变换系数的位置、相邻符号值和其他因素。作为示例,编码组(cg)编码标志取决于当前cg下方和右侧的cg编码标志是否为1来选择,如图10所示。总而言之,上下文选择取决于很多因素,因此有大量的上下文。当然,解码器必须更新上下文值以与在编码器侧执行的相对应,以确保与编码器的同步和流的解析。这里描述的实施例提出对最后编码系数的y坐标的上下文选择添加依赖性,这种依赖性是所述x坐标的值。应注意,该上下文选择还取决于(如hevc中标准化的)颜色通道(亮度或色度)、tu大小和扫描顺序。除了可以在比特流中用信号通知的部分变换的情况之外,没有实现所描述原理所需的特定语法。关于解码过程,这里描述的原理影响与最后编码系数位置和解码最后编码系数位置的过程相关联的上下文的数量。在具有部分变换的实施例中,y后缀的改进的二进制化和截断的一元编码也受到影响。除了本原理的上述特征之外,所描述的实施例还提供了y坐标的熵编码由cabac和相关联的上下文执行,依赖性是通过x的值对上下文的选择的推断;y坐标的熵编码通过使用前缀和后缀来执行,依赖性是通过x的值对用于y的前缀进行编码的上下文的选择的推断,并且作为变型,变换是部分变换,且对y后缀的二进制化使用部分变换的大小m的知识来截断。所提出的构思在其呈现在视频流的语法中的意义上是规范的并且隐含了一种要应用的解码方法。因此,本构思可以在诸如hevc的后继者的视频标准中实现。图11中示出了用于编码一组变换系数的方法1100的一个实施例。该方法在开始框1101处开始,并且控制前进到框1110,用于变换图像值的块以产生变换系数值。控制从框1110前进到框1120,以使用x坐标对最后编码系数进行熵编码以对y坐标进行编码。图12中示出了用于编码一组变换系数的装置1200的一个实施例。该装置包括变换电路1210,变换电路在其输入端口上接收图像值的块并在其输出端口上产生变换系数。变换电路1210的该输出端口与熵编码器1220的输入在信号上连接。熵编码器1220基于最后编码系数位置的x坐标对最后编码系数位置的y坐标进行编码,以产生最后编码系数值。图13中示出了用于解码一组变换系数的方法1300的实施例。该方法在开始框1301处开始,并且控制前进到框1310,以使用x坐标值对最后编码系数进行熵解码以解码y坐标值。控制从框1310前进到框1320,用于对系数进行逆变换以产生图像值。图14中示出了用于解码一组变换系数的装置1400的实施例。该装置包括熵解码器1410,熵解码器接收包括针对最后编码系数的编码的变换系数并基于x坐标对最后编码系数的y坐标进行解码。熵解码器1410的输出与逆变换电路1420的输入在信号上连接。逆变换电路1420在其输入端口上接收变换系数并对它们进行逆变换以在其输出端口上产生图像值的块。前述实施例可以在机顶盒(stb)、调制解调器、网关或执行视频编码或解码的其他设备中实现。可以通过使用专用硬件以及与适当软件相关联的能够运行软件的硬件来提供图中所示的各个元件的功能。当由处理器提供时,可以由单个专用处理器、由单个共享处理器或由其中某些可以被共享的多个单独处理器提供功能。此外,术语“处理器”或“控制器”的明确使用不应被解释为专指能够运行软件的硬件,并且可以隐含地包括但不限于数字信号处理器(“dsp”)硬件、用于存储软件的只读存储器(“rom”)、随机存取存储器(“ram”)和非易失性存储器。还可以包括其他硬件、传统的和/或定制的。类似地,图中所示的任何开关仅是概念性的。它们的功能可以通过程序逻辑的操作、通过专用逻辑、通过程序控制和专用逻辑的交互,或甚至手动地执行,特定技术可由实施者选择,如从上下文中更具体地理解的。本说明书说明了本原理。因此,应当理解,本领域技术人员将能够设计出各种布置,这些布置虽然未在本文中明确描述或示出,但体现了本原理并且包括在其精神和范围内。本文所引用的所有示例和条件语言旨在用于教学目的,以帮助读者理解由本发明人提供的本原理和概念,以促进本领域,并且应被解释为不限于这些具体引用的示例和条件。此外,这里叙述本原理的原理、方面和实施例的所有陈述以及其具体示例旨在包含其结构和功能等同方式。另外,其旨在这些等同方式包括当前已知的等同方式以及将来开发的等同方式,即,开发的执行相同功能的任何元件,而不管结构如何。因此,例如,本领域技术人员将理解,这里给出的框图表示体现本原理的说明性电路的概念图。类似地,应当理解,任何流程图、流程示意图、状态转换图、伪代码等表示可以实质上在计算机可读介质中表示并且由计算机或处理器运行的各种过程,无论这样的计算机或处理器是否被明确显示。在权利要求中,表示为用于执行指定功能的部件的任何元件旨在包含执行该功能的任何方式,包括例如:a)执行该功能的电路元件的组合,或b)与用于运行软件以执行该功能的适当电路相结合的任何形式的软件,因此包括固件、微代码等。由这些权利要求限定的本原理在于,由各种所述装置提供的功能以权利要求所要求的方式组合和结合在一起。因此认为任何能够提供这些功能的部件都等同于这里所示的部件。说明书中对本原理的“一个实施例”或“实施例”以及其其他变型的引用意味着结合该实施例描述的特定特征、结构、特性等被包括在本原理的至少一个实施例中。因此,出现在在整个说明书中的各个地方的短语“在一个实施例中”或“在实施例中”以及任何其他变型的出现不一定都指代相同的实施例。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1