用于编码视频的方法和装置与流程
公开了一种用于将视频编码为比特流的方法和装置。
背景技术:
为了对视频序列的图片进行编码,视频压缩方法通常将图片划分成像素块集合。
在hevc视频压缩标准中(“itu-th.265国际电信联盟电信标准化部/门”(10/2014),h系列:视听及多媒体系统,视听业务基础设施-移动视频编码,高效视频编码,推荐书itu-th.265”),圈片划分为大小可以是64x64、128x128或256x256像素的编码树单元(ctu)。可以采用四叉树划分对每个ctu进一步细分,其中四叉树的每片叶子称为编码单元(cu)。然后向每个cu赋予一些帧内或帧间预测参数。为此目的,cu在空间上被分区为一个或多个预测单元(pu),pu可以具有正方形或矩形形状。
将编码单元分区为预测单元是根据在比特流中用信号通知的分区类型来完成的。对于帧内编码单元而言,仅允许图1所示的分区类型2nx2n和nxn。这意味着在帧内编码单元中仅使用正方形的预测单元。相反,帧间编码单元可以使用图1所示的所有分区类型。
四叉树加二叉树(qtbt)编码工具(“联合探索测试模型3的算法描述”,文档jvet-c1001_v3,iso/iecjtc1/sc29/wg11的联合视频探索小组,第3次会议,2015年5月26日-6月1日,geneva,ch),提供了ctu表示,用于以比hevc标准的单元布置更灵活的方式表示图片数据。四叉树加二叉树(qtbt)编码工具存在于编码树中,其中编码单元可以以四叉树和二叉树方式进行分裂。图2a中示出了编码树单元的这种编码树表示,其中实线表示四叉树分区,而虚线表示cu的二元分区。
通过速率失真优化过程在编码器侧对编码单元的分裂作出决策,该速率失真优化过程包括以最小速率失真成本确定ctu的qtbt表示。在qtbt表示中,cu具有正方形或矩形形状。编码单元的大小总是2的幂,通常为4到128。ctu的qtbt分解由两个阶段组成:首先,ctu以四叉树方式分裂,然后,每片四叉树叶子可以进一步按照二元方式划分,如图2b所示,其中实线表示四叉树分解阶段,而虚线表示在空间上嵌入四叉树叶子中的二元分解。
从图3可以看出,在引入了qtbt工具的情况下,可以通过不同的分裂路径对指定块进行编码。如图3所示,可以通过以下方式获得子cu(图3中以散列填充):
-要评估的当前cu(在图3中具有加粗边界)的水平分裂,得到上子cu和下子cu,随后是上子cu的垂直分裂,或者,
-要评估的当前cu的垂直分裂,得到左子cu和右子cu,随后是左子cu的水平分裂,或者,
-要评估的当前cu的四叉树分裂。
因此,为了确定包括当前cu的分裂配置的最佳编码模式,多次进行了左上子cu的速率失真成本的计算。
技术实现要素:
根据本原理的一个方面,公开了一种用于编码视频的方法。对于来自所述视频的图片的至少一个块,这种方法包括:
-执行第一速率失真优化,用于针对所述块分裂为第一集合的至少一个第一子块的第一分裂模式,确定所述至少一个第一子块的编码参数;
-执行至少一个第二速率失真优化,用于针对所述块分裂为至少一个第二集合的至少一个第二子块的至少一个第二分裂模式,确定所述至少一个第二集合的所述至少一个第二子块的编码参数;
-将参数与所述至少一个第一子块相关联,所述参数的特定值指示在所述第一速率失真优化期间确定的所述第一子块的至少一个编码参数用于确定第二子块的编码参数;
-根据所述第一速率失真优化和所述至少一个第二速率失真优化,确定用于编码所述块的最佳分裂模式,
-根据所述最佳分裂模式,对所述块进行编码;
其中:
-当第二子块位于图片中与所述第一子块相同的位置时;
-当所述第二子块具有与所述第一子块相同的宽度和相同的高度时;以及
-当所述第一子块和所述第二子块具有相同的因果邻域时,所述因果邻域包括用于预测子块或者用于编码第一或第二子块的编码参数的数据,
与至少一个第一子块相关联的参数被设置为所述特定值。
当这些子块位于相同的位置并且具有相同的宽度和相同的高度时,本公开允许将已经为由第一分裂模式得到的子块进行估计的编码参数重新用于由第二分裂模式得到的子块。因而降低了计算复杂性。
根据实施例,当根据扫描顺序对所述第一集合进行排序时,在所述第一子块是第一集合的第一子块时,所述第一子块和所述第二子块具有与子块相同的因果邻域。
根据本公开的另一实施例,所述特定值指示所述至少一个第一子块的编码参数可用,并且所述至少一个第二子块的编码参数被确定为与为所述至少一个第一子块确定的编码参数相同的编码参数。
根据实施例,当所述至少一个第一子块的所述编码参数包括所述至少一个第一子块的分裂配置时,所述至少一个第二子块继承(1005)所述分裂配置。
根据本公开的另一实施例,所述参数的所述特定值指示:通过从为所述至少一个第一子块确定的编码参数中搜索用于编码所述至少一个第二子块的最佳编码参数,确定(802)所述至少一个第二子块的编码参数。
根据本实施例,子块的编码参数被部分地重新用于另一个对应的子块。由于子块的因果邻域从一个分裂模式变为另一个分裂模式,完全重新使用已经针对子块进行估计的编码参数可能会影响压缩效率。但是,当在第二分裂模式下估计子块的编码参数时,可以将已经针对子块进行估计的编码参数部分地重新用作编码参数搜索的起始点。因此,由于没有完全执行对编码参数的搜索,因此降低了计算复杂度,但是,本实施例对压缩效率的影响很小。
根据本公开的另一实施例,仅当评估所述至少一个第二子块的非分裂模式时才使用(802)所述至少一个第一子块的所述编码参数。
根据本公开的另一实施例,该方法还包括:
-计算(1201)所述至少一个第一子块的标识符,所述标识符允许识别所述至少一个第一子块的所述位置、所述宽度和所述高度以及所述至少一个第一子块的因果邻域,所述因果邻域至少指示是否已经在之前确定了所述至少一个第一子块的相邻部分的编码参数,
-针对所述至少一个第一子块或所述至少一个第二子块,与所述标识符相关联地存储(1204)针对所述至少一个第一子块确定的编码参数,
-针对所述至少一个第二子块,如果与所述至少一个第一子块相关联的所述参数等于所述特定值,则使用(1205)所述标识符来读取与所述标识符相关联的存储的编码参数,所述至少一个第二子块的编码参数被确定为所读取的编码参数。
根据本公开的另一方面,公开了一种用于编码视频的装置。针对来自所述视频的图片的至少一个块,这种装置包括:处理器,该处理器配置为:
-执行第一速率失真优化,用于针对所述块分裂为第一集合的至少一个第一子块的第一分裂模式,确定所述至少一个第一子块的编码参数;
-执行至少一个第二速率失真优化,用于针对所述块分裂为至少一个第二集合的至少一个第二子块的至少一个第二分裂模式,确定所述至少一个第二集合的所述至少一个第二子块的编码参数;
-将参数与所述至少一个第一子块相关联,所述参数的特定值指示:在所述第一速率失真优化期间确定的所述第一子块的至少一个编码参数用于确定第二子块的编码参数;
-根据所述第一速率失真优化和所述至少一个第二速率失真优化,确定用于编码所述块的最佳分裂模式,
-根据所述最佳分裂模式,对所述块进行编码;
其中:
-当第二子块位于图片中与所述第一子块相同的位置时;
-当所述第二子块具有与所述第一子块相同的宽度和相同的高度时;以及
-当所述第一子块和所述第二子块具有相同的因果邻域时,所述因果邻域包括用于预测子块或者用于编码第一或第二子块的编码参数的数据,
与至少一个第一子块相关联的参数设置为所述特定值。
本公开还提供了根据本公开中描述的任何一个实施例的一种计算机可读存储介质,其上存储有用于编码视频的指令。
根据一种实施方式,如上所述的用于编码视频的方法的不同步骤由一个或多个软件程序或软件模块程序实现,所述软件程序或软件模块程序包括旨在由用于编码视频的装置的数据处理器执行的软件指令,这些软件指令设计成命令根据本原理的方法的不同步骤的执行。
还公开了一种能够由计算机或数据处理器执行的计算机程序,此程序包括指令,用于命令如上所述的用于编码视频的方法的步骤的执行。
此程序可以使用任何编程语言,并且可以是源代码、目标代码或源代码与目标代码之间的中间代码的形式,例如,部分编译的形式或任何其他期望的形式。
信息载体可以是能够存储程序的任何实体或装置。例如,载体可以包括诸如rom之类的存储装置(例如,cdrom或微电子电路rom),或者也可以包括磁记录装置(例如,软盘或硬盘驱动器)。
同样,信息载体可以是可传输载体,例如,电信号或光信号,其可以通过电缆或光缆、通过无线电或通过其他方式进行传送。可以特别地将根据本原理的程序上传到因特网类型的网络。
作为替代方案,信息载体可以是其内包含程序的集成电路,该电路适于执行或适于用于执行所讨论的方法。
根据一个实施例,可以借助于软件和/或硬件组件来实现方法/装置。就此而言,术语“模块”或“单元”在本文献中可以同等地对应于软件组件和硬件组件或者对应于硬件组件和软件组件的集合。
软件组件对应于一个或多个计算机程序、程序的一个或多个子程序,或者更普遍地对应于能够实现有关模块的如下文所述的功能或功能集合的程序或软件的任何元素。这样的软件组件由物理实体(终端、服务器等)的数据处理器执行,并且能够访问该物理实体的硬件资源(存储器、记录介质、通信总线、输入/输出电子板、用户接口等)。
同样地,硬件组件对应于能够实现有关模块的如下文所述的功能或功能集合的硬件单元的任何元素。它可以是可编程硬件组件或具有用于执行软件的集成处理器的组件,例如,集成电路、智能卡、存储卡、用于执行固件的电子板等。
附图说明
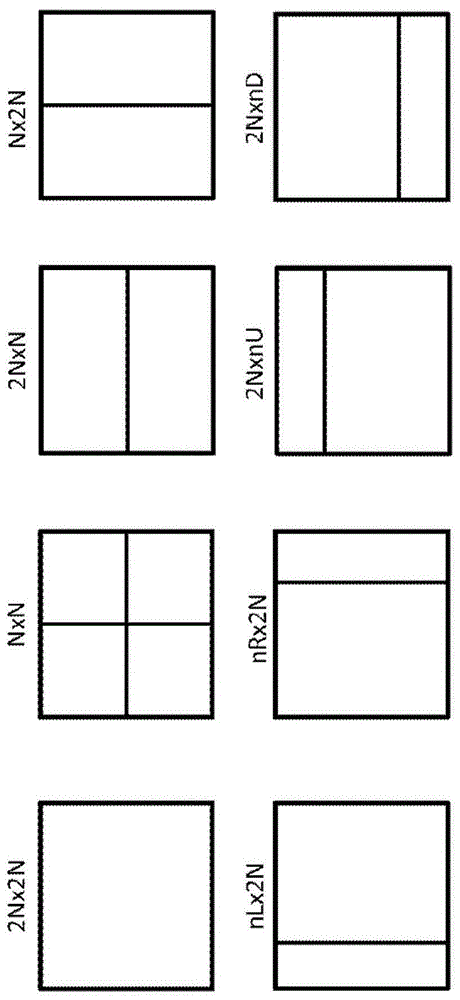
图1示出了根据hevc标准的ctu的示例性分区,
图2a示出了根据基于四叉树和二叉树的方法(qtbt)的示例性ctu分区,
图2b示出了根据基于四叉树和二叉树的方法(qtbt)的ctu分区的示例性树状表示,
图3示出了用于对编码单元(cu)进行编码的示例性分裂路径,
图4示出了根据本原理的实施例的用于编码视频的示例性编码器的框图,
图5示出了根据本公开的实施例的与包括在分裂模式集合中的分裂模式相关联的空间编码结构,
图6示出了根据本公开的实施例的用于编码视频的示例性方法的流程图,
图7示出了根据本公开的实施例的qtbt不同分裂路径和对应的因果邻域,
图8示出了根据本公开的另一实施例的用于编码视频的示例性方法的流程图,
图9示出了导致子cu的相同分裂配置的qtbt不同分裂路径,
图10示出了根据本公开的另一实施例的用于编码视频的示例性方法的流程图,
图11示出了导致相同子cu具有不同的因果邻域状态的qtbt不同分裂路径,
图12示出了根据本公开的另一实施例的用于编码视频的示例性方法的流程图,
图13示出了可以在本原理的任何一个实施例中使用的示例性编码器。
具体实施方式
虽然本文公开的原理被描述为用于编码来自视频序列的图片,但是,所公开的原理也可以应用于静止数字图片。
为了对具有一个或多个图片的视频序列进行编码,可以将图片分区为具有可配置大小的方形编码树单元(ctu)。可以将连续编码树单元集合分组为片。ctu是分区为编码单元(cu)的qtbt的根节点。
图4示出了根据本原理的实施例的用于编码视频的示例性编码器的框图。下面公开的视频编码器30可以符合任何视频或静止图片编码方案。在示例性视频编码器30中,图片由编码器模块进行编码,如下所述。
就传统上而言,视频编码器30可以包括用于基于块的视频编码的若干模块,如图4所示。待编码的图片i输入到视频编码器30。图片i首先通过细分模块细分为块集合。然后,处理图片i的每个块(blk),以进行编码。在下文中,块可以对应于来自qtbt分区的编码单元。
下面描述的编码和解码过程用于说明目的。根据一些实施例,可以添加或移除编码或解码模块,或者编码或解码模块可以根据以下模块而发生改变。然而,本文公开的原理仍可应用于这些变型。
视频编码器30如下执行图片i的每个块的编码。视频编码器30包括模式选择单元,用于为待编码的图片的块选择编码模式(例如,基于速率/失真优化)。使用帧内或帧间模式对每个块进行编码。模式选择单元包括:
-运动估计模块,用于估计待编码的图片的一个当前块与参考图片之间的运动,
-运动补偿模块,用于使用估计的运动来预测当前块,
-帧内预测模块,用于在空间上预测当前块。
模式选择单元还可以根据速率/失真优化来决定是否需要对块进行分裂。在那种情况下,模式选择单元随后针对块blk的每个子块进行操作。
当块被进一步分裂时,块模式选择单元为块或块的子块的每种候选编码模式执行块的编码,并计算这些编码模式中的每一种的速率失真成本。将提供最低速率失真成本的编码模式选为当前块blk的最佳编码模式。候选编码模式可以是可用于对块进行编码的任何编码模式,并且取决于所使用的视频压缩标准。例如,对于hevc编码器而言,可以从36种帧内预测模式中的一种模式、采用估计运动矢量的帧间预测模式、从空间和/或时间相邻块导出运动信息的合并编码模式等中选择候选编码模式。
为了确定当前块的最佳编码模式,执行速率失真优化,并且当允许进行当前块的分裂时,评估当前块的所有可用分裂模式。
图5示出了当前块的不同分裂模式。qt_split产生4个子块。hor和ver分别产生2个子块。no_split模式对应于当前块未进行分裂的情况,因此,可以将其理解为产生了宽度和高度与当前块相同的一个子块。当评估当前块的分裂模式时,针对由分裂模式产生的当前块的每个子块执行速率失真优化,并且在确定与当前块的分裂模式相关联的速率失真成本时,必须将分裂语法考虑在内。
根据实施例,由分裂模式产生的当前块的子块可以根据可用的分裂模式或这些子块进一步进行分裂。可以为子块分配树深度,以便指示达到该子块所需的连续分裂数量。
回到图4,一旦为当前块blk选择了编码模式或者为当前块blk的子块选择了编码模式,模式选择单元就得到预测块pred和要在比特流中进行编码的对应语法元素,以便在解码器处执行相同的块预测。当当前块blk已经进行了分裂时,预测块pred由模式选择单元针对每个子块得到的预测子块集合形成。
之后,通过从原始块blk中减去预测块pred来获得残差块res。
残差块re随后通过变换处理模块变换,得到变换系数的变换块tcoef。然后,通过量化模块量化变换块tcoef,得到量化残差变换系数的量化变换块qcoef。
然后,将块qcoef的语法元素和量化残差变换系数输入到熵编码模块以传递编码数据,进而形成编码比特流str。
量化变换块qcoef的量化残差变换系数由反量化模块处理,得到去量化变换系数的块tcoef′。块tcoef′被传递到逆变换模块,用于重建残差预测块res′。
然后,通过将预测块pred添加到重建残差预测块res′来获得块blk的重建版本rec。
重建块rec存储在存储器中以供图片重建模块使用。图片重建模块根据重建块rec执行图片i的解码版本i′的重建。然后,将重建图片i′添加到参考图片存储器中,以供稍后用作参考图片,该参考图片用于对要编码的图片集合的后续图片进行编码或者用于对图片i的后续块进行编码。
如图3所示,为了确定当前块的最佳编码模式,多次完成由当前块的分裂模式产生的子块的速率失真优化。下面公开了一种用于编码视频的方法,其中对于由当前块的第一分裂模式产生的并且对应于由当前块的第二分裂模式产生的子块的子块,当已经评估了当前块的第一分裂模式时,为该子块执行的速率失真优化可以重新使用先前为该子块估计的编码参数。
根据本公开的实施例,参数cucache(p,w,h)与由当前块的分裂或当前块的子块的分裂产生的子块相关联。这样的参数表明是否已经为该子块估计了编码参数。这样的参数与位置p处的每个子块相关联,其中宽度=w且高度=h,所述位置p由所述子块的左上像素的位置指示。
在下文中,术语“块”或“cu”可以无差别地用于指定块。
术语“子块”或“子cu”可以无差别地用于指定子块,其中子块是由父块分裂成至少一个子块而产生的较高深度等级下的块。
考虑根据实体的深度来使用术语“子块”或“块”。当将块分裂成一组子块时,被分裂的块具有比由分裂产生的子块(例如,子块的深度为1)更低的深度(例如,0)。当进一步分裂子块时,所得子块的深度增加。在本公开中,在分裂树的子块上以递归方式执行速率失真优化。因此,当考虑由块的分裂产生的子块的分裂时,可以将该子块称为块。
图6示出了根据本公开的实施例的用于编码视频的示例性方法的流程图。根据本实施例,参数cucache可以采用两个可能的值,例如0或1。
值0表示子块的编码参数都不可用。值1表示子块的编码参数可用(通过先前执行的对当前块的分裂模式的评估而提供),并且在评估另一分裂模式时,应该完全重新使用这样的编码参数。
对图6中公开的过程的输入是要压缩的输入编码单元,其具有位置(由当前图片中左上像素的位置指示)和由宽度和高度表示的大小。
对该算法的输入是要编码的输入编码单元currcu,这样的输入cucurrcu在当前图片中分别具有沿水平和垂直方向的大小(width,height)和位置(位置)。
在步骤600中,首先检查currcu是否允许no_split分裂模式。在允许no_split分裂模式的情况下,过程转到步骤601,否则,过程转到步骤606。
根据本实施例,在步骤601中,检查与当前cu相关联的cucache参数,以确定是否已经计算了该cu(值1)。
如果是,则在步骤605,从高速缓冲存储器中检索结果。也就是说,存储在存储器中的预测模式和rdcost被复制到当前cu的当前编码参数中,并且过程进行到步骤606。
如果尚未计算当前块(cucache的值0),则如下评估所有编码模式。
在步骤602中,no_split分裂模式被评估为当前cucurrcu的候选编码结构。no_split分裂模式意味着当前cu不被划分为子cu,因此,预测、变换、量化和熵编码步骤应用于具有大小(width,height)((宽度,高度))的当前块。
因此,在步骤602中,正在搜索当前编码单元的最佳编码模式(预测模式、帧内预测角度、帧内平滑模式、运动矢量、变换索引......)。最佳cu编码参数标记为p*,并且对应于具有最小速率失真成本dp+λ·rp的编码参数集合,其中dp是失真,rp是速率成本(编码当前cu的比特数),而λ是拉格朗日参数。
在步骤602中,在no_split分裂配置下,与当前cu相关联的所得速率失真成本(标记为rdcost(currcu,no_split))通过如下方式计算:用最佳编码参数p*编码当前cu,并且还整合与分裂语法(用于发信号通知当前cu的no_split配置)相关联的速率成本。
在这些步骤期间,特别是当用参数p*对当前cu进行编码时,矩形块的特征在于相对形状(这里,形状是指与由一系列分裂操作产生的cu状态有关的参数)。在当前标准中,块通常以其qt深度为特征(其中qt深度是连续qt分裂的数量)。这用于例如选择与块相关联的编码参数的熵编码的上下文信息。
从图3中可以看出,要评估的当前子cu可以具有不同的分裂模式,从而导致不同的qt深度或bt深度值(bt深度是连续bt分裂的数量)。例如,左侧情况和中间情况导致qt深度为1,而右侧情况导致qt深度为2。使用qt深度来选择熵编码的上下文信息会导致不同的熵编码。因此,不再参考cu的深度,而是参考当前cu的宽度或高度。通过使用块的宽度或高度来表征其形状,确保了使用相同的上下文信息来编码或解码那些编码参数。
例如,基于形状相关的上下文信息来发信号通知的编码参数可以涉及指示出采用了当前cu的系数的自适应变换的标志。
在步骤604中,将在步骤602中估计的模式决策和rdcost存储在高速缓冲存储器中,以供进一步使用。
当子块的因果关系相同时,为由其他分裂模式产生的子块估计的编码参数是相同的。通过因果关系,应理解的是,子块的因果邻域包括用于预测子块或用于编码子块的编码参数的数据。这样的数据可以是子块的上侧和左侧的重建像素值、帧内预测模式、运动矢量等。
例如,对于由父cu的分裂产生的第一子cu,没有改变当前cu的因果关系。
因此,根据本公开的实施例,在步骤604之前,根据由父cu的分裂产生的子cu的扫描顺序,在步骤603中检查评估中的当前cu是否是来自子cu(是由父cu的分裂而产生的)的第一子cu。例如,检查子cu的位置是否与其父cu的位置相同,即,子cu的索引是否为0。对于分裂模式hor、ver、qt_split,在图5中示出了由父cu的分裂产生的子cu的示例性扫描顺序。在图5中,子cu内的数字表示子cu在扫描顺序中的顺序。其他扫描顺序也是可能的。
如果评估中的当前cu不是来自由父cu的分裂而产生的子cu的第一子块,则该过程转到步骤606。
否则,该过程进行到步骤604。
该过程的下一阶段包括连续地评估当前cu的所有候选分裂模式。所有二元和四元分裂模式对应于以下集合:
s-{hor,ver,qt_split}
图5示出了这些分裂模式中的每一种的示例性方形编码单元的空间分裂。
在步骤606中,从分裂模式集合中选择候选分裂模式,例如列表中的第一分裂模式。
对于每个候选分裂模式,执行以下步骤。
在步骤607中,确定当前cu是否允许当前候选分裂模式。如果候选分裂模式是二元分裂模式(hor或ver),则该测试包括首先检查当前cu的大小是否高于最小cu大小(在宽度或高度方面),其次是当前cu的大小小于最大cu大小(在宽度或高度方面),以及第三,连续二元分裂的数量低于二元分裂的最大数量:
((height>uiminbtsize||width>uiminbtsize)
&&width<=uimaxbtsize&&height<=uimaxbtsize&&uibtdepth<uimaxbtd)
其中
uiminbtsize表示二叉树中编码单元允许的最小大小,
uimaxbtsize表示二叉树中编码单元允许的最大大小,
uibtdepth表示二叉树中当前cu的深度(即,从父cu获得当前cu的连续二元分裂的数量),其配置由正在进行的过程确定,
uimaxbtd表示二叉树的最大允许深度。
如果不允许候选分裂模式,则过程直接进入步骤612。
如果允许候选分裂模式,则过程转到步骤608。
在步骤608中,根据当前候选分裂模式,将当前cu划分为2个或4个较小的子cu。如果分裂模式对应于二元分裂配置,则获得2个子cu,其具有根据图3所示的块空间划分的相应大小。在当前候选分裂模式等于qt_split的情况下,获得大小相同
((宽度/2,高度/2))的4个子cu。
在步骤609中,一旦获得了子编码单元,就对每个获得的子cu执行循环。对于每个获得的子cu,以递归方式调用图6的当前过程。这样做能为每个获得的子cu获得最佳编码参数集。
在步骤610中,根据为每个获得的子cu获得的最佳编码参数集,为每个子cu获得最小速率失真成本,标记为
在步骤611中,根据当前候选分裂模式,通过将子编码单元subcui,i=0,...,n-1与指示当前cu如何划分为子编码单元所需的分裂语法一起进行编码来对当前cucurrcu进行编码。因此,获得与当前cu和当前候选分裂模式相关联的速率失真成本,标记为rdcost(currcu,candidate_split_mode)。
在步骤612中,检查是否已经评估了所有可用的候选分裂模式。如果没有,则该过程转到步骤606。否则,该过程转到步骤613。
在步骤606中,选择来自候选分裂模式集合s的下一候选分裂模式,并且对于这样的下一候选分裂模式,从步骤607开始重复该过程。
在步骤613中,已经评估了所有可用的候选分裂模式。在已经评估的所有候选分裂模式中选择具有最低rd成本的候选分裂模式bestsplitmode,即,对其已经计算并存储了速率失真成本。
如果正在处理的当前子cu不是第一个,则下次为此位置调用该过程时(即,对于父cu的其他分裂模式),因果关系可能会发生改变。在这种情况下,模式不能以直接方式重新使用。
在步骤614中,检查当前子cu是否是第一子cu(i是否等于0)。
如果是,则在步骤615,针对所有块大小,清除当前位置的高速缓存,并且将与当前子cu相关联的参数cucache设置为0。
在步骤616中,例如根据图4中公开的编码处理,利用最佳分裂配置bestsplitmode对当前cu进行编码。
根据实施例,在此步骤期间,通过qt或bt深度对当前cu的所有表征由块的宽度或高度代替。例如,不是基于当前块的qt深度而是基于当前块的宽度来选择熵编码的上下文信息。
如图7所公开的,若干分裂路径可能导致其中因果邻域不会发生明显改变的子块。
如图7所示,可以从根据以下分裂路径分裂的父cu(由图7中的加粗虚线表示)获得子cu(图7中以散列填充):
-父cu的垂直分裂,得到左子cu和右子cu,接着是右子cu的水平分裂,得到上子cu(作为要评估的当前cu,在图7中由加粗边界表示)和下子cu,接着是要评估的当前cu的水平分裂,得到上子cu和下子cu,接着是下子cu的垂直分裂,得到左子cu(作为要评估的当前子cu)和右子cu,或者,
-父cu的四叉树分裂,得到4个子cu:左上子cu、右上子cu、左下子cu和右下子cu,要评估的当前cu为右上子cu,接着是要评估的当前cu的垂直分裂,得到左子cu和右子cu,接着是左子cu的水平分裂,得到上子cu和下子cu(作为要评估的当前子cu),或者,
-父cu的四叉树分裂,得到4个子cu:左上子cu、右上子cu、左下子cu和右下子cu,要评估的当前cu为右上子cu,接着是要评估的当前cu的水平分裂,得到上子cu和下子cu,接着是下子cu的垂直分裂,得到左子cu(作为要评估的当前子cu)和右子cu。
图7中的虚线区域示出了已经编码的区域,即可用于预测的区域。可以看出,根据达到要评估的目标子cu的不同分裂路径,可用于预测的区域不会发生明显的改变。
因此,根据本公开的另一实施例,尽管子cu的因果邻域已经发生了改变,但是,某些计算出的编码参数仍可以重新用于子cu。这样的实施例在实现编码时间的明显缩短的同时对压缩性能造成的影响有限。
根据本实施例,可以如之前在先前速率失真优化期间计算的那样(针对父cu的先前评估的分裂模式执行)完全重新使用为子cu估计的编码参数,或者也可以部分地重新使用为子cu估计的编码参数。部分地重新使用编码参数应该被理解为使用已经估计的编码参数来搜索新的编码参数。这可以通过如下方式来完成:将已经估计的编码参数中的一些或所有参数用作搜索评估中的子cu的最佳编码参数的起始点。换言之,从已经估计的编码参数中复制子cu的编码参数,但是这些已经估计的编码参数是用于搜索新的编码参数。或者,已经估计的编码参数的子集可以被复制并用作新的编码参数,例如,对于子cu的色度分量,可以从当前子cu重新使用已经估计的帧内预测方向,但是对于亮度分量,再次搜索了帧内预测方向。
本实施例能够减少计算,但是避免了执行完整的编码参数搜索。
根据本实施例,与子cu相关联的参数cucache可以取3个可能的值,例如,0和1可以具有与图6所公开的相同的含义,并且第三个值2表明:将已经估计的编码参数用作起始点或者用来在估计子cu的新编码参数时缩小编码参数的搜索范围。
在图8中示出了本实施例,其中以类似方式进行了附图标记与图6类似的步骤。
根据本实施例,在步骤800中,检查与评估中的当前子cu相关联的参数cucache(位置、宽度、高度)是否为0。
如果参数cucache不为0,则过程前进到步骤601,其中检查参数cucache是否为1。如果是,则过程前进到步骤605,以恢复当前子cu的先前估计的编码参数。否则,参数cucache具有等于2的值,因此,过程进行到步骤802。
在步骤802中,当参数cucache具有当前子cu的值2时,在当前子cu的no_split分裂模式中部分地重新使用已经估计的编码参数。
正在搜索当前子cu的标记为p*的最佳编码参数(预测模式、帧内预测角度、帧内平滑模式、运动矢量、变换索引......)。与完整速率失真优化搜索的不同之处在于:搜索空间缩小了并且搜索空间受到相同位置的相同大小的先前编码块的约束。可以重新使用任何数量的已经计算出的参数。例如,但不限于:
-仅帧内方向预测,
-帧内方向预测和pdpc索引(pdpc是指位置相关预测器组合,并且包括在每个样本的基础上在空间上预测样本,作为分别位于与预测样本相同的x-和y-图片坐标上的参考样本的加权组合),
-预测模式(帧内/帧间)、运动矢量和帧内预测方向,
-除了依赖于系数的模式之外,所有模式都被重新使用(例如,必须重新计算rsaf决策环,这是因为过滤索引采用了依赖于编码残差系数的比特隐藏)。
根据本实施例,如图6中所公开的那样探索分裂模式候选(hor、ver、qt_split)。
在步骤800中,当参数cucache为0时,过程进行到步骤602,其中
执行用于确定最佳编码参数的完整搜索。
在步骤801中,当当前子cu不是第一子cu(子cu的索引不为0)时,参数cu-cache被设置为值2,并且在步骤602中估计的编码参数存储在高速缓存存储器中。
根据本实施例,在过程结束时,更新高速缓冲存储器和参数cucache。
在步骤614中,检查当前子cu是否是第一子cu(子cu的索引为0)。
如果正在处理的当前子cu不是第一子cu(i!=0),则下次为此位置调用该过程时(即,当评估父cu的其他分裂模式时),因果关系可能会发生改变。因此,模式不能以直接方式重新使用。因此,在步骤803中,对于所有块大小,参数cucache针对当前位置从1变为2,并且如果其值为0或2,则不发生变化。
图9示出了导致子cu的相同分裂配置的不同分裂路径。在图9中,示出了填充有散列线的要评估的当前子cu。从图9中可以看出,即使当前子cu的父cu的不同分裂路径导致了当前子cu,也能找到当前子cu的相同分裂配置。如图9所示,当前子cu可以通过以下方式获得:
-当前cu的水平分裂,接着是上子cu的垂直分裂,或者,
-当前cu的垂直分裂,接着是左子cu的水平分裂。
在这两条分裂路径中,当前子cu被分成4个子cu,并且右上子cu已经进一步进行了水平分裂。
根据另一实施例,存储并重新使用为子cu在更高深度下估计的编码参数,其中包括子cu的分裂配置。
根据本实施例,每当找到大小与之前在当前位置处遇到的相同的块时,重新使用块的分裂配置和编码参数。在图10中示出了本实施例,其中以类似方式进行了附图标记与图6类似的步骤。
为简单起见,仅讨论了图10中公开的实施例与图6中公开的实施例之间的不同之处。
根据图10中公开的实施例,在步骤600之前,在过程开始时,执行步骤1001,即检查与评估中的当前cu相关联的参数cucache是否为1。这样,当参数cucache的值为1时,在步骤1005中,恢复已经为当前cu估计的编码参数(按照与图6中公开的步骤605类似的方式),并且绕过用于确定当前cu的编码参数和最佳分裂模式的速率失真优化。
此外,在步骤1001中,当与评估中的当前cu相关联的参数cucache不为1时,与图6类似地执行用于确定当前cu的编码参数和最佳分裂模式的速率失真优化过程,区别之处在于:在过程结束时执行步骤603和604,这样一来,如果当前cu是父cu的第一子cu(步骤603中i=0),则为当前cu估计的整个分裂配置和相关联的编码参数存储在高速缓冲存储器中。
根据本实施例的变型,为了提高压缩效率,应该移除当前视频压缩标准的一些规范和语法限制。例如,根据当前的qtbt工具,在二元分裂之后不允许进行四叉树分裂。此外,根据当前的qtbt工具,二叉树深度是有限的。不过,编码树探索的顺序会对存储在存储器高速缓存中的数据产生影响。根据此变型,最大二元分裂深度限制被移除或被设置为更大的值,如此便可以进一步分裂从二元分裂给出的子cu。此外,根据此变型,还移除了四叉树限制,包括相关联的qtsplit语法。根据此变型,可以用二叉树语法获得所有四叉树分裂,例如,通过上子cu和下子cu的水平分裂和随后的垂直分裂。
根据本公开的另一实施例,以最佳方式分配和使用高速缓冲存储器,这样使得每次适用时可以以最佳方式重新使用已经估计的编码参数。
根据本实施例,每当可以重新使用当前cu时,估计的编码参数存储在高速缓冲存储器中,并且不会覆盖稍后可能会重新使用的已经为当前cu估计的现有编码参数。
本实施例与上面公开的实施例是兼容的。
在图12中示出了本实施例,其中以类似方式进行了附图标记与图6类似的步骤。为简单起见,仅讨论图12中公开的实施例与图6中公开的实施例之间的不同之处。
根据图12中公开的实施例,在步骤1201中计算唯一标识符(图12中的hash(bcodedblkinctu))。这样的标识符允许识别当前cu的位置、宽度和高度以及当前cu的因果邻域。这种因果邻域指示先前是否已经确定了当前cu的相邻cu的编码参数。
因此,可以让当前子cu的若干编码参数集可用,这取决于用于到达当前子cu的分裂路径并且取决于当前子cu的因果邻域。根据本实施例,在估计当前子cu的编码参数时的因果邻域的状态与为当前子cu估计的编码参数一起进行存储。因此,当又遇到相同的子cu时(例如,当评估子cu的父cu的另一分裂模式时),该标识符允许检索已经为具有与当前因果邻域状态相同的因果邻域状态的子cu估计的编码参数(如果它存在于高速缓存存储器中)。
标识符对高速缓存存储器位置进行索引处理,在该位置处存储估计的编码参数并检索已经估计的编码参数。此标识符可以通过散列函数获得,比如,公知的murmur3、crc或md5sum。对散列函数的输入是计算出的最小cu的图。例如,对于ctu的大小为4×4像素的每个块,如果已经编码了4×4块,则将标志设置为1,如果没有,则将标志设置为0。这定义了要评估的当前cu的因果邻域的图。
在图11中示出了这样的图,图11示出了获得ctu的当前子cu(在图11中填充有散列线)和对应的因果邻域的不同分裂路径。
在图11中,ctu包括4×4像素的8×8块,由ctu内部的虚线示出。根据应用于ctu的以下分裂路径,获得当前子cu:
-(a)ctu的垂直分裂,接着是右cu的水平分裂,接着是上子cu的垂直分裂,接着是左子cu的水平分裂,评估中的当前子cu是得到的下子cu,
-(b)ctu的垂直分裂,接着是右cu的水平分裂,接着是上子cu的水平分裂,接着是下子cu的垂直分裂,评估中的当前子cu是得到的左子cu,
-(c)ctu的四叉树分裂,接着是右上cu的四叉树分裂,评估中的当前子cu是得到的左下子cu,
-(d)ctu的四叉树分裂,接着是右上cu的水平分裂,接着是下子cu的垂直分裂,评估中的当前子cu是得到的左子cu。
在每种情况(a)、(b)、(c)和(d)下,对于ctu的每个4x4块,值0或1指示4x4块是(值1)否(值0)已经进行了编码。当根据不同的分裂路径估计当前子cu的编码参数时,这些图指示出邻域的状态。
散列函数将该图转换为索引,在此是上面公开的标识符。然后将该索引用作高速缓冲存储器地址,以便在首次遇到该索引时存储计算的编码参数,或者在后续时间遇到该索引时检索编码参数。根据本实施例,每当当前子cu的因果邻域处于由散列函数在索引中编码的状态下时,就会遇到该索引。
因此,计算的标识符允许识别已导致当前子cu的分裂路径。根据如图6所公开那样进行评估的候选分裂模式的顺序,将按以下顺序遇到图11所示的分裂路径:(b)、(a)、(d)和(c)。根据此评估顺序,当评估(d)和(c)分裂路径时,可以部分地重新使用在分裂路径(b)中为当前子cu估计的编码参数。根据另一变型,当评估分裂路径(c)时,可以完全重新使用在分裂路径(d)中为当前子cu估计的编码参数。
根据本实施例的变型,为因果邻域的特定状态存储的数据可以包括诸如因果样本的重建样本值之类的信息和/或诸如帧内预测模式、采用的运动矢量预测器之类的编码模式。
根据本实施例的变型,因果邻域的状态还可以包括诸如分裂深度、子cu大小或子cu周围可用的像素的数量之类的信息。此变型能够区分出相同子cu的若干因果邻域,其中因果邻域的块已经进行了编码(因此值为1),但却具有不同的编码参数。
根据图12中公开的实施例,在步骤1201中,检查现在与当前子cu和当前子cu的因果邻域的状态相关联的参数cucache是否为1。如果不是,则过程前进到步骤602,其中按照与图6所公开的类似的方式估计当前子cu的编码参数。
在步骤1204中,根据在步骤1201中计算出的唯一标识符,将在步骤602中估计的编码参数存储在高速缓冲存储器中。根据本实施例,在存储为子cu估计的编码参数之前,不再检查该子cu是否是父cu的第一子cu。这样,所有编码参数和因果邻域的状态都存储在高速缓冲存储器中以用于评估中的cu的每个子cu,而不是像图6中公开的实施例那样(其中,编码参数仅存储用于第一子cu(图6中的步骤603))。
在步骤1201中,如果参数cucache的值是1,则过程前进到步骤1205,其中由于唯一标识符的缘故,从高速缓冲存储器中读取已经估计的编码参数。然后,按照与图6中公开的步骤605类似的方式,为当前子cu恢复编码参数。
此外,在过程结束时,不再为当前子cu清除高速缓冲存储器(没有图6中的步骤614,615)。
图13示出了根据本原理的实施例的用于编码视频的装置(30)的简化结构。这样的装置30配置为根据上面公开的任何实施例实现根据本原理的用于编码视频的方法。已经参考图4公开了编码器装置30的功能单元。下面公开的结构装置30可以配置为根据以上公开原理的任何一个实施例单独地或组合地实现这些功能单元中的每一个。
根据实施例,编码器装置30包括处理单元proc,该处理单元proc配备有例如处理器并由存储在存储器mem中的计算机程序pg驱动,并且还实现根据本原理的用于编码视频的方法。
在初始化时,计算机程序pg的代码指令例如被加载到ram(未示出)中,然后再由处理单元proc的处理器执行。处理单元proc的处理器根据计算机程序pg的指令实现上面已经描述的用于编码视频的方法的各步骤。
编码器装置30包括通信单元comout,以将编码的比特流str发送到数据网络。
编码器装置30还包括用于接收要编码的图片或视频的接口comin。
- 还没有人留言评论。精彩留言会获得点赞!