一种基于主备切换的MooseFS高可用方法及系统与流程
本发明涉及分布式存储技术领域,尤其涉及一种基于主备切换的MooseFS高可用方法及一种基于主备切换的MooseFS高可用系统。
背景技术:
MooseFS是一个开源的分布式文件系统,MooseFS主要采用主/从架构。其中,主表示元数据节点,称为 master;从表示数据节点,称为chunkserver。元数据节点是 MooseFS 的核心,只有一个,它管理整个文件系统的元数据及客户端对文件系统的访问。数据节点存储实际的文件数据,并在不同节点之间同步数据副本,一般一个系统有多个数据节点。所有客户端的读写请求都需要经过元数据节点。MooseFS 的主/从架构大大简化了设计。然而,如果唯一的元数据节点发生故障,整个系统就无法对外提供服务,客户端的所有读写请求将无法得到响应,这就是 MooseFS 的单点故障(Single Point of Failure)问题。MooseFS的高可用指的是当元数据节点发生故障时仍能对外提供服务。然而,MooseFS 只有一个元数据节点,没有备用节点。当该唯一的元数据节点发生故障时没有其他元数据节点能接替其工作,必然导致服务中断。服务不可用可能对企业带来巨大的损失。
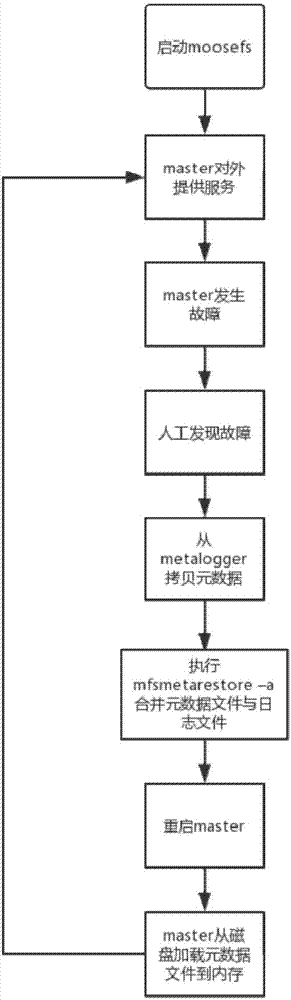
如图1所示,针对MooseFS元数据节点的单点故障问题,现有技术中通常是通过增加一个元数据备份节点,即metalogger。元数据节点master将元数据同步到元数据备份节点metalogger。当master出故障时,或者元数据丢失时,从metalogger所在节点拷贝元数据文件,然后重启元数据节点。图2所示为图1的结构在故障恢复时的工作过程,由图2可以看出,该方案中没有自动的故障发现机制,需要人工发现故障,故障发生后可能需要一段时间才能被发现,服务不可用的时间长。且该方案中的metalogger只是用来备份元数据,无法替代master(不具备响应客户端读写请求的功能)。故障恢复时需要重启master,master将元数据从本地加载到内存中需要耗费大量的时间(分钟级),导致长时间的服务不可用。该方案对人工运维的依赖性大,且故障恢复时间长。
因此,如何能够实现自动故障检测以及故障恢复以实现MooseFS的高可用成为本领域技术人员亟待解决的技术问题。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一,提供一种基于主备切换的MooseFS高可用方法及一种基于主备切换的MooseFS高可用系统,以解决现有技术中的问题。
作为本发明的第一个方面,提供一种基于主备切换的MooseFS高可用方法,其中,所述MooseFS包括元数据节点和多个数据节点,所述元数据节点包括第一元数据节点和第二元数据节点,所述基于主备切换的MooseFS高可用方法包括:
通过主备选举确定所述第一元数据节点为主元数据节点,所述第二元数据节点为备元数据节点;
所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据;
实时监测所述主元数据节点的工作状态,并判断所述主元数据节点的工作状态是否异常;
若所述主元数据节点的工作状态异常,则控制重新进行主备选举;
若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点。
优选地,所述基于主备切换的MooseFS高可用方法还包括:
若所述主元数据节点选举成功,则返回执行所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据。
优选地,所述若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点包括:
若所述备元数据节点选举成功,且原主元数据节点的工作状态恢复正常,则将所述备元数据节点作为新的主元数据节点,将原主元数据节点作为新的备元数据节点,返回执行所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据。
优选地,所述若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点包括:
若所述备元数据节点选举成功,且原主元数据节点的工作状态仍为异常,则将所述备元数据节点作为新的主元数据节点,与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块。
优选地,所述基于主备切换的MooseFS高可用方法还包括在若所述主元数据节点的工作状态异常,则控制重新进行主备选举的步骤之前进行的:
定时向所述主元数据节点发送心跳包,并接收反馈信息;
若当前时刻发送的心跳包间隔第一阈值时间未接收到反馈信息,则判定所述主元数据接待你的工作状态异常。
优选地,所述主备选举包括:
所述第一元数据节点和所述第二元数据节点同时竞争创建锁节点;
若所述第一元数据节点创建锁节点成功,则所述第一元数据节点选举成功,所述第一元数据节点被确定为主元数据节点;
反之,所述第二元数据节点选举成功,所述第二元数据节点被确定为主元数据节点。
优选地,所述主备选举还包括在若所述第一元数据节点创建锁节点成功,则所述第一元数据节点选举成功,所述第一元数据节点被确定为主元数据节点的步骤之后进行的:
所述第二元数据节点在所述锁节点上设置监听;
若所述主元数据节点的工作状态异常,则所述锁节点被删除,所述第二元数据节点接收到所述监听的通知后竞争创建新的锁节点;
若所述第二元数据节点创建新的锁节点成功,则所述第二元数据节点选举成功,并被确定为新的主元数据节点。
作为本发明的第二个方面,提供一种基于主备切换的MooseFS高可用系统,其中,所述基于主备切换的MooseFS高可用系统包括MooseFS、元数据同步模块、故障恢复控制模块和ZooKeeper集群,所述MooseFS包括元数据节点和多个数据节点,所述元数据节点包括第一元数据节点和第二元数据节点,所述元数据同步模块、所述故障恢复控制模块和所述数据节点均与所述第一元数据节点和所述第二元数据节点连接,所述ZooKeeper集群与所述故障恢复控制模块连接,所述第一元数据节点和所述第二元数据节点中的一个为主元数据节点,另一个为备元数据节点;
所述主元数据节点用于与所述数据节点进行数据传输,并用于实时将元数据同步到所述元数据同步模块;
所述备元数据节点用于定期从所述元数据同步模块获取元数据;
所述故障恢复控制模块用于实时监测所述主元数据节点的工作状态,并判断所述主元数据节点的工作状态是否异常,以及用于若所述主元数据节点的工作状态异常,则控制重新进行主备选举,以及用于根据选举结果控制进行主备切换;
所述ZooKeeper集群用于进行主备选举。
优选地,所述元数据同步模块包括由奇数个节点组成的集群,所述集群间通过运行paxos算法对所述主元数据节点的元数据进行同步。
优选地,所述故障恢复控制模块通过rpc对所述主元数据节点的工作状态和备元数据节点的工作状态进行监测。
本发明提供的基于主备切换的MooseFS高可用方法,通过使用两个元数据节点,且其中一个元数据节点作为主元数据节点,另外一个作为备元数据节点。当主元数据节点出故障时,能够自动发现故障,并将备元数据节点切换为主元数据节点,继续对外提供服务,实现了MooseFS的高可用,整个故障恢复过程无需人工干预,且故障恢复时间短。
附图说明
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
图1为现有技术中的MooseFS的架构图。
图2为现有技术中的故障恢复过程流程图。
图3为本发明提供的基于主备切换的MooseFS高可用方法的流程图。
图4为本发明提供的基于主备切换的MooseFS高可用系统的架构图。
图5为本发明提供的基于主备切换的MooseFS高可用方法的故障恢复过程流程图。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
作为本发明的第一个方面,提供一种基于主备切换的MooseFS高可用方法,其中,所述MooseFS包括元数据节点和多个数据节点,所述元数据节点包括第一元数据节点和第二元数据节点,如图3所示,所述基于主备切换的MooseFS高可用方法包括:
S110、通过主备选举确定所述第一元数据节点为主元数据节点,所述第二元数据节点为备元数据节点;
S120、所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据;
S130、实时监测所述主元数据节点的工作状态,并判断所述主元数据节点的工作状态是否异常;
S140、若所述主元数据节点的工作状态异常,则控制重新进行主备选举;
S150、若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点。
本发明提供的基于主备切换的MooseFS高可用方法,通过使用两个元数据节点,且其中一个元数据节点作为主元数据节点,另外一个作为备元数据节点。当主元数据节点出故障时,能够自动发现故障,并将备元数据节点切换为主元数据节点,继续对外提供服务,实现了MooseFS的高可用,整个故障恢复过程无需人工干预,且故障恢复时间短。
作为一种具体地实施方式,所述基于主备切换的MooseFS高可用方法还包括:
若所述主元数据节点选举成功,则返回执行所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据。
作为另一种具体地实施方式,所述若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点包括:
若所述备元数据节点选举成功,且原主元数据节点的工作状态恢复正常,则将所述备元数据节点作为新的主元数据节点,将原主元数据节点作为新的备元数据节点,返回执行所述主元数据节点与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块,所述备元数据节点定期从所述元数据同步模块获取元数据。
作为再一种具体地实施方式,所述若所述备元数据节点选举成功,则将所述备元数据节点作为新的主元数据节点包括:
若所述备元数据节点选举成功,且原主元数据节点的工作状态仍为异常,则将所述备元数据节点作为新的主元数据节点,与多个数据节点进行数据传输,并实时将元数据同步到所述元数据同步模块。
具体地,所述基于主备切换的MooseFS高可用方法还包括在若所述主元数据节点的工作状态异常,则控制重新进行主备选举的步骤之前进行的:
定时向所述主元数据节点发送心跳包,并接收反馈信息;
若当前时刻发送的心跳包间隔第一阈值时间未接收到反馈信息,则判定所述主元数据接待你的工作状态异常。
可以理解的是,通过定时向所述主元数据节点发送心跳包,然后根据是否在第一阈值时间内接收到该心跳包的反馈信息来判断所述主元数据节点是否处于正常的工作状态。
具体地,所述主备选举包括:
所述第一元数据节点和所述第二元数据节点同时竞争创建锁节点;
若所述第一元数据节点创建锁节点成功,则所述第一元数据节点选举成功,所述第一元数据节点被确定为主元数据节点;
反之,所述第二元数据节点选举成功,所述第二元数据节点被确定为主元数据节点。
进一步具体地,所述主备选举还包括在若所述第一元数据节点创建锁节点成功,则所述第一元数据节点选举成功,所述第一元数据节点被确定为主元数据节点的步骤之后进行的:
所述第二元数据节点在所述锁节点上设置监听;
若所述主元数据节点的工作状态异常,则所述锁节点被删除,所述第二元数据节点接收到所述监听的通知后竞争创建新的锁节点;
若所述第二元数据节点创建新的锁节点成功,则所述第二元数据节点选举成功,并被确定为新的主元数据节点。
作为本发明的第二个方面,提供一种基于主备切换的MooseFS高可用系统,其中,如图4所示,所述基于主备切换的MooseFS高可用系统包括MooseFS、元数据同步模块、故障恢复控制模块和ZooKeeper集群,所述MooseFS包括元数据节点和多个数据节点,所述元数据节点包括第一元数据节点和第二元数据节点,所述元数据同步模块、所述故障恢复控制模块和所述数据节点均与所述第一元数据节点和所述第二元数据节点连接,所述ZooKeeper集群与所述故障恢复控制模块连接,所述第一元数据节点和所述第二元数据节点中的一个为主元数据节点,另一个为备元数据节点;
所述主元数据节点用于与所述数据节点进行数据传输,并用于实时将元数据同步到所述元数据同步模块;
所述备元数据节点用于定期从所述元数据同步模块获取元数据;
所述故障恢复控制模块用于实时监测所述主元数据节点的工作状态,并判断所述主元数据节点的工作状态是否异常,以及用于若所述主元数据节点的工作状态异常,则控制重新进行主备选举,以及用于根据选举结果控制进行主备切换;
所述ZooKeeper集群用于进行主备选举。
本发明提供的基于主备切换的MooseFS高可用系统,通过使用两个元数据节点,且其中一个元数据节点作为主元数据节点,另外一个作为备元数据节点。当主元数据节点出故障时,能够自动发现故障,并将备元数据节点切换为主元数据节点,继续对外提供服务,实现了MooseFS的高可用,整个故障恢复过程无需人工干预,且故障恢复时间短。
具体地,所述元数据同步模块包括由奇数个节点组成的集群,所述集群间通过运行paxos算法对所述主元数据节点的元数据进行同步。
具体地,所述故障恢复控制模块通过rpc对所述主元数据节点的工作状态和备元数据节点的工作状态进行监测。
为了更加清楚的理解上述基于主备切换的MooseFS高可用方法以及基于主备切换的MooseFS高可用系统,下面结合图4和图5进行详细描述。
如图4所示,本发明提供的基于主备切换的MooseFS高可用系统主要包括第一元数据节点, 第二元数据节点、多个数据节点,元数据同步模块,故障恢复控制模块,ZooKeeper集群,其中第一元数据节点作为主master,第二元数据节点作为备master。只有主master对外提供服务。
主master将元数据同步到元数据同步模块,备master定期从元数据同步模块获取元数据并加载到内存,保持元数据与主master一致。
故障恢复控制模块监控两个master的健康状态,并跟ZooKeeper交互完成主备选举,最后进行主备切换。本发明中的主备master具有相同的功能,根据状态的不同执行不同的操作(若为主master,则响应客户端的读写请求,且将元数据同步到元数据同步模块;若为备master,则从元数据同步模块拉取元数据更新到内存中)。
元数据同步模块由奇数个节点(一般为3个或5个)组成一个集群。集群间运行paxos算法。主master需要将元数据写入元数据同步模块,只有一半以上的元数据同步节点写入成功,该操作才完成。通过使用paxos算法,在保证数据一致性的同时,极大提高了系统的可用性。备master定期从元数据同步模块更新元数据,使自身元数据跟主master保持一致,并将元数据加载到内存中,这样当备master切换为主master后能够直接对外提供服务,无需从磁盘加载元数据到内存,故障恢复时间在秒级。通过元数据同步模块,在该模块中运行paxos算法,相比于直接将元数据从主master同步到备master的方式,该方式大大提高了系统的可用性(因为允许一半以下的元数据同步模块节点宕机),也提高了元数据的安全性。
故障恢复控制模块主要完成两个功能,一是监控master的健康状况。通过rpc来检测master的状况。二是与ZooKeeper建立连接,进行主备选举,并根据选举结果切换master的状态。通过故障恢复控制模块,实现故障自动发现及恢复,避免了人工介入运维。
ZooKeeper集群用于主备选举,通过在ZooKeeper上创建锁节点,创建成功的为主master,创建失败的为备master。利用ZooKeeper的写一致性,保证同一时刻只有一个master能够成功创建锁节点,即同一时刻只有一个主master,避免同时存在两个主master导致的数据不一致。此外,利用ZooKeeper订阅的功能,备master在锁节点上注册一个watcher监听,当主master出故障,该锁节点会被删除,备master收到NodeDeleted通知后立即竞争创建锁节点,若创建成功,则切换为主master。
需要说明的是,所述ZooKeeper集群与所述主master和备master之间均存在数据通信连接,当所述ZooKeeper集群与主master或备master之间的连接中断时间超过第二阈值时间时,所述ZooKeeper集群主动删除主master/备master对应的锁节点。
通过引入ZooKeeper,利用其写一致性进行主备选举,保证系统中任意时刻只有一个主master,防止“脑裂”(即同时存在两个主master)的情况,保证了元数据的一致性。同时利用ZooKeeper的订阅功能,在锁节点被删除时能迅速通知,提高了主备选举的效率。
如图5所示,为故障恢复的过程。在主master发生故障时,故障恢复控制模块能够快速自动地发现故障,并删除ZooKeeper上的锁节点,备master收到锁节点删除的通知,迅速通过ZooKeeper重新进行主备选举,成为新的主master,对外提供服务。整个故障恢复过程自动化,无需人工干预。
由于备master从元数据同步模块同步元数据时直接加载到内存中,因此当其切换为主master后无需从本地加载元数据,可以直接对外提供服务,故障恢复时间短。
通过本发明提供的基于主备切换的MooseFS高可用系统,使得master发生故障时能够快速自动地进行主备切换,无需人工干预,且故障恢复时间在秒级,实现了MooseFS的高可用。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!