基于负载映射与随机森林的非加密流量识别方法与流程
本发明涉及流量分类与识别技术领域,尤其涉及一种非加密移动应用流量识别方法。
背景技术
网络流量识别在网络管理中处于十分重要的位置,是网络监管、带宽计费、qos等多方面的基础。近几年,移动设备的数量呈现爆炸式增长,越来越深入到人们的生活中。在这些设备上,人们下载安装应用程序,这些应用程序产生的流量称之为移动应用流量。这些流量增长得十分迅速,并且包含了网络环境中的重要信息,因此对这些流量进行分析变得十分有意义,而流量识别作为流量分析的基础,吸引了学术界的许多目光。
移动应用程序大多使用http/https等协议,目前流量识别的方式主要有3种:基于端口的识别方法、基于机器学习的识别方法、基于数据包负载的识别方法(dpi)。
基于端口的识别方法是将一些熟知端口作为识别规则,如80端口对应http协议,53号端口对应dns协议。但由于大多数移动应用都采用http/https协议,流量端口基本固定为80或443,基于端口识别的方案不能很好地识别移动应用流量。
基于机器学习的识别方法通常是先按照五元组的方式提取出数据流,所谓数据流就是指在一定时间间隔内报文的集合,这些报文有着相同的源ip、目的ip、源端口、目的端口和协议。而后可以通过提取流特征,如数据包到达间隔、数据包大小等,完成数据包到特征空间的映射,进而可以建立如贝叶斯、svm、决策树等分类器以进行分类。或是采用k-means、dbscan等无监督方法进行聚类,预测类别。但同样是由于移动应用大都采用http/https协议,流特征会较为相近,常用的流特征将近250个,如何选择有效的特征成为一个复杂的问题。
基于dpi的识别方法依赖于报文负载内容,将位置固定或不固定的关键字符串作为应用签名。通过字符串匹配进行流量识别。如何找到具有代表性的匹配模式,在很大程度上决定了这种分类方法的识别准确度。不同学者提出了不同的方法来对寻找特征模式,但过程相对较为复杂。
本发明基于dpi的识别方法,仅针对使用http协议的应用流量进行识别。依赖于http负载报文,但不采用提取特征字符串的方式,而是使用自然语言处理领域中的方法,将负载映射为向量,建立随机森林分类器进行应用类别预测。
技术实现要素:
本发明提供一种非加密移动应用流量识别方法,不必提取特征字符串,而是将负载映射为向量,具有较为准确的识别率。
本发明提供一种基于随机森林的非加密移动应用流量识别方法。http流量负载为明文,可以将其视为文本进行处理,引入自然语言处理中的向量空间模型,实现负载到向量的映射。
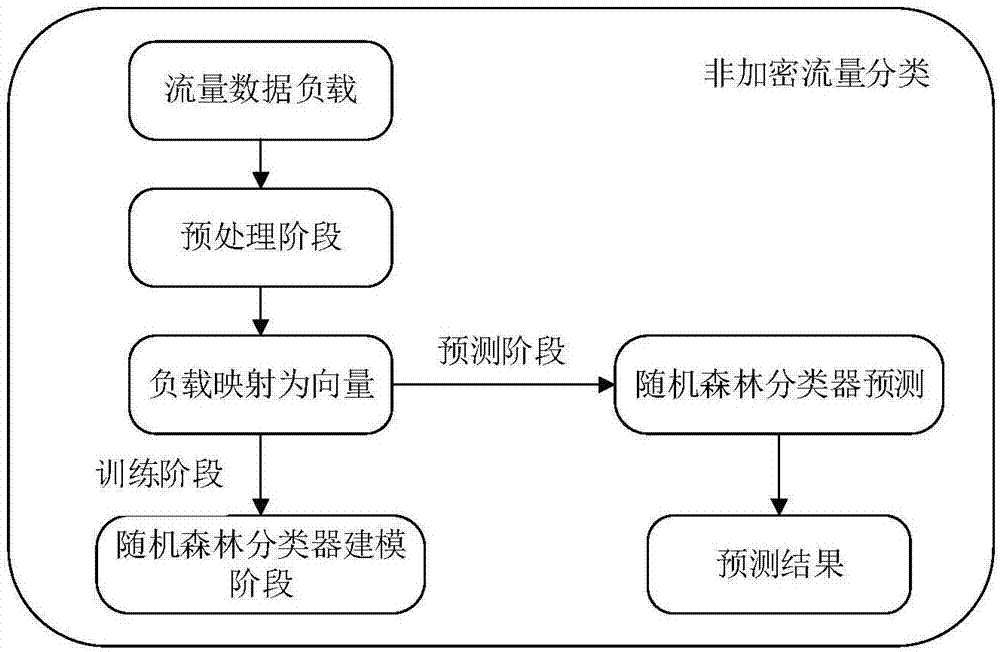
图1展示了本方法的框架图,在预处理阶段,截取http报文负载中“\r\n\r\n”之前的内容,该内容包含了http的请求行与请求报文,拥有足够的信息量可以用于分类器的建立。
对每条负载进行分词处理,可以简单地使用空格、斜杠等分隔符进行分割,将长度过短的单词删除。将单词存入单词集合w={w1,w2,...,wn},w也可称之为词袋(bagofwords)。
本文所提到的流量分类为二分类问题,即预测的结果为属于某个应用或不属于某个应用,故在随机森林分类器建模阶段,建立二分类模型。计算词袋中每个单词的tfidf值,所谓tfidf值,是自然语言处理领域用来衡量单词重要度的指标之一。计算公式为:
但若使用全部单词,计算量较大且包含噪声。因此,将每个单词对应的所有tfidf值进行求和,对和值进行排序,并设定比率ratio,使用排名在前ratio*|w|的单词构建词袋w′。顺序扫描一条报文中的单词,若单词存在于词袋w′,可使用单词对应的tfidf值代替该单词;若不存在于w′中,则忽略该单词。至此,将报文负载转化为tfidf向量,建立了向量空间模型。
使用训练样本向量与对应标签建立随机森林分类器。方法包括:对训练向量集合,随机抽样生成数据子集d1、d2、......、dn,对于某数据子集di,采用的是tfidf特征,相当于连续特征,利用二分法对连续特征进行处理,假设单词wi,j的tfidf取值有k个,将这k个取值从小到大排列,记为{a1,a2,...,ak},基于划分点at可将di分为两个子集
在构建随机森林的第i棵树ti时,若输入的所有训练样本都属于同一类ck,则ti为单节点树,并将类ck作为该节点的类标记;否则,对于每一个特征a,对其可能取的每一个值a,计算基尼指数,计算公式定义为
在分类阶段,对待识别的数据包负载进行预处理,即截取”\r\n\r\n”之前的部分,利用分隔符进行分词,并删除长度较短的单词,计算每个单词的tfidf值。顺序扫描待分类报文中的单词,若单词存在于词袋w',可使用单词对应的tfidf值代替该单词;若不存在于w′中,则忽略该单词。建立好向量空间模型,将tfidf向量输入到随机森林分类器进行预测。对于每条待识别的报文x,都会输出该样本属于目标应用的概率p(y=1|x),以及样本不属于目标应用的概率p(y=0|x),选择概率值大的作为最终的标签。
附图说明
图1是非加密移动应用流量识别方法框架图
图2是选择不同关键字比率ratio与准确率的关系
图3是选择不同树的棵数与准确率的关系
图4是不同移动应用识别的准确率、召回率、f1值
具体实施方式
为了更清晰直观的表达本发明的方法思路,下面对算法的细节进行详细说明:
1.确定参数
算法需要确定的参数包括:
1)关键字的比率ratio
2)树的棵数estimators
2.预处理阶段
读取数据包负载,截取“\r\n\r\n”之前的部分。使用空格、斜杠等分隔符对等分隔符进行分割,将长度小于2的单词删除,将其余单词存入单词集合w={w1,w2,...,wn}。
3.建立随机森林分类器模型
计算每个单词的tfidf值,将对应单词的tfidf值进行求和累加,并对和值进行排序,设定ratio的数值,选取排名在前ratio*|w|的单词构建词袋w′。顺序扫描一条报文中的单词,若单词存在于词袋w′,可使用单词对应的tfidf值代替该单词;若不存在于w′中,则忽略该单词。多次设定ratio的数值,并比较训练时移动应用的分类准确率,最终选定一个ratio值用于最终的分类。同样,多次设定树的棵数estimators,并比较训练时移动应用的分类准确率,最终选定一个estimators值用于最终的分类。
4.随机森林分类器预测
待识别的数据包负载截取”\r\n\r\n”之前的部分,使用空格、斜杠等分隔符对等分隔符进行分割,将长度小于2的单词删除,利用词袋将负载映射到向量空间。输入到训练好的随机森林分类器模型中,进行预测。
实施例
本发明采用现实数据的方式实施。
本发明选择10组真实的网络环境下采集的网络流量数据集作为实施例中的数据源。这10组数据集分别对应了当前中国最为流行的10种应用,分别是:大众点评、爱奇艺、今日头条、美团、优酷视频、优酷视频、手机淘宝、腾讯新闻、新浪微博、微信、酷我音乐。
定义分类准确率为正确分类的样本数与所有样本数的比值。
图2显示了在不同ratio值下,在训练随机森林分类器时分类准确率的变化。ratio<0.5时,准确率大致呈现向上增长的趋势,优酷视频的准确率在ratio<0.5时,变化幅度不大;腾讯新闻与手机淘宝的曲线在ratio<0.5时,呈现出先下降后上升的趋势,大致在ratio=0.5时准确率最高,然后准确率又开始下降。选择ratio=0.5用于最后的应用识别的准确率测试。
图3显示了在不同estimators值下准确率的变化,estimators<40时,腾讯新闻与手机淘宝的准确率大致呈现向上增长的趋势,优酷视频的准确率在estimators<40时,变化幅度不大;大致在estimators<40时准确率最高,然后准确率又开始下降。选择estimators=40用于最后的应用识别的准确率测试。
准确率、召回率、f1值常见于衡量分类器性能,计算公式为:
其中tp表示正样本预测为正类的数量,fp表示正样本预测为负类的数量,fn表示负样本预测为正类的数量。
图4显示了在ratio=0.5,estimators=40时,对不同移动应用识别的准确率(precision)、召回率(recall)、f1值(f1-score)。分类准确率最高可达99%以上,平均准确率为98.2%,平均召回率为98.27%,准确率与召回率相差不大。验证了本发明对于非加密的移动应用识别有良好的识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!