基于机器学习的室内定位方法与流程
本发明涉及室内无线定位领域,特别是涉及一种基于机器学习的室内定位方法。
背景技术
一种常见的室内定位方法是基于测距的定位算法:通过测量目标点与各个已知基站间的距离,从而计算出目标点的坐标。其中的测距方案包括:基于到达时间(toa,timeofarrival),基于接收信号强度(rss,receivedsignalstrength),基于到达时间差(tdoa,timedifferenceofarrival)以及利用信道脉冲响应的信息(例如平均超额延迟,最大超额延迟,rms延迟扩展,上升时间和峰度等)来估算距离。到达时间与接收信号强度作为最常用的测距手段,均存在着各自的缺陷:基于到达时间的测距需要基站与用户之间的时钟同步,但当用户数巨大时,这种同步变得相当复杂;不同设备获取的信号强度存在差异,同时由于环境的影响,基于接收信号强度的测距精度并不高。因此,仅需要基站间相互同步的到达时间差测量成为一个更好的选择。
基于信号到达时间差的测距过程:用户在某一时刻发出的信号,到达不同基站的时刻是不同的,根据这个时间差,可以计算出用户到基站间的距离差。chan-算法可以将距离差映射为目标用户的坐标,在视距(los,lineofsight)环境下,它通过两次的加权的线性ls估计,能够使坐标的估计值达到克拉美罗下限(crlb,cramer-raobound)。但在非视距(nlos,notlineofsight)环境下,此算法计算出的坐标具有较大的偏差。
第一类方法可以通过分析连续距离估计值之间的变化来实现,前提是假设非视距情况下测量值通常具有比视距情况下的测量值更大的方差。然而,因为这种方法需要大量的测量,将会导致非常高的延迟。第二类方法认为非视距情况下的测距误差的分布取决于散射体的空间分布,可以通过对这些散射体建模来实现减轻。然而,由于环境的复杂几何形状以及可能存在的动态障碍,这种方法通常是不可行的。另外一类机器学习方法基于支持向量机(svm,supportvectormachine)的方法,利用信道冲击响应的信息,来对单个的非视距数据进行辨别以及误差减轻。但大量的信道冲激响应的信息获取存在问题,因为成本的限制,大部分的室内定位装置都无法满足这种要求。诸如此类的方法还有很多,但这些方法的实现受到了极大制约,因此在室内定位中非视距情况依然是一个严峻的问题。
技术实现要素:
发明目的:本发明的目的是提供一种能够解决现有技术中存在的缺陷的基于机器学习的室内定位方法。
技术方案:为达到此目的,本发明采用以下技术方案:
本发明所述的基于机器学习的室内定位方法,包括以下步骤:
s1:在室内定位区域布置多个坐标已知的基站;
s2:将室内空间分为多个小区域,对于每一个小区域,取其中心点测得其视距以及非视距环境下的基于到达时间差的测距值;
s3:在步骤s2得到的测距值的实测数据的基础上,利用计算机模拟出视距以及非视距环境下的基于到达时间差的测距值;
s4:构建机器学习分类器网络,混合使用步骤s2得到的测距值的实测数据与步骤s3得到的测距值的模拟数据作为训练样本,训练出基于测距值的分类模型;
s5:在目标点进行定位时,首先将基于到达时间差的测距值输入到训练好的分类模型中,分辨出视距与非视距数据,并舍弃非视距数据;
s6:使用一种基于到达时间差测距的定位算法,在视距情况下此算法能得到高精度的坐标估算值,将s5辨别出的视距数据及其对应的基站坐标作为此算法的输入,得到目标点的三维坐标估算值。
进一步,所述步骤s1中的基站个数大于等于4,且任意的4个基站不处于同一个平面。
进一步,所述步骤s2中的各个小区域之间均不重叠,且小区域的大小规格通过定位精度确定。
进一步,所述步骤s3的详细过程为:采集大量的实验数据,包含视距以及非视距环境下的基于到达时间差的测距值及其对应的真实距离值,进行误差统计建模。
进一步,所述步骤s4中的机器学习分类网络采用机器学习分类器,机器学习分类器采用支持向量机分类器,支持向量机在特征空间中根据不同类别数据分布情况构建一个超平面,使不同类别之间存在最大间隔。
进一步,所述机器学习分类器的输入为一组基站的基于到达时间差的测距值,通过分析测距值之间的相关性,将这组测距值分类成两种情况:全部为视距情况下的数据、包含至少一个非视距情况下的数据。
进一步,所述步骤s1中的基站个数大于等于4,步骤s4中的机器学习分类器的总数为
进一步,所述步骤s5中分辨视距与非视距数据的过程如下:在得到目标点的全部基于到达时间差的测距值之后,首先判断个数为n的基站组合是否包含非视距数据,n≥4,如果有,则继续判断个数为n-1的基站组合是否包含非视距数据;如此逐层的使用分类器,直到找出测距值全部为视距情况下获得的基站组合;如果所有的个数为4的基站组合中仍包含非视距的数据,那么使用全部的n个基站的测距数据作为步骤s6中坐标算法的输入。
有益效果:本发明公开了一种基于机器学习的室内定位方法,与现有技术相比,具有如下有益效果:
1)通过设置大量的基站,确保了系统能够获取足够多的视距的数据。对于非视距的数据的识别以及丢弃,能够极大的提高定位算法的精度。
2)使用非参数描述的机器学习算法,通过经验数据来进行学习而不确定任何具体模型,所建立的模型能够应对产生误差的各类场景。训练样本包含了各个位置下的各类情况,使得当环境发生改变时,这些模型依然能够适应这些变化并发挥作用。
3)相较于基于机器学习利用信道信息来对非视距情况进行辨别,本方案利用机器学习的方法,挖掘测距值之间的相互关系,来实现对非视距情况的辨别,降低了设备成本,因为信道信息的获取需要频谱仪等辅助设备,这对于广泛的大量布置的室内定位装置是相当昂贵的要求。
4)基于到达时间差的定位,仅需要基站之间的相互同步。当用户数量巨大时,这会带来两类好处:基站间的同步过程不受用户数的影响;相较于其他测距方案仅需要用户向基站发射一次定位信号,用户与基站之间的通信更加高效,。
5)模拟数据可以大量产生,使得在实测数据训练样本较少的情况下依旧能够达到较好的训练效果。
附图说明
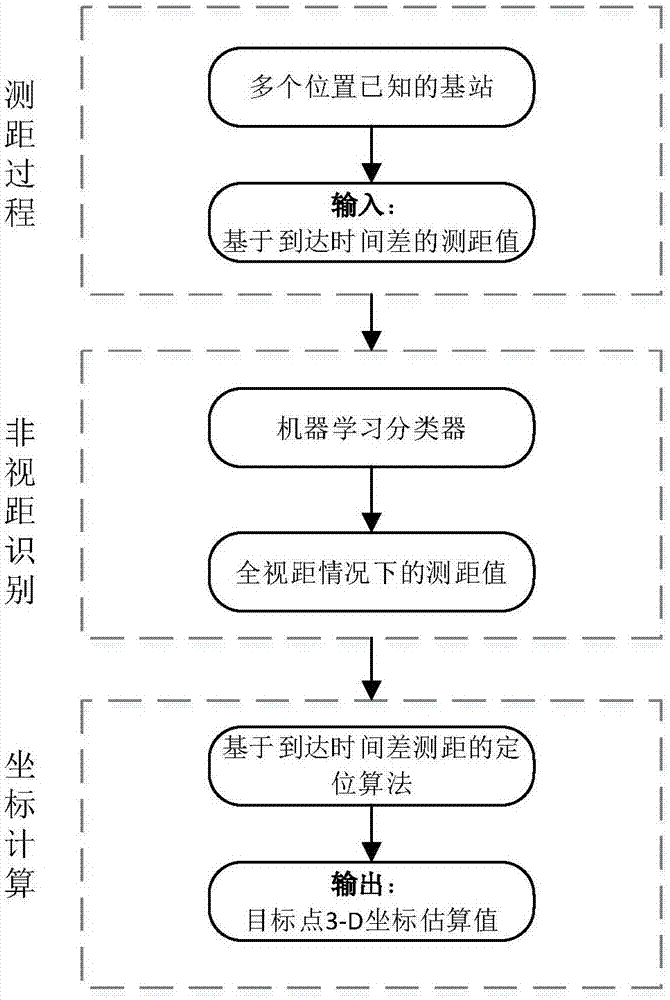
图1为本发明具体实施方式中基于机器学习的室内定位流程图;
图2为本发明具体实施方式中基于实测数据与模拟数据结合的支持向量机训练流程图;
图3为本发明具体实施方式中6基站基于测距值的非视距情况识别过程图。
具体实施方式
下面结合具体实施方式对本发明的技术方案作进一步的介绍。
本具体实施方式公开了一种基于机器学习的室内定位方法,如图1所示,包括以下步骤:
s1:在室内定位区域布置多个坐标已知的基站;基站个数大于等于4,且任意的4个基站不处于同一个平面;
s2:将室内空间分为多个小区域,对于每一个小区域,取其中心点测得其视距以及非视距环境下的基于到达时间差的测距值;各个小区域之间均不重叠,且小区域的大小规格通过定位精度确定;
s3:在步骤s2得到的测距值的实测数据的基础上,利用计算机模拟出视距以及非视距环境下的基于到达时间差的测距值;详细过程为:采集大量的实验数据,包含视距以及非视距环境下的基于到达时间差的测距值及其对应的真实距离值,进行误差统计建模;
s4:构建机器学习分类器网络,如图2所示,混合使用步骤s2得到的测距值的实测数据与步骤s3得到的测距值的模拟数据作为训练样本,训练出基于测距值的分类模型;
s5:在目标点进行定位时,首先将基于到达时间差的测距值输入到训练好的分类模型中,分辨出视距与非视距数据,并舍弃非视距数据,将视距数据及其对应的基站坐标作为基于到达时间差测距的定位算法的输入,得到目标点的三维坐标估算值,如图3所示。
步骤s4中的机器学习分类网络采用机器学习分类器,机器学习分类器的总数为
步骤s5中分辨视距与非视距数据的过程如下:在得到目标点的全部基于到达时间差的测距值之后,首先判断个数为n的基站组合是否包含非视距数据,n≥4,如果有,则继续判断个数为n-1的基站组合是否包含非视距数据;如此逐层的使用分类器,直到找出测距值全部为视距情况下获得的基站组合;如果所有的个数为4的基站组合中仍包含非视距的数据,那么使用全部的n个基站的测距数据作为坐标算法的输入。
视距情况下的基于信号到达时间差测距的算法:
s11:基站的总数记为m,目标点坐标(x,y,z),第i个基站的坐标为(xi,yi,zi),
距离的测量值存在误差:
其中,di,j为基站i与基站j到目标点的真实距离的差值,
其中:
将上面两式分别代入到di2-d12中,可以得到:
di,12+2di,1d1=-2xi,1x-2yi,1y-2zi,1z+ki-k1(5)
其中:
xi,1=xi-x1
yi,1=yi-y1
zi,1=zi-z1
s12:当基站的个数为4时,即m=4:
有如下方程组:
求解方法:
(1)以测量值
(2)此时方程中还剩下四个未知量x,y,z,d1,联立方程的前两项,使用d1表示出x,y,z。
(3)将(2)中的结果代入到第四个个方程中,得到只含有d1的方程,从而求解出d1。
s13:当基站的个数大于4时:
s13.1:定义:
θa=[θt,d1]t,θ=[x,y,z]t
定义误差向量
其中:
在los下,
其中:b=diag{d2,d3,...,dm},q是噪声矢量n的协方差矩阵,c为光速。
此时,使用最大似然的方法可以估计出θa,即:
由于
在(8)中,ψ是未知的,因为b包含了目标点到基站的真实值。因此需要更进一步的近似。当目标点远离基站阵列时,每个di都可以近似为d0,此时b=d0i。i是大小为m-1单位矩阵。由于ψ的缩放对于结果没有影响,此时(8a)的近似的表达式为:
当目标点离基站阵列较近时,可以首先使用(9b)获得一个初步的结果去估计b。最后的结果通过计算(9a)获得。迭代一次就足够获得精确结果。
其中:
在这里,可以用ga来近似的替代
s13.2:得到(9a)和(9b)的前提之一是我们假设x,y,z,d1是三个独立的分量。事实上,x,y,z,d1满足如下的关系式:
d12=(x-x1)2+(y-y1)2+(z-z1)2
因此,可以在(9a)和(9b)的基础上,利用x,y,z,d1之间的相互关联性,得到更精确的坐标估计。
另外一组误差矢量:
其中:
其中b'=diag{x-x1,y-y1,z-z1,d1}。
因为
ψ'是未知的,因为b'中包含着真实值。此时,可以使用估计值
最终坐标的估计值为:
或
s22:支持向量机分类的过程:
使用预先准备的训练集来训练出支持向量机分类器。xk代表输入,由基站间的测距差值
y(x)=wtφ(x)+b(16)
其中,φ(x)代表固定的特征空间转换,w与b是分类器位置的参数,需要通过训练去得到。使用sign函数将y(x)从rn映射到{+1,-1}上:
l(x)=sign(y(x))(17)
训练集用
其中,ξk代表松弛变量,c代表松弛变量与最大间隔之间的权衡。使用smo算法可以求解此优化问题,得到具体的支持向量机模型。
- 还没有人留言评论。精彩留言会获得点赞!