一种多索引的网络流量数据索引方法、设备及存储介质与流程
本发明涉及网络流量数据分析技术领域,尤其是一种多索引的网络流量数据索引方法、设备及存储介质。
背景技术
随着网络技术的发展和各种网络业务应用的普及,网络已经成为人们日常工作生活中不可或缺的信息承载工具。通过对网络流量数据的分析,能够帮助网络技术人员更好的了解网络运行情况、网络流量内容,可以更好的维护、优化网络,提升通信性能和安全性,提高解决问题的效率。网络流量数据的爆炸性增长,为网络技术人员分析数据带来了极大的挑战,现有主流网络流量数据分析工具存在很多缺点,例如:加载文件速度慢、硬件资源占用高、每次查询均需要对整个文件进行搜索,响应速度慢、每次仅能分析一个文件,无法多文件同时分析等。
技术实现要素:
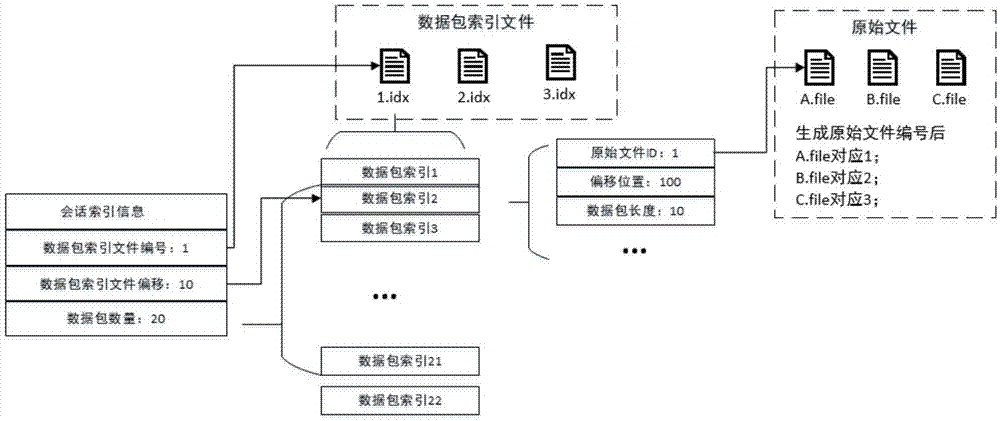
本发明所要解决的技术问题是:针对上述存在的问题,提供一种多索引的网络流量数据索引方法、设备及存储介质。能快速生成两级索引——会话索引信息和数据包索引信息。首先,对网络流量数据进行解析,并提取数据包索引信息;然后,进行会话重组,会话重组意义在于,能将大量的数据包冗余信息合并,减少会话索引体积;最后,对所有会话建立会话索引信息。会话索引由会话公共头和数据包索引信息构成,可以通过会话索引快速定位到会话的所有数据包索引信息。数据包索引由数据包长度、在文件中偏移位置以及文件编号等信息构成,可以通过数据包索引中的文件编号、偏移位置、数据包长度,准确无误的读取到原始网络流量数据信息。
本发明采用的技术方案如下:
一种多索引的网络流量数据索引方法包括:
对待处理的网络流量数据包所在的文件统一进行第一级文件编号;
解析所述网络流量数据包,获取网络流量数据包索引信息;其中数据包索引信息包括网络流量数据包所在文件的编号、网络流量数据包在文件中的文件偏移位置以及网络流量数据包信息;
对网络流量数据包进行会话重组,并进行结束条件设置;
基于所述网络流量数据包信息,提取并生成会话索引信息,然后通过该会话的会话索引信息与该会话对应的网络流量数据包索引信息进行关联;
对于结束的会话,将当前会话关联的数据包索引信息写入文件,为该文件设置第二级文件编号,同时设置该会话索引中的数据包索引文件编号的编号值和数据包索引偏移位置的偏移位置值,然后将会话索引写出到上述文件。
进一步的,当会话未结束,则累计会话数据包数量。
进一步的,所述会话索引信息至少包括网络流量数据包信息、设置初始值的数据包索引文件编号、设置初始值的数据包索引偏移位置以及会话信息以及七元组信息。
进一步的,当未建立某一网络流量数据包对应的会话索引信息时,则重新基于所述网络流量数据包信息,提取并生成会话索引信息。
进一步的,通过会话索引中的数据包索引文件编号以及数据包索引偏移位置找到对应的数据包索引文件信息。
进一步的,通过数据包索引文件信息中的网络流量数据包所在文件的编号、网络流量数据包在文件中的文件偏移位置找到该网络流量数据包。
进一步的,对网络流量数据包进行会话重组,并进行结束条件设置指的是判断网络流量数据包的传输层协议标志位或会话超时为依据。
一种存储介质,其中存储有多条指令,所述指令适用于由处理器加载并执行所述的多索引的网络流量数据索引方法的步骤。
一种多索引的网络流量数据索引设备包括处理器,适于实现各指令;以及存储设备,适于存储多条指令,所述指令适于由处理器加载并执行上述权利要求1至7任意一项所述的多索引的网络流量数据索引方法。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1本发明的结构图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
本说明书中公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
本发明相关说明:
1、网络流量数据包信息包括数据包长度、负载长度、数据包时间。
方案1:一种多索引的网络流量数据索引方法包括:
步骤1:对待处理的网络流量数据包所在的文件统一进行第一级文件编号;
步骤2:解析所述网络流量数据包(例如图1中的原始文件),获取网络流量数据包索引信息;其中数据包索引信息包括第一级所在文件编号(即网络流量数据包所在文件的编号,例如图1中的数据包索引中的原始文件id)、第一级偏移位置(网络流量数据包在文件中的文件偏移位置,例如图1中的数据包索引中的偏移位置)以及网络流量数据包信息(例如图1中的数据包索引中的数据包长度等);
步骤3:对网络流量数据包进行会话重组,并进行结束条件设置;
例如:对网络流量数据包进行会话重组,并进行结束条件设置指的是判断网络流量数据包的传输层协议标志位或会话超时为依据;
1)tcp协议,则使用五元组进行会话重组,并以fin标志、rst标志或超时作为会话结束条件;
2)如果是udp协议,同样使用五元组进行会话重组,并仅以超时作为会话结束条件;
其中,五元组信息包括源ip地址、目的ip地址、源端口、目的端口、传输层协议),会话超时指的是在相同端点之间一定时间范围内无任何数据通信,端点指的是ip地址相同且端口相同,忽略通信方向。
步骤4:基于所述网络流量数据包信息,提取并生成会话索引信息,然后通过该会话的会话索引信息与该会话对应的网络流量数据包索引信息进行关联;
其中,所述会话索引信息至少包括网络流量数据包信息、设置初始值的第二级编号(数据包索引文件编号,例如图1中会话索引信息中数据包索引文件编号)、设置初始值的第二级偏移位置(数据包索引偏移位置,例如图1中会话索引信息中的数据包索引偏移位置)、会话信息以及七元组信息。
会话信息包括会话开始时间、会话结束时间以及会话数据包数量,会话开始时间指的是第一个网络流量数据包获取时间、会话结束时间指的是最后一个网络流量数据包获取时间、会话数据包数量指的是网络流量数据包的数量;
七元组信息包括源ip、目的ip、源端口、目的端口、源mac地址、目的mac地址、传输层协议。
步骤5:对于结束的会话,将当前会话关联的数据包索引信息写入文件,为该文件设置第二级文件编号,同时设置该会话索引中的第二级编号(第二级编号指的是数据包索引文件编号)的编号值和第二级偏移位置(第二级偏移位置指的是数据包索引偏移位置)的偏移位置值,然后将会话索引写出到上述文件。
方案2:在方案1基础上,当会话未结束,则累计会话数据包数量。
方案3:在方案1或2基础上,当未建立某一网络流量数据包对应的会话索引信息时,则重新基于所述网络流量数据包信息,提取并生成会话索引信息。
方案4,在方案1、2或3基础上,通过会话索引中的数据包索引文件编号以及数据包索引偏移位置找到对应的数据包索引文件信息;然后通过数据包索引文件信息中的网络流量数据包所在文件的编号、网络流量数据包在文件中的文件偏移位置找到该网络流量数据包。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。
- 还没有人留言评论。精彩留言会获得点赞!