一种基于势博弈的负载已知用户关联方法与流程
本发明涉及通信的技术领域,特别是涉及基于宏基站和小功率基站的用户关联算法。
背景技术
为了满足用户对移动数据流量的需求,移动通信系统需要从时、频、空、码等多维度扩展资源以及提升资源利用率。超密集组网(ultradensenetwork)是充分利用空间资源提升移动通信系统整体性能的一种有效手段。udn的基本思想是:在大功率宏基站的覆盖范围内增加大量小功率基站,以补充宏小区覆盖的不足、提升目标覆盖区域内的接入量和流量密度。udn被视为5g的关键技术之一。
udn缩短了基站间距,导致小区间干扰加剧,尤其当宏基站和小功率基站工作在相同的频段上时。采用频率复用的方法可以有效避免小区间干扰,但极大地降低了覆盖区域内的频谱利用率,不符合移动通信系统未来发展的方向。另一种有效对抗小区间干扰的技术是多点协调(coordinatedmulti-point,comp)传输技术。comp容许多个基站通过相互协调为处位于小区边缘的用户服务,以期达到降低干扰、增强信号、从而提升边缘用户传输速率的目的,联合传输(jointtransmission,jt)是comp传输技术的主要类型之一。jtcomp中与边缘用户关联的多个基站在相同的时频资源上为用户传输数据,利用空间多样性提升数据传输的质量和速率,因此,下文中出现的comp技术,如无特殊说明均指jtcomp。
在移动通信系统中,用于传输的无线资源是有限的,因此每个基站在一个传输周期内可以承载的用户数量有限。例如,在lte系统中,频谱资源被分割成资源块(resourceblock,rb),每个rb的带宽为180khz,假设基站使用20m带宽,即共有100个rb;如果每个用户为满足服务质量(qualityofservice)需求至少需要2个rb,那么基站服务的用户数不能超过50个,如果超过50个,那么必将有一部分用户不能获得满足qos需求的服务。
传统的用户关联方法是:用户基于接收到的参考信号,选择其中强度最大的基站进行关联。这样的方法执行简单,在同构网络中有较高的效率;在异构网络中,由于宏基站的发射功率相比于低功率小基站大得多,使得用户更倾向于与宏基站关联,从而导致宏基站负载过重,无法满足用户qos;而靠近用户的低功率小基站负载较轻甚至空载,这样的负载不均衡现象严重影响了udn的性能。小区扩展(cellrageexpansion,cre)偏置(bias),提高用户选择小功率基站的几率,相比于传统基于rsrp的方法,cre可有效均衡基站负载,且实现简单,cre已被3gpp引入到lte-a技术标准中,但是,由于无线网络环境是时变的,自适应设置cre的bias值成为难题。
comp技术的引入和负载均衡的需求,对异构udn的用户关联策略提出挑战。如专利申请201480002767.6公开了一种用于在网络中多个节点的第一节点为下行链路comp处理生成至少一个下行链路comp协作集的方法。多个节点的每个节点管理至少一个小区。确定多个多维ue点。相应多维ue点的每个维度对应于与ue从对应小区收到的下行链路信号相关联的信道质量度量值。确定至少一个k维ue星座。每个k维ue星座包括接收来自k个小区的下行链路信号的ue集。基于确定的至少一个k维ue星座,确定至少一个k维ue群组。每个k维ue群组与相同小区相关联。基于多个k维ue群组,生成至少一个下行链路comp协调集。该方法是通过配置成将具有至少相同数量的信道质量度量值的信道质量列表编组,以生成信道质量列表的编组,这种方法仅仅能够反映信道的质量,并不能提升网络吞吐量和负载,因此,仍需对提升网络吞吐量和负载进行提高,以满足用户的需求。
技术实现要素:
基于此,本发明的目的在于提供一种基于势博弈的负载已知用户关联方法,该方法可在满足用户qos需求的前提下,提升网络吞吐量和负载均衡,该算法可有集中式和分布式两种执行方式,可适应不同的网络需求。
本发明的目的是通过以下技术方案实现的。
一种基于势博弈的负载已知用户关联方法,其特征在于该方法所采用的异构网络通过ma个大功率宏基站构建的宏小区和大量随机分布的微基站构成,udn由用户集合ωue和基站集合ωbs构成,关于用户关联的博弈模型可定义为
其中,
上述博弈模型满足势博弈条件,势博弈可通过最大化本地决策函数达到纳什均衡,通过对每个用户选择最大化υu的策略求解公式:
s.t.ai,u={si,u,a-u}
定义的用户关联问题。
进一步,所述qos需求特指数据速率的需求。
更进一步,根据具体的信道状态,每个用户可产生多个备选的关联策略,用户u的策略集可表示为
假设用户u根据前一次迭代或者前一个传输周期的用户关联结果a来选择当前的策略,则mu是关于a和用户u的关联策略相关的函数,mu(si,u,a-u),其中,
其中,
更进一步,udn由用户集合ωue和基站(包括宏、微基站)集合ωbs构成,关于用户关联的博弈模型可定义为
进一步,当网络中存在一个能够统筹全局的中心计算单元,可通过集中式计算达到纳什均衡。
更进一步,所述方法包括有集中式和分布式两种算法。下面分别介绍集中式laua(laua-c)和分布式laua(laua-d)两种算法。
进一步,所述集中式laua算法(laua-c),laua-c算法中每个用户的策略选择非独立的,每个用户根据上述最大化υu的策略求解公式选择最优策略后,将相应地更新用户关联结果a,更新后的a将作为下一个用户进行策略选择时的输入,按顺序对用户进行策略选择后,判断当前的用户关联结果a是否满足收敛条件,如果不满足则需要重新对每个用户进行策略选择。
进一步,所述分布式laua算法(laua-d),每个用户选择策略的过程是相互独立的,每个用户根据上述最大化υu的策略求解公式选择最优策略,策略判决所需的全局用户关联结果a可由历史结果代替,显然这样的简化会导致性能下降,但计算复杂度大幅降低,但是laua-d系统性能下降的程度是可以接收的。
进一步,微基站的位置服从泊松点过程(poissonpointprocess,ppp)模型,密度为λbs,在随机生成微基站位置时要求其与宏基站的最小距离不得小于给定值dmin,宏基站与微基站共同构成的基站集合记为ωbs;网络中的用户位置同样服从ppp模型,密度为λue。
本发明可在满足用户qos需求的前提下,提升网络吞吐量和负载均衡,该算法可有集中式和分布式两种执行方式,可适应不同的网络需求。
本发明适合有中心计算单元,且对延迟要求低、对吞吐量和负载均衡要求高的场景。
附图说明
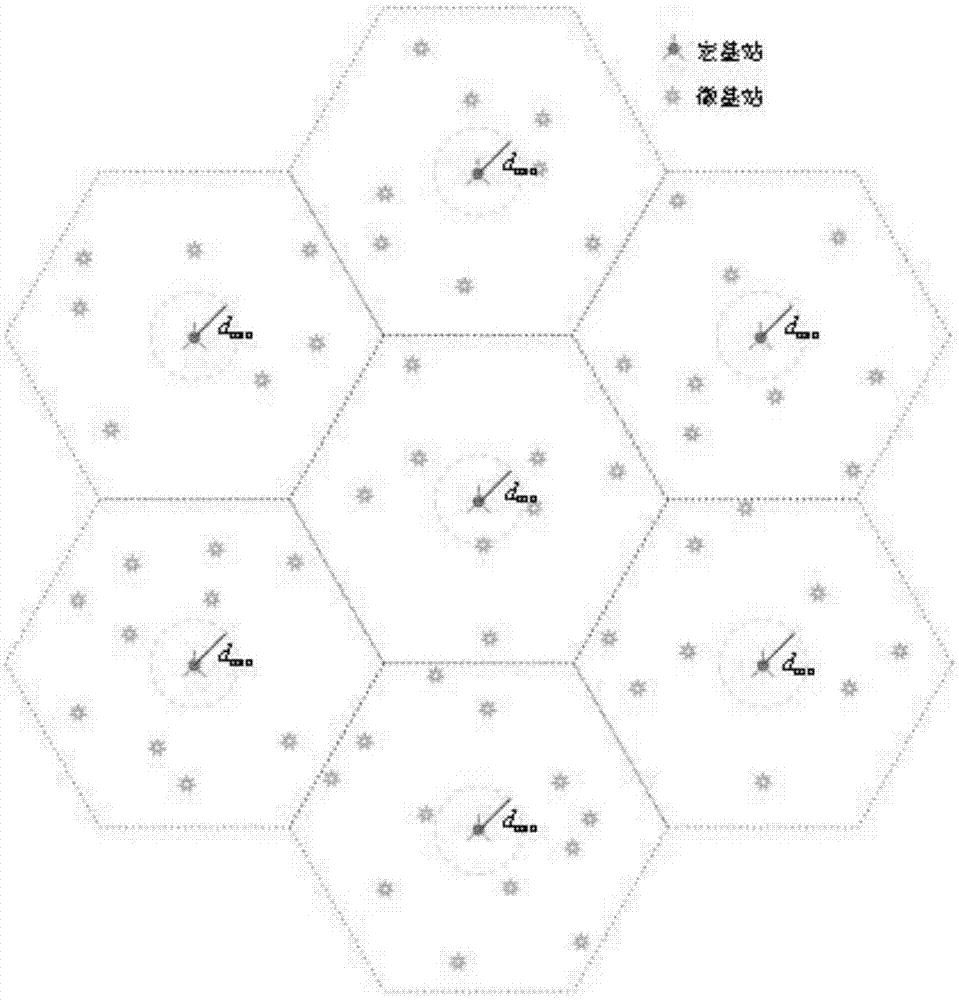
图1是本发明所应用的网络拓扑图。
图2是本发明所实现集中式laua算法的流程图。
图3是本发明所实现分布式laua算法的流程图。
图4是本发明所实现各算法用户数据速率cdf对比图。
图5是本发明所实现各算法网络吞吐量对比图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为了描述本发明的实施,考虑构建一个两层的异构网络:第一层包括ma个大功率宏基站构建的宏小区,其中宏基站均匀分布,每个宏基站的覆盖区域可等效为六边形;第二层由大量随机分布的微基站构成,微基站的位置服从泊松点过程(poissonpointprocess,ppp)模型,密度为λbs。为了更准确的模拟现实情况,在随机生成微基站位置时要求其与宏基站的最小距离不得小于给定值dmin,宏基站与微基站共同构成的基站集合记为ωbs,网络中的用户位置同样服从ppp模型,密度为λue。令ωue表示用户集合,k表示集合中用户的数量。上述网络拓扑如图1所示。
在异构网络中,基于参考信号强度的用户关联方法容易导致基站负载不均衡,影响网络性能。同时,采用comp技术对抗小区间干扰需要为小区边缘用户选择多个基站进行关联。用户可基于参考信号强度选择一个信道条件最好的基站进行控制信令的交互,一方面控制信令数据量小,不会导致基站超载;另一方面因为信道质量较高,不易产生断网的情况,用户可得到连续的可靠服务;相对应地,系统通过灵活地为用户选择传输数据(用户面)的基站,达到均衡负载、提高网络整体性能的目的。下文中的用户关联算法即针对用户面基站的选择。
假设用户u通过用户关联算法获得的传输基站集合表示为
采用jtcomp传输技术时,
其中,hu,b表示基站b与用户u之间的信道系数,σ2表示白噪声的功率谱密度。公式(2)中,pb表示基站b在每rb上的发射功率。本发明假设基站将总发射功率均匀分配给每个rb,因此有
令βu表示用户u占用的rb数量,则用户u的传输速率可表示为:
其中,w表示每个rb的带宽,γu由公式(2)定义。
由公式(2)可以看出,对单一用户来说,
以最大化吞吐量为目标,考虑每个基站的总带宽限制,用户关联问题可建模为如下优化问题:
其中,
从公式(5)定义的用户关联问题可以看出,用户关联与rb分配是不独立的,在进行用户关联时,必须考虑每个基站的频谱资源是否足以承载与其关联的用户,而comp技术的引入又进一步增加了复杂度。由于采用了comp技术,一个用户很可能同时与多个基站关联。此时,用户可获得的rb个数,受限于其传输集合中负载最重的基站,比如,用户u的传输集合
令
则用户u可获得的rb数量可估计为:
其中,
针对公式(5)定义的优化问题,本发明提出一种基于势博弈的负载已知用户关联算法,下文中简称为laua(load-awareuserassociation)算法。
在前文描述的异构网络中,根据具体的信道状态,每个用户可产生多个备选的关联策略,令si,u表示用户u的第i个关联策略,其中si,u是由基站id组成的集合,根据公式(4)有|si,u|≤cmax,用户u的策略集可表示为
令s*,u表示某次用户关联中用户u最终选定的策略,则集合
假设用户u根据前一次(前一次迭代或者前一个传输周期)的用户关联结果a来选择当前的策略,则mu是关于a和用户u的关联策略相关的函数,即mu(si,u,a-u)。其中,
其中,
前文描述的udn由用户集合ωue和基站(包括宏、微基站)集合ωbs构成,因此关于用户关联的博弈模型可定义为
本发明将用户u的本地决策函数υu定义为:
令u(ai,u)表示由公式(5)定义的优化问题的总效用函数,即
υu(ai',u)-υu(ai,u)=u(ai',u)-u(ai,u)(11)
因此,上述博弈模型满足势博弈条件,势博弈可通过最大化本地决策函数达到纳什均衡,因而,可通过对每个用户选择最大化υu的策略求解公式(5)定义的用户关联问题。即,
s.t.ai,u={si,u,a-u}(12)
当网络中存在一个能够统筹全局的中心计算单元,可通过集中式计算达到纳什均衡。集中式计算更有利于获得最优解,从而得到较好的系统性能。但其计算复杂度高、计算消耗和延迟较大。上述博弈模型也可采用分布式算法进行求解。分布式算法不可避免地降低了系统性能,但能够有效降低计算量和计算延迟。下面分别介绍集中式laua(laua-c)和分布式laua(laua-d)两种算法。
对于集中式laua算法(laua-c)
laua-c中每个用户的策略选择非独立的。每个用户根据公式(12)选则最优策略后,将相应地更新用户关联结果a。更新后的a将作为下一个用户进行策略选择时的输入。按顺序对用户进行策略选择后,判断当前的用户关联结果a是否满足收敛条件。如果不满足则需要重新对每个用户进行策略选择。图2描述了laua-c算法的过程。
对于分布式laua算法(laua-d)
分布式算法中,每个用户选择策略的过程是相互独立的,策略判决所需的全局用户关联结果a可由历史结果代替。显然这样的简化会导致性能下降,但计算复杂度大幅降低。后文中的仿真结果说明,laua-d系统性能下降的程度是可以接收的。如图3描述了laua-d算法的过程。
为了对比算法的性能,本发明对基于参考信号强度的用户关联(下文称为rsrp算法)和cre算法进行了仿真,其中cre算法的bias设置为6db。laua算法中的策略集选择可以基于rsrp算法,也可基于cre算法。下文中将基于rsrp的laua算法称为laua-c和laua-d;将基于cre算法的laua算法称为laua-c&cre和laua-d&cre。
图4为不同算法下用户数据速率的累积分布函数(cumulativedistributionfunction,cdf)。从图中可以看出,laua-c和laua-c&cre算法得到的用户数据速率优于其他算法。laua-d和laua-d&cre与集中式算法相比有小幅度的下降,其中laua-d中有少量用户的数据速率没有达到qos需求,laua-d&cre与cre算法的用户数据速率结果相近。rsrp算法中有大量用户无法获得满足qos需求的数据速率。
图5所示是各算法获得的网络总吞吐量。可以看出,相比于rsrp算法,cre明显提升了网络的吞吐量,而集中式的lac又在cre的基础上进一步提高了网络吞吐量。分布式lac算法获得的吞吐量与cre算法接近。
为了量化负载均衡的情况,本发明定义了负载系数:令集合
由上式可知,ηload越小表示每个基站承载的用户数量越平均,当所有基站负载相同是ηload为0。
下表对比了各个算法的负载系数。其中laua-c&cre算法的负载系数最小,说明基站间的负载最均衡;而rsrp算法的负载系数最大,表示各个基站的负载偏差最大。laua-d算法的负载系数较大,但laua-d&cre的负载系数与集中式算法相近。
表1不同算法负载系数对比
下表根据上述仿真结果,对仿真中的6中算法进行了综合对比。可以看出,本发明提出的laua-c和laua-cre算法的吞吐量和负载均衡性能最优,但其复杂度也最高,适合有中心计算单元,且对延迟要求低、对吞吐量和负载均衡要求高的场景。本发明提出的laua-d和laua-d&cre算法吞吐量性能与cre相似,但负载均衡性能优于cre,并且相比于集中式算法,分布式算法的计算复杂度低。
表2不同算法性能综合对比
由此,本发明所实现的基于势博弈的负载已知用户关联算法laua,能够在获得满足用户qos需求的基础上均衡负载,同时获得网络吞吐量的提升。算法可分为集中式(laua-c)和分布式(laua-d)两种,可适用于不同的网络需求。对比结果表明算法在吞吐量和负载均衡方面均可获得优于rsrp和cre算法的系统。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!