一种基于邻居迭代相似度的用户身份链接方法与流程
本发明属于网络通信
技术领域:
,更为具体地讲,涉及一种基于邻居迭代相似度的用户身份链接方法。
背景技术:
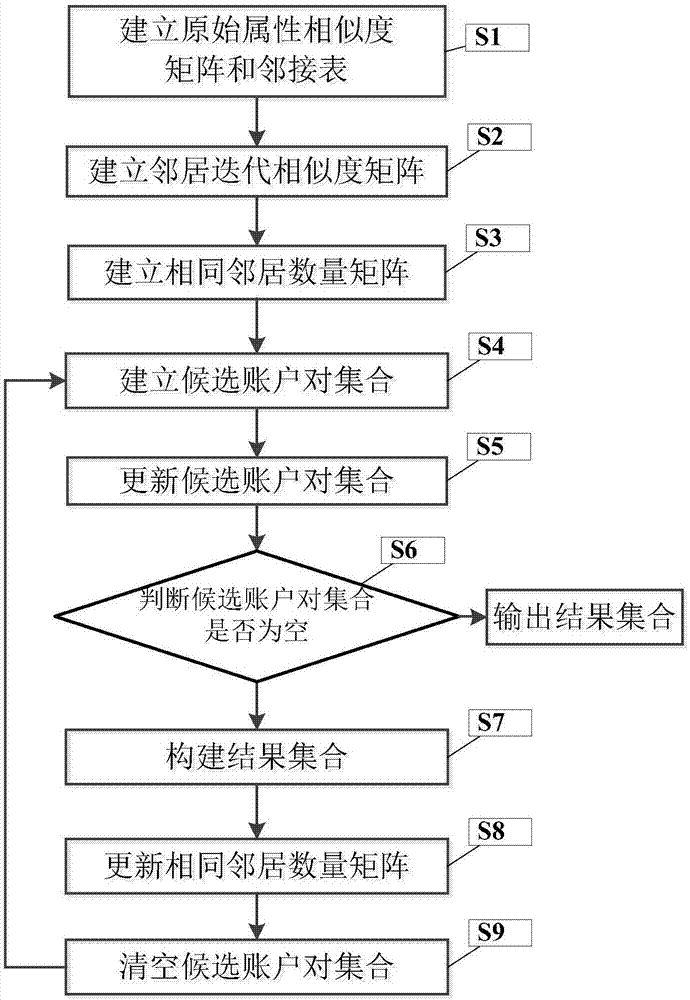
:上个世纪末至今,正是互联网腾飞的时代,人类生活的方方面面,包括经济、政治、文化、娱乐等,都面临着巨大的变革与颠覆性的发展。人们的社交模式也不可避免发生了改变,邮件、bbs、即时通信(im)、博客(blog)等新兴社交媒体一个接一个的出现在人们的日常生活中,并逐步替代了书信等传统的社交联系方式在人们生活中的地位。不同的在线社交网络平台拥有不同的功能,面向不同的应用场景。为了更好地利用每个社交网络提供的服务,用户倾向于同时在多个在线社交网络拥有自己的账户,这意味着人们在进行不同的社交活动,同时也将留下丰富的用户的行为数据。由于用户出于不同目的使用不同的在线社交网络,在单个社交媒体上分析用户可能不能全面了解其个性和兴趣。如果同时利用多个平台的数据,数据研究工作者将可以更加充分的理解用户兴趣,并提供更好的推荐或服务。然而,各个社交媒体站点之间的账号没能相互链接,用户的行为痕迹分布散乱,难以统一,对用户兴趣的进一步深入研究自然无从下手。也就是说,如果研究者能够将多个网络中的账户链接到其对应的用户身份,在这些社交媒体站点上收集和分析他/她的数据,研究者可能对用户有更全面的了解,并提供更好的服务。这种将多个网络中的账户链接到其对应用户身份的技术被称为跨社交网络用户身份链接技术。在数据研究领域,记录链接(recordlinkage)是一个被研究者长期关注且与用户身份链接问题密切相关的问题,其目的是在一个包含许多的不同数据源的数据集中找到引用同一实体的记录。现代记录链接的概念起源于遗传学家howardnewcombe,他介绍了频率比的概念,并给出了划分匹配与非匹配的判定规则。在过往的研究中,为解决记录链接问题,已经发展出大量的有监督或无监督的算法,其主要分为确定性链接和概率链接两类方法。前一种方法通常是基于规则的,力求精确地对用户名和其他用户属性进行匹配,通常适用于简单的链接问题,或者存在匹配的特殊知识领域。概率链接的方法一般则先将概率加权分配给各个记录,然后将其中具有足够高权重的记录对作为最后确定的链接对。fellegi等人的研究提供了一些概率链接相关的数学基础知识与理论分析内容。然而,尽管与记录链接问题具有一定的相似性,本文中考虑的用户身份链接问题具有其独特的社会数据特性,自然需要不同于过往记录链接研究的新突破。用户身份链接问题的概念第一次正式出现,是由zafarani等提出,其研究了跨社区链接对应身份的问题,并用基于web搜索的方法进行处理。考虑到社会网络的多样性和信息的不对称性,许多早期研究都是基于用户信息进行的,其中包括基于用户配置文件、基于用户生成内容和基于用户行为模型等多个角度。基于用户配置文件的方法收集由用户或用户配置文件提供的用户标识信息,例如,用户名、个人描述、位置等。基于用户生成内容的方法从用户个人阅读记录或用户平时生成的内容中收集个人可识别信息。基于用户行为模型的方法分析用户日常行为模式,并从用户名、语言和写作风格等方面入手建立用户特征模型。近年来,研究者们在监督学习和非监督学习的框架中都提出了更加新颖的方法。liben-nowel等人研究了基于大规模无监督链接框架的同构网络链路预测方法。为解决集体链路识别问题,zhang等人提出了一个统一链路预测框架。其后,zhang等人进一步研究了部分对齐网络中的多网络链路预测问题。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于邻居迭代相似度的用户身份链接方法,基于结构的邻居迭代相似度,用于解决跨社交网络用户身份链接问题,并从多个角度对算法的性能做出了分析,证明了算法拥有优越的性能。为实现上述发明目的,本发明一种基于邻居迭代相似度的用户身份链接方法,其特征在于,包括以下步骤:(1)、建立原始属性相似度矩阵和邻接表(1.1)、在社交网络a和社交网络b中,设a为社交网络a中的任一账户,b为社交网络b中的任一账户;(1.2)、根据社交网络a、b的所有账户两两之间的原始属性相似度,建立原始属性相似度矩阵q,其中,q(a,b)表示两个账户a、b间的原始属性相似度;(1.3)、根据社交网络a、b中的所有账户两两之间是否为好友关系,建立邻接表la、lb,其中,la(a)表示与账户a具有好友关系的所有账户的集合,lb(b)表示与账户b具有好友关系的所有账户的集合;(2)、建立邻居迭代相似度矩阵根据原始属性相似度矩阵q、邻接表la、lb,计算任意两个账户间的邻居迭代相似度,从而建立邻居迭代相似度矩阵t;(3)、建立相同邻居数量矩阵在邻接表la、lb中,若账户x、y分别为账户a、b的好友,即x∈la(a),y∈lb(b),且账户x、y之间存在链接,则判断账户a、b拥有一个相同邻居;那么,根据邻接表la、lb和先验种子链接集合ems,建立社交平台a、b中未链接账户的相同邻居数量矩阵d,其中,d(a,b)表示两个账户a、b间的相同邻居数量;(4)、在相同邻居数量矩阵d中进行遍历,找出相同邻居数量最多并且未被链接的所有账户对,存放到候选账户对集合c中;(5)、根据邻居迭代相似度矩阵t和预设阈值y,将候选账户对集合c中邻居迭代相似度小于阈值y的账户对删除;(6)、判断候选账户对集合c是否为空,如果不为空,则进入步骤(7),否则,返回结果集合r作为迭代的结果,完成用户身份链接;(7)、根据邻居迭代相似度矩阵t,找出候选账户对集合c中邻居迭代相似度最大的账户对,将该账户对加入结果集合r中;(8)、将所有与步骤(7)中找出的账户对具有好友关系的账户之间的相同邻居数量加1,完成相同邻居数量矩阵d的更新;(9)、清空候选账户对集合c,再返回步骤(4)。本发明的发明目的是这样实现的:本发明一种基于邻居迭代相似度的用户身份链接方法,利用多阶top-k邻居节点对的相似度与节点对本身的相似度进行加权平衡,得到了邻居迭代相似度这样一种更为有效的社交帐号间相似程度的评判标准;同时,该方法通过以先验种子为基点,逐步向整个网络迭代覆盖的方法,能准确高效地完成社交网络中用户身份链接的工作。同时,本发明一种基于邻居迭代相似度的用户身份链接方法还具有以下有益效果:(1)、区别于传统的属性相似度计算方法,在计算一对节点的相似度时,邻居迭代相似度使用多阶top-k邻居节点对的相似度与节点对本身的相似度进行加权平衡,利用节点对邻居之间的相似度来对节点对相似度的判定进行辅助,减轻了用户在不同社交网络中脸谱信息可能出现的差异性对进行用户身份链接的负面影响;(2)、在邻居迭代相似度方法的基础上,基于邻居迭代相似度的用户身份链接方法以先验种子链接为基点,通过迭代的方式,逐渐向整个网络传播覆盖,利用脸谱信息与结构信息的互补,有效地应对过往方法难以解决的网络差异性问题,能适用于不同规模的各种社交网络中的用户链接工作;(3)、基于邻居迭代相似度的用户身份链接方法是一种半监督的方法,与传统监督方法相比,大大减少了运行所需的先验信息量,能用于解决先验信息匮乏情况下的实际问题,节约了数据采集成本与方法训练成本。附图说明图1是本发明一种基于邻居迭代相似度的用户身份链接方法流程图;图2是账户信息缺失率统计图;图3是不同算法的性能统计对比图。具体实施方式下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。实施例图1是本发明一种基于邻居迭代相似度的用户身份链接方法流程图。在本实施例中,如图1所示,本发明一种基于邻居迭代相似度的用户身份链接方法,其特征在于,包括以下步骤:s1、建立原始属性相似度矩阵和邻接表多个社交网络中的账户彼此分隔,却可以通过其使用者相互联系起来,这样由多个具有联系的不同社交网络耦合形成的网络可以称为一个多重社交网络。s1.1、在社交网络a和社交网络b中,设a为社交网络a中的任一账户,b为社交网络b中的任一账户;s1.2、根据社交网络a、b的所有账户两两之间的原始属性相似度,建立原始属性相似度矩阵q,其中,q(a,b)表示两个账户a、b间的原始属性相似度;s1.3、根据社交网络a、b中的所有账户两两之间是否为好友关系,建立邻接表la、lb,其中,la(a)表示与账户a具有好友关系的所有账户的集合,lb(b)表示与账户b具有好友关系的所有账户的集合;s2、建立邻居迭代相似度矩阵根据原始属性相似度矩阵q、邻接表la、lb,计算任意两个账户间的邻居迭代相似度的方法为:其中,表示两个账户a、b间的邻居迭代相似度;为a、b之间的i阶邻居迭代相似度,ko为常数,∈为大于0的极小实数;假设有两个账户z、w属于不同的社交网络,有另两个账户x∈γ(z),y∈γ(w)。如果x、y拥有很高的度,即x、y拥有很多的邻居节点。这时,x、y很有可能是一些具有公共职能的人或公众号,它们对链接用户的贡献一般会小于那些度更小的邻居,因为度更小的邻居更可能是普通人群,例如用户的亲人、朋友、同事等。那么,的计算方法为:s2.1、当i=0时,s2.2、当i>0时,其中,βi=1/(i+1)i+1,表示两个账户a、b间的i阶top-ko邻居对集合,q(x,y)表示两个账户x、y间的原始属性相似度,γ(x,y)为两个账户x、y的原始属性相似度的修正值,γ(x,y)的取值为:γ(x,y)=min(δ(x,z),δ(y,w))其中,x、y分别为账户z、w的好友,即x∈la(z),y∈lb(w);δ(x,z)的计算方法为:其中,|la(x)|表示集合la(x)中包含的账户数量;|la(z)|表示集合la(z)中包含的账户数量。其中,的计算方法为:1)、当i=0时,为包含集合j0(a,b)中按原始属性相似度q(x,y)从大到小排序后前ko个账户对的集合,其中,j0(a,b)的计算方法为:j0(a,b)={(x,y)|x∈la(a),y∈lb(b)}2)、当i>0时,为包含集合ji(a,b)中按原始属性相似度q(x,y)从大到小排序后前ki个账户对的集合,其中,ji(a,b)的计算方法为:其中,0≤j≤i-1,*代表社交网络a、b中的任一账户。这里,相似度是递归的,在第i次迭代中,相似度是第i-1次迭代得到的相似度与加入了修正系数的i阶top-ki邻居对相似度的加权结果。本算法认为距离节点越远的邻居对节点相似度的贡献也应该越小。因此,每经过一次迭代,ki呈指数降低,βi也呈指数降低。即随着迭代次数的增加,用于影响相似度的邻居对数逐渐减少,并且新邻居的权重也逐渐减小。当所有账户间的邻居迭代相似度计算完成后,根据任意两个账户间的邻居迭代相似度,从而建立邻居迭代相似度矩阵t;在本实施例中,邻居迭代相似度使用多阶top-k邻居节点对的相似度与节点对本身的相似度进行加权平衡,利用节点对邻居之间的相似度来对节点对相似度的判定进行辅助,以减轻用户在不同社交网络中脸谱信息可能出现的差异性对用户身份链接的负面影响。s3、建立相同邻居数量矩阵在跨平台身份链接问题中,先验种子链接往往能提供十分重要的基准信息。过往的许多相关方法都需要使用到先验种子链接信息,根据其算法的设计思路的不同,其使用先验种子链接信息的方法也各有不同。一种典型的思路是,利用先验种子链接提供的有效信息,可以对算法选定的模型进行训练,获取到能用于解决身份链接问题的模型与相关参数.另外,以先验种子链接为基点,从先验种子节点的邻居开始搜索,通过逐步迭代来慢慢覆盖到整个网络的方法,也是一种常见却行之有效的算法设计思路。本实施例使用的是后一种迭代搜索的思路。在邻接表la、lb中,若账户x、y分别为账户a、b的好友,即x∈la(a),y∈lb(b),且账户x、y之间存在链接,则判断账户a、b拥有一个相同邻居;那么,根据邻接表la、lb和先验种子链接集合ems,建立社交平台a、b中未链接账户的相同邻居数量矩阵d,其中,d(a,b)表示两个账户a、b间的相同邻居数量;s4、在相同邻居数量矩阵d中进行遍历,找出相同邻居数量最多并且未被链接的所有账户对,存放到候选账户对集合c中;s5、根据邻居迭代相似度矩阵t和预设阈值y,将候选账户对集合c中邻居迭代相似度小于阈值y的账户对删除;s6、判断候选账户对集合c是否为空,如果不为空,则进入步骤s7,否则,返回结果集合r作为迭代的结果,完成用户身份链接;s7、根据邻居迭代相似度矩阵t,找出候选账户对集合c中邻居迭代相似度最大的账户对,将该账户对加入结果集合r中;s8、将所有与步骤s7中找出的账户对具有好友关系的账户之间的相同邻居数量加1,完成相同邻居数量矩阵d的更新;s9、清空候选账户对集合c,再返回步骤s4。实例本实施例中选用的数据集采集于两个真实的社交网络,新浪微博与人人网,共包含用户账号205个,其具体信息如表1所示。表1是采集数据信息表;表1本数据集中选取了其中5项属性项:性别,省份,城市,生日和毕业院校。由于数据来自于真实的社交网络,其完整性难以保证,信息的缺失情况较为严重,对账户信息缺失率做出统计,如图2所示。本实施例中,通过以下几种算法来体现不发明的特点与性能。第一种方法是使用原始属性相似度作为用户亲和度评分的无监督对齐方法,称其为y-a算法。第二种方法是使用邻居迭代相似度作为用户亲和度评分的无监督对齐方法,称其为n-a算法。第三种方法是只使用原始属性相似度的变种snis算法,称其为snis-y算法。第四种方法是frui算法,其全称为friendrelationship-baseduseridentificationalgorithm,其与snis算法相似,是一种半监督方法中的进行局部搜索的传播方法。表2是不同算法的性能对比表;算法准确率召回率f1值y-a0.510.760.61n-a0.640.780.7snis-y0.610.720.66frui0.920.310.46snis(阈值0)0.710.760.73snis(阈值0.7)0.90.620.74snis(动态阈值)0.760.840.8snis(动态阈值,裁剪)0.870.810.84表2其结果对比如表2和图3所示,其中,frui算法得到的结果非常精准,其准确率在所有算法中最高,为92%。但无法忽略的是,frui算法的准确率是以牺牲召回率的代价得到的,其召回率极低,仅有31%。其召回率较低的原因,是frui算法只使用了结构信息,而没有使用节点相似度来进行辅助判断,导致frui算法无法处理具有同样相同邻居数量但具有冲突的节点对。使用邻居迭代相似度的无监督对齐方法n-a算法的召回率为78%,其准确率表现也不错,达到了64%,f1值达到0.7。而使用原始属性相似度的无监督对齐方法y-a算法的准确率仅为51%,为所有算法中最低,召回率为76%,f1值为0.61。从y-a算法与n-a算法的结果对比中可以看出,n-a算法各项指标均要优于y-a算法。在进行用户身份链接时,相比于原始属性相似度,邻居迭代相似度能更好的对节点间的相似程度进行判定。使用原始属性相似度的传播方法snis-y算法的准确率与f1值明显优于使用原始属性相似度的无监督对齐方法y-a算法,其召回率则相差不多;使用邻居迭代相似度的的传播方法snis算法的准确率与f1值明显优于使用邻居迭代相似度的无监督对齐方法n-a算法,其召回率也相差不多。使用基于结构的迭代传播方法的准确率一般要优于无监督对齐方法,并且召回率损失不大,综合性能更好。相比于阈值为0的snis算法,在设置0.7的阈值之后,snis算法的准确性获得了明显提升,从71%提升到了90%。这显然符合本发明阈值设置的初衷,即去掉那些相似度很低的节点对,减少误判,增加正确率。不过,由于阈值判定比较严格,获得的链接都满足相似度极高的要求,过滤了相似度较低的正确链接,导致算法的召回率相对较低,只有62%。为了提升设置阈值之后的召回率,本发明使用了动态阈值的方法,即使用动态阈值的snis算法极大的提高了召回率,达到了84%,远远超过了阈值为0的snis算法与阈值为0.7的snis算法。同时,使用动态阈值的snis算法综合评价指标f1值达到了0.8。相比阈值为0的snis算法与阈值为0.7的snis算法的f1值仅有0.73与0.74,使用动态阈值的snis算法综合性能有了进一步的提升。使用动态阈值的snis算法也增加了误判的可能性,其准确率为76%,较使用阈值为0.7的snis算法90%的准确率有了较多降低。本文使用结果裁剪的方法来保证结果的准确率,根据之前提到的节点重叠率的概念以及数据集的特点,实验中使用的结果裁剪比例为10%。在对使用动态阈值的snis算法进行裁剪之后,其准确率来到了87%,较未裁剪之前有了明显的回升。而裁剪之后的召回率并没有太大损失,为81%,f1值则为所有算法最高。如图3所示,通过上述讨论对比,可以认为,完整snis算法在综合性能上的具有明显的优势,在保证召回率的同时,也有较好的准确率,其具有上述所有算法中最好的有效性与实用性。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1