一种基于主动学习的鲁棒性网络流量分类方法及系统与流程
本发明设计网络信息领域,具体涉及一种基于主动学习的鲁棒性网络流量分类方法与系统。
背景技术:
近年来,随着互联网的迅猛发展,越来越多的新型网络应用逐渐兴起,网络规模不断扩大,网络组成也越来越复杂。网络流量分类技术作为增强网络可控性的基础技术之一,不仅可以帮助网络运营商提供更好的服务,而且能够对网络进行有效的监督管理,确保网络安全。同时,也为了能够识别新的应用类型。
目前有各种技术处理以上问题。
(1)基于端口号的流量分类方法
传统的流分类方法依赖于对tcp或udp数据包中端口号的分析,将熟知的端口号进行映射来识别不同的应用类型。基于端口的识别方法优点是简单,容易实现,速度快,但是正确率比较低,特别是现在新的网络应用不断增多其可以识别应用的比重越来越低,分类正确率不稳定。
(2)基于有效载荷的流量分类方法
为了避免对端口号的过分依赖,提出了基于有效负载分类方法。该方法通过分析分析包的有效负载是否包含已知应用的特殊签名进行流分类,具有较高的准确性。
虽然该方法具有很高的分类正确率,但是分析代价太大。为了降低计算代价,可将其与一些分代价较低的分类方法结合使用,先过滤出一些很容易分析出的流量,以减少计算开销。moore和papagiannaki使用了一种端口号和有效载荷相结合的技术来识别网络应用。虽然基于有效负载的分类方法避免了过分依赖端口号带来的问题,但是其自身也存在一定的限制:它只能识别那些已知的非加密流量,而无法分类其他未知流量;此外,这种方法无法应用于私有协议或加密流量,而且直接分析应用层的内容会带来隐私侵犯和安全性等问题。
(3)基于机器学习的流量分类技术
目前研究的热点主要在机器学习的分类方法,不同应用类型网络流量具有一定的流特征,将流特征提取出来并用机器学习算法来训练建立分类模型,然后对在线应用进行分类。以统计理论为基础的机器学习算法由于其广泛的应用背景和成熟的理论框架在流量分类研究中被越来越多的使用。但是机器学习的方法比较依赖数据集,不同网络环境可能会影响分类正确率,而且在计算一些流特征的时候,需要计算流中每个包的特征,在网络流量暴涨情况下,应用识别的性能有所下降,分类准确率不稳定。
技术实现要素:
针对上述已有方法存在的问题,本发明的目的是提供了一种基于主动学习的鲁棒性网络流量分类方法及系统。
为实现上述目的,本发明采用如下的技术方案:
一种基于主动学习的鲁棒性网络流量分类系统,包括流量分类以及未知类型流量的发现模块、主动学习过程模块和系统更新模块;其中,
流量分类以及未知流量类型发现模块,用于实现对应用流量类型的分类识别;流量分类以及未知流量类型发现模块由基于机器学习的未知流量检测模块和流量分类模块,以及基于神经网络的数据降维模块组成;
主动学习模块用于优化分类器,在流量分类以及未知流量类型发现模块对样本分类的同时,如果样本是确定的一种类型,则将该样本加入分类器的训练集中,增加样本数量;如果不是确定的一种类型,则对模型树进行分支,等分支数量达到阈值16时,在产生异常的样本中选择信息量最大的一个队模型树进行剪枝;
系统更新模块用于首先将流量分类以及未知流量类型发现模块分类过程中检测到的未知类型的流量通过dbscan聚类算法进行聚类,然后将聚类的新类型进行标注。
本发明进一步的改进在于,基于机器学习的未知流量检测模块用于对待检测的流量中提取出中不属于已知分类器类型的流量。
本发明进一步的改进在于,流量分类模块用于对流量分类。
本发明进一步的改进在于,基于神经网络的数据降维模块用于通过correntropy改进损失函数的稀疏自编码器来对待检测的流量进行数据降维处理。
本发明进一步的改进在于,进行数据降维处理的过程为:利用两层隐藏节点并且每一层的节点都是100,最终由249维的数据降为100维。
基于上述基于主动学习的鲁棒性网络流量分类系统的实现方法,包括以下步骤:
第一步,将采集的网络流流量通过稀疏自编码器进行降维;
第二步,选取有标签的样本作为训练集生成一个初始的分类器,并计算初始的分类器中每一类型的阈值;
第三步:用未标签的样本通过主动学习的方法生成分类模型,同时进行异常点检测,并将未标签的数据放入异常点集合;
第四步,当分类模型的最大分支达到阈值时,从集合中选取信息量最大的样本;将选取出来的样本标记样本类型,并且对分类模型进行剪枝,得到优化后的分类器;其中阈值为16;
第五步:当异常点集合的数量达到阈值时通过dbscan聚类算法进行新类型发现,用发现的新类型更新分类器;其中,阈值为200。
本发明进一步的改进在于,步骤一中,通过correntropy改进损失函数的稀疏自编码器来对待检测的流量,利用两层隐藏节点并且每一层的节点都是100,最终由249维的数据降为100维。
本发明进一步的改进在于,第三步的具体过程如下:
对于一个新的样本,和初始的分类器中每一种类型进行相似度的计算,得到相似度阈值;将初始的分类器中每一类型的阈值与相似度阈值进行比较,若是新的样本符合其中一个类型,则将新的样本判别为该类型,若是新的样本符合多个类型,则进行分支,生成modeltree,并将该新的样本放入一个集合中,若是新的样本不符号任何一种类型,则加入异常点集合。
本发明进一步的改进在于,第四步的具体过程为:
令专家委员会中第jth个分类器赋予流量x的类型标签为y(j)(x),建立一个分类器委员会投票的直方图,计算类型标签label(x)的熵,则共有m个成员的专家委员会中类型标签分布为:
其中,δ为克罗内克函数,l为样本x对应的标签;
则流量x的香农熵为:
选择查询的流量对象为:
通过查询得到的流量x进行剪枝,得到优化后的分类器。
本发明进一步的改进在于,第五步的具体过程为:首先将分类过程中检测到的未知类型的样本通过dbscan聚类算法进行聚类,而且dbscan聚类算法里面采用的并非传统的欧氏距离而是相互关系熵,然后将聚类的新类型样本进行标注,将优化后的分类器和已经标注的聚类的新类型进行整合,得到一个有新类型的优化的分类器。
与现有技术相比,本发明的有益效果为:
本发明以主动学习和稀疏自编码器的概念,针对日益增多的网络流量类型的特点,提出了基于主动学习的鲁棒性网络流量分类框架。该系统可以简单的分为三部分,流量分类以及未知类型流量的发现模块、主动学习过程模块和系统更新模块。该系统一方面可以大大减少人工标注的成本,另一方面该系统可以发现新的流量类型并且对分类器进行更新,以此能对分类效果进行较大的提升。与此同时,该系统也加入了数据降维功能以此来让高维数据有一个更好的表达。
进一步的,由于网络流量都是高维数据,如果直接用来进行实验,实验效果表现一般,这里就通过改进的稀疏自编码器来进行数据降维,使数据有一个更好的表达。
本发明的基于机器学习的未知类型流量检测算法和流量分类算法,提高了流量分类的准确性,此应用分类架构能够更加灵活的应对成爆炸性增长的应用类型。本发明的方法可以发现新的应用类型,且该方法可以大大减少标记样本的人力和物力,同时还可以应用到其他需要大量有标签数据的场景中。
附图说明
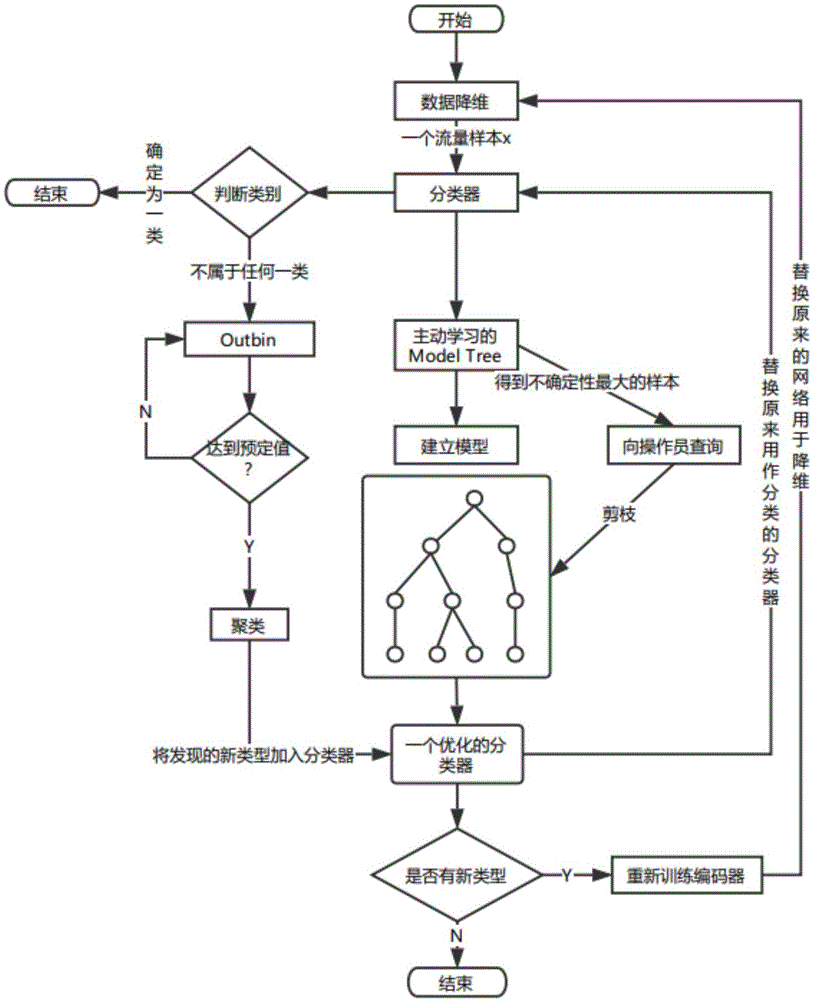
图1是基于主动学习的鲁棒性流量分类系统示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述
本发明中流量分类框架以主动学习,稀疏自编码器以及dbscan聚类,通过对抓取的流量先通过稀疏自编码器对抓取的流量进行处理,让数据有一个更好的表达,然后用分类器对其进行分类,分类后再对该流量进行主动学习去优化分类器与此同时通过聚类算法对新类型的流量进行聚类发现,最后更新分类器。
基于主动学习的理念,由于传统使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家来进行人工标注,所花费的时间成本和经济成本都是很大的。而且,如果训练样本的规模过于庞大,训练的时间花费也会比较多。在人类的学习过程中,通常利用已有的经验来学习新的知识,又依靠获得的知识来总结和积累经验,经验与知识不断交互。同样,机器学习模拟人类学习的过程,利用已有的知识训练出模型去获取新的知识,并通过不断积累的信息去修正模型,以得到更加准确有用的新模型。不同于被动学习被动的接受知识,主动学习能够选择性地获取知识,即可以在一批样本中选择出分歧度最大的样本来进行人工标注,相对于传统的方式可以大大减少人工标注的成本,因此能够达到对分类器优化的作用。
如图1所示,本发明所述基于主动学习的鲁棒性网络流量分类系统简单的可以分为三个层次:流量分类以及未知类型流量的发现,主动学习的过程和系统更新。
下面分别介绍每一个层次的功能。
在第一个模块里面,由基于神经网络和机器学习的数据降维模块和流量分类模块。首先将抓取的网络流量通过稀疏自编码器进行数据降维,将处理好的流量数据进行分类,如果该流量不属于目前分类器里面的任何一类,就将该流量放入异常点集合(outbin),以备系统更新时处理。
在第二个层次中主要是基于“专家委员会”(qbc)的主动学习的算法。对上一层的流量不断地通过主动学习构建模型树(modeltree),树的一个节点代表一个分类器,根节点为初始分类器。每个分类器中都保存有各已知类型的训练集以及各类型对应的相似度阈值要求。
根据阈值分类过程中遇到的部分样本的分类判断具有的不确定性,在对这些不确定样本分类时,产生树的分歧。按照该样本可能属于哪些不同的类型,也就是符合哪些类型的相似度阈值要求,建立若干个当前分类器的子分类器。在这若干子分类器中,首先继承父分类器的训练集和各类的阈值要求数据,再将该样本按照其可能属于的类型加入对应类型的训练集中,并对其加入的类型根据当前训练重新计算阈值标准。同一分类器的子分类器之间的区别在于对该不确定样本的分类判断以及处理,对于之前分类和处理的其他样本,子分类器和父分类器没有区别。在分类的过程中只保存modeltree(分类模型)中所有的叶节点分类器,不断删除非叶节点分类器。
当下一条待检测流量进入系统时,所有的叶节点分类器根据自身存储的训练集和各类型阈值要求对其进行分类判断,重复以上两步,就生成了一颗由多个不同分类器构成的modeltree。
随着分类过程的进行,遇到的不确定样本越来越多,modeltree的分枝和层数将不断增加。因此需要预设一个分类器数目的最大限值,当达到最大限值时,由系统选择出一个所有分类器的分类判断中分歧最大的一个样本,认为该样本即为主动学习研究中要求选择的最合适学习的,包含信息量最大的样本,这样就完成了样本选择工作。然后再将该样本的详细信息发送给研究人员进行查询,由研究人员对其类型做出准确判断后,再反馈给系统。
系统根据该样本的准确类型,将modeltree中所有对该样本做了错误判断的分类器删除,只保留对该样本进行了准确判断的分类器,完成对被选中的高信息量样本的学习工作,直到剩下一个优化的分类器。
在系统更新这一模块,得到一个优化的分类器,此时如果outbin里面的未知类型的流量个数达到预定值就进行聚类操作,将得到的聚类进行人工标注,标注后和主动学习得到的优化的分类器进行合并得到一个更加类型丰富的分类器。然后将该分类器替换原来的分类器去实现分类任务。最后,同样也需要重新训练稀疏自编码器,以便满足发现的新类型的网络流量。
本发明的基于主动学习的鲁棒性网络流量分类系统,具体包括流量分类以及未知类型流量的发现模块、主动学习过程模块和系统更新模块;其中,
流量分类以及未知流量类型发现模块,用于实现对应用流量类型的分类识别;流量分类以及未知流量类型发现模块由基于机器学习的未知流量检测模块和流量分类模块,以及基于神经网络的数据降维模块组成;其中,基于机器学习的未知流量检测模块用于对待检测的流量中提取出中不属于已知分类器类型的流量;
流量分类模块用于对流量分类。
基于神经网络的数据降维模块用于通过correntropy改进损失函数的稀疏自编码器来对待检测的流量进行数据降维处理。其中,进行数据降维处理的过程为:利用两层隐藏节点并且每一层的节点都是100,最终由249维的数据降为100维,以此达到一个相对较好的效果。
主动学习模块用于优化分类器,在流量分类以及未知流量类型发现模块对样本分类的同时,如果样本是确定的一种类型,则将该样本加入分类器的训练集中,增加样本数量;如果不是确定的一种类型,则对模型树进行分支,等分支数量达到阈值16时,在产生异常的样本中选择信息量最大的一个队模型树进行剪枝;
系统更新模块用于首先将流量分类以及未知流量类型发现模块分类过程中检测到的未知类型的流量通过dbscan(density-basedspatialclusteringofapplicationswithnoise)聚类算法进行聚类,然后将聚类的新类型进行标注。
参见图1,基于上述主动学习的鲁棒性网络流量分类系统的实现方法,包括以下步骤:
第一步,将采集的网络流流量通过稀疏自编码器进行降维;通过correntropy改进损失函数的稀疏自编码器来对待检测的流量,利用两层隐藏节点并且每一层的节点都是100,最终由249维的数据降为100维。具体过程如下:本发明中correntropy改进损失函数,简称clf。
传统的稀疏自编码器损失函数为jcost(θ)=jmse(θ)+jweight(θ)+jsparse(θ)。
第一项为基于均方差的重构损失函数,其计算公式为:
第二项为权重衰减,用于防止过拟合,其表达式为:
第三项为稀疏惩罚项,其表达式为:
虽然mse可以对异常值比较敏感,本发明使用了一个更加鲁棒性的损失函数来提升效果和去除噪声(correntropyinducedlossfunction,clf)。本质上,clf是在rkhs(reproducingkernelhilbertspace)上的一种mse。与传统稀疏自编码器相比,一般来说,mse用来构建损失函数,kl散度用来作为惩罚项。本发明中的的损失函数和惩罚项都是基于clf来构建的。其表达式为:
jcsae(θ)=jclf1(θ)+jweight(θ)+jclf2(θ)
其中:jclf1(θ)=clf(s,t)=β[1-e(kσ(s,t))]jclf2(θ)=clf(θ,0)
其中,β为常量系数。kσ为核函数;
s,t是两个样本s,t∈rm×n
s=[s1,s2,...,sn]t=[t1,t2,...,tn]
第二步,选取有标签的样本作为训练集生成一个初始的分类器,并计算初始的分类器中每一类型的阈值;
第三步:用未标签的样本通过主动学习的方法生成分类模型(modeltree),同时进行异常点检测,并将未标签的数据放入异常点集合;具体过程如下:
对于一个新的样本,需要和初始的分类器中每一种类型进行相似度的计算,得到相似度阈值;将初始的分类器中每一类型的阈值与相似度阈值进行比较,若是新的样本符合其中一个类型,则将新的样本判别为该类型,若是新的样本符合多个类型,则进行分支,生成modeltree,并将该新的样本放入一个集合中,若是新的样本不符号任何一种类型,则加入异常点集合(outbin)。
第四步,当分类模型的最大分支达到阈值时,从集合中选取信息量最大的样本;将选取出来的样本让操作员标记样本类型,并且对分类模型进行剪枝,得到优化后的分类器;其中阈值为16;具体过程为:分类器间关于某一流量样本产生分歧的数量通过各分类器赋予该流量的类型标签(label)的熵(entropy)来量化;
令专家委员会(qbc)中第jth个分类器赋予流量x的类型标签为y(j)(x),建立一个分类器委员会投票的直方图,计算类型标签label(x)的熵,则共有m个成员的专家委员会中类型标签分布为:
其中,δ为克罗内克函数(kroneckerdelta),l为样本x对应的标签label。
则流量x的香农熵(shannonentropy)为:
选择查询的流量对象为:
通过查询得到的流量x进行剪枝,得到优化后的分类器。
第五步:当异常点集合(outbin)的数量达到阈值时通过dbscan聚类算法进行新类型发现,用发现的新类型更新分类器。其中,阈值为200;具体过程为:首先将分类过程中检测到的未知类型的样本通过dbscan聚类算法进行聚类,而且dbscan聚类算法里面采用的并非传统的欧氏距离而是相互关系熵,然后将聚类的新类型样本进行标注,将优化后的分类器和已经标注的聚类的新类型进行整合,得到一个有新类型的优化的分类器。
本发明具有以下优点:
1.基于机器学习的未知类型流量检测算法和流量分类算法,提高了流量分类的准确性,此应用分类架构能够更加灵活的应对成爆炸性增长的应用类型。
2.由于网络流量都是高维数据,如果直接用来进行实验,实验效果表现一般,这里就通过改进的稀疏自编码器来进行数据降维,使数据有一个更好的表达。
- 还没有人留言评论。精彩留言会获得点赞!