故障告警处理方法、系统及计算机可读存储介质与流程
本发明涉及故障运维技术领域,尤其涉及一种故障告警处理方法、系统及计算机可读存储介质。
背景技术
网络设备或应用发生故障通常都可以通过在线监控方式及时获得告警。当发生告警时,现有技术通常是直接提示存在故障,然后让运维人员前往检测确定故障原因并分析出故障排除方案后再排除故障,前前后后可能需要花费很长时间,进而时效性不高。
技术实现要素:
本发明的主要目的在于提供一种故障告警处理方法、系统及计算机可读存储介质,旨在解决如何提高故障告警处理时效的技术问题。
为实现上述目的,本发明提供一种故障告警处理方法,所述故障告警处理方法包括以下步骤:
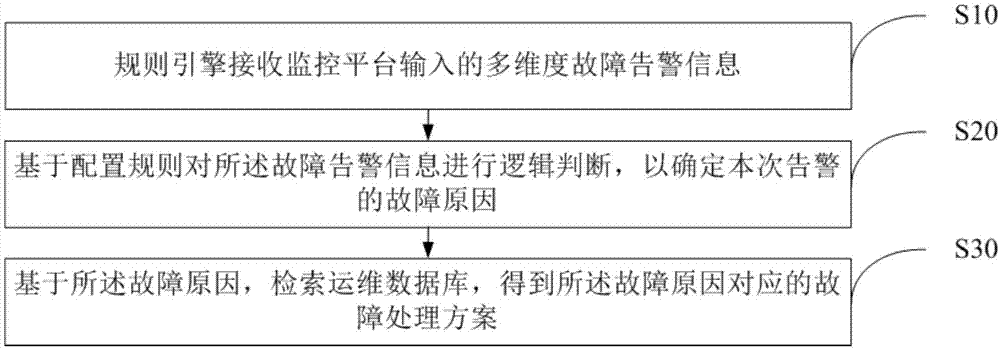
规则引擎接收监控平台输入的多维度故障告警信息;
基于配置规则对所述故障告警信息进行逻辑判断,以确定本次告警的故障原因;
基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案。
可选地,所述基于配置规则对所述故障告警信息进行逻辑判断,以确定本次告警的故障原因的步骤包括:
将多维度的告警信息与配置规则进行比较,以在配置规则中查找与多维度的告警信息相同字段的信息;
根据预设的信息与故障原因的映射关系,确定查找的所述信息对应的故障原因。
可选地,在所述基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案的步骤之后,所述故障告警处理方法包括:
基于对应的自动处理方案自动化处理对应故障点,其中,自动化处理包括自动恢复故障点或自动隔离故障点。
可选地,在故障原因是预设操作时,所述基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案的步骤之后,所述故障告警处理方法包括:
调用机器人对预设操作自动生成审批单,以将审批单发送至预设节点进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
可选地,在所述基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案的步骤之后,所述故障告警处理方法还包括:
根据所述故障告警信息、所述故障原因以及所述故障处理方案,生成本次告警的不同通知话术;
调用机器人将所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
可选地,在所述调用机器人将所述通知话术分别推送至对应的合作方与运维方各自所在的通知群的步骤之后,所述故障告警处理方法还包括:
在故障恢复期间,所述规则引擎缓存相同的故障告警信息;
生成故障恢复进展通知,并每隔预设时长将所述故障恢复进展通知推送至对应的合作方所在的通知群。
可选地,所述故障告警处理方法还包括:
在接收监控平台输入的多维度故障告警信息时,所述规则引擎还从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,以供精确定位本次告警的故障原因。
可选地,在所述规则引擎接收监控平台输入的多维度故障告警信息的步骤之前,所述故障告警处理方法还包括:
所述监控平台收集多种告警源上报的故障告警信息以进行关联告警,其中,所述告警源类型包括:主机、网络、数据库、平台、应用程序;
基于预设的阈值判断规则,将高于预设阈值的故障告警信息输入所述规则引擎。
进一步地,为实现上述目的,本发明还提供一种故障告警处理系统,所述故障告警处理系统包括:
监控平台,用于向规则引擎输入多维度故障告警信息;
规则引擎,用于基于配置规则对所述故障告警信息进行逻辑判断,以确定本次告警的故障原因;基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案。
可选地,所述规则引擎还用于:基于对应的自动处理方案自动化处理对应故障点,其中,自动化处理包括自动恢复故障点或自动隔离故障点。
可选地,在故障原因是预设操作时,所述规则引擎还用于:调用机器人对预设操作自动生成审批单,以将审批单发送至预设节点进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
可选地,所述规则引擎还用于:根据所述故障告警信息、所述故障原因以及所述故障处理方案,生成本次告警的不同通知话术;调用机器人将所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
可选地,所述规则引擎还用于:
在故障恢复期间,缓存相同的故障告警信息;
生成故障恢复进展通知,并每隔预设时长将所述故障恢复进展通知推送至对应的合作方所在的通知群。
可选地,所述规则引擎还用于:
在接收监控平台输入的多维度故障告警信息时,还从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,以供精确定位本次告警的故障原因。
可选地,所述监控平台还用于:
收集多种告警源上报的故障告警信息以进行关联告警,其中,所述告警源类型包括:主机、网络、数据库、平台、应用程序;
基于预设的阈值判断规则,将高于预设阈值的故障告警信息输入所述规则引擎。
可选地,所述故障告警处理系统还包括:
机器人,用于在接收到所述规则引擎的调用请求时,将所述规则引擎输出的所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
进一步地,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有故障告警处理程序,所述故障告警处理程序被处理器执行时实现如上述任一项所述的故障告警处理方法的步骤。
本发明将多种告警源输出的多个维度的故障告警信息输入规则引擎中进行一系列复杂的逻辑判断,进而实现故障原因的快速运算,提高故障处理的时效性。本发明还能在告警的同时,进一步自动检索出对应的故障处理方案,进而从整体上提高了告警的时效性,缩短了故障定位时间。
附图说明
图1为本发明故障告警处理方法第一实施例的流程示意图;
图2为本发明故障告警处理方法第二实施例的流程示意图;
图3为本发明故障告警处理方法第三实施例的流程示意图;
图4为本发明故障告警处理方法第四实施例的流程示意图;
图5为本发明故障告警处理系统第一实施例的功能模块示意图;
图6为本发明故障告警处理系统第二实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明提供一种故障告警处理方法。
参照图1,图1为本发明故障告警处理方法第一实施例的流程示意图。本实施例中,所述故障告警处理方法包括以下步骤:
步骤s10,规则引擎接收监控平台输入的多维度故障告警信息;
本实施例中,规则引擎可基于内置的规则对输入的参数进行逻辑判断并输出判断结果。可选使用experian规则引擎定义函数,编写脚本,创建用于故障告警信息综合运算规则,进而可对多维度故障告警信息进行逻辑判断。
本实施例对于监控平台的具体设置不限,可选为基于falcon框架进行二次开发和配置所生成的监控平台,该监控平台可以收集多种告警信息并实现秒级告警。
为实现对告警故障原因的准确判断,本实施例中优选通过多种维度的故障告警信息进行全故障告警分析。多个维度体现在,通过监控平台收集主机、网络、数据库、平台以及各种应用程序上产生的告警信息,从而覆盖所有可能的故障原因,提升故障告警分析的准确性,进而节省告警分析事件,提高告警处理时效。
进一步可选的,为丰富告警源信息,进而使规则引擎拥有更全面信息定位故障根源,因此,在接收监控平台输入的多维度故障告警信息时,规则引擎还从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,以供精确定位本次告警的故障原因。其中,从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,是通过拉取应用中的关键字以确定应用类告警信息。本实施例中,需要说明的是,虽然监控平台和告警平台都会从应用中获取应用类告警信息,但是监控平台抓取的是系统运行中的一些物理指标等告警信息,而告警平台拉取的是系统运行中的日志及各交易量,时延、成功率及上报的异常等告警信息。
应理解,监控平台从主机、网络、数据库、平台等位置收集告警信息时,主机、网络、数据库、平台和java虚拟机等位置产生的告警信息是基础级别的告警信息,告警信息获取的维度较为单一,虽然监控平台也能从应用中拉取部分告警信息,但是拉取的信息仅仅是一些物理指标。本实施例中,通过规则引擎从告警平台拉取的告警信息是应用级别的告警信息,并且拉取的告警信息类型更加丰富,通过两种不同级别的告警信息的获取,可以提高定位本次告警的故障原因的精确度。
步骤s20,基于配置规则对所述故障告警信息进行逻辑判断,以确定本次告警的故障原因;
本实施例中,规则引擎基于内置的告警评判规则,快速对多维故障告警信息进行逻辑判断,在本实施例中,所述步骤s20的实施方式包括:
1)方式一、将多维度的告警信息与配置规则进行比较,以在配置规则中查找与多维度的告警信息相同字段的信息;
根据预设的信息与故障原因的映射关系,确定查找的所述信息对应的故障原因。
2)方式二、在多维度的告警信息中,根据各个维度的告警信息确定出现故障的源头,该源头为主机、网络、数据库、平台或应用中的任一个或多个;
当产生故障的源头为1个时,将该源头产生的故障原因作为本次告警的故障原因;
当产生故障的源头包括多个时,对每个源头产生告警信息中的各个子模块进行分析,以确定每个源头产生的故障原因的最终分值,将最终分值最高的源头对应的故障原因作为本次告警的故障原因。其中,对源头产生告警信息中的各个子模块进行分析,以确定源头产生的故障原因的最终分值的方式包括:识别该源头的各个子模块产生的告警信息的权重值以及实际值,根据各个子模块的产生的告警信息的权重值和实际值,计算出该源头的最终分值。
可以理解,由于告警信息维度较多,因此通过逻辑判断得出的故障原因可能存在多个,因此,在本实施方式下,优选规则引擎通过对每一种子模块的故障原因进行综合权重评分并排序,从而输出本次告警最准确的故障原因。例如,系统合作方a的公网丢包率大于30%,所在位置为广州,同时,系统合作方b、c的公网丢包率大于50%,所在位置也为广州。此刻同时还有应用合作方存在交易成功率下降的告警,因此,最终规则引擎综合所有维度的故障告警信息进行逻辑运算,发现广州地区公网丢包率这个故障原因的分数最高,从而得出本次报警最有可能的故障原因为广州地区的公网异常而非因系统自身故障导致交易成功率下降;另如,业务系统因sql(structuredquerylanguage,结构化查询语言)执行效率低并且返回大结果集,从而产生数据库慢查询,数据库io(input/output)异常,java虚拟机指标异常,拖慢了整个业务处理效率,上下游系统平均时延增加,成功率下降,通过规则引擎判断出产生问题的源系统,再对源原系统的各项告警指标加权(如数据库io,cpu及jvm的gc时间,队列深度告警权重依次递减,并且高于业务系统时延及成功率等告警),最终对各项告警指标进行加权平均得到源系统的最终分值,并将最终分值最高的源系统的故障原因作为本次告警的故障原因。
步骤s30,基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案。
本实施例中,为实现告警故障的快速排除,规则引擎在确定故障原因的同时还给出相应的故障处理方案。优选设有运维数据库且该运维数据库中存储有涵盖所有可能的故障原因对应的处理方案(运维标准作业程序sop(standardoperatingprocedure))。
在本实施中,所述故障处理方案可选为手动处理方案和自动处理方案,其中,采用自动处理方案处理的方式为:基于对应的自动处理方案自动化处理对应故障点以恢复系统,自动化处理包括自动恢复故障点或自动隔离故障点,具体地:根据确定的故障处理方案调用到对应的脚本,通过所述脚本将产生故障原因的节点进行隔离,然后将所述节点中处理事情的状态dowm下来,去分析代码程序段,以判断实际的原因,其中,原因包括磁盘过满、主机故障等,最终根据实际的原因与处理手段的映射关系,确定实际的原因对应的处理手段,并执行所述处理手段。例如,在实际的原因为磁盘过满时,若磁盘过满对应的处理手段是自动清除缓存,则执行自动清除缓存的方式进行磁盘清理;又如java程序运行中出现线程死锁情况,在自动发现问题后可自动隔离对应结点。
规则引擎通过检索数据库中存储的运维sop,进而可获得故障原因对应故障处理方案,并实现告警信息+故障原因+故障处理方案的组合输出,从而提升故障全流程处理的高时效性。相比传统电子版sop存在不同目录的txt、word、excel中而获取不便,即使各sop统一存放,但在故障发生时也不方便检索,而本实施例的故障全流程处理可极大缩短故障恢复时间,提高运维效率。例如,同一时刻存在n个系统告警,规则引擎通过逻辑判断得出告警的根本故障原因为某个城市xx运营商公网异常,并检索运维数据库,通过异常ip+系统名称而匹配到对应sop。
此外,在故障原因是预设操作时,所述步骤s30之后,所述方法还包括:
调用机器人对预设操作自动生成审批单,以将审批单发送至预设节点进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
其中,所述预设操作包括删除数据,隔离多个结点,重启核心系统等高危操作,在故障原因是高危操作时,调用机器人对这些高危操作自动生成审批单,再将审批单发送至预设节点(可选为领导节点)进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
本实施例将多种告警源输出的多个维度的故障告警信息输入规则引擎中进行一系列复杂的逻辑判断,进而实现故障原因的快速运算,提高故障处理的时效性。本实施例还能在告警的同时,进一步自动检索出对应的故障处理方案,进而从整体上提高了告警的时效性,缩短了故障定位时间。
参照图2,图2为本发明故障告警处理方法第二实施例的流程示意图。基于上述第一实施例,本实施例中,在上述步骤s30之后,所述故障告警处理方法还包括:
步骤s40,根据所述故障告警信息、所述故障原因以及所述故障处理方案,生成本次告警的不同通知话术;
步骤s50,调用机器人将所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
本实施例中,规则引擎在获得了故障告警信息、故障原因以及故障处理方案后,需要将上述信息推送给合作方与运维方。为便于合作方与运维方能够简便故障详情,规则引擎进一步将故障告警信息、故障原因以及故障处理方案按照设定格式整理为相应的通知话术。
本实施例中,先搭建合作方通知群以及运维方通知群(不同的产品分别搭建不同的合作方通知群,或者不同的运维方通知群),比如微信群,然后再通过接口调用机器人(一种应用程序),如微信的wechat机器人,通过机器人识别规则引擎所推送的本次告警的通知话术具体对应的通知群,然后再分类推送到对应合作方通知群和运维方通知群。
本实施例将多种告警源输出的多个维度的故障告警信息输入规则引擎中进行一系列复杂的逻辑判断,进而实现故障原因与故障处理方案的快速运算,提高故障处理的时效性,最后再将故障信息分别推送到对应的合作方与运维方各自所在的通知群中,本实施例能在告警的同时,进一步提供故障处理方案以及实现与合作方之间交易的主动预警,进而从整体上提高了告警的时效性,缩短了故障定位时间以及提升了对合作方的服务质量。
参照图3,图3为本发明故障告警处理方法第三实施例的流程示意图。基于上述第二实施例,本实施例中,在上述步骤s50之后,所述故障告警处理方法还包括:
步骤s60,在故障恢复期间,所述规则引擎缓存相同的故障告警信息;
步骤s70,生成故障恢复进展通知,并每隔预设时长将所述故障恢复进展通知推送至对应的合作方所在的通知群。
本实施例中,由于故障告警通常都是实时采集实时上报的,因此,为避免告警长时间刷屏,在故障恢复期间,规则引擎缓存相同的故障告警信息,同时生成故障恢复进展通知,并每隔预设时长通知合作方有关故障恢复的进展通知,避免告警信息长时间刷屏,降低了规则引擎的处理压力,并且更好提升对合作方的服务质量,提升客户满意度。
参照图4,图4为本发明故障告警处理方法第四实施例的流程示意图。基于上述第一实施例,本实施例中,在上述步骤s10之前,所述故障告警处理方法还包括:
步骤s80,所述监控平台收集多种告警源上报的故障告警信息以进行关联告警,其中,所述告警源类型包括:主机、网络、数据库、平台、应用程序;
本实施例中,为实现多维度、全范围的故障告警分析,监控平台收集多种告警源的故障告警信息并进行汇总后上报规则引擎进行处理。
本实施例中,告警源类型包括:
(1)主机,比如计算机、服务器等发生的告警;
(2)网络,比如互联网网络发生的告警,如断网、丢包率等;
(3)数据库,比如各种产品的数据库、交易账户数据库等发生的告警;
(4)平台,比如消息中间件平台、服务管理平台等发生的告警;
当监控平台收集到多种故障告警信息时,由于这多种告警故障信息是同一种故障原因产生的信息,因此在各种故障告警信息中找到相同的标志位信息(如字段xx),根据该相同的标志位信息将收集的多种故障告警信息进行关联告警。
(5)应用程序,比如账户应用、支付应用等发生的告警。
步骤s90,基于预设的阈值判断规则,将高于预设阈值的故障告警信息输入所述规则引擎。
通常,告警对系统的影响有大有小,如果影响较小甚至几乎不会有任何影响,则此类告警是无需上报的。因此,本实施例中,预先设有各种告警的判断阈值,通过配置相应的判断规则,实现秒级输出高于阈值的异常故障信息到规则引擎。
例如,公网丢包率大于50%,则该类告警信息需要上报;主机磁盘使用空间率到达50%,则该类告警信息需要上报;cpu利用率超过70%,则该类告警信息需要上报。
在本实施例中,通过预设的阈值判断机制,以过滤出高于预设阈值的故障告警信息进行告警处理,避免了所有告警信息都上报给规则引擎处理,降低了规则引擎的处理压力。
本发明还提供一种故障告警处理系统。
参照图5,图5为本发明故障告警处理系统第一实施例的功能模块示意图。本实施例中,所述故障告警处理系统包括:
监控平台10,用于向规则引擎输入多维度故障告警信息;
本实施例对于监控平台的具体设置不限,可选为基于falcon框架进行二次开发和配置所生成的监控平台,该监控平台可以收集多种告警信息并实现秒级告警。
进一步可选的,为丰富告警源信息,进而使规则引擎拥有更全面信息定位故障根源,因此,在接收监控平台输入的多维度故障告警信息时,规则引擎还从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,以供精确定位本次告警的故障原因。
其中,从指定的告警平台拉取与本次告警相关联的告警源的所有应用类告警信息,是通过拉取应用中的关键字以确定应用类告警信息。本实施例中,需要说明的是,虽然监控平台和告警平台都会从应用中获取应用类告警信息,但是监控平台抓取的是系统运行中的一些物理指标等告警信息,而告警平台拉取的是系统运行中的日志及各交易量,时延、成功率及上报的异常等告警信息。
应理解,监控平台从主机、网络、数据库、平台等位置收集告警信息时,主机、网络、数据库、平台和java虚拟机等位置产生的告警信息是基础级别的告警信息,告警信息获取的维度较为单一,虽然监控平台也能从应用中拉取部分告警信息,但是拉取的信息仅仅是一些物理指标。本实施例中,通过规则引擎从告警平台拉取的告警信息是应用级别的告警信息,并且拉取的告警信息类型更加丰富,通过两种不同级别的告警信息的获取,可以提高定位本次告警的故障原因的精确度。
规则引擎20,用于基于配置规则对所述故障告警信息进行逻辑判断,以确定本次告警的故障原因;基于所述故障原因,检索运维数据库,得到所述故障原因对应的故障处理方案;
本实施例中,规则引擎可基于内置的规则对输入的参数进行逻辑判断并输出判断结果。可选使用experian规则引擎定义函数,编写脚本,创建用于故障告警信息综合运算规则,进而可对多维度故障告警信息进行逻辑判断。
为实现对告警故障原因的准确判断,本实施例中优选通过多种维度的故障告警信息进行全故障告警分析。多个维度体现在,通过监控平台收集主机、网络、数据库、平台以及各种应用程序上产生的告警信息,从而覆盖所有可能的故障原因,提升故障告警分析的准确性,进而节省告警分析事件,提高告警处理时效。
本实施例中,规则引擎基于内置的告警评判规则,快速对多维故障告警信息进行逻辑判断,在本实施例中,具体实施方式包括:
1)方式一、将多维度的告警信息与配置规则进行比较,以在配置规则中查找与多维度的告警信息相同字段的信息;
根据预设的信息与故障原因的映射关系,确定查找的所述信息对应的故障原因。
2)方式二、在多维度的告警信息中,根据各个维度的告警信息确定出现故障的源头,该源头为主机、网络、数据库、平台或应用中的任一个或多个;
当产生故障的源头为1个时,将该源头产生的故障原因作为本次告警的故障原因;
当产生故障的源头包括多个时,对每个源头产生告警信息中的各个子模块进行分析,以确定每个源头产生的故障原因的最终分值,将最终分值最高的源头对应的故障原因作为本次告警的故障原因。其中,对源头产生告警信息中的各个子模块进行分析,以确定源头产生的故障原因的最终分值的方式包括:识别该源头的各个子模块产生的告警信息的权重值以及实际值,根据各个子模块的产生的告警信息的权重值和实际值,计算出该源头的最终分值。
可以理解,由于告警信息维度较多,因此通过逻辑判断得出的故障原因可能存在多个,因此,在本实施方式下,优选规则引擎通过对每一种子模块的故障原因进行综合权重评分并排序,从而输出本次告警最准确的故障原因。
例如,系统合作方a的公网丢包率大于30%,所在位置为广州,同时,系统合作方b、c的公网丢包率大于50%,所在位置也为广州。此刻同时还有应用合作方存在交易成功率下降的告警,因此,最终规则引擎综合所有维度的故障告警信息进行逻辑运算,发现广州地区公网丢包率这个故障原因的分数最高,从而得出本次报警最有可能的故障原因为广州地区的公网异常而非因系统自身故障导致交易成功率下降;另如,业务系统因sql(structuredquerylanguage,结构化查询语言)执行效率低并且返回大结果集,从而产生数据库慢查询,数据库io(input/output)异常,java虚拟机指标异常,拖慢了整个业务处理效率,上下游系统平均时延增加,成功率下降,通过规则引擎判断出产生问题的源系统,再对源原系统的各项告警指标加权(如数据库io,cpu及jvm的gc时间,队列深度告警权重依次递减,并且高于业务系统时延及成功率等告警),最终对各项告警指标进行加权平均得到源系统的最终分值,并将最终分值最高的源系统的故障原因作为本次告警的故障原因。
本实施例中,为实现告警故障的快速排除,规则引擎在确定故障原因的同时还给出相应的故障处理方案。优选设有运维数据库且该运维数据库中存储有涵盖所有可能的故障原因对应的处理方案(运维标准作业程序sop(standardoperatingprocedure))。
在本实施中,所述故障处理方案可选为手动处理方案和自动处理方案,其中,采用自动处理方案处理的方式为:基于对应的自动处理方案自动化处理对应故障点以恢复系统,自动化处理包括自动恢复故障点或自动隔离故障点,具体地:根据确定的故障处理方案调用到对应的脚本,通过所述脚本将产生故障原因的节点进行隔离,然后将所述节点中处理事情的状态dowm下来,去分析代码程序段,以判断实际的原因,其中,原因包括磁盘过满、主机故障等,最终根据实际的原因与处理手段的映射关系,确定实际的原因对应的处理手段,并执行所述处理手段。例如,在实际的原因为磁盘过满时,若磁盘过满对应的处理手段是自动清除缓存,则执行自动清除缓存的方式进行磁盘清理;又如java程序运行中出现线程死锁情况,在自动发现问题后可自动隔离对应结点。
规则引擎通过检索数据库中存储的运维sop,进而可获得故障原因对应故障处理方案,并实现告警信息+故障原因+故障处理方案的组合输出,从而提升故障全流程处理的高时效性。相比传统电子版sop存在不同目录的txt、word、excel中而获取不便,即使各sop统一存放,但在故障发生时也不方便检索,而本实施例的故障全流程处理可极大缩短故障恢复时间,提高运维效率。例如,同一时刻存在n个系统告警,规则引擎通过逻辑判断得出告警的根本故障原因为某个城市xx运营商公网异常,并检索运维数据库,通过异常ip+系统名称而匹配到对应sop。
此外,在故障原因是预设操作时,规则引擎还用于,调用机器人对预设操作自动生成审批单,以将审批单发送至预设节点进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
其中,所述预设操作包括删除数据,隔离多个结点,重启核心系统等高危操作,在故障原因是高危操作时,调用机器人对这些高危操作自动生成审批单,再将审批单发送至预设节点(可选为领导节点)进行审批,并在审批完成后自动执行所述审批单对应的操作过程。
本实施例将多种告警源输出的多个维度的故障告警信息输入规则引擎中进行一系列复杂的逻辑判断,进而实现故障原因的快速运算,提高故障处理的时效性。本实施例还能在告警的同时,进一步自动检索出对应的故障处理方案,进而从整体上提高了告警的时效性,缩短了故障定位时间。
进一步地,在本发明故障告警处理系统另一实施例中,所述规则引擎20还用于:
根据所述故障告警信息、所述故障原因以及所述故障处理方案,生成本次告警的不同通知话术;
调用机器人将所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
本实施例中,规则引擎在获得了故障告警信息、故障原因以及故障处理方案后,需要将上述信息推送给合作方与运维方。为便于合作方与运维方能够简便故障详情,规则引擎进一步将故障告警信息、故障原因以及故障处理方案按照设定格式整理为相应的通知话术。
本实施例中,先搭建合作方通知群以及运维方通知群(不同的产品分别搭建不同的合作方通知群,或者不同的运维方通知群),比如微信群,然后再通过接口调用机器人(一种应用程序),如微信的wechat机器人,通过机器人识别规则引擎所推送的本次告警的通知话术具体对应的通知群,然后再分类推送到对应合作方通知群和运维方通知群。
本实施例将多种告警源输出的多个维度的故障告警信息输入规则引擎中进行一系列复杂的逻辑判断,进而实现故障原因与故障处理方案的快速运算,提高故障处理的时效性,最后再将故障信息分别推送到对应的合作方与运维方各自所在的通知群中,本实施例能在告警的同时,进一步提供故障处理方案以及实现与合作方之间交易的主动预警,进而从整体上提高了告警的时效性,缩短了故障定位时间以及提升了对合作方的服务质量。
进一步可选的,在本发明故障告警处理系统一实施例中,所述规则引擎20还用于:
在故障恢复期间,缓存相同的故障告警信息;
生成故障恢复进展通知,并每隔预设时长将所述故障恢复进展通知推送至对应的合作方所在的通知群。
本实施例中,由于故障告警通常都是实时采集实时上报的,因此,为避免告警长时间刷屏,在故障恢复期间,规则引擎缓存相同的故障告警信息,同时生成故障恢复进展通知,并每隔预设时长通知合作方有关故障恢复的进展通知,避免告警信息长时间刷屏,降低了规则引擎的处理压力,并且更好提升对合作方的服务质量,提升客户满意度。
进一步可选的,在本发明故障告警处理系统另一实施例中,所述监控平台10还用于:
收集多种告警源上报的故障告警信息以进行关联告警,其中,所述告警源类型包括:主机、网络、数据库、平台、应用程序;
基于预设的阈值判断规则,将高于预设阈值的故障告警信息输入所述规则引擎。
本实施例中,为实现多维度、全范围的故障告警分析,监控平台收集多种告警源的故障告警信息并进行汇总后上报规则引擎进行处理。
本实施例中,告警源类型包括:
(1)主机,比如计算机、服务器等发生的告警;
(2)网络,比如互联网网络发生的告警,如断网、丢包率等;
(3)数据库,比如各种产品的数据库、交易账户数据库等发生的告警;
(4)平台,比如消息中间件平台、服务管理平台等发生的告警;
当监控平台收集到多种故障告警信息时,由于这多种告警故障信息是同一种故障原因产生的信息,因此在各种故障告警信息中找到相同的标志位信息(如字段xx),根据该相同的标志位信息将收集的多种故障告警信息进行关联告警。
(5)应用程序,比如账户应用、支付应用等发生的告警。
通常,告警对系统的影响有大有小,如果影响较小甚至几乎不会有任何影响,则此类告警是无需上报的。因此,本实施例中,预先设有各种告警的判断阈值,通过配置相应的判断规则,实现秒级输出高于阈值的异常故障信息到规则引擎。
例如,公网丢包率大于50%,则该类告警信息需要上报;主机磁盘使用空间率到达50%,则该类告警信息需要上报;cpu利用率超过70%,则该类告警信息需要上报。
在本实施例中,通过预设的阈值判断机制,以过滤出高于预设阈值的故障告警信息进行告警处理,避免了所有告警信息都上报给规则引擎处理,降低了规则引擎的处理压力。
参照图6,图6为本发明故障告警处理系统第二实施例的功能模块示意图。本实施例中,所述故障告警处理系统还包括:
机器人30,用于在接收到所述规则引擎的调用请求时,将所述规则引擎输出的所述通知话术分别推送至对应的合作方与运维方各自所在的通知群。
本实施例中,机器人30是一种应用程序,如wechat机器人。通过机器人30可实现告警通知的分类推送。
本实施例中预先搭建沟通群,比如根据产品分类而建立合作方沟通群,或者还可以建立不同产品对应的运维沟通群,然后激活机器人。比如,事先将机器人拉入通知群中,发送“激活”字样的指令即可一键式激活通知群。
本实施例中,机器人30可以识别规则引擎推送的各种类别的告警通知,然后分类推送到对应的合作方沟通群以及对应的运维方沟通群中。比如,机器人按照对应群id,将告警通知分别推送到对应的合作方沟通群以及运维方沟通群中。
本发明还提供一种计算机可读存储介质。
本发明中,计算机可读存储介质上存储有故障告警处理程序,所述故障告警处理程序被处理器执行时实现如上述任一项实施例中所述的故障告警处理方法的步骤。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器或者网络设备等)执行本发明各个实施例所述的方法。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!