一种带智能音箱的全息通信系统的制作方法
本发明涉及深度摄像、智能识别、360全息成像、全息通信领域,具体公开了一种带智能音箱的全息通信系统。
背景技术
随着科学技术的发展,激光技术以及智能识别技术等的不断进步,全息影像以及智能音箱等产品开始具备实用化以及商品化的基础。
智能音箱作为下一代智能家居的控制核心,语音操作输入口,有着广泛的前景。
全息影像是真正的三维立体影像,用户不需要佩戴带立体眼镜或其他任何的辅助设备,就可以在不同的角度裸眼观看立体的影像。然而现阶段的全息显示产品非常稀少,应用成果很少,仍然属于稀有的高科技玩物。
参见中国实用新型授权专利,授权公告号为cn107454483a,申请公布日为2017年12月8日,具体公开了一种全息成像音箱,具体包括:扬声器、箱体、主控板、显示屏、全息成像板、遮光板;可以通过该全息成像音箱实现全系图像的显示以及传统音响的功能,但是不具备全息通信以及智能音箱的功能,功能单一,推广价值很小。
随着网络以及数字技术的发展,视频通讯已经成为了人们日常交流的重要手段,随着互联网服务成本的降低、数字设备的普及与小型化、国家5g通信技术的发展,已经具备了通信技术进一步升级的基础。
然而,全息通信的现状还没有被大多数人所了解,仍将全息通信以及全息显示功能当作科幻电影中可望不可即的高科技,市面上也没有该功能的产品,更进一步的通过虚拟三维形象交流的功能也没有。
技术实现要素:
为了克服现有的三维通信设备缺乏、三维通信功能单一的问题,本发明提供一种带智能音箱的全息通信系统,将智能音箱、全息显示设备、全息通信系统集成在一个产品中,一台设备即可实现人们所需的各种功能。
本发明采用的技术方案是:一种带智能音箱的全息通信系统,包括箱体、扬声器、功放、主控板、360全息成像组件、电源模块,所述箱体正面还设有深度摄像头,箱体内部设有全向麦克风,深度摄像头、全向麦克风、功放、360全息成像组件分别与主控板相连,扬声器与功放相连,电源模块与主控板、功放、360全息成像组件和全向麦克风的供电接口相连;所述主控板包括:
全息显示模块,包括gpu电路,用于控制360全息成像组件,将全息视频信号显示成全息图像;
语音识别模块,用于识别全向麦克风收集到的音频信号,并从中识别出语音信号并转换成数字逻辑信号;
智能ai模块,采用神经网络算法,用于智能语音应答以及智能全息形象交互的智能程序判断;
全息摄像模块,用于通过深度摄像头采集图像以及深度信息,通过软件以及gpu的处理,形成全息视频信号;
网络通信模块,用于连接无线网络或有线网络并接入互联网,以实现即时通信以及各类互联网在线服务;
动作捕捉模块,用于通过软件从全息视频信号中智能识别人物的动作与表情数据,生成对应的三维节点运动数据;
智能全息模块,用于通过智能ai模块判断的交互全息影像需要显示的动作与表情,根据预设程序生成对应的三维节点运动数据;
虚拟形象模块,用于将预设或者自定义的虚拟三维形象套用捕获的或生成的三维节点运动数据发送或者显示出来;
智能语音形象模块,用于在智能应答以及智能对话时,将逻辑指令以及文字信息转换成语音音频信号;
声音播放模块,用于通过功放与扬声器播放声音信号。
优选的,所述360全息成像组件设在箱体的上方或者下方。
优选的,所述箱体的4个侧面均设有连通箱体内外且用于全向麦克风收集各方向的声音信号的开口。
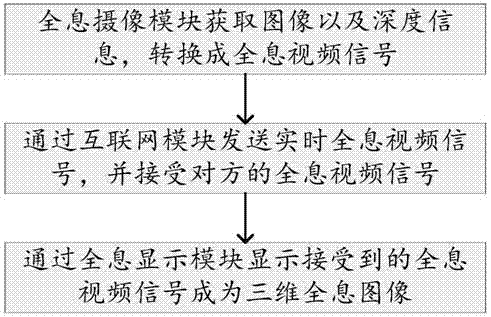
优选的,所述全息通信系统的实现方法包括步骤:
a1.全息摄像模块获取图像以及深度信息,转换成全息视频信号;
a2.通过网络通信模块发送实时全息视频信号,并接受对方的全息视频信号;
a3.通过全息显示模块将接受到的全息视频信号显示成三维全息图像。
优选的,所述的全息通信系统实现三维虚拟形象通信的方法包括步骤:
b1.全息摄像,全息摄像模块获取图像以及深度信息,转换成全息视频信号;
b2.动作识别,动作捕捉模块对全息视频信号进行识别,从中智能识别人物动作与表情信息,生成对应的三维节点运动数据,并根据预设的通信模式执行b3或b4;
b3.动作数据交互模式,通过互联网发送三维节点运动数据,接收方的设备将三维节点运动数据套用到虚拟形象并显示;
b4.虚拟影像交互模式,将三维节点运动数据套用到虚拟形象,并编码成全息视频信号,通过互联网发送虚拟形象的全息视频信号。
优选的,所述的全息通信系统实现三维形象智能交互的方法包括步骤:
c1.通过语音识别模块采集用户的语音信号,通过全息摄像模块拍摄用户的全息影像,通过动作捕捉模块生成对应的三维节点运动数据;
c2.通过智能ai模块根据语音信号以及三维节点运动数据理解用于表达的互动信息,并智能生成应答的语音信号以及三维节点运动数据;
c3.三维节点运动数据导入虚拟形象模块生成对应的虚拟形象,语音信号导入智能语音形象模块生成对应的语音输出。
本发明的有益效果是:提供了一种可以实现远程全息通信的设备和方法,全息通信即可使用真实的全息摄影图像,亦可采用预设的三维虚拟形象通过动作捕捉识别功能来实现全息虚拟形象沟通以及智能交互,相比于真实影像更生动有趣、真实可亲,且丰富多变。集全息显示、智能音箱等功能于一体,可以作为未来的新一代多功能家用主机的雏形与智能家居的主控核心。
附图说明
图1是本发明的全息通信流程图。
图2是本发明的三维虚拟形象通信流程图。
图3是本发明的硬件架构图。
图4是本发明的硬件结构示意图。
图中:1、360全息成像组件,2、深度摄像头,3、扬声器,4、全向麦克风,5、箱体。
具体实施方式
参见图3和图4,本发明是一种带智能音箱的全息通信系统,包括箱体5、扬声器3、功放、主控板、360全息成像组件1、电源模块,其特征是:所述箱体5正面还设有深度摄像头2,箱体5内部设有全向麦克风4,深度摄像头2、全向麦克风4、功放、360全息成像组件1分别与主控板相连,扬声器3与功放相连,电源模块与主控板、功放、360全息成像组件1和全向麦克风4的供电接口相连;主控板包括cpu电路、gpu电路、apu电路、无线网络模块和存储器。
主控板以及内置程序根据功能可以划分为下列模块:
全息显示模块,包括gpu电路,用于控制360全息成像组件(1),将全息视频信号显示成全息图像;
语音识别模块,用于识别全向麦克风(4)收集到的音频信号,并从中识别出语音信号并转换成数字逻辑信号;
智能ai模块,采用神经网络算法,用于智能语音应答以及智能全息形象交互的智能程序判断;
全息摄像模块,用于通过深度摄像头(2)采集图像以及深度信息,通过软件以及gpu的处理,形成全息视频信号;
网络通信模块,用于连接无线网络或有线网络并接入互联网,以实现即时通信以及各类互联网在线服务;
动作捕捉模块,用于通过软件从全息视频信号中智能识别人物的动作与表情数据,生成对应的三维节点运动数据;
智能全息模块,用于通过智能ai模块判断的交互全息影像需要显示的动作与表情,根据预设程序生成对应的三维节点运动数据;
虚拟形象模块,用于将预设或者自定义的虚拟三维形象套用捕获的或生成的三维节点运动数据发送或者显示出来;
智能语音形象模块,用于在智能应答以及智能对话时,将逻辑指令以及文字信息转换成语音音频信号;
声音播放模块,用于通过功放与扬声器(3)播放声音信号。
本发明集全息显示、智能音箱等功能于一体,硬件基础具有极大的兼容性以及拓展性,可以作为未来的新一代多功能家用主机的雏形与智能家居的主控核心。
360全息成像组件1设在箱体5的上方或者下方。360全息成像,是由透明材料制成的四面锥体,利用分光镜成像原理,对产品实拍三维建模后将产品影像或三维模型叠加进场景中,不需任何辅助设备即可观看三维画面。该系统展示的三维图像细节丰富,立体感好。当观众的视线透过椎体的一个面时,通过表面镜射和反射,能够从椎体内的空间里看到自由飘浮的影像。
箱体5的四个侧面均设有连通箱体5内外且用于全向麦克风4收集各方向的声音信号的开口。开口处可以假装防尘网或采用防尘设计。扬声器3可以设置在箱体5的正面,也可以在两侧甚至四面均设有扬声器3。
参见图1,通过本发明实现全息通信系统的方法包括步骤如下:
a1.全息摄像模块获取图像以及深度信息,转换成全息视频信号;
a2.通过网络通信模块发送实时全息视频信号,并接受对方的全息视频信号;
a3.通过全息显示模块将接受到的全息视频信号显示成三维全息图像。
深度摄像头除了具备摄像头的图像采集功能以外,还可以同时采集场景画面的与摄像头的距离信息,现有比较成熟的方案是包括一个rgb摄像头+结构光投射器(红外)+结构光深度感应器(cmos),通过软件以及图像处理器的处理,即可得到全息影像数据。
参见图2,通过本发明实现全息通信系统实现三维虚拟形象通信的方法包括步骤如下:
b1.全息摄像,全息摄像模块获取图像以及深度信息,转换成全息视频信号;
b2.动作识别,动作捕捉模块对全息视频信号进行识别,从中智能识别人物动作与表情信息,生成对应的三维节点运动数据,并根据预设的通信模式执行b3或b4;
b3.动作数据交互模式,通过互联网发送三维节点运动数据,接收方的设备将三维节点运动数据套用到虚拟形象并显示;
b4.虚拟影像交互模式,将三维节点运动数据套用到虚拟形象,并编码成全息视频信号,通过互联网发送虚拟形象的全息视频信号。
全息通信系统实现三维形象智能交互的方法包括步骤:
c1.通过语音识别模块采集用户的语音信号,通过全息摄像模块拍摄用户的全息影像,通过动作捕捉模块生成对应的三维节点运动数据;
c2.通过智能ai模块根据语音信号以及三维节点运动数据理解用于表达的互动信息,并智能生成应答的语音信号以及三维节点运动数据;
c3.三维节点运动数据导入虚拟形象模块生成对应的虚拟形象,语音信号导入智能语音形象模块生成对应的语音输出。
虚拟形象可以预先设计,虚拟形象的三维骨架各关节节点以及表情节点可以根据系统采集的用户动作表情或者智能ai模块计算出的三维节点运动数据灵活变换。虚拟形象可以自定义,且可以打包进行共享。
虚拟形象通信可以避免由于单独的深度摄像头导致采集不到人物背面的全息而使三维形象只有正面部分的问题,相比于真实影像更生动有趣、真实可亲,且丰富多变。
- 还没有人留言评论。精彩留言会获得点赞!