一种基于演化博弈的网络切片接入强化学习方法与流程
本发明属于5g无线网络领域的网络切片选择技术领域,主要涉及到一种基于演化博弈的网络切片接入强化学习方法。
背景技术:
现如今网络信息技术发展越来越快,随着5g网络商用在即,整个无线通信网络的运营进入了铁塔模式,运营商们将共享不断成立的铁塔公司的基站服务,根据性能要求最大化其承载负载。
网络切片技术作为5g网络提供的一种重要手段,引起了业界和学术界的极大兴趣。网络切片主要运用网络功能虚拟化和软件自定义网络技术构建一个用户需要的逻辑网络,该技术能够解决最大化网络容量的问题。网络切片技术可以针对不同网络用户的需求提供不同的网络服务功能,它还可以使网络拥有高安全性、低时延、高吞吐量等特性;另外,网络切片技术可以延长网络的运营周期,便于网络管理,有效降低运营商的投入成本。
目前针对网络切片技术的研究越来越多,一些国际专家提出了一种基于生物发育和进化机制来调节无线接入点的方法,针对多租户异构云无线接入网(h-cran)的网络切片研究也已经处于起步阶段,为了解决网络切片和访问控制的问题,部分专家提出基于三个步骤的启发式算法:频谱分配,访问控制,以及空间复用。在cran架构的公开空口和灵活sdn控制器上设计和实现网络切片的原型系统。但是网络切片技术还存在诸多实现难点,比如:如何有效地实现无线网络的资源虚拟化;如何接入不同的运营商切片网络切片等。
技术实现要素:
针对多运营商网络接入问题,本发明提供了一种基于演化博弈的网络切片接入强化学习方法,通过分布式q_learning强化学习不断更新系统q值,提高网络效用,使用户获得更好的体验。
为解决上述技术问题,本发明采用了如下技术手段:
一种基于演化博弈的网络切片接入强化学习方法,在多运营商无线网络场景下,用户终端可以选择单个或多个网络切片接入,所有的网络切片接入策略构成一个网络切片接入策略集合k,k={k1,...,ki,...,kt},ki表示选择网络切片i,ki∈k,i=1,...,t,t是网络切片总个数。本方法具体包括以下步骤:
s1、选择初始网络切片接入策略,得到网络初始状态;
s2、计算初始状态下采用初始网络切片接入策略获得的累计回报q值;
s3、利用ε-greedy算法选择下一个阶段的网络切片策略;
s4、基于演化博弈的分布式q_learning强化学习算法更新q值;
s5、重复步骤s3、s4,提高系统的网络效用。
进一步的,通过基于演化博弈的复制动态分布式强化学习算法选择步骤s1中的初始网络切片接入策略,具体步骤如下:
s11、根据吞吐量和功耗计算网络切片接入后用户获得的期望效用
其中,
s12、计算用户获得的平均效用uk_i:
其中,pi是用户选择网络切片i的概率;
s13、基于演化博弈理论构建网络切片接入的复制动态方程,计算复制动态方程的均衡点;
s14、采用雅可比矩阵局部稳定性分析方法获得整个网络切片接入的演化均衡解。
进一步的,所述的步骤s13中的复制动态方程如下:
其中,t表示当前阶段,ε是策略调整因子,ε∈[0,1]。
进一步的,所述的步骤s4更新q值的方程为:
其中,qt+1(st+1,kj)表示t+1阶段状态st+1下采用策略kj获得的累积回报,qt(st,ki)表示t阶段状态st下采用策略ki获得的累积回报,kj∈k,j=1,...,t,αt是学习速率,αt∈[0,1],rt是采用策略ki对应的短期回报,γ是折扣系数,γ∈[0,1],
采用以上技术手段后可以获得以下优势:
本发明公开了一种基于演化博弈的网络切片接入强化学习方法,通过复制动态方程的进化均衡解获得网络切片初始策略,在初始策略和初始状态下通过分布式q_learning强化学习算法不断更新系统q值,最大化网络切片接入得到的网络效用,使用户获得更好的体验。本发明方法可以准确找到合适的网络切片接入用户终端,既保证了用户的使用体验,又为运营商提供了帮助,减低运营商运营成本,简化网络接入操作。
附图说明
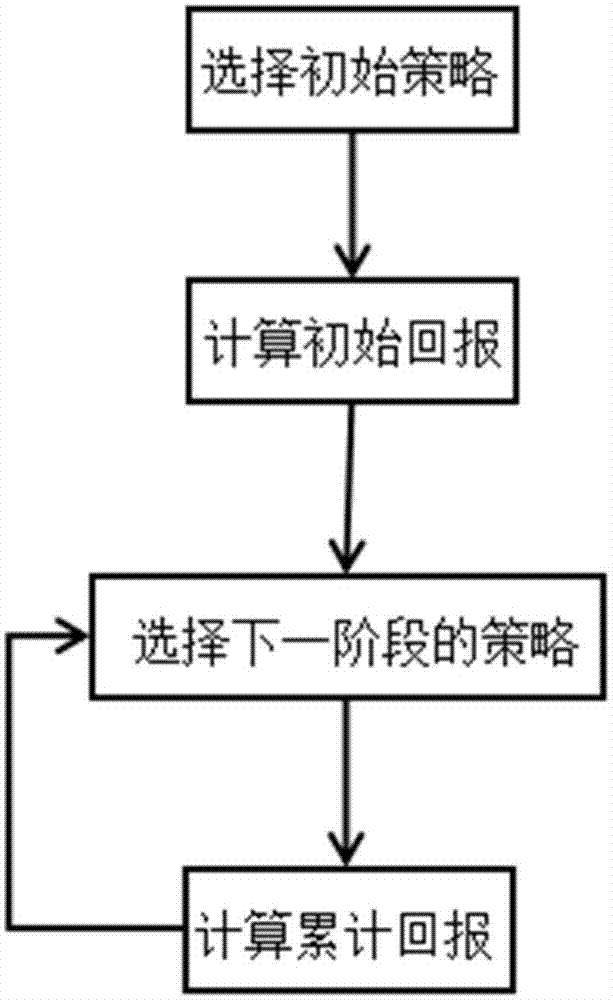
图1为本发明一种基于演化博弈的网络切片接入强化学习方法的流程示意图。
图2为本发明无线网络多个运营商的网络切片场景示意图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明:
一种基于演化博弈的网络切片接入强化学习方法,如图1所示,具体包括以下步骤:
s1、选择初始网络切片接入策略,得到网络初始状态;
s2、计算初始状态下采用初始网络切片接入策略获得的累计回报q值;
s3、利用ε-greedy算法选择下一个阶段的网络切片策略;
s4、基于演化博弈的分布式q_learning强化学习算法更新q值;
s5、重复步骤s3、s4,提高系统的网络效用。
本发明无线网络多个运营商的网络切片场景如图2所示,为了方便下面的算法评估,用户终端随机分布在网络场景中且静止的,某个网络终端可以选择一个或多个网络切片来接入网络。当有t个网络切片可以选择,用户选择网络切片的策略集合为k,k={k1,...,ki,...,kt},ki表示选择网络切片i,ki∈k,i=1,...,t;比如,有网络切片1和网络切片2,用户选择网络的策略集合为k={网络切片1,网络切片2}。
本发明方法通过基于演化博弈的复制动态分布式强化学习算法选择初始网络切片接入策略,将所有的网络切片接入策略随机划分成两两一组进行比较,效果好的策略再进行比较,以此类推,知道找到效果最好的策略。下面通过网络切片1和网络切片2的对比来具体分析:
s11、根据吞吐量和功耗计算网络切片接入后用户获得的期望效用,用户选择网络切片1的期望效果为:
用户选择网络切片2的期望效果为:
其中,
s12、在这一组对比计算中,用户选择网络切片1的概率为p1,用户选择网络切片2的概率为p2=1-p1,用户获得的平均效用为:
s13、基于演化博弈理论构建网络切片接入的复制动态方程,计算复制动态方程的均衡点;
用户选择网络切片1的复制动态方程为:
同理可知,用户选择切片2的复制动态方程为:
其中,t表示当前阶段,ε是策略调整因子,ε∈[0,1]。当
s14、采用雅可比矩阵局部稳定性分析方法获得整个网络切片接入的演化均衡解;在复制动态方程中,当其均衡点等于局部渐进稳定点,则这个均衡点就是这个动态体系的进化均衡点ess。
雅克比矩阵如下:
其中,
当均衡点同时满足行列式det(jac)>0和迹tr(jac)<0,该均衡点就是进化均衡点ess,即满足:
在确定了初始网络切片接入策略之后,计算初始状态下采用初始网络切片接入策略获得的累计回报q值,接着本发明方法利用ε-greedy算法选择下一个阶段的网络切片策略,在该算法中,每个状态下有ε的概率随机选取行动,否则会选取当前状态下q值较大的动作。
马尔可夫决策过程(mdp)是一个网络中的终端用户总体与提供服务的网络切片之间进行互相作用的循环过程。马尔可夫决策过程由一个五元组<s,a,p,r,γ>表示,其中,s表示网络中所有可能状态的集合,a表示所有用户针对当前状态选择动作的集合,p表示马尔可夫状态转变的概率,r表示网络效用改善的用户数量,γ是折扣系数,γ∈[0,1]。
在本发明方法中,通过基于mdp的分布式q_learning强化学习算法更新q值,我们可以将网络切片的整体选择情况视为状态s,将整体选择策略视为行动a,将网络效益改善的用户数量视为奖励r,得到下列公式:
其中,qt+1(st+1,kj)表示t+1阶段状态st+1下采用策略kj获得的累积回报,qt(st,ki)表示t阶段状态st下采用策略ki获得的累积回报,kj∈k,j=1,...,t,αt是学习速率,αt∈[0,1],rt是采用策略ki对应的短期回报,
上面结合附图对本发明的实施方式作了详细地说明,但是本发明并不局限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!