中文在线音视频的字幕生成方法与流程
本发明涉及一种字幕自动生成方法,具体而言,涉及一种中文在线课程音视频的字幕自动生成方法,属于音频识别技术领域。
背景技术:
伴随着互联网技术的不断进步和提高,各类中文在线音频、视频课程网站也得到了广泛地普及和迅速的发展,传播各领域专业知识的途径和形式都发生了改变。音频、视频信息中的同步字幕,帮助学习者克服了由于地域文化和语言差异在理解新知识时造成的困难,也消除了由于授课人吐词不清、同音字、语音不标准等引起的收听、观看音视频信息的障碍。同时,给音视频加上字幕,还能有效帮助一些听力功能衰弱或有障碍的人群理解课程中的学习内容。
传统的对音视频进行字幕添加的方式,是由专业的速记人员在收听、观看音视频数据的同时,以文字的方式快速记录每个时刻听到的声音信息,并记录下相应信息的时间戳,再由人工校对的方式将记录下的文字添加到音视频的特定时间戳位置上。该方式不仅对速记人员提出了很高的专业要求,还经常需要反复校对才能保证字幕内容的完善。此外,在添加字幕的过程中,往往也会因时间轴上存在误差而进行大量的精细调整,十分耗费人力资源。
国外的一些视频课程网站,比如coursera,已经开始为所有的英语视频提供自动生成的字幕。对于听力有障碍的用户或者希望观看他国语言视频的用户是一个极大的福利。google科学家mikecohen表示,字幕生成技术集语音识别和翻译算法于一体,但这一技术并非完美无缺,仍需要不断进步。并且,目前也有一些学者针对国内目前的中文音视频的自动字幕生成技术进行了调研,发现在中文在线课程的相关站点中,该项技术尚未得到广泛应用。
综上所述,如何在现有技术的基础上提出一种中文在线音视频的字幕生成方法,结合现有技术中的诸多优点,也就成为了本领域内技术人员亟待解决的问题。
技术实现要素:
鉴于现有技术存在上述缺陷,本发明提出了一种中文在线音视频的字幕生成方法,包括如下步骤:
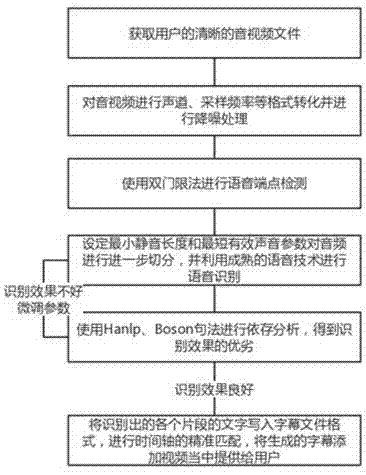
s1、音频数据提取步骤,服务器接收用户上传的音视频文件、并从所接收的音视频文件中提取出音频数据,将音频数据转化为标准格式;
s2、降噪步骤,对已转化为标准格式的音频数据进行降噪处理,得到降噪完成的音频文件;
s3、数据切分步骤,对音频文件进行端点切分,得到音频样本;
s4、片段识别步骤,对所得到的音频样本进行进一步切分,得到一系列语音片段,再对语音片段进行识别,整理得到全部音频数据的识别结果;
s5、字幕生成步骤,整合分析出文本及对应的时间轴,得到字幕文件,按照生成的字幕文件将字幕与音频数据进行匹配。
优选地,s1所述音频数据提取步骤,具体包括:用户通过中文在线课程视频网站上传一段音视频文件,服务器接收到音视频文件、提取出其中的音频数据,服务器从音频数据中读取参数信息,并将音频数据转化为标准格式;所述参数信息至少包括声道数、编码方式及采样率。
优选地,所述的标准格式为单声道和16000帧率的wav格式。
优选地,s2所述降噪步骤,具体包括:选取音频数据中前0.5秒的声音作为噪声样本,通过汉宁窗对噪声样本进行分帧并求出每一帧对应的强度值,以此作为噪声门阈值,再通过汉宁窗对音频数据进行分帧并求出每一帧对应的强度值,获得音频信号强度值,随后对音频信号强度值与噪声门阈值进行逐帧比较,保留音频信号强度值大于噪声门阈值的音频数据,最终得到降噪完成的音频文件。
优选地,s3所述数据切分步骤,具体包括:采用双门限语音端点检测技术,对已完成降噪的音频文件进行端点切分,切分出可用的音频样本,将未满足门限的部分音频文件当做静音或噪音、不做处理。
优选地,s3所述数据切分步骤中,所述双门限语音端点检测技术中的两个门限为包括过零率及短时能量。
优选地,s4所述片段识别步骤,具体包括:按照默认的最小静音长度和最短有效声音两项参数对s3中选择出的音频样本进行进一步切分,得到一系列的语音片段,然后将得到语音片段通过调用百度api进行语音识别,整理得到全部音频数据的识别结果,对识别结果采用boson句法依存分布来检测符合依存语法关系的情况、判断识别效果。
优选地,s4所述片段识别步骤中,依存语法关系包括以下条件:
一个句子中只有一个成分是独立的;
句子的其他成分都从属于某一成分;
句子中的任何一个成分都不能依存于两个或两个以上的成分;
若句子中的成分a直接从属成分b,而成分c在句子中位于a和b之间,那么,成分c或者从属于a,或者从属于b,或者从属于a和b之间的某一成分;
句子中心成分左右两边的其他成分相互不发生关系。
优选地,s4所述片段识别步骤中,若识别结果与上述的语法关系存在较大差异,则将最小静音长度及最短有效声音提供给用户进行参数调整,调整完毕后重新执行s4所述片段识别步骤;若识别结果经过用户确认后满足预期,则进入s5所述字幕生成步骤。
优选地,s5所述字幕生成步骤,具体包括:将各个语音片段对应的中文字幕,按照字幕的格式写入srt文件,每个语音片段的时间戳对应一段中文字幕,然后利用脚本自动调用字幕添加软件,将生成好的字幕文件按照时间添加进用户上传的音视频文件当中,最终得到一个带有字幕的中文课程视频,返回给用户以供下载。
与现有技术相比,本发明的优点主要体现在以下几个方面:
本发明的方法可以自动完成音视频信息的语音识别和字幕生成工作,有效地弥补了传统的人工速记在字幕生成工作中转换效率上的不足。同时,本方法能够自动地将字幕文本对齐到时间轴,不仅省去了传统人工反复校正时间轴和精细调整等繁琐的工作,还提高了生成字幕的质量,使得中文在线课程音视频制作人员可以将更多的时间放在制作高质量的视频工作上,而非制作和调整大量视频字幕数据上,从而大大地降低了中文在线课程音视频制作的后期维护成本。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他音频识别项目的技术方案中,具有十分广阔的应用前景。
以下便结合实施例附图,对本发明的具体实施方式作进一步的详述,以使本发明技术方案更易于理解、掌握。
附图说明
图1为本发明的流程示意图。
具体实施方式
如图1所示,本发明揭示了一种中文在线音视频的字幕生成方法,包括如下步骤:
s1、音频数据提取步骤,服务器接收用户上传的音视频文件、并从所接收的音视频文件中提取出音频数据,将音频数据转化为标准格式。
具体包括:用户通过中文在线课程视频网站上传一段音视频文件,服务器接收到音视频文件、提取出其中的音频数据,服务器从音频数据中读取参数信息,并将音频数据转化为标准格式。所述参数信息至少包括声道数、编码方式及采样率。
本步骤中处理分析的生成的音频格式为wav格式,wav是微软与ibm公司所开发在个人电脑存储音频流的编码格式,此格式属于资源交换档案个十(riff)应用之一。riff是由chunk构成的,chunk是riff组成的基本单位,每个chunk可看作存贮了视频的一帧数据或者是音频的一帧数据。其中formatchunk记录了wav的各种参数信息,有formattag音频数据的编码方式、channels声道数、samplespersec采样率(每秒样本数)、bitspersample*每个声道的采样精度等。这里我们对数据的声道数和采样频率进行检测,如果不是标准格式就将其转化为标准格式。
所述的标准格式为单声道和16000帧率的wav格式。
s2、降噪步骤,使用噪声门技术对已转化为标准格式的音频数据进行降噪处理,得到降噪完成的音频文件。
此处使用了一种噪声门技术对音频数据进行了降噪处理,以提高识别率,其基本方法是选取一段噪声样本,对噪声样本进行建模,然后降低用户上传的原始音频信号中噪声的分贝。在样本信号的若干频段f[1],...,f[m]上,分别设置噪声门g[1],...,g[m],每个门对应一个阈值t[1],...,t[m]。这些阈值是根据噪声样本确定。当通过某个门g[m]的信号强度超过阈值t[m]时,门就会关闭,反之,则会重新打开。以此保留下强度更大的声音。
具体包括:选取音频数据中前0.5秒的声音作为噪声样本,通过汉宁窗对噪声样本进行分帧并求出每一帧对应的强度值,以此作为噪声门阈值,再通过汉宁窗对音频数据进行分帧并求出每一帧对应的强度值,获得音频信号强度值,随后对音频信号强度值与噪声门阈值进行逐帧比较,保留音频信号强度值大于噪声门阈值的音频数据,最终得到降噪完成的音频文件。
s3、数据切分步骤,对音频文件进行端点切分,得到音频样本。
具体包括:采用双门限语音端点检测技术,对已完成降噪的音频文件进行端点切分,切分出可用的音频样本,将未满足门限的部分音频文件当做静音或噪音、不做处理。
所述双门限语音端点检测技术中的两个门限为包括过零率(zcr)及短时能量(ep)。
所述zcr的数学形式化定义为:
zcr=
其中,s是采样点的值,t为帧长,函数π{a}在a为真时值为1,否则为0。
ep的数学形式化定义为:
volume=10∗log10
s4、片段识别步骤,对所得到的音频样本进行进一步切分,得到一系列语音片段,再对语音片段进行识别,整理得到全部音频数据的识别结果。
具体包括:按照默认的最小静音长度(space)和最短有效声音(min_voice)两项参数对s3中选择出的音频样本进行进一步切分,得到一系列的语音片段,然后将得到语音片段通过调用百度api进行语音识别,整理得到全部音频数据的识别结果,对识别结果采用boson句法依存分布来检测符合依存语法关系的情况、判断识别效果。
所述的依存语法关系包括以下五个条件:
1、一个句子中只有一个成分是独立的。
2、句子的其他成分都从属于某一成分。
3、句子中的任何一个成分都不能依存于两个或两个以上的成分。
4、若句子中的成分a直接从属成分b,而成分c在句子中位于a和b之间,那么,成分c或者从属于a,或者从属于b,或者从属于a和b之间的某一成分。
5、句子中心成分左右两边的其他成分相互不发生关系。
需要说明的是,本步骤中,通过向bosonnlp的api发送一个post请求,按照要求将httpheader设置成指定的格式,请求body为需要依存分析的json文本,最终得到依存文法分析引擎返回的结果。以此能够判断出识别出的句式是否大致满足依存关系。若识别结果与上述语法关系存在较大差异,则将最小静音长度及最短有效声音提供给用户进行参数调整,调整完毕后重新执行s4所述片段识别步骤。若识别结果在经过用户确认后满足预期,则进入s5所述字幕生成步骤。
s5、字幕生成步骤,利用python自动化脚本,整合分析出文本及对应的时间轴,得到字幕文件,按照生成的字幕文件将字幕与音频数据进行匹配,按照生成的字幕文件里各段文字的时间轴将字幕自动添加进去,生成带字幕的音视频文件。
具体包括:将各个语音片段对应的中文字幕,按照字幕的格式写入srt文件,每个语音片段的时间戳对应一段中文字幕,然后利用脚本自动调用字幕添加软件,将生成好的字幕文件按照时间添加进用户上传的音视频文件当中,最终得到一个带有字幕的中文课程视频,返回给用户以供下载。
本发明的方法可以自动完成音视频信息的语音识别和字幕生成工作,有效地弥补了传统的人工速记在字幕生成工作中转换效率上的不足。
同时,本方法能够自动地将字幕文本对齐到时间轴,不仅省去了传统人工反复校正时间轴和精细调整等繁琐的工作,还提高了生成字幕的质量,使得中文在线课程音视频制作人员可以将更多的时间放在制作高质量的视频工作上,而非制作和调整大量视频字幕数据上,从而大大地降低了中文在线课程音视频制作的后期维护成本。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他音频识别项目的技术方案中,具有十分广阔的应用前景。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!