一种提高数据加解密速度的快速数据处理方法与流程
本发明属于使用分组密码算法对文件数据进行加解密的领域,更具体的说,涉及一种提高数据加解密速度的快速数据处理方法。
背景技术:
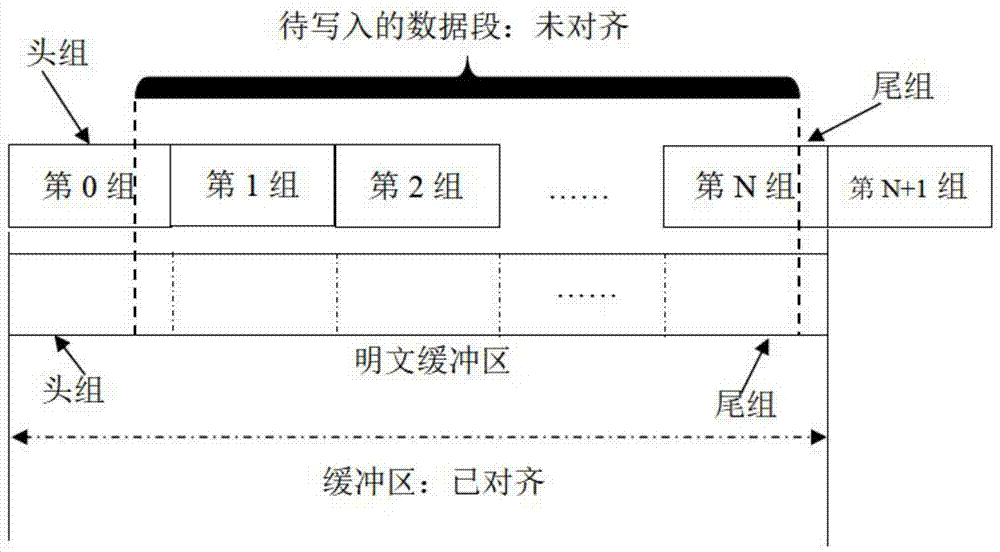
:对称密码算法,是指加密和解密使用相同秘钥的密码算法。分组密码算法,是指将输入数据划分成固定长度的分组进行加解密的一类对称密码算法。密文,指加密后的数据。明文,指未加密的数据或解密还原后的数据。明文缓冲区中最前面的一组称为头组,最后面的一组称为尾组。使用分组密码算法(如aes、sm1、sm4、sm7等)对随机写入文件的数据进行加密时,首先要进行数据对齐操作。原因是:分组密码算法每次加解密数据时最小操作单位是一个“组”,其大小通常是16字节。因此采用分组密码算法对文件进行加解密时,需要按顺序把文件分割成若干个连续的“组”,对每组数据进行加解密。当一段数据在文件中的起始地址和长度都是分组大小的整数倍时,称这段数据是对齐的,反之是未对齐的。或者说,当起始位置刚好位于某个组的首个字节,称起始位置对齐;当数据段的终止位置刚好位于某个组的最后一个字节,称终止位置对齐。当数据段在文件中的起始位置和终止位置都对齐时,长度才会对齐。人们在计算机上写文件时,通常是随机写入,如修改/删除/插入某段文字等。需要写入的数据段,99.6%都是未对齐的,即起始地址和/或长度不是分组大小的整数倍。对于随机写入的数据段,起始位置对齐的概率是1/16,长度对齐的概率也是1/16,因此数据对齐的概率是(1/16)*(1/16),数据未对齐的概率是1-(1/16)*(1/16)=99.6%。为了把未对齐的明文数据段用分组密码算法进行加密,然后写入文件,通常需要执行以下步骤:1、把加密文件里数据段地址占用的所有组(在图1中,是从第0组到第n组)中的密文读出并解密;2、把解密后的数据放入明文缓冲区,明文缓冲区的长度是对齐的;3、把要写入的明文数据段插入到明文缓冲区的对应位置,此时实现了数据对齐;4、对整个明文缓冲区进行加密,然后写入到文件中,完成上述明文数据段的加密写入操作。假设数据段的长度是length=n*16+t字节,其中n≥0,0<t<16,在文件中要写入的起始位置是position=16*p+s,其中p≥0,0≤s<16,则数据段共占用q个分组,q的取值有两个:其中,length表示数据段的长度,position表示起始位置,q表示数据段占用的分组数,*表示相乘,n、t、p、s均为整数。按照上述的方法,在第1步中需要从文件中读出q个组的密文数据,解密出q个组的明文并存入明文缓冲区,然后把待写入的明文数据插入到明文缓冲区的对应位置中实现数据对齐,再加密整个明文缓冲区,最后写入文件。加密和解密的总数据量是2*q组。当待写入数据的长度增大时,q随之增大,数据加解密处理的时间会变得非常长。技术实现要素:本发明主要解决的技术问题是提供一种提高数据加解密速度的快速数据处理方法,可以在分组密码算法框架下提高数据加解密的速度。为解决上述技术问题,本发明一种提高数据加解密速度的快速数据处理方法包括如下步骤:步骤一、处理待写入数据段在加密文件里对应的起始位置的头组数据和结束位置的尾组数据;步骤二、把要写入的明文数据段插入到长度对齐的明文缓冲区的对应位置;步骤三、对整个明文缓冲区进行加密,写到加密文件中。作为本技术方案的进一步优化,本发明一种提高数据加解密速度的快速数据处理方法所述处理待写入数据段在加密文件里对应的头组和尾组数据的具体过程为:步骤一一、如果待写入数据段在加密文件里对应的起始位置和结束位置均对齐,则直接进行步骤二;步骤一二、如果待写入数据段在加密文件里对应的起始位置未对齐而待写入数据段在加密文件里对应的结束位置对齐,则从加密文件里读取待写入数据段在加密文件里对应的起始位置所在的头组数据并解密,并将解密的头组数据写入到明文缓冲区的头组中;步骤一三、如果待写入数据段在加密文件里对应的起始位置对齐而待写入数据段在加密文件里对应的结束位置未对齐,则从加密文件里读取待写入数据段在加密文件里对应的结束位置所在的尾组数据并解密,并将解密的尾组数据写入到明文缓冲区的尾组中;步骤一四、如果待写入数据段在加密文件里对应的起始位置和结束位置均未对齐,则从加密文件里读取待写入数据段在加密文件里对应的起始位置所在的头组数据和待写入数据段在加密文件里对应的结束位置所在的尾组数据并解密,并将解密的头组数据和尾组数据分别写入到明文缓冲区的头组和尾组中。一种提高数据加解密速度的快速数据处理方法的有益效果为:1.明文缓冲区中除了头组和尾组数据之外,所有中间组里的数据会被待写入的数据段内容所覆盖,因此这部分数据无需读出,也无需解密出明文并写入明文缓冲区。只需要对头组和尾组进行解密,用解密后的头组、尾组和待写入的明文数据段共同组成对齐后的明文缓冲区。这样减少了解密的数据量,最多只需要对头组和尾组进行解密,从而可以加快数据加解密处理的速度。2.随着待写入数据段长度所占用分组数q的增加,本发明中的快速数据处理方法的速度逐渐趋近于传统方法速度的2倍,提高了数据加解密的处理速度。附图说明下面结合附图和具体实施方法对本发明做进一步详细的说明。图1为本发明一种提高数据加解密速度的快速数据处理方法的文件数据分组加解密图。具体实施方式具体实施方式一:下面结合图1说明本实施方式,本发明属于使用分组密码算法对文件数据进行加解密的领域,更具体的说,涉及一种提高数据加解密速度的快速数据处理方法,可以在分组密码算法框架下提高数据加解密的速度。所述提高数据加解密速度的快速数据处理方法包括如下步骤:步骤一、处理待写入数据段在加密文件里对应的起始位置的头组数据和结束位置的尾组数据;步骤二、把要写入的明文数据段插入到长度对齐的明文缓冲区的对应位置;步骤三、对整个明文缓冲区进行加密,写到加密文件中。人们在计算机上写文件时,通常是随机写入,如修改、删除、插入某段文字等。需要写入的数据段,99.6%都是未对齐的,即起始地址和/或长度不是分组大小的整数倍,如图1所示。因此,需要先处理待写入数据段在加密文件里对应的起始位置的头组数据和结束位置的尾组数据,使得待写入数据段在加密文件里对应的起始位置和结束位置均对齐。只有待写入数据段在加密文件里对应的起始位置和结束位置均对齐,才能进行加密,然后写入到文件中。从图1中可以看出,明文缓冲区中除了头组和尾组数据之外,所有中间组里的数据会被待写入的数据段内容所覆盖,因此这部分数据无需读出,也无需解密出明文并写入明文缓冲区。只需要对头组和尾组进行解密,用解密后的头组、尾组和待写入的明文数据段共同组成对齐后的明文缓冲区。这样可以加快数据加解密处理的速度。具体实施方式二:下面结合图1说明本实施方式,本实施方式对实施方式一作进一步说明,所述处理待写入数据段在加密文件里对应的头组和尾组数据的具体过程为:步骤一一、如果待写入数据段在加密文件里对应的起始位置和结束位置均对齐,则直接进行步骤二;即直接把要写入的明文数据段插入到长度对齐的明文缓冲区的对应位置。但是,需要写入的数据段,99.6%都是未对齐的,即起始地址和/或长度不是分组大小的整数倍,因此往往需要进行步骤一二、步骤一三或步骤一四。步骤一二、如果待写入数据段在加密文件里对应的起始位置未对齐而待写入数据段在加密文件里对应的结束位置对齐,则从加密文件里读取待写入数据段在加密文件里对应的起始位置所在的头组数据并解密,并将解密的头组数据写入到明文缓冲区的头组中;步骤一三、如果待写入数据段在加密文件里对应的起始位置对齐而待写入数据段在加密文件里对应的结束位置未对齐,则从加密文件里读取待写入数据段在加密文件里对应的结束位置所在的尾组数据并解密,并将解密的尾组数据写入到明文缓冲区的尾组中;步骤一四、如果待写入数据段在加密文件里对应的起始位置和结束位置均未对齐,则从加密文件里读取待写入数据段在加密文件里对应的起始位置所在的头组数据和待写入数据段在加密文件里对应的结束位置所在的尾组数据并解密,并将解密的头组数据和尾组数据分别写入到明文缓冲区的头组和尾组中。本发明提出的提高数据加解密速度的快速数据处理方法最多只需解密2组数据:头组和尾组,而无需解密所有的q组数据。加密时仍需处理q组数据。此时解密和加密需要处理的总分组数tb是:条件1为:q=1,或数据段的起始位置和数据段的终止位置有且仅有一个是未对齐的。本发明提出的提高数据加解密速度的快速数据处理方法和传统方法的加解密数据总量之比为q:数据加解密的速度和处理的分组数量成反比,因此本发明提出的提高数据加解密速度的快速数据处理方法和传统方法的数据处理速度之比r为:当q增大时,本发明提出的提高数据加解密速度的快速数据处理方法和传统方法的速度之r的值下表所示。qr(条件1成立)r(条件1不成立)21.3333151.66671.4286101.81821.6667201.90481.8182501.96081.92311001.98021.96082001.99001.98025001.99601.992010001.99801.996020001.99901.998050001.99961.9992从表中可以看出,随着待写入数据段长度所占用分组数q的增加,本发明提出的提高数据加解密速度的快速数据处理方法的速度逐渐趋近于传统方法速度的2倍,提高了数据加解密速度。当然,上述说明并非对本发明的限制,本发明也不仅限于上述举例,本
技术领域:
的普通技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1