基于行动价值函数学习的数据分流方法、电子设备与流程
本发明涉及数据分流技术,尤其涉及基于行动价值函数学习的数据分流方法和电子设备。
背景技术:
专利号为cn102821424a的专利公开了一种辅助移动数据分流的方法和通信装置以及移动装置,在该专利中,在移动通信模式下,通过一辅助通信装置对信号进行验证,构建第一通信连结,在第一通信上进行数据的分流。虽然此种方式能够实现分流,但是构建方式过于复杂,且耗能大。专利号为us20110317571a1的美国专利公开了methodandapparatusfordataoffloading,该专利通过设置多个设备对网络环境监听,对网络当中设备的数据使用进行比较,选择是否需要分流到其他网络。但是此方法对系统开销较大,并不具有实用性。专利号为us20120230191a1的美国专利公开了methodandsystemfordataoffloadinginmobilecommunications,该专利通过一个基础设置与数据分流控制器构成数据分流系统,通过基础设备对数据交换的监听,来判断是否需要进行数据分流,从而对数据分流控制器发出信号进行控制。此方法并未考虑到能量消耗及效率,并且复杂度较高,并不具实用性。已有的专利大多是从网络运营商来考虑数据分流的,这些策略并为考虑到移动用户的服务质量(qos)。而已有的从移动用户考虑的策略,对整体系统的能量消耗和网络成本需求较高,效率并不明显。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供基于行动价值函数学习的数据分流方法,其能解决现有技术无法对数据更好的分流的问题。
本发明的目的之二在于提供一种电子设备,其能解决现有技术无法对数据更好的分流的问题。
本发明的目的之一采用以下技术方案实现:
基于行动价值函数学习的数据分流方法,应用于网络系统,包括如下步骤:
s1:设定一随机参数,通过该随机参数初始化行动价值函数;
s2:获取所有数据流的向量集,以及每一个数据流在任意时间分别对应的位置;
s3:根据网络系统在任一时间t的状态、用户的动作向量、所有数据流在时间为t时保留文件大小的向量、所有数据流的向量集中的任意一个数据流以及用户在时间为t时的能量消耗计算得到时间为t时的货币成本和能耗成本;
s4:根据货币成本、能耗成本、用户在时间为t时的能量消耗、用户的动作向量计算理想的行动价值函数;更新网络系统状态并重新计算货币成本和能量消耗,并将当前更新后的网络系统状态存储,计算目标行动价值函数。
优选的,在s1之前,还包括s0:初始化重播内存d到容量n。
优选的,s1中的随机参数定义为θ,行动价值函数为q,在s1与s2之间,还包括如下步骤:sa:用随机参数θ-初始化目标行动价值函数
优选的,在s3中,定义网络系统在时间为t时的状态为:st={lt,bt},
优选的,s3具体包括如下步骤:
s31:设定t=1,
s32:判断到当t≤t并且b>0时,在[0,1]之间任意选取一个随机数rnd,判断rnd是否小于∈,若是,从用户的动作向量中随机选取一个动作,否则根据公式
s33:定义st+1=(lt,[bt-at,c-at,w]+),其中lt为时间t时的对应数据流所在位置,at,c为蜂窝网络分配数据率的向量,at,w为无线网络分配数据率的向量;
s34:通过公式rt(st,at)=ct(st,at)+εt(st,at)计算时间为t时的货币代价和能耗代价的总和,其中,rt(st,at)为货币成本和能耗代价的总和,ct(st,at)为货币成本,εt(st,at)为能耗代价。
优选的,s4步骤具体为:
s41:将(st,at,rt,st+1)作为经验存入内存d中;
s42:从内存d中随机抽样样本(sj,aj,rj,sj+1),判断j=j+1时是否终止,若是,则设定zj=rj,否则,设定
s43:通过(zj-qt(st,at;θ)2执行梯度下降,设定t∶=t+1,并当t∶=t+1时,重新设定
本发明的目的之二采用以下技术方案实现:
一种电子设备,其上设有存储器、处理器,所述存储器中存储有可被处理器执行的计算机程序,所述计算机程序被处理器执行时实现以下步骤:
s1:设定一随机参数,通过该随机参数初始化行动价值函数;
s2:获取所有数据流的向量集,以及每一个数据流在任意时间分别对应的位置;
s3:根据网络系统在任一时间t的状态、用户的动作向量、所有数据流在时间为t时保留文件大小的向量、所有数据流的向量集中的任意一个数据流以及用户在时间为t时的能量消耗计算得到时间为t时的货币成本和能耗成本;根据货币成本、能耗成本、用户在时间为t时的能量消耗、用户的动作向量计算理想的行动价值函数;
s4:更新网络系统状态并重新计算货币成本和能量消耗,并将当前更新后的网络系统状态存储,计算目标行动价值函数。
优选的,在s1之前,还包括s0:初始化重播内存d到容量n。
优选的,s1中的随机参数定义为θ,行动价值函数为q,在s1与s2之间,还包括如下步骤:sa:用随机参数θ-初始化目标行动价值函数
相比现有技术,本发明的有益效果在于:
本发明通过强化学习,在未知环境中用户可以及时作出反应,选择成本最小的策略实现了数据分流,降低系统整体的开销。
附图说明
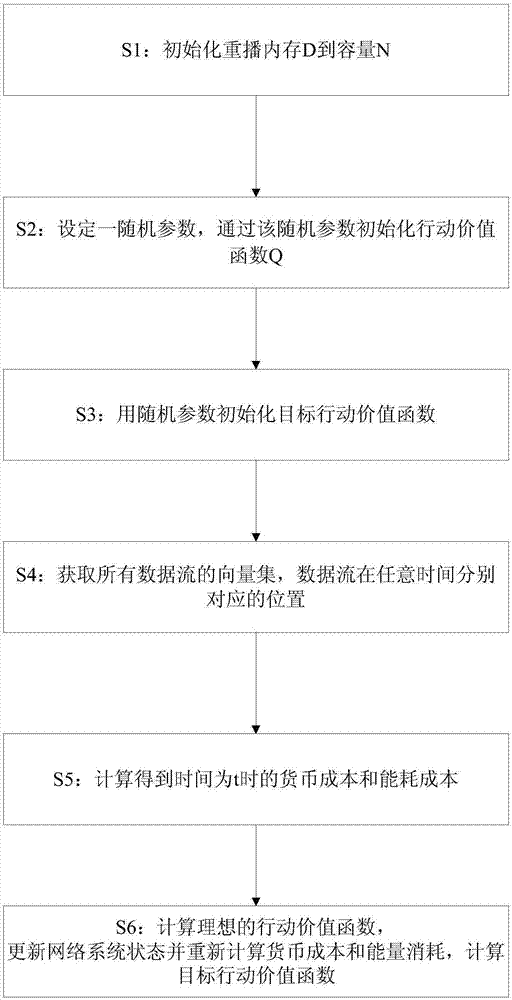
图1为本发明的基于行动价值函数学习的数据分流方法的流程图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述:
如图1所示,本发明提供一种基于行动价值函数学习的数据分流方法,包括如下步骤:
s1:初始化重播内存d到容量n;
s2:设定一随机参数θ,通过该随机参数θ初始化行动价值函数q;
s3:用随机参数θ-初始化目标行动价值函数
s4:获取所有数据流的向量集,以及每一个数据流在任意时间分别对应的位置;
s5:根据网络系统在任一时间t的状态、用户的动作向量、所有数据流在时间为t时保留文件大小的向量、所有数据流的向量集中的任意一个数据流以及用户在时间为t时的能量消耗计算得到时间为t时的货币成本和能耗成本;
s6:根据货币成本、能耗成本、用户在时间为t时的能量消耗、用户的动作向量计算理想的行动价值函数;更新网络系统状态并重新计算货币成本和能量消耗,并将当前更新后的网络系统状态存储,计算目标行动价值函数。
对于s5而言,定义网络系统在时间为t时的状态为:st={lt,bt},
s6步骤具体为:
s61:将(st,at,rt,st+1)作为经验存入内存d中;
s62:从内存d中随机抽样样本(sj,aj,rj,sj+1),判断j=j+1时是否终止,若是,则设定zj=rj,否则,设定
s63:通过(zj-qt(st,at;θ)2执行梯度下降,设定t∶=t+1,并当t∶=t+1时,重新设定
由于蜂窝网络覆盖率很广,假设移动用户能接入蜂窝网,但不能总是接入无线局域网。无线局域网的接入点通常设定在家,车站,超市等等。因此,我们假设无线局域网接入是基于地理位置的。我们主要关心的是数据大小和延迟的容忍度的应用。移动用户有m个文件需要从远程服务器下载,每个文件构成一个流,数据流的集合表示成
移动用户的动作at在决策时间点t决定选择无线局域网或者蜂窝网去传输数据,或者保持空闲并决定怎样给m个数据流分配网络数据率。因此,移动用户的动作向量表达如下:at=(at,c,at,w),
但基于两点理由:(1)通过限制仅使用一种网络,用户设备能依靠剩下的能力工作更长时间。(2)如今的智能机仅能使用一种网络。依靠这种假设,我们可以通过不改变硬件与操作系统就能将算法应用于设备上。当移动用户选择无线局域网时,分配数据率为j,
无线局域网和蜂窝网的总的流的数据率分别表示为
在每一个时间t,有货币成本、能量消耗、惩罚三个因素影响移动用户的动作决策。
货币成本是从用户到网络运营商的费用。我们定义网络运营商采用各国广泛使用的基于使用的策略。移动网络运营者的价格定义为pc。无线局域网是免费的。货币成本ct(st,at)表示如下:
是在位置l处使用蜂窝网时用焦耳或比特代表的能量成本率,
移动用户的策略是从时间t=0到t=tm的动作构成的,由下列公式定义:
理想的行动价值函数如下:
在上述过程中,状态离散包括了误差。保留数据的状态是连续的,但是在公式中是离散的。一种减少误差的方式是用小的粒度去离散保留数据,增加保留数据的状态的数量。过大的数据量导致运用二维的表存储q值数据,分别存储状态和动作。随着状态和数据的增多,这种方法也变得不可行。收敛率太低。如果用户经历很多状态,代理从未知状态将不能计算得到经验,算法才开始收敛。
因此,本发明中采用dqn算法解决上述问题。层神经网络被用来计算移动用户的经验以预测对未知状态的q值。进一步来说,不带离散误差的连续保留数据被输入深层神经网络。
在dqn中,动作价值函数由带参数θ的函数逼近qt(s,a;θ)估算。移动用户的最佳策略由下列公式得到
本发明还提供一种电子设备,其上设有存储器、处理器,所述存储器中存储有可被处理器执行的计算机程序,所述计算机程序被处理器执行时实现以下步骤:
s1:初始化重播内存d到容量n;
s2:设定一随机参数θ,通过该随机参数θ初始化行动价值函数q;
s3:用随机参数θ-初始化目标行动价值函数
s4:获取所有数据流的向量集,以及每一个数据流在任意时间分别对应的位置;
s5:根据网络系统在任一时间t的状态、用户的动作向量、所有数据流在时间为t时保留文件大小的向量、所有数据流的向量集中的任意一个数据流以及用户在时间为t时的能量消耗计算得到时间为t时的货币成本和能耗成本;
s6:根据货币成本、能耗成本、用户在时间为t时的能量消耗、用户的动作向量计算理想的行动价值函数;更新网络系统状态并重新计算货币成本和能量消耗,并将当前更新后的网络系统状态存储,计算目标行动价值函数。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!