一种基于熵和支持向量机的高级持续性威胁的检测方法与流程
本发明涉及信息安全
技术领域:
,尤其涉及一种检测高级持续性威胁的方法。
背景技术:
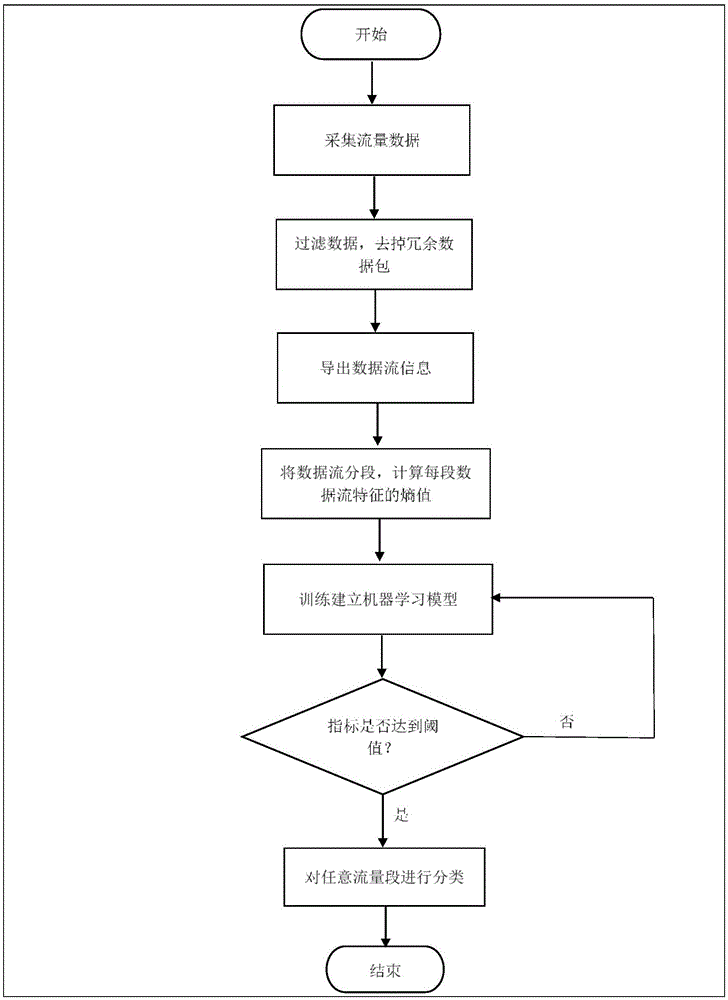
:在过去的十几年中,全球互联网高速发展。同时,网络攻击也层出不穷,在攻击的数量和手段上都在不断发展。2010年,臭名昭著的网络攻击震网(stuxnet)被安全研究人员发现并披露了大量的攻击细节。自此以后,高级持续性威胁(advancedpersistentthreats,apt)不断地出现在人们的视野。apt是一种长期的,针对特定目标高度定制化的网络攻击手段。由于其攻击行为特征多样,攻击方式层出不穷,因此传统的基于模式匹配的检测方式难以发挥有效的作用。近年来,已经有了许多关于apt检测的工作。针对apt攻击,许多安全厂商和研究人员给出了多种解决方案。“传统特征匹配”、“黑白名单”等技术都无法有效发现未知的apt攻击。因此,xuwang等人研究了许多apt攻击案例后提出,针对apt攻击中的通信阶段来检测是否存在命令与控制行为及其产生的流量,方案发现命令控制行为访问的目标地址之间的关联性相比较正常流量中的地址关联性有很大的不同之处,方案通过检测计算各个访问地址的关联性从而找到可疑的流量。但此方法的不足在于检测时间过长,无法及时地发现和减少apt攻击带来的损失。另外,sanasiddiqui提出使用基于分形维数的机器学习的分类方法,通过学习已被发现的apt攻击案例中使用的恶意软件产生的攻击流量的特征建立检测模型,并通过与常用的knn算法进行对比得到较优秀的分类性能。此方案虽然能检测出部分恶意流量,但产生的误报率非常高,并且对于海量的流量数据的处理需要很高的计算能力,因此其检测能力极大地受到了限制。fàtimabarceló-rico等人侧重于检测http请求的行为特征,用半监督机器学习模型geneticprogramming(gp),twodecisiontreeclassifier(dtc)和supportvectormachine(svm)进行测试,并对比了这几种不同的机器学习算法的优劣。结果发现svm和dtc能够在大量数据中仅仅只有少量已知可疑实例的情况依然能够保持较好的性能。技术实现要素:发明目的:本发明的目的是针对现有技术的不足,提供一种高级持续性威胁的检测方法。该方法能快速,准确地识别apt攻击,同时该方法将海量数据通过提取新的特征极大地减少了所需要处理的数据量。技术方案:为了实现上述目的,本发明提出一种基于熵和支持向量机的高级持续性威胁的检测方法,包括如下步骤:一种基于熵和支持向量机的高级持续性威胁的检测方法,包括如下步骤:a)在局域网中心交换机上记录流量数据,采集流量信息,流量信息包括但不限于数据包的源、目的地址,源、目的端口,字节数,时间戳;b)将采集保存的数据通过网络封包分析还原成数据流,保存数据流的若干个特征信息;c)设定一个时间段t,将步骤b)所得数据划分成n个时间间隔为t的样本,分别计算各个样本的若干个特征信息的熵值形成新的数据特征向量;d)以步骤c)中所得数据特征向量作为输入,通过机器学习来训练建立能够识别带有异常流量的模型,直至训练模型的评估指标达到指定阈值;e)使用步骤d)所得模型对任意一段时间间隔t内的流量进行分类,从而判断这段流量中是否存在异常的数据流。进一步的,步骤b中,所述特征信息包括传输字节数,传输数据包个数和数据流的持续时间。进一步的,步骤b中,所述采集保存的数据包括正常流量数据样本和异常流量数据样本,其中正常流量数据样本来自于步骤a中收集的流量数据,异常流量数据样本来自公开的milaparkour贡献的contagio恶意软件数据库。进一步的,步骤c中,所述时间段t在100mbps的网络中取10秒,处理数据的设备配置为intel4核2.5ghzcpu,8gbram和2.5tb硬盘。进一步的,步骤c中,计算数据流特征信息的熵值形成新的特征向量时,采用香农的离散信源信息熵算法:其中,h(x)表示数据流特征信息x的离散信源熵,p(xi)表示特征信息x取xi时,在该样本中出现在某取值区间内的概率,b为对数底数,m表示该样本中特征信息x的采样个数。进一步的,步骤d中,机器学习模型采用支持向量机:其中,f(t)∈{-1,+1},(.)′表示矩阵的转置,sign(ζ)表示数ζ的符号,t是所述数据特征向量中标准化后的元素,即测试样本,α是阿拉格朗日变量,xs(s=1,...,|s|)是支持向量,s表示训练样本数据集合,p代表多项式的次数,k是训练过程中得到的分类参数;支持向量机中的核函数采用高斯核函数,对于两个样本数据点xi和观测数据点xj,其目标值为y,得到高斯核函数:k(xi,xj)=e-y‖xi-xj‖2。进一步的,步骤d中,所述评估指标包括:准确率,精准率,回召率和f1score。进一步的,步骤d中,所述指定阈值设定为90%以上。有益效果:本发明通过将连续的流量数据分段,将海量数据划分成数量级更小的流量段,并通过统计计算提取新的特征向量使得最终被用于训练机器学习模型的数据量被进一步缩小,进而能够很快地进行分类训练和检测。同时,将检测具体的恶意流量转化为检测包含恶意流量的流量段,极大地简化了数据的处理和减小了误报率。附图说明图1是本发明方法的总体流程图;图2是数据流持续时间概率分布图示例。具体实施方式:下面结合附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明基于熵和支持向量机的高级持续性威胁的检测方法。在收集整理流量包数据之后,通过数据统计,计算局域网内流量信息的熵值进而提取新的特征向量,再使用支持向量机训练建立机器学习模型,最终达到检测高级持续性威胁的目的。具体实施步骤如下,且具体流程见附图1。步骤s1:从中心交换机采集流量数据,提取关键的流量信息,对二进制的数据流进行还原,以pcap(processcharacterizationanalysispackage,过程特性分析软件包)文件的形式将tcp包,udp包进行保存。其中流量信息包括但不限于数据包的源、目的地址,源、目的端口,字节数,时间戳。采集的未处理的原始流量分组数据如表1所示,表1原始流量分组数据步骤s2:通过使用网络封包分析工具wireshark,对流量数据包进行整理。先使用过滤器去掉长度为0和重发包,具体的过滤条件为“!tcp.analysis.retransmissionandtcp.len>0”。得到预处理后的数据后,使用命令行工具tshark根据数据包的序号和时间戳重新排序,组成数据流,并导出保存成txt文件。如表2所示为导出的数据示例,表2导出的数据示例address:portaaddress:portbpacketsbytesduration172.18.125.127:5050442.202.151.230:80149891154352628.7467172.18.19.8:703758.221.74.144:80148211615188521.8665172.26.28.188:26528182.247.250.19:8012694961018520.8633172.21.61.237:57685172.106.33.219:100196030464545023.8794步骤s3:设定一个时间段t,把t时间段内的一段数据流作为一个样本,如此把现在有的流量数据分为n段,便得到n个样本。如附图2所示,为其中一个样本中持续时间的概率分布图。横轴为数据流持续时间,纵轴为数据流的持续时间落在某个时间段内的概率。然后通过香农信息熵公式其中,h(x)表示数据流特征信息x的离散信源熵,p(xi)表示特征信息x取xi时,在该样本中出现在某取值区间内的概率,b为对数底数,通常取b=2,m表示该样本中特征信息x的采样个数,计算出每个样本的熵值,作为一条记录保存。需要计算的特征包括样本的字节数,数据包数和持续时间的熵值,进而这三个特征的熵值成为输入学习器的特征向量。表3为其中4个样本最终经计算得出的各个特征的熵值和用于分类的标识。表3各个特征的熵值和用于分类的标识ep_packetsep_bytesep_durationflag1.629973967651.133450788297.7018855248601.576025668011.260458738527.5987107510401.142336808110.9108386762364.6465943600211.133223757110.8596118910721.741213805841步骤s4:以步骤s3中的结果作为输入,采用支持向量机作为学习器进行机器学习训练,建立分类模型,其中,支持向量机中的核函数采用高斯核函数。对学习器不断进行迭代训练,直至各项指标超过90%,这些指标包括:准确率,精准率,回召率和f1score。其中支持向量机:准确率(accuracy):精准率(precision):召回率(recall):f1score:其中,tp,tn,fp,fn分别是真正例,真反例,假正例,假反例的个数。准确率能够评估预测的结果中正确的比例,精准率能够评估预测的结果中正例的比例,召回率能够评估真是情况中的正例被查出来的比例。f1分数是精准率和召回率的综合,f1越高说明模型越稳健。步骤s5:完成模型训练后便可对后续进行相同处理的流量数据进行判断。以上,通过示例说明了本发明的实施方式,但本发明的范围不限定于上述示例,在权利要求所记载的范围内,可根据目的进行变更、变形。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1