基于连续符号的低复杂度超奈奎斯特检测方法与流程
本发明属于通信技术领域,特别涉及一种低复杂度检测方法,适用于大容量卫星通信系统中的超奈奎斯特接收机检测。
背景技术:
不同于传统奈奎斯特传输系统,超奈奎斯特ftn传输系统可以通过减小码元的发射间隔,有效提高系统的频带利用率,在当今这个频谱资源有效的情况下,超奈奎斯特技术的优势是足够明显的。1975年j.mazo在bellsystemtechnicaljournal发表论文“faster-than-nyquistsignaling”,指出当采用sinc函数作为成型脉冲时,超奈奎斯特技术可以在相同的带宽内多传输25%的数据,并且不会有系统误码性能的损失。1972年g.d.forney在ieeetransactionsoninformationtheory发表论文“maximum-likelihoodsequenceestimationofdigitalsequenceinthepresenceofintersymbolinterference”,提出一种消除符号间干扰的最大似然均衡技术,它通过在众多路径中选取出一条最优的路径,来消除超奈奎斯特技术带来的符号间干扰,尽管该算法的性能是最优的,但是其复杂度呈指数形式增长,会严重影响通信传输的效率。为降低超奈奎斯特检测技术的实现复杂度,很多学者都进行了深入的研究。如2017年ebrahimbedeer等人在ieeeaccess上发表论文“averylowcomplexitysuccessivesymbol-by-symbolsequenceestimatorforfaster-than-nyquistsignaling”,提出了两种低复杂度的超奈奎斯特检测技术,其中连续符号序列估计sssse算法的复杂度有大幅度地降低,但是其性能也有一定程度上地损失。而另外一种可以重新估计k个符号的连续符号序列估计sssgbkse算法则将性能提升到了一种较优的程度,但是因为估计当前符号之前还需要重新去估计之前的k个符号,所以这也带来了实现复杂度上的急剧上升。
技术实现要素:
本发明的目的在于克服上述已有技术的不足,提出一种在单载波系统中基于连续符号的低复杂度超奈奎斯特检测方法,以保证误码性能的基础上,降低大容量卫星通信系统中超奈奎斯特接收机检测的复杂度。
为实现上述目的,本发明的技术方案如下:
1)信源生成二进制随机数并进行星座映射,将映射后的数据依次进行m倍的上采样和平滑处理,得到发送信号s(t);
2)发送信号s(t)经过高斯白噪声信道,得到接收机的接收信号r(t);
3)对接收信号r(t)使用与发送端对应的滤波器进行匹配滤波,再进行与发射机对应的m倍下采样,得到k时刻的采样符号yk;
4)对k时刻的采样符号yk进行超奈奎斯特检测:
(4a)将k-1,...,k-l+1时刻的采样符号yk-1,...,yk-l+1以及k+1,...,k+l-1时刻的采样符号yk+1,...,yk+l-1组成k时刻的符号矩阵y:
y=[yk-l+1yk-l+2...yk-1yk+1...yk+l-2yk+l-1],
(4b)确定干扰系数矩阵g:
g=[g1,l...gk,n...g1,2g1,2...gk,n...g1,l],
该干扰系数矩阵g是左右对称矩阵,起对称元素对应相等,其中,l为当前采样符号与单边符号干扰长度之和,gk,n=gn-k=∫h(t-nτt)h*(t-kτt)dt表示第n个符号对当前采样时刻符号的干扰系数,即符号间干扰isi的抽头系数,k取1表示当前采样时刻,n的取值范围为[2,l],
(4c)将干扰系数矩阵g与符号矩阵y的转置进行矩阵相乘,得到干扰项p:
p=g1,lyk-l+1+...+g1,2yk-1+g1,2yk+1+...+g1,lyk+l-1,
(4d)将k时刻的采样符号yk与干扰项p作差,得到k时刻采样符号的估计值
(4e)在判决域对k时刻采样符号的估计值
5)对k时刻判决符号
本发明与现有的超奈奎斯特检测方法相比,具有如下优点:
(1)误码性能良好。
本发明考虑到了符号间干扰是存在于当前符号两侧的情况,从两个方向都对符号间干扰进行了消除,从而大大地提升了系统的误码性能。
(2)减小了误码传播现象。
本发明在对每个符号进行干扰消除的时候,都是利用的接收符号,而没有利用判决后符号,所以避免了符号在判决错误后,被下一个符号利用当前的错误判决信息,减小了误差传播现象。
(3)降低了检测算法的复杂度。
本发明没有对当前符号之前的符号进行重新估计,而只是利用了前后接收的符号对当前符号进行了估计,大大减小了计算的复杂度。
仿真结果表明,本发明因降低复杂度而造成的性能损失很小,满足大容量卫星通信系统传输的需求。
下面通过附图和实施实例,对本发明作进一步的描述。
附图说明
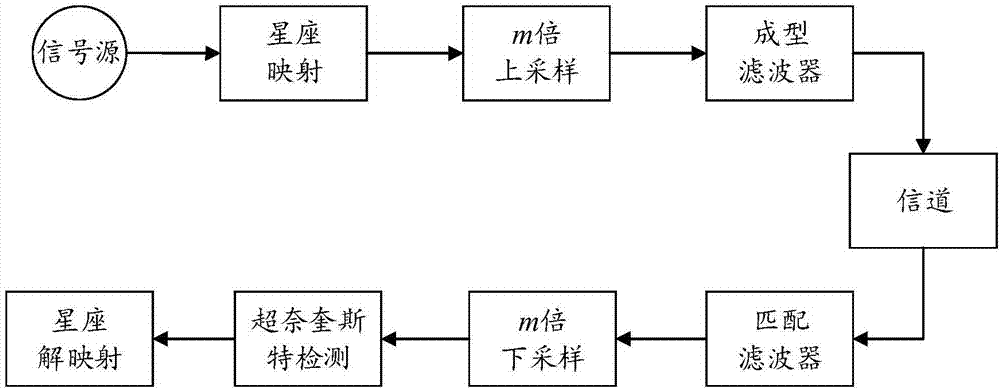
图1是现有的超奈奎斯特传输系统框图;
图2是本发明基于连续符号的低复杂度超奈奎斯特检测方法的实现总流程图;
图3是本发明中超奈奎斯特检测子流程图;
图4是传统奈奎斯特与超奈奎斯特传输系统的传输波形比较示意图;
图5是在加速因子为0.9条件下,用现有的两种算法和用本发明分别进行一次检测、两次检测的误比特率曲线比较图;
图6是在加速因子为0.8条件下,用现有的两种算法和用本发明分别进行一次检测、两次检测的误比特率曲线比较图。
具体实施方式
下面结合附图对本发明作进一步详细描述。
传统奈奎斯特系统即加速因子τ取1时的超奈奎斯特传输系统,该系统可以达到系统无码间串扰时的奈奎斯特速率,而超奈奎斯特传输系统的加速因子τ取值范围为(0,1),码元传输速率可以超越奈奎斯特速率。
参照图1,现有的超奈奎斯特传输系统由发射机,信道以及接收机三部分组成,发射机包含信号源,星座映射,上采样以及成型滤波器模块,接收机包含匹配滤波器,下采样,超奈奎斯特检测以及星座解映射这些模块,其工作原理如下:
信号源产生随机二进制比特流,经过qpsk星座映射后得到符号级序列,然后对该序列进行m倍上采样操作,上采样之后的信号经过脉冲成型滤波器平滑后得到发射机发射信号,
传统奈奎斯特系统和超奈奎斯特传输系统发射机信号如图4所示,由图4可知,传统奈奎斯特传输系统码元间隔为t,而在超奈奎斯特传输系统中,码元间隔τt<t,即码元以更快的速率传播,通常用加速因子τ来表示码元的加速程度,τ越小,码元传输速率越快,但当τ<1时,码元传输速率超过了奈奎斯特速率,从而引入了码间干扰,因此需要在接收机进行超奈奎斯特检测,以消除码间干扰。即发射信号经过加性高斯白噪声awgn信道后,到达接收机。接收机首先对接收信号进行匹配滤波,然后对接收信号进行m倍下采样操作得到采样序列,经过超奈奎斯特检测之后再进行qpsk解映射,最终得到恢复后的二进制比特序列。
本发明就是实现该超奈奎斯特传输系统中的超奈奎斯特检测方法。
参照图2,本发明超奈奎斯特检测方法是基于连续符号的低复杂度超奈奎斯特检测方法,其实现步骤如下:
步骤1.发射机产生发射信号。
(1a)信源产生随机二进制比特序列,并将该序列经过qpsk星座映射,即将00这两个二进制比特映射为符号-1+i,将10这两个二进制比特映射为符号1+i,将11这两个二进制比特映射为符号1-i,将01这两个二进制比特映射为符号-1-i,得到符号序列a1,a2,a3,...,an-1,an,an+1,...;
(1b)对该符号序列a1,a2,a3,...,an-1,an,an+1,...进行m倍的上采样操作,即在每两个相邻符号之间插入n-1个零,对上采样之后的信号进行脉冲成型滤波器平滑处理,得到发射机发射信号:
其中,n为符号序列的序号,an取值为[-1+i,1+i,1-i,-1-i]中的任意一种,t为传统奈奎斯特码元间隔,τ为加速因子,取值范围是(0,1),h(t-nτt)为平方根升余弦滚降滤波器srrc的时域表达式,具体表示如下:
式中α表示滤波器的滚降因子,在本实施例中,当加速因子τ选取为0.9时,滤波器的滚降因子α选取为0.3;当加速因子τ选取为0.8时,滤波器的滚降因子α选取为0.5。
步骤2.对发射信号加噪。
在发射信号上叠加方差为σ2的零均值高斯随机噪声n(t),得到加噪后的发射信号,即接收信号,可以表示为:
r(t)=s(t)+n(t),
步骤3.对接收信号匹配滤波及下采样。
接收信号r(t)在接收端首先进行匹配滤波,滤除滤波器带外的噪声,然后进行n倍下采样,得到采样符号序列y1,y2,y3,...,yk-1,yk,yk+1,...,其中k时刻采样符号表示如下:
式中,k表示当前的采样时刻,gn-k=∫h(t-nτt)h*(t-kτt)dt表示第n个符号对当前第式中,gn-k=∫h(t-nτt)h*(t-kτt)dt表示第n个符号对当前k时刻符号的干扰系数,即符号间干扰isi的抽头系数;h*(t-nτt)表示h(t-nτt)的共轭函数,g0表示n=k时gn-k的值;wk=∫n(t)h*(t-nτt)dt是指k时刻噪声的采样值,式中第一项akg0为k时刻采样符号的理想值,第二项
步骤4.超奈奎斯特检测。
参照图3,本步骤的具体实现如下:
(4a)确定符号矩阵y:
从采样符号序列y1,y2,y3,...,yk-1,yk,yk+1,...中提取k-1,...,k-l+1时刻的采样符号yk-1,...,yk-l+1以及k+1,...,k+l-1时刻的采样符号yk+1,...,yk+l-1,组成k时刻的符号矩阵y:
y=[yk-l+1yk-l+2...yk-1yk+1...yk+l-2yk+l-1],
该矩阵为1行,2(l-1)列矩阵,其中包含2(l-1)个元素,l为当前采样符号与单边符号干扰长度之和,l>1;
(4b)确定干扰系数矩阵g:
将步骤1中的gn-k用gk,n表示,取k为1,取n为2到l,并且考虑到符号间干扰isi存在于采样符号两侧,得到干扰系数矩阵g:
g=[g1,l...gk,n...g1,2g1,2...gk,n...g1,l],
该干扰系数矩阵g是左右对称矩阵,其对称元素对应相等,该矩阵为1行,2(l-1)列矩阵,包含2(l-1)个元素,其中,矩阵中元素gk,n表示第n个符号对k时刻采样符号的干扰系数,即符号间干扰isi的抽头系数,对每个采样时刻的符号进行干扰消除时,干扰系数矩阵g均不变;
(4c)由符号矩阵y和干扰系数矩阵g得到干扰项p:
对符号矩阵y进行转置,得到维度为2(l-1)行,1列的转置矩阵yt,表示如下:
将干扰系数矩阵g与转置矩阵yt进行矩阵相乘,得到干扰项p:
p=g1,lyk-l+1+...+g1,2yk-1+g1,2yk+1+...+g1,lyk+l-1;
(4d)消除干扰:
将采样符号yk与(4c)中得到的干扰项p作差,得到k时刻采样符号的估计值
(4e)星座判决:
对k时刻采样符号的估计值
步骤5.星座解映射。
对k时刻的判决符号
本发明的效果可通过以下仿真进一步说明:
仿真1:设置测试数据长度为20000000,设置加速因子τ为0.9,成型与匹配滤波器滚降因子α为0.3,当前采样符号与单边符号干扰长度之和l为5,重新估计符号数k为3,设置ebno为1~10,分别用本发明,现有连续符号序列估计sssse方法和重新估计k个符号的连续符号序列估计sssgbkse方法对采样符号序列y1,y2,y3,...,yk-1,yk,yk+1,...进行不同次数的检测,即用本发明方法分别检测一次和两次,用连续符号序列估计sssse方法检测一次,用重新估计k个符号的连续符号序列估计sssgbkse方法检测一次,得到不同方法随ebno变化的误比特率曲线,如图5所示。
由图5可见,所述三种方法的检测效果比较如下:
用现有的连续符号序列估计sssse方法检测一次,在误码率性能方面,与理论线相比有1.2db的性能损失,在复杂度方面,估计一个符号需要做l-1次乘法和l-2次加法运算,此法虽然有较低的复杂度,但是和理论线相比,性能损失较大;
用现有的重新估计k个符号的连续符号序列估计算法sssgbkse方法检测一次,在误码率性能方面,与理论线相比有0.2db的性能损失,在复杂度方面,估计一个符号需要做
用本发明方法检测一次,在误码率性能方面,与理论线相比仅有0.7db的性能损失,但在复杂度方面,则需要做2(l-1)次乘法和2(l-2)次加法进行符号估计,相比连续符号序列估计sssse方法,在误码率性能方面有很大的性能提升,但是在复杂度方面的代价较小;
用本发明方法检测两次,在误码率性能方面,与理论线相比仅有0.05db的性能损失,在复杂度方面,只需要做4(l-1)次乘法和4(l-2)次加法进行符号估计,相比重新估计k个符号的连续符号序列估计算法sssgbkse方法,本发明可以在保证误码率性能的基础上,大大降低计算复杂度。
仿真2:设置测试数据长度为20000000,设置加速因子τ为0.8,成型与匹配滤波器滚降因子α为0.5,当前采样符号与单边符号干扰长度之和l为5,重新估计符号数k为3,设置ebno为1~10,分别用本发明,现有连续符号序列估计sssse方法和重新估计k个符号的连续符号序列估计sssgbkse方法对采样符号序列y1,y2,y3,...,yk-1,yk,yk+1,...进行不同次数的检测,即用本发明方法分别检测一次和两次,用连续符号序列估计sssse方法检测一次,用重新估计k个符号的连续符号序列估计sssgbkse方法检测一次,得到不同方法随ebno变化的误比特率曲线,如图6所示。
由图6可见,所述三种方法的检测效果比较如下:
用现有的连续符号序列估计sssse方法检测一次,在误码率性能方面,与理论线相比有2.1db的性能损失,在复杂度方面,估计一个符号需要做l-1次乘法和l-2次加法运算,此法虽然有较低的复杂度,但是和理论线相比,性能损失较大;
用现有的重新估计k个符号的连续符号序列估计算法sssgbkse方法检测一次,在误码率性能方面,与理论线相比有0.1db的性能损失,在复杂度方面,估计一个符号需要做
用本发明方法检测一次,在误码率性能方面,与理论线相比仅有1.3db的性能损失,在复杂度方面,仅需要做2(l-1)次乘法和2(l-2)次加法进行符号估计,相比连续符号序列估计sssse方法,在误码率性能方面有很大的性能提升,但是在复杂度方面要付出较小的代价;
用本发明方法检测两次,在误码率性能方面,与理论线相比仅有0.1db的性能损失,在复杂度方面,仅需要做4(l-1)次乘法和4(l-2)次加法进行估计一个符号,相比重新估计k个符号的连续符号序列估计算法sssgbkse方法,可以在保证误码率性能的基础上,大大降低计算复杂度。
- 还没有人留言评论。精彩留言会获得点赞!