基于统计学习的威胁情报利用与繁殖方法与流程
本发明属于计算机网络安全领域。
背景技术:
为了躲避安全检测,网络攻击方不断改进使用的攻击手段,例如域名生成算法(domaingeneratealgorithm,dga),可以生成海量恶意域名,使得网络攻击可以绕过安全防火墙,威胁用户的计算机安全。不断更新的攻击手段导致威胁情报的数量激增、时效性缩短。传统的只利用已知威胁情报的安全检测模型,会受到模型退化的影响,无法准确检测出众多新的威胁情报。故而要求威胁情报检测方法能够根据已知的有限情报,构建出一个更加全面的检测模型来应对还未发现的威胁。
技术实现要素:
本发明目的是缓解传统安全监测模型面对海量、时效性显著的威胁情报,出现的模型退化进而导致预测准确率下降的问题,提供一种基于统计学习的威胁情报利用与繁殖方法。该方法基于统计学习算法,引入可信度,代替静态阈值,提高模型对未知威胁的识别能力;该方法支持多种异构检测模型,实现了多模型协同防御;该方法引入滑动时间窗概念,实现检测模型对预测出的新威胁情报的快速吸收,对过期已知情报的有效遗忘,缓解模型退化,提高预测准确度。
本发明的技术方案
基于统计学习的威胁情报利用与繁殖方法,包括如下步骤:
第1、基本概念:
(1)威胁情报:是通过大数据、分布式系统或其它特定收集方式获取的,包括漏洞、威胁、特征、行为等一系列证据的知识集合及可操作性建议。
(2)不一致度量函数:是通过得分来评价待测样本与已知样本集合不一致性的函数。
描述一个样本与一组已知样本的不一致性,输入是一组已知样本和一个测试样本,输出是一个数值,也叫做不一致性得分。得分越高,说明待测样本与该组样本越不一致,得分越低,说明待测样本与该组样本越一致。
(3)基于阈值的检测模型:是依据不一致度量函数给出待测样本得分,将之与固定阈值比较,给出预测结果的模型。
(4)p-value:是衡量当前样本在已知样本集合中显著度的统计量,用于多模型预测结果可信度的比较。
(5)基于conformalprediction的统计学习算法:是将检测模型根据不一致度量函数计算的样本得分作为输入,通过计算得分高于或等于被检测样本得分的样本数量与总数的比值得到样本p-value的算法。
第2、多模型不一致得分的计算,包括如下步骤:
第2.1步、提取特征矩阵
第2.1.1、设定不同的特征集合,对威胁情报提取出每个特征的特征值f;
第2.1.2、将威胁情报的所有特征值组成特征向量v(f1,f2,...fn),将多个特征向量值组成特征矩阵c(v1,v2,...vn);
第2.2步、计算不一致得分
第2.2.1、每一个异构的检测模型,对待测样本x,能根据情报库样本集合t,利用不一致度量函数g,计算出不一致得分α。异构模型给出的不一致得分之间不具有可比较性,不能根据不一致得分,来直接对比模型预测结果的质量。
第2.2.2、不一致度量的输入:情报库样本集合t、待测样本集合x、不一致度量函数集合g:
①情报库样本集合t:包含n个情报库样本ti,i∈{1,2,…,n},t={t1,…,tn};
②待测样本集合x:包含n’个待测样本xi,i∈{1,2,…,n’},x={x1,…,xn’};
③不一致度量函数集合g:包含m个不一致度量函数gj,i∈{1,2,…,n’},g={g1,…,gm};该函数集合的输入均为一个待测样本和情报库样本集合t,返回值均为一个实数,该实数表明待测样本与情报库中已知样本的不一致性;
第2.2.3、不一致度量的输出:待测样本的不一致得分集合;
第2.2.4、算法流程:
令tn=xi,xi∈x;t={t1,…,tn-1},ti∈t,将待测样本xi加入情报库t中,作为第tn个样本;
第3、基于统计学习的威胁情报繁殖方法,该方法包括如下步骤:
第3.1步、计算p-value
第3.1.1、每个检测模型将对待测样本x进行不一致度量得到对应的不一致得分α,多个检测模型从不同角度对待测样本x进行度量,得到不一致得分集合{α1,α2,…,αm}。
第3.1.2、将待测样本x的不一致得分α放入黑名单情报库样本的不一致得分集合中,黑名单中p-value值pnj_m是小于或等于该待测样本x不一致得分的黑名单情报库样本数量与总数的比值;将待测样本x的不一致得分α放入白名单情报库样本的不一致得分集合中,白名单中p-value值pnj_b是高于或等于该待测样本x不一致得分的白名单情报库样本数量与总数的比值。
第3.1.3、p-value值越大说明该待测样本x在白名单或黑名单中的显著度越高。不同检测模型中,待测样本x的所有pnj_m和pnj_b是可以比较的。
第3.1.4、输入:待测样本的不一致得分集合。
第3.1.5、输出:待测样本x的p-value值pn;
第3.1.6、算法流程:
第3.2步、基于统计学习预测待测样本
第3.2.1、若p-value值取值于pnj_m的最大值,则预测该待测样本x为恶意样本;若p-value值取值于pnj_b的最大值,则预测该待测样本x为正常样本。
第3.2.2、输入:可接受最大出错概率ε,由用户提供,表明用户能够接受的最大出错概率。
第3.2.3、输出:预测结果。
第3.2.4、算法流程:
第3.3步、基于时间窗的情报繁殖
采用滑动时间窗对情报库进行繁殖,根据待测样本的检测在时间轴上的分布密度和检测时长设定适宜大小的滑动时间窗;时间窗的设定能够快速吸收新发现的威胁情报,并依据遗忘规则有效遗忘时间窗外的过期情报。
在待测样本的时间窗内,其p-value值是基于上一个时间窗的情报库的样本集合计算得到的。在一个时间窗内,若待测样本被判断为恶意,同时在用户可接受的最大出错概率内,可将该待测样本吸收进情报库,实现威胁情报的繁殖。
在当前时间窗结束后,下一个时间窗开始前,遗忘新时间窗之外的过期威胁情报,对新的威胁情报库重新建模。
本发明的优点和积极效果:
本发明提出基于统计学习的威胁情报利用与繁殖方法。该方法灵活开放,支持多种异构检测模型,实现多种异构模型的协同防御;该方法基于统计学习算法,引入可信度,代替固定阈值,提高了对未知威胁情报预测的准确度;该方法引入滑动的时间窗,快速吸收新情报、遗忘过期情报,通过情报繁殖,一定程度上缓解了模型退化的问题。
附图说明
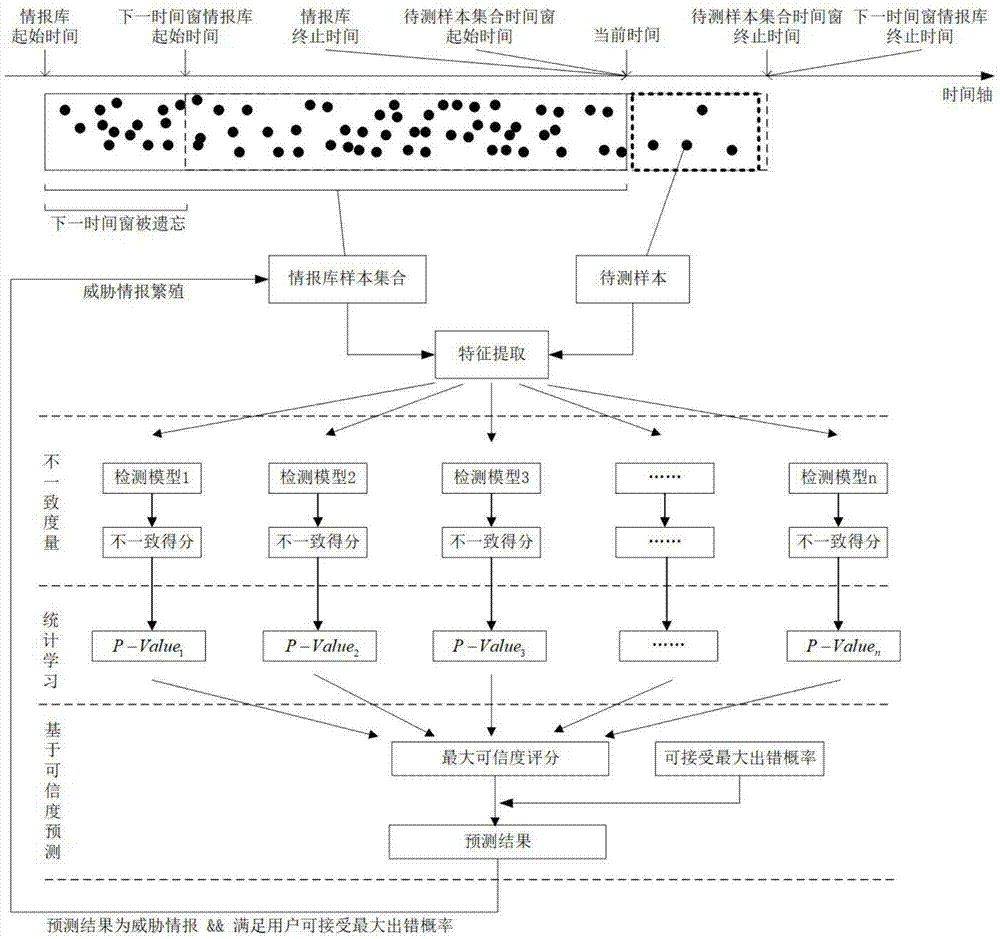
图1是基于统计学习的威胁情报利用与繁殖方法流程图。
图2是分别对白名单和黑名单数据进行特征值提取的13类特征。
图3是具体实施方式中使用的386个待测样本。
图4是对386个待测样本分别提取特征得到的特征矩阵。
图5是两个情报库样本的不一致得分集合。
图6是对部分测试数据打分的截图,格式为域名加打分。
图7是基于统计学习的威胁情报繁殖方法的预测结果的混淆矩阵。
图8是实施例中实际为恶意的部分待测样本集合的p-value值及预测结果,label值为1表示预测结果为恶意,label值为0表示预测结果为善意。
具体实施方式
本发明以检测恶意域名为例进行具体说明,任何使用基于固定阈值的检测模型都可以用到该方法上,方法流程如图1,本实施方式中以xgboost和lstm两种检测模型举例说明,具体介绍如下:
xgboost是一种基于gbdt梯度提升决策树的boosting算法。它首先使用简单的模型去拟合数据,得到一个比较一般的结果,然后不断向模型中添加简单模型,随着树的增多,整个模型的复杂度逐渐变高接近数据本身的复杂度。通过对情报的不同的特征值集合的cart树的建立和拟合,进行树结构的打分。该方法的学习效果好,速度快,能处理大规模数据,可以有效地对海量威胁情报进行打分。
lstm是一种特定形式的循环神经网络。它的全称是长短期记忆网络,是门限循环神经网络中的一种。训练时采用误差的反向传播算法,数据对象是一个时间窗内情报库中情报的集合。算法通过增加输入门限。遗忘门限和输出明显使得自循环的权重不断变化,实现是否利用上时刻学习到的知识对当前时刻进行学习,从而使得到的情报打分更加准确。
每一个异构的检测模型,对待测样本x,能根据情报库样本集合t,利用不一致度量函数g,计算出不一致得分α。异构模型给出的不一致得分之间不具有可比较性,不能根据不一致得分来直接对比模型预测结果的质量,因此在各异构模型得到不一致得分后还需基于统计学习预测待测样本,本实施方式的步骤如下。
1.提取特征矩阵
本实施方式,对情报库样本集合和待测样本提取多种特征。这些特征如图2所示,包括不同字母占比、不同数字占比、后缀占比、元音字母占比、数字与字母交换次数和单词长度等。将每一个域名得到的所有特征值组成一个特征向量,将多个域名提取得到的特征向量组成特征矩阵,如图4所示,每一行代表一个域名提取得到的13个特征值,每一列代表每个域名在该列特征下的取值。
2.训练检测模型
本实施方式,使用一百万白名单和八十万黑名单组成的情报库样本集合,对xgboost和lstm两个检测模型进行训练。
对xgboost检测模型的训练,需要将第1步中对情报库样本集合提取的特征值以及情报库样本对应的恶意和善意的标签作为训练样本来训练xgboost检测模型,并通过不断调整该检测模型的参数使xgboost检测模型达到最优。
对lstm检测模型的训练,需要将情报库样本的域名以及对应的恶意和善意的标签作为训练样本来训练lstm检测模型,并通过不断调整该检测模型的参数使lstm检测模型达到最优。
3.计算不一致得分
首先利用第2步中训练完成的xgboost和lstm两个检测模型,依据不一致度量函数对情报库样本集合计算不一致得分,得到黑名单情报库样本的不一致得分集合和白名单情报库样本的不一致得分集合。对于每个检测模型,我们最终都可以得到两个情报库样本的不一致得分集合,白名单情报库集合的不一致得分集合为b,黑名单情报库集合的不一致得分集合为m,如图5。
随后,xgboost和lstm两个检测模型,将对如图3所示的待测样本x进行不一致度量,得到对应的不一致得分αxgboost和αlstm。多个检测模型从不同角度对待测样本x进行度量,得到不一致得分集合{αxgboost,αlstm},如图6。xgboost和lstm两个异构模型给出的不一致得分之间不具有可比较性,不能根据不一致得分,来直接对比模型预测结果的质量。
4.计算p-value
以xgboost检测模型为例,将待测样本x的不一致得分αxgboost放入黑名单情报库样本的不一致得分集合m中,黑名单中p-value值pn1_m是集合m中不一致得分小于或等于αxgboost的黑名单情报库样本的数量与总数的比值;将待测样本x的不一致得分αxgboost放入白名单情报库样本的不一致得分集合b中,白名单中p-value值pn1_b是集合b高于或等于该待测样本x不一致得分的白名单情报库样本数量与总数的比值。对于lstm检测模型,我们也可以得到黑名单中的p-value值pn2_m和白名单中的p-value值pn2_b。
p-value值越大说明该待测样本x在白名单或黑名单中的显著度越高,在待测样本x的所有的p-value值pn1_m、pn1_b、pn2_m、pn2_b中选择最大值作为该待测样本x最终的p-value值pn。
5.基于统计学习预测待测样本
若待测样本x的p-value值pn取值于pn1_m或者pn2_m,则预测该待测样本x为恶意域名;反之,若待测样本x的p-value值pn取值于pn1_b或者pn2_b,则预测该待测样本x为善意域名。实施例中实际为恶意的部分待测样本集合的p-value值及预测结果如图8所示。
6.时间窗更新模型
本次实施方式中,设定一周作为待测样本更新的时间窗,用户提供的可接受的最大出错概率ε取1。在当前时间窗内,待测样本的p-value值是基于上一个时间窗的情报库的样本集合计算得到的。在本周时间窗结束时,将当前时间窗内预测为恶意且p-value值pn大于用户提供的可接受的最大出错概率ε的样本,吸收进情报库中,实现威胁情报的繁殖。在本周时间窗结束后,时间窗向后滑动一周。随着时间窗的滑动,情报库遗忘过期的情报,并且利用新加入的情报对模型进行重新训练。
7.总体算法流程
(1)输入:情报库样本集合t、待测样本集合x、不一致度量函数集合g、可接受最大出错概率ε:
①情报库样本集合t:包含n个情报库样本:t={t1,…,tn},ti∈t;
②待测样本集合x:包含n’个待测样本x={x1,…,xn’},xi∈x;
③不一致度量函数集合g:包含2个不一致度量函数:g={g1,g2},gj∈g。该函数集合的输入均为一个待测样本和情报库样本集合t,返回值均为一个实数,该实数表明待测样本与情报库中已知样本的不一致性;
④可接受最大出错概率ε,由用户提供,表明用户能够接受的最大出错概率。
(2)输出:
待测样本x的p-value值pn;
若pn大于可接受最大出错概率ε,则将该待测样本扩充进黑名单,实现威胁情报的繁殖;反之,pn小于可接受最大出错概率ε,其可信度无法达到用户的要求,不进行扩充。
(3)算法流程:
令tn=xi,xi∈x;t={t1,…,tn-1},ti∈t,将待测样本xi加入情报库t中,作为第tn个样本;
- 还没有人留言评论。精彩留言会获得点赞!