安防视频监控分析方法与流程
本发明涉及安防监控技术领域,特别涉及一种安防视频监控分析方法。
背景技术:
随着当今人口数量的增加和城市规模的不断扩大,现代社会所面临的突发、异常事件逐年增加,使得安全监控的难度与重要性也越来越突出。特别是对于某些安全敏感场合,如军事基地、监狱、供电站、医院、银行以及商场等区域,出于安全因素的考虑,管理人员必须了解是否有异常人物或车辆进入该场所。
传统的视频安全监控都是以人为主,由安保人员直接查看监控画面来判断是否有非法入侵人员。对于一些范围较大的工厂,需要进行安全防护的地方多,布置的视频监控点的数量多,呈现在工作人员面前的监控画面数量很多,工作人员很难兼顾所有待监控场所,加之人眼的易疲劳性,经常会遗漏许多可疑目标,工作人员不能保证及时的对每一个监控画面做出有效判断,从而会给监控场所带来重大损失。
随着智能视频监控技术的日益成熟,以人工智能与视频分析等技术为主的智能入侵检测系统在一定程度上弥补了人工监控的不足。智能入侵检测系统是指通过视频分析的方法,自动发现监控视频中的入侵目标,并且根据一定判定条件,确定是否自动报警。
目前的区域入侵检测和越界检测一般是先预置警示区域,然后当拍摄装置检测到视频监控图像中的入侵目标时,设置入侵目标的检测框,当检测框的顶点坐标位于警示区域内时,则判断出有入侵行为。但是采用此种方式,有时明明检测框的大部分还在警示区域内,只是检测框的顶点不在警示区域内,都不能判定为入侵了区域,存在着入侵漏报的可能;因此,目前亟需一套精准的安防视频监控分析方法。
技术实现要素:
本发明意在提供一种安防视频监控分析方法,以解决现有的视频监控方法因漏报入侵而存在危险的问题。
为解决上述技术问题,本发明提供的基础方案如下:
安防视频监控分析方法,包括以下步骤:
警示区域划定步骤:获取视频监控图像并标记警示区域;
目标物体检测步骤:识别并检测视频监控图像中是否含有目标物体;
mask图片获取步骤:根据标记的警示区域得到该警示区域的mask1图片;当检测到视频监控图像含有目标物体时,给该目标物体划定将目标物体包围的检测框,根据检测框得到该目标物体的mask2图片;
区域入侵检测步骤:将mask1图片和mask2图片的每个像素点进行计算得到结果值,根据该结果值与预设值判断得出检测框是否与警示区域重合,当结果值等于预设值时,则判断为检测框与警示区域重合;当结果值不等于预设值时,则判断为检测框与警示区域不重合。
本发明的技术方案中,先对视频监控图像标记警示区域,并根据标记的警示区域得到该警示区域的mask1图片;同时识别检测视频监控图像中是否含有目标物体,当检测到视频监控图像含有目标物体时,给该目标物体划定将目标物体包围的检测框,根据检测框得到该目标物体的mask2图片;将mask1图片和mask2图片的每个像素点进行计算得到结果值,根据该结果值与预设值判断得检测框是否与警示区域重合,当结果值等于预设值时,判断结果为检测框与警示区域重合,也就是目标物体入侵了警示区域;当结果值不等于预设值时,判断结果为检测框与警示区域不重合,也就是目标物体没有入侵警示区域。相对于现有的只有检测框的顶点在警示区域内才算入侵的方式而言,本方案中只要检测框与警示区域任意一点重合,就判断为目标物体入侵了警示区域,因此能够减少入侵的漏报;并且本发明可以对视频监控图像进行实时精准的自动分析,及时发现潜在的安全风险,减少安全隐患,避免灾祸的发生。
进一步,所述警示区域划定步骤包括:
视频监控图像获取步骤:获取监控点的视频监控图像;
坐标系建立步骤:将获取的视频监控图像的画面建立坐标系;
mask1原始图片制作步骤:将获取的视频监控图像的画面制作mask1原始图片;
警示区域构建步骤:通过给定顶点坐标构建mask1原始图片的警示区域。
mask1原始图片就是全黑的图片,与原图片有完全相同的像素尺寸,只是每个点的rgb值都是(0,0,0),也就是每个像素都是黑点,由于对获取的视频监控图像的画面建立了坐标系,通过给定顶点坐标的连线即可构建mask1原始图片的警示区域。
进一步,mask图片获取步骤包括:
给定点选取步骤:选取位于警示区域内的某一点作为第一给定点;
mask1图片制作步骤:利用第一给定点将mask1原始图片变为mask1图片。
在画好直线的mask1原始图片中,利用位于警示区域内的第一给定点,不断将这个点周围的点都变成白色,直到遇到警示区域的直线边界,这时警示区域内的点都变成白色,警示区域外的点都还是黑色,从而得到了警示区域内为白色和警示区域外为黑色的mask1图片。
进一步,所述mask图片获取步骤还包括:
mask2原始图片制作步骤:当检测到视频监控图像含有目标物体时,给该目标物体划定将目标物体包围的检测框,并制作目标物体的mask2原始图片;
给定点选取步骤:选取位于检测框内的某一点作为第二给定点;
mask2图片制作步骤:根据第二给定点将mask2原始图片变为mask2图片。
利用检测框内的第二给定点,不断将这个点周围的点都变成白色,直到遇到检测框的直线边界,这时检测框内的点都变成白色,检测框外的点都是黑色,从而得到了检测框内为白色和检测框外为黑色的mask2图片。
进一步,在所述坐标系建立步骤中,坐标系的原点为画面的某一顶点。
坐标系的原点为画面的某一顶点,具体地,可采用画面最左上角的像素点为坐标原点(0,0),画面最上面的那条边作为x轴,正方向向右,最左边的边作为y轴,正方向向下,那么,每个像素点就都有了一个坐标。
进一步,所述警示区域和检测框均为选定区域,所述给定点选取步骤包括:
垂线公式计算步骤:获取选定区域任意两个相邻顶点的线段的斜率,根据该斜率获得过该线段的中点且垂直于该线段的垂线的公式;
测试点坐标获取步骤:选取该垂线上位于中点两边的测试点,并根据垂线公式获得两个测试点的坐标;
测试点判断步骤:利用两个测试点填充被选定区域线段隔开的两个区域,根据原点颜色和选定区域的颜色判断哪个测试点位于选定区域内,并将位于选定区域内的测试点作为第一给定点或第二给定点。
获取选定区域任意两个相邻顶点的线段的斜率,根据该斜率获得过该线段的中点且垂直于该线段的垂线的公式;选取该垂线上位于中点两边的测试点,并根据垂线公式获得两个测试点的坐标,两个测试点其中一个一定位于选定区域内,另外一个必定在选定区域外;利用两个测试点填充被选定区域线段隔开的两个区域,根据原点颜色和选定区域的颜色判断哪个测试点位于选定区域内,具体地,先选取两个测试点的其中一个对画面进行颜色填充,如果该测试点位于选定区域外,那么选定区域外的所有像素点都会变成白色,而原点(0,0)肯定是在区域外的,所以此时需要判断原点的颜色,当原点的rgb值是(255,255,255)时,说明原点是白色的,所以选取的测试点位于选定区域外,那么另外一个测试点必定位于选定区域内;反之,如果原点的rgb值是(0,0,0)时,说明原点是黑色的,那么选取的测试点就位于选定区域内,从而将位于选定区域内的测试点作为第一给定点或第二给定点,利用第一给定点将mask1原始图片变为mask1图片,利用第二给定点将mask2原始图片变为mask2图片。
警示区域和检测框可为规则的多边形,也可为不规则的多边形,当警示区域和检测框的边界线构成一个不规则的多边形时,仅仅通过警示区域和检测框的顶点坐标还是无法得到警示区域和检测框内的点,所以采用上述方法能够精确地获取到警示区域和检测框内的点。
进一步,所述目标物体检测步骤之后还包括:
运动轨迹跟踪步骤:当检测到视频监控图像含有目标物体时,跟踪目标物体并获取该目标物体的运动轨迹。
当检测到视频监控图像含有目标物体时,利用跟踪算法对目标物体进行跟踪,可以得到该目标物体从初始帧开始的每一帧的坐标,也就是该目标物体的运动轨迹,当目标物体存在对警示区域的入侵时,通过目标物体的运动轨迹可判断目标物体是从哪个方向越界。
进一步,还包括:
计时步骤:当目标物体不与警示区域重合时,开始计时;
离岗判断步骤:将计时结果与预设的时间阈值进行比较,判断目标物体是否离岗超时;
报警步骤:当目标物体离岗超时,则发出警报。
当目标物体不与警示区域重合时,说明目标物体离开了警示区域内,此时开始计时,将计时结果与预设的时间阈值进行比较,判断目标物体是否离岗超时,当判断出目标物体离岗超时,则发出警报通知相关人员,通过目标物体与警示区域的重合与否,可判断出工作人员是在岗还是离岗,从而可实现对某些岗位的工作人员的实时监控。
附图说明
图1为本发明安防视频监控分析方法实施例一的示意性框图;
图2为本发明安防视频监控分析方法实施例二的示意性框图。
具体实施方式
下面通过具体实施方式进一步详细说明:
实施例一
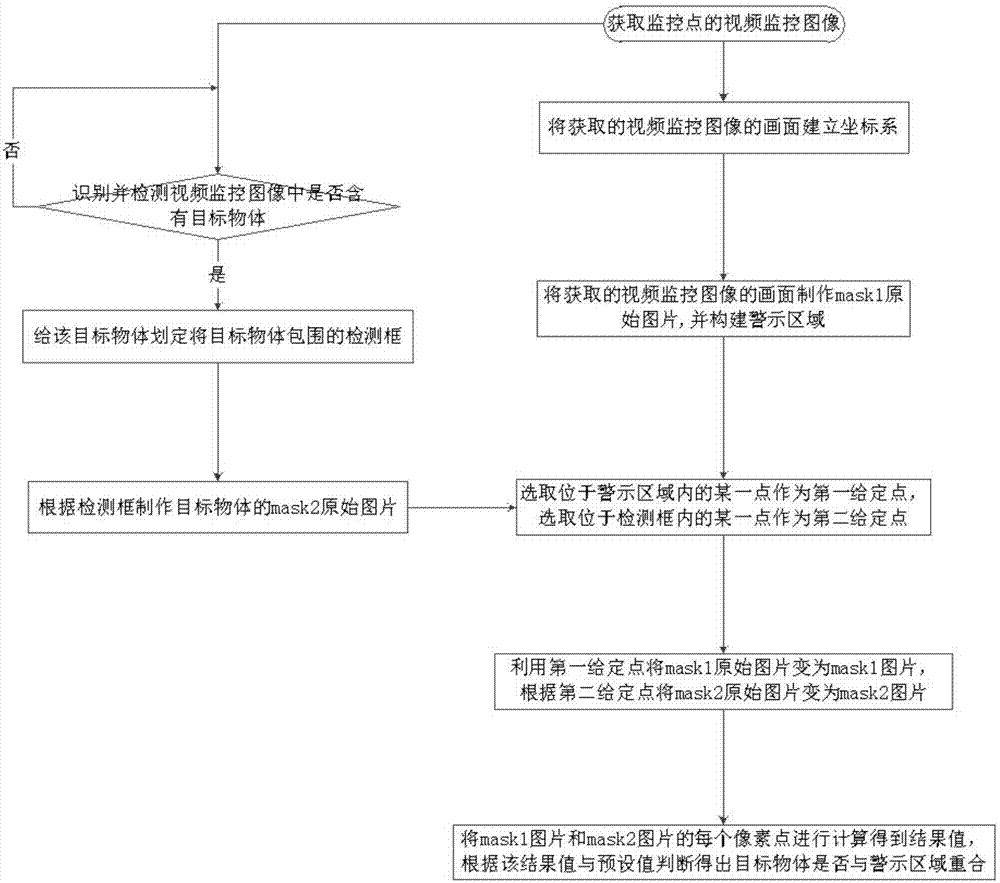
如图1所示,本发明安防视频监控分析方法,包括以下步骤:
一、警示区域划定步骤:获取视频监控图像并标记警示区域;
其中,警示区域划定步骤具体包括:
视频监控图像获取步骤:获取监控点的视频监控图像;
坐标系建立步骤:将获取的视频监控图像的画面建立坐标系;具体地,坐标系的原点为画面的某一顶点;本实施例采用画面最左上角的像素点为坐标原点(0,0),画面最上面的那条边作为x轴,正方向向右,最左边的边作为y轴,正方向向下,那么,每个像素点就都有了一个坐标;
mask1原始图片制作步骤:将获取的视频监控图像的画面制作mask1原始图片;mask1原始图片就是全黑的图片,与原图片有完全相同的像素尺寸,只是每个点的rgb值都是(0,0,0),也就是每个像素点都是黑色;
警示区域构建步骤:通过给定顶点坐标构建mask1原始图片的警示区域;具体地,利用opencv库的cv2.line()函数将这些给定顶点连接成的直线在mask1原始图片中画出来;假设给定的顶点坐标分别为(20,30),(50,30),(50,70),(20,70),按逆时针顺序将这四个顶点依次连接起来,构成一个长为30和宽为40的长方形区域,该长方形区域即为警示区域;
二、目标物体检测步骤:识别并检测视频监控图像中是否含有目标物体;具体地,本实施例使用的是深度学习pytorch框架下实现的yolo3人工神经网络算法对目标物体进行识别检测,目标物体可为人、动物或者其他物体;
三、mask图片获取步骤:根据标记的警示区域得到该警示区域的mask1图片;当检测到视频监控图像含有目标物体时,给该目标物体划定将目标物体包围的检测框,根据检测框得到该目标物体的mask2图片;
其中,mask图片获取步骤具体包括:
给定点选取步骤:选取位于警示区域内的某一点作为第一给定点;
mask1图片制作步骤:利用第一给定点将mask1原始图片变为mask1图片;具体地,在画好直线的mask1原始图片中,利用opencv库的cv2.floodfill()函数,根据位于警示区域内的第一给定点,不断将这个点周围的点都变成白色,直到遇到警示区域的直线边界,这时警示区域内的点都变成白色,警示区域外的点都是黑色,从而得到了警示区域内为白色和警示区域外为黑色的mask1图片;
mask2原始图片制作步骤:当检测到视频监控图像含有目标物体时,给该目标物体划定将目标物体包围的检测框,并制作目标物体的mask2原始图片;具体地,检测框可为矩形或椭圆形等几何图形;
给定点选取步骤:选取位于检测框内的某一点作为第二给定点;
mask2图片制作步骤:根据第二给定点将mask2原始图片变为mask2图片;具体地,利用opencv库的cv2.floodfill()函数,当确定位于检测框内的第二给定点时,不断将这个点周围的点都变成白色,直到遇到检测框的直线边界,这时检测框内的点都变成白色,检测框外的点都是黑色,从而得到了检测框内为白色和检测框外为黑色的mask2图片。
其中,警示区域和检测框均为选定区域,给定点选取步骤具体包括:
垂线公式计算步骤:获取选定区域任意两个相邻顶点的线段的斜率,根据该斜率获得过该线段的中点且垂直于该线段的垂线的公式;以警示区域为例:首先,选取警示区域任意两个相邻顶点,假设已知两个相邻顶点分别为m1(x1,y1),m2(x2,y2),那么这两个点连接而成的线段l1肯定是警示区域的边,然后取线段l1的中点坐标md(x0,y0),计算这个线段l1的斜率为k1,然后作一条过线段l1的中点且垂直于该线段l1的垂线l2,则可得到该垂线的斜率为k2=-1/k1,利用点斜式方程,可得到该条垂线l2的公式为y=k2*x+b;
测试点坐标获取步骤:选取该垂线上位于中点两边的测试点,并根据垂线公式获得两个测试点的坐标;具体地,针对如何选取垂线上位于中点两边的测试点,需要先对垂线l2的斜率k2进行判断,假设预先设有斜率阈值范围为ks~km,当k2<ks时,意味着垂线l2与x轴几乎是平行的,那也就是说线段l1与x轴几乎是垂直的,这时候就要在线段l1左右两边取点,也就是改变横坐标的值来获得线段l1左右两个测试点的坐标,当k2>km时,说明垂线与x轴几乎是垂直的,那么与该垂线垂直的线段与横轴就几乎是水平的,这时候就要在线段的上下方向取点,也就是改变纵坐标的值来获得线段上下两个测试点的坐标;
以警示区域为例:由于警示区域可为任意形状,有可能垂线上位于选定点两边的测试点均位于警示区域内或者均位于警示区域外,为保证两个测试点其中一个必定位于警示区域内,另外一个位于警示区域外,改变横坐标的值和改变纵坐标的值都有限制条件,假设垂线与警示区域的边界线还有另外多个交点m3(x3,y3),m4(x4,y4)…mn(xn,yn)时,假设改变横坐标的值和改变纵坐标的值为z,则z应该取与md距离最近的交点与md的距离值,假设与md距离最近的交点为m3(x3,y3),也就是当垂线斜率小于最小斜率阈值时,这时候就要在线段l1的左右方向取点,则z小于x3与x0差值的绝对值,例如,线段l1左边的测试点的横坐标假设为x=x0-z,则纵坐标y=k2*(x0-z)+b,线段l1右边的测试点的横坐标假设为x=x0+z,则纵坐标y=k2*(x0+z)+b;当垂线斜率大于最大斜率阈值时,这时候就要在线段l1的上下方向取点,则z小于y3与y0差值的绝对值,令y=y0+z,解出x即得到了线段l1上方的测试点,令y4=y0–z,解出x,则得到线段l1下方的测试点;从而无论警示区域是什么形状,两个测试点一个必定位于警示区域内,另外一个必定位于警示区域外;当ks<k2<km时,采取上述的两种方式均可。
测试点判断步骤:利用两个测试点填充被选定区域线段隔开的两个区域,根据原点颜色和选定区域的颜色判断哪个测试点位于选定区域内,并将位于选定区域内的测试点作为第一给定点或第二给定点。以警示区域为例:先选取两个测试点的其中一个对画面进行颜色填充,如果该测试点位于警示区域外,那么警示区域外的所有像素点都会变成白色,而原点(0,0)肯定是在区域外的,所以此时需要判断原点的颜色,当原点的rgb值是(255,255,255)时,说明原点是白色的,所以选取的测试点位于警示区域外,那么另外一个测试点必定位于警示区域内;反之,如果原点的rgb值是(0,0,0)时,说明原点是黑色的,那么选取的测试点就位于警示区域内,从而将位于警示区域内的测试点作为第一给定点,利用该第一给定点将mask1原始图片变为mask1图片。
同理,按照上述步骤,也可得到检测框内的第二给定点,利用第二给定点将mask2原始图片变为mask2图片。
警示区域和检测框可为规则的多边形,也可为不规则的多边形,当警示区域和检测框的边界线构成一个不规则的多边形时,仅仅通过警示区域和检测框的顶点坐标还是无法得到警示区域和检测框内的点,所以采用上述方法能够精确地获取到警示区域和检测框内的点。
四、区域入侵检测步骤:将mask1图片和mask2图片的每个像素点进行计算得到结果值,根据该结果值与预设值判断得出检测框是否与警示区域重合,当结果值等于预设值时,则判断为检测框与警示区域重合;当结果值不等于预设值时,则判断为检测框与警示区域不重合;具体地,将警示区域的mask1图片的每个像素点和目标物体的mask2图片的每个像素点相加,那么会出现以下三种情况:
1、mask1图片中的某一像素点为黑点,rgb值是(0,0,0),也就代表这一点不在警示区域内,mask2图片对应的像素点也为黑点,rgb值是(0,0,0),也就表示这一点不在检测框内,那么这两点相加后仍为黑点,也就是rgb值是(0,0,0);2、mask1图片中的某一像素点为黑点,rgb值是(0,0,0),也就代表这一点不在警示区域内,而mask2图片对应的像素点为白点,rgb值是(255,255,255),也就表示这一点在检测框内,那么两点相加的rgb值是(255,255,255),表示目标物体没有闯入警示区域;3、mask1图片中的某一像素点为白点,rgb值是(255,255,255),代表这一点在警示区域内,而mask2图片对应的像素点也为白点,rgb值是(255,255,255),代表这一点在检测框内,两点相加的rgb值是(510,510,510),由于rgb值是八位二进制的数,也就是rgb值最大为255,那么这两个点相加就会溢出,rgb值变成(254,254,254),这就代表目标物体闯入警示区域。
从而预设值即为rgb值(254,254,254),当mask1图片和mask2图片的每个像素点进行计算得到的结果值为(254,254,254)时,即可判断得出目标物体与警示区域重合,也就是目标物体闯入警示区域。相对于现有的只有检测框的顶点在警示区域内才算入侵的方式而言,本方案中只要检测框与警示区域任意一点重合,就判断为目标物体入侵了警示区域,因此能够减少入侵的漏报;并且本发明可以对视频监控图像进行实时精准的自动分析,及时发现潜在的安全风险,减少安全隐患,避免灾祸的发生。
实施例二
本实施例与实施例一的区别在于,如图2所示,还包括:
计时步骤:当目标物体不与警示区域重合时,开始计时;
离岗判断步骤:将计时结果与预设的时间阈值进行比较,判断目标物体是否离岗超时;
报警步骤:当目标物体离岗超时,则发出警报;
所述目标物体检测步骤之后还包括:
运动轨迹跟踪步骤:当检测到视频监控图像含有目标物体时,跟踪目标物体并获取该目标物体的运动轨迹。具体地,当目标物体出现在视频监控图像中时,利用跟踪算法对目标物体进行跟踪,例如采用dcfnet深度学习算法对目标物体进行跟踪,从而可得到该目标物体从初始帧开始的每一帧的坐标,也就是该目标物体的运动轨迹。当mask1图片和mask2图片的每个像素点相加得到的结果值为预设值(254,254,254)时,则代表在这一帧画面目标物体入侵警示区域,假设目标物体在第300帧画面时入侵了警示区域,则倒推从第一帧到300帧目标物体的坐标,从而可得到该目标物体的运动轨迹,例如,某些警示区域只能允许人从左往右通过,禁止人从右往左通过,通过运动轨迹可得出目标物体从哪个方向对警示区域存在越界入侵,从而实现对目标物体入侵方向的判断。
对于某些重要的场合,需要安防人员进行24小时的看守,通过本发明,可以监控安防人员是否位于看守处,安防人员作为目标物体,当安防人员位于看守处时,警示区域的mask1图片和目标物体的mask2图片的每个像素点相加后得到的结果值为(254,254,254),则判定安防人员在岗;当警示区域的mask1图片和目标物体的mask2图片的每个像素点相加后得到的结果值不为(254,254,254),则代表安防人员离开了看守处,开始计时,当计时的时长超过预先设置的时间阈值时,则判断安防人员离岗超时,发出警报通知相关人员,以使相关人员及时采取措施;通过目标物体与警示区域的重合与否,可判断出工作人员是在岗还是离岗,从而可实现对某些岗位的工作人员的实时监控。
实施例三
在某些场景下,例如某一栋楼的某一楼层的某些区域被划定为警示区域,不仅需要判定是否有目标物体入侵警示区域,还需要判断入侵人员的危险等级,以区分是恶意入侵还是无意间闯入警示区域。
针对这一场景,本发明还包括另一实施例,本实施例与实施例一的区别在于,监控点设置在大楼内各楼层的各个位置,还包括设置在各个交叉路口处的路牌指示灯,还包括:
路线生成步骤:当目标物体与警示区域重合时,根据该警示区域的位置和出口生成最短路线;
路牌指示灯控制步骤:根据最短路线控制相应的路牌指示灯闪亮;路牌指示灯指示的警示区域到出口的路线,从而可帮助目标物体尽快地找到离开该楼栋的出口,设置路牌指示灯也是为了检验目标物体是否为故意入侵警示区域,因为在有路牌指示灯指路的情况下,正常人一般都会选择按照指示前进,而非法入侵者为了躲避安防人员则不会按照指示前进;
实际停留时长计时步骤:当目标物体与警示区域重合时,开始计时目标物体离开出口之前的实际停留时长;
停留时长预估步骤:当目标物体与警示区域重合时,根据最短路线计算理论停留时长;例如,目标人员入侵的区域为某一栋楼的4楼,则目标物体从4楼到离开该栋楼的理论停留时长应该为20分钟;
时长及路线判断步骤:判断目标物体的实际停留时长是否超过理论停留时长,并判断目标物体是否按照路牌指示灯的指示从出口离开,并得到第一判断结果;当目标物体的实际停留时长不超过理论停留时长,且目标物体是按照路牌指示灯的指示从出口离开,则第一判断结果为目标物体无意闯入警示区域;其他情况则第一判断结果为目标物体恶意闯入警示区域;
运动路径预判步骤:当目标物体与警示区域重合时,跟踪目标物体并获取该目标物体的运动轨迹,根据目标物体的运动轨迹判断目标物体的行进路径;具体地,当目标物体与该楼栋的某一层楼的警示区域重合时,利用跟踪算法对目标物体进行跟踪,例如采用dcfnet深度学习算法对目标物体进行跟踪,从而可得到该目标物体从初始帧开始的每一帧的坐标,也就是该目标物体的运动轨迹;通过目标物体的运动轨迹可得出该目标物体的前进方向;
电梯控制步骤:根据目标物体的行进路径控制空的电梯停留在对应行进路径的楼层,并获取该楼层的高度;例如目标物体入侵的区域为某一楼栋的6楼,当该目标物体的行进路径被预判为下楼时,则控制电梯停留在5楼等待目标物体,让电梯等待目标物体是为了检验目标物体是否故意入侵警示区域,因为电梯内设有摄像头,如果目标物体故意入侵警示区域,则不会选择乘坐电梯;如果目标物体无意间闯入警示区域,则不会恐惧摄像头而选择乘坐电梯;
行进路径时长预估步骤:当目标物体与警示区域重合时,根据目标物体当前位置与停留在行进路径中的电梯停留位置预估目标物体到电梯处所需的步行时长;具体地,当某一个摄像头拍摄到目标物体与该摄像头的警示区域重合时,目标物体的当前位置也就是该摄像头的位置,假设各个摄像头与各层电梯之间的距离都被预先存储,以一个成年人正常步行速度来计算,则可得到目标物体当前位置到停留在行进路径中的电梯停留位置的步行时长;
电梯乘坐判断步骤:预设有高度阈值,判断楼层高度是否超过高度阈值;根据步行时长内电梯内的摄像头是否拍摄到目标物体来判断目标物体是否乘坐电梯,并得到第二判断结果;具体地,如果步行时长内目标物体未乘坐电梯,且楼层高度超过高度阈值,则第二判断结果为目标物体恶意闯入警示区域;其他情况则第二判断结果为目标物体无意间闯入警示区域;具体地,高度阈值为2,当超过该高度阈值时,人们一般会选择乘坐电梯下楼,当低于该高度阈值时,人们可能会选择步行下楼,楼层高度的判断是为了避免错将无意闯入警示区域的人员当作非法入侵者;
情绪识别步骤:当目标物体乘坐停留在行进路径上的电梯时,利用电梯内的摄像头对目标物体进行拍摄,并从拍摄的图像中提取目标物体的面部图像,通过面部图像识别用户情绪是否为恐惧或焦急不安,并得到第三判断结果;具体地,采用现有技术中的算法或软件来识别目标物体的情绪是否为恐惧或焦急不安,可以采用与第三方情绪识别平台合作,例如,将获取到的面部图像发送给现有的face++人工智能开放平台,该平台将是否识别到恐惧或焦急不安的情绪识别结果返回,当返回的结果为识别到恐惧或焦急不安的情绪时,则第三判断结果为目标物体恶意闯入警示区域;当返回的结果为未识别到恐惧或焦急不安的情绪时,则第三判断结果为目标物体无意间闯入警示区域;
危险等级评价步骤:根据第一判断结果、第二判断结果和第三判断结果对该目标物体划分危险等级;具体地,可预先设置危险等级评价表,根据该评价表来评价危险等级,由于目标物体未乘坐电梯时,则不会启动情绪识别步骤,也就没有第三判断结果,所以将第一判断结果、第二判断结果和第三判断结果归纳起来有以下6种情况,具体如表一所示:
表一
例如,当第一判断结果、第二判断结果和第三判断结果均为目标物体无意间闯入警示区域时,危险等级为一级;当第一判断结果、第二判断结果和第三判断结果中有任意一个结果为目标物体恶意闯入警示区域时,危险等级为二级;当第一判断结果、第二判断结果和第三判断结果中有任意两个结果为目标物体恶意闯入警示区域,以及第一判断结果为无意间闯入警示区域且第二判断结果为目标物体恶意闯入警示区域时,危险等级为三级;当第一判断结果、第二判断结果均为目标物体恶意闯入警示区域时,危险等级为四级。危险等级越高,则代表目标物体越危险;
预警信息发送步骤:根据划分的危险等级发送对应的预警信息给安保人员使用的移动终端。例如,当判断出危险等级为四级时,预警信息为围堵目标物体;当判断出危险等级为三级时,预警信息为搜查目标物体携带的物品和通信产品;当判断出危险等级为二级时,预警信息为盘问目标物体、登记目标物体信息;当判断出危险等级为一级时,预警信息为了解目标物体进出情况。
本实施例通过三个维度来判断目标物体危险等级,相对于仅从一个维度来判断而言,能够更加精确地分析判断目标物体是否恶意入侵警示区域,通过对目标物体危险等级的划分,能够区分出目标物体是恶意入侵还是无意间闯入警示区域,从而能够发送预警信息给对应的安保人员,让安保人员能够根据目标物体的危险等级作出不同的安防措施。
实施例四
本实施例与实施例三的区别在于:
等级判断步骤:判断目标物体的危险等级是否达到危险的最高等级;例如,最高危险等级为四级,目标物体的危险等级达到危险的最高等级时,也就可以确定目标物体为非法入侵者;
行进速度获取步骤:当目标物体的危险等级达到危险的最高等级时,根据目标物体的运动轨迹获取目标物体的行进速度,并判断行进速度是否超过速度阈值;当目标物体的行进速度超过速度阈值时,说明目标物体准备逃跑;
路灯控制步骤:当行进速度超过速度阈值时,控制目标物体行进路径上的路灯闪烁。非法入侵者逃跑过程中为了躲避摄像头和追赶者,一般会前往光线较暗的地方隐藏,通过控制行进路径上的路灯闪烁,让慌忙逃窜中的目标物体误以为有人追赶前来,从而让目标物体找寻另外黑暗的地方前往,以此来延长目标物体停留在楼栋里的时间,让安防人员能够有足够的时间前往该楼栋去围堵非法入侵者。
实施例五
当有非法入侵者恶意入侵警示区域时,需要通过识别拍摄到非法入侵者视频图像来识别入侵者的身份信息,从而留存入侵者的证据,以便于后期对入侵者的追溯,但是由于现有的摄像头一般都固定设置不能转动,所以摄像头存在拍摄的死角,再加上在入侵者逃跑的过程中速度较快,摄像头存在对入侵者抓拍画面不清晰的情况,导致安防人员后期无法识别到入侵者的身份,针对这一情况,本发明还包括另一实施例。
本实施例与实施例一的区别在于,各个监控点的摄像头处设有用于驱动摄像头转动的驱动机构,本实施例中的驱动机构为步进电机,步进电机信号连接有控制器;还包括:
运动路径预判步骤:当目标物体与警示区域重合时,根据目标物体的运动轨迹判断目标物体的行进路径;在实施例二中,当检测到视频监控图像含有目标物体时,跟踪目标物体并获取该目标物体的运动轨迹,所以通过目标物体的运动轨迹可得出该目标物体的前进方向,从而可以预判目标物体的行进路径;
特征提取步骤:当目标物体与警示区域重合时,提取目标物体的人体特征图像;也就是目标物体入侵警示区域后,即开始在视频监控图像中提取目标物体的人体特征图像;
图像分析步骤:对提取的人体特征图像进行分析,得出缺少的人体特征图像;具体地,利用现有技术的图像分析处理算法对人体特征图像进行识别分析,例如,拍摄到目标物体的前10张照片中只提取到目标物体的人体特征图像为右脸,从而得出缺少的人体特征图像包括左脸、眼睛、鼻子、嘴巴等特征图像;
摄像头控制步骤:控制器根据缺少的人体特征图像控制驱动机构驱动行进路径上的摄像头旋转合适角度以拍摄缺少的人体特征图像。具体地,假设目标物体在6楼下楼梯,则目标物体的行进路径肯定经过5楼的楼梯,从而控制5楼的楼梯口处的驱动机构驱动该处的摄像头旋转合适角度以对准目标物体的左脸,以获取缺少的目标物体的人体特征图像。
在目标物体逃跑的过程中,实时采集目标物体的人体特征图像并实时分析缺少的人体特征图像,从而能够不断地驱动目标物体行进路径中的摄像头旋转不同的角度对目标物体进行拍摄,从而能够获取到目标物体完整的人体特征图像,有利于安防人员后期对入侵者的追溯。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!