基于流量数据样本统计和平衡信息熵估计的网络异常检测方法与流程
本发明属于计算机网络安全技术领域,具体涉及基于流量数据样本统计和平衡信息熵估计的网络异常检测方法。
背景技术:
网络行为异常检查(nbad,networkbehavioranomalydetection)能连续监测专有网络的不寻常事件或趋势。网络行为异常检查是网络行为分析(nba)的主要部分。
网络行为异常检查(nbad,networkbehavioranomalydetection)能连续监测专有网络的不寻常事件或趋势。网络行为异常检查是网络行为分析(nba)的主要部分,除了传统反威胁应用程序(如防火墙、防病毒软件和间谍软件检测软件)提供的安全之外,网络行为分析也提供安全保护。
网络行为异常检查(nbad)程序实时跟踪关键网络特性,如果检测到一个不寻常事件或趋势,就生成显示威胁存在的警报。网络特性的例子有流量、带宽使用和协议使用。
网络行为异常检查程序还可以监视个人网络用户的行为。为了使网络行为异常检查达到最佳效果,就必须在一段时间内建立正常网络或用户行为的基准。一旦某些参数被定义为是正常的,那么违背一个或多个参数就会被标记为异常。
除了使用传统的防火墙和恶意软件检测软件外,也应使用网络行为异常检查(nbad)。一些厂商已开始认识到这一事实,并且将网络行为分析或网络行为异常检查作为其网络安全套件的主要组成部分。
熵是统计力学和信息论中衡量统计总体信息内容或随机变量不确定度的重要函数,目前常见的熵家族包括香农信息熵、rényi熵及tsallis熵。一般给定随机问题的全概率分布是未知的,大多数情况下是用小数据集来推断总体的分布情况。理论上由于熵具有非线性特性,对于使用小数据样本进行总体估计,不可能同时减小系统性偏差和统计方差,该问题在香农信息熵、rényi熵及tsallis熵中都同样存在。香农信息熵是rényi熵的特例,其使用范围广、接受度高且计算相对容易。
流量数据采集,广播式以太网的特征是广播数据,即在广播域内某个位置部署采集点能获取到该域所有数据流量。目前大多数基于ip的园区以太网属于交换式以太网,采集点位置选择、采集方式等很重要,否则无法获取到感兴趣的流量数据,具体需根据网络类型、拓扑设计采集方案。以一般的三层交换式以太网络为例,拒绝服务攻击一般针对服务器等重要资源,采集点应部署服务器所在的核心层,可采用网络端口镜像方式;端口扫描攻击应部署在靠近恶意终端所在的网络接入层,采用端口镜像方式,如果无法获知恶意终端的分布,采集点可部署在网络分布层。
网络流量特征选择,针对不同的网络攻击方式应选取不同的网络流量特征:如数据包ip地址-源端口-目的ip地址-目的端口-协议、数据包间隔时间、流量的大小、包长的信息、协议的信息、端口流量的信息、tcp标志位的信息、syn包的个数等,这些特征比较详细地描述了网络流量的运行状态。
在总体分布未知的网络流量数据中,通常由于数据采集的时间短,一般判断采集到的数据属于小样本数据集,根据前面的统计理论背景知识,如果直接采用样本信息熵公式估计总体存在偏离性,因此不能直接使用。
技术实现要素:
本发明的目的在于提供一种基于集网络流量小样本数据特征,使用样本信息熵的平衡方法来估计总体情况,识别网络中的dos和portscan攻击拒的检测方法。
本发明的目的是通过以下技术方案实现的:
基于流量数据样本统计和平衡信息熵估计的网络异常检测方法,其特征在于,包括以下步骤:
流量数据采集,采集核心层进出端口和恶意终端所在接入层进出端口的流量数据,同时采集公开基准数据;
统一数据格式,将采集流量数据获取的数据统一为json格式;
数据特征分析,对数据格式统一后的流量数据特征,采用信息熵的平衡估计方法来估计总体分布信息;
网络异常判断,基于网络流量数据特征分析得到的信息,采取k-s统计检验的方法计算出流量数据采集时得到的实际流量数据所构成的数据集的平衡信息熵估计值,并对其进行归一化处理得到相对系数用于判断流量数据的聚合程度并判断网络是否存在异常。
所述流量数据采集,是使用开源工具tcptrace、wireshark、ethereal、snort或商业软硬件系统cisconetflow、网络时间机器ntm、华为netstream中的一种或多种,用串联、旁挂或端口镜像的方式采集获取得到核心层进出端口和恶意终端所在接入层进出端口的流量数据以及公开基准数据。
所述公开基准数据为覆盖了probe,dos,r2l,u2r和data攻击方式的darpa入侵数据集。这里的darpa入侵数据集即美国防部高级计划研究署入侵数据集,darpa资助了入侵检测系统ids的开发工作,mit林肯实验室对其进行了评估,这是网络异常检测领域的开创性研究工作,对学界及工业界产生了重要影响,之后该领域众多科研工作都基于此展开。入侵数据集intrusiondataset是该工作的重要成果之一,目前虽有研究指出该数据集可能过时或存在其他问题,但其研究方法等仍具有重要指导意义。该数据集通过互联网可公开访问,本专利以此为基准数据集。
所述统一数据格式,采集到的流量数据包括ip数据包的header包头和payload载荷,只选取header包头的特征在离线状态下转换为json格式。国际互联网工程任务组ietf的rfc791等对ip数据包header格式进行了定义:ip数据包由header及payload组成,header包括ip协议版本号、长度、协议号、源和目的ip地址等字段信息,payload指ip数据包的数据载荷信息。
所述数据特征分析,信息熵的平衡估计方法估计总体分布信息的具体方法如下:
设离散随机变量x的取值范围为字母表a、集合大小为n,则使用香农信息熵带入得到信息熵平衡估计初值
随机变量x在字母表a和集合n相等时取得,信息熵平衡估计值最大值
用公式(1)得到的信息熵平衡估计初值
用公式(3)对信息熵平衡估计值进行归一化处理计算得到平衡熵估计值的相对系数r,优选地,相对系数r计算过程可参见实例步骤3。
相对系数r反应了特征值的聚合程度,r越趋近于0,说明特征值x聚集程度高,现实中假设x为目的ip地址,则可能出现大量源ip地址访问固定目的ip地址的数据流,考虑拒绝服务(dos)攻击情况。r趋近于1,说明特征值较分散,现实中假设x为源ip地址,可能出现的情况是端口扫描(portscan)攻击。
所述网络异常判断,k-s统计检验的具体方法如下:
用公开获取的数据的集作为参考数据集的分布,用于与获取到的实际流量数据进行比较,采用两样本k-s检验方法,用于判断在显著性水平。
设置置信区间dm,n:,且
其中
设置零假设检验条件,所述零假设检验条件为假设参考数据和实际流量数据的平衡信息熵不存在相似性,显著性水平为ɑ,如果
举例如,假定上述置信区间零假设是正确的,即参考数据集的平衡信息熵与实际数据集的平衡信息熵符合相同的概率分布,计算结果发生这样事件的概率小于显著性水平5%(经典费希尔阀值概率),则拒绝零假设,判断实际流量数据集存在异常。
所述的公开获取的数据集是指从互联网中可以获取到的网络异常及入侵检测数据集,一些研究机构和组织提供了免费下载。本方案使用的数据集包括(可从互联网下载):
1、darpa1998、1999、2000入侵检测数据集提供了probe、dos、r2l、u2r等典型网络攻击流量数据,是研究领域广泛使用的基准数据。
2、kddcup99数据集(可从www.kdd.org网站下载),基于网络ids入侵检测数据,模拟军用网络中的网络攻击等异常事件流量数据,对数据进行了标记,如该流量数据标记端口扫描数据、smurf攻击、正常数据等。标记为正常的数据可作为参考基准使用。
所述网络异常判断中,判断网络是否存在异常是对归一化处理得到的相对系数用于判断流量数据的聚合程度,进行流量数据是否存在dos、端口扫描攻击初步判断的,若判断结果中发现有异常的流量数据,则将有异常的流量数据与参考数据的集进行相似性对比。
所述相似性对比,是计算参考数据和有异常的流量数据的集平衡信息熵的置信区间,并设置零假设检验条件,所述零假设检验条件为假设参考数据和实际流量数据的平衡信息熵不存在相似性,在显著性水平ɑ的条件下进行计算,若置信区间大于该计算值,说明在该零假设下观察到这种数据的概率在显著性水平ɑ之下,则拒绝该零假设检验,判断网络中存在dos拒绝服务或端口扫描攻击。
与现有技术相比,本发明具有以下优点:
现有技术中采集到的网络流量数据在统计意义上属于小样本数据集,若直接使用样本参数估计总体分布会产生偏差,统计学理论已证明不可能同时降低均值和方差的偏离程度,本发明提出的基于流量数据样本统计和平衡信息熵估计的网络异常检测方法,在综合考虑各因素前提下,主要针对dos和portscan攻击,可选择数据包ip地址-源端口-目的ip地址-目的端口-协议、数据包间隔时间、数据包大小等特征,提出的使用样本信息熵的平衡方法来估计总体情况,能有效降低信息熵偏离程度,从而为后续k-s统计检验提供准确的数据基准。提出对采集到的流量数据要统一格式,不仅可用于本文进行后续分析处理还可方便应用其他统计处理方,本发明对流量数据特征进行了梳理,本发明方法对其他特征进行类似处理。
本发明选择使用香农信息熵(如果使用rényi熵、tsallis熵后续处理不存在本质区别),是目前的研究表明在同时减小系统均方差方面存在一种平衡的方法;本发明特别适合于小样本数据集估计总体分布情况,在网络拒绝服务dos和端口扫描(portscan)攻击检测等网络异常检测上特别有效。
现有技术直接使用样本数据特征来估计总体特征并据此进行后续检测处理,易造成较大误差。与直接用样本参数来估计总体信息不同,本发明采用的流量数据是基于小样本流量数据,现实中自行采集的数据在统计学意义上一般认为是小样本,这样做更符合实际。统计学上已证明小样本数据估计同时减小均值和方差的误差不可能同时做到,本专利采用减小均值和方差的一种信息熵平衡估计方法。
本发明对流量数据进行标准化处理,采用json格式,便于后续计算处理。采用该格式表达的网络流量数据特征不仅可用于本专利,还可用于其它数据处理分析方法,如k-s统计检验、kl距离等方法,采用k-s统计检验方法进行数据结果推断,有助于增强结果可信;本专利清楚的描述了如何获取网络数据、对数据进行标准化处理,具有较强的应用性。
附图说明
本发明的前述和下文具体描述在结合以下附图阅读时变得更清楚,其中:
图1是本发明流量数据处理流程;
图2是本发明组件架构示意;
图3是本发明基于三层以太网络拓扑流量数据采集(端口镜像)示意。
具体实施方式
下面通过几个具体的实施例来进一步说明实现本发明目的技术方案,需要说明的是,本发明要求保护的技术方案包括但不限于以下实施例。
实施例1
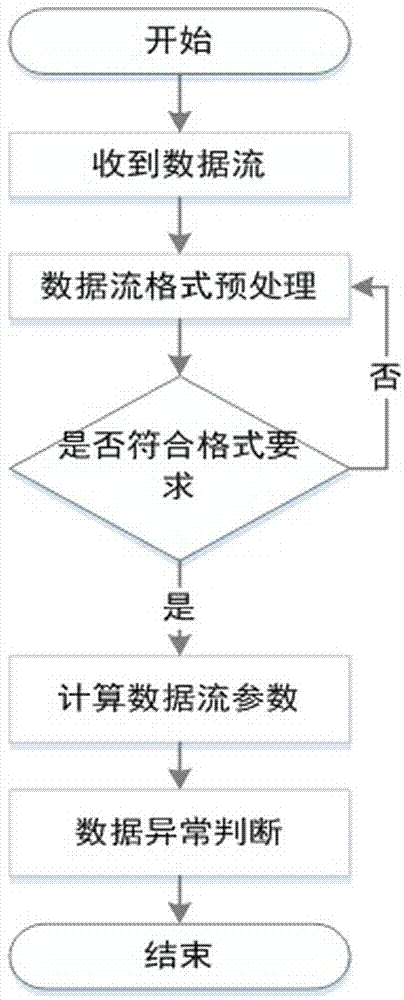
作为本发明一种最基本的实施方案,本实施例公开了基于流量数据样本统计和平衡信息熵估计的网络异常检测方法,如图1所示,包括以下步骤:
流量数据采集,采集核心层进出端口和恶意终端所在接入层进出端口的流量数据,同时采集公开基准数据;
统一数据格式,将采集流量数据获取的数据统一为json格式;
数据特征分析,对数据格式统一后的流量数据特征,采用信息熵的平衡估计方法来估计总体分布信息;
网络异常判断,基于网络流量数据特征分析得到的信息,采取k-s统计检验的方法计算出流量数据采集时得到的实际流量数据所构成的数据集的平衡信息熵估计值,并对其进行归一化处理得到相对系数用于判断流量数据的聚合程度并判断网络是否存在异常。
现有技术中采集到的网络流量数据在统计意义上属于小样本数据集,若直接使用样本参数估计总体分布会产生偏差,统计学理论已证明不可能同时降低均值和方差的偏离程度,本发明提出的基于流量数据样本统计和平衡信息熵估计的网络异常检测方法,在综合考虑各因素前提下,主要针对dos和portscan攻击,可选择数据包ip地址-源端口-目的ip地址-目的端口-协议、数据包间隔时间、数据包大小等特征,提出的使用样本信息熵的平衡方法来估计总体情况,能有效降低信息熵偏离程度,从而为后续k-s统计检验提供准确的数据基准。提出对采集到的流量数据要统一格式,不仅可用于本文进行后续分析处理还可方便应用其他统计处理方,本发明对流量数据特征进行了梳理,本发明方法对其他特征进行类似处理。
实施例2
为本发明一种最基本的实施方案,本实施例公开了基于流量数据样本统计和平衡信息熵估计的网络异常检测方法,如图1所示,包括以下步骤:
流量数据采集
采集核心层进出端口和恶意终端所在接入层进出端口的流量数据,同时采集公开基准数据;所述流量数据采集,是使用开源工具tcptrace、wireshark、ethereal、snort或商业软硬件系统cisconetflow、网络时间机器ntm、华为netstream中的一种或多种,用串联、旁挂或端口镜像的方式采集获取得到核心层进出端口和恶意终端所在接入层进出端口的流量数据以及公开基准数据;所述公开基准数据为覆盖了probe,dos,r2l,u2r和data攻击方式的darpa入侵数据集。这里的darpa入侵数据集即美国防部高级计划研究署入侵数据集,darpa资助了入侵检测系统ids的开发工作,mit林肯实验室对其进行了评估,这是网络异常检测领域的开创性研究工作,对学界及工业界产生了重要影响,之后该领域众多科研工作都基于此展开。入侵数据集intrusiondataset是该工作的重要成果之一,目前虽有研究指出该数据集可能过时或存在其他问题,但其研究方法等仍具有重要指导意义。该数据集通过互联网可公开访问,本专利以此为基准数据集。
统一数据格式
将采集流量数据获取的数据统一为json格式;采集到的流量数据包括ip数据包的header包头和payload载荷,只选取header包头的特征在离线状态下转换为json格式。国际互联网工程任务组ietf的rfc791等对ip数据包header格式进行了定义:ip数据包由header及payload组成,header包括ip协议版本号、长度、协议号、源和目的ip地址等字段信息,payload指ip数据包的数据载荷信息。
数据特征分析,对数据格式统一后的流量数据特征,采用信息熵的平衡估计方法来估计总体分布信息;信息熵的平衡估计方法估计总体分布信息的具体方法如下:
设离散随机变量x的取值范围为字母表a、集合大小为n,则使用香农信息熵带入得到信息熵平衡估计初值
随机变量x在字母表a和集合n相等时取得,信息熵平衡估计值最大值
用公式(1)得到的信息熵平衡估计初值
用公式(3)对信息熵平衡估计值进行归一化处理计算得到平衡熵估计值的相对系数r,优选地,相对系数r计算过程可参见实例步骤3。
相对系数r反应了特征值的聚合程度,r越趋近于0,说明特征值x聚集程度高,现实中假设x为目的ip地址,则可能出现大量源ip地址访问固定目的ip地址的数据流,考虑拒绝服务(dos)攻击情况。r趋近于1,说明特征值较分散,现实中假设x为源ip地址,可能出现的情况是端口扫描(portscan)攻击。
网络异常判断
基于网络流量数据特征分析得到的信息,采取k-s统计检验的方法计算出流量数据采集时得到的实际流量数据所构成的数据集的平衡信息熵估计值,并对其进行归一化处理得到相对系数用于判断流量数据的聚合程度并判断网络是否存在异常。
k-s统计检验的具体方法如下:
用公开获取的数据的集作为参考数据集的分布,用于与获取到的实际流量数据进行比较,采用两样本k-s检验方法,用于判断在显著性水平。
设置置信区间dm,n:,且
其中
设置零假设检验条件,所述零假设检验条件为假设参考数据和实际流量数据的平衡信息熵不存在相似性,显著性水平为ɑ,如果
举例如,假定上述置信区间零假设是正确的,即参考数据集的平衡信息熵与实际数据集的平衡信息熵符合相同的概率分布,计算结果发生这样事件的概率小于显著性水平5%(经典费希尔阀值概率),则拒绝零假设,判断实际流量数据集存在异常。
所述的公开获取的数据集是指从互联网中可以获取到的网络异常及入侵检测数据集,一些研究机构和组织提供了免费下载。本方案使用的数据集包括(可从互联网下载):
1、darpa1998、1999、2000入侵检测数据集提供了probe、dos、r2l、u2r等典型网络攻击流量数据,是研究领域广泛使用的基准数据。
2、kddcup99数据集(可从www.kdd.org网站下载),基于网络ids入侵检测数据,模拟军用网络中的网络攻击等异常事件流量数据,对数据进行了标记,如该流量数据标记端口扫描数据、smurf攻击、正常数据等。标记为正常的数据可作为参考基准使用。
所述网络异常判断中,判断网络是否存在异常是对归一化处理得到的相对系数用于判断流量数据的聚合程度,进行流量数据是否存在dos、端口扫描攻击初步判断的,若判断结果中发现有异常的流量数据,则将有异常的流量数据与参考数据的集进行相似性对比。
所述相似性对比,是计算参考数据和有异常的流量数据的集平衡信息熵的置信区间,并设置零假设检验条件,所述零假设检验条件为假设参考数据和实际流量数据的平衡信息熵不存在相似性,在显著性水平ɑ的条件下进行计算,若置信区间大于该计算值,说明在该零假设下观察到这种数据的概率在显著性水平ɑ之下,则拒绝该零假设检验,判断网络中存在dos拒绝服务或端口扫描攻击。
如3,一种基于小样本流量数据统计和平衡信息熵估计的端口扫描及拒绝服务攻击检测的系统,其特征在于:
组件1、用于网络流量数据采集方法。
组件2、用于网络流量数据格式标准化处理。
组件3、流量数据特征分析处理模块,用于针对小样本数据集的信息熵平衡估计分析处理。
组件4、用于网络拒绝服务和端口扫描攻击等的网络异常检测模块。
其中流量数据采集可采用现有的开源或商业软件,数据格式统一处理模块,需根据后续数据特征的要求对采集到的数据进行统一处理。数据分析处理模块和异常检测判断是单独搭建的模块,实现小样本网络流量数据的异常攻击检测。
步骤1、根据特定的网络,设计流量数据采集方案,用以在特定网络环境中采集流量数据,可采用开源工具如tcptrace、wireshark、ethereal、snort等,具备条件的可采用商业软硬件系统如cisconetflow、网络时间机器ntm、华为netstream等,根据不同的网络类型(如sdn网络、一般ip数据网络)、拓扑设计相应的数据采集方法,如采用串联、旁挂、端口镜像等。流量数据采集方法很重要,直接关系到后续分析处理,影响判断结果:在拒绝服务攻击检测中,流量数据采集应能获取到重要服务器等设备所在的核心层进出端口的流量数据;在网络端口扫描攻击检测中,流量数据应能获取到恶意终端所在的接入层进出端口的流量数据。同时获取公开基准数据(选择darpaintrusiondataset,该数据集覆盖了probe,dos,r2l,u2r和data等常见攻击方式,本方法选用probe,dos数据集)。
步骤2、流量数据格式统一化处理。一般的采集到的流量数据不能方便使用,综合分析比较目前的数据通用格式xml和json,选取json格式(实施方式举例)便于后续计算处理,同时由于格式通用还可用于除本发明外的其它统计处理方法。该统一化处理模块是离线操作,不影响数据采集性能。
步骤3、流量数据特征分析处理。对采集到的流量特征进行分析处理,采用信息熵的平衡估计方法来估计总体分布情况。计算举例:
离散随机变量x取值范围为字母表a,集合大小为n,假设随机变量可取四种值z=4,如a={x1,x2,x3,x4},有n=10个数据:{x1x1x2x4x3x2x1x2x1x3}对应的n1=4n2=3n3=2n4=1(其中xi可代表网络流量数据的特征,如源ip地址、源端口等)代入公式计算该小数据集样本信息熵的平衡估计值为:1.3762,样本最大信息熵的平衡估计值为2.9863;直接使用香农信息熵带入p1=0.4,p2=0.3,p3=0.2,p4=0.1计算得到1.2799,可看出两者差距较大,直接影响后续判断准确度。
相对系数的最大值rmax=2在样本取最大熵平衡估计且集合数n趋于无穷时得到。本例中样本信息熵平衡估计值的相对系数r为1.3762/log(10)=0.5977;信息熵最大值的平衡估计相对系数r为2.9863/log(10)=1.2969相对系数r反应了特征值的聚合程度,可根据r大小进行初步判断。r越趋近于0,说明特征值x聚集程度高,现实中假设x为目的ip地址,则可能出现大量源ip地址访问固定目的ip地址的数据流,考虑拒绝服务(dos)攻击情况。r趋近于1,说明特征值较分散,现实中假设x为源ip地址,可能出现的情况是端口扫描(portscan)攻击。
步骤4、网络异常检测判断。使用基于小样本平衡估计的信息上来推断总体分布情况,与从公开获取的流量数据进行比对判断。本发明采取k-s统计检验的方法,结合置信区间,给出合理的判断结果。网络端口扫描攻击中源ip地址固定,而目的ip地址/端口分散,即源ip地址聚合程度高而目的ip地址聚合程度低,可根据源-目的ip/端口聚合程度的信息熵准确判断网络中是否存在该攻击;而拒绝服务攻击中目的地址聚合程度高,可用同样方法判断网络中是否存在拒绝服务攻击。可重复几次采集网络流量数据,取均值采用本方法进行异常检测,进一步提高结果准确度。
本专利使用小样本网络流量数据信息平衡熵来估计总体熵。
信息熵平衡估计值计算公式(1),公式1的最大值在字母表a和集合n相等时取得,最大值为(2),用公式1除以2将平衡估计值规范化。(见具体实施方式举例)
对样本熵的平衡估计值进行归一化处理,得到平衡熵相对系数r:
3k-s检验统计可定量测定样本分布函数与参考分布函数的距离。本专利将公开获取的数据集设置为参考数据集的分布,用实际获取到的数据与其进行比较,设置置信区间,对结果进行统计推断。
其中
所述网络异常判断,是基于网络流量数据特征分析得到的信息,采取k-s统计检验的方法,计算实际数据集的平衡信息熵估计值,并对其进行归一化处理,通过归一化处理得到的相对系数用于判断流量数据的聚合程度,进行流量数据是否存在dos、端口扫描攻击初步判断。若结果发现感兴趣的流量数据,可进行下一步实际和参考数据集相似性比较。计算参考和实际数据集平衡信息熵的置信区间,设置零假设检验:假设参考和实际数据平衡信息熵不存在相似性,在显著性水平ɑ(一般设置为0.05经典阀值)进行计算,若置信区间大于该计算值,说明在该零假设下观察到这种数据的概率不到0.05,则拒绝该零假设检验,判断网络中存在dos拒绝服务或端口扫描攻击。
- 还没有人留言评论。精彩留言会获得点赞!