配置成定位目标声源的听力系统的制作方法
本申请涉及听力装置如助听器领域,本申请还涉及听力系统如双耳助听器系统领域。
背景技术:
到达方向(doa)估计和声源位置估计变得日益重要。一些例子是在wifi接入点和移动基站中节能和用户跟踪、声源的检测和跟踪。使用现代阵列处理技术,应用如大规模多输入输出(m-mimo)和有源电子扫描阵列(aesa)雷达可操纵输出能或者天线在希望方向的灵敏度。aesa和m-mimo均基于平面阵列,从而按方位角和仰角产生方向性。然而,一些系统可能受限于用于计算doa的线性阵列,例如每只耳朵使用一个传声器及在深海探索时使用拖曳阵列的双耳助听器系统(has)仅可估计一个角度。
技术实现要素:
本申请涉及听力装置如助听器,尤其涉及捕获用户周围环境中的声音信号。本发明的实施例涉及合成孔径到达方向,例如使用助听器及可能惯性传感器。本发明的实施例涉及体戴式(例如头戴式)听力装置,其包括具有比适于位于用户耳朵中或耳朵处的典型助听器大的尺寸的载体,例如大于0.05m,例如体现在眼镜架中。
到达方向(doa)是估计感兴趣的声源的方向的技术。在本说明书中,感兴趣的声源主要为人类讲话者,但该技术可应用于任何声源。在许多场合,感兴趣能够借助于声源的空间分布即它们的不同doa分离声源。例子为“鸡尾酒会”场合中的声源分类、用于噪声衰减的波束形成、及十分有关的“餐厅问题解决者”。当使用仅包括位于用户的左和右耳处的左和右听力装置如助听器(ha)的听力系统进行doa确定时,两个基本限制起作用,其中左和右听力装置中的每一个包括至少一输入变换器如传声器,输入变换器一起形成变换器(如传声器)阵列(称为doa阵列):
1、对于右和左ha,仅考虑每ha一个传声器,构成doa阵列,仅可计算从doa阵列的起点到声源的线(向量)与阵列向量之间的角度,二者均为3d空间中的向量(参见图1b)。这意味着doa在3d空间中模糊,即相对于声源的仰角和方位角不能分开地确定。在2d情形下,即当该阵列和声源处于同一平面中时,仅有镜像模糊,不能确定声源是在doa阵列的前面还是后面。
2、如果ha用户因转动其头部(纯粹的转动)而运动和/或移动(平移),不能确定是ha用户还是声源移动。
为解决这些限制,考虑配备有3d陀螺仪、3d加速计和3d磁力计(所谓的惯性测量单元,缩写为imu)的ha。imu使能估计ha定向及对应地估计doa阵列定向,关于局部重力场和局部磁场。同样,在短时间间隔中,ha的平移可被估计。使用用imu估计的doa阵列的定向和平移,上面列出的限制可被克服。
听力系统
本发明目标在于使用(空间上)截然不同的doa阵列定向估计到用户周围环境中的声源的三维(3d)方向,假定两个以上doa测量结果(其中转动未在传感器阵列周围进行,因为这不提供信息)。本发明还使能估计声源的3d定位,假定三个以上截然不同的doa阵列位置(其中传感器阵列位置不必直接放在doa上,因为这不提供信息)。
总之,通过随时间估计(或记录)ha用户的头部位置和定向(反映用户相对于声源的运动),来自2ddoa传感器阵列的3ddoa传感器可被合成。这使能估计到声源的3ddoa及声源的3d位置。
在本申请的一方面,提供一种适于由用户佩戴并配置成捕获用户环境中的声音(当听力系统在工作时安装在用户身上时)的听力系统。该听力系统包括:
-m个输入变换器如传声器的传感器阵列,其中m≥2,每一输入变换器提供表示所述环境中的所述声音的电输入信号,所述传感器阵列的所述输入变换器pi,i=1,…,m在听力系统由用户佩戴时相对于彼此具有已知的几何配置。
所述听力系统还包括:
-检测器单元,用于在听力系统由用户佩戴时检测听力系统随时间的运动并提供所述传感器阵列在不同时间点t,t=1,…,n的定位数据;
-第一处理器,用于接收所述电输入信号及(在所述声音包括来自被定位的声源s的声音的情形下)用于提取所述传感器阵列的传感器阵列配置特有数据τij,所述数据标示来自所述被定位的声源s的声音在不同时间点t,t=1,…,n到达相应输入变换器的到达时间之间的差;及
-第二处理器,配置成基于在所述不同时间点t,t=1,…,n所述定位数据和所述传感器阵列配置数据的对应值估计标示所述被定位的声源s相对于用户的定位的数据。
从而可提供一种改进的听力系统。
术语“被定位的声源”例如包括来自人类的语音的声源意为在用户环境中的空间中具有特定(非弥散性)起点的点类声源。被定位的声源可相对于用户移动(因用户或被定位的声源或者二者移动)。
在实施例中,包括听力系统(包含传感器阵列)的用户的初始空间定位(例如在t=0时)对听力系统而言已知,例如在惯性坐标系中。在实施例中,声源的初始空间定位(例如在t=0时)对听力系统而言已知。在实施例中,包括听力系统(包含传感器阵列)的用户的初始空间定位及声源的初始空间定位(例如在t=0时)对听力系统而言已知。惯性坐标系可被固定到具体房间。传感器阵列的输入变换器的定位可在相对于用户身体固定的身体坐标系中定义。
检测器单元可配置成检测听力系统的转动和/或平移运动。检测器单元可包括各个传感器或者集成的传感器。
标示被定位的声源s在所述不同时间点t,t=1,…,n相对于用户的定位的数据可构成或包括来自所述声源s的声音的到达方向。
标示被定位的声源s在所述不同时间点t,t=1,…,n相对于用户的定位的数据可包括所述声源相对于所述用户的坐标或者来自所述声源的声音相对于所述用户的到达方向及所述用户距所述声源的距离。
检测器单元可包括多个imu传感器,包括加速计、陀螺仪和磁力计中的至少一个。惯性测量单元(imu)如加速计、陀螺仪、磁力计及其组合可以多种形式获得(例如多轴,如3d版),例如由集成电路构成或者形成集成电路的一部分,因而适合集成,即使在微型装置如听力装置例如助听器中。传感器可形成听力系统的一部分或者可以是单独的、个别的装置,或者形成其它设备如智能电话或可穿戴设备的一部分。
第二处理器可配置成基于下面源自所述时刻t=1,…,n的堆叠(stacked)剩余向量r(se)的表达式估计标示被定位的声源s相对于用户的定位的数据
其中se表示所述声源在惯性参照系中的位置,rt和
第二处理器可形成听力系统的一部分,例如可被包括在听力装置中(或者被包括在双耳听力系统的两个听力装置中)。作为备选,第二处理器可形成单独的设备的一部分,例如与听力系统通信的智能电话或其它(固定不动的或者可穿戴的)设备。
第二处理器可配置成在最大似然框架中解决堆叠剩余向量r(se)表示的问题。
第二处理器可配置成使用扩展卡尔曼滤波器(extendedkalmanfilter,ekf)算法解决堆叠剩余向量r(se)表示的问题。
听力系统可包括第一和第二听力装置例如助听器,适于位于用户的左和右耳处或者左和右耳中或者完全或部分植入在用户的左和右耳处的头部中。第一和第二听力装置中的每一个可包括:
-至少一输入变换器,用于提供表示所述环境中的声音的电输入信号;
-至少一输出变换器,用于按照所述环境中的声音的表示提供可由用户感知的刺激。
所述第一和第二听力装置的至少一输入变换器可构成所述传感器阵列或者形成所述传感器阵列的部分。
第一和第二听力装置中的每一个可包括用于与另一听力装置和/或与辅助装置无线交换所述电输入信号中的一个或多个或者其部分的电路(例如天线和收发器电路)。第一和第二听力装置中的每一个可配置成将所述电输入信号中的一个或多个(或其部分,例如所选频带)转发给相应的另一个听力装置(可能经中间装置)或者转发给单独的(辅助)处理装置如遥控器或智能电话。
听力系统可包括助听器、头戴式耳机、耳麦、耳朵保护装置或者组合。
第一和第二听力装置可由相应的第一和第二助听器构成或者包括相应的第一和第二助听器。
听力系统可适于身体佩戴,例如头部佩戴。听力系统可包括载体,例如用于承载所述传感器阵列的m个输入变换器的至少部分。该载体如眼镜架可具有比适于位于用户耳朵中或耳朵处的典型助听器大的尺寸,例如大于0.05m,例如大于0.10m。载体可具有弯曲或有角度的(例如铰接)结构(例如镜框)。载体可配置成承载检测器单元的传感器(如imu传感器)的至少部分。
当载体包含输入变换器和/或传感器(例如m≥12个传声器)时,载体(如眼镜架)的形状因数很重要。其是确定从来自输入变换器的电输入信号产生的波束图的波束宽度的、传声器之间的物理距离。输入变换器(如传声器)之间的距离越大,可形成越窄的波束。窄波束通常不可能在助听器中产生(形状因数具有几厘米的最大尺寸)。在实施例中,听力系统包括具有沿(实质上平面)曲线(优选跟随佩戴听力系统的用户的头部的曲度)的尺寸的载体,从而使能(在工作时)安装最小数量的(nit个)输入变换器。输入变换器的最小数量nit例如可以是4或8或12。输入变换器的最小数量nit例如可等于m,例如小于或等于m。载体可具有至少0.1m的纵向尺寸,如至少0.15m,如至少0.2m,如至少0.25m。
听力系统的输入变换器(如传声器)之间的适当距离可从目前的波束形成技术提取(例如0.01m或更大)。然而,也可使用需要小得多的间隔的其它到达方向(doa)原理,例如小于0.008m,如小于0.005m,如小于0.002m(2mm),例如参见ep3267697a1。
在实施例中,载体配置成承载一个或多个照相机(例如场景照相机,例如用于同时定位和建图(simultaneouslocalizationandmapping,slam)及用于眼睛凝视的眼球跟踪照相机,例如一个或多个高速照相机)。听力系统可包括眼球跟踪照相机,或与eog传感器一起,或作为eog传感器的替代。
场景照相机可包括面部跟踪算法以给出脸在场景中的位置。从而可确定(潜在的)被定位的声源(及估计到该声源的方向或者该声源的定位)。
在实施例中,听力系统包括用于眼球跟踪的eog(基于位于助听器中或助听器上的eog传感器)与用于slam的场景照相机(例如安装在助听器上(顶部))按助听器形状因数的组合(例如定位在位于用户的一只或两只耳朵中或耳朵处的一个或多个助听器的壳体中)。
在实施例中,听力系统包括与用于运动跟踪/头部转动的imu结合的、用于眼球跟踪的eog(基于eog传感器,例如电极,或眼球跟踪照相机)与用于slam的场景照相机的组合。
通过定位用户周围的声源(例如使用slam),声源的原始位置的映像可通过应用标准化的头部相关传递函数(hrtf)进行“重复”。由于我们知道声源在空间中的何处(例如经slam),当我们将声音呈现给左和右耳时,我们可将不同的声源投射到它们的“原始”位置。在实施例中,针对相对于参考方向(如用户的视向)的不同入射角的头部相关传递函数的数据库可由听力系统访问(例如存储在听力系统的存储器中,或者可由听力系统访问)。
听力系统可包括辅助装置,其包括第二处理器,配置成基于在所述不同时间点t,t=1,…,n所述定位数据和所述传感器阵列配置数据的对应值估计标示所述被定位的声源s相对于用户的定位的数据。
辅助装置可包括第一处理器,用于接收所述电输入信号及在所述声音包括来自被定位的声源s的声音的情形下用于提取所述传感器阵列的传感器阵列配置特有数据τij,所述数据标示来自所述被定位的声源s的声音在不同时间点t,t=1,…,n到达相应输入变换器的到达时间之间的差。
听力系统可包括听力装置(例如双耳听力系统的第一和第二听力装置)和辅助装置。
在实施例中,该听力系统适于在听力装置和辅助装置之间建立通信链路以使信息(如控制和状态信号(例如包括检测器信号,例如位置数据),和/或可能音频信号)能在其间进行交换或从一装置转发给另一装置。
在实施例中,听力系统包括辅助装置,例如遥控器、智能电话、或者其它便携或可穿戴电子设备如智能手表等。
在实施例中,辅助装置是或包括遥控器,用于控制听力装置的功能和运行。在实施例中,遥控器的功能实施在智能电话中,该智能电话可能运行使能经智能电话控制听力装置的功能的app(听力装置包括适当的到智能电话的无线接口,例如基于蓝牙或一些其它标准化或专有方案)。
在实施例中,听力系统包括两个听力装置,适于实施双耳听力系统例如双耳助听器系统。
听力装置
在实施例中,听力装置适于提供随频率而变的增益和/或随电平而变的压缩和/或一个或多个频率范围到一个或多个其它频率范围的移频(具有或没有频率压缩)以补偿用户的听力受损。在实施例中,听力装置包括用于增强输入信号并提供处理后的输出信号的信号处理器。
在实施例中,听力装置包括输出单元,用于基于处理后的电信号提供由用户感知为声学信号的刺激。在实施例中,输出单元包括耳蜗植入物的多个电极或者骨导听力装置的振动器。在实施例中,输出单元包括输出变换器。在实施例中,输出变换器包括用于将刺激作为声信号提供给用户的接收器(扬声器)。在实施例中,输出变换器包括用于将刺激作为颅骨的机械振动提供给用户的振动器(例如在附着到骨头的或骨锚式听力装置中)。
在实施例中,听力装置包括用于提供表示声音的电输入信号的输入单元。在实施例中,输入单元包括用于将输入声音转换为电输入信号的输入变换器如传声器。在实施例中,输入单元包括用于接收包括声音的无线信号并提供表示所述声音的电输入信号的无线接收器。
在实施例中,听力装置包括定向传声器系统(如波束形成器滤波单元),其适于对来自环境的声音进行空间滤波从而增强佩戴听力装置的用户的局部环境中的多个声源之中的目标声源。在实施例中,定向系统适于检测(如自适应检测)传声器信号的特定部分源自哪一方向(doa)。在助听器中,传声器阵列波束形成器通常用于空间上衰减背景噪声源。许多波束形成器变型可在文献中找到。最小方差无失真响应(mvdr)波束形成器广泛用在传声器阵列信号处理中。理想地,mvdr波束形成器保持来自目标方向(也称为视向)的信号不变,而最大程度地衰减来自其它方向的声音信号。广义旁瓣抵消器(gsc)结构是mvdr波束形成器的等同表示,其相较原始形式的直接实施提供计算和数字表示优点。
在实施例中,听力装置包括用于从另一装置如从娱乐设备(例如电视机)、通信装置、无线传声器或另一听力装置接收直接电输入信号的天线和收发器电路(如无线接收器)。在实施例中,直接电输入信号表示或包括音频信号和/或控制信号和/或信息信号。在实施例中,听力装置包括用于对所接收的直接电输入进行解调的解调电路,以提供表示音频信号和/或控制信号的直接电输入信号,例如用于设置听力装置的运行参数(如音量)和/或处理参数。总的来说,听力装置的天线及收发器电路建立的无线链路可以是任何类型。在实施例中,无线链路在两个装置之间建立,例如在娱乐设备(如tv)与听力装置之间,或者在两个听力装置之间,例如经第三中间装置(如处理装置,例如遥控装置、智能电话等)。在实施例中,无线链路在功率约束条件下使用,例如由于听力装置是或包括便携式(通常电池驱动的)装置。在实施例中,无线链路为基于近场通信的链路,例如基于发射器部分和接收器部分的天线线圈之间的感应耦合的感应链路。在另一实施例中,无线链路基于远场电磁辐射。在实施例中,经无线链路的通信根据特定调制方案进行安排,例如模拟调制方案,如fm(调频)或am(调幅)或pm(调相),或数字调制方案,如ask(幅移键控)如开-关键控、fsk(频移键控)、psk(相移键控)如msk(最小频移键控)或qam(正交调幅)等。
优选地,听力装置与另一装置之间的通信基于高于100khz的频率下的某类调制。优选地,用于在听力装置和另一装置之间建立通信链路的频率低于70ghz,例如位于从50mhz到70ghz的范围中,例如高于300mhz,例如在高于300mhz的ism范围中,例如在900mhz范围中或在2.4ghz范围中或在5.8ghz范围中或在60ghz范围中(ism=工业、科学和医学,这样的标准化范围例如由国际电信联盟itu定义)。在实施例中,无线链路基于标准化或专用技术。在实施例中,无线链路基于蓝牙技术(如蓝牙低功率技术)。
在实施例中,听力装置为便携装置,如包括本机能源如电池例如可再充电电池的装置。
在实施例中,听力装置包括输入单元(如输入变换器,例如传声器或传声器系统和/或直接电输入(如无线接收器))和输出单元如输出变换器之间的正向或信号通路。在实施例中,信号处理器位于该正向通路中。在实施例中,信号处理器适于根据用户的特定需要提供随频率而变的增益。在实施例中,听力装置包括具有用于分析输入信号(如确定电平、调制、信号类型、声反馈估计量等)的功能件的分析通路。在实施例中,分析通路和/或信号通路的部分或所有信号处理在频域进行。在实施例中,分析通路和/或信号通路的部分或所有信号处理在时域进行。
在实施例中,表示声信号的模拟电信号在模数(ad)转换过程中转换为数字音频信号,其中模拟信号以预定采样频率或采样速率fs进行采样,fs例如在从8khz到48khz的范围中(适应应用的特定需要)以在离散的时间点tn(或n)提供数字样本xn(或x[n]),每一音频样本通过预定的nb比特表示声信号在tn时的值,nb例如在从1到48比特的范围中如24比特。每一音频样本因此使用nb比特量化(导致音频样本的2nb个不同的可能的值)。数字样本x具有1/fs的时间长度,如50μs,对于fs=20khz。在实施例中,多个音频样本按时间帧安排。在实施例中,一时间帧包括64个或128个音频数据样本。根据实际应用可使用其它帧长度。
在实施例中,听力装置包括模数(ad)转换器以按预定的采样速率如20khz对模拟输入(例如来自输入变换器如传声器)进行数字化。在实施例中,听力装置包括数模(da)转换器以将数字信号转换为模拟输出信号,例如用于经输出变换器呈现给用户。
在实施例中,听力装置如传声器单元和/或收发器单元包括用于提供输入信号的时频表示的tf转换单元。在实施例中,时频表示包括所涉及信号在特定时间和频率范围的相应复值或实值的阵列或映射。在实施例中,tf转换单元包括用于对(时变)输入信号进行滤波并提供多个(时变)输出信号的滤波器组,每一输出信号包括截然不同的输入信号频率范围。在实施例中,tf转换单元包括用于将时变输入信号转换为(时-)频域中的(时变)信号的傅里叶变换单元。在实施例中,听力装置考虑的、从最小频率fmin到最大频率fmax的频率范围包括从20hz到20khz的典型人听频范围的一部分,例如从20hz到12khz的范围的一部分。通常,采样率fs大于或等于最大频率fmax的两倍,即fs≥2fmax。在实施例中,听力装置的正向通路和/或分析通路的信号拆分为ni个(例如均匀宽度的)频带,其中ni例如大于5,如大于10,如大于50,如大于100,如大于500,至少其部分个别进行处理。在实施例中,助听器适于在np个不同频道处理正向和/或分析通路的信号(np≤ni)。频道可以宽度一致或不一致(如宽度随频率增加)、重叠或不重叠。
在实施例中,听力装置包括多个检测器,其配置成提供与听力装置的当前网络环境(如当前声环境)有关、和/或与佩戴听力装置的用户的当前状态有关、和/或与听力装置的当前状态或运行模式有关的状态信号。作为备选或另外,一个或多个检测器可形成与听力装置(如无线)通信的外部装置的一部分。外部装置例如可包括另一听力装置、遥控器、音频传输装置、电话(如智能电话)、外部传感器等。
在实施例中,多个检测器中的一个或多个对全带信号起作用(时域)。在实施例中,多个检测器中的一个或多个对频带拆分的信号起作用((时-)频域),例如在有限的多个频带中。
在实施例中,多个检测器包括用于估计正向通路的信号的当前电平的电平检测器。在实施例中,预定判据包括正向通路的信号的当前电平是否高于或低于给定(l-)阈值。在实施例中,电平检测器作用于全频带信号(时域)。在实施例中,电平检测器作用于频带拆分信号((时-)频域)。
在特定实施例中,听力装置包括话音检测器(vd),用于估计输入信号(在特定时间点)是否(或者以何种概率)包括话音信号。在本说明书中,话音信号包括来自人类的语音信号。其还可包括由人类语音系统产生的其它形式的发声(如唱歌)。在实施例中,话音检测器单元适于将用户当前的声环境分类为“话音”或“无话音”环境。这具有下述优点:包括用户环境中的人发声(如语音)的电传声器信号的时间段可被识别,因而与仅(或主要)包括其它声源(如人工产生的噪声)的时间段分离。在实施例中,话音检测器适于将用户自己的话音也检测为“话音”。作为备选,话音检测器适于从“话音”的检测排除用户自己的话音。
在实施例中,多个检测器包括运动检测器,例如加速度传感器,如直线加速度或转动传感器(例如陀螺仪)。在实施例中,运动检测器配置成检测例如记录用户随时间的运动,例如从已知的起点。
在实施例中,听力装置包括分类单元,配置成基于来自(至少部分)检测器的输入信号及可能其它输入对当前情形进行分类。在本说明书中,“当前情形”由下面的一个或多个定义:
a)物理环境(如包括当前电磁环境,例如出现计划或未计划由听力装置接收的电磁信号(包括音频和/或控制信号),或者当前环境不同于声学的其它性质);
b)当前声学情形(输入电平、反馈等);
c)用户的当前模式或状态(运动、温度、认知负荷等);
d)听力装置和/或与听力装置通信的另一装置的当前模式或状态(所选程序、自上次用户交互之后消逝的时间等)。
在实施例中,听力装置还包括用于所涉及应用的其它适宜功能,如压缩、降噪、反馈抑制等。
在实施例中,听力装置包括听音装置,例如助听器,例如听力仪器,例如适于位于用户耳朵处或者完全或部分位于耳道中的听力仪器,例如头戴式耳机、耳麦、耳朵保护装置或其组合。在实施例中,听力装置包括喇叭扩音器(包含多个输入变换器和多个输出变换器,例如用在音频会议情形下),例如包括波束形成器滤波单元,例如提供多种波束形成能力。
方法
一方面,本申请还提供适于由用户佩戴并配置成捕获用户环境中的声音(当听力系统在工作时安装在用户身上时)的听力系统的运行方法。所述听力系统包括m个输入变换器如传声器的传感器阵列,其中m≥2,每一输入变换器提供表示所述环境中的所述声音的电输入信号,所述传感器阵列的所述输入变换器pi,i=1,…,m在听力系统由用户佩戴时相对于彼此具有已知的几何配置。所述方法包括:
-在听力系统由用户佩戴时检测听力系统随时间的运动并提供所述传感器阵列在不同时间点t,t=1,…,n的定位数据;
-在所述声音包括来自被定位的声源s的声音的情形下,从所述电输入信号提取所述传感器阵列的传感器阵列配置特有数据τij,所述数据标示来自所述被定位的声源s的声音在不同时间点t,t=1,…,n到达相应输入变换器的到达时间之间的差;及
-基于在所述不同时间点t,t=1,…,n所述定位数据和所述传感器阵列配置数据的对应值估计标示所述被定位的声源s相对于用户的定位的数据。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的或权利要求中限定的系统的部分或所有结构特征可与本发明方法的实施结合,反之亦然。方法的实施具有与对应系统一样的优点。
计算机可读介质
本发明进一步提供保存包括程序代码的计算机程序的有形计算机可读介质,当计算机程序在数据处理系统上运行时,使得数据处理系统执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
作为例子但非限制,前述有形计算机可读介质可包括ram、rom、eeprom、cd-rom或其他光盘存储器、磁盘存储器或其他磁性存储装置,或者可用于执行或保存指令或数据结构形式的所需程序代码并可由计算机访问的任何其他介质。如在此使用的,盘包括压缩磁盘(cd)、激光盘、光盘、数字多用途盘(dvd)、软盘及蓝光盘,其中这些盘通常磁性地复制数据,同时这些盘可用激光光学地复制数据。上述盘的组合也应包括在计算机可读介质的范围内。除保存在有形介质上之外,计算机程序也可经传输介质如有线或无线链路或网络如因特网进行传输并载入数据处理系统从而在不同于有形介质的位置处运行。
计算机程序
此外,本申请提供包括指令的计算机程序(产品),当该程序由计算机运行时,导致计算机执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法(的步骤)。
数据处理系统
一方面,本发明进一步提供数据处理系统,包括处理器和程序代码,程序代码使得处理器执行上面描述的、“具体实施方式”中详细描述的及权利要求中限定的方法的至少部分(如大部分或所有)步骤。
app
另一方面,本发明还提供称为app的非短暂应用。app包括可执行指令,其配置成在辅助装置上运行以实施用于上面描述的、“具体实施方式”中详细描述的及权利要求中限定的听力装置或(例如双耳)听力系统的用户接口。在实施例中,该app配置成在移动电话如智能电话或另一使能与所述听力装置或听力系统通信的便携装置上运行。
定义
在本说明书中,“听力装置”指适于改善、增强和/或保护用户的听觉能力的装置如助听器例如听力仪器或有源耳朵保护装置或其它音频处理装置,其通过从用户环境接收声信号、产生对应的音频信号、可能修改该音频信号、及将可能已修改的音频信号作为可听见的信号提供给用户的至少一只耳朵而实现。“听力装置”还指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为听得见的信号提供给用户的至少一只耳朵的装置如头戴式耳机或耳麦。听得见的信号例如可以下述形式提供:辐射到用户外耳内的声信号、作为机械振动通过用户头部的骨结构和/或通过中耳的部分传到用户内耳的声信号、及直接或间接传到用户耳蜗神经的电信号。
听力装置可构造成以任何已知的方式进行佩戴,如作为佩戴在耳后的单元(具有将辐射的声信号导入耳道内的管或者具有安排成靠近耳道或位于耳道中的输出变换器如扬声器)、作为整个或部分安排在耳廓和/或耳道中的单元、作为连到植入在颅骨内的固定结构的单元如振动器、或作为可连接的或者整个或部分植入的单元等。听力装置可包括单一单元或几个彼此电子通信的单元。扬声器可连同听力装置的其它元件一起设置在壳体中,或者本身可以是外部单元(可能与柔性引导元件如圆顶件组合)。
更一般地,听力装置包括用于从用户环境接收声信号并提供对应的输入音频信号的输入变换器和/或以电子方式(即有线或无线)接收输入音频信号的接收器、用于处理输入音频信号的(通常可配置的)信号处理电路(如信号处理器,例如包括可配置(可编程)的处理器,例如数字信号处理器)、及用于根据处理后的音频信号将听得见的信号提供给用户的输出单元。信号处理器可适于在时域或者在多个频带处理输入信号。在一些听力装置中,放大器和/或压缩器可构成信号处理电路。信号处理电路通常包括一个或多个(集成或单独的)存储元件,用于执行程序和/或用于保存在处理中使用(或可能使用)的参数和/或用于保存适合听力装置功能的信息和/或用于保存例如结合到用户的接口和/或到编程装置的接口使用的信息(如处理后的信息,例如由信号处理电路提供)。在一些听力装置中,输出单元可包括输出变换器,例如用于提供空传声信号的扬声器或用于提供结构或液体传播的声信号的振动器。在一些听力装置中,输出单元可包括一个或多个用于提供电信号的输出电极(例如用于电刺激耳蜗神经的多电极阵列)。在实施例中,听力装置包括喇叭扩音器(包括多个输入变换器和多个输出变换器,例如用在音频会议情形中)。
在一些听力装置中,振动器可适于经皮或由皮将结构传播的声信号传给颅骨。在一些听力装置中,振动器可植入在中耳和/或内耳中。在一些听力装置中,振动器可适于将结构传播的声信号提供给中耳骨和/或耳蜗。在一些听力装置中,振动器可适于例如通过卵圆窗将液体传播的声信号提供到耳蜗液体。在一些听力装置中,输出电极可植入在耳蜗中或植入在颅骨内侧上,并可适于将电信号提供给耳蜗的毛细胞、一个或多个听觉神经、听觉脑干、听觉中脑、听觉皮层和/或大脑皮层的其它部分。
听力装置如助听器可适应特定用户的需要如听力受损。听力装置的可配置的信号处理电路可适于施加输入信号的随频率和电平而变的压缩放大。定制的随频率和电平而变的增益(放大或压缩)可在验配过程中通过验配系统基于用户的听力数据如听力图使用验配基本原理(例如适应语音)确定。随频率和电平而变的增益例如可体现在处理参数中,例如经到编程装置(验配系统)的接口上传到听力装置,并由听力装置的可配置的信号处理电路执行的处理算法使用。
“听力系统”指包括一个或两个听力装置的系统。“双耳听力系统”指包括两个听力装置并适于协同地向用户的两只耳朵提供听得见的信号的系统。听力系统或双耳听力系统还可包括一个或多个“辅助装置”,其与听力装置通信并影响和/或受益于听力装置的功能。辅助装置例如可以是遥控器、音频网关设备、移动电话(如智能电话)、或音乐播放器。听力装置、听力系统或双耳听力系统例如可用于补偿听力受损人员的听觉能力损失、增强或保护正常听力人员的听觉能力和/或将电子音频信号传给人。听力装置或听力系统例如可形成广播系统、耳朵保护系统、免提电话系统、汽车音频系统、娱乐(如卡拉ok)系统、远程会议系统、教室放大系统等的一部分或者与它们交互。
本发明的实施例如可用在如便携音频处理装置例如助听器的应用中。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
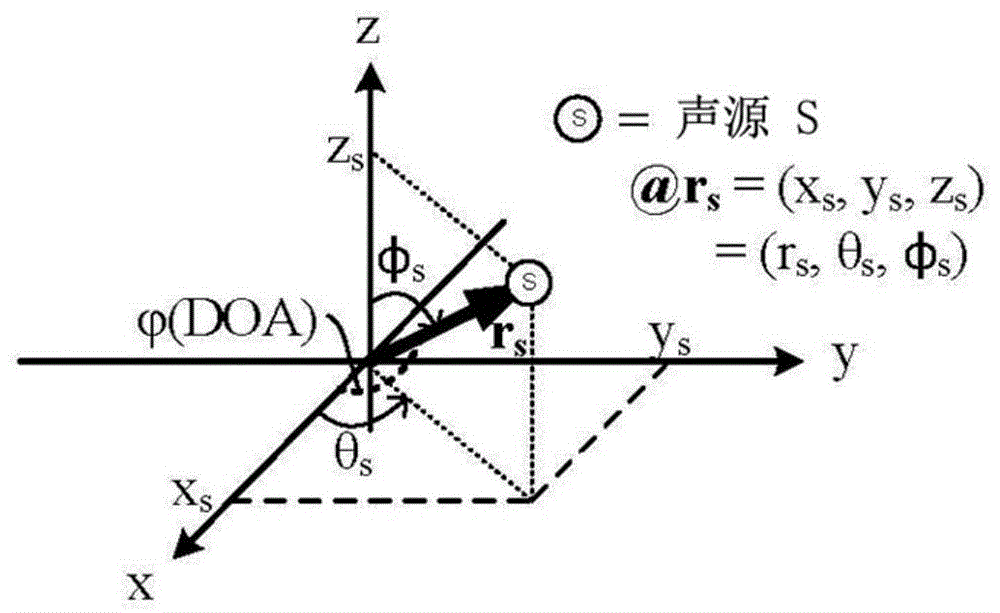
图1a示出了声源位于三维坐标系中,其确定声源的笛卡尔坐标(x,y,z)和球坐标
图1b示出了声源相对于包括两个传声器的传声器阵列位于三维坐标系中,其中两个传声器在该坐标系的起点附近对称地位于x轴上(这些传声器例如位于左和右听力装置中的每一个中)。
图1c为3d到达方向的几何学例子的进一步图示,其中粗线为到声源se(用实心圆点图示)的方向,与y轴一致的线上的菱形表示传感器节点(例如传声器定位)pi,i=1,…,m,θ为方位角,
图2示出了所述阵列(p1,p2,…,pm)相对于e参照系的定向r和位置te。
图3示出了根据本发明的听力系统的第一实施例。
图4示出了根据本发明的听力装置的实施例。
图5示出了与辅助装置通信的、根据本发明的听力系统的第二实施例。
图6示出了根据本发明的听力系统的第三实施例。
图7示出了根据本发明的听力系统的第四实施例。
图8示出了根据本发明的听力系统的第五实施例。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域技术人员来说,基于下面的详细描述,本发明的其它实施方式将显而易见。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
电子硬件可包括微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、选通逻辑、分立硬件电路、及配置成执行本说明书中描述的多个不同功能的其它适当硬件。计算机程序应广义地解释为指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、可执行、执行线程、程序、函数等,无论是称为软件、固件、中间件、微码、硬件描述语言还是其他名称。
在本发明中,考虑具有两个以上从声源接收信号的传感器的线性阵列。当传感器被等距地间隔开时,获得所谓的均匀线性阵列(ula),其给出波场的均匀空间采样。该采样使非参数窄带doa方法容易,如多信号分类(music)和最小方差无失真响应(mvdr),因为它们寻求具有最强功率的检测。
为克服线性阵列的限制,已提出几种方法来估计3d声源方向或者其全位置。胸部佩戴的平面传声器阵列可用于估计该方向,同时头部相关传递函数(hrtf)用于估计所述位置。
所提出的方法利用遭受运动时所述阵列的几何性质。孔是所述阵列占用的空间,及在此利用的简单想法是所述阵列的运动合成一个更大的空间。提出利用已知运动的非线性最小平方(nonlinearleast-squares,nls)公式表示,及提出了两个相继的解决方案。所述公式表示被扩展到包括运动中的不确定性,从而使能同时估计声源定位和运动。
图1a示出了声源s位于三维坐标系中,其确定声源s的笛卡尔坐标(x,y,z)和球坐标
图1b示出了声源s相对于包括两个传声器(mic1,mic2)的传声器阵列位于三维坐标系(x,y,z)中,其中两个传声器在该坐标系的起点(0,0,0)附近对称地位于x轴上并间隔开距离d=2a(即分别以(a,0,0)和(-a,0,0)为中心)。声源向量rs与传声器阵列向量mav(称为doa阵列向量)之间的角度在图1b中由粗虚线弧
图1b中所示的设置为具有两个从声源s接收信号的传感器(在此为传声器)的线性阵列。为了简化,进行自由场假设,这导致未被阻挡的波入射在所述阵列上。还假定波前为平面的波前。当声源不垂直于所述阵列时,传感器与声源之间的距离将不同,导致所接收的信号中的时间差。使用介质(在此例如为空气)的已知速度,该时间差可被转换为距离,及使用传感器之间已知的分隔,可计算相对于声源的角度。
图1c为3d到达方向的几何学例子的进一步图示,其中粗线为到声源se(用实心圆点图示)的方向,与y轴一致的线上的菱形表示传感器节点(例如传声器定位)pi,i=1,…,m,θ为方位角,
为了简化,进行自由场假设,这导致未被阻挡的波入射在所述阵列上。还假定波前为平面的波前。当声源不垂直于所述阵列时,传感器与声源之间的距离将不同,导致所接收的信号中的时间差。使用介质的已知速度,该时间差可被转换为距离,及使用传感器之间已知的分隔,可计算相对于声源的角度。
当传感器不必要等距地间隔时,如图1c中所示,线性传感器阵列上的doa可通过下式描述:
其中
常见设置是考虑所述阵列及doa源均位于同一平面中(例如图1b中的xy平面)。然而,更一般的情形是将所述阵列考虑为
声源方向则具有两个自由度(dof),即方位角θ和极角(或仰角)
确定包含传感器节点位于其处的阵列的、身体固定的坐标系(b),
sb=r(se-te)(2)
阵列向量和声源位置的这种刚体变换在图2中示出。
图2示出了传感器阵列(p1,p2,…,pm)相对于e参照系的定向r和位置te。身体固定的阵列向量与yb向量对准。声源位置se用实心圆点图示。
设m个节点之间的逐对差由
其中hij为每一传声器对pi和pj之间的时间差τij的模型。因而,每一节点对之间的时间差可被表达为声源位置、阵列长度、其位置和定向的非线性函数。此外,使用se=[x,y,z],方位角和仰角可分别定义为
及
由于距离未观察到,未知变量se仅具有两个dof,因此假设║se║=1是方便的。在该情形下,doa测量结果及测量函数对应于非线性等式的系统。
仅转动:如果没有平移,即
如早前论述的,一般doa问题具有几何模糊性,对于某些配置导致转动不变性。该不变性意味着doa保持一样,因为距声源的相对距离未因转动而改变。
绕doa阵列自身的转动对应于节距变化。这是因为,对于绕其自己的轴的旋转/转动,任何向量均旋转地不变,即xb=r(xb)xb,其中r(xb)指绕向量xb的旋转。因而,对于绕doa阵列的旋转,相对于声源的两个角度不能被求解。
转动和平移:当有所述阵列的平移时,se的所有三个dof均可基于三角测量法考虑。假设xb经历已知的旋转和平移
估计
假设阵列向量xb的所有旋转和平移(姿态轨迹)
在此,
通过堆叠n个剩余向量(对于t=1,…,n),我们获得
r(se)=[r1(se)t,…,rn(se)t]t
(5)
其中
其为非线性最小平方(nls)公式表示。nls问题容易解决,例如使用levenberg-marquardt(lm)方法,例如参见[levenberg;1944],[marquardt;1963]。lm仅使用梯度信息进行拟牛顿搜索。(6)的梯度为
其中h为雅可比(jacobian),即一阶偏导数dr(se)的矩阵
还优选对于nls问题使用加权策略,其通过考虑测量噪声可能随时间变化和/或不同。(6)中对应的残差之后通过测量协方差的逆
其中r=diag(r1,…,rb)。当测量误差为高斯误差时,
如果节点的空间分布产生明显的估计问题,则所述阵列被认为模糊。结果是对该模糊阵列有两个运动,se不能被估计。第一个是仅旋转(ro),对此,只要旋转不是绕阵列轴,可仅得到声源方向。第二个是阵列的旋转和平移(rt)。从这样的一般运动,只要平移不平行于se-te,声源定位通过nls解决方案进行隐含地三角测量。
目标跟踪和slam:由于针对固定不动的声源和阵列的已知运动确定的nls问题,确定更富挑战性的情形很简单。如果声源被使能移动,则参数se在等式(6)中变为时变参数
其中
q为适当维数的对角线协方差矩阵。在实施例中,q大。
当在声源位置及阵列运动方面均有不确定性时,获得同时定位和建图(slam)问题。slam的最大似然(ml)版不考虑任何运动模型,因而获得下面的nls问题
有k个固定不动的声源
序贯解决方案:在许多应用中,希望以在线方式处理数据。nls从结构上讲为离线解决方案,但从其可容易地推导序贯递归方法。众所周知的算法为扩展卡尔曼滤波(ekf[jazwinski;1970]),其可被看作没有迭代的nls的特殊情形。这自然导致迭代的解决方案,其通常导致性能增加。为计算ro情形的搜索方向,每次更新时需要至少两个快照。类似地,在rt情形需要至少三个快照。
序贯非线性最小二乘方:简单的序贯nls(s-nls)解决方案可按如下进行。给定未知参数x的初始猜测(x)0,则对于适当数量的快照迭代
xi+1=xi+αi(hth)-1hr(10)
直到收敛为止。在此h和r通过当前的迭代xi参数化,及αi∈[0,1]为步长,其可用例如回溯法进行计算。在ro情形下(x=se),x仅可按比例进行估计,因此估计量在每次迭代时应被归一化为
迭代扩展卡尔曼滤波:状态空间模型是重要的工具,因为它们承认通过处理模型对本来固定的参数进行动态假设有效。通常,状态被假定根据一些处理模型演变
xt+1=f(xt,wt)(12)
其中wt为处理噪声。迭代扩展卡尔曼滤波(iekf)可被看作状态空间模型的nls解决者。iekf通常获得更小的残余误差并在非线性严重及计算资源可用时优于标准ekf。迭代在测量更新中进行,其中最小后验(map)价值函数被相对于未知状态最小化。价值函数可用于确保在迭代应终止时价值降低。iekf中的测量更新的基本版在算法1中概述。对于完整描述和其它选择
算法1迭代扩展卡尔曼测量更新:
需要初始状态
1、测量更新迭代
2、更新状态和协方差
例子:固定不动的目标
对于在se=[10,10,10]t+w初始化的固定不动的目标,其中
表1:对于仅旋转的情形和旋转及平移的情形,用所提出的方法获得的估计量的rmse。
例子(固定的传声器距离):
假定自由场和平面波前,入射在阵列上的声波的到达方向(doa)可通过下式描述
其中
其中y为例如经延迟及求和或者波束形成得到的doa测量结果。之后,对于两种场合可求解双范数剩余向量r(se):
1、给定来自截然不同的定向的两个以上doa测量结果,所述定向不是绕阵列轴xb的旋转,则对应的等式系统可关于se进行求解。在该场合,仅能得到相对于声源的方向
2、给定在截然不同的位置的三个以上doa测量结果,及平移不是沿doa向量的平移,则对应的等式系统可关于se进行求解。在该场合,系统的全部三个自由度均可被得到。该方法要求阵列的位置可被计算。这可在短时间间隔内使用imu进行。
最小化程序可以是任何非线性最小二乘方(nls)方法,如levenberg-marquardt或者具有线搜索的标准nls。
图3示出了根据本发明的听力系统的第一实施例。听力系统hd适于由用户佩戴并配置成在听力系统安装到用户头上工作时捕获用户环境中的声音。听力系统包括m=2个输入变换器(在此为传声器m1,m2)的传感器阵列。每一传声器提供表示环境中的声音的电输入信号。传感器阵列的输入变换器在由用户佩戴时相对于彼此具有已知的几何配置(在此通过m1与m2之间的传声器距离d确定)。每一传声器通路包括用于采样模拟电信号的模数转换器(ad),从而将模拟电信号转换为数字电输入信号(例如使用20khz或更大的采样频率)。每一传声器通路还包括分析滤波器组fba,用于在多个子频带(例如k=64或更大)提供数字化的电输入信号。每一子频带信号(例如通过指数x表示)可包括输入信号在相继的时刻m,m+1,…(时间帧)的时变复数表示。
听力系统还包括检测器单元det(或者配置成从单独的传感器接收对应的信号),用于在听力系统由用户佩戴时检测听力系统随时间的运动并提供所述传感器阵列在不同时间点t,t=1,…,n的定位数据。检测器det提供标示用户(听力系统)相对于声源的轨迹的数据(参见信号trac,例如来自q个不同的传感器或者包括q个不同的信号)。
听力系统还包括第一处理器pro1,用于接收所述电输入信号,及在所述声音包括来自被定位的声源s的声音的情形下,用于提取所述传感器阵列的传感器阵列配置特有数据τij(参见信号tau),该数据标示来自所述被定位的声源s的声音在不同时间点t,t=1,…,n到达相应输入变换器(m1,m2)的到达时间之间的差。
图3示出了在时间t=1的情形自被定位的声源s如讲话者的传播通路(在平面波逼近(声学远场)下)。可以看出,来自声源s的声音到达第二传声器m2的时间晚于到达第一传声器m1的时间。记为τ12的时间差在第一处理器中基于两个电输入信号确定(例如将时间差τ12确定为使两个电输入信号之间的相关测量最大化的时间)。用户和声源s相对于彼此的运动由声源s分别在时刻t=2和t=3的空间移位示意性标示。
听力系统还包括第二处理器pro2,配置成基于在所述不同时间点t,t=1,…,n所述定位数据和所述传感器阵列配置数据的对应值估计标示所述被定位的声源s相对于用户的定位的数据。标示所述被定位的声源s相对于用户的定位的数据例如可以是到达方向(参见从处理器pro2到波束形成器滤波单元bf的信号doa)。
图3中实施例的听力系统还包括(如已经提及的)波束形成器滤波单元bf,用于对来自传声器m1和m2的电输入信号进行空间滤波并提供波束成形信号。波束形成器滤波单元bf是来自第二处理器pro2的定位数据的“客户”以使能产生对来自声源s的信号衰减比来自其它方向的信号少的波束形成器(例如mvdr波束形成器,例如参见ep2701145a1)。在图3的实施例中,波束形成器滤波单元bf接收标示(目标)声音相对于用户(因而相对于传感器阵列m1,m2)的到达方向的数据,如图3中所示(从s到m1与m2之间的中间的记为doa的实线箭头)。作为备选,波束形成器滤波单元bf可接收目标声源的定位,例如包括从声源到用户的距离。
图3中实施例的听力系统还包括信号处理器spu,用于在多个子频带处理来自波束形成器滤波单元的空间滤波的(及可能进一步降噪的)信号。信号处理器spu例如配置成应用另外的处理算法,例如压缩放大(以将随频率和电平而变的放大或衰减应用于波束成形信号)、反馈抑制等。信号处理器spu提供处理后的信号,其被馈给合成滤波器组fbs以从时频域转换到时域。合成滤波器组fbs的输出馈给输出单元(在此为扬声器),用于向用户提供表示声音的刺激(基于表示环境中的声音的电输入信号)。
图3中实施例的听力系统可以不同的方式进行划分。在实施例中,听力系统包括适于位于用户的左和右耳附近(例如使得第一和第二传声器(m1,m2)分别位于用户的左和右耳处)的第一和第二听力装置。
图4示出了根据本发明的听力装置的实施例。图4示出了包括听力装置hd的听力系统的实施例,听力装置包括适于位于耳廓后面的bte部分(bte)和适于位于用户耳道中的部分(ite)。如图4中所示,ite部分可包括输出变换器(如扬声器/接收器),其适于位于用户耳道中并提供声学信号(在耳膜处提供或贡献于声学信号)。在后一情形下,提供所谓的耳内接收器式(rite)助听器。bte部分和ite部分通过连接元件ic连接(如电连接),连接元件例如包括多个电导体。连接元件ic的电导体例如可具有将电信号从bte部分传到ite部分的目的,例如包括音频信号到输出变换器,和/或用作用于提供无线接口的天线。bte部分包括包含两个输入变换器(it11,it12)(如传声器)的输入单元,每一输入变换器用于提供表示来自环境的输入声音信号的电输入音频信号。在图4的情境中,输入声音信号sbte包括来自声源s(可能及来自环境的附加噪声)的贡献。图4的助听器hd还包括两个无线收发器(wlr1,wlr2),用于传输和/或接收相应的音频和/或信息信号和/或控制信号(可能包括来自外部检测器的定位数据,和/或来自对侧听力装置或辅助装置的一个或多个音频信号)。助听器hd还包括衬底sub,其上安装多个电子元件并根据所涉及应用进行功能划分(模拟、数字、无源元件等),包括经电导体wx彼此连接并连接到输入和输出变换器及无线收发器的可配置的信号处理器spu,例如包括用于执行多个处理算法例如以补偿听力装置佩戴者的听力损失的处理器、根据本发明的用于提取定位数据的处理器pro(例如参见图3的pro1,pro2)、及检测器单元det。通常,用于与输入和输出变换器等接口连接的前端ic也被包括在衬底上。所提及的功能单元(及其它元件)可根据所涉及的应用按电路和元件进行划分(例如为了大小、功耗、模拟-数字处理等),例如集成在一个或多个集成电路中,或者作为一个或多个集成电路与一个或多个单独的电子元件(如电感器、电容器等)的组合。可配置的信号处理器spu提供处理后的音频信号,其计划呈现给用户。在图4实施例的听力装置中,ite部分包括输入变换器(如传声器)it2,用于在耳道处或耳道中提供表示来自环境(包括来自声源)的输入声音信号的电输入音频信号。在另一实施例中,助听器可仅包括bte传声器(it11,it12)。在另一实施例中,助听器可仅包括ite传声器(it2)。在又一实施例中,助听器可包括位于除耳道处之外的别处的输入单元与位于bte部分和/或ite部分中的一个或多个输入单元的组合。ite部分还可包括引导元件如圆顶件do或等效元件,用于在用户的耳道中引导和定位ite部分。
图4中例示的助听器hd为便携设备及进一步包括电池如可再充电电池bat,用于对bte部分及可能ite部分的电子元件供电。
在实施例中,图4的听力装置hd形成根据本发明的用于定位用户环境中的目标声源的听力系统的一部分。
助听器hd例如可包括定向传声器系统(包括波束形成器滤波单元),适于在佩戴助听器的用户的局部环境中的多个声源之中空间上滤出目标声源并抑制来自该环境中的其它声源的“噪声”。波束形成器滤波单元可将来自输入变换器it11,it12,it2(可能及另外的输入变换器)(或其任何组合)的相应电信号接收为输入并基于其产生波束成形信号。在实施例中,该定向系统适于检测(如自适应检测)传声器信号的特定部分(如目标部分和/或噪声部分)源自哪一方向。在实施例中,波束形成器滤波单元适于从用户接口(如遥控器或智能电话)接收关于目前的目标方向的输入。存储器单元mem例如可包括预定(或自适应确定)的复数、随频率而变的常数wij,其连同确定波束成形信号ybf一起确定预定的(或自适应确定的)或者“固定的”波束图(例如全向、目标消除、指向相对于用户的多个具体方向)。
图4的助听器可构成或形成根据本发明的助听器和/或双耳助听器系统的一部分。助听器的正向通路(该正向通路包括输入变换器、信号处理器和输出变换器)中的音频信号的处理例如可完全或部分在时频域进行。类似地,助听器的分析或控制通路中的信号的处理可完全或部分在时频域中进行。
根据本发明的助听器hd可包括用户接口ui,例如如图5中所示,实施在辅助装置ad如遥控器中,例如实施为智能电话或其它便携(或固定不动的)电子设备中的app。
图5示出了根据本发明第二实施例的听力系统与辅助装置通信。图5示出了根据本发明的包括彼此通信的左和右听力装置hdleft,hdright及辅助装置ad的双耳听力系统的实施例。左和右听力装置适于位于用户的左和右耳处或左和右耳中和/或适于完全或部分植入在左和右耳处的头部中。左和右听力装置及辅助装置(例如单独的处理或中继设备,如智能电话等)配置成使能在其间交换数据(参见图5中的链路ia-wl(分别为定位数据locleft,locright)及ad-wl(控制信息信号x-cntleft/right)),不可靠交换定位数据、音频数据、控制数据、信息等。双耳听力系统包括完全或部分实施在辅助装置ad中的用户接口ui,例如实施为app,参见图5中的辅助装置ad的“声源定位app”屏幕。该app使能显示声源s相对于用户(佩戴听力系统)的当前定位,并使能控制听力系统的功能,例如启用或禁用根据本发明的声源定位。
左和右听力装置中的每一个包括m个输入单元iui,i=1,…,m(每一输入单元包括例如输入变换器,如传声器或传声器系统和/或直接电输入(如无线接收器))与输出单元sp例如输出变换器(在此为扬声器)之间的正向通路。波束形成器或选择器bf及信号处理器spu位于该正向通路中。在实施例中,信号处理器适于根据用户的特定需要提供随频率而变的增益。在图5的实施例中,正向通路包括适当的模数转换器和分析滤波器组ad/fba以在子频带(在(时-)频域)提供输入信号in1,…,inm(及使能进行信号处理)。在另一实施例中,正向通路的部分或所有信号处理在时域进行。加权单元(波束形成器或混合器或选择器)bfu基于一个或多个输入信号in1,…,inm提供波束成形或混合或选择的信号ybf。加权单元bf的功能经信号处理器spu进行控制,参见信号ctr,例如通过用户接口影响(信号x-cnt)和/或分别表示相对于环境中当前活跃的声源(如根据本发明确定的)定位信号doa和rs。正向通路还包括合成滤波器组和适当的数模转换器fbs/da以将来自信号处理器spu的处理后的子频带信号out准备为模拟时域信号进而经输出变换器(扬声器)sp呈现给用户。相应的可配置的信号处理器spu经信号ctr和loc与用于确定定位数据(doa和rs)的相应处理器pro通信。从单元spu到单元pro的控制信号ctr例如可使信号处理器spu能控制听力系统的运行模式(例如经用户接口),例如启用或禁用声源定位(或者影响它)。数据信号loc可在两个处理单元之间交换,例如以使来自对侧听力装置的定位数据能影响应用于波束形成器滤波单元bf的合成定位数据,例如经链路ia-wl(locleft,locright)交换。用于在左和右听力装置之间传送音频和/或控制信号的耳间无线链路ia-wl例如可基于近场通信,例如磁感应技术(如nfc或专用方案)。
图6示出了根据本发明的听力系统hs的第三实施例。图6示出了根据本发明实施例的听力系统包括左和右听力装置及安装在眼镜架上的多个传感器。该听力系统hs包括分别与左和右听力装置hd1,hd2相关联(例如形成其一部分或者与其连接)的多个传感器s1i,s2i(i=1,…,ns)。第一、第二和第三传感器s11,s12,s13和s21,s22,s23安装在眼镜gl的镜架上。在图6的实施例中,传感器s11,s12和s21,s22安装在相应的侧杆(sb1和sb2)上,而传感器s13和s23安装在与右和左侧杆(sb1和sb2)具有铰接连接的横杆cb上。镜片或透镜le安装在横杆cb上。左和右听力装置hd1,hd2包括相应的bte部分bte1,bte2,及例如还可包括相应的ite部分ite1,ite2。ite部分例如可包括用于从用户拾取身体信号的电极,例如形成用于监视用户的生理功能如大脑活动或眼球运动活动或温度的传感器s1i,s2i(i=1,…,ns)的一部分。安装在眼镜架上的传感器(检测器,参见图3中的检测器单元det)例如可包括加速计、陀螺仪、磁力计、雷达传感器、眼球照相机(例如用于监视瞳孔)等中的一个或多个,或者用于定位或贡献于佩戴听力系统的用户感兴趣的声源的定位的其它传感器。
图7示出了根据本发明的听力系统的实施例。该听力系统包括听力装置hd如助听器,在此示为特定类型(有时称为耳内接收器式或rite型),其包括适于位于用户耳朵处或耳后的bte部分(bte)和适于位于用户耳道中或耳道处的ite部分(ite)及包括接收器(扬声器)spk。bte部分和ite部分通过连接元件ic和ite部分及bte部分中的内部接线(例如参见bte部分中的接线wx)进行连接(例如电连接)。作为备选,连接元件可完全或部分由bte部分与ite部分之间的无线链路构成。
在图7实施例的听力装置中,bte部分包括三个包含相应的输入变换器(如传声器)的输入单元(mbte1,mbte2,mbte3),每一输入单元用于提供表示输入声音信号(sbte)(源自听力装置周围的声场s)的电输入音频信号。输入单元还包括两个无线接收器(wlr1,wlr2)(或收发器),用于提供相应的直接接收的辅助音频和/或控制输入信号(和/或使能将音频和/或控制信号传给其它设备如遥控器或处理装置)。输入单元还包括位于bte部分的壳体中的摄像机vc,例如使得其视场(fov)被朝向佩戴听力装置的用户的视向(在此与到连接元件ic的电接口相邻)。摄像机vc例如可连接到处理器并设置成构成用于slam的场景照相机。听力装置hd包括衬底sub,其上安装多个电子元件,包括存储器mem,例如存储不同的助听器程序(例如确定前述程序的参数设置,或者(例如用于实施slam的)算法的参数,例如神经网络的优化参数)和/或助听器配置,例如输入源组合(mbte1,mbte2,mbte3,mite1,mite2,wlr1,wlr2,vc),例如针对多个不同的听音情形优化。衬底还包括可配置的信号处理器(dsp,例如数字信号处理器,例如包括用于施加随频率和电平而变的增益的处理器,例如提供波束形成、降噪(包括使用照相机实现的改善)、滤波器组功能,及根据本发明的听力装置的其它数字功能)。可配置的信号处理器dsp适于访问存储器mem及适于基于当前选择(启用)的助听器程序/参数设置(例如或自动选择,例如基于一个或多个传感器;或基于来自用户接口的输入选择)而选择和处理一个或多个电输入音频信号和/或一个或多个直接接收的辅助音频输入信号和/或照相机信号。所提及的功能单元(及其它元件)可根据所涉及的应用按电路和元件进行划分(例如为了大小、功耗、模拟-数字处理等),例如集成在一个或多个集成电路中,或者作为一个或多个集成电路与一个或多个单独的电子元件(如电感器、电容器等)的组合。可配置的信号处理器dsp提供处理后的音频信号,其计划呈现给用户。衬底还包括前端ic(fe),用于使可配置的信号处理器dsp与输入和输出变换器等接口连接且通常包括模拟信号与数字信号之间的接口。输入和输出变换器可以是个别的、分开的元件,或者与其它电子电路集成(如基于mems)。
该听力系统(在此为听力装置hd)还包括包含一个或多个惯性测量单元imu的检测器单元,例如3d陀螺仪、3d加速计和/或3d磁力计,在此记为imu1并位于bte部分中。惯性测量单元imu例如加速计、陀螺仪、磁力计及其组合可以多种形式(如多轴,例如3d版)获得,例如由集成电路构成或者形成集成电路的一部分,因而适合集成,甚至集成在微型设备如听力装置例如助听器中。传感器imu1因而可连同其它电子元件(如mem、fe、dsp)一起位于衬底sub上。作为备选或另外,一个或多个运动传感器imu可位于ite部分之中或之上或者连接元件ic之中或之上。
该听力装置hd还包括输出单元(如输出变换器),其基于来自处理器的处理后的音频信号或者源自该音频信号的信号提供可由用户感知为声音的刺激。在图7实施例的听力装置中,ite部分包括扬声器(也称为“接收器”)spk形式的输出单元,用于将电信号转换为声学(空传)信号,其(在听力装置安装在用户耳朵处时)被导向耳膜从而在那里提供声音信号sed。ite部分还包括引导元件如圆顶件do,用于在用户的耳道中引导和定位ite部分。ite部分(例如壳体或者软或刚性或半刚性圆顶状结构)包括多个电极或电位传感器(eps)el1,el2,用于在安装在耳道中时拾取来自用户身体的信号(例如电位或电流)。通过电极或eps拾取的信号例如可用于估计用户的眼睛凝视角度(使用eog)。ite部分还包括两个另外的输入变换器如传声器mite1,mite2,用于提供表示耳道处的声场site的相应电输入音频信号。
源自来自摄像机vc的视觉信息的辅助电信号可用在其与来自一个或多个输入变换器(如传声器)的电声音信号结合以相对于用户定位声源的运行模式中。在另一运行模式中,波束成形信号通过适当组合来自输入变换器(mbte1,mbte2,mbte3,mite1,mite2)的电输入信号而提供,例如通过将适当的复数权重应用于相应的电输入信号(波束形成器)。在一运行模式下,辅助电信号用作处理算法(如单通道降噪算法)的输入以增强正向通路的信号如波束成形(空间滤波的)信号。
电输入信号(来自输入变换器mbte1,mbte2,mbte3,mite1,mite2)可在时域或者在(时-)频域进行处理(如对所涉及应用有利,或者部分在时域及部分在频域进行处理)。
图7中例示的听力装置hd为便携装置,其还包括用于对bte部分可能及ite部分的电子元件供电的电池bat如可再充电电池,例如基于锂离子电池技术。在实施例中,听力装置如助听器适于提供随频率而变的增益和/或随电平而变的压缩和/或一个或多个频率范围到一个或多个其它频率范围的移频(具有或没有频率压缩),例如以补偿用户的听力受损。
图7中的听力装置因而可实施包括eog(基于eog传感器(el1,el2),例如电极)和场景照相机vc的组合的听力系统,eog用于眼球跟踪,场景照相机用于与用于运动跟踪/头部转动的运动传感器imu1结合进行slam。
图8示出了根据本发明的听力系统的另一实施例。该听力系统包括包含多个输入变换器在此为12个传声器的眼镜架,左和右侧杆中的每一个上各3个及在横杆上6个。从而可监视用户感兴趣的(大部分)声音场景的声学图像。此外,听力系统包括多个运动传感器imu,在此为两个,左和右侧杆上各一个,用于采集用户的运动包括用户头部的转动。听力系统还包括多个照相机,在此为三个。所有三个照相机均位于横杆上。照相机中的两个(在图8中记为“眼球跟踪照相机”)定位和定向成朝向用户面部以使能监视用户的眼睛,例如提供用户当前的眼睛凝视的估计量。第三照相机(在图8中记为“向前的照相机”)位于横杆的中间并定向成使其能监视用户前面如用户视向的环境。
图8中的听力系统因而可实施包括载体(在此为眼镜架的形式)的听力系统,其配置成承载听力系统的至少部分输入变换器(在此为12个传声器)、多个照相机(场景照相机,例如用于同时定位和建图(slam),及用于眼睛凝视的两个眼球跟踪照相机)。听力系统例如还可包括适于位于用户耳朵处(例如安装在载体(眼镜架)上或连接到载体)的一个或两个听力装置,其在工作时连接到(12个)传声器和(3个)照相机。听力系统因而可配置成定位用户环境中的声源并使用该定位改善听力装置的处理,例如补偿用户的听力受损和/或在困难声音环境中帮助用户。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的及权利要求中限定的装置的结构特征可与本发明方法的步骤结合。
除非明确指出,在此所用的单数形式“一”、“该”的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非另行指明,在此公开的任何方法的步骤不精确限于相应说明的顺序。
应意识到,本说明书中提及“一实施例”或“实施例”或“方面”或者“可”包括的特征意为结合该实施例描述的特定特征、结构或特性包括在本发明的至少一实施方式中。此外,特定特征、结构或特性可在本发明的一个或多个实施方式中适当组合。提供前面的描述是为了使本领域技术人员能够实施在此描述的各个方面。各种修改对本领域技术人员将显而易见,及在此定义的一般原理可应用于其他方面。
权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。
因而,本发明的范围应依据权利要求进行判断。
参考文献
[jazwinski;1970]andrewh.jazwinski,stochasticprocessesandfilteringtheory,vol.64ofmathematicsinscienceandengineering,academicpress,inc,1970.
[knapp&carter;1976]c.knappandg.carter,“thegeneralizedcorrelationmethodforestimationoftimedelay,”ieeetransactionsonacoustics,speech,andsignalprocessing,vol.24,no.4,pp.320–327,aug1976.
[levenberg;1944]kennethlevenberg,“amethodforthesolutionofcertainnon-linearproblemsinleastsquares,”quarterlyjournalofappliedmathmatics,vol.ii,no.2,pp.164–168,1944.
[marquardt;1963]donaldw.marquardt,“analgorithmforleast-squaresestimationofnonlinearparameters,”siamjournalonappliedmathematics,vol.11,no.2,pp.431–441,1963.
ep2701145a1(oticon,retune)26.02.2014.
ep3267697a1(oticon)10.01.2018.
- 还没有人留言评论。精彩留言会获得点赞!