基于亮灯效应的定长消息格式逆向方法与流程
本发明涉及网络安全
技术领域:
,尤其涉及基于亮灯效应的定长消息格式逆向方法。
背景技术:
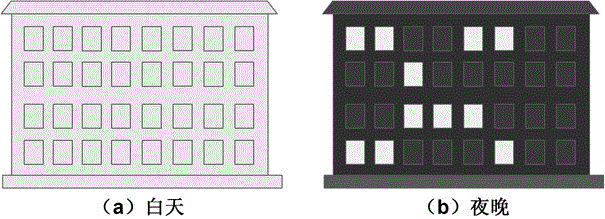
:定长消息格式是一种常见的应用协议消息格式,很多应用协议中包含定长消息或定长段。由于定长格式的信息压缩性高,难以对其进行特征提取及特征分析,因此也难以对其进行格式逆向。2004年,pi(protocolinformatics)项目利用了生物信息学中基因序列比对的思想来对消息进行格式逆向。该方法适用于存在丰富特征字段的消息,例如传统协议分类中的文本消息。而定长消息的信息压缩性较高,特征字段不明显,因此pi对定长消息的逆向效果有限。2006年,微软的cui等提出了消息格式逆向的discoverer算法。该算法在对定长消息进行格式逆向时,简单地把消息中的每一个字节当做一个单独的域,具有一定的片面性。asap和prodecoder利用自然语言主题提取里的n-gram方法对定长消息进行格式逆向。然而基于n-gram的方法只对长度不小于n且特征字段明显的消息有效,对定长消息的逆向结果不理想。prograph利用图论和信息论的相关方法进行协议逆向,该方法对消息的分析粒度过小,且其前提是假设消息中的不同域的取值存在普遍关联,具有一定的片面性。总之,由于定长消息的信息压缩性高,特征字段不明显。因此,以上基于特征字段分析的定长消息格式逆向技术效果有限。此外,一些研究人员考虑通过二进制分析的方法对定长消息进行格式逆向,其思想可以简要概括为:通过二进制分析技术观察应用程序对消息的处理过程,从而确定消息中每个域的大小、位置、语义等信息。基于二进制分析的协议逆向技术准确性高,得到结果比较丰富。然而基于二进制分析的协议逆向技术需要获取协议的应用程序,而应用程序的获取比较困难,且存在软件保护问题。同时,基于二进制分析的协议逆向技术很难做到自动化。技术实现要素:针对现有的定长消息格式逆向技术中的不足,本发明提供一种基于亮灯效应的定长消息逆向方法。通过在建筑物与定长消息之间建立映射关系,将推测定长消息中每个域的边界问题转化为概率统计问题,提高了定长消息格式逆向的正确率。本发明提供一种基于亮灯效应的定长消息格式逆向方法,该方法包括:步骤1、判断定长消息m中所有定长域的域类型,所述域类型包括同步域和异步域;步骤2、若所述定长消息m中所有定长域均为同步域,则按照第一域边界识别规则确定定长消息各定长域的域边界序列;步骤3、若所述定长消息m中的定长域包括异步域,则按照第二域边界识别规则确定定长消息各定长域的域边界序列。进一步地,所述第一域边界识别规则具体包括:步骤21、获取定长消息m中的任意两个消息片段mi和mj;步骤22、定义消息片段mi和mj中偏移为k的字节的取值分别为mik和mjk,重复比较mik和mjk的取值直至比较结果趋于稳定,k不大于定长消息m的长度;步骤23、根据比较结果,确定定长消息m中亮灯区域的边界序列,将所述亮灯区域的边界序列作为所述定长消息m中所有定长域的边界序列,所述亮灯区域指在一次比较中取值连续相等的字节所组成的消息区间。进一步地,所述第二域边界识别规则具体包括:步骤31、确定定长消息m中的定长域的存储模式,所述存储模式包括大端存储和小端存储;步骤32、统计定长消息m中每个字节的取值种类,根据统计结果确定定长消息m中的常亮区域和常暗区域,所述常亮区域指在定长消息m中取值唯一的字节所组成的消息区间,所述常暗区域指在定长消息m中取值种类为256的字节所组成的消息区间;步骤33、根据常亮区域和常暗区域将定长消息m划分为n个消息块,n为大于1的正整数;步骤34、针对消息块n,若消息块n的长度l为1,则将所述消息块n作为一个定长域;步骤35、若消息块n的长度l大于1,定义消息块n包括消息序列n1,...,nl,对消息序列中的任意两个子消息ni和nj中的偏移为x的取值nix和njx进行比较;若消息块n中的定长域为大端存储,统计所述消息块n中偏移为x的首灯频率fxs,并按照第一预设校正规则对偏移为x的首灯频率fxs进行校正;若消息块n中的定长域为小端存储,则统计所述消息块n中偏移为x的末灯频率为fxe,并按照第二预设校正规则对偏移为x的末灯频率为fxe进行校正;其中,所述首灯频率指偏移为x的字节是亮灯区域的起始边界的频率,所述末灯频率指偏移为x的字节是亮灯区域的结束边界的频率,所述亮灯区域指在一次比较中取值连续相等的字节所组成的消息区间,n=1,2,……,n,0≤x≤l-1;步骤36、在统计到的所有首灯频率中或所有末灯频率中确定最大首灯频率或最大末灯频率步骤37、以最大首灯频率或最大末灯频率为基准,按照预设筛选条件得到能够作为域的起始边界或者域的结束边界的x。进一步地,所述第一预设校正规则具体包括:当满足第一校正条件时,偏移为x的首灯频率fxs加1;所述第一校正条件包括:偏移为x的字节为消息块的起始边界且nix=njx;或者偏移为x的字节不是消息块的起始边界,且有ni(x-1)≠nj(x-1)与nix=njx同时成立;所述第二预设校正规则具体包括:当满足第二校正条件时,偏移为x的末灯频率fxe加1;所述第二校正条件包括:偏移为x的字节为消息块的结束边界且满足nix=njx;或者偏移为x的字节不是消息块的结束边界,且nix=njx与ni(x+1)≠nj(x+1)同时成立;进一步地,所述预设筛选条件具体包括:当首灯频率满足不等式(1)时,则将偏移为x的字节作为定长域的起始边界;当末灯频率满足不等式(2)时,则将偏移为x的字节作为定长域的结束边界;当和均满足上述条件时,比较和的大小,若则将偏移为x的字节作为定长消息m中某个定长域的起始边界;若则将偏移为x的字节作为定长消息m中某个定长域的结束边界,其中β为预设阈值。本发明的有益效果:本发明提供的基于亮灯效应的定长消息格式逆向方法,能够有效解决定长域边界识别的难题。由于定长消息信息压缩性高,特征提取困难,现有方法对定长域边界识别的效果普遍较差。本发明将定长消息类比为建筑物,将消息中的每一字节类比为建筑物的窗户,将两个消息取值相同的连续区间类比为亮灯区域,并结合定长消息的域类型对亮灯效应的影响,针对不同类型的定长消息(理想消息和非理想消息)制定不同的域边界识别规则,以及通过统计首灯概率和末灯概率分别得到大小端存储模式下定长域的候选边界序列。再根据一定的规则,从这些候选边界中筛选出真正的域边界。实验结果证明本发明的效果明显好于其它方法,能够准确识别较多的域边界。同时本发明也为定长域消息格式逆向提供了一种全新的可行的思路,有利于定长域消息格式逆向的进一步发展。附图说明图1为本发明实施例提供的建筑物的亮灯效应的示意图;图2为本发明实施例提供的将建筑物的亮灯效应映射到定长消息的示意图;图3为本发明实施例提供的定长消息的亮灯区域的流程示意图;图4为本发明实施例提供的基于亮灯效应的定长消息格式逆向方法的流程示意图;图5为本发明实施例提供的理想消息中的亮灯概率的示意图;图6为本发明实施例提供的定长域分别采用大端存储模式和小端存储模式的示意图;图7为本发明实施例提供的smb消息首部的常亮区域的示意图;图8为本发明实施例提供的dhcp协议首部的常暗区域的示意图;图9为本发明实施例提供的取值种类、取值均匀性与亮灯概率的关系示意图;图10为本发明实施例提供的亮灯概率与首灯概率的关系示意图;图11为本发明实施例提供的定长域采用小端存储时的亮灯概率和末灯概率的示意图;图12为本发明实施例提供的smb消息首部的标识域的示意图;图13为本发明实施例提供的bittorrent消息首部的标识域的示意图;图14为本发明实施例提供的dns消息中的常暗区域的示意图;图15为本发明实施例提供的根据常亮区域和常暗区域进行消息分块的示意图;图16为本发明实施例提供的smb消息首部取值种类分布的示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。为了更好地理解本发明所提供的技术方案,下面首先对本发明提供的实施例中涉及到的专业术语作具体介绍。定长域是指长度固定的域。定长域的取值可能是数值,也可能是字节数组,可以统一视为数值型。定长域在定长消息(或定长段)中的位置及顺序固定,其语义由其位置确定。定长消息是指由定长域组成的消息。定长消息并非长度固定的消息,而是一种消息类型(一级类型)。虽然定长消息不等同于长度固定的消息,然而大多数情况下定长消息的长度是固定的,只有当定长消息中存在可扩展字段时,消息长度才有可能发生变化,本发明不考虑定长消息中存在可扩展字段的情况。定长段是指由定长域组成的段。为了便于消息解析,定长段通常位于消息首部。定长段的格式逆向方法与定长消息的格式逆向方法相同。定长消息格式逆向的实质:定长消息格式逆向的关键是推测定长消息中每个定长域的边界。定长域的边界是指定长域在定长消息中的起始位置和结束位置,分别称为起始边界和结束边界。由于定长域的长度和顺序固定,定长域的起始边界与结束边界距离定长消息首部的偏移也是固定的。设定长域的起始边界为bs(i),结束边界为be(i),其中s和e分别表示起始和结束,i表示定长域在定长消息中的序号,且i≥1,bs(i)和be(i)的取值分别为定长域的第一个字节距离定长消息首部的偏移和最后一个字节距离定长消息首部的偏移。定长消息中第一个定长域的起始边界为bs(1),设bs(1)=0。由于定长消息中的定长域首尾相接,因此等式be(i)+1=bs(i+1)成立,根据该等式可知,通过定长域的起始边界可以推断定长域的结束边界;反之亦然。因此,定长消息格式逆向的核心可以概括为:推测定长域的起始边界序列或结束边界序列。亮灯效应:如何在不进入一座建筑物的前提下,推测其中每个房间的起始边界(或结束边界)?假设每个房间都有若干扇窗户,且窗户的位置及数量可以表征房间的位置及大小。如图1所示:白天时,窗户之间没有明显的差异;而在夜晚时,由于某些房间亮灯,某些房间不亮灯,导致窗户之间明暗不一。将同一层的连续若干扇亮灯窗户组成的区域称为“亮灯区域”。亮灯区域可能包含一个或多个房间,由于每个房间中所有窗户的亮暗是一致的,因此亮灯区域的起始边界必然是某个房间的起始边界,其结束边界也必然是某个房间的结束边界。由于每天的亮灯区域可能不同,统计每天亮灯区域的起始边界(结束边界),当记录天数足够多时,边界序列将会稳定。此时,序列中的每个边界就对应了建筑物中每个房间的起始边界(结束边界)。本发明将上述原理称为建筑物的“亮灯效应”,利用“亮灯效应”可以在不进入建筑物的情况下推测其中每间房间的边界。如图2和图3所示:建筑物由房间构成,每个房间包含若干窗户;消息由域组成,每个域包含若干字节。本发明首先进行以下概念映射:将定长消息映射为一层建筑;将定长域映射为房间;将字节映射为窗户。在“亮灯效应”中,一个窗户只有两种状态,即亮或暗;而一个字节的取值有256种,因此字节取值无法直接映射为窗户状态。定长消息的亮灯区域:设任意两个定长消息为mi和mj,设所述两个定长消息中偏移为k的字节的取值分别为mik和mjk,将mik与mjk是否相等映射为窗户状态,其中将mik=mjk映射为亮灯,将mik≠mjk映射为不亮灯,将一次比较中取值连续相等的字节所组成的消息区间称为定长消息的“亮灯区域”。亮灯概率:在相同协议的任意两个定长消息中,偏移为x的字节取值相等的概率称为x的亮灯概率。亮灯概率刻画的是相同偏移的字节在不同定长消息中取值相等的可能性。亮灯概率的大小受两种因素影响:取值种类和取值均匀性。取值种类指相同偏移的字节在所有消息中的取值类型的个数;取值均匀性指字节取值在各个取值类型上分布的均匀程度。为了更加直观的阐述这两个影响因素,具体示例如表1所示。表1中的第j、j+1和j+2行分别表示相同偏移的字节在不同定长消息中的取值,第i、i+1、…、i+5列分别表示同一定长消息中的一个消息片段,表格中的数字对应字节取值。表1中列举了6个消息片段,每个消息片段的长度均为3。表1消息中不同字节取值示例取值种类最多可能为256种,最少为1种。由表1可知:表1中偏移为j的字节的取值种类共有三种,分别为2、3、4。表1中偏移为j的字节的取值种类与偏移为j+1的字节的取值种类相同,且都为2、3、4,然而偏移为j的字节取值集中于2,偏移为j+1的字节的取值则比较均匀。对表1中的6个消息片段进行两两比较,比较的总次数为15次。如表2所示,偏移为j、j+1、j+2的字节取值相同的次数分别为6、3、0,对该结果进行分析为:首先,字节j+1与j+2的取值在各个类型上的分布都比较均匀,然而由于j+1的取值种类较少,其取值相同的次数多于j+2;其次,字节j与j+1的取值种类相等,但是j+1的取值分布更加均匀,因此取值相同的次数较少。表2消息中不同字节取值相同的次数字节偏移取值相同次数j6j+13j+20由表1和表2可知:取值种类与取值均匀性对亮灯概率的影响为:第一、取值种类越多,亮灯概率越小,反之亦然。第二、取值越均匀,亮灯概率越小,反之亦然。图4为本发明实施例提供的基于亮灯效应的定长消息格式逆向方法的流程示意图。如图4所示,该方法包括以下步骤:s101、判断定长消息m中所有定长域的域类型,所述域类型包括同步域和异步域;s102、若所述定长消息m中所有定长域均为同步域,则按照第一域边界识别规则确定定长消息各定长域的域边界序列;s103、若所述定长消息m中的定长域包括异步域,则按照第二域边界识别规则确定定长消息各定长域的域边界序列。具体地,本发明定义同步域为满足以下条件的定长域:第一、若域中任意一个字节的取值固定,其它字节的取值也固定;第二、若域中任意一个字节的取值变化,其它字节的取值也变化。由同步域定义可知:同步域中各个字节取值的变化情况是同步的。同步域是一种特殊的定长域,长度为1或取值唯一的定长域可以视为同步域。当组成定长消息的定长域都是同步域时,称该定长消息为理想消息。参照同步域定义可知,异步域是指非同步域的定长域。参照理想消息定义可知,包括异步域的定长消息为非理想消息。在同步域中,各字节的亮灯概率相等,亮灯时机一致。当组成消息的定长域均为同步域时,即当定长消息为理想消息时,利用“亮灯效应”原理可以推测域的边界。在异步域中,各字节的亮灯概率不同,亮灯时机不同。因此,当定长消息为非理想消息时,“亮灯区域”的边界可能与定长域的非边界重合,简单地将“亮灯区域”的边界作为定长域的边界必然会出现错误。由上述内容可知,本发明提供的基于亮灯效应的定长消息格式逆向方法,首先对定长消息中各定长域的域类型进行判断,确定定长消息是理想消息或非理想消息;然后,若定长消息为理想消息,则按照第一域边界识别规则进行消息格式逆向;若定长消息为非理想消息,则按照第二域边界识别规则进行消息格式逆向。在上述实施例的基础上,所述第一域边界识别规则具体包括:s1021、获取定长消息m中的任意两个消息片段mi和mj;s1022、定义消息片段mi和mj中偏移为k的字节的取值分别为mik和mjk,重复比较mik和mjk的取值直至比较结果趋于稳定,k不大于定长消息m的长度;s1023、根据比较结果,确定定长消息m中亮灯区域的边界序列,将所述亮灯区域的边界序列作为所述定长消息m中所有定长域的边界序列,所述亮灯区域指在一次比较中取值连续相等的字节所组成的消息区间。具体地,在上述实施例中已说明,根据同步域定义可知:同步域中各字节的亮灯概率相等,亮灯时机一致,利用“亮灯效应”原理可以推测域的边界。如图5所示为由4个域组成的长度为14的理想消息的亮灯概率。当组成消息的域均为同步域时,步骤s1021至步骤s1023可以简单描述为:对消息进行两两比较,统计“亮灯区域”的边界。当统计次数足够多时,“亮灯区域”的边界序列将会稳定,此时“亮灯区域”的边界序列即为消息中所有域的边界序列。在上述各实施例的基础上,所述第二域边界识别规则具体包括:s1031、确定定长消息m中的定长域的存储模式,所述存储模式包括大端存储和小端存储;具体地,域的存储模式是指域中高低位的存储顺序。类似于数据在内存中的存储模式,域的存储模式可以分为以下两种:大端存储模式和小端存储模式。其中,大端存储模式指域的高位字节靠近消息首部,低位字节靠近消息尾部。小端存储模式指域的高位字节靠近消息尾部,低位字节靠近消息首部。大小端存储模式对数值“0x12345678”的存储如图6所示。由于组成定长消息的定长域通常为异步域,因此域的存储模式也会对消息格式逆向造成影响,必须分别对大小端存储模式进行分析。s1032、统计定长消息m中每个字节的取值种类,根据统计结果确定定长消息m中的常亮区域和常暗区域,所述常亮区域指在定长消息m中取值唯一的字节所组成的消息区间,所述常暗区域指在定长消息m中取值种类为256的字节所组成的消息区间;具体地,常亮区域指定长消息中取值唯一的区域在“亮灯效应”中表现为常亮,本发明称其为常亮区域。常亮区域可以分为两种:第一种为理论取值唯一:协议规定消息中某个域的取值唯一,则在不考虑消息错误的情况下,该域的取值总是唯一。例如smb消息前四个字节的取值总是“0xff534d42”,因此形成了如图7所示的常亮区域。第二种为实际取值唯一:某些域可以取多个值,然而在实际的实验数据中,取值可能唯一;此外,由于数值型域的高位取值个数较少,当实验数据不丰富时,高位的取值也可能唯一。常亮区域在消息中比较常见。常亮区域对格式逆向有两方面影响。一方面,常亮区域的前驱字节的末灯概率为0,后继字节的首灯概率为0,无法判断这两个位置是否为域的边界。另一方面,“常亮区域”的边界通常也是域的边界,而且常亮区域比较容易识别。常暗区域指如果某个区域中每个字节的取值种类都是256种,则每个字节的亮灯概率较小,整个区域在“亮灯效应”中表现为常暗,本发明称其为常暗区域。如图8中起始偏移为4,长度为4的区域为dhcp消息首部的常暗区域,该常暗区域是dhcp的transactionid域。常暗区域在消息中比较常见。常暗区域对格式逆向有两方面影响。一方面,“超数值型域”亮灯概率较小,首灯概率和末灯概率也较小;而另一方面,常暗区域的边界通常也是域的边界,且其特征明显,识别较为容易。s1033、根据常亮区域和常暗区域将定长消息m划分为n个消息块,n为大于1的正整数;具体地,在步骤s1032中统计消息中每个字节的取值种类,然后对消息中的常亮区域和常暗区域进行识别之后,如图14所示,利用常亮区域和常暗区域将消息划分为多个消息块。如果消息块的长度为1,则将其作为一个域,如步骤s1034。如果消息块的长度大于1,则继续进行以下操作,如步骤s1035至步骤s1037。s1034、针对消息块n,若消息块n的长度l为1,则将所述消息块n作为一个定长域;具体地,除了将长度为1的消息块作为一个定长域之外,考虑到常亮区域和常暗区域的特殊性,作如下规定:如果常亮区域中存在不少于三个连续ascii可打印字符,该常亮区域很可能是某个协议的标识域,本发明将其当做一个单独的域。如果常亮区域中每个字节的取值都不为0,且不存在连续文本字符,本发明将常亮区域中的每个字节当做一个域。如果在数据量很丰富的情况下,某个常亮区域中每个字节都是0,则该常亮区域很可能是消息中的预留字段,本发明将其当做一个完整的域。例如smb消息首部第一个域的取值为“0xff534d42”,其中“0x534d42”对应的ascii文本为“smb”,如图12;bittorrent消息中第二个域的取值对应的ascii文本为“bittorrentprotocol”,如图13。常暗区域通常为一个数值型域或者该数值型域的一部分。当数据量比较丰富时,常暗区域总是能够覆盖整个域。因此本发明将常暗区域当做一个完整的域。如图14所示,例如dns消息中的第一个域为“transactionid”域,其长度为2。本发明从darpa数据集中过滤出26万个dns消息,当消息数量为13万时,“transactionid”中第一个字节的取值种类为172种,第二个字节的取值种类为256种,即常暗区域只包含低位字节;当消息数量增大到26万个时,第一个字节的取值种类也增加到256种。s1035、若消息块n的长度l大于1,定义消息块n包括消息序列n1,...,nl,对消息序列中的任意两个子消息ni和nj中的偏移为x的取值nix和njx进行比较;若消息块n中的定长域为大端存储,统计所述消息块n中偏移为x的首灯频率fxs,并按照第一预设校正规则对偏移为x的首灯频率fxs进行校正;若消息块n中的定长域为小端存储,则统计所述消息块n中偏移为x的末灯频率为fxe,并按照第二预设校正规则对偏移为x的末灯频率为fxe进行校正;其中,所述首灯频率指偏移为x的字节是亮灯区域的起始边界的频率,所述末灯频率指偏移为x的字节是亮灯区域的结束边界的频率,所述亮灯区域指在一次比较中取值连续相等的字节所组成的消息区间,n=1,2,……,n,0≤x≤l-1;具体地,由于步骤s1034已对常亮区域和常暗区域的域边界识别进行了具体规定,因此本步骤中的比较并不包括对常亮区域和常暗区域进行比较。异步域是数值型域,而数值型域存在高低位的差别。位数越高,取值种类越少,取值越集中,因此亮灯概率也越大。当组成消息的域为异步域时,假设消息为大端模式,消息中每个字节的取值种类、取值均匀性与亮灯概率的关系如图9所示。域的亮灯概率随着位数的降低呈现出阶梯状递减的特征。由于消息中存在长度为1的域,且域结束边界的亮灯概率可能大于下一个域起始边界的亮灯概率,因此该特征不足以作为域边界识别的依据。在该特征的基础上,介绍本发明的另一个重要概念:首灯概率。首先进行以下定义:a.x表示消息中偏移为x的字节,且x≥1。b.l(x)表示x亮灯这一事件,表示x不亮灯,p(l(x))表示x的亮灯概率,表示x不亮灯的概率,且c.定义sl(x)为事件“x是某个‘亮灯区域’的起始边界”。在上述定义的基础上,首灯概率指在相同协议的任意两个消息中,偏移为x的字节是某个“亮灯区域”的起始边界的概率。以p(sl(x))表示x的首灯概率,则有即x的首灯概率等于x-1不亮灯且x亮灯的概率。由公式可知,首灯概率的大小与两种因素有关:第一、与p(l(x))的大小有关,当p(l(x-1)|l(x))确定时,p(l(x))越大,p(sl(x))越大。第二、与p(l(x-1)|l(x))的大小有关,当p(l(x))确定时,p(l(x-1)|l(x))越小,p(sl(x))越大。其中,对p(l(x-1)|l(x))的大小进行分析,分为两种情况:第一种情况:x和x-1属于同一个域。由于位数越低亮灯概率越小,如果位数较低的字节亮灯,则位数较高的字节也很有可能亮灯,因此p(l(x-1)|l(x))通常较大。第二种情况:x是某个域的开始边界,x-1是上一个域的结束边界。由于x-1与x属于不同的域,相关性较弱,且x-1的亮灯概率较小,因此p(l(x-1)|l(x))通常较小。本发明在图9以及上述分析的基础上推测首灯概率的分布,如图10所示。可以看出,首灯概率在域的起始边界处出现了锐化的现象,本发明称其为首灯概率的边界锐化特征。利用这一特征可以对域的起始边界进行推测。上面已经分析了消息为大端存储时的情况。而当消息为小端存储时,参照首灯概率定义,对末灯概率进行如下定义。末灯概率:在相同协议的任意两个消息中,偏移为x的字节是某个“亮灯区域”的结束边界的概率。定义el(x)为事件“x是某个‘亮灯区域’的结束边界”,则p(el(x))为x的末灯概率,且即末灯概率表示x亮灯且x+1不亮灯的概率。参照首灯概率与亮灯概率的关系分析方法,推测亮灯概率与末灯概率的关系如图11所示。因此当消息为小端存储时,可以利用末灯概率作为域结束边界的识别特征。s1036、在统计到的所有首灯频率中或所有末灯频率中确定最大首灯频率或最大末灯频率s1037、以最大首灯频率或最大末灯频率为基准,按照预设筛选条件得到能够作为域的起始边界或者域的结束边界的x。在上述各实施例的基础上,所述第一预设校正规则具体包括:当满足第一校正条件时,偏移为x的首灯频率fxs加1;其中,所述第一校正条件包括:偏移为x的字节为消息块的起始边界且nix=njx;或者偏移为x的字节不是消息块的起始边界,且有ni(x-1)≠nj(x-1)与nix=njx同时成立;所述第二预设校正规则具体包括:当满足第二校正条件时,偏移为x的末灯频率fxe加1;其中,所述第二校正条件包括:偏移为x的字节为消息块的结束边界且满足nix=njx;或者偏移为x的字节不是消息块的结束边界,且nix=njx与ni(x+1)≠nj(x+1)同时成立;所述预设筛选条件具体包括:当首灯频率满足不等式(1)时,则将偏移为x的字节作为定长域的起始边界;当末灯频率满足不等式(2)时,则将偏移为x的字节为作为定长域的结束边界;当和均满足上述条件时,比较和的大小,若则将偏移为x的字节作为定长消息m中某个定长域的起始边界;若则将偏移为x的字节作为定长消息m中某个定长域的结束边界,其中β为预设阈值。下面通过具体的实验对本发明提供的基于亮灯效应的定长消息格式逆向方法的有效性进行验证。1.实验数据及参数本章实验数据主要从darpa数据集、校园网数据、电信运营商数据以及单机条件下利用wireshark捕获的数据中经过过滤、去重后得到。本节的实验数据为dns消息、smb消息。两种消息都是混合类消息,首部存在定长段,本发明截取其定长段进行实验。实验数据描述如表3所示。实验参数为频率挑选参数β,本发明根据经验值设置β=15。表3定长消息格式逆向实验数据描述编号协议名称定长段长度数据量消息数量1dns1240.9mb2663372smb3213.7mb727392.实验结果分析2.1dns消息dns消息首部为定长段,长度为12,包含6个定长域。其中每个域的长度、位置等信息如表4所示。对定长段中每一字节的取值种类进行统计,结果如表10所示。从表5可以看出,定长段中存在一个常暗区域和四个常亮区域。常暗区域的起始边界为0,长度为2,判断其为一个域,该判断是正确的。常亮区域的起始边界及长度如表6所示,按照判断标准,这四个常亮区域都被当做单独的域,然而该判断是错误的。出现错误的原因为:这四个常亮区域分别对应序号为3至6的域的高位字节。这些域的取值决定了参数段的个数。例如,当questions域的取值为2时,对应questions参数有2个。假设每个参数的长度为10,如果其中某个域的高位字节不为0,则dns消息的长度至少应为256*10+12=2572。而实际的dns消息长度最多只有几百字节,因此,高位字节的取值总是0。利用常亮区域和常暗区域对消息进行分块,将每个长度为1的消息块作为一个域,则得到的dns消息块如表7所示。统计长度大于1的消息块中各字节的首灯频率和末灯频率,结果如表8所示。表4dns消息中的定长域的信息编号名称起始偏移长度1transactionid022flags223questions424answerrrs625authorityrrs826additionalrrs102表5dns消息首部的取值种类分布消息偏移01234567891011取值种类2562568812131213表6dns消息中的常亮区域起始边界46810长度1111表7dns消息块的起始边界及长度编号12345起始边界257911长度21111表8dns消息块中各字节的首灯频率和末灯频率消息偏移23首灯频率735756888108146724末灯频率3070741816345523由表8可知且有因此挑选偏移2作为起始边界,偏移3作为结束边界,即该消息块中只有一个域,该判断是正确的。而是由于flags域由多个以比特为单位的flag组成,且各个flag之间并不存在高低位的差别,因此边界锐化现象不明显。2.2smb消息smb消息头部为定长段,长度为32字节,包含14个域,其中每个域的信息如表9所示。常亮区域和常暗区域将消息分成了两个消息块,如表10所示。统计定长段中每一字节的取值种类,结果如图16所示。由图16可以看出,smb消息的定长段包含一个常亮区域和两个常暗区域。常亮区域的取值中存在连续的ascii文本字符“smb”,因此将其作为一个完整的域;两个常暗区域分别对应消息中signature域和multiplexid域。对常亮区域及常暗区域的判断是正确的。统计两个消息块中各字节的首灯频率和末灯频率并计算及得到结果如表11所示。表11中加黑突出显示的项为最大首灯频率和最大末灯频率。根据筛选条件得到的域的起始边界序列和结束边界序列如表12所示。将结束边界转化为起始边界,则推测得到的起始边界序列和实际起始边界序列如表13所示。表9smb消息中的定长域的信息表10smb消息块的起始边界及长度编号12起始边界422长度108表11smb消息块实验结果描述表12根据筛选条件得到的边界序列起始边界序列4,5,6,10,11,12,22,28结束边界序列7,8,9,13,23,25,29表13实际序列和实验序列实际序列4,5,6,7,9,10,12,22,24,26,28实验序列4,5,6,8,9,10,11,12,22,24,26,28如表13所示,实验结果与实际序列存在两处不同(加黑突出)。首先第四个起始边界的识别出现了错误。其次,实验结果中多出了起始边界11。后者对应的域为flags2域,由多个以比特为单位的flag组成,且各个flag之间并不存在高低位的差别,因此边界锐化不明显。而且虽然将flags2域拆分为两个长度为1的域,但实际上不会对后续的消息解析产生影响。3.实验总结本发明对dns消息和smb消息进行了格式逆向实验,并对结果进行了分析,实验结果验证了基于亮灯效应的定长消息格式逆向方法的正确性。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1