基于分布式泛在计算的高并发服务请求处理方法和设备与流程
本发明涉及物联网技术领域,特别是涉及一种基于分布式泛在计算的高并发服务请求处理方法和设备。
背景技术:
近年来,随着物联网技术的发展,传统的云计算中心已经难以承载物联网设备每天产生的海量数据。为了缓解云端的压力,可以让部署于网络边缘的计算设备处理部分来自物联网设备的服务请求。随着边缘计算、雾计算等技术的发展,利用基于分布式的计算节点处理物联网设备的服务请求,已经成为一种可行的解决方案。
泛在网络使其基础设施(小型服务器,基站等)可以介于云和终端设备之间。泛在网络由共享的计算节点组成,并允许部署在这些节点上的服务依据任务请求被调配。但是,当一台计算设备在短时间内接收来自不同物联网设备的大量服务请求时,往往会造成该计算设备所在的泛在网络堵塞,导致物联网设备请求不能及时得到响应。
目前,为了解决物联网环境下高并发的服务请求问题,现有技术主要关注如何在基于边缘分布式网络中有效地分配任务和搜寻服务。基于线性规划和博弈理论的任务分配模型虽然可以很快解决任务请求,但是,它们针对单个任务进行服务搜寻,而不是针对包含多个子任务的工作流,因此对于复杂的服务请求需要先将分解其所需任务的工作流;利用分布式服务搜寻模型可以减少寻找服务过程造成的延迟,解决方案通常使用抽象的覆盖网络来支持快速服务搜索,使用分布式哈希表等索引函数来缩短寻找时间,并引入分层的虚拟雾拓扑网络来管理历史组合服务,以便在将来能够快速访问,但是,这种解决方案在应对高并发服务请求时需要在网络中频繁地发送搜索指令,使得网络带宽被大量占用,从而引起网络拥塞,造成部分服务的搜寻失败。
本发明定义技术名词如下:
处理设备:部署在云和终端设备之间,具有共享的计算能力的设备。该设备的具体形态可包括小型服务器、基站、路由、个人计算机、平板电脑等;该设备的组网方式与基础框架可以是雾计算、边缘计算、多通路边缘计算、微云等相似技术。
高并发:所述计算设备每秒钟需要响应的请求数量(qps)大于1(qps=每秒并发服务请求数量/服务请求的平均响应时间)。
技术实现要素:
本发明所要解决的技术问题是提供一种基于分布式泛在计算的高并发服务请求处理方法和设备,可以用于高并发服务请求的物联网环境,并支持包含多个子任务的服务请求。
本发明解决其技术问题所采用的技术方案是:提供一种基于分布式泛在计算的高并发服务请求处理方法,包括以下步骤:
(1)处理设备根据请求间的相似性对请求进行分组,其中,相似性的判定依据包括请求的功能特性需求和非功能特性需求;
(2)处理设备提取一组请求中的服务需求,并找到能够满足所述服务需求的微服务。
所述步骤(1)中功能特性需求是指服务请求功能的语义表达,非功能特性需求是指服务请求的发出时间和发出设备在网络拓扑中位置的任意一个。
所述步骤(1)中处理设备是依据请求所对应特征向量的相似性对其进行分组,其中,特征向量利用请求的功能特性需求和非功能特性需求来表征。
所述步骤(1)中通过聚类算法实现对请求进行分组。
所述聚类算法可以为采用基于密度的聚类算法,其中,每个请求被定义为特征向量r,r的邻域被定义为neighborhoodeps(ri)={rj∈{r}|dist(ri,rj)≤eps},其中,eps表示请求r邻域的最大半径,dist()表示请求之间的距离,minpts表示其邻域中向量的最小数目,只要新请求neighborhoodeps(r)≥minpts,则新建一个集群,r和它的邻域neighborhoodeps(r)都将添加到新集群中;如果neighborhoodeps(r)<minpts,新集群将与现有集群合并。该分组的形式采用渐进式,根据新请求到达的先后顺序依次进行分组;所述渐进式分组建立了分组监视机制,所述分组监视机制为每个分组设置一个时间阈值,该阈值的选择是基于分组请求的平均时限值。该分组的形式也可采用缓存-处理模式,将新请求预先缓存,当缓存的请求数量达到预设值后再集中进行分组。
所述聚类算法可以为基于k-means的聚类算法,其中,在n个高并发请求中随机选取k个请求作为集群中心点,分别计算出剩余请求到这k个中心点的距离,将它们划分至最近的集群中;然后再重新计算出每一个新集群的中心点,定义第k个集群的中心点:
所述步骤(2)中计算节点提取的服务需求包括请求分组中所需的子任务、子任务之间的依赖关系以及分组中每个子任务需要的微服务数量。
所述步骤(2)中计算节点基于服务需求采用服务搜寻算法来找到能够满足分组中所有需求的微服务。
所述服务搜寻算法是指如果计算节点中没有请求分组所需的微服务,则该节点会转发服务需求到其他节点中继续寻找。
本发明所采用的技术方案还包括:提供一种基于分布式泛在计算的高并发服务请求处理设备,包括:请求分组模块,用于接收来自多台物联网设备的请求,并根据请求间的相似性对请求进行分组,其中,相似性的判定依据包括请求的功能特性需求和非功能特性需求;服务管理模块,用于为所述请求分组模块的每组请求提供服务。
所述功能特性需求是指服务请求功能的语义表达,非功能特性需求是指服务请求的发出时间和发出设备在网络拓扑中位置的任意一个。
所述请求分组模块包括:特征提取单元,用于从功能性需求和非功能性需求方面对每个请求进行特征提取;相似性分析单元,用于根据所述特征提取单元提取的特征分析两个请求之间的相似性。
所述请求分组模块还包括:渐进式分组单元,用于采用渐进式的方式将具有相似特征的请求放在一个请求分组中,所述渐进式分组单元为每个所述请求分组设置一个时间阈值;其中,如果所述请求分组在时间阈值内没有进入任何新的请求,则所述设备将直接为所述请求分组寻找相应服务。
所述服务管理模块中没有所述请求分组模块所需微服务时,则所述服务管理模块会发送服务需求消息到其他所述设备中以寻找所需微服务。
有益效果
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明将物联网环境下高并发服务请求进行分组,以请求集群为单位进行处理,并且利用联合发现方法为请求集群查找适当微服务,不仅可以缩短服务响应时间,还可以减少数据流量。
附图说明
图1是本发明一种实施方式的流程图;
图2是本发明一种实施方式中提供的一种基于分布式泛在计算的高并发服务请求处理方法流程图;
图3是本发明一种实施方式中提供的另一种基于分布式泛在计算的高并发服务请求处理方法流程图;
图4是本发明另一种实施方式的结构示意图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
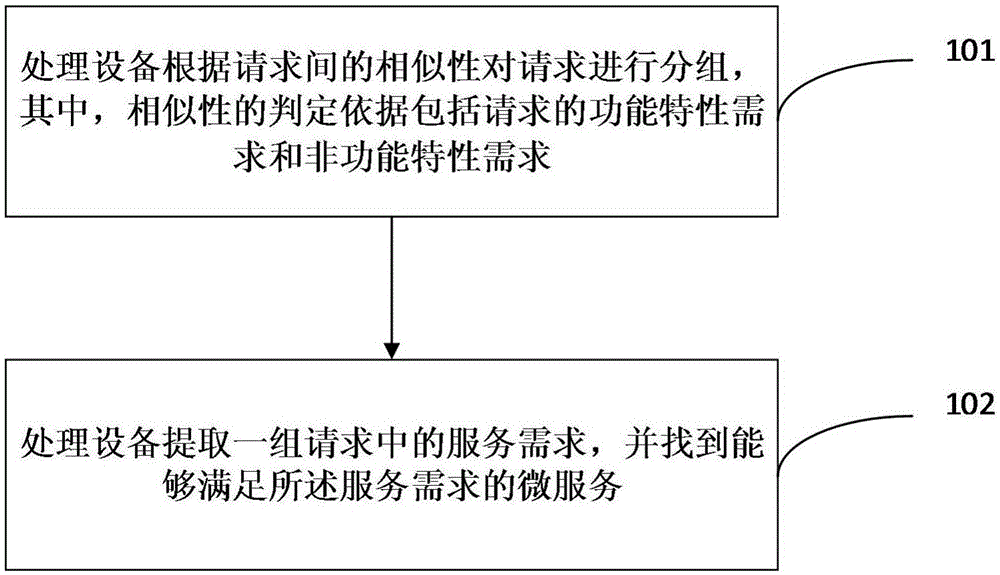
本发明的一种实施方式涉及一种基于分布式泛在计算的高并发服务请求处理方法,如图1所示,包括以下步骤:
步骤101:处理设备根据请求间的相似性对请求进行分组,其中,相似性的判定依据包括请求的功能特性需求和非功能特性需求;
步骤102:处理设备提取一组请求中的服务需求,并找到能够满足所述服务需求的微服务。
由此可见,本发明将物联网环境下高并发服务请求进行分组,以请求集群为单位进行处理。下面通过两个具体的实例来进一步说明本发明。
实施例1:如图2所示,包括以下步骤:
步骤一、处理设备根据请求间的相似性将请求分组,其中,相似性的判定依据包括请求的功能特性需求和非功能特性需求:
(1)本实例中功能性需求是服务请求r功能的语义表达f,非功能性需求是服务请求的发出时间sp和发出设备在网络拓扑中位置tp;
鉴于所讨论特征的异质性,首先考虑一个二维特征向量vi=(spi,tpi)表示服务请求的发出时间和发出设备在网络拓扑中位置,选用马哈拉诺比斯距离(mahalanobisdistance)计算请求i和请求j在上述两个维度中的相似性:
其中
然后利用语义距离来指示功能的相似性,请求r功能的语义表达f表示为由一组子任务组成的工作流。相似度计算定义为:
distsem(i,j)=sim(fi,fj)
其中函数sim(fi,fj)被定义为
最后采用数据融合的方法融合distsp-tp(i,j)和distsem(i,j),得到不同请求所对应的特征向量之间的距离:
其中α和β是不同特征维度的权重值,取值方法包括q-learning等,可依据具体业务调整;
(2)进一步地,选用基于密度的渐进式聚类算法依据新请求和现有集群中请求的相似性对其进行聚类处理:
用eps表示请求r邻域的最大半径,minpts表示它邻域中向量的最小数目,ri的邻域定义为:
neighborhoodeps(ri)={rj∈{r}|dist(ri,rj)≤eps}
只要新请求neighborhoodeps(r)≥minpts,该算法就会新建一个集群,r和它的邻域neighborhoodeps(r)都将添加到新集群中;如果neighborhoodeps(r)<minpts,新集群将与现有集群合并;
上述聚类过程中包括一个聚类监视机制,它为每个集群设置一个时间阈值,该阈值的选择是基于聚类请求的平均时限值,如果集群在特定时间段内没有任何新的请求,处理设备会将集群转换为封闭集群,停止向其增加新请求并继续前进到下一步;
步骤二、处理设备提取一组请求中的服务需求,并找到能够满足所述服务需求的微服务:
(1)处理设备提取的服务需求包括请求集群中所需的子任务、子任务之间的依赖关系以及分组中每个子任务需要的微服务数量;
服务需求的相关信息可以选用有向无环图(dag)来表示:
定义服务需求信息为gdscv=(t,d,w),其中t为表示集群需要的子任务的顶点,d是表示子任务之间依赖关系的边,w是顶点的权重值,表示集群中需要微服务来满足子任务的请求数量;
进一步地,定义服务消息为rcluster=(gdscv,c),其中c表示请求集群所允许的最大响应时间,它是根据单个请求的时限值而定;
(2)处理设备依据服务发现消息,并采用启发式服务搜寻算法来找到可满足集群中所有需求的微服务:
服务发现消息从最近的处理设备发出,它将首先由可以支持最后一个子任务的处理设备处理,再转发到其他处理设备继续寻找可以完成剩余子任务的微服务;
在服务发现过程中还需设置启发值h用来减少转发次数,防止网络拥堵。具体地,就是在服务发现过程开始时将h设置为0,并且通过向h添加预期响应时间使h值在每次转发服务发现信息之后增加;
其中预期响应时间是根据服务发现过程中找到微服务的大致执行时间来估计。如果h值大于c,处理设备将停止转发gdscv;
(3)在服务发现结束后,处理设备将为请求分组中每一个请求分配相应的微服务,联合完成请求。
实施例2:如图3所示,包括以下步骤:
步骤一、处理设备根据请求间的相似性将请求分组,其中,相似性的判定依据包括请求的功能特性需求和非功能特性需求:
(1)本实例中功能性需求是服务请求r功能的语义表达f,非功能性需求是服务请求的发出时间sp;
首先选用欧氏距离(euclideandistance)计算请求i和请求j在时间sp维度中的相似性:
distsp(i,j)=|spi-spj|
然后利用语义距离来指示功能的相似性,请求r功能的语义表达f表示为由一组子任务组成的工作流。相似度计算定义为:
distsem(i,j)=sim(fi,fj)
其中函数sim(fi,fj)被定义为
再采用数据融合的方法融合distsp(i,j)和distsem(i,j),得到不同请求所对应的特征向量之间的距离:
其中λ和β是不同特征维度的权重值;
(2)进一步地,选用基于k-means聚类算法的缓存-处理模式,当缓存区中的请求数量达到n后再对其集中进行聚类处理:
在n个高并发请求中随机选取k个请求作为集群中心点,分别计算出剩余请求到这k个中心点的距离,将它们划分至最近的集群中;然后再重新计算出每一个新集群的中心点,定义第k个集群的中心点:
其中,ck表示第k个集群,|ck|表示第k个集群中请求的个数;
重复上述操作,直到δj<δ时终止迭代,其中
步骤二、处理设备提取一组请求中的服务需求,并找到能够满足所述服务需求的微服务:
(1)处理设备提取的服务需求包括请求集群中所需的子任务、子任务之间的依赖关系以及分组中每个子任务需要的微服务数量;
服务需求的相关信息可以选用有向无环图(dag)来表示:
定义服务需求信息为gdscv=(t,d,w),其中t为表示集群需要的子任务的顶点,d是表示子任务之间依赖关系的边,w是顶点的权重值,表示集群中需要微服务来满足子任务的请求数量;
进一步地,定义服务消息为rcluster=(gdscv,c),其中c表示请求集群所允许的最大响应时间,它是根据单个请求的时限值而定;
(2)处理设备依据服务发现消息,并采用启发式服务搜寻算法来找到可满足集群中所有需求的微服务:
服务发现消息从最近的处理设备发出,它将首先由可以支持最后一个子任务的处理设备处理,再转发到其他处理设备继续寻找可以完成剩余子任务的微服务;
在服务发现过程中还需设置启发值h用来减少转发次数,防止网络拥堵。具体地,就是在服务发现过程开始时将h设置为0,并且通过向h添加预期响应时间使h值在每次转发服务发现信息之后增加;
其中预期响应时间是根据服务发现过程中找到微服务的大致执行时间来估计。如果h值大于c,处理设备将停止转发gdscv;
(4)在服务发现结束后,处理设备将为请求分组中每一个请求分配相应的微服务,联合完成请求。
不难发现,本发明以请求集群为单位进行处理,并且利用联合发现方法为请求集群查找适当微服务,不仅可以缩短服务响应时间,还可以减少数据流量。
实施例3:
本发明的另一种实施方式涉及一种基于分布式泛在计算的高并发服务请求处理设备,所述设备为可以是小型基站、车载终端等边缘设备或雾计算设备;手机、汽车以及家用电器等终端设备通过有线或者无线连接到距离最近的所述设备。所述设备结构如图4所示,主要包括请求分组模块310和服务管理模块320。所述请求分组模块310用于接收来自多台终端设备的请求,并根据请求之间功能性和非功能性特征的关联进行分组,对请求进行分组的依据是短时间内大量的请求可能存在一定的相似性,例如,世界杯比赛期间来自终端设备的视频直播服务请求、车载导航的实时路况服务请求等;所述服务管理模块320,用于为所述请求分组模块的每组请求提供服务;
进一步地,所述功能性特征关联由请求之间的语义相似性决定,所述非功能性特征关联由请求发出的时间和发出请求的设备在网络拓扑中的位置所决定;
进一步地,所述请求分组模块310包括:
特征提取单元311,用于对来自所述多台终端设备的每个数据请求进行特征提取;具体地,特征提取单元311将每个请求建模为三维特征空间中的特征向量,其中,所述三维特征空间包括语义、时间和空间三个维度;
进一步地,所述请求分组模块310还包括:
相似性分析单元312,用于根据所述特征提取单元提取的特征分析两个请求之间的相似性;具体地,当所述特征向量之间的距离小于某一阈值时,所述分组单元312会判定为相似请求,并把它们分组到一起,形成一个请求集群;
进一步地,所述请求分组模块310还包括:
渐进式分组单元313,用于采用渐进式的方式将具有相似特征的请求放在一个请求分组中,还用于为每个所述请求集群设置一个时间阈值,其中,如果所述请求集群在时间阈值内没有进入任何新的请求,则所述设备分组单元312将会停止分组,所述服务管理模块320将直接为所述请求集群寻找相应服务;
进一步地,所述服务管理模块320具体用于在应用程序初始化阶段部署微服务,所述请求分组模块310通过接口向所述服务管理模块320调用所需微服务,如果所述服务管理模块320中没有所需微服务,则所述服务管理模块320会发送服务需求消息到其他所述设备中以寻找所需微服务。
不难发现,本发明将物联网环境下高并发服务请求进行分组,以请求集群为单位进行处理,并且利用联合发现方法为请求集群查找适当微服务,不仅可以缩短服务响应时间,还可以减少数据流量。
- 还没有人留言评论。精彩留言会获得点赞!