一种视频压缩方法及系统与流程
本发明涉及视频压缩领域,特别涉及一种视频压缩方法及系统。
背景技术:
目前的视频压缩方法在发展上遇到瓶颈,且复杂度越来越高,并不能很好得利用gpu硬件加速性能,在cpu上也难以优化。
技术实现要素:
为了解决上述问题,本发明实施例提供了一种视频压缩方法。
根据本发明的第一方面,提供了一种视频压缩方法,包括:
基于预测网络中的分离卷积网络,根据前一帧和当前帧计算运动向量;
基于所述预测网络,根据所述前一帧和所述运动向量对当前帧进行预测,得到预测帧;
计算所述当前帧和所述预测帧的残差;
根据残差网络对所述残差进行压缩,得到残差压缩;
基于视频压缩网络,根据所述残差压缩和所述预测帧对所述当前帧进行压缩。
进一步地,所述残差网络的训练方法包括:
通过特征提取网络提取训练图像的特征;
根据概率模型对所述特征进行估计,得到码率估计结果;
将所述特征输入解码网络,得到重建图;
将所述重建图与所述训练图像进行比较,并根据所述码率估计得到率-失真优化结果;
根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
进一步地,所述通过特征提取网络提取训练图像的特征包括:
通过特征提取网络进行图像特征的映射,得到所述训练图像的特征,其中,所述特征提取网络为自编码网络。
进一步地,所述根据概率模型对所述特征进行估计,得到码率估计结果包括:
根据概率模型对分布进行估计,并根据熵进行码率估计,得到所述码率估计结果。
进一步地,所述将所述特征输入解码网络,得到重建图包括:
根据自解码网络,对所述特征进行解码,得到重建图;
进一步地,所述将所述重建图与所述训练图像进行比较,并根据所述码率估计得到率-失真优化结果包括:
将所述重建图和所述训练图像进行比较,得到失真残差;
根据所述码率估计结果和所述失真残差得到所述率-失真优化结果。
进一步地,所述自编码网络和自解码网络为多层卷积神经网络,其中所述自编码网络的层数和所述自解码网络的层数可以相同和/或不同。
进一步地,在所述将所述特征输入解码网络,得到重建图之前,还包括:
对所述特征进行量化,得到量化后的特征。
根据本发明的第二方面,提供了一种视频压缩系统,其特征在于,包括:
获取装置,用于获取前一帧和当前帧;
压缩装置,用于根据预测网络、残差网络以及视频压缩网络对所述视频进行压缩,得到压缩后的视频;
训练装置,用于对所述预测网络、残差网络以及视频压缩网络进行训练。
进一步地,所述训练装置包括:
提取单元,用于通过特征提取网络提取图像的特征;
估计单元,用于根据概率模型对所述特征进行估计,得到码率估计结果;
解码单元,用于将所述特征输入解码网络,得到重建图;
比较单元,用于将所述重建图与所述图像进行比较,并根据所述码率估计得到率-失真优化结果;
调整单元,用于根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
本发明实施例提供一种视频压缩方法及系统,具有法压缩效果更好并易于实现、扩展性强的优点。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的方法流程图;
图2是本发明实施例提供的模型训练方法流程图;
图3是是本发明实施例提供的模型训练方法流程图;
图4是本发明实施例提供的模型训练示意图;
图5是本发明实施例提供的模型训练示意图;
图6是本发明实施例提供的模型训练示意图;
图7是本发明实施例提供的装置示意图;
图8是本发明实施例提供的模型训练装置示意图;
图9是本发明实施例提供的装置示意图;
图10是本发明实施例提供的模型训练装置示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
这里需要指出的是本发明中的前一帧和当前帧是相对的,并且在下面的描述中为了简便起见,通常用i帧来表示前一帧,p帧来表示当前帧,因为前一帧和当前帧是相对的,所以对于上述p帧的下一帧来说,该p帧即为i帧,并且对于视频的第一个i帧来说,可以对该i帧采用如实施例二、三中所述的残差网络进行压缩,得到压缩后的i帧。
实施例一
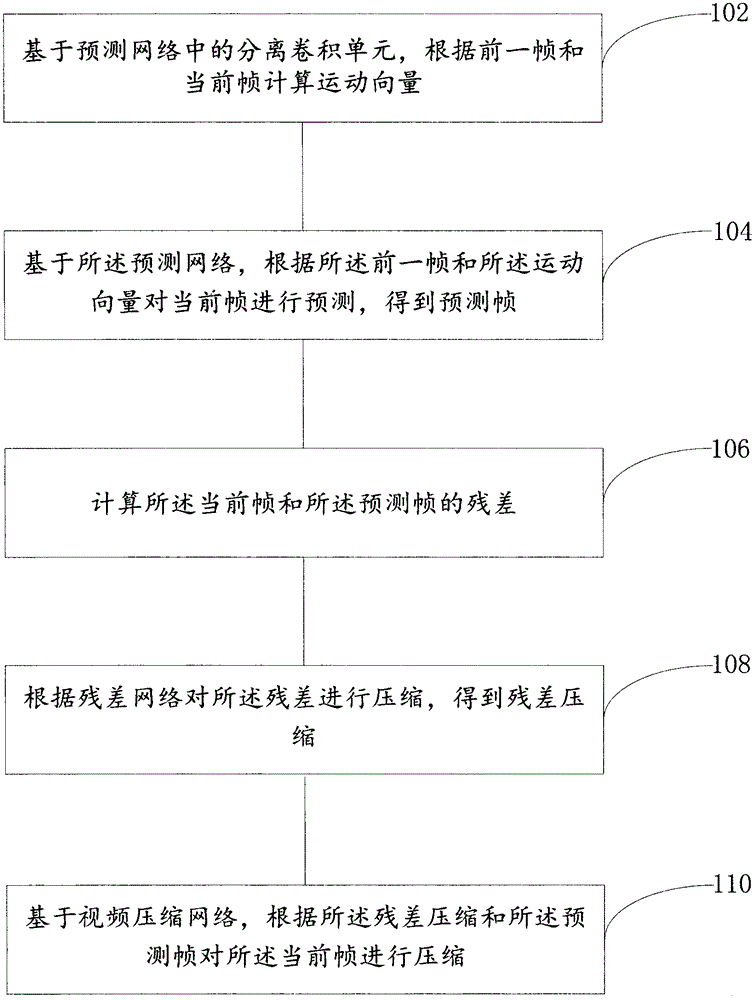
本发明实施例提供了一种视频压缩方法,如图1所示,包括:
步骤102,基于预测网络中的分离卷积单元,根据前一帧和当前帧计算运动向量。
具体的,分离卷积单元设计为encoder-decoder结构,提取bottle_neck层的高维特征信息,之后对其进行量化、熵编码。decoder阶段得到的是分离卷积kernel,运动向量mv压缩需要消耗的比特数记为bit_m。
步骤104,基于所述预测网络,根据所述前一帧和所述运动向量对当前帧进行预测,得到预测帧。
具体的,i帧中每个像素都有一个大小为[21*21]的运动kernel,对每个像素与其对应的分离卷积kernel进行卷积操作,得到预测帧p_predict,其中,预测网络的结构,量化,码率估计结构和实施例x中的描述类似,只是网络参数有所不同。
步骤106,计算所述当前帧和所述预测帧的残差。
具体的,p帧与预测帧p_predict相减便得到残差r。
步骤108,根据残差网络对所述残差进行压缩,得到残差压缩。
具体的,残差r通过自编码网络进行压缩,提取bottle_neck层的高维特征信息,然后对其进行量化、熵编码,其中,残差网络的结构,量化,码率估计结构和实施例x中的描述类似,只是网络参数有所不同。
步骤110,基于视频压缩网络,根据所述残差压缩和所述预测帧对所述当前帧进行压缩。
具体的,根据该视频压缩网络对预测准确度和压缩程度的占比,对所述残差压缩和所述预测帧进行相应的处理得到当前帧的压缩结果。
实施例二
残差网络的训练方法如图2所示,包括:
步骤202,通过特征提取网络提取图像的特征。
具体的,可以通过自编码网络提取图像的特征。
自编码网络的作用是将数据从图像空间x,转换到数据编码空间y,它包含一个编码器fe。编码器的作用是将图像像素值x转换为压缩特征y=fe(x)。
步骤204,根据概率模型对所述特征进行估计,得到码率估计结果。
具体的,包括:
根据概率模型对分布进行估计,并根据熵进行码率估计,得到所述码率估计结果。
码率可用熵的结构进行建模,公式为:
其中,r表示码率,q表示量化,p表示概率模型,
可以使用带参数的方式对先验分布进行拟合,然后用数据驱动的方式对先验概率模型进行学习。
步骤206,将所述特征输入解码网络,得到重建图。
具体的,
根据自解码网络,对码所述特征进行解码,得到重建图。
步骤208,将所述重建图与所述图像进行比较,并根据所述码率估计得到率-失真优化结果。
具体的,
将所述重建图和所述图像进行比较,得到失真残差;
根据所述码率估计结果和所述失真残差得到所述率-失真优化结果。
在压缩模型中,失真d可以用均方误差
步骤210,根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
具体的,根据所述率-失真优化结果对所述特征提取网络的参数进行训练,并根据训练结果对所述参数进行优化。
进一步地,在步骤206之前,还包括:对所述压缩特征进行量化,得到量化后的压缩特征。
具体的,在训练过程中,使用加性均匀噪声设计量化器,表示方式为
进一步地,对于预测网络中除分离卷积单元外的部分,训练方式跟上述残差网络的训练方式类似,包括:
通过特征提取网络提取训练p帧的特征;
根据概率模型对所述特征进行估计,得到码率估计结果;
将所述特征输入解码网络,得到预测p帧;
将预测p帧与训练p帧像进行比较,并根据所述码率估计得到率-失真优化结果;
根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
实施例三
残差网络的训练方法如图3所示,包括:
步骤302,通过特征提取网络提取图像的特征。
具体的,采用如图4所示的三层卷积神经网络对图像的特征进行提取,在一种可选的方式中,将每层卷积神经网络得到的结果都作为输入来计算得到最终的特征,即通过将每层卷积后得到的归一化特征再次进行卷积并作为级联的输入。
步骤304,根据概率模型对所述特征进行估计,得到码率估计结果。
具体的,包括:
根据概率模型对分布进行估计,并根据熵进行码率估计,得到所述码率估计结果。
自然图像的数据分布一般被认为是符合高斯分布,所以可以采用零均值,方差表示为
其中μ表示平均分布,
进一步地,可以采用自编码网络对方差
特征的码率可用熵的结构进行建模
步骤306,对特征进行量化,得到量化后的特征。
具体的,包括:
在训练过程中,使用加性均匀噪声设计量化器,表示方式为
步骤308,将量化后的特征输入解码网络,得到重建图。
具体的,
根据自解码网络,对量化后的特征进行解码,得到重建图。
步骤310,将所述重建图与所述图像进行比较,并根据所述码率估计得到率-失真优化结果。
具体的,
将所述重建图和所述图像进行比较,得到失真残差;
根据所述码率估计结果和所述失真残差得到所述率-失真优化结果。
在压缩模型中,失真d可以用均方误差
步骤312,根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
具体的,采用梯度反向传播算法对卷积神经网络的参数进行更新。
进一步地,对于预测网络中除分离卷积单元外的部分,训练方式跟上述残差网络的训练方式类似,包括:
通过特征提取网络提取训练p帧的特征;
根据概率模型对所述特征进行估计,得到码率估计结果;
将所述特征输入解码网络,得到预测p帧;
将预测p帧与训练p帧像进行比较,并根据所述码率估计得到率-失真优化结果;
根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
实施例四
本发明实施例中的视频压缩网络如图6所示,熵编码网络同样通过类似于实施例二、实施例三中方式进行训练,根据残差图像的拉普拉斯分布特性,训练对应的概率模型,预测帧p_predict,累加解码后的残差r,得到原始帧的重建帧p_recon,残差压缩需要消耗的比特数为bit_r,具体来说,使用联合损失loss,loss的设计由预测帧及重建帧两部分损失叠加而成,loss=iambda_1*loss_recon+loss_predict,iambda_1=0.25,通过更改iambda_1的大小,分配模型对预测和残差压缩阶段的重视程度,只约束精度损失loss,会使模型对p帧的恢复越来越精准,但与此同时,压缩消耗的码率也会直线上升,因此需要根据不同的目的来寻求精度与压缩比的平衡,所以网络最终的rd-loss是由两部分组成:rd-loss=iambda_2*loss+rate。其中iambda_2是可调参数,分配网络对预测准确度和压缩程度的占比,rate则由两部分组成:rate=bit_m+bit_r。
实施例五
本发明实施例提供了一种视频压缩系统,如图7所示,包括:
获取装置701,用于获取前一帧和当前帧。
具体的,获取装置701用于获取待压缩的视频帧。
压缩装置702,用于根据预测网络、残差网络以及视频压缩网络对所述视频进行压缩,得到压缩后的视频。
具体的,压缩装置702用于根据训练好的预测网络、残差网络以及视频压缩网络对所述视频进行压缩,得到压缩后的视频。
训练装置703,用于对所述预测网络、残差网络以及视频压缩网络进行训练。
具体的,
如图8所示,训练装置703包括:
提取单元801,用于通过特征提取网络提取图像的特征。
具体的,可以通过自编码网络提取图像的特征。
自编码网络的作用是将数据从图像空间x,转换到数据编码空间y,它包含一个编码器fe。编码器的作用是将图像像素值x转换为压缩特征y=fe(x)。
估计单元802,用于根据概率模型对所述特征进行估计,得到码率估计结果。
具体的,包括:
根据概率模型对分布进行估计,并根据熵进行码率估计,得到所述码率估计结果。
码率可用熵的结构进行建模,公式为:
其中,r表示码率,q表示量化,p表示概率模型,
可以使用带参数的方式对先验分布进行拟合,然后用数据驱动的方式对先验概率模型进行学习。
解码单元803,用于将所述特征输入解码网络,得到重建图。
具体的,
根据自解码网络,对特征进行解码,得到重建图。
比较单元804,用于将所述重建图与所述图像进行比较,并根据所述码率估计得到率-失真优化结果。
具体的,
将所述重建图和所述图像进行比较,得到失真残差;
根据所述码率估计结果和所述失真残差得到所述率-失真优化结果。
在压缩模型中,失真d可以用均方误差
调整单元805,用于根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
具体的,根据所述率-失真优化结果对所述特征提取网络的参数进行训练,并根据训练结果对所述参数进行优化。
进一步地,还包括量化单元806,用于对特征进行量化,得到量化后的特征。
具体的,在训练过程中,使用加性均匀噪声设计量化器,表示方式为
实施例六
本发明实施例提供了一种视频压缩系统,如图9所示,包括:
获取装置901,用于获取前一帧和当前帧。
具体的,获取装置901用于获取待压缩的视频帧。
压缩装置902,用于根据预测网络、残差网络以及视频压缩网络对所述视频进行压缩,得到压缩后的视频。
具体的,压缩装置902用于根据训练好的预测网络、残差网络以及视频压缩网络对所述视频进行压缩,得到压缩后的视频。
训练装置903,用于对所述预测网络、残差网络以及视频压缩网络进行训练。
具体的,
如图10所示,训练装置903包括:
提取单元1001,用于通过特征提取网络提取图像的特征。
具体的,采用如图4所示的三层卷积神经网络对图像的特征进行提取,在一种可选的方式中,将每层卷积神经网络得到的结果都作为输入来计算得到最终的特征,即通过将每层卷积后得到的归一化特征再次进行卷积并作为级联的输入。
量化单元1002,用于对特征进行量化,得到量化后的特征。
具体的,包括:
在训练过程中,使用加性均匀噪声设计量化器,表示方式为
估计单元1003,用于根据概率模型对所述特征进行估计,得到码率估计结果。
具体的,包括:
根据概率模型对分布进行估计,并根据熵进行码率估计,得到所述码率估计结果。
自然图像的数据分布一般被认为是符合高斯分布,所以可以采用零均值,方差表示为
其中μ表示平均分布,
进一步地,可以采用自编码网络对方差
码率可用熵的结构进行建模
解码单元1004,用于将所述特征输入解码网络,得到重建图。
具体的,
根据自解码网络,对量化后的特征进行解码,得到重建图。
比较单元1005,用于将所述重建图与所述图像进行比较,并根据所述码率估计得到率-失真优化结果。
具体的,
将所述重建图和所述图像进行比较,得到失真残差;
根据所述码率估计结果和所述失真残差得到所述率-失真优化结果。
在压缩模型中,失真d可以用均方误差
考虑到码率约束,可以构建一个进行码率有效分配的优化算法,目的是为码率约束的条件下,为每个图像选择最优的模型。每张图的最优配置,通过优化以下的优化问题进行选择,具体公式为:
其中,d表示失真,xi表示所述图像,
调整单元1006,用于根据所述率-失真优化结果对所述特征提取网络的参数进行调整。
具体的,采用梯度反向传播算法对卷积神经网络的参数进行更新。
- 还没有人留言评论。精彩留言会获得点赞!