为热点内容设置副本的方法与流程
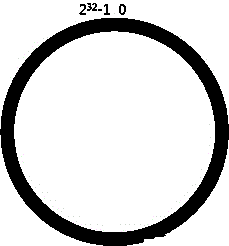
本发明属于大数据的负载均衡领域。
背景技术:
一致性哈希算法(consistenthashingalgorithm)是一种分布式算法,常用于负载均衡。memcachedclient也选择这种算法,解决将key-value均匀分配到众多memcachedserver上的问题。它可以取代传统的取模操作,解决了取模操作无法应对增删memcachedserver的问题(增删server会导致同一个key,在get操作时分配不到数据真正存储的server,命中率会急剧下降)。
但现有技术中,采用一致性哈希算法和虚拟节点的方式,做到了将数据大致均匀的分布到各个节点上,但是没有考虑数据之间的冷热性。而现实的应用中,数据的冷热差异很大,从而导致对各个节点的访问量是不均匀的。当连接数过大时,系统将无法提供服务。从而导致负载不均衡的问题出现。
技术实现要素:
为热点内容设置副本的方法,包括:
步骤1:大数据系统具有n个服务器,采用一致性哈希算法,将这n个服务器放置到哈希函数的值空间为0-(
步骤2:大数据系统开始运行后,监控器周期性监测各个服务器的负载参数,具体方式为:在时刻t服务器i的负载为
步骤3:计算t时刻服务器群的平均负载为:
步骤4:计算t时刻服务器群的负载方差为:
步骤6:从所有服务器中找到负载最大的服务器;
步骤7:从该负载最大的服务器上找到最近一段时间(例如是1天)内被访问次数最多的m个内容文件,例如可以预先将m设定为10;
步骤8:为这m个内容文件设置副本名称。优选的方式是在原始文件名后添加副本号,例如原始文件名为:filename,则副本名可以设置为filename#1。如果已经存在了一个副本,副本名为filename#1,后续还需要再增加副本时,可以将副本名设置为filename#2。
步骤9:计算副本名的哈希值,根据一致性哈希算法,将该副本存入相对应的服务器上。所有的副本信息都存放到一个负载服务器上,当用户需要访问某个文件内容时,先向负载服务器发送请求,负载服务器通过查询发现该内容没有设置副本,则直接根据现有的处理流程处理直接去访问原始内容,如果发现了存在副本,则从原始内容和副本内容中随机选择一个内容进行访问。从而实现了热门内容的多副本设置,降低单个服务器的访问压力。
步骤10:返回到步骤2。
为热点内容设置副本的方法,包括:
步骤1:所述大数据系统中具有n个服务器,采用一致性哈希算法,将这n个服务器放置到哈希函数的值空间为0-(
步骤2:大数据系统开始运行后,监控器周期性监测各个服务器的负载参数,具体方式为:在时刻t服务器i的负载为
步骤3:计算t时刻服务器群的平均负载为:
步骤4:计算t时刻服务器群的负载方差为:
步骤6:从所有服务器中找到负载最大的服务器;
步骤7:从该负载最大的服务器上找到最近一段时间(例如是1天)内被访问次数最多的m个内容文件,例如可以预先将m设定为10;
步骤8:为这m个内容文件设置副本名称。优选的方式是在原始文件名后添加副本号,例如原始文件名为:filename,则副本名可以设置为filename#1。如果已经存在了一个副本,副本名为filename#1,后续还需要再增加副本时,可以将副本名设置为filename#2。
步骤9:计算副本名的哈希值,根据一致性哈希算法,将该副本存入相对应的服务器上。所有的副本信息都存放到一个负载服务器上,当用户需要访问某个文件内容时,先向负载服务器发送请求,负载服务器通过查询发现该内容没有设置副本,则直接根据现有的处理流程处理直接去访问原始内容,如果发现了存在副本,则从原始内容和副本内容中随机选择一个内容进行访问。从而实现了热门内容的多副本设置,降低单个服务器的访问压力。
步骤10:返回到步骤2。
本发明的优点是根据服务器负载的均方差,来确定是否要为负载最大的服务器上的热门内容设置副本,从而达到分担负载,减轻单个服务器负载压力的问题。
附图说明
图1是根据本发明实施例的原理图1;
图2是根据本发明实施例的原理图2;
图3是根据本发明实施例的原理图3;
图4是根据本发明实施例的原理图4。
具体实施方式
一致性哈希原理
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数h的值空间为0-(
整个哈希空间环如图1所示,整个空间按顺时针方向组织。0和(
下一步将各个服务器使用h进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希空间环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如图2所示。
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数h计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有a、b、c、d四个数据对象,经过哈希计算后,在环空间上的位置如图3所示:根据一致性哈希算法,数据a会被定为到server1上,d被定为到server3上,而b、c分别被定为到server2上。
虚拟节点原理
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“memcachedserver1#1”、“memcachedserver1#2”、“memcachedserver1#3”、“memcachedserver2#1”、“memcachedserver2#2”、“memcachedserver2#3”的哈希值,于是形成六个虚拟节点,如图4所示。
实施例1
为热点内容设置副本的方法,包括:
步骤1:大数据系统具有n个服务器,采用一致性哈希算法,将这n个服务器放置到哈希函数的值空间为0-(
步骤2:大数据系统开始运行后,监控器周期性监测各个服务器的负载参数,具体方式为:在时刻t服务器i的负载为
步骤3:计算t时刻服务器群的平均负载为:
步骤4:计算t时刻服务器群的负载方差为:
步骤6:从所有服务器中找到负载最大的服务器;
步骤7:从该负载最大的服务器上找到最近一段时间(例如是1天)内被访问次数最多的m个内容文件,例如可以预先将m设定为10;
步骤8:为这m个内容文件设置副本名称。优选的方式是在原始文件名后添加副本号,例如原始文件名为:filename,则副本名可以设置为filename#1。如果已经存在了一个副本,副本名为filename#1,后续还需要再增加副本时,可以将副本名设置为filename#2。
步骤9:计算副本名的哈希值,根据一致性哈希算法,将该副本存入相对应的服务器上。所有的副本信息都存放到一个负载服务器上,当用户需要访问某个文件内容时,先向负载服务器发送请求,负载服务器通过查询发现该内容没有设置副本,则直接根据现有的处理流程处理直接去访问原始内容,如果发现了存在副本,则从原始内容和副本内容中随机选择一个内容进行访问。从而实现了热门内容的多副本设置,降低单个服务器的访问压力。
步骤10:返回到步骤2。
为热点内容设置副本的方法,包括:
步骤1:所述大数据系统中具有n个服务器,采用一致性哈希算法,将这n个服务器放置到哈希函数的值空间为0-(
步骤2:大数据系统开始运行后,监控器周期性监测各个服务器的负载参数,具体方式为:在时刻t服务器i的负载为
步骤3:计算t时刻服务器群的平均负载为:
步骤4:计算t时刻服务器群的负载方差为:
步骤6:从所有服务器中找到负载最大的服务器;
步骤7:从该负载最大的服务器上找到最近一段时间(例如是1天)内被访问次数最多的m个内容文件,例如可以预先将m设定为10;
步骤8:为这m个内容文件设置副本名称。优选的方式是在原始文件名后添加副本号,例如原始文件名为:filename,则副本名可以设置为filename#1。如果已经存在了一个副本,副本名为filename#1,后续还需要再增加副本时,可以将副本名设置为filename#2。
步骤9:计算副本名的哈希值,根据一致性哈希算法,将该副本存入相对应的服务器上。所有的副本信息都存放到一个负载服务器上,当用户需要访问某个文件内容时,先向负载服务器发送请求,负载服务器通过查询发现该内容没有设置副本,则直接根据现有的处理流程处理直接去访问原始内容,如果发现了存在副本,则从原始内容和副本内容中随机选择一个内容进行访问。从而实现了热门内容的多副本设置,降低单个服务器的访问压力。
步骤10:返回到步骤2。
- 还没有人留言评论。精彩留言会获得点赞!