一种去中心化的参数服务器优化算法的制作方法
本发明涉及深度学习技术领域,更具体的说是涉及一种去中心化的参数服务器优化算法。
背景技术:
目前,分布式深度学习框架中常进行基于参数服务器的异步数据并行的模型训练,但是随着网络规模的不同和硬件带宽等限制,训练过程经常会出现更新停止和通信等待的问题,因为无论是单参数服务器还是分级参数服务器的设计,整个通信网络的通信量和利用梯度更新模型的计算量都集中在参数服务器节点上,通信量集中在通信网络中心、特定时期的计算量也集中在通信网络的中心,造成了参数服务器节点的通信阻塞,工作节点的计算停等,进一步造成了工作节点的cpu空载和带宽空载,降低了整个通信网络的训练效率。而随着网络规模和并行度的增加,硬件带宽若不能有同等比例的提升,则通信阻塞和cpu空载、带宽浪费的瓶颈还会进一步加重。
因此,如何避免分布式深度学习的模型训练中的通信阻塞和环节由于通信停等带来的cpu空载和带宽浪费是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种去中心化的参数服务器优化算法,区别于传统的中心化参数服务器算法,将传统中心化参数服务器算法的参数服务器的工作线程平均分配到每个工作节点中,根据每一个工作节点中分配的参数服务器的工作线程负责的部分模型设定的网络层,收集部分网络层的梯度,更新计算这一部分网络的参数,最后将每一个工作节点的参数进行汇总得到全局网络模型的更新后的参数,如此进行多次迭代后完成模型训练。
为了实现上述目的,本发明采用如下技术方案:
一种去中心化的参数服务器优化算法,包括如下具体步骤:
步骤1:将需要进行训练的数据集分割成n个块,将每个单独的所述块分配给一个特定的工作节点;
步骤2:每个所述工作节点从所分配到的块中采样模型训练数据用于训练所述工作节点的本地模型;
步骤3:将全局网络模型平均分成n个部分模型分配给每个所述工作节点,为每个所述工作节点分配一个参数服务器线程,所述参数服务器线程负责所述部分模型的维护和更新,每个所述工作节点根据所述参数服务器线程同时采用迭代法和随机梯度下降法进行所述工作节点参数更新计算;
其中所述工作节点参数更新的具体步骤如下:
步骤31:首先对所述本地工作节点进行初始化:设置网络参数初始值w;设置迭代次数k;设置初始学习率e和学习策略;设置所述参数服务器线程,即所述部分模型的网络层序号;所述本地工作节点根据模型定义文件生成初始所述本地模型;
步骤32:在所述本地工作节点的本地数据集中随机抽取用于迭代的数据;
步骤33:所述本地模型根据所述数据生成标签,所述本地工作节点根据所述数据采用前向传播进行标签预测得到预测结果,所述标签与所述预测结果进行比较获得误差,采用反向传播将误差进行回传得到所述本地工作节点梯度u;
步骤34:所述本地工作节点收集所述参数服务器线程负责的所述部分模型对应的所述梯度u并进行参数更新计算,得到更新参数,并将所述更新参数回传至收集的所述梯度u对应的所述工作节点中,所述本地工作节点得到本地更新参数;
步骤4:将所有所述工作节点中的所述本地更新参数整合成全局网络模型参数;
步骤5:判断是否完成k次迭代,如果否则再次进入步骤32,如果是则完成本地模型训练。
优选的,步骤34的具体计算过程如下:
步骤341:根据所述梯度和所述全局网络模型的对应关系将所述梯度u拆分成包括多个小节梯度u’的梯度数组;
步骤342:所述本地工作节点收集所述参数服务器线程负责的所述部分模型对应的不同所述工作节点的所述小节梯度u’,并根据wi+1=wi-e*u’计算出所述部分模型的更新参数wi+1,wi为本次迭代更新参数;
步骤343:根据收集的所述小节梯度u’,将所述更新参数wi+1传回至所述小节梯度u’对应的所述工作节点,所述本地工作节点将接收的所述更新参数wi+1拼接成本地更新参数。
优选的,根据整个网络的层数和每层数据量分配每个所述工作节点中的所述参数服务器线程负责汇总的层序号。
优选的,所述参数服务器线程持续监听并收集对应负责的所述部分网络层的梯度并进行更新参数计算,将所述更新参数回传至所述参数服务器线程对应的所述工作节点。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种去中心化的参数服务器优化算法,将传统的中心化参数服务器算法中的中心参数服务器去掉,将中心参数服务器的工作线程平均分配到每个工作节点中,利用迭代算法和下降梯度算法在每一个工作节点中根据参数服务器的工作线程更新计算部分网络的参数,并将更新的参数回传至参数更新计算中应用到的梯度对应的工作节点中,取出每个工作节点的参数进行汇总得到全局网络模型参数,如此进行多次迭代后得到训练模型。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
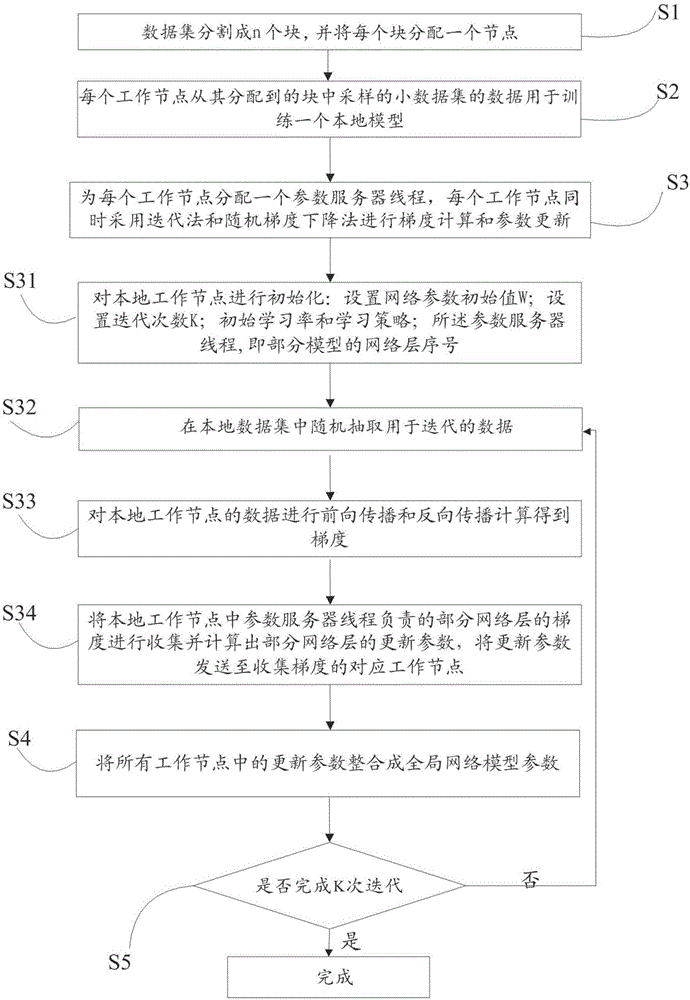
图1附图为本发明提供的一种去中心化的参数服务器优化算法流程结构示意图;
图2附图为本发明提供的工作节点通讯结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种去中心化的参数服务器优化算法,包括如下具体步骤:
s1:将需要进行训练的数据集分割成n个块,将每个单独的块分配给一个特定的工作节点;
s2:每个工作节点从所分配到的块中采样模型训练数据用于训练工作节点的本地模型;
s3:将全局网络模型平均分成n个部分模型分配给每个工作节点,为每个工作节点分配一个参数服务器线程,参数服务器线程负责部分模型的维护和更新,每个工作节点根据参数服务器线程同时采用迭代法和随机梯度下降法进行工作节点参数更新计算;
其中工作节点参数更新的具体步骤如下:
s31:首先对本地工作节点进行初始化:设置网络参数初始值w;设置迭代次数k;设置初始学习率e和学习策略;设置参数服务器线程,即部分模型的网络层序号;本地工作节点根据模型定义文件生成初始本地模型,各工作节点进行一次模型同步;
s32:在本地工作节点的本地数据集中随机抽取用于迭代的数据;
s33:本地模型根据数据生成标签,本地工作节点根据数据采用前向传播进行标签预测得到预测结果,标签与预测结果进行比较获得误差,采用反向传播将误差进行回传得到本地工作节点梯度u;
s34:本地工作节点收集参数服务器线程负责的部分模型对应的梯度u并进行参数更新计算,得到更新参数,并将更新参数回传至收集的梯度u对应的工作节点中,本地工作节点得到本地更新参数;
s4:将所有工作节点中的本地更新参数整合成全局网络模型参数;
s5:判断是否完成k次迭代,如果否则再次进入步骤32,如果是则完成本地模型训练。
为了进一步优化上述技术方案,s34的具体计算过程如下:
s341:根据梯度和全局网络模型的对应关系将梯度u拆分成包括多个小节梯度u’的梯度数组;
s342:本地工作节点收集参数服务器线程负责的部分模型对应的不同工作节点的小节梯度u’,并根据wi+1=wi-e*u’计算出部分模型的更新参数wi+1,wi为本次迭代更新参数;
s343:根据收集的小节梯度u’,将更新参数wi+1传回至小节梯度u’对应的工作节点,本地工作节点接收多个小节梯度对应的更新参数wi+1,本地工作节点将接收的多个更新参数wi+1拼接成本地更新参数。
为了进一步优化上述技术方案,本地工作节点根据模型定义文件生成初始本地模型,各工作节点进行一次模型同步,保证进行第一次迭代的最初的每个本地模型参数一致。
为了进一步优化上述技术方案,根据整个网络的层数和每层数据量分配每个工作节点中的参数服务器线程负责汇总的层序号。
为了进一步优化上述技术方案,参数服务器线程持续监听并收集对应负责的部分网络层的梯度并进行更新参数计算,将更新参数回传至参数服务器线程对应的工作节点,即部分模型计算所用小节梯度对应的工作节点,工作节点将回传的更新参数整合成最新的本地更新参数。
为了进一步优化上述技术方案,全局网络模型相当于一个长条数组,拆分成n等分的部分模型由不同的参数服务器线程负责,进行参数更新时,将工作节点的梯度拆分成n等分发给对应的部分模型进行参数更新计算,最后再将更新的参数回传给对应的工作节点,将所有工作节点的本地更新参数直接按照顺序拼接整合成全局网络模型参数。
为了进一步优化上述技术方案,完成k次迭代的最终输出结果是最新的网络更新参数以及全局网络模型最后的预测准确率。
实施例
基于分布式深度学习进行网络模型训练中经常采用传统的中心参数服务器算法,本发明是对传统的中心参数服务器算法的优化,将传统的中心参数服务器算法中的参数服务器去掉。全局网络模型训练在通信网络中进行,通信网络具有n个工作节点,进行深度学习训练的全局网络包括m层网络,将全局网络模型按照全局网络的层进行划分,将划分后的部分模型分配给每个工作节点,并通过参数服务器线程进行维护更新,将进行模型训练的数据集分割成n个块,每块数据单独分配给一个工作节点并进行本地模型训练,每个工作节点均采用梯度下降法进行迭代模型训练中的参数更新,迭代过程为首先初始定义网络参数初始值w、迭代次数k、初始学习率和学习策略和参数服务器线程负责的部分模型的网络层序号,工作节点根据模型定义文件生成初始本地模型,每个工作节点根据本地模型、参数,将本地工作节点中的随机选取的数据投喂给本地模型训练输入口,进行前向传播提取特征得到标签和预测结果,然后根据标签和预测结果计算误差,再进行反向传播计算出本地工作节点梯度,之后每个工作节点根据参数服务器工作线程负责的网络层序号收集相应工作节点的小节梯度利用随机梯度下降法更新参数,并将更新后的参数回传至收集的小节梯度相应的工作节点中,最后汇总每个工作节点更新之后的参数得到全局网络模型参数,如此进行k次迭代后得到训练模型。
本发明是基于异步数据并行,全局参数更新的计算,将参数服务器和工作节点进行角色统一,使工作节点具有参数服务器的部分计算功能,使得进行模型训练中的计算量和通信量均匀地分布到整个通信网络中,从而拥有异步并行的迭代速度的同时不会由于空间上的通信量集中而导致通信阻塞,而且,在同一个工作节点中,训练网络和实现参数服务器功能的线程共享cpu资源,因此极大地缓解了由于通信停等带来的cpu空载问题。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!