一种基于机器学习的WEB应用防火墙的实现方法与流程
本发明涉及web应用安全技术领域,特别是一种基于机器学习的web应用防火墙的实现方法。
背景技术:
web应用防火墙是信息安全的第一道防线。随着网络技术的快速更新,新的黑客技术也层出不穷,为传统规则防火墙带来了挑战。传统web入侵检测技术通过维护规则集对入侵访问进行拦截。一方面,硬规则在灵活的黑客面前,很容易被绕过,且基于以往知识的规则集难以应对0day攻击;另一方面,攻防对抗水涨船高,防守方规则的构造和维护门槛高、成本大。基于机器学习技术的新一代web入侵检测技术有望弥补传统规则集方法的不足,为web对抗的防守端带来新的发展和突破。机器学习方法能够基于大量数据进行自动化学习和训练,已经在图像、语音、自然语言处理等方面广泛应用。然而,机器学习应用于web入侵检测也存在挑战,其中最大的困难就是标签数据的缺乏。尽管有大量的正常访问流量数据,但web入侵样本稀少,且变化多样,对模型的学习和训练造成困难。
技术实现要素:
为解决现有技术中存在的问题,本发明的目的是提供一种基于机器学习的web应用防火墙的实现方法,本发明针对当前web防火墙规则集合建立的不足问题,采用了单分类的机器学习方法建立模型,动态更新规则库,使得web应用防火墙更加智能。
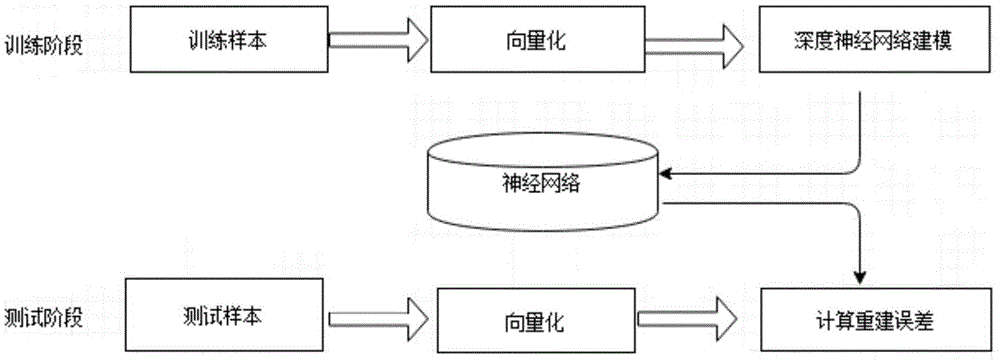
为实现上述目的,本发明采用的技术方案是:一种基于机器学习的web应用防火墙的实现方法,所述方法采用单分类模型建立规则的机器学习方法,构造能充分表达白样本的最小模型作为profile,从而实现异常检测,该方法包括训练阶段和测试阶段;其中,所述训练阶段用于建立单分类模型,具体包括以下步骤:
s1、通过n-gram模型将训练样本的文本数据向量化,得到文本数据训的向量集;
s2、降低向量集的维度,对n-gram的向量进行聚类,指定的类别数k即为约减后的特征维数,并将约减后的特征向量投入单分类svm模型中进行profile训练;
s3、采用深度学习中的深度自编码网络模型进行非线性特征约减,通过给定输入的重建误差,判断输入样本是否与profile相符;
所述的测试阶段,对测试样本向量化,再通过计算重建误差作为异常检测的标准。
作为一种优选的实施方式,所述步骤s1包括以下步骤:
s11、通过长度为n的滑动窗口算法将文本数据分割为n-gram序列;
s12、将n-gram序列转化成向量。
作为另一种优选的实施方式,所述步骤s12具体如下:
假设共有m种不同的字符,则会得到m*m种n-gram的组合,用一个m*m长的向量,每一位独热码表示文本数据中是否出现了该n-gram,其中有独热码则置1,没有则置0,从而可得到一个m*m长的0/1向量,对于每个出现的n-gram,用该n-gram在文本数据中出现的频率来代替单调的“1”,以表示更多的信息,则每个文本数据都可以通过一个m*m长的向量表示。
本发明的有益效果是:本发明在web应用防火墙基础上,采用了单分类建立模型的机器学习方法,使得web应用防火墙更加智能,更加准确的防御攻击,大大提升了用户体验;采用了单分类建立模型的机器学习方法,该模型更加准确高效,集成机器学习建立规则,不断更新规则集。
附图说明
图1为本发明实施例的流程示意图;
图2为本发明实施例将文本数据分割为n-gram序列的示意图;
图3为本发明实施例中文本数据通过向量表示的示意图;
图4为本发明实施例中降低向量集维度的示意图;
图5为本发明实施例中判断输入样本是否与profile相符的示意图;
图6为本发明实施例中测试阶段的示意图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例
目前大多数web入侵检测都是基于无监督的方法,针对大量正常日志建立模型(profile),而与正常流量不符的则被识别为异常。这个思路与拦截规则的构造恰恰相反。拦截规则意在识别入侵行为,因而需要在对抗中“随机应变”;而基于profile的方法旨在建模正常流量,在对抗中“以不变应万变”,且更难被绕过。本实施例提出一种智能的profile建立方法,异常检测的web入侵识别,训练阶段通常需要针对每个url,基于大量正常样本,抽象出能够描述样本集的统计学或机器学习模型(profile)。
如图1所示,一种基于机器学习的web应用防火墙的实现方法,所述方法采用单分类模型建立规则的机器学习方法,构造能充分表达白样本的最小模型作为profile,从而实现异常检测,该方法包括训练阶段和测试阶段;其中,所述训练阶段用于建立单分类模型,具体包括以下步骤:
s1、通过n-gram模型将训练样本的文本数据向量化,得到文本数据训的向量集;
s2、降低向量集的维度,对n-gram的向量进行聚类,指定的类别数k即为约减后的特征维数,并将约减后的特征向量投入单分类svm模型中进行profile训练;
s3、采用深度学习中的深度自编码网络模型进行非线性特征约减,通过给定输入的重建误差,判断输入样本是否与profile相符;
所述的测试阶段,对测试样本向量化,再通过计算重建误差作为异常检测的标准。
下面通过例子“http://abc.com/test?path=/category-0002.htm”对本实施了做详细说明:
通过n-gram模型将训练样本的文本数据向量化:
首先通过长度为n的滑动窗口算法将文本数据分割为n-gram序列,例子中,n取2,窗口滑动步长为1,可以得到如图2所示的n-gram序列。
下一步要把n-gram序列转化成向量。假设共有256种不同的字符,那么会得到256*256种2-gram的组合(如aa,ab,ac…)。可以用一个256*256长的向量,每一位独热码(one-hot)的表示(有则置1,没有则置0)文本数据中是否出现了该2-gram。由此得到一个256*256长的0/1向量。对于每个出现的2-gram,用这个2-gram在文本数据中出现的频率来替代单调的“1”,以表示更多的信息,则每个文本数据都可以通过一个m*m长的向量表示。
至此,如图3所示,每个文本数据都可以通过一个256*256长的向量表示。
得到了训练样本的256*256向量集,需要通过单分类svm去找到最小边界。然而问题在于,样本的维度太高,会对训练造成困难。还需要再解决一个问题:如何缩减特征维度。
如图4所示,左矩阵中黑色表示0,白色表示非零。矩阵的每一行,代表一个输入文本(sample)中具有哪些2-gram。如果换一个角度来看这个矩阵,则每一列代表一个2-gram有哪些sample中存在,由此,每个2-gram也能通过sample的向量表达。从这个角度可以获得2-gram的相关性。对于2-gram的向量进行聚类,指定的类别数k即为约减后的特征维数。约减后的特征向量,再投入单分类svm模型进行进一步模型训练。
本实施例中,如图5所示,深度自编码网络模型的训练过程本身就是学习训练样本的压缩表达,通过给定输入的重建误差,就可以判断输入样本是否与模型相符。
测试阶段,如图6所示,通过判断web访问是否与profile相符,来识别异常。由于web入侵黑样本稀少,传统监督学习方法难以训练。基于白样本的异常检测,通过非监督或单分类模型进行样本学习,构造能够充分表达白样本的最小模型作为profile,实现异常检测。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!