一种从网络报文中提取账号信息的方法与流程
本发明属于大数据技术领域,尤其涉及一种从网络报文中提取账号信息的方法。
背景技术:
随着深度报文解析技术的日益发展,人们对报文解析的程度也越来越深入。比如,从开始的在大量网络报文中识别各种应用,到现在需要在从各种具体的应用中,能够提取到用户所关注的各类信息,如账号信息、位置信息等等。目前人们对深度报文解析的实现方式,大多还是按照以下流程进行的:1)让客户列出具体的需要提取的信息;2)组织专门的报文分析工程师,按照客户指定的应用、指定的信息,在网络上抓取相关的报文分析;3)编码实现,按照分析出来的报文特征提取信息;4)不断完善不同版本、不同应用的各类信息。
当前的处理方式的缺点是:1)分析报文的人和编码实现的人可能不是同一个人,那么就需要分析报文和编码实现的人都要熟悉一遍特定报文的特征信息;2)客户需求只要有一点的变化,上述流程就需要重新做一遍,严重增加人力成本;3)随着应用类型的增加,还有需要提取的特征的种类的增加,网络分析设备的负载越来越重,因为按照当前大多数的处理方式,会在每一个报文上检查一遍所有的应用和特征,然后提取信息;4)提取到的信息的准确度无法衡量。
技术实现要素:
本发明的目的是提供一种从网络报文中提取账号信息的方法,解决了通过定制规则、解读规则、按照规则提取信息的方式,来实现各种应用信息的提取的技术问题。
为实现上述目的,本发明采用如下技术方案:
一种从网络报文中提取账号信息的方法,其特征在于:包括如下步骤:
步骤1:用户通过客户端输入网络报文,客户端将网络报文传送给中心服务器;
步骤2:中心服务器制定xml格式文件;xml格式文件包括六层:第一层设置应用的名称<name>;第二层设置应用对应的id号<id>和传输协议;第三层设置要提取的信息的类型;第四层设置提取信息的方式<type>;第五层包括<condition>节点和<get_data>节点,<condition>节点表示只有当报文信息满足了其中某个<type>下的任意一个<condition>节点后,才能在这个<type>中的<get_data>节点中提取信息;第六层设置<condition>节点的子规则和<get_data>节点的子规则,<condition>节点的子规则和<get_data>节点的子规则均由用户自定义设定;
步骤3:中心服务器将xml格式文件中的规则保存起来,xml格式文件中的每一层次的节点均对应设定一种结构体,在结构体中保存具体数据;
步骤4:中心服务器根据xml格式文件中的规则,采用链表和hash表管理结构体及其结构体内保存测数据,其包括以下步骤:
步骤s1:将所有的<type>节点对应的结构体,用链表链接起来;
步骤s2:将所有的含有子规则的<condition>节点对应的结构体用hash表链接起来;
步骤s3:将所有的<get_data>节点对应的结构体用hash表链接起来;
步骤5:中心服务器接收到网络报文后,按照xml格式文件中第六层设置的<condition>节点的子规则,从网络报文中获取条件信息;
步骤6:匹配xml格式文件中<condition>节点下的非字符匹配条件,如果匹配成功,将相应的bitmap位置位;
步骤7:匹配xml格式文件中<condition>节点下的字符匹配条件,如果匹配成功,将相应的bitmap位置位;
步骤8:检查每个<type>节点中的<condition>节点的匹配情况,只要有某个<condition>节点的所有子规则被都满足,就将该<condition>节点所在的<type>节点设置为matched状态;
步骤9:在matched状态的<type>节点中,根据该<type>节点下所有<get_data>节点的子规则,逐个提取所有账号信息;
步骤10:中心服务器将步骤9提取的账号信息返回给客户端,供客户查看。
优选的,在执行步骤6时,包括如下步骤:
步骤a1:在网络报文中提取非字符匹配项;
步骤a2:遍历所有<type>节点下的所有<condition>节点,获取每个<condition>节点下的非字符子规则,并与步骤a1中提取到的非字符匹配项比较,对于匹配成功的子规则,将该子规则所在的<condition>节点中对应的bitmap位置位。
步骤a3:检查步骤a2中获得的bitmap值与<condition>中预先设定的标示<condition>节点中所有匹配项的bitmap值的关系,如果相等则将该<condition>节点所在的<type>节点设置为matched状态。
优选的,在执行步骤7时,包括如下步骤:
步骤b1:在网络报文中提取字符匹配项;
步骤b2:利用ac算法匹配所述字符匹配项,获取匹配到的字符;
步骤b3:遍历所有<type>节点下的,所有非match状态的<condition>节点,获取该<condition>节点中的字符子规则,与步骤b2中得到的字符比较,如果匹配成功,将该子规则所在的<condition>节点中对应的bitmap位置位。
步骤b4:检查b3中获得的bitmap值与<condition>中预先设定的标示<condition>节点中所有匹配项的bitmap值(即流程图3中的thread_bit_map)的关系,如果相等则将该<condition>节点所在的<type>节点设置为matched状态。
优选的,在执行步骤9时,<get_data>节点的子规则包括按照偏移量来获取信息和按照关键字来获取信息;
按照偏移量来获取信息的具体步骤如下:
步骤c1:判断当<type>节点的链表不为空,并且<type>节点为matched状态时,逐一获取该<type>节点的<get_data>节点的数据;
步骤c2:将<get_data>节点的数据与<get_data>节点的子规则进行匹配,提取匹配正确的<get_data>节点的提取信息;
按照关键字来获取信息的具体步骤如下:
步骤c3:获取所有<get_data>节点中的字符匹配项;
步骤c4:用ac算法匹配字符匹配项,获取匹配正确的字符匹配项;
步骤c5:判断当<type>节点的链表不为空,并且<type>节点为matched状态时,获取该<type>节点下<get_data>中的关键字,将该关键字与步骤c4中获得字符信息做比较,对于匹配成功的关键字,则按照该关键字对应的规则提取账号信息。
本发明所述的一种从网络报文中提取账号信息的方法,解决了通过定制规则、解读规则、按照规则提取信息的方式,来实现各种应用信息的提取的技术问题,本发明可以有效的使报文分析人员的工作(编写规则)与信息提取人员的工作(解读规则)解耦合,更好的适配用户需求的变更,使提取账号信息装置的修改达到最小化,通过在提取信息前预先标记是否要从该节点中匹配信息的方式,减少了报文查找、匹配次数,有效提高了装置性能。
附图说明
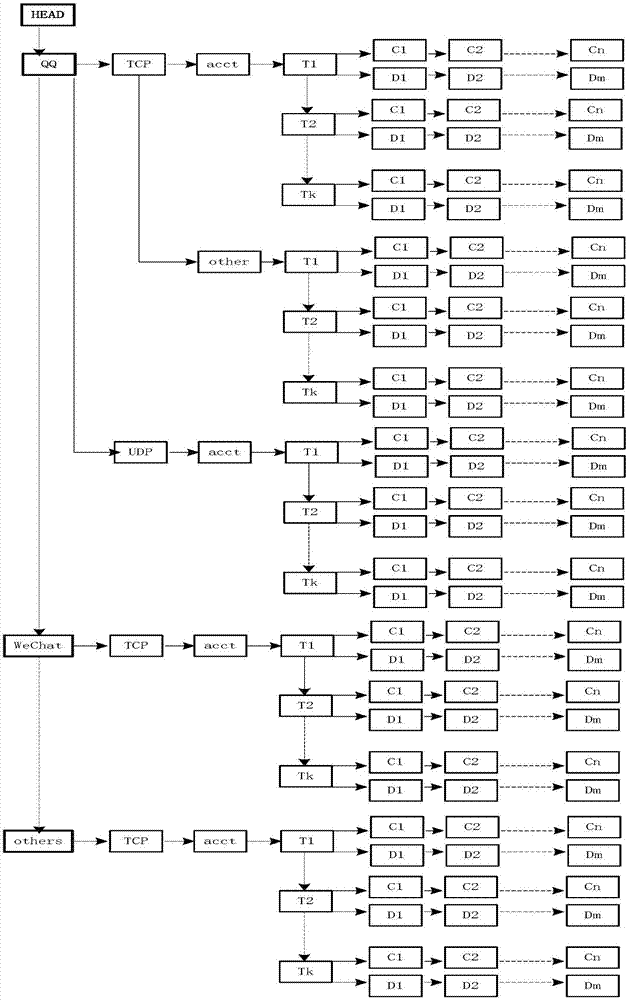
图1为本发明的xml文件存储结构;
图2为本发明的condition匹配条件中非字符类型匹配流程;
图3为本发明的condition匹配条件中字符类型匹配流程;
图4为本发明的get_data中按照偏移量类获得信息的流程;
图5为本发明的get_data中按照关键字来获取信息的流程。
具体实施方式
由图1-图5所示的一种从网络报文中提取账号信息的方法,包括如下步骤:
步骤1:用户通过客户端输入网络报文,客户端将网络报文传送给中心服务器;
步骤2:中心服务器制定xml格式文件;xml格式文件包括六层:第一层设置应用的名称<name>,如<qq></qq>表示应用名称为“qq”;
第二层设置应用对应的id号<id>和传输协议,如<id>1</id>表示应用的id为1,<tcp></tcp>表示传输层协议为tcp;
第三层设置要提取的信息的类型,如<account></account>表示要提取的信息类型为账号;
第四层设置提取信息的方式<type>,提取信息的方式<type></type>,方式可以有很多个,<typevalue="1">表示第一种提取方式,<typevalue="2">表示第二种提取方式,本实施例提取信息的方式为按照偏移量来获取信息和按照关键字来获取信息;
第五层包括<condition>节点和<get_data>节点,<condition>节点表示只有当报文信息满足了其中某个<type>下的任意一个<condition>节点后,才能在这个<type>中的<get_data>节点中提取信息;
第六层设置<condition>节点的子规则和<get_data>节点的子规则,<condition>节点的子规则和<get_data>节点的子规则均由用户自定义设定;
步骤3:中心服务器将xml格式文件中的规则保存起来,xml格式文件中的每一层次的节点均对应设定一种结构体,在结构体中保存具体数据;
步骤4:中心服务器根据xml格式文件中的规则,采用链表和hash表管理结构体及其结构体内保存测数据,其包括以下步骤:
步骤s1:将所有的<type>节点对应的结构体,用链表链接起来;
步骤s2:将所有的含有子规则的<condition>节点对应的结构体用hash表链接起来;
步骤s3:将所有的<get_data>节点对应的结构体用hash表链接起来;
步骤5:中心服务器接收到网络报文后,按照xml格式文件中第六层设置的<condition>节点的子规则,从网络报文中获取条件信息;
步骤6:匹配xml格式文件中<condition>节点下的非字符匹配条件,如果匹配成功,将相应的bitmap位置位;
步骤7:匹配xml格式文件中<condition>节点下的字符匹配条件,如果匹配成功,将相应的bitmap位置位;
步骤8:检查每个<type>节点中的<condition>节点的匹配情况,只要有某个<condition>节点的所有子规则被都满足,就将该<condition>节点所在的<type>节点设置为matched状态;
步骤9:在matched状态的<type>节点中,根据该<type>节点对应的<get_data>节点的子规则提取账号信息;
步骤10:中心服务器将步骤10提取的账号信息返回给客户端,供客户查看。
优选的,在执行步骤6时,包括如下步骤:
步骤a1:在网络报文中提取非字符匹配项;
步骤a2:遍历所有<type>节点下的所有<condition>节点,获取每个<condition>节点下的非字符子规则,并与步骤a1中提取到的非字符匹配项比较,对于匹配成功的子规则,将该子规则所在的<condition>节点中对应的bitmap位置位。
步骤a3:检查步骤a2中获得的bitmap值与<condition>中预先设定的标示<condition>节点中所有匹配项的bitmap值的关系,如果相等则将该<condition>节点所在的<type>节点设置为matched状态。
优选的,在执行步骤7时,包括如下步骤:
步骤b1:在网络报文中提取字符匹配项;
步骤b2:利用ac算法匹配所述字符匹配项,获取匹配到的字符;
步骤b3:遍历所有<type>节点下的,所有非match状态的<condition>节点,获取该<condition>节点中的字符子规则,与步骤b2中得到的字符比较,如果匹配成功,将该子规则所在的<condition>节点中对应的bitmap位置位。
步骤b4:检查b3中获得的bitmap值与<condition>中预先设定的标示<condition>节点中所有匹配项的bitmap值的关系,如果相等则将该<condition>节点所在的<type>节点设置为matched状态。
优选的,在执行步骤9时,<get_data>节点的子规则包括按照偏移量来获取信息和按照关键字来获取信息;
按照偏移量来获取信息的具体步骤如下:
步骤c1:判断当<type>节点的链表不为空,并且<type>节点为matched状态时,逐一获取该<type>节点的<get_data>节点的数据;
步骤c2:将<get_data>节点的数据与<get_data>节点的子规则进行匹配,提取匹配正确的<get_data>节点的提取信息;
按照关键字来获取信息的具体步骤如下:
步骤c3:获取所有<get_data>节点中的字符匹配项;
步骤c4:用ac算法匹配字符匹配项,获取匹配正确的字符匹配项;
步骤c5:判断当<type>节点的链表不为空,并且<type>节点为matched状态时,获取该<type>节点下<get_data>中的关键字,将该关键字与步骤c4中获得字符信息做比较,对于匹配成功的关键字,则按照该关键字对应的规则提取账号信息。
如图3所示为xml文件存储结构,其中在map中,qq、wechat、others均为第一层设置应用的名称<name>,tcp为传输协议,acct为要提取的信息的类型,t1、t2和tk为<type>节点,c1-cn为<condition>节点的子规则,d1-dn为<get_data>节点的子规则。
以提取应用的名称为<wechat>的账号信息为例:
首先根据步骤2的方法编写和制定<wechat>的xml格式文件,然后,根据步骤3和步骤4的方法,中心服务器读取xml格式文件并保存,中心服务器根据xml格式文件建立存储结构及其对应的map,再然后,中心服务器获取获取网络报文后,按照步骤6和步骤7的方法分别匹配非字符匹配条件和字符匹配条件,在然后,检查每个<type>节点中的<condition>节点的匹配情况,只要有某个<condition>节点的所有子规则被都满足,就将该<condition>节点所在的<type>节点设置为matched状态,再然后,根据步骤9的方法按照偏移量来获取信息或按照关键字来获取信息从<get_data>节点提取信息。
本发明所述的一种从网络报文中提取账号信息的方法,解决了通过定制规则、解读规则、按照规则提取信息的方式,来实现各种应用信息的提取的技术问题,本发明可以有效的使报文分析人员的工作(编写规则)与信息提取人员的工作(解读规则)解耦合,更好的适配用户需求的变更,使提取账号信息装置的修改达到最小化,通过在提取信息前预先标记是否要从该节点中匹配信息的方式,减少了报文查找、匹配次数,有效提高了装置性能。
- 还没有人留言评论。精彩留言会获得点赞!