全链路跟踪系统的制作方法
本发明涉及链路跟踪领域,特别涉及全链路跟踪系统。
背景技术:
目前随着计算机技术、网络技术的创新进步,特别是虚拟化技术的进步,还有新概念、新方案的创新和发展,尤其是微服务架构技术的发展,改变了传统的软件开发与运维模式。
微服务架构解决了传统的分层架构中的一些问题,它的核心特点是高可伸缩性、易于开发、测试和部署独立的服务组件,这些服务组件解耦的、分布式的、相互独立的,可以快速的迭代更新应用平台上的微服务,教育云平台就是这样一种微服务架构。在此基础上,以往对单台服务器的监控模式,需要转变为基于成百上千个实例之间相互调用的监控模式。
技术实现要素:
本发明实施例提供了全链路跟踪系统。为了对披露的实施例的一些方面有一个基本的理解,下面给出了简单的概括。该概括部分不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围。其唯一目的是用简单的形式呈现一些概念,以此作为后面的详细说明的序言。
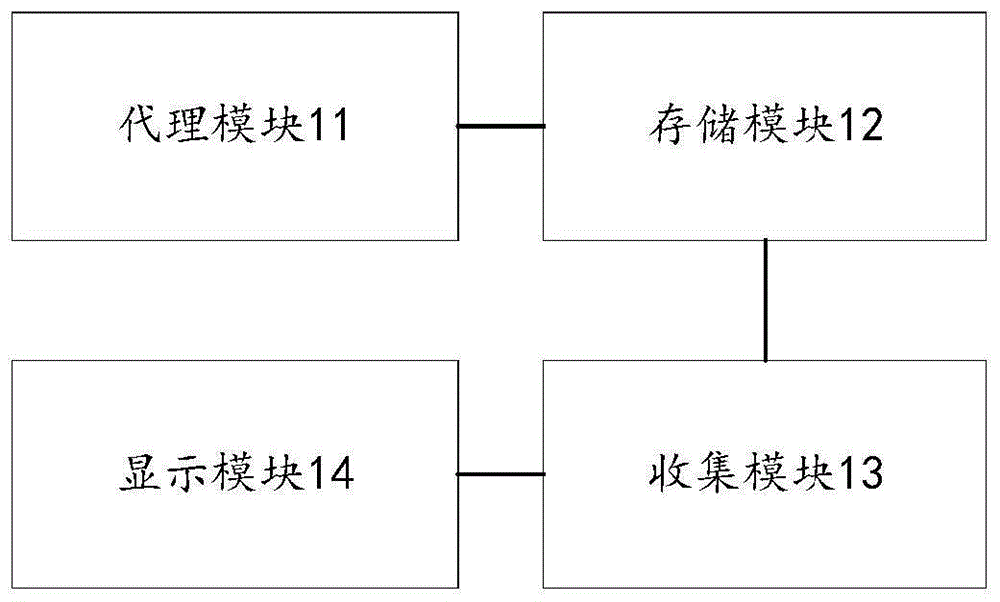
本发明实施例提供了一种全链路跟踪系统,所述系统部署于教育云平台上,所述系统包括:
代理模块,用于收集各服务的链路调用数据;
存储模块,用于存储所述数据;
收集模块,用于通过业务分析调用所述数据,得出跟踪结果;
显示模块,用于显示所述跟踪结果。
基于所述系统,作为可选的第一实施例,所述存储模块,包括:
以elasticsearch、h2、及由shardingshpere项目管理的mysql关系数据库集群;
所述elasticsearch用于在常规模式下进行存储;
所述h2用于预览版本。
基于所述系统,作为可选的第二实施例,所述收集模块以群集模式运行。
基于所述第二实施例,作为可选的第三实施例,所述收集模块配置有zookeeper,用于协调所述群集模式的运行。
基于所述系统,作为可选的第四实施例,所述收集模块与所述代理模块,采用超文本传输协议http和远程过程调用grpc连接。
基于所述系统,作为可选的第五实施例,所述数据具有失效时间,当到达所述失效时间时,所述存储模块删除所述数据。
基于所述系统,作为可选的第六实施例,所述收集模块,还用于在所述跟踪结果满足预警条件时,输出预警消息。
本发明实施例中的全链路跟踪系统,可以在分布式环境下,跨线程和进程收集链路调用数据,实现全链路跟踪。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是一示例性实施例示出的全链路跟踪系统的框图;
图2是一示例性实施例示出的全链路跟踪系统的架构图。
具体实施方式
以下描述和附图充分地示出本发明的具体实施方案,以使本领域的技术人员能够实践它们。实施例仅代表可能的变化。除非明确要求,否则单独的部件和功能是可选的,并且操作的顺序可以变化。一些实施方案的部分和特征可以被包括在或替换其他实施方案的部分和特征。本发明的实施方案的范围包括权利要求书的整个范围,以及权利要求书的所有可获得的等同物。在本文中,各实施方案可以被单独地或总地用术语“发明”来表示,这仅仅是为了方便,并且如果事实上公开了超过一个的发明,不是要自动地限制该应用的范围为任何单个发明或发明构思。本文中,诸如第一和第二等之类的关系术语仅仅用于将一个实体或者操作与另一个实体或操作区分开来,而不要求或者暗示这些实体或操作之间存在任何实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素。本文中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
在一示例性实施例中,如图1所示,全链路跟踪系统部署于教育云平台上,包括:代理模块11、存储模块12、收集模块13和显示模块14。
代理模块11,用于收集各服务的链路调用数据。
存储模块12,用于存储所述数据。
收集模块13,用于通过业务分析调用所述数据,得出跟踪结果。
显示模块14,用于显示所述跟踪结果。
本示例性实施例中的全链路跟踪系统,可以在分布式环境下,跨线程和进程收集链路调用数据,实现全链路跟踪。
在一示例性实施例中,全链路跟踪系统包括:代理模块11、存储模块12、收集模块13和显示模块14。这些模块的功能与前文示例性实施例中所述的相同,这里不再赘述,本示例性实施例仅对这些模块的可选实施方式进行详细介绍。
图2为本示例性实施例中全链路跟踪系统的架构图。
本示例性实施例中的全链路跟踪系统具有以下特点:
1.模块化设计。
系统中的各模块分别定义了各自的特性,这些完全由模块定义及其模块实现来决定。
每个模块都可以在java接口中定义它们的服务,每个模块的提供者都必须为这些服务提供实现者。提供者应该基于自己的实现定义依赖模块。
这些模块的配置在application.yml中是分离的。
2.多种连接方式。
收集模块13可以以群集模块运行。收集模块13提供两种类型的连接,即超文本传输协议(http)和远程过程调用(gprc)。
http中的命名服务,群集中的所有可用的收集器(collector)的地址。
在gprc和http中使用上行链路服务,它将跟踪和度量数据上传到collector。每个代理模块12将只向单个collector发送服务的链路调用数据。如果代理模块12与连接的collector在某个时刻断开连接,将会尝试连接其它的collector。
3.集群服务发现机制。
当collector以群集模式运行时,配置使用zookeeper进行协调,并作为实例发现的注册中心。
4.流模式。
流模式类似轻量级storm/spark的实现,它允许使用api构建流处理图(dag)以及每个节点的输入/输出数据协定。
5.可切换的存储模块。
由于流模式负责并发,因此存储模块12的实现的职责是提供高速写入和组合查询。
本示例性实施例中,存储模块12包括以elasticsearch、h2、及由shardingshpere项目管理的mysql关系数据库集群,其中elasticsearch作为主要实现模块,h2用于预览版本,以及由shardingshpere项目管理的mysql关系数据库集群。
6.具有时效的数据
本示例性实施例中,存储模块12中的数据具有失效时间,当达到失效时间时,存储模块12将删除这些数据。
7.预警机制
收集模块13在跟踪结果满足预警条件时,输出预警消息。预警条件可以灵活设置。
本示例性实施例中的全链路跟踪系统具有如下优点:在分布式环境/微服务环境下,跨线程/进程收集链路调用信息以及指标;自动感知链路拓扑;应用、实例、服务性能指标分析;应用和服务依赖分析;慢服务监测;预警及报警。易于维护、可控和流式处理。
下面给出一些全链路跟踪系统的应用实例。
一、部署探针:
1.拷贝agent目录到所需位置.日志,插件和配置都包含在包中,请不要改变目录结构.
2.增加jvm启动参数,-javaagent:/path/to/skywalking-agent/skywalking-agent.jar.参数值为skywalking-agent.jar的绝对路径。
二、配置collector
三、启动collector节点
1.使用bin/startup.sh同时启动collector和ui,若不使用1启动,需要单独启动,参考2,3
2.单独启动collector,运行bin/collectorservice.sh
3.单独启动ui,运行bin/webappservice.sh
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的流程及结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!