一种基于布谷鸟搜索的storm动态负载均衡方法与流程
本发明属于大数据实时处理领域,具体涉及一种基于布谷鸟搜索算法的storm动态负载均衡方法。
背景技术:
随着物联网和社交网络的快速发展,流数据的规模不断增长,流处理在交通监测、气象观测和银行交易管理等领域都有着广泛的应用。以无人机货运实时流数据为例,其产生的流数据具有到达速度快、到达时间持续和动态改变等特点,传统地大数据批处理框架已无法满足实时性的需求。storm分布式实时计算系统作为流式计算的典型代表以其低延迟、高性能、分布式、可扩展、高容错等特性,在海量数据实时处理中得到广泛应用。
在数据处理对实时性和高效性要求越来越高的情况下,集群中节点的管理与资源的分配在集群管理中占据着越来越重要的地位,负载均衡技术是保证storm实时计算应用高性能和高吞吐量的有效手段。storm实时计算应用通常是计算密集型应用,负载均衡对storm实时计算应用的执行性能起着决定性的作用。
然而storm默认调度在负载均衡方面的表现却无法令人满意,存在着较多的问题,致使一些对于实时性和高效性要求高的系统无法及时的处理数据。第一,storm平台采用默认的任务调度采用的是轮询调度(roundrobinscheduling)算法,即将用户提交的拓扑中包含的任务均匀分配到各工作进程中,再将各工作进程均匀分配到各工作节点上,由于其未考虑到不同节点的性能和负载差异,致使节点资源利用率不高。第二,storm集群中节点会经常动态的增加或删除,worker进程也会动态的增加或删除,从而导致集群计算资源的变化,而在集群节点或进程动态增删后,storm无法根据改变后的可用资源做出有效调整策略,影响负载的均衡。第三,默认调度对于节点资源更关注cpu资源,而忽略内存、磁盘、网络等其他类型的资源,如此可能会造成工作节点内存不足、网络堵塞等问题。综上所述,为满足实时性和高效性更高系统的需求,需要提出一种新的方法来保证storm调度的负载均衡,新的方法可以使得集群的响应时间更快、吞吐量更高、系统延迟更低。
技术实现要素:
发明目的:为解决上述技术问题,为下一步流数据的实时存储打好基础,本发明提供了一种基于布谷鸟搜索算法的storm动态负载均衡方法。
技术方案:
本发明是一种基于布谷鸟搜索算法的storm集群动态负载均衡方法,该方法包括如下步骤:
步骤一:获取集群节点负载信息,包括节点性能向量以及节点上任务的完成率,初始化相关参数,包括宿主鸟巢的数目即需要分配的任务数量,鸟蛋被发现的概率即迭代产生解的淘汰概率,全局最大迭代次数,步长初值,适应度阈值;
步骤二:判断是否达到迭代停止条件,即达到最大迭代次数max或适应度阈值大于步骤一中设定的阈值,若达到停止条件则停止迭代,否则继续;
步骤三:通过节点性能向量和性能权重向量α计算集群节点的负载向量,计算节点上任务的分配权重和适应度函数值;
步骤四:判断本次迭代适应度函数值是否更优,即函数值值更小,若更优则进行下一步,否则保留上次求得的节点性能权重向量;
步骤五:根据当前节点性能权重向量与初始距离的平均值与步长初值的乘积计算布谷鸟搜索算法的步长因子,根据节点性能权重向量更新公式计算新的节点性能权重向量;
步骤六:随机产生一个数k(0<k<1),判断随机数k是否大于步骤一中设定的淘汰概率,若大于则随机更新解,否则保持原解不变;
步骤七:根据迭代最后一轮求得的性能向量的权重的值,计算节点负载向量,节点负载向量计算方法与第三步中相同;
步骤八:根据最新的节点负载计算节点上任务的分配权重,通过选择函数,根据计算得到的分配权重分配任务。
进一步地,步骤三中计算集群第i个节点的负载向量li方法为:
其中,i=1,2,…,m;j=1,2,…,n;n为任务个数,m为节点个数;k=1,2,3,4,表示要监测使用率的资源的编号,分别代表cpu资源、内存、磁盘、网络带宽,u为集群节点的性能向量,u=[u1,u2,u3…um],集群中某个节点的性能向量即u的分向量ui,有
进一步地,步骤三中计算节点上任务的分配权重wi为:
其中wi为分配权重w=[w1,w2,w3…,wm]的分向量。
进一步地,步骤三中适应度函数值计算方法包括如下步骤:
3a)根据任务分配权重w拟分配任务到节点上,并得出理论完成时间
其中,
3b)计算适应度函数值:
其中
进一步地,步骤五中步长因子a的计算方法为:
其中,a0为步长因子的初值,
进一步地,步骤五中节点性能权重向量更新公式:
其中,a为更改后的步长因子,
进一步地,步骤八中分配任务的步骤包括:
8a)计算判断向量thrval以计算选择函数值,单个节点su的判断分向量计算方法为:
thrvalsu=wsu×restol-∑w×hissu
其中,restol表示当前积累的总负载请求,hissu表示负载分配历史向量的一个分量,也就是单个节点su的负载分配历史,wsu表示单个节点su的任务分配权重,∑w为所有节点任务分配权重向量之和;
8b)根据选择函数选择合适的节点δ来处理当前任务:
{δ=sel(t,h,w)|thrvalδ=max(thrval)}
其中,sel(t,h,w)为选择函数,t={t1,t2,…tn}表示n个任务集,h为负载分配历史向量,w为节点任务分配权重向量
有益效果:本发明综合考虑集群节点的cpu、内存、网络带宽、磁盘io等资源利用情况,避免了默认调度更关注cpu资源而可能造成内存不足、网络堵塞等问题的局限性。同时,本发明实时监测集群运转情况,根据实时监测到的节点负载数据计算集群节点性能的权值,完成资源的动态分配,达到节点负载的均衡并使得集群的响应时间更快、吞吐量更高、系统延迟更低。
附图说明
图1为动态负载均衡模型图。
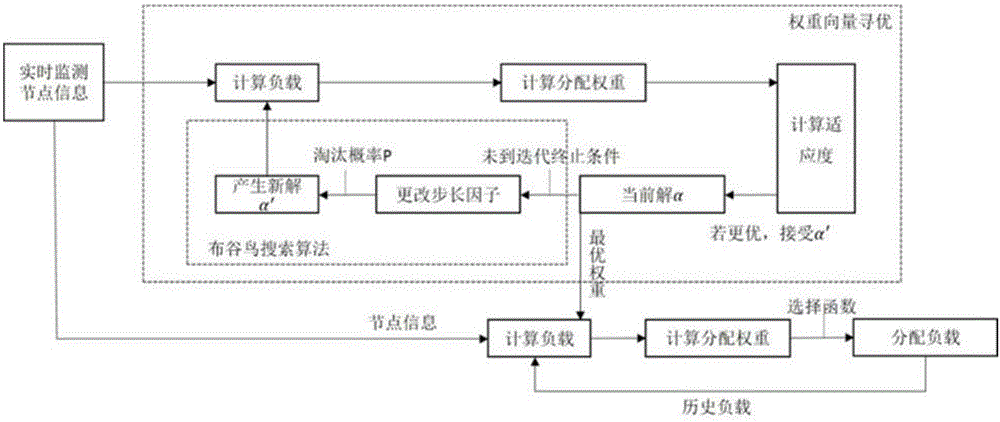
图2为本发明基于布谷鸟搜索算法的storm动态负载均衡方法的控制流程图。
具体实施方式
下面结合附图对本发明做更进一步的解释。
本发明环境为5台物理机器组成的storm完全分布式集群,每个节点的具体硬件配置如表1所示。
表1
每个节点运行ubuntu12.04操作系统。其中一个作为主节点运行nimbus进程,负责资源分配和任务调度;从节点负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。同时还搭建了zookeeper集群,它们始终处于运行状态。过程中使用ganglia来监控storm集群的各节点状态。
strom动态负载均衡的模型为:
strom中任务分配过程可描述为将一个topology中的n个tasks分配到m个supervisors工作节点上执行的过程,
t={t1,t2,…tn}表示n个任务集,其中ti(i=1,2,…,n)表示第i个task;
s={s1,s2,…sm}表示m个supervisor节点集,其中sj(j=1,2,…,m)表示第j个节点;
l=[l1,l2,…lm]表示m个节点的动态负载向量;
u=[u1,u2,u3…um]和α=[α1,α2,α3,…αn]分别表示节点性能向量和性能的权重向量。
根据性能向量和性能权重向量可以计算出节点的负载的值,之后根据节点负载的值可以计算得到节点上任务的分配权重,最后通过选择函数有效地按照计算出的分配权重向量向节点分配任务,实现任务的动态分配。
其中性能权重的计算是一个动态的过程,通过布谷鸟搜索算法的寻优过程在逐步迭代中寻找出最优的性能权重,该权重可以使得集群的平均响应时间最低。具体模型表现为图1所示。
如图2所示,本发明是一种基于布谷鸟搜索算法的storm动态负载均衡方法,该方法具体包括以下步骤:
第一步:获取集群节点负载信息,包括节点性能向量以及节点上任务的完成率,初始化相关参数,确定宿主鸟巢的数目为任务数量n,发现概率鸟蛋的概率p=0.75,设定全局最大迭代次数max=220,步长初值a0=0.1,适应度阈值val=103。
第二步:判断是否达到算法迭代停止条件,即达到最大迭代次数max或适应度阈值大于步骤一中设定的阈值val,若达到停止条件则停止迭代,否则继续进行迭代;
第三步:通过节点性能向量和性能权重向量α计算集群节点的负载向量,计算节点上任务的分配权重和适应度函数值;
第i个节点的负载li计算公式如下,
其中,i=1,2,…,m;j=1,2,…,n;n为任务个数,m为节点个数;k=1,2,3,4,表示要监测使用率的资源的编号,分别代表cpu资源、内存、磁盘、网络带宽,u为集群节点的性能向量,u=[u1,u2,u3…um],集群中某个节点的性能向量即u的分向量ui,有
分配权重w计算公式如下;
其中wi为分配权重w=[w1,w2,w3…,wm]的分向量。
适应度函数值
a)根据任务分配权重w拟分配任务到节点上,可以得出理论完成时间
其中,
b)计算适应度函数值:
其中
第四步:判断本次迭代适应度函数值是否更优,即将本次适应度函数值与上次迭代的中求得的函数值进行比较,若本次函数值更小则进行下一步骤,否则保留上次迭代的求得的节点性能权重向量。
第五步:根据当前节点性能权重向量α与初始距离的平均值与步长初值的乘积计算布谷鸟搜索算法的步长因子,根据节点性能权重向量更新公式计算新的节点性能权重向量,
步长因子计算公式如下,
其中,a0为步长因子的初值,
新的节点性能权重向量
其中,a为更改后的步长因子;
第六步:随机产生一个数k(0<k<1),判断随机数k是否大于淘汰概率p,若大于则说明在布谷鸟搜索算法中当前的鸟蛋容易被发现,即当前的解不够优,因此需要再次随机更新节点性能权重向量,否则保持原节点性能权重向量不变;
第七步:迭代完成后根据权重最优解计算节点负载l,节点负载计算方法与第三步中相同,步骤三中是负载向量的拟分配,本次求解是根据算法迭代求得的性能权重最优解计算集群节点真实的负载
第八步:根据最新的节点负载l计算节点上任务的分配权重w,方法与第三步中相同,步骤三中是分配权重的拟分配,本次求解是根据集群节点真实的负载来计算节点上任务的分配权重)
通过选择函数,根据计算得到的分配权重分配任务,具体步骤为:
a)计算判断向量thrval以描述选择函数,单个节点的判断分向量计算方法为:
thrvalsu=wsu×restol-∑w×hissu
其中,restol表示当前积累的总负载请求,hissu表示负载分配历史向量的一个分量,也就是某个单个节点的负载分配历史,wsu表示单个节点su的任务分配权重,∑w为所有节点任务分配权重向量之和。
b)根据选择函数选择合适的节点δ来处理当前任务:
{δ=sel(t,h,w)|thrvalδ=max(thrval)}
其中,sel(t,h,w)为选择函数,t={t1,t2,…tn}表示n个任务集,h为负载分配历史向量,w为节点任务分配权重向量。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!