用于传输沉浸式视频的方法与流程
本发明涉及一种用于向多个用户传输沉浸式视频的方法以及实施所述方法的系统和装置。
在过去几年中,出现了多种图像和视频观看模式。因此,尽管直到2000年仅有二维(2d)图像,但是已经出现了描绘以多个视角(例如,以360度)拍摄的同一场景的立体视频、三维(3d)视频和沉浸式视频。
目前,用于广播沉浸式视频的系统不再需要使用专用房间,所述专用房间包括360度屏幕和多个图像投影装置,每个图像投影装置可投影沉浸式视频的一个视角。事实上,现在可以获得一种使用眼镜(被称为沉浸式眼镜或沉浸式3d眼镜)广播沉浸式视频的系统,所述系统包括集成图像显示装置。
这种更简单的使用方法使得能够设想用于广播沉浸式视频的系统将在每个人的使用范围内。因此,在未来,用户将能够在其家中显示沉浸式视频。这些沉浸式视频将例如由运营商提供,并且通过通信网络(如互联网等)进行传输,就像当前通过互联网广播2d视频所发生的一样。
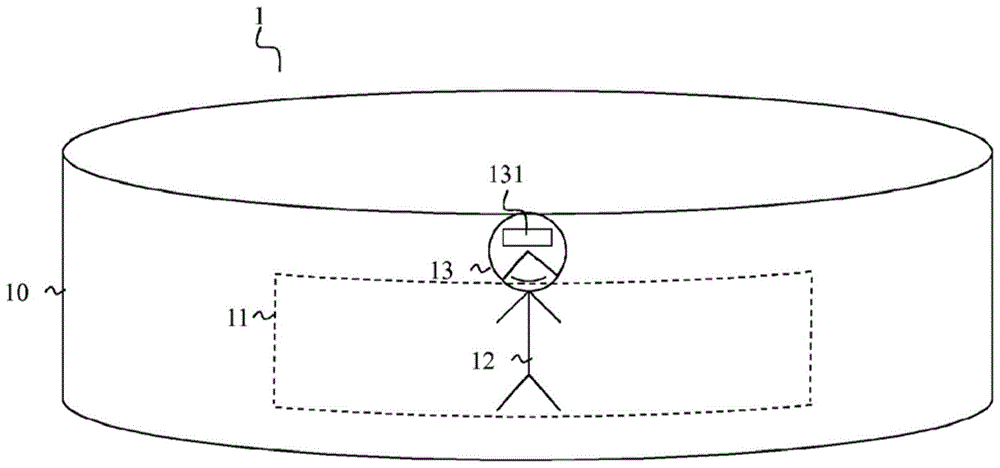
图1示意性地示出了用于广播沉浸式视频的系统1的实例。在此系统中,用户12佩戴一副沉浸式眼镜13。此副沉浸式眼镜13包括处理模块131和图像观看模块(未示出)。图像观看模块包括例如面对用户12的每只眼睛的屏幕。图像观看模块使用户能够观看由图1中的环10所表示的360度视频。在此系统中,沉浸式视频已经通过通信网络由服务器的处理模块131接收,并且然后在将其显示在图像观看模块上之前由处理模块131解码。
在显示期间,用于广播沉浸式视频的系统1限定了沉浸式视频所应用的简单几何形状(此处是环形,但其它形状也是可能的,如球体、圆顶或立方体)。然而,用户12仅看到受其视野限制的沉浸式视频的一部分。因此,在图1中,用户12仅看到面对其的沉浸式视频的空间子部分11。只有当用户12改变视频上的视角时,才使用沉浸式视频的其余部分。
除了向用户提供比常规高清(hd:1920×1080个像素)视频更宽广的视角之外,沉浸式视频通常具有明显优于常规hd视频的空间分辨率和时间分辨率。此类特性涉及非常高的比特率,所述比特率对于网络来说可能难以支持。
在一些沉浸式视频广播系统中,用户以全空间和时间分辨率接收沉浸式视频。因此,通信网络必须支持相对高的比特率。由于多个用户可以同时接收相同的沉浸式视频,因此此比特率整体较大。为了克服比特率的这一问题,在其它沉浸式视频广播系统中,每个用户只接收对应于其视角的沉浸式视频的空间子部分。然而,一旦用户改变在沉浸式视频上的视角,就会在这种类型的系统中引起时延问题。这是因为当用户改变视角时,其必须通知服务器他已经改变视角,并且所述服务器必须通过向用户传输对应于新视角的视频的空间子部分来作出响应。
期望克服现有技术的这些缺点。特别期望提供一种系统,所述系统在沉浸式视频上的视角改变时是反应性的,并且当多个用户正在观看所述视频时,在所述沉浸式视频的传输速率方面是经济的。
此外,期望提供一种易于以低成本实施的解决方案。
根据本发明的第一方面,本发明涉及一种用于在网络单元与至少一个观看设备之间传输沉浸式视频的方法,所述至少一个观看设备使多个用户能够同时观看所述沉浸式视频,所述网络单元和每个观看设备由通信网络连接,所述沉浸式视频包括一系列图像集,每个图像集由像素块构成,所述沉浸式视频根据预定视频压缩标准以编码形式传输到每个观看设备。所述方法由所述网络单元实施,并且对于每个图像集,所述方法包括:获得表示由每个用户观察到的所述沉浸式视频上的视角的信息;确定对应于所述视角中的至少一些视角的被称为特权区域的至少一个图像区域;对于包含在所述图像集中的每个图像,向不属于特权区域的像素块应用压缩率,所述压缩率平均高于向属于特权区域的像素块应用的压缩率的平均值;以及将所述图像集传输到每个观看设备。
以此方式,与以全质量传输的沉浸式视频相比,无论从哪个视角看,所述沉浸式视频的比特率都降低了,因为对应于由大多数用户观察到的所述沉浸式视频的区域的位于特权区域外部的图像区域以较低质量进行编码。
根据一个实施例,所述网络单元获得呈非压缩形式的沉浸式视频并根据所述预定视频压缩标准对所述沉浸式视频进行编码,或者所述网络单元获得呈压缩形式的沉浸式视频并对所述沉浸式视频进行转码,使得其与所述预定视频压缩标准相兼容。
根据一个实施例,所述方法包括:对于每个视角,确定所述沉浸式视频的对应于所述视角的空间子部分;确定每个空间子部分的中心;确定所述空间子部分的所述中心中的至少一些的重心;以及限定以重心为中心的矩形区域,所述矩形区域形成特权区域,所述矩形区域具有根据通信网络上可用的比特率预先限定或确定的尺寸。
根据一个实施例,所述方法包括:对于每个视角,确定所述沉浸式视频的对应于所述视角的空间子部分;确定重叠的所述空间子部分的至少一个联合;以及对于由联合产生的每组空间子部分,限定涵盖所述组空间子部分的矩形区域,每个矩形区域形成特权区域。
根据一个实施例,所述方法包括:对于每个视角,确定所述沉浸式视频的对应于所述视角的空间子部分;限定像素块的多个类别,第一类别包括不出现在任何空间子部分中的像素块,并且至少一个第二类别包括至少出现在预定义数量的空间子部分中的像素块;根据此像素块出现在空间子部分中的次数,对类别中的所述图像集中的图像的每个像素块进行分类;以及由分类在每个第二类别中的像素块形成至少一个特权区域。
根据一个实施例,所述方法进一步包括:将至少一个预定义空间子部分添加到根据视角限定的空间子部分,或将在所述沉浸式视频的其它观看期间根据所述沉浸式视频上的用户视角的统计限定的空间子部分添加到所述根据视角限定的空间子部分。
根据一个实施例,所述方法进一步包括:将根据当前空间子部分的位置并根据表示对应于此视角的用户头部的移动的信息限定的被称为外推空间子部分的空间子部分与根据视角限定的被称为所述当前空间子部分的每个空间子部分相关联,在每个特权区域的定义中考虑所述当前空间子部分和所述外推空间子部分。
根据本发明的第二方面,本发明涉及一种适合于实施根据第一方面所述的方法的网络单元。
根据本发明的第三方面,本发明涉及一种系统,所述系统包括使多个用户能够同时观看沉浸式视频的至少一个观看设备和根据第二方面所述的网络单元。
根据第四方面,本发明涉及一种计算机程序,所述计算机程序包括指令,当所述程序由装置的处理器执行时,所述指令用于由所述装置实施根据第一方面所述的方法。
根据第五方面,本发明涉及一种存储装置,所述存储装置存储包括指令的计算机程序,当所述程序由装置的处理器执行时,所述指令用于由所述装置实施根据第一方面所述的方法。
在阅读以下对实例实施例的描述之后,将更加清楚地呈现上文所提及的本发明的特征以及其它方面,所述描述参照附图给出,在附图中:
-图1示意性地展示了用于广播沉浸式视频的系统的实例;
-图2示意性地展示了由多个用户看到的沉浸式视频的空间子部分;
-图3示意性展示了实施本发明的系统;
-图4示意性地展示了根据本发明的住宅网关的硬件架构的实例;
-图5示意性地展示了用于使沉浸式视频适配用户的一组视角的方法;
-图6a、6b和6c示意性地展示了用于限定至少一个图像区域(被称为特权区域)的方法的三个实例,其中像素块平均必须具有比不属于特权区域的像素块更低的压缩率;
-图7a示意性地展示了在hevc编码期间由视频图像经历的连续划分;
-图7b示意性地描绘了用于编码与hevc标准兼容的视频流的方法;
-图7c示意性地描绘了根据hevc标准的解码方法;
-图8示意性地描绘了旨在适配未经编码的视频的适配方法;并且
-图9示意性地描绘了旨在适配经过编码的视频的适配方法。
在下文中,在多个用户各自使用包括处理模块的一个观看设备(如沉浸式眼镜)的背景下描述了本发明。每个用户观看相同的沉浸式视频,但视角可能不同。每个用户可以远离或更靠近沉浸式视频移动、转身、转头、抬起头等。所有这些移动都改变了用户的视角。然而,本发明适合于其它观看设备,如包括专用于广播沉浸式视频的房间的观看设备,所述房间配备有360度屏幕或呈圆顶形式的屏幕或多个图像投影装置,所述多个图像投影装置各自投影沉浸式视频的一部分。每个图像投影装置然后连接到外部处理模块。然后,用户可以在房间里移动,并且从不同视角观看沉浸式视频。
图3示意性展示了实施本发明的系统3。
系统3包括服务器30,所述服务器通过如互联网等广域网(wan)32连接到住宅网关34(下文简称为网关),所述住宅网关位于例如住所中。网关34使得可以将局域网(lan)35连接到广域网32。局部网络35为例如无线网络,如wi-fi网络(iso/iec8802-11)。在图3中,多个相同客户端131a、131b和131c通过局部网络35连接到网关,所述多个相同客户端各自包含在一副沉浸式眼镜中。每副沉浸式眼镜由用户佩戴,所述用户可以在住所中走动,以便获得沉浸式视频上的不同视角。此外,每副沉浸式眼镜包括定位模块,所述定位模块适合于确定代表沉浸式视频上的用户视角的信息。
服务器30以二进制视频流的形式以完整的空间和时间分辨率存储沉浸式视频,所述二进制视频流是非压缩的或者根据视频压缩标准进行压缩,所述视频压缩标准如mpeg-4可视视频压缩标准(iso/iec14496-2)、标准h.264/mpeg-4avc(iso/iec14496-10——mpeg-4第10部分、先进视频编码/itu-th.264)或标准h.265/mpeg-4hevc(iso/iec23008-2–mpeg-h第2部分、高效视频编码/itu-th.265)。沉浸式视频由一系列图像构成,每个图像由像素块构成。
服务器30适合于向网关34广播沉浸式视频。网关34包括适配模块340,所述适配模块能够将沉浸式视频适配到一组用户的视角,以便满足最大数量的用户。
应该注意的是,所述方法也可以在没有服务器的情况下起作用。在这种情况下,除了负责适配沉浸式视频并将其发射到客户端131a、131b和131c之外,网关还存储沉浸式视频。
图2示意性地展示了由多个用户看到的沉浸式视频的空间子部分。
在图2中,可以看到应用于图1中的环的沉浸式视频10。然而,在图2中,环已经展开,使得视频出现在平面中。假设在图2中,三个用户正在观看不同的视角。使用包括处理模块131a的沉浸式眼镜的用户正在观看子部分11a。使用包括处理模块131b的沉浸式眼镜的用户正在观看区域11b。使用包括处理模块131c的沉浸式眼镜的用户正在观看区域11c。使用包括处理模块131a的沉浸式眼镜的用户在视频上的视角比其它两个用户更远,这解释了子部分11a大于子部分11c和11b的事实。与使用包括处理模块131b的沉浸式眼镜的用户相比,使用包括处理模块131c的沉浸式眼镜的用户在沉浸式视频上被定向得更靠左。
图4示意性展示了适配模块340的硬件架构的实例。适配模块340然后包括通过通信总线3400连接的:处理器或中央处理单元(cpu)3401;随机存取存储器ram3402;只读存储器rom3403;存储单元或存储介质读取器,如安全数字(sd)卡读取器3404;一组通信接口3405,所述组通信接口使适配模块340能够通过广域网32与服务器30通信并通过局域网35与每个客户端131通信。
处理器3401能够从rom3403、外部存储器(未示出)、从如sd卡等存储介质或从通信网络执行加载在ram3402中的指令。当适配模块340通电时,处理器3401能够从ram3402读取指令并执行所述指令。这些指令形成计算机程序,从而使得由处理器3401实施关于图5所描述的方法。
关于图5所描述的方法的全部或部分可以通过可编程机器(如dsp(数字信号处理器)或微控制器)执行指令集以软件形式实施,或者通过机器或专用组件(如fpga(现场可编程门阵列)或asic(专用集成电路))以硬件形式实施。
图5示意性地展示了用于使沉浸式视频适配用户的一组视角的方法,从而使得可以最好地满足最大数量的用户。
关于图5所描述的方法由网关34的适配模块341执行。然而,此方法也可以由独立于网关34并且位于网关34与每个客户端131a、131b或131c之间的适配模块341实施。在另一个实施例中,适配模块还可以包含在位于服务器30与如dslam(数字用户线接入复用器)等网关34之间的网络节点中。
适配模块340的一个作用是适配沉浸式视频,使得所述沉浸式视频在显示质量方面和在视角变化的情况下的反应性方面满足最大数量的用户。
关于图5所描述的方法以规律间隔实施,例如,对应于图像或一系列几个图像的持续时间的周期p。例如,对于具有每秒30幅图像的沉浸式视频,p=34毫秒,或对于具有每秒60幅图像的沉浸式视频,p=17毫秒。因此,适配模块可以适配沉浸式视频中的每个图像,以满足大多数用户。
在步骤501中,适配模块340从客户端131a(并且分别为131b和131c)获得表示对应于所述客户端的由用户观察到的视角的信息。例如,表示视角的每个信息项包括方位角、仰角和距离。
在步骤502中,适配模块340确定对应于视角中的至少一些视角的至少一个图像区域(被称为特权区域)。我们将在下文中详述关于图6a、6b和6c的用于确定至少一个特权区域的各种方法。
在步骤503中,对于在确定至少一个特权区域之后的每个图像,在编码或转码期间,适配模块340向不属于特权区域的像素块应用压缩率,所述压缩率平均高于向属于特权区域的像素块应用的压缩率。步骤503使得能够获得与适配于用户视角的沉浸式视频相对应的视频流。此沉浸式视频的每个图像在大多数用户观看的至少一个区域中具有较高的质量,并且在图像的其余部分中具有较低的质量。我们将在下文中详述此步骤的各个实施例。
在一个实施例中,特权区域的像素块的压缩率的平均值和不属于特权区域的块的压缩率的平均值取决于网络35上可用的比特率。
在步骤504中,使用局部网络35将如此获得的视频流传输到每个观看设备。
在另一个实施例中,所述方法是在大多数用户的视角改变之后实施的。
图6a、6b和6c示意性地展示了用于限定至少一个图像区域(被称为特权区域)的方法的三个实例,其中像素块平均必须具有比不属于特权区域的像素块更低的压缩率。因此,属于特权区域的像素块的质量平均将高于不属于特权区域的像素块的质量。以这种方式,由用户看到或至少由大多数用户看到的沉浸式视频的图像区域是有特权的。关于图6a、6b和6c所描述的方法对应于步骤502。
关于图6a所描述的方法从步骤5020开始。在步骤5020期间,适配模块340根据表示视角的每个信息项确定对应于所述视角的沉浸式视频的空间子部分。每个空间子部分例如是在像素块边界上对齐的矩形。
在步骤5021中,适配模块340确定每个空间子部分的中心。
在步骤5022中,适配模块340确定空间子部分的中心的重心,即使所述点与每个中心之间的距离总和最小化的点。在一个实施例中,重心是使距离最小化到中心的预定百分比的点。预定百分比为例如80%。
在步骤5023中,适配模块340限定以重心为中心的矩形区域,所述矩形区域形成特权区域。在一个实施例中,矩形区域具有预定尺寸。在一个实施例中,矩形区域的尺寸等于空间子部分尺寸的平均值。在一个实施例中,适配模块根据网络35上可用的比特率确定矩形区域的尺寸。当所述比特率较低(即低于第一比特率阈值)时,矩形区域的尺寸等于空间子部分的预定平均尺寸,这使得可以固定矩形区域的最小尺寸。当所述比特率较高(即高于第二比特率阈值)时,矩形区域的尺寸等于例如空间子部分的预定平均尺寸的两倍,这使得可以固定矩形区域的最大尺寸。当所述比特率为平均的(即介于第一比特率阈值与第二比特率阈值之间)时,矩形区域的尺寸根据介于空间子部分的预定平均尺寸之间并为空间子部分的预定平均尺寸的两倍的比特率线性地增加。在此实施例中,用户实际看到的区域因此是有特权的。然而,当比特率允许时,特权区域被扩展,以便使改变视角的用户能够具有高质量的沉浸式视频显示,尽管发生了这种变化。在一个实施例中,第一比特率阈值和第二比特率阈值相等。
关于图6b所描述的方法从与步骤5020相同的步骤5024开始。
在步骤5025中,适配模块340确定空间子部分的联合。形成仅针对重叠的空间子部分的联合。因此,有可能获得由重叠空间子部分的联合产生的多个空间子部分组。
在步骤5026中,对于由联合形成的每个空间子部分组,适配模块限定涵盖所述空间子部分组的矩形区域。每个矩形区域然后形成特权区域。在一个实施例中,未考虑用于限定特权区域的包括几个空间子部分的空间子部分组(例如,包括低于预定数目的多个空间子部分)。
关于图6c所描述的方法从与步骤5020相同的步骤5027开始。
在步骤5028中,根据此像素块出现在空间子部分中的次数,将图像的每个像素块分类到类别中。因此,形成多个类别的像素块是可能的。第一类别是例如不出现在空间子部分中的像素块的类别。第二类别包括在空间子部分中出现至少n次的像素块。n为等于例如5的整数。第三类别包括既不出现在第一类别中也不出现在第二类别中的像素块。在步骤5029中,适配模块340从属于第二类别的像素块形成第一特权区域,并且从属于第三类别的像素块形成第二特权区域。在一个实施例中,在实施关于图6c所描述的方法之后,消除了尺寸小于空间子部分的平均尺寸的特权区域。属于这些经过消除的区域的像素块被认为不形成特权区域的一部分。
在一个实施例中,在步骤5020、5024和5027中,向对应于用户视角的空间子部分添加至少一个空间子部分,所述至少一个空间子部分例如由沉浸式视频的制作者预先限定或根据在所述沉浸式视频的其它观看期间用户对所述沉浸式视频的视角的统计而限定。
在一个实施例中,在步骤5020、5024和5027中,将对应于用户视角的被称为当前空间子部分的每个空间子部分与通过考虑用户头部的移动而获得的被称为外推空间子部分的第二空间子部分相关联。假设用户的沉浸式眼镜包括运动测量模块。客户端131从运动测量模块获得运动信息,并将此信息传输到适配模块340。运动信息为例如运动向量。根据运动信息并且根据当前空间子部分的位置,适配模块确定外推空间子部分的位置。由当前空间子部分和外推空间子部分形成的整体接下来用于关于图6a、6b和6c所描述的方法的剩余部分。
在一个实施例中,在步骤503中,根据视频压缩标准对在时间段p期间考虑的沉浸式视频的每个图像进行压缩或转码,使得其与视频压缩标准兼容。在一个实施例中,所使用的视频压缩标准为hevc。
图7a、7b和7c描述了hevc标准的实施方案的实例。
图7a展示了由原始视频71的像素72的图像在其根据hevc标准编码期间经历的连续划分。此处认为像素由三个分量构成:亮度分量和两个色度分量。在图7a的实例中,图像72最初被分成三个切片。切片是可以覆盖整个图像或覆盖仅一部分(如图7a中的切片73)的图像区域。切片包括至少一个切片片段,任选地随后是其它切片片段。切片中第一位置的切片片段称为独立切片片段。独立切片片段(如切片73中的切片片段is1)包括完整报头,如报头78。报头78包括使切片能够解码的一组语法元素。切片的任何其它切片片段(如图7a中的切片73的切片片段ds2、ds3、ds4、ds5和ds6)被称为从属切片片段,因为所述切片片段仅具有部分报头,所述部分报头指切片中在其之前的独立切片片段报头,此处是报头78。应该注意的是,在avc标准中,仅切片的概念存在,切片必然包括完整报头并且不能被划分。
应该注意的是,图像的每个切片可以独立于相同图像的任何其它切片进行解码。然而,在切片中使用环路后滤波可能需要使用另一个切片的数据。
在将图像72划分成切片之后,图像的每个切片的像素被划分成编码树块(ctb),如图7a中的一组编码树块74。在下文中,为了简化起见,我们将使用首字母缩略词ctb来指定编码树块。ctb(如图7a中的ctb79)是正方形像素块,所述正方形像素块的大小等于2的幂,并且所述正方形像素块的大小的范围可以为16到64个像素。ctb可以以四叉树的形式划分在一个或多个编码单元(cu)中。编码单元是正方形像素块,所述正方形像素块的大小等于2的幂,并且所述正方形像素块的大小的范围可以为8到64个像素。编码单元(如图4中的编码单元405)然后可以被划分成用于空间或时间预测的预测单元(pu)和用于频域中像素块变换的变换单元(tu)。
在图像编码期间,划分是自适应的,也就是说,每个ctb被划分以便优化ctb的压缩性能。在下文中,为了简化起见,我们将考虑将每个ctb划分成编码单元,并且将此编码单元划分成变换单元和预测单元。另外,所有的ctb都具有相同的大小。ctb对应于关于图3、5、6a、6b和6c所描述的像素块。
在下文中还假设每个经过编码的图像仅包括一个独立切片。
图7b示意性地描绘了用于对与由编码模块所使用的hevc标准兼容的视频流进行编码的方法。图像的当前图像701的编码在步骤702期间从当前图像701的划分开始,如关于图7a所描述的。为了简化,在图7b的描述的剩余部分中和图7c的描述中,我们不区分ctb、编码单元、变换单元和预测单元,并且我们在术语像素块下对这四个实体进行分组。当前图像701因此被划分成像素块。对于每个像素块,编码装置必须在图像内编码模式(被称为帧内编码模式)与图像间编码模式(被称为帧间编码模式)之间确定编码模式。
帧内编码模式由在步骤703中根据帧内预测方法预测当前像素块的来自预测块的像素组成,所述像素源自于位于有待编码的像素块因果附近的重构像素块的像素。帧内预测的结果是指示要使用附近的像素块中的哪些像素的预测方向,以及通过计算当前像素块与预测块之差而得到的残差块。
帧间编码模式由从当前图像之前或之后的图像的像素块(被称为参考块)预测当前像素块的像素组成,此图像被称为参考图像。在根据帧间编码模式对当前像素块进行编码期间,根据相似性准则,参考图像中最接近当前像素块的像素块由运动估计步骤704确定。在步骤704中,确定指示参考图像中参考像素块的位置的运动向量。所述运动向量在运动补偿步骤705期间被使用,在所述步骤期间,以当前像素块与参考块之差的形式计算残差块。应该注意的是,我们在此描述了单预测帧间编码模式。还存在双预测帧间编码模式(或b模式),在所述编码模式中,当前像素块与两个运动向量相关联,这在两个不同的图像中指定两个参考块,然后此像素块的残差块为两个残差块的平均值。
在选择步骤706中,在所测试的两种模式中,根据比特率/失真标准对压缩性能进行优化的编码模式由编码装置选择。当选择编码模式时,残差块在步骤707中被变换,并在步骤709中被量化。当根据帧内编码模式对当前像素块进行编码时,在步骤510期间,由熵编码器对预测方向以及经过变换且经过量化的残差块进行编码。当根据帧间编码模式对当前像素块进行编码时,使用从一组运动向量选择的对应于重构像素块的预测向量预测像素块的运动向量,所述重构像素块位于有待编码的像素块附近。在步骤710期间,接下来由熵编码器以运动残差和用于标识预测向量的索引的形式对运动向量进行编码。在步骤710期间,由熵编码器对经过变换且经过量化的残差块进行编码。熵编码的结果被插入到二进制视频流711中。
在hevc标准中,用于像素块量化的参数根据用于邻近像素块量化的参数或根据切片报头中所描述的量化参数进行预测。语法元素然后在视频的二进制流中对像素块量化参数与其预测之差进行编码(参见hevc标准的节段7.4.9.10和节段8.6)。
在步骤709中量化之后,重构当前像素块,使得所述当前像素块包含的像素可以用于未来预测。此重构阶段还被称为预测环路。因此,步骤712中的逆量化和步骤713中的逆变换被应用于经过变换且经过量化的残差块。根据用于在步骤714中获得的像素块的编码模式,对像素块的预测块进行重构。如果根据帧间编码模式对当前像素块进行编码,则在步骤716中,编码装置使用当前像素块的运动向量来应用逆运动补偿,以便标识当前像素块的参考块。如果根据帧内编码模式对当前像素块进行编码,则在步骤715中,对应于当前像素块的预测方向用于重构当前像素块的参考块。将参考块与经过重构的残差块相加,以便获得经过重构的当前像素块。
重构之后,在步骤717中,对经过重构的像素块应用环路后滤波。此后滤波被称为环路后滤波,因为此后滤波发生在预测环路中,以便在编码时获得与解码相同的参考图像,并且因此避免编码与解码之间的任何偏移。hevc环路后滤波包括两种后滤波方法,即去块滤波和sao(样本自适应偏移)滤波。应该注意的是,h.264/avc的后滤波仅包括去块滤波。
去块滤波的目的是衰减由于像素块之间量化差而导致的像素块边界处的任何不连续性。自适应滤波可以被激活或去激活,并且当其被激活时,可以采取基于具有包括六个滤波器系数的维度的可分离滤波器的高复杂度去块滤波的形式,所述可分离滤波器在下文中称为强滤波器,并且可以采取基于具有包括四个系数的维度的可分离滤波器的低复杂度去块滤波的形式,所述可分离滤波器在下文中称为弱滤波器。强滤波器极大地衰减了像素块边界处的任何不连续性,这可能损坏原始图像中存在的空间高频。弱滤波器弱衰减像素块边界处的任何不连续性,这使得可以保存原始图像中存在的空间高频,但是对于通过量化人为创建的任何不连续性来说效率较低。滤波或不滤波的决定以及在滤波的情况下使用的滤波器的形式取决于有待滤波的像素块的边界处的像素值以及以由hevc标准限定的两种语法元素的形式编码在二进制视频流中的两个参数。解码装置可以使用这些语法元素来确定是否必须应用去块滤波以及有待应用的去块滤波的形式。
sao滤波采取具有两个不同目标的两种形式。第一形式(被称为边缘偏移)的目的为补偿量化对像素块中轮廓的影响。边缘偏移sao滤波包括根据对应于四种相应轮廓类型的四个类别对重构图像的像素进行分类。通过根据四个滤波器进行滤波对像素进行分类,每个滤波器使得能够获得滤波梯度。使分类标准最大化的滤波梯度指示对应于像素的轮廓类型。每种类型的轮廓都与在sao滤波期间添加到像素的偏移值相关联。
sao的第二形式被称为频带偏移,并且其目的是补偿量化对属于某些范围(即频带)的值的像素的影响。在频带偏移滤波中,像素的所有可能值(最常见的是位于0与255之间的8位视频流)被分成32个范围的8个值。在这32个范围中,选择四个连续的范围进行偏移。当像素的值位于有待偏移的四个范围值之一时,将偏移值与所述像素的值相加。
通过比特率/失真优化由编码装置确定了针对每个ctb的实施sao滤波的决定以及当实施sao滤波时sao滤波的形式和偏移值。在熵编码步骤510中,编码装置在二进制视频流511中插入信息,从而使解码装置能够确定是否将sao滤波应用于ctb,并且在适用的情况下,确定将应用的形式和sao滤波参数。
当重构像素块时,在步骤520中,将所述像素块插入到存储在重构图像存储器521(也称为参考图像存储器)中的重构图像中。如此存储的重构图像然后可以充当有待编码的其它图像的参考图像。
当切片中的所有像素块被编码时,对应于所述切片的二进制视频流被插入到称为网络抽象层单元(nalu)的容器中。在网络传输的情况下,这些容器被直接插入到网络分组中或插入到中间传输流容器(如mp4传输流)中。
图7c示意性地描绘了用于对根据由解码装置实施的hevc标准压缩的流进行解码的方法。解码逐像素块进行。对于当前像素块,所述解码开始于在步骤810期间对当前像素块进行熵解码。熵解码使得能够获得用于像素块的编码模式。
如果已经根据帧间编码模式对像素块进行编码,则熵解码使得能够获得预测向量索引、运动残差和残差块。在步骤808中,使用预测向量索引和运动残差重构针对当前像素块的运动向量。
如果已经根据帧内编码模式对像素块进行编码,则熵解码使得能够获得预测方向和残差块。由解码装置实施的步骤812、813、814、815和816分别与由编码装置实施的步骤812、813、814、815和816在所有方面都相同。
解码装置接下来在步骤817中应用环路后滤波。与编码一样,对于hevc标准,环路后滤波包括去块滤波和sao滤波,而对于avc标准,环路滤波仅包括去块滤波。
在步骤819中,sao滤波由解码装置实施。在解码期间,解码装置不必确定是否必须向像素块应用sao滤波,并且如果必须应用sao滤波,则解码装置不必确定有待应用的sao滤波的形式和偏移值,因为解码装置将在二进制视频流中找到此信息。如果对于ctb,sao滤波属于边缘偏移类型,则对于ctb的每个像素,解码装置必须通过对轮廓类型进行滤波来确定并且添加对应于经过确定的轮廓类型的偏移值。如果对于ctb,sao滤波属于频带偏移类型,则对于ctb的每个像素,解码装置将有待滤波的像素的值与有待偏移的值的范围进行比较,并且如果像素的值属于有待偏移的值的范围之一,则将对应于所述范围的值的偏移值与像素的值相加。
如上文关于图5所见,在步骤503中,适配模块340向不属于特权区域的像素块应用压缩率,所述压缩率平均高于向属于特权区域的像素块应用的压缩率的平均值。像素块的压缩率在很大程度上首先取决于其编码模式,并且其次取决于其量化参数。
当适配模块接收到未经编码的沉浸式视频时,其必须对沉浸式视频的每个图像进行编码,从而根据像素块是否属于特权区域来应用不同的压缩率。
图8示意性地描绘了旨在适配未经编码的视频的适配方法,所述未经编码的视频由适配模块在步骤503中实施。
在步骤5031中,适配模块获得表示在局部网络35上可用的比特率的信息。
在步骤5032中,适配模块根据表示比特率的信息确定有待编码的图像的比特预算。
在步骤5033中,适配模块根据所述预算确定有待编码的图像的每个像素块的比特预算。对于有待编码的图像的第一像素块,像素块的比特预算等于有待编码的图像的预算除以有待编码的图像的像素块的数量。对于图像的其它像素块,像素块的比特预算等于根据减去先前编码的像素块已经消耗的比特编码的图像的比特预算除以剩余有待编码的待编码的图像的像素块的数量。
在步骤5034中,适配模块确定有待编码的当前像素块是否为属于特权区域的像素块。如果是这种情况,则适配模块在步骤5036中将关于图7b描述的方法应用于当前像素块。比特率/失真优化使得能够确定当前像素块的编码模式和量化参数。
如果当前像素块不属于特权区域,则适配模块还将关于图7b描述的方法应用于所述当前像素块。然而,在步骤5035中,适配模块将预定义常数δ与由比特率/失真优化确定的量化参数的值相加。在一个实施例中,预定义常数δ=3。
在步骤5035和5036之后,适配模块在步骤5037中确定当前像素块是否为有待编码的图像的最后一个像素块。如果不是这种情况,则适配模块返回到步骤5033,以便执行新像素块的编码。如果所述当前像素块为有待编码的图像的最后一个像素块,则关于图8描述的方法结束,并且适配模块返回到步骤501或开始新图像的编码。
通过将比由比特率/失真优化确定的量化参数高的量化参数分配给不属于特权区域的像素块,将图像的比特率预算的较大比例留给属于特权区域的像素块。以此方式,特权区域的质量比非特权区域的质量更好。
应当注意,图8的方法适用于其它视频压缩标准,如avc或mpeg-4visual。然而,在mpeg-4visual的背景中,像素块的量化参数根据图像中最后一个经过编码的像素块的量化参数而预测,但是量化参数与其预测值之间的绝对值差不超过2。在这种情况下,如果预定义常数δ大于2,则特权区域与非特权区域之间的转换(并且反之亦然)必须发生在若干像素块上。
在一个实施例中,并非使用预定义常数δ人为地增加不位于特权区域中的每个像素块的量化参数,而是将有待编码的图像的比特预算分成两个独立的子预算:属于特权区域的像素块的第一子预算以及不属于特权区域的像素块的第二子预算。第一子预算大于第二子预算。例如,第一子预算等于图像的比特预算的三分之二,而第二预算等于图像的比特预算的三分之一。
当沉浸式视频是根据视频压缩标准编码的视频时,由适配模块340对沉浸式视频进行的适配可以由转码组成。
在一个实施例中,在转码期间,适配模块340在时间段p期间例如根据关于图7c描述的方法对正在讨论的沉浸式视频的每个图像进行完全解码,并且根据关于图8描述的方法对其进行重新编码。
在一个实施例中,在转码期间,适配模块仅部分地对经过编码的沉浸式视频进行解码和重新编码,以便降低转码的复杂性。在此假设以hevc格式对沉浸式视频进行编码。
图9示意性地描绘了一种适配方法,所述适配方法旨在适配由适配模块在步骤503中实施的经过编码的视频。
在逐像素块进行的时间段p期间,对正在讨论的沉浸式视频的每个图像实施关于图9描述的方法。
在步骤901中,适配模块340将如步骤810中所述的熵解码应用于当前像素块。
在步骤902中,适配模块340将如步骤812中所述的逆量化应用于当前像素块。
在步骤903中,适配模块340将如步骤813中所述的逆变换应用于当前像素块。在此阶段,获得残差预测块。
在步骤904中,适配模块340确定当前像素块是否属于特权区域。
如果当前像素块属于特权区域,则适配模块340执行步骤905。在步骤905期间,考虑到当前像素块的一个或多个参考块(用于帧内预测的参考块或用于帧间预测的参考块)已经能够被重新量化的事实。因此,在重新量化的情况下,参考块不同于原始参考块。因此,使用此经过修改的参考块的帧间或帧内预测是不正确的。因此,在步骤905中,将重新量化误差添加到根据当前像素块重构的残差块,以便补偿重新量化效果。
重新量化误差是在重新量化之前重构的残差块与已经考虑到的在重新量化之后重构的相同残差块之间的差异。重新量化残差块之后可能存在直接重新量化误差,而重新量化通过帧内或帧间预测而预测的像素块的至少一个参考块之后可能存在间接重新量化误差。在关于图9描述的方法中,每当重构当前像素块的残差块时,适配模块340计算经过重构的当前像素块的原始残差块与经过重构的当前像素块的残差块之差,同时考虑影响此残差块的直接和/或间接重新量化误差。此差异在当前像素块中形成重新量化误差。每个像素块的重新量化误差由适配模块340例如以重新量化误差图像的形式保留,以便能够用于计算参考当前像素块的其它像素块中的重新量化误差(即,在步骤905中)。
在步骤906中,适配模块340将如步骤707中所述的变换应用于在步骤905中获得的残差块。
在步骤907中,适配模块340将如步骤709中所述的量化应用于在步骤906中获得的经过变换的残差块,从而重新使用所述当前像素块的原始量化参数。
在步骤908中,适配模块340将如步骤710中所述的熵编码应用于在步骤907中获得的经过量化的残差块,并且将对应于所述熵编码的二进制流插入沉浸式视频的二进制流中以替换对应于当前像素块的原始二进制流。
在步骤909中,将适配模块340传递到当前图像的下一个像素块,或者如果当前像素块是当前图像的最后一个像素块,则将其传递到另一个图像。
在当前像素块不属于特权区域时,用比所述当前像素块的原始量化参数更高的量化参数对此像素块进行重新量化。
适配模块340执行分别与步骤905和906相同的步骤910和911。
在步骤912中,适配模块340修改当前像素块的量化参数。然后适配模块将预定义常数δ与当前像素块的量化参数的值相加。
在步骤913中,适配模块340将如步骤709中所述的量化应用于在步骤911中获得的经过变换的残差块,从而使用当前像素块的经过修改的量化参数。
关于图7b,我们已经看到,在hevc标准中,根据其附近的像素块的量化参数对像素块的量化参数进行预测。接下来语法元素在视频的二进制流中对像素块的量化参数与其预测之间的差异进行编码。在当前像素块的量化参数被修改时,有必要对邻近像素块中的此种修改进行补偿,所述邻近像素块的量化参数根据当前像素块的量化参数进行预测。
在步骤914中,适配模块340在视频的二进制流中修改每个语法元素,所述每个语法元素表示像素块的量化参数与其的每个像素块的预测之间的差异,所述像素块的量化参数根据有待获取的当前像素块的量化参数进行预测。因此,适配模块340将表示像素块的量化参数与其预测之间的差异的值与每个语法元素的值相加,以便补偿由于量化参数的修改而引起的预测的修改。
在步骤915中,适配模块继续对在步骤913中获得的残差块和在步骤914中获得的每个语法元素进行熵编码,并且将对应于所述熵编码的二进制流插入沉浸式视频的二进制流中以替换对应于当前像素块的原始二进制流。
在一个实施例中,在图9的方法中,预定义常数δ是固定的,使得经过转码的沉浸式视频与局部网络35上的比特率约束相兼容。
在一个实施例中,在图9的方法中,使属于特权区域的像素块的量化参数也增加预定义常数δ′,使得经过转码的沉浸式视频与局部网络35上的比特率约束相兼容。然而,δ′<δ。
- 还没有人留言评论。精彩留言会获得点赞!