通过多个备用数据路径进行分组喷射的数据中心网络的结构控制协议的制作方法
本申请要求于2017年9月29日提交的美国临时申请号62/566,060和于2018年3月5日提交的美国临时申请号62/638,788的权益,其每个的全部内容通过引用并入本文。
本发明涉及计算机网络,更具体地涉及数据中心网络。
背景技术:
在典型的基于云的数据中心中,大量互连的服务器为执行各种应用提供了计算和/或存储容量。例如,数据中心可以包括为订阅者托管应用和服务的设施,即,数据中心的客户。例如,数据中心可以托管所有基础设施设备,诸如,计算节点、联网和存储系统、电力系统以及环境控制系统。
在大多数数据中心中,存储系统和应用服务器的集群经由高速交换结构互连,该高速交换结构由物理网络交换机和路由器的一个或多个层提供。数据中心的大小差异很大,有些公共数据中心包含成千上万的服务器,并且通常分布在多个地区以实现冗余。典型的数据中心交换结构包括多层互连的交换机和路由器。在当前的实现中,源服务器与目的地服务器或存储系统之间的给定分组流(flow)的分组总是通过路由器和包括交换结构的交换机沿着单个路径从源被转发到目的地。
技术实现要素:
描述了用于在数据中心或其他计算环境内使用的新数据传输协议的示例实现,在本文中通常称为结构控制协议。作为一个示例,结构控制协议可以在环境中提供某些优点,其中交换结构提供全网格互连性,使得任何服务器都可以使用数据中心交换结构内的多个并行数据路径中的任何一个并行数据路径来将给定分组流的分组数据传递给任何其他服务器。如本文进一步描述的,结构控制协议的示例实现使得能够跨数据中心交换结构中的多个并行数据路径中的一些或所有针对给定分组流喷射各个分组,并且可选地,对分组进行重排序以递送到目的地。在一些示例中,结构控制协议分组结构是通过诸如用户数据报协议(udp)等基础协议承载的。
本文描述的技术可以提供某些优点。例如,结构控制协议可以基于流的端点控制的请求和授权在单个隧道内提供端到端带宽缩放和流公平性。另外,结构控制协议可以延迟流的分组分段,直到接收到授权为止,提供对请求和授权的容错和基于硬件的自适应速率控制,提供自适应请求窗口缩放,对请求和授权进行加密和认证,并且改善显式拥塞通知(ecn)标记支持。
在一些示例中,结构控制协议包括端到端许可控制机制,其中发送器显式地请求接收器转移一定数量的有效负载数据字节。作为响应,接收器基于其缓冲器资源、服务质量(qos)和/或结构拥塞度量来发出授权。例如,结构控制协议包括许可控制机制,源节点通过该许可控制机制在将结构上的分组传输到目的地节点之前请求许可。例如,源节点向目的地节点发送请求消息,以请求传送一定数量的字节,并且目的地节点在保留出口带宽之后向源节点发送授权消息。另外,结构控制协议使得单独分组流的分组能够跨源节点和目的地节点之间的所有可用路径被喷射,而不是用于在同一路径上发送传输控制协议(tcp)流的所有分组的基于流的交换和等成本多路径(ecmp)转发,以便避免分组重排序。源节点向流的每个分组指派分组序列号,并且目的地节点可以使用分组序列号来按顺序排列相同流的传入分组。
在一个示例中,本公开涉及一种网络系统,该网络系统包括:多个服务器;包括多个核心交换机的交换结构;以及多个接入节点,接入节点中的每个接入节点被耦合至服务器的子集并且被耦合至核心交换机的子集,其中接入节点包括各自执行结构控制协议(fcp)的源接入节点和目的地接入节点。源接入节点被配置为发送针对数据量的fcp请求消息,该数据量在分组流中要从被耦合至源接入节点的源服务器被传送到被耦合至目的地接入节点的目的地服务器,并且响应于指示针对分组流保留的带宽量的fcp授权消息的接收,根据所保留的带宽跨多个并行数据路径喷射分组流的fcp分组。目的地接入节点被配置为响应于fcp请求消息的接收而执行授权调度并发送指示针对分组流保留的带宽量的fcp授权消息,并且响应于接收到分组流的fcp分组,将在分组流中传送的数据递送到目的地服务器。
在另一示例中,本公开涉及一种方法,该方法包括:在计算机网络内的源接入节点与目的地接入节点之间通过多个并行数据路径建立逻辑隧道,其中源接入节点和目的地接入节点分别被耦合至一个或多个服务器,其中源接入节点和目的地接入节点由中间网络连接,该中间网络包括具有多个核心交换机的交换结构,并且其中源接入节点和目的地接入节点各自执行结构控制协议(fcp);由源接入节点发送针对数据量的fcp请求消息,该数据量在分组流中要从被耦合至源接入节点的源服务器被传送到被耦合至目的地接入节点的目的地服务器;以及响应于指示针对分组流保留的带宽量的fcp授权消息的接收,通过由源接入节点根据所保留的带宽跨多个并行数据路径喷射分组流的fcp分组,来转发fcp分组。
在附加示例中,本公开涉及一种方法,该方法包括:在计算机网络内的源接入节点与目的地接入节点之间通过多个并行数据路径建立逻辑隧道,其中源接入节点和目的地接入节点分别被耦合至一个或多个服务器,其中源接入节点和目的地接入节点由中间网络连接,该中间网络包括具有多个核心交换机的交换结构,并且其中源接入节点和目的地接入节点各自执行结构控制协议(fcp);响应于针对数据量的fcp请求消息的接收,由目的地接入节点执行授权调度,该数据量在分组流中要从被耦合至源接入节点的源服务器被传送到被耦合至目的地接入节点的目的地服务器,;由目的地接入节点发送fcp授权消息,该fcp授权消息指示针对分组流保留的带宽量;以及响应于接收到分组流的fcp分组,由目的地接入节点将在分组流中传送的数据递送到目的地服务器。
在下面的附图和描述中阐述了一个或多个示例的细节。本发明的其他特征、目的和优点将通过说明书和附图以及通过权利要求而变得明显。
附图说明
图1是图示了可以实现本文描述的技术的示例的具有数据中心的示例网络的框图。
图2是进一步详细地图示了由数据中心内的接入节点和交换结构提供的逻辑互连性的框图。
图3是图示了包括接入节点组及其支持的服务器的网络存储计算单元(nscu)40的一个示例的框图。
图4是图示了包括来自图3的两个nscu的示例逻辑机架布置的框图。
图5是图示了逻辑机架内的两个接入节点组之间的全网格连接性的示例的框图。
图6是图示了包括来自图4的两个逻辑机架的完整物理机架的示例布置的框图。
图7a是示出了接入节点内的联网数据路径和操作的逻辑视图的框图。
图7b是图示了在逻辑机架内的接入节点集合之间实现的示例第一级网络扇出的框图。
图8是图示了跨接入节点之间的数据中心交换结构的示例多级网络扇出的框图。
图9是图示了包括联网单元和两个或更多个处理核的示例接入节点的框图。
图10是图示了接入节点的示例联网单元的框图。
图11是图示了源接入节点与目的地接入节点之间的示例网络结构的概念图。
图12是图示了源接入节点和目的地接入节点之间的示例结构控制协议队列对结构的概念图。
图13是图示了在源接入节点和目的地接入节点处的结构控制协议队列状态的示例的概念图。
图14是图示了用于将输入分组流(stream)从源接入节点传送到目的地接入节点的示例结构控制协议操作的概念图。
图15是图示了示例结构控制协议源接入节点操作流程的概念图。
图16是图示了示例结构控制协议目的地接入节点操作流程的概念图。
图17a和图17b是图示了在目的地接入节点处使用结构控制协议授权调度器实现的流公平性的示例的概念图。
图18是图示了用于请求消息或授权消息的结构控制协议控制分组的示例格式的概念图。
图19是图示了结构控制协议数据分组的示例格式的概念图。
图20是图示了根据本文描述的技术的具有分组交换网络的示例系统的框图,该分组交换网络具有在分组交换网络上被动态配置的多个网络接入节点虚拟结构。
图21是图示了根据本文描述的技术的网络系统的操作的示例的流程图。
图22是图示了根据本文描述的技术的网络系统的操作的另一示例的流程图。
具体实施方式
当今的大型数据中心网络可以连接超过100,000个双插槽(two-socket)服务器,并且通常被设计为以接近对分(bisection)吞吐量的25%来操作。因此,随着容量需求的增长,大多数数据中心都需要提供较大的对分带宽。数据中心还必须支持从大数据分析到金融服务的不断增长的各种应用。它们还必须是敏捷的,并允许将应用部署到任何服务器,以提高效率和成本效益。
数据中心利用各种流调度技术来尝试平衡网络的底层互连结构的利用率。例如,传统上,端点(服务器)之间的业务流依赖于基于ecmp(等成本多路径)的负载平衡。然而,由于ecmp随机对到网络路径的分组流进行哈希操作,因此经常导致不良的负载平衡。由于哈希冲突和少量大业务,数据中心的结构经常会严重失衡。ecmp与小流(flowlet)交换耦合可以在每次进行小流交换时选择新路径,从而在某种程度上改善负载平衡。然而,ecmp使用本地决策在等成本路径之间分割业务,而在任何所选路径的下游中没有关于任何可能的拥塞或链路故障的任何反馈。结果,即使网络可能具有内置的冗余,故障也可能会大大降低有效吞吐量。
另一流调度技术(称为hedera)尝试为数据中心网络提供动态流调度。hedera从组成的交换机收集流信息,计算流的无冲突路径,并指示交换机相应地重新路由业务。通过对路由和业务需求进行高级了解,hedera尝试使调度系统能够看到负载交换元素无法克服的瓶颈。然而,对于当今数据中心的业务波动性而言,hedera太慢了,因为它需要在做出重新分配决策之前监测流一段时间及其估计的理想需求。
mptcp(多路径传输控制协议)是另一示例流调度技术。mptcp将大型tcp流分割为多个tcp流,并且有效负载在mptcp流之间被条带化,使得每个mptcp流都足够小,以至于不会因哈希冲突而出现ecmp瓶颈。然而,mptcp确实需要对最终主机网络堆栈进行改变,而这些改变通常不受网络操作者的控制。即使网络操作者确实可以控制网络堆栈,一些高带宽低时延的应用(诸如,存储业务)也可能绕过内核并实现自己的运输。mptcp进一步增加了本已复杂的运输层的复杂性,而这些复杂的传输层又承受了当今数据中心的低时延和突发吸收要求。
作为另一示例,conga(数据中心的分布式拥塞感知负载平衡)将tcp流分割为小流,估计结构路径中的实时拥塞,并基于来自远程交换机的反馈将小流分配给路径。来自远程交换机的反馈使conga能够无缝处理不对称性,而无需进行任何tcp修改。然而,conga必须作为新网络结构的一部分在定制的asic中被实现,以便能够在微秒内对拥塞做出反应。
当今数据中心中明显的一些问题总结如下:
·尽管内置冗余,但由于负载失衡而导致结构使用不足。
·结构无法对业务模式变化做出反应,并且组件/链路故障导致效率进一步降低
·tcp拥塞避免使用aimd(加法式增加/乘法式减少)机制,其具有多种拥塞管理算法,只要网络遇到拥塞,都会导致业务流波动。
·终端主机处缺少许可控制,因此需要主机之间进行tcp慢速启动,以防止终端和网络资源超额订阅,但要以时延为代价。
·诸如ecn(显式拥塞通知)等复杂算法会对本地交换机元素所见的本地业务拥塞做出反应,并取决于业务配置文件(profile)和网络拓扑,导致tcp添头之间的不公平,这是以拥塞控制为代价的。
本公开描述了一种新的数据传输协议,在本文中称为结构控制协议(fcp),被设计为解决当今数据中心中的一些问题。在各种示例实现中,fcp可以显著提高网络吞吐量,诸如,90%或更高。本文描述的建议协议和技术与现有协议有许多示例差异,依次如下所述。可以按照任何组合和子组合使用以下示例,以提供本文描述的技术的各种实现。而且,fcp可以代替其他传输协议或与其他传输协议结合使用。
作为第一示例,如本文所描述的,fcp可以提供结构许可控制。源节点为每个目的地节点和业务类别维护一个队列。在结构上传输分组之前,源节点通过向目的地节点发送请求消息以请求传送一定数量的字节来请求许可。在保留出口带宽之后,目的地节点将授权消息发送到源。然后,源节点传输分组,直到它将所授权的字节数发送到目的地为止(在分组边界处停止)。
第二,如果需要的话,fcp使得能够将相同分组流的分组喷射到源节点和目的地节点之间的所有可用路径。例如,数据中心网络具有从源节点通过典型的叶/主干拓扑到达目的地节点的许多路径。传统上,为了维持tcp流的分组顺序,交换元素通过5元组哈希和ecmp转发算法来确定流的路径。流的所有分组(基于哈希桶)都在同一路径上行进,以避免分组重排序。连接网络中的多层交换机的路径使用低带宽链路。低带宽链路限制了tcp流所承载的最大带宽。fcp允许将分组喷射到源节点和目的地节点之间的所有可用链路,从而限制了tcp流的大小。源节点向每个分组指派(assign)一个分组序列号。目的地节点可以使用分组序列号将传入的分组按顺序排列,然后再将其递送到更高层(诸如,tcp)。
第三,fcp的示例实现可以用于提供针对请求/授权分组丢失和乱序递送的弹性。请求消息和授权消息不需要由端节点重排序,并且不承载分组序列号。请求/授权消息使用基于滑动窗口的标记来传递大小信息,从而使请求/授权消息的基础运输能够抵御丢失/丢弃或乱序递送。如上所述,承载有效负载的数据分组被目的地节点使用分组序列号显式地重排序。分组丢失是通过重排序超时来处理的,并且丢失是通过更高级别(诸如,通过重传的tcp)来恢复的。
第四,fcp支持自适应和低时延的结构实现。源/目的地节点通过传出请求和授权消息使用自适应带宽控制技术,这些消息对由结构故障导致的长期结构拥塞做出反应。通过自适应地控制请求和授权速率,控制进入/离开结构的数据量。通过经由授权速率限制使目的地节点的吞吐量略低于最大支持的吞吐量,fcp维持无拥塞的结构操作,从而为遍历通过结构的分组实现可预测的时延。
第五,在一些示例中,fcp提供了故障恢复,可适应网络交换机/链路故障,以将影响降至最低。fcp会采用硬件在往返时间(rtt)内检测到的任何结构故障,以使分组丢失最小化。
第六,在一些示例中,fcp已经减少或最小化了协议开销成本。fcp涉及要在节点之间传送的有效负载的每个分段的显式请求/授权消息交换。为了便于协议操作,有效负载分组通过udp+fcp报头封装。fcp以时延和一定量的带宽为代价提供了此处列出的各种优点。经由未经请求的分组传输而无需显式的请求授权握手(handshake),将时延影响最小化到小的流。
第七,在一些示例中,fcp为未经请求的分组传送提供支持。fcp允许将有限的结构带宽用于从发送器向接收器发送未经请求的分组(无显式的请求-授权握手)。在接收器处,可以配置少量的信用,以允许少量的带宽用于未经请求的传送。仅从非常浅的队列(基于阈值)允许未经请求的业务。请求/授权速率限制器会针对未经请求的业务和非fcp业务进行调整,以免造成持续的结构拥塞。
第八,在一些示例中,fcp为支持/不支持fcp的节点共存提供支持。fcp允许不支持fcp的节点(非fcp)与支持fcp的节点共存于同一网络中。非fcp节点可以使用ecmp或任何其他模式的分组运输和负载平衡。
第九,在一些示例中,fcp提供了流感知的公平带宽分配。通过目的地节点处的流感知许可控制调度器来管理业务。请求/授权机制使用“拉取”模型(经由授权),并确保在添头流之间实现流感知的公平带宽分配。
第十,在一些示例中,fcp通过自适应请求窗口缩放来提供传输缓冲器管理。目的地节点基于活动的添头流的全局视图提供比例因子。源节点基于比例因子调整未完成的请求窗口,从而基于其流失速率限制每个fcp队列使用的总传输缓冲器。因此,基于它们相应的流失速率,传输缓冲器有效地用于各种大小流。
第十一,在一些示例中,fcp启用基于接收缓冲器占用率的授权管理。fcp通过显式的授权步测算法来控制授权的生成。授权生成做出反应以接收缓冲器占用率、结构中已授权块的数量以及重排序缓冲器中的块的数量。
第十二,在一些示例中,fcp支持改进的端到端qos。fcp通过目的地处的授权调度器提供了改进的端到端qos。目的地查看基于优先级而被分成组的来自多个源的传入请求,并基于优先级组之间的期望qos行为调度授权。假设由于许可控制,fcp实现了低时延的结构操作,那么qos感知授权调度将从基础结构中移除qos行为的任何依赖性。
第十三,在一些示例中,fcp通过加密和端到端认证来支持安全性。fcp通过加密支持端到端隐私,还支持对fcp分组的认证,从而保护所有fcp特定协议握手。
第十四,在一些示例中,fcp启用改进的ecn标记支持。fcp授权调度器基于在授权调度器处看到的所有未决请求的总数提供总负载的唯一视图。基于目的地端点看到的全局负载的ecn标记相对于基于通过结构的各个交换机/路径看到的局部拥塞的ecn标记提供了重大改进。由于数据中心tcp实现依赖于ecn的广泛使用来管理拥塞,因此与通过结构的一些路径的不连续视图和局部视图相比,基于授权调度器处的输出出口队列的全局视图的ecn标记具有显著改进,并且在tcp级别提供更好的拥塞管理。
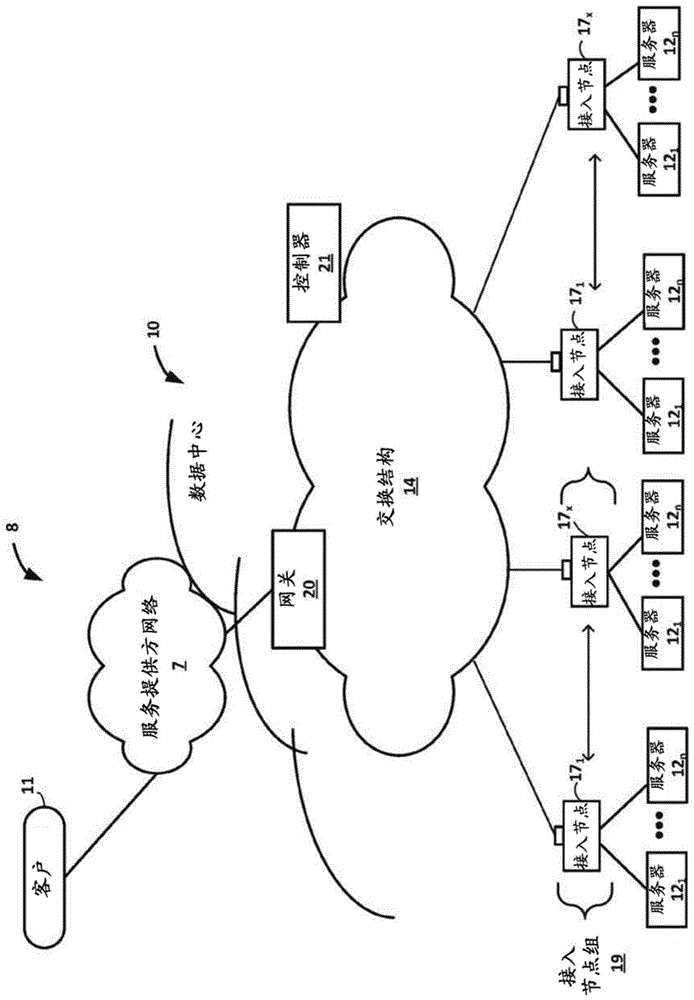
图1是图示了可以实现本文描述的技术的示例的具有数据中心10的示例系统8的框图。通常,数据中心10为通过内容/服务提供方网络7和网关设备20耦合到数据中心的客户11提供应用和服务的操作环境。在其他示例中,内容/服务提供方网络7可以是数据中心广域网(dcwan)、专用网络或其他类型的网络。数据中心10可以例如托管基础设施设备,诸如,计算节点、联网和存储系统、冗余电源和环境控制。内容/服务提供方网络7可以被耦合至由其他提供方管理的一个或多个网络,并因此可以形成大规模公共网络基础设施的一部分,例如,互联网。
在一些示例中,数据中心10可以表示许多地理上分布的网络数据中心之一。在图1的示例中,数据中心10是为客户11提供信息服务的设施。客户11可以是诸如企业和政府等集体实体、或个人。例如,网络数据中心可以为多个企业和最终用户托管web服务。其他示例性服务可以包括数据存储、虚拟专用网络、文件服务服务、数据挖掘服务、科学计算或超级计算服务等。
在该示例中,数据中心10包括存储系统的集合和经由高速交换结构14互连的应用服务器12。在一些示例中,服务器12被布置成多个不同的服务器组,每个服务器组包括任何数量的服务器,多达例如n个服务器121–12n。服务器12为与客户11相关联的应用和数据提供计算和存储设施,并且可以是物理(裸机)服务器、在物理服务器上运行的虚拟机、在物理服务器上运行的虚拟化容器、或其组合。
在图1的示例中,软件定义网络(sdn)控制器21提供了高级控制器,以用于配置和管理数据中心10的路由和交换基础设施。sdn控制器21提供了逻辑上并且在一些情况下是物理上集中的控制器,以用于根据本公开的一个或多个实施例利于数据中心10内的一个或多个虚拟网络的操作。在一些示例中,sdn控制器21可以响应于从网络管理员接收到的配置输入而操作。
在一些示例中,根据本文描述的技术,sdn控制器21操作以将接入节点17配置为逻辑上建立一个或多个虚拟结构作为在由交换结构14提供的物理底层网络之上动态配置的覆盖网络。下面关于图20描述虚拟结构和接入节点建立虚拟结构的操作。
例如,尽管未示出,但是数据中心10还可以包括一个或多个非边缘交换机、路由器、集线器、网关、诸如防火墙、入侵检测和/或入侵预防设备之类的安全设备、服务器、计算机终端、膝上型电脑、打印机、数据库、诸如蜂窝电话或个人数字助理等无线移动设备、无线接入点、桥接器、电缆调制解调器、应用加速器或其他网络设备。
在图1的示例中,每个服务器12通过接入节点17被耦合到交换结构14。如本文进一步描述的,在一个示例中,每个接入节点17是高度可编程的i/o处理器,其被专门设计用于从服务器12卸载某些功能。在一个示例中,每个接入节点17包括一个或多个处理核,其由多个内部处理器集群(例如mips核)组成,配备有卸载加密功能、压缩和正则表达式(regex)处理、数据存储功能和联网操作的硬件引擎。通过这种方式,每个接入节点17包括用于代表一个或多个服务器12完全实现和处理网络和存储堆栈的组件。另外,接入节点18可以被编程配置为充当其相应服务器12的安全网关,释放服务器的处理器以将资源专用于应用工作负载。在一些示例实现中,每个接入节点17可以被视为网络接口子系统,该网络接口子系统实现了数据分组的处理的全部卸载(在服务器存储器中具有零副本)和所附接的服务器系统的存储加速。在一个示例中,每个接入节点17可以被实现为一个或多个专用集成电路(asic)或其他硬件和软件组件,每个都支持服务器的子集。
接入节点17也可以称为数据处理单元(dpu)或包括dpu的设备。换言之,术语接入节点在本文中可以与术语dpu互换使用。在于2018年7月10日提交的标题为“dataprocessingunitforcomputenodesandstoragenodes(用于计算节点和存储节点的数据处理单元)”的美国专利申请号16/031,921(代理人案号1242-004us01)和于2018年7月10日提交的标题为“dataprocessingunitforstreamprocessing(用于流处理的数据处理单元)”的美国专利申请号16/031,945(代理人案号1242-048us01)中描述了各种示例dpu的附加示例细节,其每一个的全部内容通过引用并入本文。
在示例实现中,接入节点17可配置为在具有一个或多个接入节点的独立网络设备中操作。例如,接入节点17可以被布置成多个不同的接入节点组19,每个接入节点组包括多达例如x个接入节点171–17x的任何数量的接入节点。这样,可以将多个接入节点17分成组(例如,在单个电子设备或网络设备内),在本文中称为接入节点组19,以用于向由位于设备内部的接入节点集合支持的一组服务器提供服务。在一个示例中,接入节点组19可以包括四个接入节点17,每个接入节点支持四个服务器,以便支持一组十六个服务器。
在图1的示例中,每个接入节点17提供与不同组的服务器12的交换结构14的连接,并且可以被指派相应的ip地址,并且为耦合到其的服务器12提供路由操作。如本文所描述的,接入节点17提供路由和/或交换功能以用于来自/指向相应服务器12的通信。例如,如图1所示,每个接入节点17包括面向边缘的电气或光学本地总线接口的集合以用于与服务器12的相应组进行通信、以及一个或多个面向核的电气或光学接口以用于与交换结构14内的核心交换机进行通信。另外,本文描述的接入节点17可以提供附加服务,诸如,存储(例如,固态存储设备的集成)、安全性(例如,加密)、加速(例如,压缩)、i/o卸载等。在一些示例中,一个或多个接入节点17可以包括存储设备,诸如,高速固态驱动器或旋转硬盘驱动器,其被配置为提供网络可访问的存储装置以供在服务器上执行的应用使用。尽管未在图1中示出,但是接入节点17可以彼此直接耦合,诸如,公共接入节点组19中的接入节点之间的直接耦合,以提供相同组的接入节点之间的直接互连性。例如,多个接入节点17(例如,4个接入节点)可以位于公共接入节点组19内,以服务一组服务器(例如,16个服务器)。
作为一个示例,多个接入节点17的每个接入节点组19可以被配置为独立的网络设备,并且可以被实现为占用设备机架的两个机架单元(例如,插槽)的两个机架单元(2ru)设备。在另一示例中,接入节点17可以被集成在服务器内,诸如,单个1ru服务器,其中四个cpu被耦合到在公共计算设备内部署的母板上的本文描述的转发asic。在又一示例中,接入节点17和服务器12中的一个或多个可以以合适的大小(例如,10ru)框架被集成,在这种示例中,其可以成为针对数据中心10的网络存储计算单元(nscu)。例如,接入节点17可以被集成在服务器12的母板内,或者以其他方式与服务器位于单个底盘中。
根据本文的技术,描述了示例实现,其中接入节点17接口连接并利用交换结构14,以便提供全网格(任何到任何)互连性,使得服务器12中的任何一个可以使用数据中心10内的多个并行数据路径中的任何一个来将给定分组流的分组数据传递到服务器中的任何其他服务器。描述了示例网络架构和技术,其中在示例实现中,接入节点为接入节点之间的分组流跨数据中心交换结构14中的多个并行数据路径中的一些或所有数据路径喷射各个分组,并且可选地对分组进行重排序来递送到目的地,以便提供全网格连接性。
如本文所描述的,本发明的技术引入了被称为结构控制协议(fcp)的新数据传输协议,其可以被任何接入节点17的不同操作联网组件所使用,以利于跨交换结构14的数据通信。如进一步所描述的,fcp是端到端许可控制协议,其中在一个示例中,发送器显式地请求接收器传送一定数量的有效负载数据字节。作为响应,接收器基于其缓冲器资源、qos和/或结构拥塞度量来发出授权。通常,fcp使得能够将流的分组喷射到源和目的地节点之间的所有路径,并且可以提供本文描述的任何优点和技术,包括针对请求/授权分组丢失的弹性,自适应和低时延的结构实现,故障恢复,减少的或最小协议开销成本,对未经请求的分组传送的支持,对支持/不支持fcp的节点共存的支持,流感知的公平带宽分配,通过自适应请求窗口缩放的传输缓冲器管理,基于接收缓冲器占用率的授权管理,改进的端到端qos,通过加密和端到端认证的安全性和/或改进的ecn标记支持。
这些技术可以提供某些优点。例如,这些技术可以显著提高底层交换结构14的带宽利用率。而且,在示例实现中,这些技术可以在数据中心的服务器之间提供全网格互连性,并且仍然可以是无阻塞且无丢弃的。更具体地,基于fcp的端到端许可控制机制并且基于分组与可用带宽成比例地喷射,交换结构14可以包括高效的无丢弃结构,而不使用链路级流控制。
尽管在图1中关于数据中心10的交换结构14描述了接入节点17,但是在其他示例中,接入节点可以在任何分组交换网络上提供全网格互连性。例如,分组交换网络可以包括局域网(lan)、广域网(wan)或者一个或多个网络的集合。分组交换网络可以具有任何拓扑,例如,平坦的或多层的,只要接入节点之间存在全连接性。分组交换网络可以使用任何技术,包括通过以太网的ip以及其他技术。不管分组交换网络的类型如何,根据本公开中描述的技术,接入节点可以在接入节点之间并且跨分组交换网络中的多个并行数据路径喷射分组流的各个分组,并且可选地,对分组重排序来递送到目的地,以便提供全网格连接性。
图2是进一步详细地图示了由数据中心内的接入节点17和交换结构14提供的逻辑互连性的框图。如该示例所示,接入节点17和交换结构14可以被配置为提供全网格互连性,使得接入节点17可以使用到核心交换机22a-22m(统称为“核心交换机22”)中的任何一个的多个m个并行数据路径中的任何一个来将服务器12中的任何一个的分组数据传递到服务器12中的任何其他服务器。而且,根据本文描述的技术,可以按照使得交换结构14中的m个并行数据路径在服务器12之间提供减少的l2/l3跳和全网格互连(例如,二分图)的方式来配置和布置接入节点17和交换结构14,即使在具有成千上万个服务器的大型数据中心中。要注意的是,在该示例中,交换机22未彼此连接,这使得一个或多个交换机的任何故障将彼此独立的可能性更大。在其他示例中,可以像在clos网络中一样,使用多层互连交换机来实现交换结构本身。
在一些示例实现中,因此,每个接入节点17可以具有多个并行数据路径以到达任何给定的其他接入节点17、以及通过那些接入节点可到达的服务器12。在一些示例中,不限于将给定流的所有分组沿着交换结构中的单个路径发送,交换结构14可以被配置为使得对于服务器12之间的任何给定分组流,接入节点17可以跨交换结构14的m个并行数据路径中的所有数据路径或数据路径子集喷射分组流的分组,通过该并行数据路径可以到达目的地服务器12的给定的目的地接入节点17。
根据所公开的技术,接入节点17可以跨m个路径首尾相连地喷射各个分组流的分组,从而在源接入节点和目的地接入节点之间形成虚拟隧道。通过这种方式,交换结构14中所包括的层数或沿着m个并行数据路径的跳数对于实现本公开中描述的分组喷射技术可能无关紧要。
然而,跨交换结构14的m个并行数据路径中的所有数据路径或数据路径子集喷射各个分组流的分组的技术使得交换结构14内的网络设备的层数减少到例如绝对最小值,即1。进一步地,它使交换机不彼此连接的结构架构成为可能,降低了两个交换机之间的故障相关的可能性,从而提高了交换结构的可靠性。扁平化交换结构14可以通过消除需要电力的网络设备的层来减少成本,并且通过消除执行分组交换的网络设备的层来减少时延。在一个示例中,交换结构14的扁平拓扑可以导致核层,该核层仅包括一层主干交换机,例如核心交换机22,其可以不彼此直接通信而是沿着m个并行数据路径形成单跳。在该示例中,将业务供应到交换结构14中的任何接入节点17可以通过由核心交换机22之一进行的单个一跳l3查找来到达任何其他接入节点17。
为源服务器12供应分组流的接入节点17可以使用用于跨可用的并行数据路径喷射分组的任何技术,诸如,可用带宽、随机、循环、基于哈希或其他机制,其可以被设计成例如最大化带宽的利用率或以其他方式避免拥塞。在一些示例实现中,不一定需要利用基于流的负载平衡,并且可以通过允许服务器12所供应的给定分组流(五个元组)的分组在耦合到源和目的地服务器的接入节点17之间遍历交换结构14的不同路径来使用更有效的带宽利用率。在一些示例中,与目的地服务器12相关联的相应目的地接入节点17可以被配置为将分组流的可变长度ip分组重排序为发送它们的原始序列,并将重排序的分组递送到目的地服务器。
在其他示例中,与目的地服务器12相关联的相应目的地接入节点17可以在将分组递送到目的地服务器之前不重排序分组流的分组。在这些示例中,目的地接入节点17可以代替地按照分组到达目的地接入节点17的顺序将分组递送到目的地服务器。例如,包括存储访问请求或对目的地存储设备的响应的分组可以无需被重排序为发送它们的原始序列。相反,可以按照它们到达的顺序将这种存储访问请求和响应递送到目的地存储设备。
在一些示例实现中,每个接入节点17实现至少四个不同的操作联网组件或功能:(1)源组件,其可操作以从服务器12接收业务,(2)源交换组件,其可操作以将源业务交换到不同接入节点17(可能是不同接入节点组)的其他源交换组件或核心交换机22,(3)目的地交换组件,其可操作以交换从其他源交换组件或核心交换机22接收到的入站业务,以及(4)目的地组件,其可操作以对分组流进行重排序并将分组流提供给目的地服务器12。
在该示例中,服务器12被连接到接入节点17的源组件以将业务注入交换结构14中,并且服务器12类似地被耦合到接入节点17内的目的地组件以从中接收业务。由于交换结构14所提供的全网格并行数据路径,给定接入节点17中的每个源交换组件和目的地交换组件不需要执行l2/l3交换。相反,接入节点17可以例如基于可用带宽、随机地、循环地、服务质量(qos/调度或其他方式应用喷射算法来喷射分组流的分组,以有效地转发分组而无需进行分组分析和查找操作。
接入节点17的目的地交换组件可以提供仅用于选择适当的输出端口以将分组转发到本地服务器12所必需的有限查找。这样,关于数据中心的完整路由表,仅核心交换机22可以需要执行完整的查找操作。因此,交换结构14提供了高度可扩展的、平坦的、高速的互连,其中在一些实施例中,服务器12实际上是来自数据中心内的任何其他服务器12的一个l2/l3跳。
接入节点17可能需要连接到相当数量的核心交换机22,以便将分组数据传递到任何其他接入节点17和可通过那些接入节点访问的服务器12。在一些情况下,为了提供链路乘法效应,接入节点17可以经由架顶(tor)以太网交换机、电置换设备或光学置换(op)设备(未在图2中示出)连接至核心交换机22。为了提供附加的链路乘法效应,接入节点17的源组件可以被配置为跨一个或多个接入节点组19中所包括的其他接入节点17的集合喷射从服务器12接收到的业务的各个分组流的分组。在一个示例中,接入节点17可以通过接入节点间的喷射来实现8倍乘法效应,并且通过op设备来实现附加的8倍乘法效应,以连接至多达六十四个核心交换机22。
通过网络在等成本多路径(ecmp)路径上进行基于流的路由和交换可能会受到高度可变的负载相关时延的影响。例如,网络可以包括许多小带宽流和一些大带宽流。在路由和交换ecmp路径的情况下,源接入节点可以为两个较大的带宽流选择相同的路径,从而导致该路径上的较大时延。为了避免该问题并在网络上保持较低的时延,例如,管理员可能被迫将网络利用率保持在25-30%以下。在本公开中描述的配置接入节点17以在所有可用路径上喷射各个分组流的分组的技术能够在维持有界限或受限制的时延的同时实现更高的网络利用率,例如85-90%。分组喷射技术使源接入节点17能够在考虑链路故障的同时在所有可用路径上公平地分配给定流的分组。通过这种方式,无论给定流的带宽大小如何,负载都可以公平地分布在整个网络的可用路径上,以避免过度利用特定路径。所公开的技术使相同数量的网络设备能够通过网络传递三倍的数据业务量,同时保持低时延特性并减少消耗能量的网络设备的层数。
如图2的示例中所示,在一些示例实现中,可以将接入节点17布置成多个不同的接入节点组191-19y(图2中的ang),每个接入节点组包括多达例如x个接入节点171–17x的任何数量的接入节点17。这样,可以将多个接入节点17分成组和布置(例如,在单个电子设备或网络设备内),在本文中称为接入节点组(ang)19,以向由位于设备内部的接入节点集合支持的一组服务器提供服务。
如所描述的,每个接入节点组19可以被配置为独立的网络设备,并且可以被实现为被配置为安装在计算机架、存储机架或融合机架内的设备。通常,每个接入节点组19可以被配置为充当高性能i/o集线器,该高性能i/o集线器被设计为聚合和处理多个服务器12的网络和/或存储i/o。如上所述,每个接入节点组19内的接入节点集合17提供了高度可编程的专用i/o处理电路,以代表服务器12处理联网和通信操作。另外,在一些示例中,每个接入节点组19可以包括存储设备27,诸如,高速固态硬盘驱动器,其被配置为提供网络可访问存储,以供在服务器上执行的应用使用。包括其接入节点集合17、存储设备27以及该接入节点组的接入节点17所支持的服务器集合12的每个接入节点组19在本文中可以被称为网络存储计算单元(nscu)40。
图3是图示了包括接入节点组19及其支持的服务器52的网络存储计算单元(nscu)40的一个示例的框图。接入节点组19可以被配置为充当被设计为聚合和处理到多个服务器52的网络和存储i/o的高性能i/o集线器。在图3的特定示例中,接入节点组19包括连接到本地固态存储装置41的池的四个接入节点171-174(统称为“接入节点17”)。在所图示的示例中,接入节点组19支持总共十六个服务器节点121-1216(统称为“服务器节点12”),其中接入节点组19内的四个接入节点17中的每个都支持四个服务器节点12。在一些示例中,由每个接入节点17支持的四个服务器节点12中的每个可以被布置为服务器52。在一些示例中,贯穿本申请描述的“服务器12”可以是双插槽或双处理器“服务器节点”,其以独立服务器设备内的两个或更多个成组地被布置,例如,服务器52。
尽管在图3中将接入节点组19图示为包括全部连接到固态存储装置41的单个池的四个接入节点17,但是可以按照其他方式布置接入节点组。在一个示例中,四个接入节点17中的每一个可以被包括在单独接入节点底座(sled)上,该底座还包括固态存储装置和/或该接入节点的其他类型的存储装置。在该示例中,接入节点组可以包括四个接入节点底座,每个底座具有本地存储设备的集合和接入节点。
在一个示例实现中,接入节点组19内的接入节点17使用外围组件互连高速(pcie)链路48、50连接到服务器52和固态存储装置41,并使用以太网链路42、44、46连接到其他接入节点和数据中心交换结构14。例如,每个接入节点17可以支持六个高速以太网连接,包括用于与交换结构通信的两个外部可用的以太网连接42、用于与其他接入节点组中的其他接入节点通信的一个外部可用的以太网连接44以及用于与同一接入节点组19中的其他接入节点17通信的三个内部以太网连接46。在一个示例中,每个外部可用的连接42可以是100千兆以太网(ge)连接。在该示例中,接入节点组19具有8x100ge外部可用端口以连接到交换结构14。
在接入节点组19内,连接42可以是铜线,即,电气链路,被布置在每个接入节点17和接入节点组19的光学端口之间作为8x25ge链路。在接入节点组19和交换结构之间,连接42可以是耦合到接入节点组19的光学端口的光学以太网连接。光学以太网连接可以连接到交换结构内的一个或多个光学设备,例如下面更详细地描述的光学置换设备。光学以太网连接可以比电气连接支持更多的带宽,而无需增加交换结构中的电缆数量。例如,耦合到接入节点组19的每个光缆可以承载4x100ge光纤,每个光纤承载四种不同波长或λ的光学信号。在其他示例中,外部可用连接42可以保留为与交换结构的以太网电连接。
每个接入节点17支持的其余四个以太网连接包括:一个以太网连接44,用于与其他接入节点组内的其他接入节点进行通信;以及三个以太网连接46,用于与同一接入节点组19内的其他三个接入节点进行通信。在一些示例中,连接44可以被称为“接入节点组间链路”,并且连接46可以被称为“接入节点组内链路”。
以太网连接44、46在给定结构单元内的接入节点之间提供全网格连接性。在一个示例中,这种结构单元在本文中可以被称为逻辑机架(例如,半机架或半物理机架),其包括具有两个agn19的两个nscu40,并支持这些agn的八个接入节点17的8向网格。在该特定示例中,连接46将在同一接入节点组19内的四个接入节点17之间提供全网格连接性,并且连接44将在每个接入节点17与逻辑机架(即,结构单元)的一个其他接入节点组内的四个其他接入节点之间提供全网格连接性。另外,接入节点组19可以具有足够的(例如,16个)外部可用的以太网端口,以连接到另一接入节点组中的四个接入节点。
在接入节点的8向网格(即,两个nscu40的逻辑机架)的情况下,接入节点17中的每个可以通过50ge连接而被连接至其他七个接入节点中的每个。例如,同一接入节点组19内的四个接入节点17之间的每个连接46可以是被布置为2x25ge链路的50ge连接。四个接入节点17与另一接入节点组中的四个接入节点之间的连接44中的每个可以包括四个50ge链路。在一些示例中,四个50ge链路中的每一个可以被布置为2x25ge链路,使得连接44中的每一个包括到另一接入节点组中的其他接入节点的8x25ge链路。下面关于图5更详细地描述该示例。
在另一示例中,以太网连接44、46在给定结构单元内的接入节点之间提供全网格连接性,该结构单元是全机架或全物理机架,其包括具有四个agn19的四个nscu40,并且支持那些agn的接入节点17的16向网格。在该示例中,连接46在同一接入节点组19内的四个接入节点17之间提供全网格连接性,并且连接44在每个接入节点17与三个其他接入节点组内的十二个其他接入节点之间提供全网格连接性。另外,接入节点组19可以具有足够的(例如,48个)外部可用的以太网端口,以连接到另一接入节点组中的四个接入节点。
在接入节点的16向网格的情况下,例如,每个接入节点17可以通过25ge连接被连接到其他十五个接入节点中的每个。换言之,在该示例中,同一接入节点组19内的四个接入节点17之间的每个连接46可以是单个25ge链路。四个接入节点17与三个其他接入节点组中的十二个其他接入节点之间的连接44中的每个可以包括12x25ge链路。
如图3所示,接入节点组19内的每个接入节点17还可以支持高速pcie连接48、50的集合,例如,pciegen3.0或pciegen4.0连接,用于与接入节点组19内的固态存储装置41进行通信,并且与nscu40内的服务器52进行通信。服务器52中的每一个包括由接入节点组19内的接入节点17之一支持的四个服务器节点12。固态存储装置41可以是每个接入节点17可经由连接48访问的基于非易失性存储器高速(nvme)的固态驱动器(ssd)存储设备。
在一个示例中,固态存储装置41可以包括二十四个ssd设备,其中每个接入节点17具有六个ssd设备。二十四个ssd设备可以被布置成四行六个ssd设备,ssd设备的每行被连接到接入节点17中的一个。每个ssd设备可以提供多达16兆兆字节(tb)的存储空间,每个接入节点组19总共384tb。如下面更详细地描述的,在一些情况下,物理机架可以包括四个接入节点组19及其受支持的服务器52。在这种情况下,典型的物理机架可以支持大约1.5千兆字节(pb)的本地固态存储。在另一示例中,固态存储装置41可以包括多达32个u.2x4ssd设备。在其他示例中,nscu40可以支持其他ssd设备,例如,2.5”串行ata(sata)ssd、微型sata(msata)ssd、m.2ssd等。
在上述示例中,其中每个接入节点17被包括在具有接入节点的本地存储装置的单独接入节点底座上,每个接入节点底座可以包括四个ssd设备以及一些附加存储装置,其可以是硬盘驱动器或固态驱动器设备。在该示例中,四个ssd设备和附加存储装置可以为每个接入节点提供与先前示例中描述的六个ssd设备大致相同的存储量。
在一个示例中,每个接入节点17支持总共96个pcie通道。在该示例中,每个连接48可以是8x4通道pcigen3.0连接,经由该连接,每个接入节点17可以与固态存储装置41内的多达八个ssd设备通信。另外,在给定接入节点17与接入节点17所支持的服务器52内的四个服务器节点12之间的每个连接50可以是4x16通道pciegen3.0连接。在该示例中,接入节点组19总共具有与服务器52接口连接的256个面向外部的pcie链路。在一些场景中,接入节点17可以支持冗余服务器连接性,使得每个接入节点17使用8x8通道pciegen3.0连接来连接到两个不同的服务器52内的八个服务器节点12。
在另一示例中,每个接入节点17支持总共64个pcie通道。在该示例中,每个连接48可以是8x4通道pcigen3.0连接,经由该连接,每个接入节点17可以与固态存储装置41内的多达八个ssd设备通信。另外,在给定接入节点17与接入节点17所支持的服务器52内的四个服务器节点12之间的每个连接50可以是4x8通道pciegen4.0连接。在该示例中,接入节点组19总共具有128个面向外部的pcie链路,这些链路与服务器52接口连接。
图4是图示了包括来自图3的两个nscu401和402的示例逻辑机架布置60的框图。在一些示例中,基于被“夹在”顶部的两个服务器52和底部的两个服务器52之间的接入节点组19的结构布置,每个nscu40可以被称为“计算三明治”。例如,服务器52a可以被称为顶部第二服务器,服务器52b可以被称为顶部服务器,服务器52c可以被称为底部服务器,并且服务器52d可以被称为底部第二服务器。每个服务器52可以包括四个服务器节点,并且每个服务器节点可以是双插槽或双处理器服务器底座。
每个接入节点组19使用pcie链路50连接到服务器52,并使用以太网链路42连接到交换结构14。接入节点组191和191可以各自包括使用以太网链路彼此连接的四个接入节点以及使用上面关于图3所描述的pcie链路连接到接入节点的本地固态存储装置。接入节点组191和192内的接入节点在全网格64中彼此连接,这将关于图5更详细地被描述。
另外,每个接入节点组19支持到服务器52的pcie连接50。在一个示例中,每个连接50可以是4x16通道pciegen3.0连接,使得接入节点组19总共具有与服务器52接口连接的256个外部可用的pcie链路。在另一示例中,每个连接50可以是4x8通道pciegen4.0连接,用于在接入节点组19内的接入节点与服务器52内的服务器节点之间进行通信。在任一示例中,在不考虑任何开销带宽成本的情况下,连接50可以提供每个接入节点19的512千兆位的原始吞吐量或每个服务器节点的大约128千兆位的带宽。
如上面关于图3所讨论的,每个nscu40支持从接入节点组19到交换结构14的8×100ge链路42。每个nscu40因此为四个服务器52中的多达十六个服务器节点、本地固态存储装置和800gbps的全双工(即,双向)网络带宽提供支持。因此,每个接入节点组19可以提供服务器52的计算、存储、联网和安全性的真正超融合。因此,逻辑机架60(包括两个nscu40)为八个服务器52中的多达32个服务器节点、接入节点组19处的本地固态存储装置和到交换结构14的16x100ge链路42提供支持,这将导致每秒1.6兆兆位(tbps)的全双工网络带宽。
图5是图示了逻辑机架60内的两个接入节点组191、192之间的全网格连接性的示例的框图。如图5所图示的,接入节点组191包括四个接入节点171-174,并且接入节点组192还包括四个接入节点175-178。每个接入节点17以网格结构拓扑连接到逻辑机架内的其他接入节点。网格拓扑中所包括的八个接入节点17可以被称为接入节点“集群”。通过这种方式,每个接入节点17能够将传入分组喷射到集群中的每个其他接入节点。
在互连两个接入节点组19的8向网格的图示配置中,每个接入节点17经由全网格连接性连接到集群中的其他七个接入节点中的每个。接入节点17之间的网格拓扑包括同一接入节点组19中所包括的四个接入节点之间的接入节点组内链路46、以及接入节点组191中的接入节点171-174与接入节点组192中的接入节点175-178之间的接入节点组间链路44。尽管图示为每个接入节点17之间的单个连接,但是连接44、46中的每一个都是双向的,使得每个接入节点经由分离的链路连接到集群中的每个其他接入节点。
第一接入节点组191内的接入节点171-174中的每个具有到第一接入节点组191中的其他接入节点的三个接入节点组内连接46。如第一接入节点组191所图示的,接入节点171支持到接入节点174的连接46a、到接入节点173的连接46b、和到接入节点172的连接46c。接入节点172支持到接入节点171的连接46a、到接入节点174的连接46d、和到接入节点173的连接46e。接入节点173支持到接入节点171的连接46b、到接入节点172的连接46e和到接入节点174的连接46f。接入节点174支持到接入节点171的连接46a、到接入节点172的连接46d和到接入节点173的连接46f。接入节点175-178被类似地连接在第二接入节点组192内。
第一接入节点组191内的每个接入节点171-174还具有到第二接入节点组192内的接入节点175-178的四个接入节点组间连接44。如图5所图示的,第一接入节点组191和第二接入节点组192分别具有十六个外部可用端口66以彼此连接。例如,接入节点171通过第一接入节点组191的四个面向外部的端口66至第二接入节点组192的四个外部可用端口66来支持连接44a、44b、44c和44d,以到达接入节点175-178。具体地,接入节点171支持到第二接入节点组192内的接入节点175的连接44a、到第二接入节点组192内的接入节点176的连接44b、到第二接入节点组192内的接入节点177的连接44c以及到第二接入节点组192内的接入节点178的连接44d。第一接入节点组191内的其余接入节点172-174类似地被连接至第二接入节点组192内的接入节点175-178。另外,在相反的方向上,接入节点175-178类似地被连接到第一接入节点组191内的接入节点171-174。
每个接入节点17可以被配置为支持高达400千兆位的带宽以连接到集群中的其他接入节点。在所图示的示例中,每个接入节点17可以支持到其他接入节点的多达八个50ge链路。在该示例中,由于每个接入节点17仅连接到七个其他接入节点,因此可以保留50千兆位的带宽并用于管理接入节点。在一些示例中,连接44、46中的每个可以是单个50ge连接。在其他示例中,连接44、46中的每个可以是2x25ge连接。在其他示例中,接入节点组内连接46中的每个可以是2×25ge连接,并且接入节点组间连接44中的每个可以是单个50ge连接,以减少盒间电缆的数量。例如,从第一接入节点组191内的每个接入节点171-174,断开4x50ge链路以连接到第二接入节点组192中的接入节点175-178。在一些示例中,可以使用dac电缆从每个接入节点17取出4x50ge链路。
图6是图示了包括来自图4的两个逻辑机架60的完整物理机架70的示例布置的框图。在图6的所图示示例中,机架70具有垂直高度的42个机架单元或插槽,包括架顶(tor)设备72的2个机架单元(2ru),用于提供到交换结构14内的设备的连接性。在一个示例中,tor设备72包括架顶以太网交换机。在其他示例中,tor设备72包括光学置换器。在一些示例中,机架70可以不包括附加的tor设备72,而是具有典型的40个机架单元。
在所图示的示例中,机架70包括四个接入节点组191-194,每个接入节点组是高度为2ru的分离的网络设备。每个接入节点组19包括四个接入节点,并且可以如图3的示例中所示被配置。例如,接入节点组191包括接入节点an1-an4,接入节点组192包括接入节点an5-an8,接入节点组193包括接入节点an9-an12,并且接入节点组194包括接入节点an13-an16。接入节点an1-an16可以基本上类似于上述接入节点17。
在该示例中,每个接入节点组19支持十六个服务器节点。例如,接入节点组191支持服务器节点a1-a16,接入节点组192支持服务器节点b1-b16,接入节点组193支持服务器节点c1-c16,并且接入节点组194支持服务器节点d1-d16。服务器节点可以是宽度为1/2机架并且高度为1ru的双插槽或双处理器服务器底座。如关于图3所描述的,四个服务器节点可以被布置为高度为2ru的服务器52。例如,服务器52a包括服务器节点a1-a4,服务器52b包括服务器节点a5-a8,服务器52c包括服务器节点a9-a12,并且服务器52d包括服务器节点a13-a16。服务器节点b1-b16、c1-c16和d1-d16可以类似地被布置为服务器52。
接入节点组19和服务器52被布置为来自图3至图4的nscu40。nscu40的高度为10ru,并且每个都包括一个2ru接入节点组19和四个2ru服务器52。如图6所图示的,接入节点组19和服务器52可以被构造为计算三明治,其中每个接入节点组19被“夹”在顶部的两个服务器52和底部的两个服务器52之间。例如,关于接入节点组191,服务器52a可以被称为顶部第二服务器,服务器52b可以被称为顶部服务器,服务器52c可以被称为底部服务器,并且服务器52d可以被称为底部第二服务器。在所图示的结构布置中,接入节点组19由八个机架单元分开,以容纳由一个接入节点组支持的底部两个2ru服务器52和由另一接入节点组支持的顶部两个2ru服务器52。
nscu40可以被布置为逻辑机架60,即,来自图5的半物理机架。逻辑机架60的高度为20ru,并且每个包括具有全网格连接性的两个nscu40。在图6的所图示示例中,接入节点组191和接入节点组192以及它们相应的受支持的服务器节点a1-a16和b1-b16被包括在同一逻辑机架60中。如上面关于图5更详细地描述的,包括相同逻辑机架60的接入节点an1-an8以8向网格彼此连接。接入节点an9-an16可以类似地被连接在另一逻辑机架60内的8向网格中,该逻辑机架包括接入节点组193和194以及它们相应的服务器节点c1-c16和d1-d16。
机架70内的逻辑机架60可以直接或通过中间的架顶设备72被连接到交换结构。如上所述,在一个示例中,tor设备72包括架顶以太网交换机。在其他示例中,tor设备72包括光学置换器,该光学置换器在接入节点17和核心交换机22之间运输光学信号,并且被配置为使得光学通信基于波长被“置换”,以便提供上游和下游端口之间的全网格连接性,而没有任何光学干扰。
在所图示的示例中,每个接入节点组19可以经由接入节点组支持的8x100ge链路中的一个或多个连接到tor设备72,以到达交换结构。在一种情况下,机架70内的两个逻辑机架60可以各自连接至tor设备72的一个或多个端口,并且tor设备72还可以从相邻物理机架内的一个或多个逻辑机架接收信号。在其他示例中,机架70本身可能不包括tor设备72,而是逻辑机架60可以连接到一个或多个相邻物理机架中所包括的一个或多个tor设备。
针对40ru的标准机架大小,可能希望保持在典型的功率极限内,诸如15千瓦(kw)的功率极限。在机架70的示例中,不考虑附加的2rutor设备72,即使具有64个服务器节点和四个接入节点组,也可以容易地保持在15kw功率极限内或附近。例如,每个接入节点组19可以使用大约1kw的功率,从而产生用于接入节点组的大约4kw的功率。另外,每个服务器节点可以使用大约200w的功率,从而为服务器52产生大约12.8kw的功率。在该示例中,接入节点组19和服务器52的40ru布置因此使用大约16.8kw的功率。
图7a是示出了接入节点17内的联网数据路径和操作的逻辑视图的框图。如图7a的示例所示,在一些示例实现中,每个接入节点17实现至少四个不同的操作联网组件或功能:(1)源(sf)组件30,其可操作以从接入节点所支持的服务器12的集合接收业务,(2)源交换(sx)组件32,其可操作以将源业务交换至(可能是不同接入节点组的)不同接入节点17的其他源交换组件或交换至核心交换机22,(3)目的地交换(dx)组件34,其可操作以交换从其他源交换组件或核心交换机22接收的入站业务,以及(4)目的地(df)组件36,其可操作以对分组流进行重排序并将分组流提供给目的地服务器12。
在一些示例中,接入节点17的不同的操作联网组件可以为传输控制协议(tcp)分组流执行基于流的交换和基于ecmp的负载平衡。然而,通常,ecmp负载平衡很差,因为它会随机地将流哈希到路径,使得可能将一些大流指派给同一路径,并使结构严重不平衡。另外,ecmp依赖于本地路径决策,并且不使用有关任何选定路径的可能拥塞或下游链路故障的任何反馈。
在本公开中描述的技术引入了称为结构控制协议(fcp)的新数据传输协议,该新数据传输协议可以由接入节点17的不同操作联网组件使用。fcp是端到端许可控制协议,其中发送器显式地请求接收器以转移一定数量的有效负载数据字节。作为响应,接收器基于其缓冲器资源、qos和/或结构拥塞度量来发出授权。
例如,fcp包括许可控制机制,源节点通过该许可控制机制在将结构上的分组传输到目的地节点之前请求许可。例如,源节点向目的地节点发送请求消息,以请求传送一定数量的字节,并且目的地节点在保留出口带宽之后向源节点发送授权消息。另外,fcp使得单独分组流的分组能够在源节点和目的地节点之间的所有可用链路上被喷射,而不是用于在同一路径上发送tcp流的所有分组的基于流的交换和ecmp转发,以便避免分组重排序。源节点向流的每个分组指派分组序列号,并且目的地节点可以使用分组序列号来按顺序排列相同流的传入分组。
接入节点17的sf组件30被认为是结构的源节点。根据所公开的技术,针对fcp业务,sf组件30被配置为通过链路将其输入带宽(例如,200gbps)喷射到逻辑机架内的接入节点的多个sx组件。例如,如关于图7b更详细地描述的,sf组件30可以跨逻辑机架内的sx组件32和其他接入节点的七个其他sx组件的八个链路喷射相同流的分组。针对非fcp业务,sf组件30被配置为选择向其发送相同流的分组的连接的sx组件之一。
接入节点17的sx组件32可以从逻辑机架内的接入节点的多个sf组件(例如,逻辑机架内的sf组件30和其他接入节点的七个其他sf组件)接收传入的分组。针对fcp业务,sx组件32还被配置为通过链路将其传入带宽喷射到结构中的多个核心交换机。例如,如关于图8更详细地描述的,sx组件32可以跨8个链路将其带宽喷射到8个核心交换机。在一些情况下,sx组件32可以跨八个链路将其带宽喷射到四个或八个中间设备,例如,tor以太网交换机、电置换设备或光学置换设备,这些设备又将业务转发到核心交换机。针对非fcp业务,sx组件32被配置为选择向其发送相同分组流的分组的核心交换机之一。由于到sx组件32的传入带宽和来自sx组件32的传出带宽是相同的(例如,200gbps),因此即使针对大量的分组流,也不应该在sx阶段发生拥塞。
接入节点17的dx组件34可以直接地或者经由一个或多个中间设备(例如,tor以太网交换机、电置换设备或光学置换设备)从多个核心交换机接收传入分组。例如,dx组件34可以从八个核心交换机或者四个或八个中间设备接收传入分组。dx组件34被配置为选择向其发送接收到的分组的df组件。例如,dx组件34可以被连接到逻辑机架内的df组件36和其他接入节点的七个其他df组件。在一些情况下,dx组件34可能会成为拥塞点,因为dx组件34可能会接收到大量带宽(例如,200gbps),这些带宽都将被发送到同一df组件。在fcp业务的情况下,dx组件34可以使用fcp的许可控制机制来避免长期拥塞。
接入节点17的df组件36可以从逻辑机架内的接入节点的多个dx组件(例如,逻辑机架内的dx组件34和其他接入节点的七个其他dx组件)接收传入的分组。df组件36被认为是结构的目的地节点。针对fcp业务,df组件36被配置为在将流传输到目的地服务器12之前对相同流的分组重排序。
在一些示例中,接入节点17的sx组件32和dx组件34可以使用相同的转发表来执行分组交换。在该示例中,接入节点17的个性(personality)和由转发表标识的针对同一目的地ip地址的下一跳可以取决于所接收的数据分组的源端口类型。例如,如果从sf组件接收到源分组,则接入节点17作为sx组件32操作,并确定下一跳,以通过结构将源分组转发到目的地节点。如果从面向结构的端口接收到分组,则接入节点17作为dx组件34操作,并确定最终的下一跳以将传入的分组直接转发到目的地节点。在一些示例中,接收到的分组可以包括指定其源端口类型的输入标签。
图7b是图示了在逻辑机架60内的接入节点集合171-178之间实现的示例第一级网络扇出的框图。在图7b的所图示示例中,逻辑机架60包括两个接入节点组191和192,其包含八个接入节点171-178以及由每个接入节点支持的服务器节点12。
如图7b所示,逻辑机架60内的接入节点17的sf组件30a-30h和sx组件32a-32h具有全网格连接性,其中每个sf组件30被连接至逻辑机架60内的八个接入节点17的所有sx组件32。如上所述,逻辑机架60内的八个接入节点17可以通过以太网电连接的8向网格彼此连接。在fcp业务的情况下,逻辑机架60内的接入节点17的sf组件30应用喷射算法,以在到sx组件32的所有可用链路上为任何给定的分组流喷射分组。通过这种方式,sf组件30不必执行针对源自服务器12的分组流的出站分组的l2/l3交换的完全查找操作。换言之,给定分组流的分组可以由sf组件30(诸如,sf组件30a)接收,并被喷射在逻辑机架60的sx组件32的一些或所有链路上。通过这种方式,在该示例中,逻辑机架的接入节点17实现1:8的第一级扇出,并且在一些示例中可以这样做,而不会引起相对于分组报头中的键控信息的任何l2/l3转发查找。这样,针对单个分组流的分组在由给定的sf组件30喷射时不必遵循相同的路径。
因此,根据所公开的技术,在从服务器12之一接收到源业务之后,例如,由接入节点171实现的sf组件30a跨到逻辑机架60中所包括的接入节点17实现的sx组件32的所有可用链路执行相同流的分组的8向喷射。更具体地,sf组件30a跨逻辑机架60内的同一接入节点171的一个内部sx组件32a和其他接入节点172-178的七个外部sx组件32b-32h进行喷射。在一些实现中,逻辑机架60内的sf30和sx32之间的这种8向喷射可以称为第一阶段喷射。如本公开的其他部分中所描述的,可以在接入节点17和核心交换机22之间的交换结构内的第二级网络扇出上执行第二阶段喷射。例如,第二阶段喷射可以通过中间设备(诸如,tor以太网交换机、电置换设备或光学置换设备)来执行。
在一些示例中,如上面更详细地描述的,前四个接入节点171-174可以被包括在第一接入节点组191中,并且第二个四个接入节点174-178可以被包括在第二接入节点组192中。第一和第二接入节点组19内的接入节点17可以经由全网格彼此连接,以便允许逻辑机架60内的sf30和sx32之间进行8向喷射。在一些示例中,包括两个接入节点组及其支持的服务器12的逻辑机架60可以被称为半机架或半物理机架。在其他示例中,可以使用全网格连接性将更多或更少的接入节点连接在一起。在一个示例中,可以在全网格中将十六个接入节点17连接在一起,以在完整的物理机架内支持第一阶段的16向喷射。
图8是图示了跨接入节点17之间的数据中心交换结构的示例多级网络扇出的框图。在图8的所图示示例中,每个逻辑机架60包括八个接入节点171-178和由每个接入节点支持的服务器节点12。第一逻辑机架601通过交换结构内的核心交换机22被连接到第二逻辑机架602。在一些示例中,第一逻辑机架601和第二逻辑机架602可以是相同的逻辑机架。
根据所公开的技术,交换结构包括基于fcp的流控制和网络结构内的网络通信。网络结构可以被可视化为包括多个信道,例如,请求信道、授权信道、fcp数据信道和非fcp数据信道,如关于图11更详细地描述的。如图8所图示的,fcp数据信道经由逻辑隧道100承载数据分组,该逻辑隧道100包括第一逻辑机架601中的源节点(例如,接入节点171的sf组件30a)与第二逻辑机架602中的目的地节点(例如,接入节点171的df组件36a)之间的所有路径。fcp数据信道使用fcp协议承载数据分组。通过合适的负载平衡方案,通过从源节点到目的地节点的结构喷射fcp分组。预计fcp分组不按顺序递送,但是目的地节点可以执行分组重排序。例如,可以将由接入节点171的sf组件30a从源服务器12接收的业务流的分组朝着接入节点171的df组件36a喷射在逻辑隧道100内的一些或所有可能的链路上。
在一些示例中,df组件36a被配置为在将分组流传输到目的地服务器12之前对接收到的分组进行重排序,以重新创建分组流的原始序列。在其他示例中,在将分组流传输到目的地服务器12之前,df组件36a可能不需要重排序接收到的分组流的分组。在这些示例中,df组件36a可以代替地以分组到达的顺序将分组递送到目的地服务器12。例如,包括存储访问请求或对目的地存储设备的响应的分组可能不需要被重排序为发送它们的原始序列。
网络结构内的请求信道可以用于将fcp请求消息从源节点承载到目的地节点。与fcp数据分组类似,fcp请求消息可能会在所有可用路径上向目的地节点喷射,但是请求消息不需要被重排序。作为响应,网络结构内的授权信道可以用于将fcp授权消息从目的地节点承载到源节点。fcp授权消息也可以在所有可用路径上朝向源节点被喷射,并且不需要对授权消息进行重排序。网络结构内的非fcp数据信道承载不使用fcp协议的数据分组。可以使用基于ecmp的负载平衡来转发或路由非fcp数据分组,并且针对由五个元组标识的给定流,预计将这些分组按顺序递送到目的地节点。
图8的示例图示了第一逻辑机架601内的接入节点17之间的第一级网络扇出,如上面关于图7b所描述的,以及接入节点17和核心交换机22之间的第二级网络扇出。如上面关于图3-图4所描述的,第一逻辑机架601内的八个接入节点17使用电气或光学以太网连接被连接到核心交换机22。第二逻辑机架602内的八个接入节点17类似地被连接到核心交换机22。在一些示例中,每个接入节点17可以连接到八个核心交换机22。在fcp业务的情况下,第一逻辑机架601内的接入节点17的sx组件32应用喷射算法以跨到核心交换机22的所有可用路径来喷射针对任何给定分组流的分组。通过这种方式,sx组件32可能不为接收的分组的l2/l3交换执行完全查找操作。
在从一个服务器12接收源业务之后,第一逻辑机架601中的接入节点171的sf组件30a跨到第一逻辑机架601中的接入节点17实现的sx组件32的所有可用路径对业务流的fcp分组执行8向喷射。如图8进一步图示的,每个sx组件32然后跨到核心交换机22的所有可用路径喷射业务流的fcp分组。在所图示的示例中,多级扇出为8x8,因此最多支持六十四个核心交换机221-2264。在其他示例中,其中第一级扇出在整个物理机架内为1:16,多级扇出可以为16x16,并支持多达256个核心交换机。
尽管在图8中图示为直接在接入节点17与核心交换机22之间发生,但是二级扇出可以通过一个或多个tor设备来执行,诸如,架顶以太网交换机、光学置换设备或电置换设备。多级网络扇出使得在第一逻辑机架601内的任何接入节点17处接收到的业务流的分组能够到达核心交换机22,以进一步转发到第二逻辑机架602内的任何接入节点17。
根据所公开的技术,在一个示例实现中,sf组件30和sx组件32中的每一个都使用fcp喷射引擎,该引擎被配置为应用适当的负载平衡方案,以在到目的地节点所有可用路径上喷射给定fcp分组流的分组。在一些示例中,负载平衡方案可以将分组流的每个fcp分组定向到基于可用带宽选择的并行数据路径之一(即,最小负载路径)。在其他示例中,负载平衡方案可以将分组流的每个fcp分组定向到并行数据路径中的随机、伪随机或循环选择的一个并行数据路径。在又一示例中,负载平衡方案可以将分组流的每个fcp分组与交换结构中的可用带宽成比例地定向到加权随机选择的并行数据路径之一。在最小负载路径选择的示例中,fcp喷射引擎可以追踪在每个路径上传输的字节数,以便选择要在其上转发分组的最小负载路径。另外,在加权随机路径选择的示例中,fcp喷射引擎可以追踪下游的路径故障,以通过在每个活动路径上按与带宽权重成比例的方式喷射分组来提供流公平性。例如,如果连接到sx组件32a的核心交换机221-228中的一个发生故障,那么sf组件30a和sx组件32之间的路径权重将发生变化,以反映在第一逻辑机架601内的接入节点171后面可用的交换结构带宽的较小比例。在该示例中,sf组件30a将与第一逻辑机架601内的接入节点17后面的可用带宽成比例地向sx组件32喷射。更具体地,基于由于所连接的核心交换机221-228中的一个的故障而在第一逻辑机架601内的接入节点171之后减少的交换结构带宽,sf组件30a将向sx组件32a喷射比其他sx组件32更少的分组。通过这种方式,在朝向目的地节点的可用路径上分组的喷射可能不是均匀的,但是即使在相对较短的时段内,有效路径之间的带宽也将是平衡的。
在该示例中,第一逻辑机架601内的源节点(例如,接入节点171的sf组件30a)向第二逻辑机架602内的目的地节点(例如,接入节点171的df组件36a)发送请求消息,以请求一定的权重或带宽,并且目的地节点在保留出口带宽后将授权消息发送到源节点。源节点还确定在核心交换机22和包括目的地节点的逻辑机架602之间是否发生了任何链路故障。然后,源节点可以使用与源和目的地带宽成比例的所有活动链路。作为示例,假设在源节点和目的地节点之间存在n个链路,每个链路的源带宽为sbi,并且目的地带宽为dbi,其中i=1..n。为了考虑故障,从源节点到目的地节点的实际带宽等于在逐个链路的基础上确定的min(sb,db)。更具体地,源带宽(sb)等于
在fcp业务的情况下,sf组件30和sx组件32使用fcp喷射引擎,以基于朝向目的地节点的每个链路上的负载(与其权重成比例)分配业务流的fcp分组。喷射引擎维持信用存储器以追踪每个下一跳成员链路的信用(即,可用带宽),使用fcp报头中包括的分组长度来扣除信用(即,减少可用带宽),并将给定分组与具有最高信用的一个活动链路(即,最小负载链路)相关联。通过这种方式,针对fcp分组,sf组件30和sx组件32在目的地节点的下一跳的成员链路上与成员链路的带宽权重成比例地喷射分组。关于结构故障弹性的更多细节可在于2018年3月5日提交的标题为“resilientnetworkcommunicationusingselectivemultipathpacketflowspraying(使用选择性的多路径分组慢喷射的弹性网络通信)”的美国临时专利申请号62/638,725(代理人案号1242-015usp1)中找到,其全部内容通过引用并入本文。
在另一示例实现中,sf组件30或sx组件32中的每一个针对分组流的每个fcp分组修改报头的udp部分,以便迫使分组在下游向核心交换机22喷射。更具体地,sf组件30或sx组件32中的每一个被配置为针对分组流的每个fcp分组在报头的udp部分中随机设置不同的udp源端口。每个核心交换机22针对每个fcp分组从报头的udp部分计算n字段的哈希,并且基于针对每个fcp分组的随机设置的udp源端口,选择在其上喷射fcp分组的并行数据路径之一。该示例实现使得能够通过核心交换机22进行喷射而无需修改核心交换机22以理解fcp。
核心交换机22沿着第一逻辑机架601中的源节点(例如,接入节点171的sf组件30a)与第二逻辑机架602中的目的地节点(例如,接入节点171的df组件36a)之间的逻辑隧道100作为单跳操作。核心交换机22执行完整的查找操作,以便对接收到的分组进行l2/l3交换。通过这种方式,核心交换机22可以将针对相同业务流的所有分组转发到支持目的地服务器12的第二逻辑机架602中的目的地节点,例如,接入节点171的df组件36a。尽管在图8中图示为直接发生在核心交换机22和第二逻辑机架602的目的地接入节点171之间,但是核心交换机22可以将针对相同业务流的所有分组转发到具有到目的地节点的连接性的中间tor设备。在一些示例中,中间tor设备可以将针对业务流的所有分组直接转发到由第二逻辑机架602的接入节点171实现的dx组件34a。在其他示例中,中间tor设备可以是被配置为提供另一扇出的光学或电置换设备,可以在置换设备的输入和输出端口之间通过该扇出喷射分组。在该示例中,第二逻辑机架602的接入节点17的dx组件34中的全部或一些部分可以接收相同业务流的喷射分组。
第二逻辑机架602内的接入节点17的dx组件34和df组件36也具有全网格连接形,因为每个dx组件34被连接到第二逻辑机架602内的所有df组件36。当dx组件34中的任何一个从核心交换机22接收到业务流的分组时,dx组件34在直接路径上将分组转发到接入节点171的df组件36a。df组件36a可以执行仅为了选择适当的输出端口以将分组转发到目的地服务器12而必需的有限查找。响应于接收到业务流的分组,第二逻辑机架602内的接入节点171的df组件36a可以基于分组的序列号对业务流的分组进行重排序。这样,关于数据中心的完整路由表,仅核心交换机22可能需要执行完整的查找操作。因此,交换结构提供了高度可扩展的、平坦的、高速的互连,其中服务器实际上是来自数据中心内的任何其他服务器12的一个l2/l3跳。
关于图1-图8b中所图示的数据中心网络架构和互连的接入节点的更多细节可在于2018年3月28日提交的标题为“non-blockingany-to-anydatacenternetworkwithpacketsprayingovermultiplealternatedatapaths(分组在多个备用数据路径上喷射的非阻塞任何到任何数据中心网络)”的美国专利申请号15/939,227(代理人案号1242-002us01)中找到,其全部内容通过引用并入本文。
此处包括了关于图8的fcp及其操作的一个示例的简要描述。在图8的示例中,接入节点17是到网络结构的结构端点(fep),其由以叶-主干拓扑布置的交换元件(例如,核心交换机22)组成。该网络结构允许一个接入节点17通过多个路径与另一接入节点通信。网络结构内部的核心交换机22具有较浅的分组缓冲器。网络结构的横截面带宽等于或大于所有端点带宽的总和。通过这种方式,如果每个接入节点17将传入数据速率限制到网络架构,则网络架构内的任何路径都不应该以很高的概率长期拥塞。
如上所述,fcp数据分组经由逻辑隧道100从源节点(例如,第一逻辑机架601内的接入节点171的sf组件30a)被发送到目的地节点(例如,第二逻辑机架602内的接入节点172的df组件36a)。在使用fcp通过隧道100发送任何业务之前,必须在端点之间建立连接。由接入节点17执行的控制平面协议可以用于在两个fcp端点之间在每个方向上建立一对隧道。可选地保护fcp隧道(例如,加密和认证)。隧道100被认为从源节点到目的地节点是单向的,并且可以在从目的地节点到源节点的另一方向上建立fcp伙伴隧道。控制平面协议协商两个端点的能力(例如,块大小、最大传输单元(mtu)大小等),并且通过设置隧道100及其伙伴隧道和针对每个隧道初始化队列状态上下文来在端点之间建立fcp连接。
为每个端点指派源隧道id和对应的目的地隧道id。在每个端点处,基于指派的隧道id和优先级,得出给定隧道队列的队列id。例如,每个fcp端点可以从句柄(handle)池中分配本地隧道句柄,并将该句柄传递到其fcp连接伙伴端点。fcp伙伴隧道句柄被存储在查找表中,并从本地隧道句柄中引用。针对源端点,例如,第一逻辑机架601内的接入节点171,源队列由本地隧道id和优先级标识,并且目的地隧道id基于本地隧道id从查找表中被标识。类似地,针对目的地端点,例如,第二逻辑机架602内的接入节点171,目的地队列由本地隧道id和优先级标识,并且源隧道id基于本地隧道id从查找表中被标识。
fcp隧道队列被定义为使用fcp在网络结构上运输有效负载的独立业务流的存储桶。给定隧道的fcp队列由隧道id和优先级标识,并且隧道id由给定隧道的源/目的地端点对标识。备选地,端点可以使用映射表来基于给定隧道的内部fcp队列id得出隧道id和优先级。在一些示例中,每个隧道的结构隧道(例如,逻辑隧道100)可以支持1、2、4或8个队列。每个隧道的队列数是网络结构属性,并且可以在部署时进行配置。网络结构内的所有隧道可以为每个隧道支持相同数量的队列。每个端点最多可以支持16,000个队列。
当源节点与目的地节点通信时,源节点使用通过udp封装的fcp来封装分组。fcp报头承载标识隧道id、队列id、分组的分组序列号(psn)以及两个端点之间的请求、授权和数据块序列号的字段。在目的地节点处,传入隧道id对于来自特定源节点的所有分组都是唯一的。隧道封装承载分组转发以及由目的地节点使用的重排序信息。单个隧道承载源节点和目的地节点之间的一个或多个队列的分组。基于跨越同一隧道队列的序列号标签,仅对单个隧道内的分组进行重排序。当通过隧道向目的地节点发送分组时,源节点会利用隧道psn标记分组。目的地节点可以基于隧道id和psn对分组进行重排序。在重排序结束时,目的地节点剥离隧道封装,并将分组转发到相应的目的地队列。
此处描述了如何将在源端点处进入fcp隧道100的ip分组被传输到目的地端点的示例。ip地址为a0的源服务器12向ip地址为b0的目的地服务器12发送ip分组。源fcp端点(例如,第一逻辑机架601内的接入节点171)传输带有源ip地址a和目的地ip地址b的fcp请求分组。fcp请求分组具有fcp报头,以承载请求块号(rbn)和其他字段。fcp请求分组在通过ip的udp上被传输。目的地fcp端点(例如,第二逻辑机架602内的接入节点171)将fcp授权分组发送回源fcp端点。fcp授权分组具有fcp报头,以承载授权块号(gbn)和其他字段。fcp授权分组在通过ip的udp上被传输。源端点在接收到fcp授权分组后传输fcp数据分组。源端点在输入数据分组上附加新的(ip+udp+fcp)数据报头。在将分组递送到目的地主机服务器之前,目的地端点会移除附加的(ip+udp+fcp)数据报头。
图9是图示了包括联网单元142和两个或更多个处理核140a-140n(统称为“核140”)的示例接入节点130的框图。接入节点130通常表示以数字逻辑电路装置实现的硬件芯片。作为各种示例,接入节点130可以被提供为安装在计算设备的母板上或安装在经由pcie连接到计算设备的母板的卡上等的集成电路。在一些示例中,接入节点130可以是被配置为用于安装在计算机架、存储机架或融合机架内的独立网络设备的接入节点组(例如,接入节点组19之一)内的集成电路。
接入节点130可以基本上类似于图1-图8的任何接入节点17进行操作。因此,接入节点130可以例如经由pcie、以太网(有线或无线)或其他这种通信介质而被通信地耦合到数据中心结构(例如,交换结构14)、一个或多个服务器设备(例如,服务器节点12或服务器52)、存储介质(例如,图3的固态存储装置41)、一个或多个网络设备、随机存取存储器等,以便互连这些各种元件中的每一个。
在图9的所图示示例中,接入节点130包括耦合到片上存储器单元134的多个核140。在一些示例中,存储器单元134可以包括高速缓存存储器。在其他示例中,存储器单元134可以包括两种类型的存储器或存储器设备,即,相干高速缓存存储器和非相干缓冲器存储器。有关分叉存储器系统的更多细节可在于2018年4月10日提交的标题为“relayconsistentmemorymanagementinamultipleprocessorsystem(在多处理器系统中的中继一致的存储器管理)”的美国专利申请号15/949,892(代理人案号1242-008us01)中找到,其全部内容通过引用并入本文。
在一些示例中,多个核140可以包括至少两个处理核。在一个特定示例中,多个核140可以包括六个处理核140。接入节点130还包括联网单元142、一个或多个主机单元146、存储器控制器144以及一个或多个加速器148。如图9所图示的,核140、联网单元142、存储器控制器144、主机单元146、加速器148和存储器单元134中的每一个彼此通信地耦合。另外,接入节点130被耦合到片外外部存储器150。外部存储器150可以包括随机存取存储器(ram)或动态随机存取存储器(dram)。
在该示例中,接入节点130表示高性能、超融合的网络、存储装置以及数据处理器和输入/输出集线器。核140可以包括mips(无互锁管线级微处理器)核、arm(高级risc(精简指令集计算)机器)核、powerpc(具有增强型risc–性能计算的性能优化)核、risc-v(risc五)核或cisc(复杂指令集计算或x86)核中的一个或多个。核140中的每一个可以被编程为处理与给定的数据分组(例如,网络分组或存储分组)有关的一个或多个事件或活动。核140中的每个可以使用高级编程语言(例如,c、c++等)来编程。
如本文所描述的,利用接入节点130的新处理架构对于流处理应用和环境可能特别有效。例如,流处理是一种非常适合于高性能和高效率处理的数据处理架构。流被定义为计算对象的有序单向序列,其长度可以无限制或不确定。在简单的实施例中,流起源于生产者并终止于消费者,并且按顺序进行操作。在一些实施例中,流可以被定义为流片段的序列;每个流片段包括在物理地址空间中可连续寻址的存储器块、该块的偏移量和有效长度。流可以是离散的(诸如,从网络接收到的分组的序列),或者是连续的(诸如,从存储设备读取的字节流)。作为处理的结果,一种类型的流可以被变换成另一类型。例如,tcp接收(rx)处理消耗段(片段)以产生有序的字节流。在传输(tx)方向上执行反向处理。与流类型无关,流操纵需要有效的片段操纵,其中片段的定义如上。
在一些示例中,多个核140可能能够处理由联网单元142和/或主机单元146按照使用一个或多个“工作单元”的顺序方式接收的、与一个或多个数据分组中的每个数据分组有关的多个事件。通常,工作单元是在核140与联网单元142和/或主机单元146之间交换的数据集,其中每个工作单元可以表示与流的给定数据分组有关的一个或多个事件。作为一个示例,工作单元(wu)是与流状态相关联并且用于描述(即,指向)(所存储的)流内的数据的容器。例如,工作单元可以动态地起源于耦合至多处理器系统的外围单元内(例如,由联网单元、主机单元或固态驱动器接口注入),或者与数据的一个或多个流相关联地在处理器自身内,并终止于系统的另一外围单元或另一处理器。工作单元关联于与执行工作单元以处理流的相应部分的实体有关的工作量。在一些示例中,接入节点130的一个或多个处理核40可以被配置为使用工作单元(wu)堆栈来执行程序指令。
在一些示例中,在处理与每个数据分组有关的多个事件时,多个核140中的第一个(例如,核140a)可以处理多个事件中的第一事件。而且,第一核140a可以向多个核140中的第二核(例如,核140b)提供一个或多个工作单元中的第一工作单元。此外,第二核140b可以响应于从第一核140b接收到第一工作单元来处理多个事件中的第二事件。
接入节点130可以充当交换机/路由器和多个网络接口卡的组合。例如,联网单元142可以被配置为从一个或多个外部设备(例如,网络设备)接收一个或多个数据分组且将一个或多个数据分组传输到一个或多个外部设备。联网单元142可以执行网络接口卡功能性、分组交换等,并且可以使用大的转发表并提供可编程性。联网单元142可以暴露以太网端口以用于连接到网络,诸如,图1的交换结构14。通过这种方式,接入节点130支持一个或多个高速网络接口,例如,以太网端口,而不需要分离的网络接口卡(nic)。每个主机单元146可以支持一个或多个主机接口,例如,pci-e端口,用于连接到应用处理器(例如,服务器设备的x86处理器)或存储设备(例如,ssd)。接入节点130还可以包括一个或多个高带宽接口,用于连接到片外外部存储器150。每个加速器148可以被配置为对各种数据处理功能执行加速,诸如,查找、矩阵乘法、加密、压缩、正则表达式等。例如,加速器148可以包括查找引擎、矩阵乘法器、密码引擎、压缩引擎、正则表达式解译器等的硬件实现。
存储器控制器144可以控制核140、联网单元142和任何数量的外部设备(例如,网络设备、服务器、外部存储设备等)对片上存储器单元134的访问。存储器控制器144可以被配置为执行多个操作以根据本公开执行存储器管理。例如,存储器控制器144可能能够映射从核140之一到存储器单元134的相干高速缓存存储器或非相干缓冲器存储器的访问。在一些示例中,存储器控制器144可以基于地址范围、指令或指令内的操作码、特殊访问或其组合中的一个或多个来映射访问。
关于接入节点的更多细节(包括其操作和示例架构)可在于2018年7月10日提交的标题为“accessnodefordatacenters(用于数据中心的访问节点)”的美国专利申请号16/031,676(代理人案号1242-005us01)中找到,其全部内容通过引用并入本文。
图10是更详细地图示了来自图9的接入节点130的示例联网单元142的框图。联网单元(nu)142暴露了以太网端口,在本文中也称为结构端口,以将接入节点130连接到交换架构。nu142经由端点端口连接到处理核140以及外部服务器和/或存储设备,诸如,ssd设备。nu142支持将分组从一个结构端口交换到另一结构端口而不存储完整的分组(即,中转(transit)交换),这有助于实现中转业务的低时延。通过这种方式,nu142使得能够创建具有或不具有外部交换元件的接入节点的结构。nu142可以实现以下作用:(1)将分组从pcie设备(服务器和/或ssd)传输到交换结构,并且从交换结构接收分组并将其发送到pcie设备;(2)支持将分组从一个交换结构端口交换到另一交换结构端口;(3)支持向接入节点控制器发送网络控制分组;以及(4)实现fcp隧道化。
如图10所图示的,nu142包括结构端口组(fpg)170。在其他示例中,nu142可以包括多个fpg170。fpg170包括连接到交换网络的两个或更多个结构端口。fpg170被配置为从交换结构接收以太网分组并将分组传输到交换结构。fpg170可以负责生成和接收链路暂停和优先级流控制(pfc)帧。在接收方向上,fpg170可以具有灵活的解析器以解析传入的字节并生成解析的结果向量(prv)。在传输方向上,fpg170可以具有分组重写子单元,以基于与分组一起存储的重写指令来修改传出分组。
nu142具有单个转发块172,以转发来自fpg170的结构端口和源代理块180的端点端口的分组。转发块172具有固定管线,其被配置为处理每个周期从fpg170和/或源代理块180接收到的一个prv。转发块172的转发管线可以包括以下处理部分:属性、入口过滤器、分组查找、下一跳解析、出口过滤器、分组复制和统计。
在属性处理部分中,确定不同的转发属性,诸如,虚拟层2接口、虚拟路由接口和业务类别。这些转发属性被传递到管线中的进一步处理部分。在入口过滤器处理部分,可以从prv的不同字段中准备搜索密钥,并根据编程规则进行搜索。入口过滤器块可以用于使用规则集来修改正常转发行为。在分组查找处理部分中,在表中查找prv的某些字段,以确定下一跳索引。分组查找块支持精确匹配和最长前缀匹配查找。
在下一跳解析处理部分中,解析下一跳指令,并确定目的地出口端口和出口队列。下一跳解析块支持不同的下一跳,诸如,最终下一跳、间接下一跳、等成本多路径(ecmp)下一跳和加权成本多路径(wcmp)下一跳。最终下一跳存储出口流的信息以及出口分组应该如何被重写。间接下一跳可以被软件用来将下一跳的地址嵌入到存储器中,该存储器可以用于执行原子下一跳更新。
wecmp下一跳可以具有多个成员,并且用于在接入节点的sf组件和sx组件之间的所有链路上喷射分组(例如,参见图8的sf组件30和sx组件32)。由于机架交换机和主干交换机之间的链路故障,sf可能需要基于目的地机架ip地址的活动链路在sx之间进行喷射。针对fcp业务,fcp喷射引擎会基于每个链路上与其权重成比例的负载来喷射分组。wecmp下一跳存储信用存储器的地址,并且fcp喷射引擎选择信用最高的链路,并基于分组长度扣除其信用。ecmp下一跳可以具有多个成员,并且用于在连接到接入节点的主干交换机的所有链路上喷射分组(例如,参见图8的核心交换机22)。针对fcp业务,fcp喷射引擎会再次基于每个链路上与其权重成比例的负载来喷射分组。ecmp下一跳存储信用存储器的地址,并且fcp喷射引擎选择信用最高的链路,并基于分组长度扣除其信用。
在出口过滤器处理部分中,基于出口端口和出口队列对分组进行过滤。出口过滤器块无法改变出口目的地或出口队列,但可以使用规则集对分组进行采样或镜像。如果任何处理阶段都已确定要创建分组的副本,则分组复制块生成其关联的数据。nu142可以仅创建传入分组的一个额外副本。统计处理部分具有计数器集合,以收集统计信息以用于网络管理目的。统计块还支持计量,以控制到一些端口或队列的分组速率。
nu142还包括存储用于端口带宽超额订阅的分组的分组缓冲器174。分组缓冲器174可以用于存储三种分组:(1)接收自在源代理块180的端点端口上的处理核140的、要被传输到fpg170的结构端口的传输分组;(2)接收自fpg170的结构端口的、要经由目的地代理块182的端点端口被传输到处理核140的接收分组;以及(3)在fpg170的结构端口上进入并且在fpg170的结构端口上离开的中转分组。
分组缓冲器174追踪不同方向和优先级上的业务的存储器使用情况。基于编程的配置文件,如果出口端口或队列非常拥塞,则分组缓冲器174可以决定丢弃分组,向工作单元调度器断言流控制,或向另一端发送暂停帧。分组缓冲器174所支持的关键特征可以包括:用于中转分组的直通、用于非显式拥塞通知(ecn)感知的分组的加权随机早期检测(wred)丢弃、用于ecn感知的分组的ecn标记、基于输入和输出的缓冲器资源管理和pfc支持。
分组缓冲器174可以具有以下子单元:分组写入器、分组存储器、单元格(cell)链路列表管理器、分组队列管理器、分组调度器、分组读取器、资源管理器和单元格空闲池。分组写入器子单元收集来自fpg170的流控制单元(flit),创建单元格并写入分组存储器。分组写入器子单元从转发块172获得转发结果向量(frv)。分组存储器子单元是存储体的集合。在一个示例中,分组存储器由16k个单元格构成,每个单元格具有256字节的大小,由四个微单元格构成,每个微单元的大小为64字节。分组存储器内的存储体可以是2pp(1个写端口和1个读端口)类型。分组存储器的原始带宽可能为1tbps写带宽和1tbps读带宽。fpg170具有保证的时隙来写入和读取来自分组存储器的分组。源代理块180和目的地代理块182的端点端口可以使用剩余带宽。
单元格链路列表管理器子单元维护表示分组的单元格列表。单元格链路列表管理器可以由1个写端口和1个读端口存储器组成。分组队列管理器子单元维护用于出口节点的分组描述符的队列。分组调度器子单元基于队列之间的不同优先级来调度分组。例如,分组调度器可以是三级调度器:端口、信道、队列。在一个示例中,fpg170的每个fpg端口具有十六个队列,并且源代理块180和目的地代理块182的每个端点端口具有八个队列。
针对调度的分组,分组读取器子单元从分组存储器读取单元格并将它们发送到fpg170。在一些示例中,分组的前64个字节可以承载重写信息。资源管理器子单元追踪不同池和队列的分组存储器的使用情况。分组写入器块咨询资源管理器块以确定是否应该丢弃分组。资源管理器块可以负责向工作单元调度器断言流控制或将pfc帧发送到端口。单元格空闲池子单元管理分组缓冲器单元格指针的空闲池。当分组写入器块想要将新的单元格写入分组缓冲器存储器时,单元格空闲池分配单元格指针,并且当分组读取器块使单元格从分组缓冲器存储器中出列时,单元格空闲池释放单元格指针。
nu142包括共同负责fcp控制分组的源代理控制块180和目的地代理控制块182。在其他示例中,源代理控制块180和目的地控制块182可以包括单个控制块。源代理控制块180针对每个隧道生成fcp请求消息。响应于fcp授权消息(其响应于fcp请求消息而被接收),源代理块180基于由fcp授权消息分配的带宽量来指示分组缓冲器174发送fcp数据分组。在一些示例中,nu142包括端点传输管线(未示出),该端点传输管线向分组缓冲器174发送分组。端点传输管线可以执行以下功能:分组喷射,从存储器178获取(fetch)分组,基于编程的mtu大小的分组分段,分组封装,分组加密和分组解析以创建prv。在一些示例中,端点传输管线可以被包括在源代理块180或分组缓冲器174中。
目的地代理控制块182针对每个隧道生成fcp授权消息。响应于接收到的fcp请求消息,目的地代理块182适当地更新隧道的状态并发送在隧道上分配带宽的fcp授权消息。响应于fcp数据分组(其响应于fcp授权消息而被接收),分组缓冲器174将接收到的数据分组发送到分组重排序引擎176,以在存储在存储器178中之前进行重排序和重组。存储器178可以包括片上存储器或外部片外存储器。存储器178可以包括ram或dram。在一些示例中,nu142包括端点接收管线(未示出),该端点接收管线从分组缓冲器174接收分组。端点接收管线可以执行以下功能:分组解密,分组解析以创建prv,基于prv的流密钥生成,确定用于传入分组的处理核140之一以及在缓冲器存储器中分配缓冲器句柄,将传入的fcp请求和授权分组发送到目的地代理块182,以及将具有所分配的缓冲器句柄的传入数据分组写入缓冲器存储器。
图11是图示了在诸如数据中心交换结构或其他基于分组的网络等网络结构200内的示例基于fcp的流控制和网络通信的概念图。如所图示的,当使用fcp时,网络结构200被可视化为在源接入节点196和目的地接入节点198之间具有多个信道的结构。fcp数据信道206承载用于多个隧道和每个隧道内的多个队列的业务。每个信道均指定用于特定类型的业务。各种信道及其属性如下所述。
控制信道202的严格优先级高于所有其他信道。该信道的预期用途是承载授权消息。授权消息被喷射到朝向请求或源节点(例如,源接入节点196)的所有可用路径上。不希望它们按顺序到达请求节点。控制信道202受到速率限制,以最小化网络结构200上的开销。高优先级信道204比数据和非fcp信道具有更高的优先级。高优先级信道204用于承载fcp请求消息。消息在朝向授权或目的地节点(例如,目的地接入节点198)的所有可用路径上被喷射,并且不期望消息按顺序到达授权节点。高优先级信道204被速率限制以最小化结构上的开销。
fcp数据信道206使用fcp承载数据分组。数据信道206具有比非fcp数据信道更高的优先级。通过合适的负载平衡方案,fcp分组被喷射到网络结构200上。fcp分组不被预期按顺序在目的地接入节点198处递送,并且目的地接入节点198不被预期具有分组重排序实现。非fcp数据信道208承载不使用fcp的数据分组。相比于所有其他信道,非fcp数据信道208具有最低的优先级。fcp数据信道206的严格优先级高于非fcp数据信道208。因此,非fcp分组使用网络中的机会性带宽,并且根据要求,可以通过请求/授权步测方案控制fcp数据速率,以允许非fcp业务获得所需的带宽份额。使用基于ecmp的负载平衡来转发/路由非fcp数据分组,并且针对给定的流(由五元组标识),分组被预期始终在目的地接入节点198处按顺序递送。非fcp数据信道208可能有多个队列,这些队列在将分组调度到结构时应用了任何优先级/qos。非fcp数据信道208可以基于分组流的优先级在每个链路端口上支持8个队列。
fcp数据分组经由逻辑隧道在源接入节点196和目的地接入节点198之间发送。隧道被认为是单向的,并且针对目的地,传入的隧道标识符(id)对于来自特定源节点的所有分组都是唯一的。隧道封装承载分组转发以及重排序信息。单个隧道在源接入节点196和目的地接入节点198之间为一个或多个源队列(210)承载分组。仅基于跨同一隧道队列的序列号标签对隧道内的分组进行重排序。当从源接入节点196发送分组时,用隧道分组序列号(psn)来标记分组。目的地接入节点198基于隧道id和psn对分组进行重排序(212)。在重排序结束时剥离隧道封装,并且将分组转发到相应的目的地队列(214)。
队列被定义为使用fcp在网络结构200上运输有效负载的独立业务流的存储体。fcp队列由[隧道id、优先级]标识,而隧道id由源/目的地接入节点对标识。备选地,接入节点196、198可以使用映射表来得出隧道id以及基于内部fcp队列id得出队列/优先级对。结构隧道可以为每个隧道支持1、2、4或8个队列。每个隧道的队列数是网络结构属性,并且可以在部署时进行配置。接入节点最多可以支持16k个队列。网络结构200内的所有隧道可以为每个隧道支持相同数量的队列。
如上面所指示的,fcp消息包括请求消息、授权消息和数据消息。当源接入节点196希望将一定数量的数据传送到目的地接入节点198时,生成请求消息。该请求消息承载目的地隧道id、队列id、队列的请求块号(rbn)和元数据。通过网络结构200上的高优先级信道204发送请求消息,并将该消息喷射到所有可用路径上。元数据可以用于指示请求重试等。当目的地接入节点198响应来自源接入节点196的传送一定数量数据的请求时,生成授权消息。授权消息承载源隧道id、队列id、队列的授权块号(gbn)、元数据(比例因子等)和时间戳。通过网络结构200上的控制信道202发送授权消息,并将该消息喷射到所有可用路径上。下面关于图18描述请求和授权消息的控制分组结构。fcp数据分组承载fcp报头,其包含目的地隧道id、队列id、分组序列号(psn)和数据块号(dbn)以及元数据。fcp数据分组的平均大小可能约为800b。fcp的最大传输单位(mtu)可能约为1.6kb-2kb,以最小化结构中的分组时延抖动。下面关于图19描述fcp数据分组结构。
图12是图示了源接入节点和目的地接入节点之间的示例fcp队列对结构的概念图。fcp是端到端许可控制协议。发送器显式地请求接收器,意在传送一定数量的有效负载数据。接收器基于其缓冲器资源、qos和/或结构拥塞度量来发出授权。结构端点(fep)节点是连接到由交换元件(叶-主干拓扑)组成的结构的节点。该结构允许一个端点通过多个路径与另一端点进行通信。结构内部的交换元件具有较浅的分组缓冲器。结构的横截面带宽等于或大于所有结构端点的带宽之和。如果每个结构端点将传入数据速率限制到结构,则结构内部的任何路径都不应长期高概率拥塞。
如图12所图示的,fcp在两个fcp端点(即,源接入节点216和目的地接入节点218)之间建立一对隧道220、222,因为每个隧道220、222被认为是单向的。已为每个节点216、218指派了源隧道id和对应的目的地隧道id。队列id是基于每个端点的所指派的隧道id、优先级得出的。当一个端点与另一端点进行通信时,它使用udp+fcp封装来封装分组。每个节点216、218通过隧道220、222的集合从本地队列传递到远程队列。fcp报头承载标识隧道id、队列id、分组的分组序列号以及源接入节点216和目的地接入节点218之间的请求、授权和数据块序列号的字段。
在可以使用fcp发送任何业务之前,必须在两个端点216、218之间建立连接。控制平面协议协商两个端点的能力(例如,块大小、mtu大小等)并通过建立隧道220、222和初始化队列状态上下文在它们之间建立fcp连接。每个端点216、218从句柄池中分配本地隧道句柄,并将该句柄传递到其fcp连接伙伴(例如,在图12中,目的地接入节点218是源接入节点216的fcp连接伙伴)。本地隧道句柄可以被存储在本地隧道id表中(例如,源接入节点216的本地隧道id表226和目的地接入节点218的本地隧道id表228)。fcp伙伴隧道句柄被存储在查找表(例如,源接入节点216的映射表224和目的地接入节点218的映射表230)中,并从本地隧道句柄中引用。
针对发送器,源队列由[本地隧道id、优先级]标识,并且目的地隧道id由map[本地隧道id]标识。针对接收器,队列由[本地隧道id、优先级]标识。如图12所图示的,源接入节点216在本地隧道id表226中具有源或本地隧道id“4”,其映射到映射表224中的远程或目的地隧道id“1024”。相反,目的地接入节点218具有本地隧道id表228中的源或本地隧道id“1024”,其映射到映射表230中的远程或目的地隧道id“4”。
图13是图示了在源接入节点和目的地接入节点处的fcp队列状态的示例的概念图。接入节点端点处的每个fcp队列维护块序列号的集合,以用于相应发送器/接收器队列以追踪队列状态。序列号指示在任何给定时间流经队列的数据量。序列号可以以字节为单位(类似于tcp),或者以块为单位(以减少fcp报头开销)。块大小可以是64、128或256字节,并且可以在fcp连接建立时协商。作为一个示例,fcp报头可以承载16位的块序列号,并在回绕之前跨越8兆字节的数据(128b)。在该示例中,假设往返时间(rtt)或网络延迟太低,以至于序列号无法在一个rtt中回绕。
每个接入节点端点维护以下块序列号的集合,以追踪入列的块、未决请求或未决/未授权的块。队列尾部块号(qbn)表示源接入节点236处的传输队列240中的尾部块。结构传输/输出队列240追踪可用于传输到目的地接入节点238的传入分组(wu),分组以块为单位。一旦wu被添加到队列240,则qbn如下递增:qbn+=wu_size/block_size。传输队列240仅在出列时追踪wu边界,这保证了永远不会在结构上传输部分wu。然而,在传输时,wu可能会拆分为多个mtu大小的分组。
在源接入节点236处,请求块号(rbn)指示源接入节点236已在结构上为其发送请求的最后一个块。源接入节点236处的qbn与rbn之差表示传输队列240中未请求块的数量。如果qbn大于rbn,则源接入节点236可以通过本地请求调度器发送针对未请求块的请求消息。本地请求调度器可以对传出请求消息进行速率限制。它还可以经由请求速率限制器来降低总的请求带宽吞吐量,这取决于长期的“近”结构拥塞。由于主干链路丢失,近结构拥塞被称为在发送器接入节点236处的局部现象。rbn基于最大允许/配置的请求大小递增。传出请求消息承载更新的rbn值。在目的地接入节点238处,rbn指示目的地接入节点238从结构接收到请求的最后一个块。
当请求消息乱序到达目的地接入节点238时,如果请求消息rbn比先前接受的rbn更新,则目的地接入节点238将其rbn更新为消息rbn。如果乱序请求消息承载的rbn早于接受的rbn,则将其丢弃。当请求消息丢失时,承载较新的rbn的后续请求消息成功地在目的地接入节点238处更新rbn,从而从丢失的请求消息中恢复。
如果源接入节点236发送其最后一个请求消息,并且该请求消息丢失,则目的地接入节点238不会感知到该请求消息丢失,因为它是来自源接入节点236的最后一个请求。源接入节点236可以维持请求重试定时器,并且如果在超时结束时,源接入节点236尚未接收到授权消息,则源接入节点236可以再次重传该请求,以尝试从假定的丢失中恢复。
在目的地接入节点238处,授权块号(gbn)指示接收队列242中的最后一个授权块。rbn与gbn之间的距离表示接收队列242处未授权块的数量。出口授权调度器可以在为接收队列242发出授权后将gbn向前移动。gbn会通过允许的授权大小或rbn与gbn之差的最小值进行更新。在源接入节点236处,gbn指示目的地接入节点238所授权的最后一个块号。如同rbn,gbn可能不符合输出队列240中的wu边界。rbn与gbn之间的距离表示传输队列240处的未授权块的数量。允许传输器通过gbn以完成当前的wu处理。
当授权消息乱序到达源接入节点236时,源接入节点236用与先前接受的gbn相比最新的gbn来更新其gbn。如果乱序授权消息承载的gbn早于接受的gbn,则将其丢弃。当授权消息丢失时,后续的授权消息成功更新源接入节点236处的gbn,从而从丢失的授权消息中恢复。
当目的地接入节点238发送最后一个授权消息并且授权消息丢失时,或者当源接入节点236接收到授权并发送在结构中丢弃的分组时,目的地接入节点238未感知该授权消息丢失或分组丢失,因为它仅知道它发送了授权并且未能将分组取回。如果隧道中有更多分组,则隧道将因重排序超时而从丢失中恢复。目的地接入节点238可以维持超时,并且如果在超时结束时目的地接入节点238还没有接收到分组,则目的地接入节点238再次重传授权以尝试从授权/分组丢失中恢复。响应于超时授权,如果源接入节点236已经发送了分组,则源接入节点236可以发送具有零有效负载的分组,仅承载dbn。零长度分组通过常规数据信道行进,并为分组丢失更新接收器状态。响应于超时授权,如果源接入节点236没有接收到较早的授权,则源接入节点236以常规分组传输来响应超时授权。
在源接入节点236处,数据块号(dbn)指示从传输队列240传输的最后一个块。gbn和dbn之间的距离表示要传输的授权块的数量。允许传输器传输块,直到当前wu部分结束为止。在目的地接入节点238处,dbn指示在重排序处理完成之后已经接收到的最后一个块。当从结构接收到分组时,更新dbn。gbn和dbn之间的距离表示尚未接收到的或者在接收队列242处等待重排序的未决授权块的数量。
当数据分组乱序到达目的地接入节点238时,它经过分组重排序引擎。在重排序过程结束时,分组被发送到处理核之一(例如,来自图9的核140)。如果在结构中丢失了分组,则重排序引擎超时,并继续前进到下一分组,前提是丢失的分组之后隧道中还有更多分组。如果该分组是源接入节点236处的发送器队列中的最后一个分组,则可以在上述超时授权之后检测到丢失。源接入节点236可以响应于超时授权而发送零长度分组,并且当接收到零长度分组时,目的地接入节点238更新其状态。丢失的分组通过上层协议恢复。
图14是图示了用于将输入分组流从源接入节点传送到目的地接入节点的示例fcp操作的概念图。fcp协议的主要目标是以有效的方式以可预测的时延将输入分组流从一个端点传送到另一端点,以最大化结构利用率。源端点在可用路径之间喷射分组。目的地端点基于分组序列号对队列对的分组进行重排序。从概念上讲,图14描述了源/目的地队列之间的握手。
图14的示例包括两个源接入节点250a和250b(统称为“源节点250”),每个源节点具有要传输到相同的目的地接入节点(“dn”)252的分组的队列254a、254b。目的地接入节点252维护请求队列256。源接入节点250通过将请求消息(如虚线所示)发送到目的地接入节点252处的相应请求队列256来请求队列254a、254b内的分组的带宽。使用源接入节点250的速率限制器(rl)来对请求进行调速。
目的地接入节点252通过向源节点250发送授权消息(以点划线示出)来响应于请求消息而分配带宽。出口带宽的分配是业务流权重感知的(稍后将在关于图17a-图17b的接收器节点操作中更详细地讨论)。目的地接入节点252追踪缓冲器占用率、基于打滑计(skidmeter)258的未决授权,并追踪长期结构拥塞以加快授权消息。授权由目的地接入节点252的速率限制器(rl)以略低于最大速率的速率来调速,以确保结构缓冲最小或结构时延抖动低。打滑计258的水平可以用于控制结构上未决字节的数量。打滑计258在授权传输时间上递增,并且在分组到达时间上递减。目的地接入节点252基于消息中的请求号从请求丢失或乱序请求到达中恢复。丢失的请求消息由下一个传入请求消息恢复。
响应于授权消息,源节点250从队列254a、254b向目的地接入节点252传输分组(以虚线图示)。在目的地接入节点252的分组重排序引擎257处,在将分组推送到应用队列259之前在每个隧道上下文上对这些分组进行重排序。图14的示例示出了目的地接入节点252正在执行分组重排序并且在重排序完成之后对分组进行入列。由于分组丢失,重排序引擎超时并对下一分组按顺序进行入列以便进行处理。
为了减少支持协议所需的重排序资源的数量,当端点节点接收到请求/授权消息时,不对其进行重排序。相反,滑动窗口队列块序列号是累积的。由于请求/授予握手的滑动窗口性质,每个新消息都会提供有关窗口的更新信息。因此,接收器只需要注意更新窗口向前的消息即可。使用块序列号,使得端点节点只需记住为更新前向窗口移动的每种类型的消息接收的最高序列号。
图15是图示了示例fcp源接入节点操作流程的概念图。首先,要在网络结构上运输的分组/有效负载被入列在分组队列中,以等待用于将分组/有效负载传输到目的地接入节点的授权(270)、(272)。分组队列管理器260为fcp和非fcp业务流两者维护队列(272)。fcp和非fcp的分组应该被推送到分离的队列中。
分组队列管理器260发送关于入列的分组/有效负载大小的信息,以在fcp发送器状态处理器262处更新fcp源队列状态(274)。fcp发送器状态处理器262维护每个队列的fcp状态,该fcp状态用于生成要发送到目的地接入节点的请求消息(276)、(278)。针对非fcp队列,fcp发送器状态处理器262可以在无限授权模式下操作,其中在内部生成授权,就像从结构中接收到授权一样。满足fcp带宽需求后,非fcp队列获得剩余带宽。fcp需求包括请求消息、授权消息和fcp数据分组。
基于非空fcp队列的fcp源队列状态(qbn>rbn),fcp发送器状态处理器262通过生成对请求调度器264的请求来参与请求生成(276)。请求调度器264可以包括最多八个基于优先级的请求队列,以调度请求消息,以通过网络结构传输到目的地接入节点(278)。基于所请求的有效负载大小对请求消息进行速率限制(mmps)和调速(控制带宽速率),以管理结构拥塞。
针对非fcp队列以及未经请求的决策队列(即,qbn-gbn<unsolicited_threshold的队列),fcp发送器状态处理器262生成内部授权。非fcp内部授权、未经请求的内部授权和结构授权被入列在分组调度器266的分离队列中(282)。由于到达可能是乱序的,因此fcp发送器状态处理器262针对fcp源队列状态解析传入的结构授权(280)。所接受的fcp授权在分组调度器266的分离队列中排队(282)。
分组调度器266维护两个队列集合,一个集合用于非fcp,并且一个集合用于fcp(基于授权消息)。分组调度器266可以被视为具有严格优先级的用于fcp分组的分层调度器,其允许非fcp分组使用剩余带宽。备选地,可以基于加权循环(wrr)在fcp/非fcp流之间调度分组。总体上,应该使用全局速率限制器来限制从源节点流出的总带宽。可以在srr(严格循环)的基础上服务fcp分组队列,并且将获胜分组发送到分组队列管理器260(284)以对分组描述符进行出列和发送,以进行传输处理和排队(286)。可以基于wrr调度来服务非fcp分组队列。
分组队列管理器260在使分组/有效负载出列后(286),在fcp发送器状态处理器262(274)和请求步调器处向fcp源队列状态发送大小更新。在有效负载出列的情况下,由于响应于授权消息的有效负载的mtu分段,该分组可能会导致一个或多个分组。隧道上的每个新分组都标记有正在运行的每个隧道分组序列号。分组缓冲器存储所有传出的fcp分组以及包含隧道id和分组序列号的分组句柄。
fcp源节点操作可以分为以下主要部分:传输缓冲器管理、请求生成和分组调度器。
此处简要描述了源接入节点处的传输缓冲器管理。fcp队列存储要传输的分组描述符。分组描述符具有存储在传输缓冲器中的有效负载的大小和地址。术语有效负载用于指示要传运输的分组或大段。可以将传输缓冲器保持在外部存储器(例如,来自图9的外部存储器150)中,但是也可以使用片上存储器(缓冲器存储器)作为传输缓冲器(例如,来自图9的片上存储器单元134)。在源接入节点处,处理器(例如,在图9的联网单元142内)与流相关联,并负责将有效负载从主机存储器获取到传输缓冲器。流处理器可以与服务器中的连接相关联,并且具有基于信用的流控制。流处理器可以从描述符队列中获取所分配数量的描述符,以避免行头(head-of-line)阻塞。
针对每个fcp队列,四个块号被维持为fcp队列状态,如上面关于图13所描述的。从rbn到gbn的窗口指示在结构上请求的“请求窗口”。从qbn到dbn的窗口指示“传输窗口”,并且表示存储在传输缓冲器中的块。假设大多数时间dbn==gbn,则传输窗口等于qbn-gbn。从qbn到rbn的窗口应该足够大,以从主机存储器中获得数据并为fcp队列生成工作单元。rbn将基于发送到源接入节点的流处理器的基于请求窗口的反程压力最终在过程或请求生成中到达qbn。
默认情况下,fcp基于最大队列流失速率和来自目的地队列的往返时间(fcp请求到fcp授权)将“请求窗口”的大小限制为最大请求块大小(mrbs)。mrbs的值是基于估计的最大队列流失速率和rtt(也称为bdp或带宽延迟乘积)进行软件编程的。在fcp队列已经达到其最大允许请求窗口之后,它应该向流处理器断言流控制。最大允许请求窗口是请求窗口比例因子和mrbs的函数。缩小因子可以直接用于计算最大允许请求窗口,或者可以基于表查找来得出。最大允许请求窗口基于队列中的未请求块确定要发送回流处理器的回压。
流处理器基于需要使用给定的fcp队列传送的数据量来计算流权重。得出的流权重是队列的动态实体,该动态实体基于传送工作要求的动态被不断更新。发送器通过每个传出的fcp请求消息将流权重传递到目的地节点。
目的地基于所有添头流的源队列流权重估计源队列流失速率。换言之,它基于给定源节点所需工作量与目的地所看到的所有活动源节点需要处理的工作总量之比为给定源生成缩小因子。当请求到达时,目的地节点通过在其数据库中维护每个单独队列的流权重来维护所有流权重的总和。目的地接入节点处的授权调度器为源接入节点计算“缩小”值,并随每个fcp授权消息一起发送因子。
当队列变空并且接收到授权数据时,该队列被认为是空闲的,并且可以通过老化定时器来重置流权重,从而使其不参与总流权重。一旦队列在类似于目的地的源处变空,发送器就可以通过老化定时器重置缩小。软件还可以对全局传输缓冲器大小(gtbs)进行编程。gtbs的值表示传输缓冲器的大小。软件应该为不同的业务优先级类别保留分离的传输缓冲器。如果所有fcp队列中的总传输缓冲器达到gtbs极限,则fcp断言流控制。缓冲器也可以在优先级/类别的基础上划分为分离的gtbs池,或者可以作为具有每个类别/优先级的分离阈值的单个实体进行管理。
描述了在源接入节点处的请求消息生成。尽管这是一个示例实现,但fcp操作中的请求调度器可以分为两个功能:请求调度和速率限制。
在请求调度功能中,每个请求的fcp队列通过请求调度器进行仲裁以发出请求。出于调度目的,将fcp队列分成为基于优先级的组(例如,最多8个优先级)。请求调度器可以通过分层短缺加权循环(dwrr)方案选择优先级组之一。一旦选择了优先级组,便以循环(rr)方式为优先级组内的fcp队列提供服务。
当队列调度fcp请求时,该请求可以承载多达所请求块的最大已配置请求大小,或者直到队列结束。如果fcp队列中有更多未请求的块(qbn>rbn),则仅允许其参与请求调度器。假设源接入节点的流处理器将对来自目的地的请求窗口缩小因子做出反应,并停止将wu放入源队列。传入的授权承载可以增加/减少允许的请求窗口的缩放因子。
在速率限制功能中,控制请求速率,使得源接入节点发出的数据请求的速度不超过其可以传输数据的速度。该速率(称为请求数据速率限制器)应该是软件可编程的。作为一个示例,源接入节点可能能够从其pcie接口获得超过400g的主机带宽,但只可以支持200g的传出网络连接性。如果允许源接入节点将所有约400g的请求发送到不同的目的地接入节点,并且如果源接入节点接收到授权的添头(授权冲突),则它将不能将承诺的带宽递送给目的地接入节点。在该示例中,源接入节点将导致近端拥塞,从而成为允许进入结构的业务的主控制器。目的地授权调度器将不再能够以可预测的时延或rtt从源接入节点拉取数据。
根据本公开中描述的技术,请求数据速率限制器基于所传输的数据速率的能力来提出请求。速率限制器使用请求消息中承载的块大小来调整请求消息的速度。针对每个分组,将块大小四舍五入到块边界,并在将实际分组传输到结构时对请求步调器执行校正。类似地,每当传输推测性或非fcp分组时,请求数据速率限制器就会被收费,使得源节点的传输带宽在任何时间都不会被超额订阅。返回到上面的示例,其中源接入节点支持200g的传出网络连接性,传出请求可以被调整为大约200g的吞吐量(1-ε),其中ε是0-1之间的小数。通过改变ε,fcp可以限制源接入节点可以向结构生成请求的速率。在一些示例中,源接入节点还可以控制请求消息本身所消耗的带宽。结果,源接入节点可以包括另一速率限制器,称为请求控制速率限制器。
此处简要描述了源接入节点处的分组调度器操作。源接入节点基于传入的授权消息(fcp)并且基于调度标准和缓冲器占用率(非fcp)来调度fcp/非fcp分组。来自fcp/非fcp队列的业务流可以可选地分离地进行速率限制并进行dwrr仲裁,或者可以利用严格优先级配置fcp业务。总体业务受到全局速率限制器的限制,以将传出业务限制为最大带宽吞吐量。由于目的地队列拥塞,非fcp调度器可以从每个队列分组端口缓冲器接收每个非fcp队列回压。非fcp调度器将分组调度到没有被回压的队列。当不受速率限制或带宽共享限制时,fcp分组只可以承受来自下游模块的临时链路级数据路径回压。如果fcp授权在源接入节点处造成临时授权拥塞,则总体带宽速率限制器控制注入网络的带宽量。由于将总体授予和请求率控制为以略小于总体最大二分带宽操作,因此源队列拥塞只会是暂时的。fcp业务和非fcp业务的份额可以明确划分。另外,网络保证了fcp分组(即,数据/请求/授权)的递送比非fcp业务具有更高的优先级。例如,如果非fcp业务出现拥塞,则网络可能会丢弃非fcp分组。然而,不应该丢弃fcp分组,因为由于端到端许可控制,fcp业务中的拥塞可能是暂时的。
每当非fcp队列为非空时,就调度非fcp分组/有效负载分段。如果需要在fcp/非fcp队列之间共享业务,则将传出的非fcp分组与分组调度器一起入列,并在其中对它们进行速率限制。常规的fcp分组/有效负载分段会在接收到队列的授权时进行调度。fcp分组队列具有最高优先级,并且优先于非fcp。源接入节点发送业务,直到当前分组/分段边界为止,并基于传送的分组大小更新dbn。源接入节点由于分组边界传送约束而发送的任何附加字节在目的地接入节点处的授权步调器处进行补偿。传出分组可能并不总是在块边界处结束。针对每个传出分组,舍入误差在请求步调器处得到补偿。
通过这种方式,本公开的技术使得能够在源接入节点处进行延迟的分组分段,直到接收到fcp授权消息为止。一旦接收到授权消息,就可以对队列中标识的数据执行运输层fcp分组分段。然后,所生成的fcp分组可以包括在发送请求消息之后但在针对队列接收到授权消息之前从处理核接收的附加数据。
在没有显式请求授权握手的情况下,允许小流发送分组可以减少时延和网络开销。然而,应该非常谨慎地使用推测性带宽,因为它可能会导致目的地接入节点被未经请求的添头业务所淹没。根据所公开的技术,可以允许每个源接入节点将其带宽的特定份额(目的地节点缓冲器)用于未经请求的业务,并且如果未经授权的队列累积很小并低于某个阈值,则该队列可能允许发送未经请求的分组,而无需等待显式的请求/授权消息交换。如果未经授权的队列大小很小,并且源接入节点具有针对未经请求的业务的可用带宽份额,则未经请求的分组只能由源接入节点发送。针对由于fcp授权到达而调度的分组,按授权到达的顺序服务fcp分组,或者针对未经请求的分组,按入列顺序服务。未经请求的分组可能具有较低的时延,因为它们避免了请求和授权消息交换的往返延迟。
图16是图示了示例fcp目的地接入节点操作流程的概念图。fcp接收器状态处理器310维护每个队列的fcp出口上下文,诸如,rbn、gbn、dbn等。出口重排序状态处理器312维护每个隧道的分组重排序上下文的数据库。fcp授权调度器314可以支持用于高优先级和低优先级的两个或更多个授权队列。可以由授权速率限制器316基于结构拥塞来对授权进行速率限制/调整。
fcp接收器状态处理器310从网络结构接收请求消息(290),并且在初始解析(例如,过滤重复项)之后,所接受的请求消息在fcp接收器状态处理器310处按队列上下文更新fcp出口。一旦在fcp接收器状态处理器310处的请求队列为非空,就由授权调度器314调度该请求队列以进行授权生成(292)。当授权速率限制器316允许生成下一授权消息时,获胜者队列被允许发送授权消息(294)。授权调度器314在出口重排序状态处理器312处对重排序缓冲器状态作出反应(296),并且如果重排序缓冲器状态(乱序字节、飞行中的授权和缓冲器占用率)达到极限,则停止发送所有新的授权。许可还可以对结构拥塞和故障做出反应,并且可以响应于结构拥塞度量来调节授权速率。基本授权速率由软件配置。每个授权的授权大小基于请求队列大小,并且限制为最大允许授权大小。
网络结构接口接收分组,并且将它们存储在分组接收缓冲器318中以等待重排序(298)。一旦分组被重排序,分组就被入队到下游块中(300)。出口重排序状态处理器312维护每个隧道重排序状态上下文。出口重排序状态处理器312处的重排序引擎基于分组在隧道上的到达来执行重排序,并在每个隧道的基础上维护重排序定时器。如果隧道具有乱序分组,并且预期的分组在重排序定时器超时时段(~2xrtt)内未到达,则超时将导致重排序引擎跳过该分组并搜索下一分组。
fcp目的地节点操作可以分为以下主要部分:授权生成、结构负载平衡和接收缓冲器管理。
此处简要描述了目的地接入节点处的授权生成。授权生成操作可以分为授权队列调度器和授权步调器。授权调度器为递送到目的地接入节点的业务提供流公平带宽分配(下面关于图17a-图17b更详细地描述)。授权调度器还基于缓冲器使用率、未完成的授权块数和重排序缓冲器的状态来限制授权。
fcp队列分为隧道和优先级。fcp授权调度器基于其优先级(例如,最多8个优先级)将队列分成组,以进行调度。授权调度器可以通过严格优先级或分层短缺加权循环(dwrr)方案选择优先级组之一。在每个优先级组调度之上,可以使用流感知算法在作为优先级组一部分的fcp队列之间进行仲裁。来自fcp队列的传入流权重可以归一化,并由dwrr授权调度器用于更新对仲裁fcp队列的信用。
授权步调器提供许可控制并管理结构拥塞。可以在泄漏桶处实现授权步调器,该泄漏桶每当桶级别下降到某个阈值以下时就允许发送授权。当发送授权时,存储桶会在授权消息中加载大小授权的块。存储桶以一定速率(软件编程)泄漏,该速率是传入的结构速率和连接到机架的活动结构链路的数量的函数。基于实际到达的分组大小和非fcp分组,对授权步调器进行补偿以进行校正,使得使结构长期保持未拥塞状态。
目的地接入节点使用授权数据速率限制器和授权控制速率限制器通过调整fcp授权来控制传入数据分组的速率,这与上面关于源接入节点操作描述的请求数据速率限制器和请求控制速率限制器类似。另外,授权步调器通过在发送fcp授权消息时递增已授权的块计数器,并在接收fcp分组时将计数器与数据块计数递减,来追踪结构上的未决块。授权步调器还追踪重排序缓冲器中的未决分组,并且如果重排序的未决分组大于阈值,则停止生成新的fcp授权。
根据本公开的技术,目的地接入节点可以基于交换结构中的分组流的全局视图来执行fcp分组的显式拥塞通知(ecn)标记。授权调度器基于在授权调度器处看到的所有未决请求的总数提供总负载的唯一视图。基于目的地端点看到的全局负载的ecn标记相对于基于通过结构的各个交换机/路径看到的局部拥塞的ecn标记提供了重大改进。由于数据中心tcp实现依赖于ecn的广泛使用来管理拥塞,因此与通过结构的一些路径的不连续视图和局部视图相比,基于授权调度器处的输出出口队列的全局视图的ecn标记具有显著改进,并且在tcp级别提供更好的拥塞管理。
此处简要描述了目的地接入节点处的结构负载平衡。fcp要求所有传出结构链路是平衡的。一种示例实现方案是使用随机混洗的(shuffled)drr。sdrr是常规的短缺循环调度器,它对所有可用链路承载相等的权重。rr指针的随机混洗提供了链路选择的随机性,并且允许结构不遵循设定的模式。
此处简要描述了目的地接入节点处的接收缓冲器管理。如果授权调度器的rbn在gbn之前,并且授权步调器信用可用,则授权调度器会为该队列生成fcp授权消息。源接入节点在接收到队列的fcp授权消息后传输数据分组。目的地接入节点将传入的数据分组存储在缓冲器存储器中。目的地接入节点基于分组序列号对工作单元消息进行重排序,并将工作单元发送到目的地接入节点中的关联流处理器。流处理器可以具有描述符(主机存储器的地址),并且可以将数据从片上缓冲器存储器中的接收器缓冲器移动到服务器中的主机存储器。如果流处理器不能将数据从缓冲器存储器移动到主机存储器,则它应该将数据移动到外部存储器(例如,图9的外部存储器150)。
图17a和图17b是图示了在目的地接入节点处使用fcp授权调度器实现的流公平性的示例的概念图。如果授权调度器在不知道每个源接入节点的流数的情况下生成授权,则可能会在流之间不公平地划分带宽。关于图17a的以下示例图示了不公平的带宽分配。在该示例中使用的带宽数量纯粹是示例性的而非限制性的。两个源(源0和源1)正在向目的地发送业务。源0处有两个流(流0和流1)处于活动状态,源1处有一个流(流2)处于活动状态。每个流都想以100g的速率发送业务,使得源0发送200g的请求消息,并且源1发送100g的请求消息。目的地在两个源之间分配带宽,而与每个源处的活动流数量无关。目的地流失速率为200g,并且目的地将带宽除以源数(即,2),并且以100g向源0和以100g向源1发送授权消息。源0在其两个流之间分配其100g带宽,使得流0和流1各自被授权50g速率。然而,在源1处活动的流2被授权完整的100g速率。结果,与从源1发送的流2经历标称或较低的端到端时延相比,从源0发送的流0和流1经历了较高的端到端时延。
根据本公开的技术,如图17b所图示的,授权调度器被配置为与每个源处活动的流的数量成比例地分配带宽,并且均衡所有流经历的时延。再次,在该示例中使用的带宽数量纯粹是示例性的而非限制性的。为了以公平的方式帮助授权调度,每个源(源0和源1)通过请求消息中承载的流权重将其预期的负载发送到目的地。在该示例中,源0发送带有flowcount(2)的200g请求消息,并且源1发送带有flowcount(1)的100g请求消息(例如,权重=流数,因为在该示例中所有流都针对相同的带宽)。目的地授权调度器根据所传递的权重调度对源的授权。再次,目的地流失速率为200g,并且目的地将带宽除以流数(即,3),并且向133.3g的源0和66.6g的源1发送授权消息。源0在其两个流之间分配其133.3g带宽,使得流0和流1分别被授权66.6g速率,并且源1从处于活动状态的流2也被授权66.6g速率。
通过执行流公平授权调度,目的地响应于其预期的负载向添头源提供公平的带宽分配。通过该修改,该技术可以实现流公平性。如图17b所示,所有流(流0、流1和流2)被授权类似的带宽并且经历类似的时延。授权调度器可以不断地通过传入请求更新流权重。源可以随时改变其预期的权重,并且授权调度器可以基于新的权重来调整带宽分配。
图18-图19图示了fcp分组的示例格式。在这些示例中,每个fcp分组至少包括以太网报头、ip报头和fcp报头。图19的fcp数据分组格式还包括数据有效负载。每个fcp分组可以包括可选的udp报头和可选的fcp安全报头和/或可选的完整性校验值(icv)。在一些示例中,fcp分组可能是通过ipv4上的udp承载的,因此包括可选的udp报头。在其他示例中,fcp分组可以直接通过ipv6承载。
每个示例fcp分组都包括fcp报头,以承载另一侧的信息。fcp报头可以是4字节的倍数,并且大小可变。fcp报头通常可以包括fcp版本字段、fcp分组类型字段(例如,请求、授权、数据或控制)、标识在fcp报头之后的协议(例如,ipv4或ipv6)的下一协议字段、fcp标志(例如,全局端口健康(gph)矩阵大小、存在的时间戳、存在的fcp安全报头)、在目的地接入节点本地的fcp隧道号、fcpqos级别、一个或多个fcp块序列号以及由fcp标志指示的gph矩阵、时间戳和fcp安全报头的可选字段。fcp报头字段可以利用以太网帧循环冗余校验(crc)或fcp安全报头(如果存在的话)进行保护。
如上所述,fcp控制软件在源接入节点和目的地接入节点之间建立双向隧道。可选地保护fcp隧道(加密和认证)。在fcp控制软件为隧道提供端到端加密和认证的示例中,控制协议可以处理密钥的创建和分配,以供加密算法使用。在这些示例中,fcp帧格式可以包括四个不同的连续区域,这些区域由数据是否经过加密和/或认证来定义。例如,未对fcp之前的报头(例如,以太网报头、ip报头中除源地址和目的地地址之外的ip报头以及udp报头)进行加密或认证;ip报头、fcp报头、fcp安全报头和一些有效负载(在数据分组的情况下)的源地址和目的地地址经过认证,但未加密;剩余的有效负载既经过加密也经过认证;并且将icv附加到帧。通过这种方式,对fcp报头中承载的块序列号(例如,rbn、gbn、dbn和/或psn)进行认证,但是不对其进行加密。块序列号的认证避免了对请求和授权消息的欺骗,并保护了源/目的地队列状态机。另外,跨所有可用数据路径对分组流的fcp分组进行喷射,即使不是不可能,也很难侦听或嗅探分组流内的加密数据,因为侦听者或嗅探者将需要访问每个数据路径上的加密分组。
图18是图示了用于请求消息或授权消息的fcp控制分组的示例格式的概念图。在请求消息的情况下,源接入节点会生成fcp请求分组。fcp请求分组的fcp报头承载rbn(请求块号)和标识请求分组的流权重的fcp请求权重字段。目的地接入节点处的授权调度器可以使用流权重公平分配出口带宽,以进行fcp授权生成。在授权消息的情况下,目的地接入节点会生成fcp授权分组。fcp授权分组的fcp报头承载gbn(授权块号)和fcp缩小字段,以请求在源接入节点处缩小请求窗口。
图19是图示了fcp数据分组的示例格式的概念图。源接入节点响应于fcp授权消息发送fcp数据分组。fcp数据分组的fcp报头包括psn(分组序列号)和dbn(数据块号)。源接入节点可以可选地发送具有零有效负载字节的空fcp数据分组和被编程为“无有效负载”的“下一协议”字段。
图20是图示了根据本文描述的技术的具有分组交换网络的示例系统的框图,该分组交换网络具有在分组交换网络上动态配置的多个网络接入节点虚拟结构。如图20所图示的,客户411通过内容/服务提供方网络407和网关设备420耦合到分组交换网络410。服务提供方网络407和网关设备420可以基本上类似于关于图1描述的服务提供方网络7和网关设备20。接入节点417a-417g(统称为“接入节点417”)耦合到分组交换网络410,以处理与接入节点417连接的服务器组(未在图20中示出)之间的信息流,诸如网络分组或存储分组,该接入节点417为与客户411相关联的应用和数据提供计算和存储设施。接入节点417可以基本上类似于上面详细描述的接入节点17或接入节点132中的任何一个来操作。接入节点417也可以称为数据处理单元(dpu)或包括dpu的设备。
在图20的所图示示例中,软件定义网络(sdn)控制器421提供用于配置和管理分组交换网络420的路由和交换基础设施的高级集中式控制器。sdn控制器421提供逻辑上且在一些情况下物理上集中的控制器以利于分组交换网络420内的一个或多个虚拟网络的操作。在一些示例中,sdn控制器421可以响应于从网络管理员接收到的配置输入而操作。
根据所描述的技术,sdn控制器421被配置为在分组交换网络410的物理底层网络之上建立一个或多个虚拟结构430a-430d(统称为“虚拟结构430”)作为覆盖网络。例如,sdn控制器421学习并维护与分组交换网络410耦合的接入节点417的知识。sdn控制器421然后与每个接入节点417建立通信控制信道。sdn控制器421使用其对接入节点417的知识来定义两个或更多个接入节点417的多个集合(多个组)来在分组交换网络420上建立不同的虚拟结构430。更具体地,sdn控制器421可以使用通信控制信道来通知给定集合的每个接入节点417哪些接入节点包括在同一集合中。作为响应,接入节点417通过分组交换网络410与包括在与虚拟结构相同的集合中的其他接入节点一起动态地建立fcp隧道。通过这种方式,sdn控制器421为每个虚拟结构430定义接入节点417的集合,并且接入节点负责建立虚拟结构430。因此,分组交换网络410可能不知道虚拟结构430。
通常,接入节点417接口连接并利用分组交换网络410,以便在同一虚拟结构430的接入节点之间提供全网格(任何到任何)互连。通过这种方式,连接到任何一个接入节点的形成给定虚拟结构430中的一个的服务器可以使用在分组交换网络410内的多个并行数据路径中的任何一个将给定分组流的分组数据传递到与该虚拟结构的接入节点耦合的服务器中的任何其他服务器,该分组交换网络410互连该虚拟结构的接入节点。分组交换网络410可以包括一个或多个数据中心、局域网(lan)、广域网(wan)或一个或多个网络的集合的路由和交换结构。分组交换网络410可以具有任何拓扑,例如,平坦的或多层的,只要相同的虚拟结构的接入节点417之间存在全连接。分组交换网络410可以使用任何技术,包括通过以太网的ip以及其他技术。
在图20所图示的示例中,sdn控制器421定义应该为其建立相应虚拟结构的四组接入节点。sdn控制器421将第一组定义为包括接入节点417a和417b,并且接入节点417a和417b将fcp隧道设置为虚拟结构430a,其中fcp隧道被配置为遍历两个接入节点之间通过分组交换网络410的任何可用路径。另外,sdn控制器421将第二组定义为包括接入节点417b-417d,并且接入节点417b-417d将fcp隧道设置为虚拟结构430b,其中fcp隧道被配置为类似地遍历接入节点之间通过分组交换网络410的任何可用路径。sdn控制器421将第三组定义为包括接入节点417d和417e,并且接入节点417d和417e将fcp隧道设置为虚拟结构430c。sdn控制器421将第四组定义为包括接入节点417e-417g,并且接入节点417e-417g将fcp隧道设置为虚拟结构430d。尽管总体上在图20中示出为虚线箭头,但是四个虚拟结构430的fcp隧道由每组的接入节点417配置为遍历通过分组交换网络410的用于特定虚拟结构的接入节点的可用路径中的任何可用路径或可用路径子集。
用于已定义组的接入节点17使用fcp控制软件与用于同一组的其他接入节点建立fcp隧道以建立虚拟结构,从而支持在可用路径上进行分组喷射。例如,针对虚拟结构430a,虚拟结构430a的接入节点417a和接入节点417b之间的fcp隧道包括通过接入节点417a和417b之间的分组交换网络410的路径中的全部或子集。然后,接入节点417a可以将针对跨分组交换网络410中的多个并行数据路径中的一些或全部的相同分组流的单个分组喷射到接入节点417b,并且接入节点417b可以执行分组重排序以便在虚拟结构430a内提供全网格连接。
每个虚拟结构430可以与在分组交换网络410上建立的其他虚拟结构隔离。通过这种方式,可以重置虚拟结构430中给定的一个虚拟结构(例如,虚拟结构430a)的接入节点,而不会影响分组交换网络410上的其他虚拟结构430,另外,可以为针对每个虚拟结构430定义的一组接入节点417交换不同的安全参数。如上所述,fcp支持隧道的端到端加密。在虚拟结构的情况下,sdn控制器421可以为每个不同的虚拟结构430创建并分配不同的加密密钥,以供接入节点的定义集合内的接入节点使用。通过这种方式,仅虚拟结构430中的给定之一(例如,虚拟结构430a)的接入节点集合可以解密在虚拟结构430a上交换的分组。
图21是图示了根据本文描述的技术的网络系统的操作的示例的流程图。为了便于说明,关于图1的网络系统8描述了图21的流程图,包括数据中心10的服务器12、接入节点17和虚拟结构14。然而,图21所图示的技术容易适用于本文描述的其他示例网络实现。
如该示例中所示,一组接入节点17交换控制平面消息以在多个并行数据路径上建立逻辑隧道,该逻辑隧道在接入节点之间提供基于分组的连接(510)。例如,关于图1,交换结构14可以包括一层或多层交换机和/或路由器,其提供用于在接入节点17之间转发通信的多个路径。可能响应于来自sdn控制器21的方向,接入节点17的相应对交换控制平面消息以协商在接入节点之间的多个并行路径上配置的逻辑端到端隧道。
一旦建立了逻辑隧道,接入节点之一(在图21中称为“源接入节点”)可以从例如应用或存储源服务器12接收与相同分组流相关联的出站分组(512)。作为响应,源接入节点发送fcp请求消息,以请求在分组流中传送的数据量(514)。响应于接收到fcp请求消息,接入节点中的另一接入节点(在图21中被称为“目的地接入节点”)执行授权调度(522)并发送指示为该分组流保留的带宽量的fcp授权消息(524)。
在从目的地接入节点接收到fcp授权消息时,源接入节点将出站分组封装在fcp分组的有效负载内,从而形成每个fcp分组以具有用于遍历逻辑隧道的报头和包含一个或多个出站分组的有效负载(516)。然后,源接入节点通过跨交换结构14上的并行数据路径喷射fcp分组来转发fcp分组(518)。在一些示例实现中,源接入节点可以在跨交换结构14转发fcp分组之前跨例如形成一个或多个接入节点组(例如,在靠近源接入节点的一个或多个逻辑机架组内)的接入节点的子集上喷射fcp分组,从而提供第一级扇出以用于在并行数据路径上分配fcp分组。另外,当fcp分组遍历并行数据路径时,接入节点的每个子集都可以将fcp分组喷射到交换结构14中包括的核心交换机的子集,从而提供达到附加并行数据路径的第二级扇出,因此在提供更高的网络系统可扩展性的同时,仍提供接入节点之间的高级连接。
在接收到fcp分组之后,目的地接入节点提取封装在fcp分组内的出站分组(526),并且将出站分组递送到目的地服务器(528)。在一些示例中,在提取和递送出站分组之前,目的地接入节点首先将fcp分组重排序为源服务器发送的分组流的原始序列。源接入节点将分组序列号指派给分组流的fcp分组中的每一个,使目的地接入节点能够基于fcp分组中的每一个的分组序列号来对fcp分组重排序。
图22是图示了根据本文描述的技术的网络系统的操作的另一示例的流程图。为了便于说明,关于图20的网络系统408描述了图22的流程图,包括分组交换网络410、接入节点417、sdn控制器421和虚拟结构430。然而,图22所图示的技术容易适用于本文描述的其他示例网络实现。
在该示例中,服务器组通过接入节点417和分组交换网络410互连(610)。分组交换网络410的sdn控制器421提供了用于配置和管理分组交换网络420的路由和交换基础设施的高级集中式控制器。sdn控制器421提供了逻辑上的以及在一些情况下物理上集中的控制器,以利于分组交换网络420内的一个或多个虚拟网络的操作。sdn控制器421建立虚拟结构430,每个虚拟结构包括两个或更多个接入节点417的集合(612)。虚拟结构430被建立为分组交换网络410的物理底层网络之上的覆盖网络。更具体地,响应于来自sdn控制器421的通知,给定集合的接入节点(例如,接入节点417b、417c和417d)交换控制平面消息以在给定集合的接入节点之间通过分组交换网络410建立作为虚拟结构(例如,虚拟结构430b)的逻辑隧道。接入节点可以使用fcp将隧道建立为虚拟结构。
虚拟结构430b的第一个接入节点可以从与第一个接入节点耦合并指向与虚拟结构430b的第二个接入节点耦合的目的地服务器的源服务器接收分组的分组流。作为响应,接入节点中的第一个通过分组交换网络410跨并行数据路径将分组喷射到虚拟结构430b的接入节点中的第二个(614)。在接收到分组时,虚拟结构430b的接入节点中的第二个将分组递送到目的地服务器(616)。在一些示例中,在递送分组之前,第二个接入节点将分组重排序为源服务器发送的分组流的原始序列。
已经对各种示例进行了描述。这些和其他示例在以下权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!